一種基于意圖的設計模式排序與優化方法
2021-08-27 06:38:20歷子謙
計算機技術與發展 2021年8期
關 慧,歷子謙,呂 穎
(1.沈陽化工大學 計算機科學與技術學院,遼寧 沈陽 110028;2.遼寧省化工過程工業智能化技術重點實驗室,遼寧 沈陽 110142)
0 引 言
軟件工程的發展使得設計模式的使用成為一種合理的實踐,使用設計模式是解決開發團隊中反復出現問題的首選方法,它可以避免“造輪子”,也可以簡化針對正在解決問題部分的解決方案進行交流[1]。但是在沒有任何工具的支持下,要找到正確的設計模式來解決給定的設計問題是非常困難的,因為確定設計模式對給定問題的適用性很大程度上依賴于軟件開發人員的經驗,而且對于不熟悉設計模式且不知道如何找到最佳模式的新手開發人員來說也是極其困難的[2]。此外還有大量的設計模式,如Booch 2006,Coad 1995,Douglass 2002等,對于非常了解模式的開發人員也十分具有挑戰性[3-4]。設計模式主要由設計意圖、適用性、結構等部分組成,H.Kampffmeyer[5]認為設計意圖部分是理解設計模式的最短路徑,因此通過設計模式意圖的處理對于設計模式的選擇是十分有必要的。
1 相關研究
很多學者就設計模式的選擇做了相關的研究。M.R.J.Qureshi等[6]在問題驅動幫助用戶選擇設計模式上做了一番研究,設計模式中一些特定的場景的表達,需要人工參與解釋,這樣有利于相對精確地選擇正確設計模式,但對于問題來說,通常是靜態或者通用,而且在模式數量巨大的情況下,構造問題也是一個極具挑戰性的任務。Suresh S等[7]使用文本分類和文本檢索技術,為每個設計模式類訓練一個分類器,但分類器的分類能力與樣本容量和稀疏密度密切相關;Hussian等[8]基于本體和文本匹配場景,基于本體方法的缺點在于構造很昂貴,并且給方法自動化帶來障礙。Gupta等[9]使用了歸一化互相關幫助用戶選擇模式,歸一化互相關技術已經廣泛應用于機器視覺,用圖像中的相關程度匹配引申到設計模式的匹配上,優點是給類圖之間比較提供了量化的方法,但只在結構上判定兩個設計是否相似,其正確性也有待斟酌。Smith等[10]設計的選擇方法,基于在設計文檔或代碼中檢測反模式的設計模式,在代碼級推薦設計模式是一個好的想法,但在代碼開發階段再考慮設計模式為時已晚,因為軟件已經設計好了,還需要更改就變成很麻煩的事。Issaoui等[11]使用了一個相似矩陣來比較從設計中提取的詞語(類名、方法名等)和模式參與者扮演的角色,并與設計人員交互,獲得設計片段的上下文的文本描述,通過預先設計的模式問題精煉結果,該方法改進了單一使用某個方面選擇模式的缺點,但設計問題需要提前設計,當模式數量巨大時同樣將面臨問題。P.Gomes等[12]采用了一種基于案例推論的方法,案例表示在過去的軟件設計中已經應用了模式的情況,用類圖來描述案例,但其缺點是圖并不總是有用的,也不能產生相關性分數。W.Muangon等[13-14]提出了一種基于案例推理和形式概念分析相結合的內聚技術的解決方案,這種集成使得檢索組織能夠構造一個完整的設計問題描述,用來尋找合適的設計模式。
2 基于意圖的設計模式排序
本方法通過Stanford Parser對設計模式的意圖文本和設計模式實際問題做文本預處理,得到相應的詞對集,表示成相應的向量,通過定義的詞對匹配評分函數,為設計模式意圖和實際問題評出相似度評分,降序排序得到設計模式的排序結果。整體流程如圖1所示。

圖1 方法整體流程
2.1 文本預處理
從文本提取關鍵詞使用Stanford Parser的Stanford Dependency parser[15-16]生成表述每個句子中成對單詞之間的語法依賴類型。在語法分析器提供的48個Type dependency(Td)中,只有四個提供了與輸入問題相關的實體和意圖[17],分別如表1所示。

