基于CycleGAN的人臉素描圖像生成
2021-08-27 06:38:22徐志鵬盧官明羅燕晴
計算機技術與發展 2021年8期
徐志鵬,盧官明,羅燕晴
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
0 引 言
圖像風格轉換是指在保留原圖像內容信息的基礎上生成具有新風格的圖像的一種技術,在藝術創作和社交娛樂等方面有著潛在的應用前景,受到學術界和工業界的高度關注。Gatys L A等人在2016年提出了一種基于卷積神經網絡的風格轉換方法[1],通過預訓練模型VGG-19[2]對圖像的內容特征和風格特征進行剝離,實現圖像風格轉換。通過實驗,Gatys等人發現卷積神經網絡可以實現圖像內容和風格的分離,圖像風格轉換可以取得較好的效果,但是生成圖像的過程非常耗時,并且訓練好的生成模型無法應用在其他風格轉換的任務上,推廣應用受限制。Goodfellow I等人開創性地提出生成對抗網絡[3](generative adversarial networks,GAN),對圖像風格轉換領域有著重大的意義,相繼出現了基于GAN的風格轉換模型,主要包括Pix2Pix[4]、CycleGAN[5]和StarGAN[6]等模型。其中,Pix2Pix和CycleGAN模型適用于兩個不同風格圖像域之間的轉換,而StarGAN模型則可以實現多個圖像域之間的風格轉換。Pix2Pix使用U-Net[7]模型,有效地保留不同尺度的特征信息,提升生成圖像的細節效果,適合應用于特定的圖像風格轉換任務。CycleGAN模型通過添加循環一致性損失函數,成功地解決了缺少成對的訓練圖像的問題。StarGAN模型解決了多個圖像域間的風格轉換的難題,只需要訓練一個生成器模型就可以實現多個圖像域間的風格轉換。
