基于抗幾何變換的離散深度哈希算法
2021-09-03 10:09:12孫幫勇
西安理工大學學報 2021年2期
劉 芳, 孫幫勇
(1.南京理工大學 計算機科學與工程學院, 江蘇 南京 210014;2.西安理工大學 印刷包裝與數字媒體學院, 陜西 西安 710048)
近似最近鄰搜索方法在大規模視覺搜索中得到了廣泛的應用[1]。哈希技術由于其低存儲量和快速檢索速度而成為近似最近鄰搜索方法中最重要的技術之一。哈希方法的目標是找到一個映射函數可以將每個樣本編碼成哈希碼,同時保持原始樣本的相似性[2]。
現有的哈希方法主要分為兩類:數據獨立的哈希方法和數據依賴的哈希方法。數據獨立的哈希方法是在不使用訓練數據的情況下,利用隨機投影實現有效哈希函數學習,其典型代表是位置敏感哈希(LSH)[1],此類方法在針對較長哈希碼時效果良好,但需要大量存儲[3]。鑒于此問題,學者們又開發了數據依賴的哈希方法[3,4],通過訓練數據來學習哈希函數。然而,這些方法都是利用手工特征進行哈希碼函數學習,無法捕獲原始數據的復雜語義結構[5]。
針對此類問題,有學者引入了深度哈希概念,即利用深度神經網絡捕獲原始數據的復雜語義結構[6]。然而,這些方法在實際應用中存在兩個挑戰。第一,一些哈希方法[5,6]不能充分考慮圖像的幾何變換,這會導致哈希碼的幾何不變性減小,最終影響圖像檢索的性能。第二,對于現有的哈希方法[7,8],首先利用連續松弛策略學習連續近似哈希碼,然后通過量化操作將其轉換為離散哈希碼。因此,這些方法不能在優化過程中直接學習離散哈希碼,這會影響生成的次優哈希碼。
本文提出了一種基于抗幾何變換的離散深度哈希算法,即幾何變換離散哈希(TIDH),利用抗幾何變換和語義監督信息直接生成離散哈希碼。TIDH的概述如圖1所示。為了學習幾何不變性,提出了抗幾何變換模塊,以實現幾何不變描述特征學習。為了學習離散哈希碼,將離散哈希碼學習和特征學習設計在統一的框架中,以便利用語義監督在優化過程中直接學習離散哈希碼。兩個公共檢索數據集CIFAR-10和NUS-WIDE上的實驗結果表明,TIDH可以取得比其他先進哈希方法更好的性能。
1 相關工作