表1 四種Td的含義與組合詞性
詞形還原(Lemmatization)被用來還原單詞形態,其使用已知單詞形式組成的字典,并考慮單詞在句子中的作用,將單詞標準化為詞元。
例如:Decorate模式的意圖“Attach additional responsibilities to an object dynamically. Decorators provide a flexible alternative to sub classing for extending functionality.”解析見表2。

表2 Decorate模式意圖抽取Td結果
文本預處理通過上述兩個方法,首先將設計模式意圖解析成語法關系,提取所需的單詞對,然后通過詞形還原獲得標準化后的單詞。
2.2 文本向量
設計模式的意圖通過解析成單詞對,表示成為設計模式向量(DPV),當輸入問題時,產生輸入問題向量(IPV),每種模式的DPV和IPV之間需要計算一個相似度,根據計算得出的相似度得分進行排序。由于不同Td之間相應位置詞的詞性有所不同,組合的方式不同,所以將文本預處理獲得的單詞對分為多個集合,分別為nsubj,nsubjp,dobj和nmod。
DPV與IPV之間的關系如圖2所示,Xi,Yi分別表示DPV與IPV的TdSet中的元素。

圖2 文本向量之間的關系
2.3 Match評分
為了增加關鍵詞的匹配,考慮WordNet中同義詞(synonyms)、上位詞(hypernyms)、下位詞(hyponyms)的匹配,當匹配的是詞匯的上位詞和下位詞時,從匹配得分中扣除懲罰項(Ps),由于單詞對比單個單詞所蘊含的語義信息更豐富,所以當兩個單詞都得到匹配時,則獲得一定獎勵。例如“provide alternative”和“supply alternative”的計算匹配得分為:(1)“supply”是“provide”的上位詞,所以匹配的分為1-Ps;(2)“alternative”和“alternative”是相同的詞,匹配得分為1;(3)兩個詞都匹配上,額外獲得獎勵1。所以總分為(1-Ps)+1+1。文中定義算法如下:
以下偽代碼中synonyms(a,b),hypernym(a,b)和hyponym(a,b)在返回a,b在WordNet中是否為同義/相等,a是否為b的上位詞和a是否為b的下位詞,返回的是boolean型。
輸入:A,B分別是設計模式和問題相應TdSet中的一個元素,Ps是懲罰項,syn,hyper,hypo分別為同義、上位和下位詞的匹配是否開啟的參數,取值boolean型。
輸出:Score是A,B兩個Td的相似性評分。
步驟:
初始化:govscore=0,depscore=0
if synonyms(A.gov,B.gov) & & syn==true then
govscore+=1
end if
if(hypernym(A.gov,B.gov)& & hyper==true) ||
(hyponoym(A.gov,B.gov)& & hypo==true) then
govsocre+=1-Ps
end if
if synonyms(A.dep,B.dep) & & syn==true then
depscore += 1
end if
if (hypernym(A.dep,B.dep)& & hyper==true) ||
(hyponoym(A.dep,B.dep)& & hypo==true) then
depsocre+=1-Ps
end if
Score=govscore+depscore
if depscore>0 & & govscore>0 then