由于人臉圖像具有較多的細節信息,采用原CycleGAN模型很難很好地處理人臉圖像的細節信息,導致生成圖像的視覺效果較差。文中針對人臉素描圖像風格轉換任務,在CycleGAN的基礎上,通過改進生成器的網絡結構,更好地保留人臉圖像的細節信息,生成高質量的圖像。實驗結果表明,使用改進CycleGAN模型可以得到更高質量的圖像,驗證了該方法的有效性。
1 相關理論
1.1 GAN
GAN是由生成器G(generator)和鑒別器D(discriminator)共同構成的深度學習模型,生成器G負責學習訓練圖像集的概率分布規律并生成具有相似概率分布規律的圖像;鑒別器D負責判別輸入圖像是生成的圖像還是訓練圖像。通過讓生成器G和鑒別器D進行對抗訓練,使生成器G生成的圖像具有與訓練圖像相似的風格,鑒別器D判別生成的圖像和訓練圖像的能力也得到不斷提高,最終使得生成器G和鑒別器D達到一種穩定平衡狀態,又稱納什均衡。GAN的網絡結構如圖1所示。
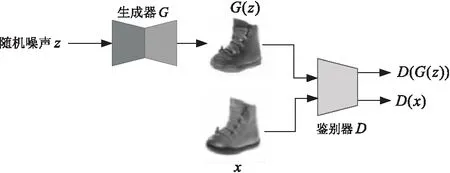
圖1 GAN網絡結構
隨機噪聲z是生成器G的輸入,x是訓練圖像,G(z)表示生成圖像,D(G(z))表示鑒別器D判定生成的圖像G(z)是訓練圖像的概率,D(x)表示鑒別器D判定圖像x是訓練圖像的概率。
目前,GAN越來越受到學術界和工業界的重視,許多基于GAN的衍生模型已經被廣泛應用于圖像風格轉換[8]、超分辨率[9]、圖像修復[10,11]等領域,并不斷向著其他領域繼續延伸,具有廣闊的發展前景[12]。
1.2 CycleGAN
CycleGAN是由Zhu J Y等人提出的風格轉換模型,該模型包含兩個生成器和兩個鑒別器,通過引入循環一致性損失函數,可以在缺少成對訓練圖像的條件下實現兩個不同風格的圖像域之間的轉換。CycleGAN模型結構如圖2所示。
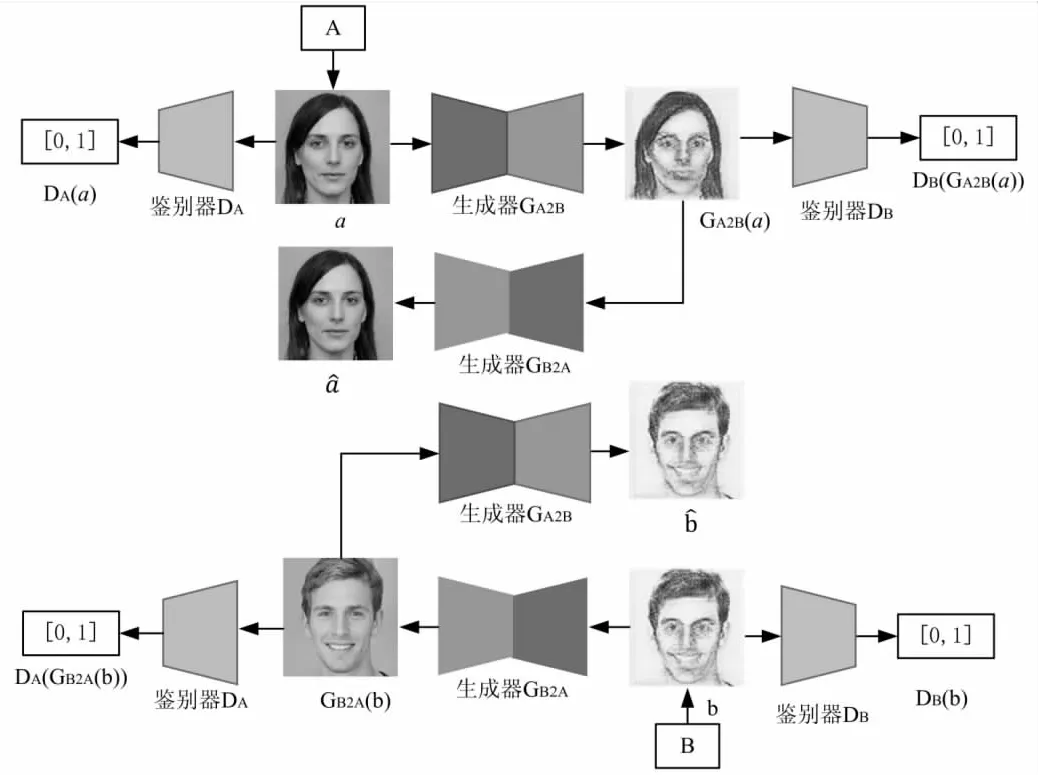
圖2 CycleGAN模型結構
1.2.1 損失函數
CycleGAN的損失函數是由對抗性損失和循環一致性損失兩部分共同組成。