根據標簽信息的利用程度,哈希算法可以分為三類:無監督哈希算法、半監督哈希算法和監督哈希算法,本文回顧了三個相關領域的文獻。
1.1 無監督哈希算法
無監督哈希方法通過未標記的訓練樣本將樣本投射到哈希碼中以學習哈希函數[9-11]。例如,蘇毅娟等[2]結合PCA與流形學習,將原始高維數據降維,然后通過最小方差旋轉得到哈希函數和二值化閾值,進而將原始數據矩陣轉換為哈希編碼矩陣,最后通過計算樣本間漢明距離得到樣本相似性。近年來,無監督深度哈希方法[12-14]利用深度神經網絡捕獲復雜語義結構的優越性能,極大地改善了此前的無監督哈希方法[12-14]。例如,Xia等[13]在不使用標簽信息的情況下,利用自編碼器和受限玻爾茲曼機去實現層次哈希函數學習。Do等[12]開發了一種使用深度神經網絡的無監督離散哈希方法,該方法利用補充變量來解決二進制約束問題。Wu等[14]使用自學的方式進行有效的哈希函數學習。
1.2 半監督哈希算法
半監督哈希方法通過標記的訓練樣本和未標記的訓練樣本將樣本投影到哈希碼中[15-17]。半監督哈希是一種很有代表性的哈希編碼方法,它通過最小化有標簽訓練樣本上的經驗誤差,最大化有標簽訓練樣本和無標簽訓練樣本上的誤差來生成緊湊的哈希編碼。隨著深度神經網絡的發展,出現了大量的半監督深度哈希方法。其中一個典型方法是半監督深度哈希(SSDH),它通過最小化有標簽訓練樣本和無標簽訓練樣本上的誤差來學習有效哈希碼。
1.3 監督哈希算法
監督哈希方法利用帶標記的訓練樣本在保留語義相似性的情況下,進行有效的哈希函數學習[18-21]。例如,劉治等[4]通過設計優化問題的求解方法,改善了哈希算法的效果。唐珂等[3]通過二進制重構嵌入和帶核的監督哈希來進行非線性哈希函數學習。然而,這些方法都是利用手工描述特征來生成哈希碼,無法捕獲原始數據的復雜語義結構。近來,鑒于深度神經網絡強大的特征學習特性,許多深度監督哈希方法已經被開發出來,以保持相似哈希函數學習。例如,Lin等[18]利用深度神經網絡同步進行哈希碼學習和深度特征學習。Yang等[19]開發了一種新的跨批處理引用方法來生成緊湊的哈希碼。Li等[20]提出了一種新的深度聯合語義嵌入哈希方法,可以捕獲樣本之間豐富的語義相關性。Deng等[21]提出了一種新的基于三聯體的深度哈希方法,該方法可以利用三聯體訓練樣本學習哈希碼的相關性。本文是利用抗幾何變換和語義監督信息直接指導離散哈希碼的學習。