score+=1
end if
Return scorsse
WordNet中的Td類型不同,搭配的詞性不同,所以匹配時將不同集合分別計算,計算公式如下:
其中,Tdi∈{nsubj,nsubjp,dobj,nomd}。
2.4 相似度函數
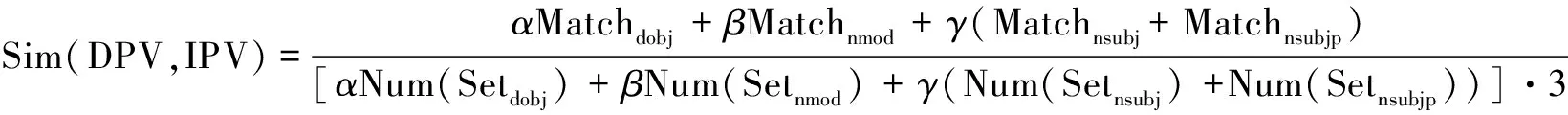
其中,α,β,γ為權重參數;DPV為設計模式向量;IPV為問題向量;Num(SetTdi)為設計模式Td集合中元素的數量;MatchTdi(DpSet,IpSet)為設計模式與問題在Tdi上的匹配評分。
相似度函數性質:
(a)相似度的值應在[0,1];
(b)當進行比較的兩個向量屬性相同時,相似度為1,完全不同時,相似度為0。
證明:
設:設計模式向量為DPV,輸入問題向量為IPV。
(1)當DPV≠IPV時,Sim(DPV,IPV)=0。
∵DPV≠IPV
∴MatchTdi(DpSet,IpSet)=0,
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+
γ(Num(Setnsubj)+Num(Setnsubjp))]*3≠0
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+
γ(Num(Setnsubj)+Num(Setnsubjp))]·3≠0
∴Sim(DPV,IPV)=0
Tdi∈{nusbj,nsubjp,dobj,nmod}
∵[αNum(Setdobj)+βNum(Setnmod)+γ(Num(Setnsubj)+Num(Setnsubjp))]·3≠0
∴Sim(DPV,IPV)=0
(2)當DPV=IPV時,Sim(DPV,IPV)=1。
∵DPV=IPV
∴MatchTdt(DpSet,IpSet)=Num(SetTdi)*3
Tdi∈{nusbj,nsubjp,dobj,nmod}
∴αMatchdobj+βMatchnmod+γ(Matchnsubj+Matchnsubjp)=
aNum(Setd0bj)÷3+βNum(Setnmod)*3+
γ(Num(Setnsubj)+Num(Setnsubjp))*3
∴Sim(DPV,IPV)=1
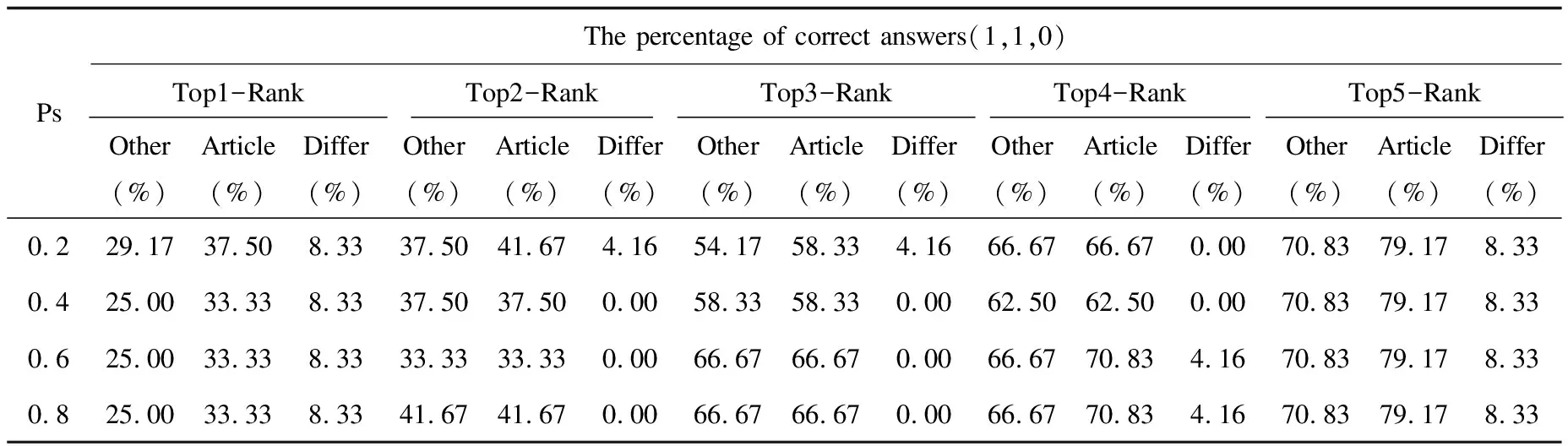
(3)當DPV與IPV部分相似時,0 ∵ DPV與IPV部分相似 ∴MatchTdi(DpSet,IpSet)≤Num(SetTdi)*3 ∴Sim(DPV,IPV)≤1 又∵(1)(2) ∴0 綜上,證畢。 有文本兩段如下: 設計模式“Visitor”意圖:“Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates.” 實際設計問題:“Many distinct and unrelated operations need to be performed on node objects in a heterogeneous aggregate structure. You want to avoid "polluting" the node classes with these operations. And, you don't want to have to query the type of each node and cast the pointer to the correct type before performing the desired operation.” 根據語法拆分可獲得各自Td集,如圖3所示。 