CycleGAN模型擁有兩個生成器和兩個鑒別器,分別實現A圖像域→B圖像域的風格轉換和B圖像域→A圖像域的風格轉換,所以CycleGAN的對抗性損失將由兩部分構成,將A圖像域→B圖像域的風格轉換的對抗性損失記作LA2B,B圖像域→A圖像域的風格轉換的對抗性損失記作LB2A。
LA2B=Eb~pdata(b)[logDB(b)]+Ea~pdata(a)[log(1-
DB(GA2B(a)))]
(1)
LB2A=Ea~pdata(a)[logDA(a)]+Eb~pdata(b)[log(1-
DA(GB2A(b)))]
(2)
式中,pdata(a)和pdata(b)分別表示A圖像域的概率分布和B圖像域的概率分布。
CycleGAN的對抗性損失LGAN如下:
LGAN=LA2B+LB2A
(3)
LSGAN[13]證明采用最小二乘損失函數可以加速模型收斂速度,提高生成圖像的質量,因此在CycleGAN的實際訓練中,將其對抗性損失LGAN中的對數運算優化成平方運算:
LA2B=Eb~pdata(b)[DB(b)]2+Ea~pdata(a)[1-
DB(GA2B(a))]2
(4)
LB2A=Ea~pdata(a)[DA(a)]2+Eb~pdata(b)[1-
DA(GB2A(b))]2
(5)
通過引入對抗性損失函數,使得鑒別器DA無法區分生成圖像GA2B(a)和B圖像域的概率分布,鑒別器DB無法區分生成圖像GB2A(b)和A圖像域的概率分布。
CycleGAN總的損失函數LCycleGAN如下:
LCycleGAN=LGAN+λ×LCycle
(7)
式(7)中,參數λ為循環一致性損失的權重,控制著抗性損失和循環一致性損失的相對重要性。
1.2.2 生成器和鑒別器的網絡結構


圖3 生成器網絡結構
CycleGAN的生成器網絡采用殘差塊結構,通過在深層網絡上添加一條直連路徑,確保了梯度信息能夠有效地在深層網絡中進行傳遞,成功地解決深層網絡中存在的梯度消失問題,改善深層網絡的性能。反卷積(deconvolution)[16]又被稱為轉置卷積,是卷積的逆運算,用于圖像生成。