2 基于抗幾何變換的離散深度哈希算法
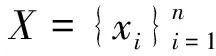
2.1 離散哈希碼學習
TIDH方法將幾何不變性構建模塊、深度特征學習模塊和離散哈希碼學習模塊集成到一個統一的框架中,其總體框架如圖1所示。該方法的體系結構由兩個子網組成,每個子網包含4個具有批處理標準化(BN)的卷積層、4個最大池化層和2個完全連接層。4個卷積層分別采用128個、128個、256個、256個3×3窗口的濾波器,這些卷積層的激活函數均采用整流線性單元(ReLU)。最大池化層使用2×2個窗口。兩個子網絡的卷積層共享相同的權值參數。第一個全連接層的神經元的數量為1 024,激活函數是tanh函數。第二個全連接層是哈希層,它包含K個單位,可以直接生成離散哈希碼。哈希函數可以定義為:
bi=HI(xi)=2×round(ψ(wbThi+vb))-1
(1)
其中,
(2)
式中:bi代表圖像xi的離散哈希碼;hi為圖像xi的深度特征,是圖像xi經過卷積神經網絡學習的全連接層的特征;wb代表哈希層的權重參數;vb代表哈希層的偏置;ψ代表Hard-Sigmoid函數,ψ(x)=max(0,min(1,c+1)/2),c代表實數;HI代表哈希函數。
式(1)中哈希函數難以求導,不適合在網絡訓練過程中傳播梯度。本文受文獻[22]的啟發,利用直通式估計器執行反向傳播,即利用Hard-Tanh函數傳播梯度,Hard-Tanh函數定義為:
Htan(x)=max(-1,min(1,c))
(3)
式中:Htan(·)代表Hard-Tanh函數;max(·)代表最大函數;min(·)代表最小函數。
2.2 幾何不變特征學習
現有研究表明,有效的局部特征不僅存在性質的區別而且可以保持幾何變換不變性[23,24]。因此,所提取的特征需保持三個重要的幾何變換不變性,即旋轉不變性、平移不變性和縮放不變性。為了學習幾何變換不變性的哈希碼,多通過最小化參考圖像和轉換圖像之間的二元特征差異來解決這個問題,一般采用一組旋轉、平移和縮放函數來計算變換后的圖像。為了使二值特征更具特色,本文通過增加任意圖像特征之間的距離來進一步增強二值特征,現將優化問題表述為幾何保持損失函數:
(4)
式中:d=‖bi-bi,g‖;bi代表圖像xi的離散哈希碼;bi,g代表轉換圖像xi,g的離散哈希碼。如果圖像xi與其轉換圖像xi,g相似,則si,g=1;如果圖像xi與其轉換圖像xi,g不相似,則si,g=0。轉換圖像包含旋轉、平移和縮放三種轉換的所有圖像。 在學習過程中,本文通過幾何保持函數將有效的局部特征編碼到深度神經網絡的頂層,然后通過反向傳播優化網絡參數,學習離散哈希碼。
2.3 目標函數
本文的目標是找到合適的映射函數HI,并保持漢明空間中相似樣本的相似性。基于此目的,提出了相似損失函數,以使相似哈希碼盡可能接近,不相似哈希碼盡可能遠離[25]。為保持哈希碼的相似性,可將相似學習損失函數Lp定義為:
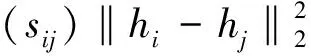
(5)
式中:‖·‖2代表L2的范數;m為常數。
在進行離散哈希碼學習時,上述損失函數的標簽信息并沒有被充分利用[26]。標簽信息可提供有用的監督信息用于增強離散哈希碼的語義信息。本文將通過學習更多的潛在語義信息來提高哈希碼的有效性。其語義監督損失函數為:
(6)
式中:Ll為語義監督損失函數,可保證離散哈希碼具有語義屬性;δ(·)為softmax函數;yi為圖像xi的標簽信息;wl為權重參數。
綜合考慮上述等式,TIDH的最終目標函數L為:
(7)
式中:α和β表示控制參數。
最終目標函數式(7)是凸函數,可通過深度學習庫TensorFlow中的Adam優化器進行優化。該算法可利用語義監督來指導離散哈希碼學習,使生成的哈希碼包含更多語義信息和抗幾何變換性質。
3 實驗及結果分析
3.1 實驗數據及環境
本文實驗環境為:GeForce GTX Titan X GPU、中央處理器為 Intel(R) Core i7-5930K 3.50 GHz、內存為64 G、操作系統為Ubuntu 14.04。根據本文提出的方法對兩個基準數據集CIFAR-10和NUS-WIDE進行評估。
1) CIFAR-10圖像數據庫:該數據集是檢索時使用最廣泛的數據集之一。包含10個對象類別,每個類包含6 000張圖片,總計60 000張圖片。這些類包含飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船和卡車等內容。數據集被分成訓練集和測試集,分別有50 000和10 000張圖像。本文將使用訓練集進行網絡訓練,使用測試集作為檢索評估的查詢。
2) NUS-WIDE圖像數據庫:NUS-WIDE數據集是從Flickr網站收集的大規模多標簽數據集,它包含了與81個概念相關的269 648個樣本,每個概念至少包含5 000個樣本。本文從21個最常見的概念中選取了195 969個樣本。如果兩個樣本共享至少有一個概念,則它們被認為是相似的,否則,它們被認為是不同的。本文將從21個最常見的概念中隨機抽取100個樣本作為查詢,剩下的樣本作為訓練集和圖庫集。
將提出的TIDH方法與9種最新的哈希方法進行比較,包括BRE[27]、MLH[28]、KSH[29]、DSRH[30]、DSCH[31]、DRSCH[31]、DHN[6]、DPSH[20]和DDSH[32]。在這些方法中,BRE、MLH和KSH是非深度方法,它們利用512維的GIST描述符作為CIFAR-10和NUS-WIDE數據集的輸入。對于利用深度特性的非深度方法(例如BRE-CNN、 MLH-CNN和KSH-CNN),本文利用CNN的4 096維特征來表示CIFAR-10和NUS-WIDE數據集的每一幅圖像。對于深度學習方法(例如DSRH、DSCH、DRSCH、DHN、DPSH和DDSH),本文使用128×128的圖像作為三個數據集的輸入。采用三個漢明排名指標來評價TIDH和其他方法。這些指標分別為平均精度(MAP)、前500幅檢索圖像的精度(precision@500)和前k幅檢索圖像的精度(precision@k)。這三個指標可以反映檢索性能[27],其指標值越大,表示檢索性能越好。
3.2 實驗結果分析
表1顯示了CIFAR-10數據集上不同位數圖像的檢索結果。圖2(a)顯示了CIFAR-10數據集上不同哈希位返回的前500幅圖像的精度曲線;圖2(b)顯示了CIFAR-10數據集上64位哈希位不同返回圖像的精度曲線。