CycleGAN的鑒別器使用PatchGAN[4]結構,其網絡結構如圖4所示。

圖4 鑒別器網絡結構
不同于普通鑒別器,PatchGAN的輸出是一個N*N的矩陣,矩陣中的每一個元素值代表著鑒別器對輸入圖像中的每一個patch的判別結果,再將矩陣的均值作為整幅圖像的最終判別結果。這種結構的鑒別器具有更少的參數,可以縮短訓練時長,并且適用于任意尺寸的圖像,有效地捕捉圖像局部的高頻特征,使生成的圖像保持高分辨率和高細節。
2 基于注意力機制的CycleGAN
注意力機制(attention mechanism,AM)是一種改進神經網絡的方法,在近些年得到迅速發展,出現了許多基于注意力機制的深度學習網絡,極大地豐富了神經網絡的表示能力。注意力機制主要是通過添加權重的方式,強化重要程度高的特征并弱化重要程度較低的特征,從而改善神經網絡模型的性能。注意力機制得到的權重可以作用在原始圖上[17-18],也可以作用在特征圖上[19]。目前,注意力機制已經在圖像分類[20-21]和圖像分割[22]等計算機視覺任務中取得較好的效果。
從注意力域的角度來分析,可以將注意力機制分為三類:空間域(spatial domain)、通道域(channel domain)和混合域(mixed domain)。空間域注意力機制的代表是spatial transformer networks(STN)[23]。STN通過圖像進行空間變換,提取出關鍵信息,降低圖像中無用信息對模型訓練的干擾,從而提升網絡的性能。空間域注意力機制主要適用于對輸入圖像的處理。通道域注意力機制的代表是squeeze-and-excitation networks(SENet)[24]。SENet能夠計算出特征圖的每一個特征通道的權重值,并實現特征通道的權重分配,從而增強重要特征對當前任務所起的作用。將空間域注意力機制和通道域注意力機制進行組合,即混合域注意力機制,可以對特征圖中每個元素同時實現空間域和通道域的注意力機制。