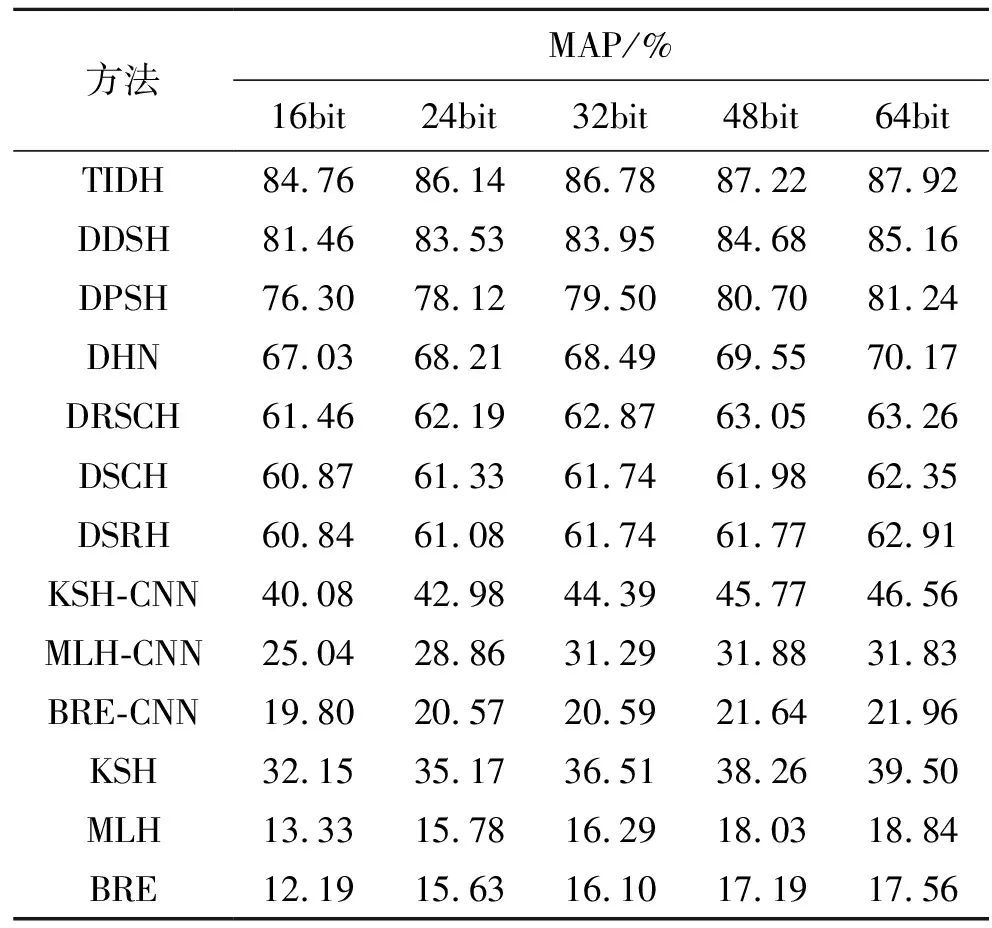
表1 CIFAR-10數據庫上不同監督哈希算法的性能對比Tab.1 Performance comparison of different supervisedHashing algorithms on the CIFAR-10 dataset
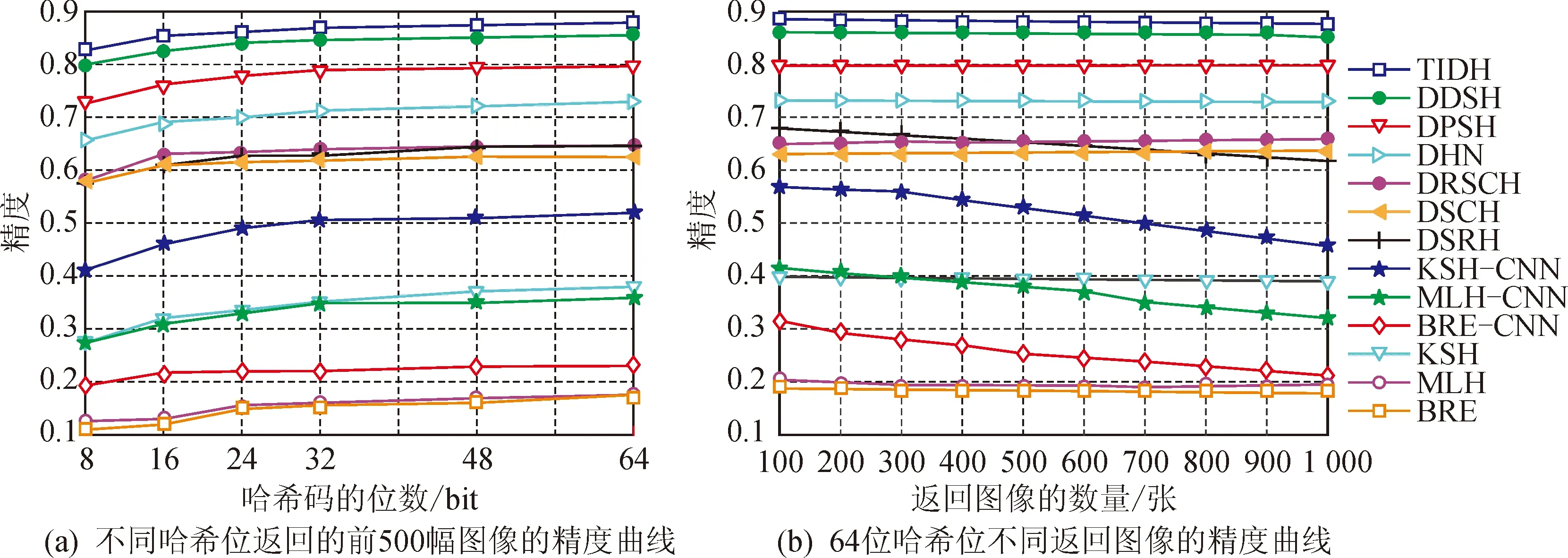
圖2 CIFAR-10數據集上的實驗結果Fig.2 Experimental results on CIFAR-10 dataset
由此可見:①使用4 096維CNN特征的非深度檢索方法較使用512維GIST特征的檢索方法獲得的檢索性能更佳,例如,BRE-CNN可將32位的檢索映射結果從BRE的16.10%提高到20.59%,驗證了深層特征可提高非深層方法的性能;②在CIFAR-10數據集上,對于不同的哈希位,TIDH方法比9種現有哈希方法獲得的映射結果更好;對于CIFAR-10數據集,TIDH方法的檢索效果最佳,此外,相較于以前最佳方法DDSH的85.16%,TIDH方法的檢索準確率提高到87.92%,驗證了TIDH方法對三個模塊更加有效;③雖然其他兩個指標比較顯示,9種現有哈希方法在兩個指標上都取得了良好的性能,但在不同bit的前500幅返回圖像的檢索結果上,TIDH方法的表現仍然相對更好,特別是在64bit的不同返回圖像的檢索結果上,TIDH方法更為優越,也取得了更好的檢索結果;④TIDH方法檢索結果顯示:本文采取的利用抗幾何變換和語義監督信息直接生成離散哈希碼的策略,使得深度哈希方法在圖像檢索方面具有有效性。
與CIFAR-10數據集相比,NUS-WIDE是一個更加復雜的多標簽數據集。為了進一步評價所提TIDH方法的有效性,將其與其他幾種哈希方法進行比較,包括BRE、MLH、KSH、DSRH、DSCH、DRSCH、DHN、DPSH和DDSH。表2顯示了NUS-WIDE數據集上不同bit的圖像檢索結果。圖3(a)顯示了NUS-WIDE數據集上不同哈希位返回的前500幅圖像的精度曲線;圖3(b)顯示了NUS-WIDE數據集上64位哈希位不同返回圖像的精度曲線。由此可以看出,在精度曲線上,所提出的TIDH方法已經超過6種深度哈希方法(即DSRH、DSCH、DRSCH、DHN、DPSH和DDSH),而且該法還將48位檢索映射結果從61.98% (DSCH)、61.77% (DSRH)、63.05% (DRSCH)、79.95%(DHN)、82.58% (DPSH)、82.74% (DDSH)提高到84.18%。此結果表明,TIDH方法不僅能利用抗幾何變換模塊來實現幾何不變描述特征學習,而且還能利用監督信息來學習離散哈希碼。
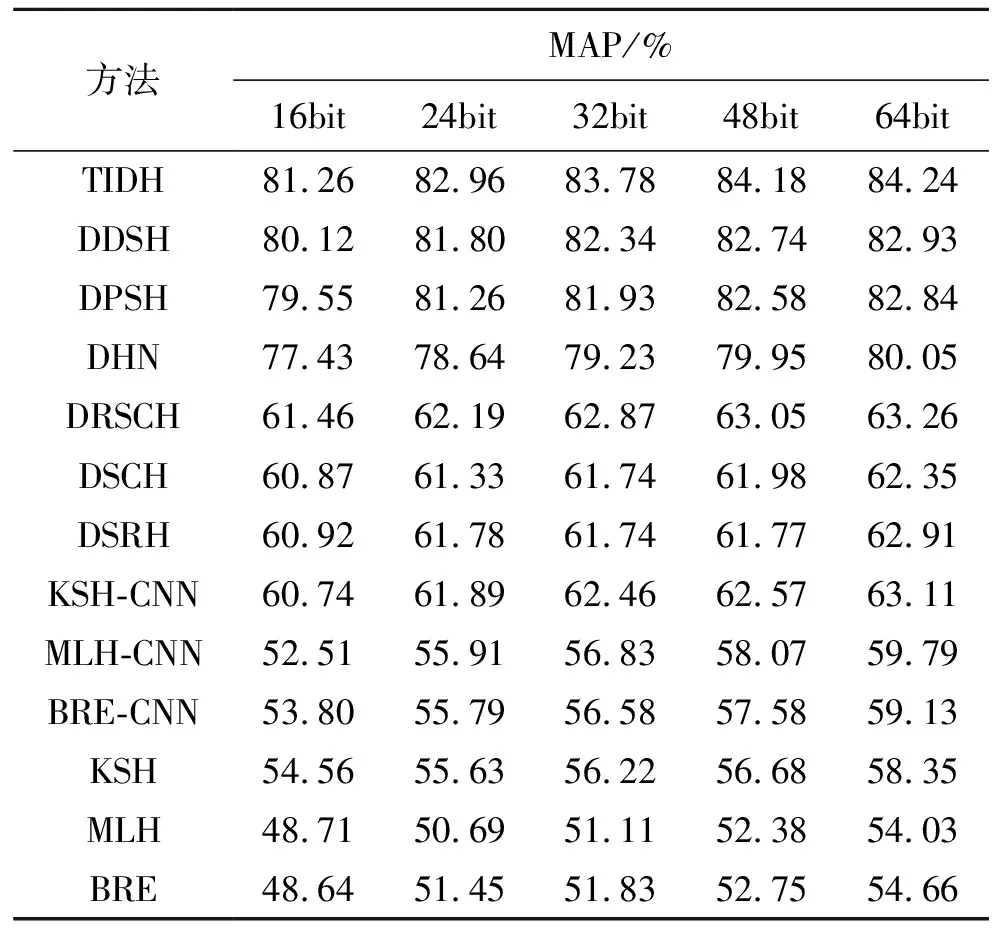
表2 NUS-WIDE數據庫上不同監督哈希算法的性能對比Tab.2 Performance comparison of different supervisedHashing algorithms on the NUS-WIDE dataset
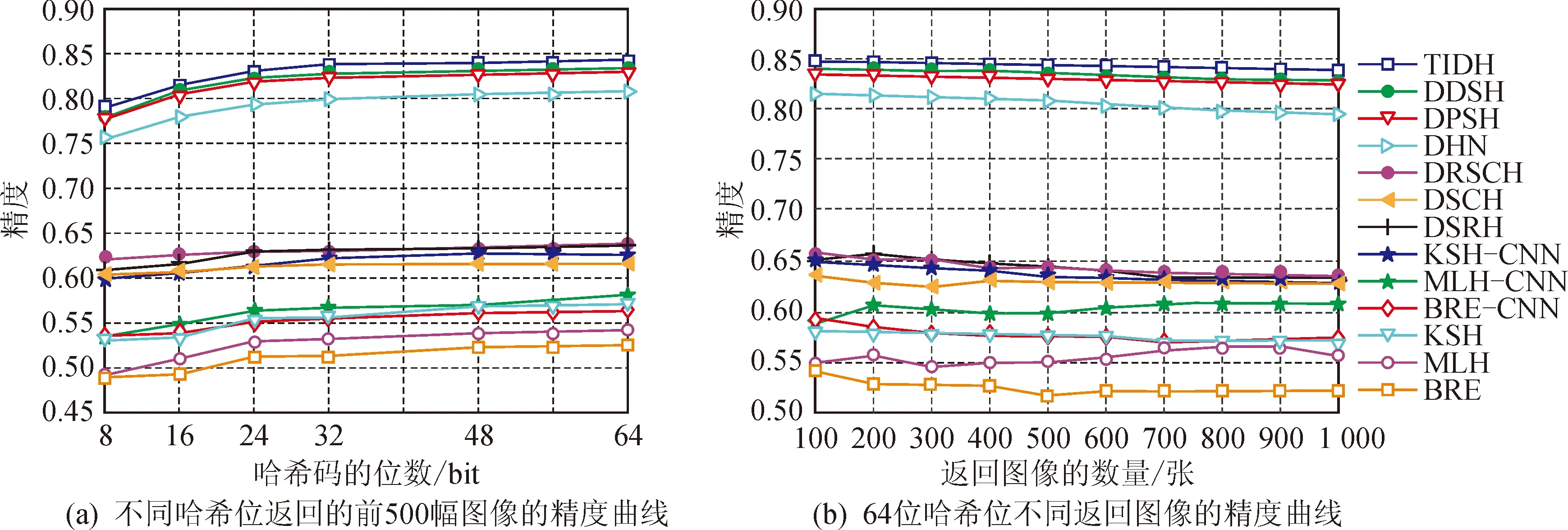
圖3 NUS-WIDE數據集上的實驗結果Fig.3 Experimental results on NUS-WIDE dataset
4 結 語
本文提出了一種基于抗幾何變換的離散深度哈希算法,該算法利用抗幾何變換和語義監督信息直接生成離散哈希碼。為了學習幾何不變性,提出了抗幾何變換模塊,以實現幾何不變描述特征學習。為了學習離散哈希碼,將離散哈希碼學習和特征學習設計在統一的框架中,以便利用語義監督在優化過程中直接學習離散哈希碼。在兩個數據集CIFAR-10和NUS-WIDE上的大量實驗結果表明,所提出的TIDH方法是有效的,其性能較其他最新、最先進的哈希方法更為優越。該方法可應用于行人再識別、跨模態學習等領域。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年4期)2020-09-21 03:39:12
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