文中提出的改進CycleGAN模型主要是將空間域和通道域注意力機制用于生成器網絡中,所采用的空間域和通道域注意力機制的結構如圖5所示。
假設空間域和通道域注意力機制輸入的特征圖的尺寸均為c*w*h,中間各層的運算結果如表1和表2所示。
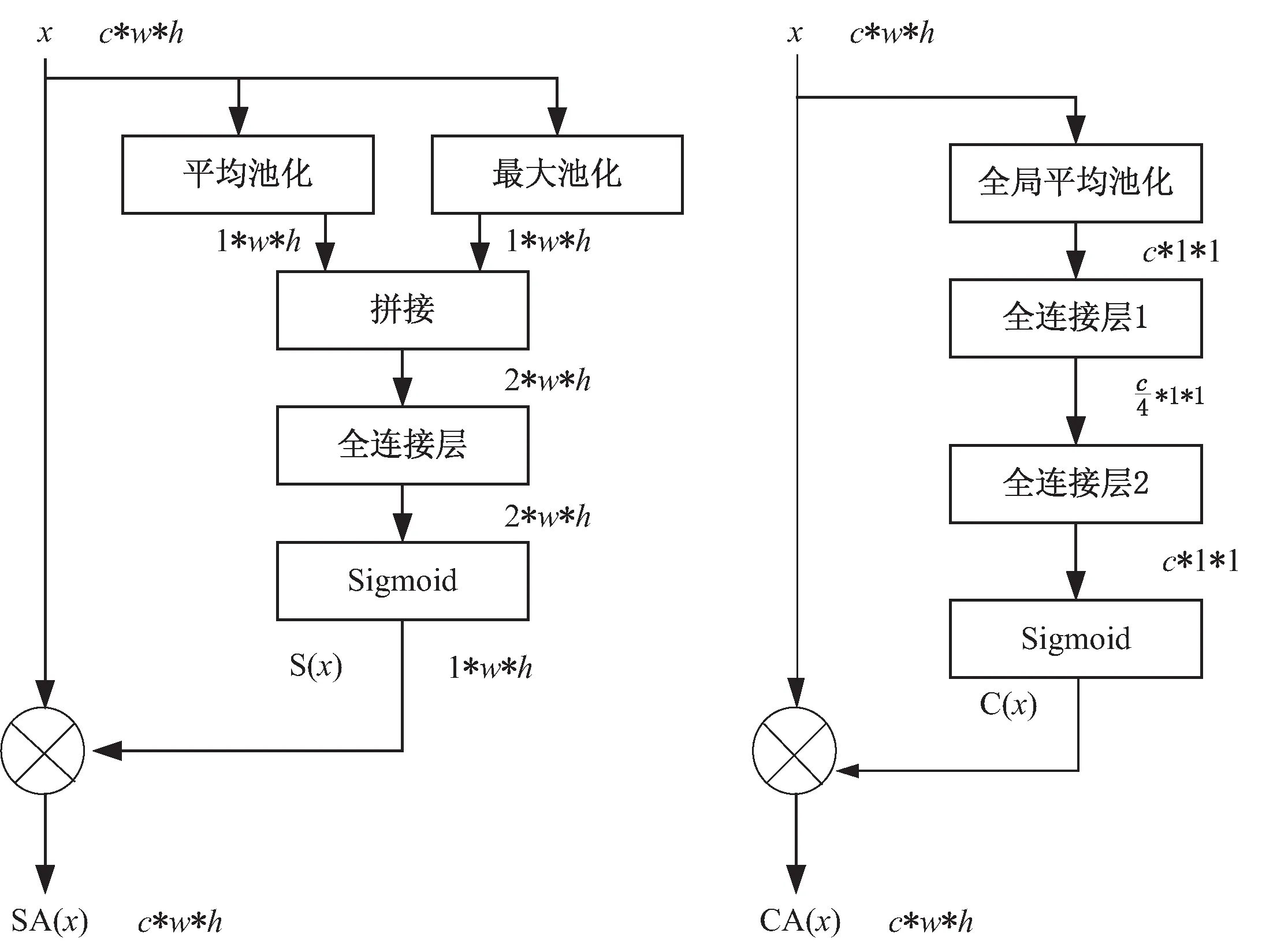
(a)空間域 (b)通道域

表1 空間域注意力機制的各層輸出結果

表2 通道域注意力機制的各層輸出結果
基于注意力機制的殘差塊(AM殘差塊)模型結構如圖6所示。AM殘差塊模型結合殘差模塊和注意力機制的優點,既可以緩解在深度神經網絡中增加網絡深度帶來的梯度消失問題,又可以在只需要增加較少的計算量的情況下減少無用信息對模型的干擾,提升網絡的表現力,改善生成圖像的質量。
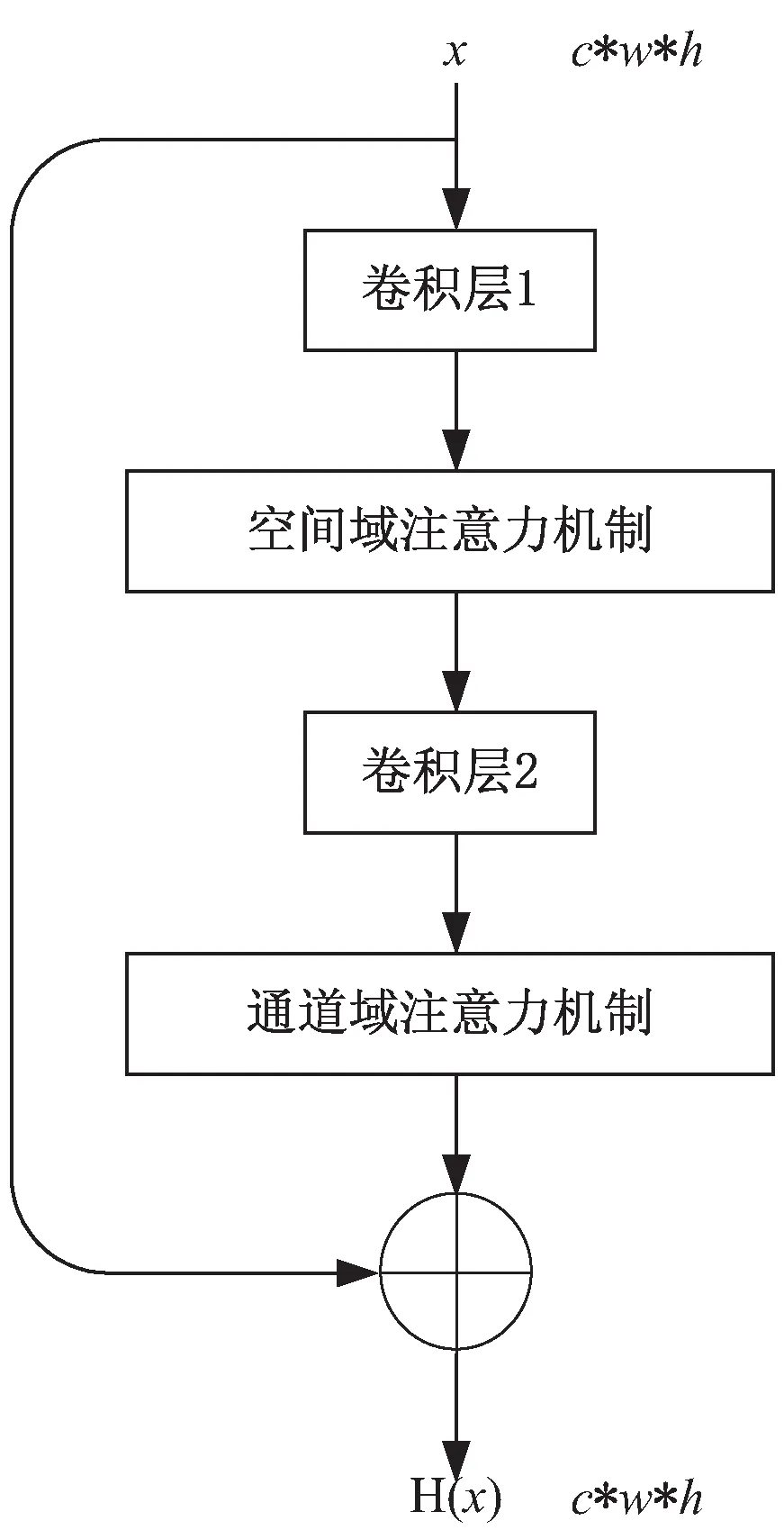
圖6 AM殘差塊
基于注意力機制的CycleGAN生成器網絡結構如圖7所示。
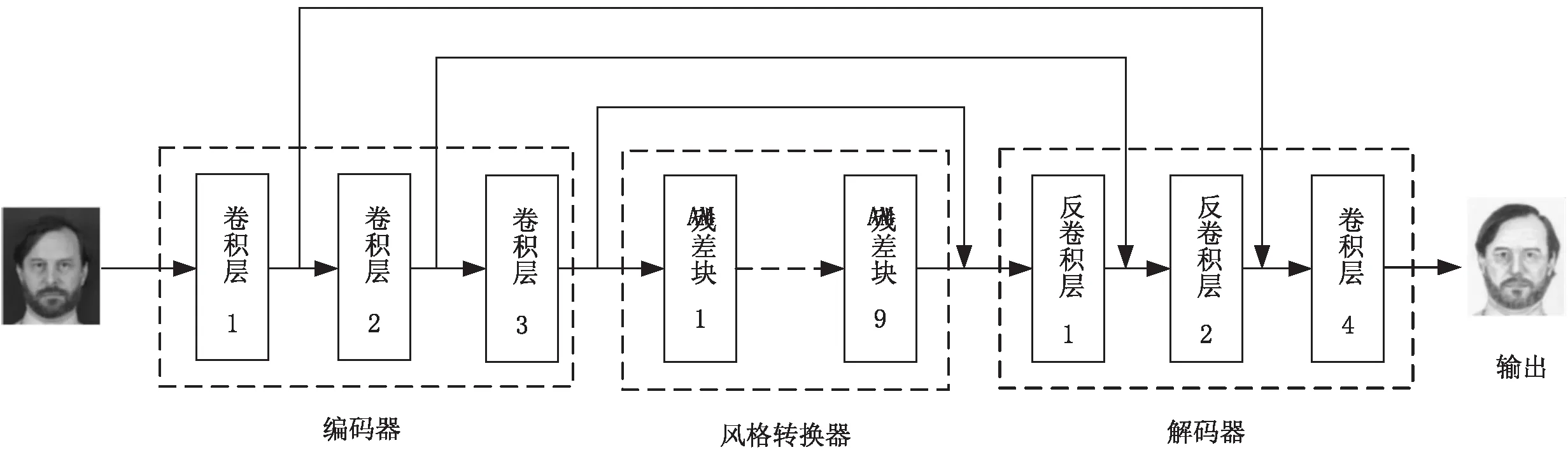
圖7 基于注意力機制的CycleGAN生成器網絡結構
文中在CycleGAN的生成器網絡中添加跳躍連接機制,實現將編碼器中卷積運算得到的特征圖傳遞到解碼器中,使得解碼器可以學習更多不同尺度的特征信息,改善生成的人臉素描圖像質量。文中提出的基于注意力機制的CycleGAN的鑒別器采用圖4所示的PatchGAN網絡結構。
3 實驗與結果分析
實驗的硬件平臺為Intel Xeon CPU E5-2650 v4,使用NVIDIA GTX 1080 GPU進行加速處理。實驗選取從網絡上收集到的300張人臉圖像和CUFSF數據集[25-26]中1 194張素描人臉圖像作為訓練數據集;選取CUFS數據集[26]中88張學生人臉圖像作為測試圖像;將所有訓練圖像和測試圖像的大小縮放為256*256像素。優化器采用性能較好的Adam算法,參數beta1和beta2分別設置為0.5和0.999,學習率lr設置為0.002。
如圖8所示,當網絡模型進行40個epoch迭代訓練之后,已經能夠實現通過人臉彩色照片生成黑白人臉圖像,初具素描風格,但是生成圖像的邊緣比較模糊;當進行60個epoch迭代訓練之后,生成圖像邊緣逐漸清晰,具有較明顯的素描風格;當進行80個epoch迭代訓練之后,可以生成較為逼真的人臉素描圖像。通過對比發現,文中提出的改進CycleGAN模型生成的圖像比CycleGAN和DualGAN生成的圖像更加清晰,在圖像邊緣處處理地更好,更好地保留了人臉五官特征和表情等有效信息。
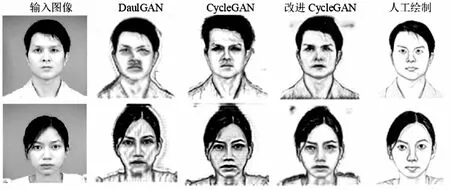
(a)epoch=40

(b)epoch=60
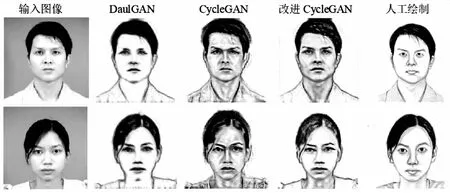
(c)epoch=80
4 結束語
當今網絡社交媒體擁有著巨大的用戶量,如果可以發布一些關于圖像風格轉換的手機端應用程序,讓用戶充分發揮藝術創造力,設計屬于自己的特有風格的作品,這會讓圖像風格轉換技術走進人們日常生活。但是,現階段的圖像風格轉換領域仍然存在一些問題。首先,目前主流的基于深度學習的圖像風格轉換算法,存在模型的參數數量過多,訓練耗時較長。其次,很難將需要進行風格轉換的部分從原圖中分割出來,無法實現局部圖像風格化,導致一些生成圖像質量較低。
文中主要對CycleGAN的生成器模型進行改進,將空間域和通道域注意力機制用于生成器網絡中,減小無用信息對生成器的影響,加強生成器對輸入圖像中的人臉重要部分的學習,提升生成的人臉素描圖像的質量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年3期)2014-11-12 13:18:12