圖3 拆分Td集結果 首先確定參數,不妨假設參數組合為:α=1,β=1,γ=1,Ps=0.4,syn=true,hyper=true,根據各自Td集內的單詞對計算相應的Score,相應求和計算Td集的Match分數,匹配上的如表3所示。 表3 Match結果 由于DPV.Z=?,所以相應的Matchnsubjpass(DpSet,IpSet )=0;DPV.W1匹配DPV.W1和DPV.W3都等于1,則取最大值1,則Matchdobj(DpSet,IpSet )=1;DPV.X1,DPV.X2,DPV.X3分別匹配上了IPV.X4,IPV.X3,IPV.X1,所以Matchnmod(DpSet,IpSet)=3;同理,Matchnsubj(DpSet,IpSet)=4。由圖3得,Num(Setdobj)=3即在參數為(1,1,1,0.4,true,true,false)時,實際問題與設計模式之間的相似度為24.2%。 參數隨著問題實例的增加,精確求解方法變得非常耗時,另外參數確定的狀態空間隨著參數取值范圍和精度的增加而增加,就文中參數而言,共225種組合方式。參數調優模塊采用遺傳算法的框架,將要解決的問題模擬成生物進化過程,進行多次迭代后就有可能會進化出相對表現較好的參數方案,然而所有的遺傳算法都必須具有良好的問題遺傳表示,合適的適應度函數才能有效的工作,因此定義規則與適應度函數如下。 編碼是應用遺傳算法時要解決的首要問題,也是設計遺傳算法的一個關鍵步驟。需要確定的參數有α,β,γ,Ps,syn,hyper,hypo共7個。α,β,γ是三種詞集的相應的權重,對不同設計模式數據集[17-18]經過10輪,每輪200代的遺傳測試顯示,在數值在0~10之間浮動會對相應適應度值有較顯著的影響,其他數值幾乎無明顯影響,所以文中參數設置取[0,10]之間,Ps是懲罰項,取值范圍為(0,1),精確到小數點后2位,syn,hyper,hypo分別是同義詞,上位詞,下位詞的開關參數,取布爾值,各參數取值范圍如表4所示。 表4 參數取值范圍 為了表示以上參數,文中采用二進制編碼的編碼方式。二進制編碼具有編解碼操作方便,交叉編譯便于實現,符合最小字符集等特點。假設某一參數的取值范圍為[Umin,Umax],用長度為l的二進制編碼符號串表示該參數,則δ為該二進制編碼的精度。 以上參數用31位的二進制符號串表示,其分布如圖4所示。 圖4 31位染色體的遺傳表示 從編碼后的基因型向可用參數的表現型轉換的方式稱為解碼。假設某一參數的編碼為bkbk-1bk-2…b2b1,則解碼公式為: 遺傳算法中,群體的進化過程就是以群體中各個個體的適應度為依據,通過一個反復迭代的過程,不斷尋找求出適應度較大的個體。所以適應度函數的確定也十分重要。設Rank為相似度排名后設置展示的數量,RankNum[i]為問題對應的設計模式在Rank結果中位于第i位的總數量,則適應度函數定義如下: 當排名越靠前的數量越多時,Fitness的值越大,并且適應度緩慢增加,有利于尋找到最優解。 文中提供兩組設計模式數據集與一組安全設計模式數據集。 設計模式數據集: 安全設計模式樣本集合(46)[17]。被分為8類,系統訪問與控制體系結構,訪問控制模型,身份識別與認證,操作系統訪問控制,安全互聯網應用,防火墻體系結構,企業安全與風險管理,賬單。 Gof模式組[18]是設計模式主要參考書籍之一,面向對象設計模式樣本集合(23),被分為3個粗粒度類別,創建型、行為型、結構型。 實際問題數據集: 為了測試所提出的排序方法的有效性,從不同的資源中檢索出實際問題,根據專家意見,檢索出已經解決和映射的設計問題 (1)46個安全設計模式集合的問題[17]。 問題1:“When objects are created we define the rights processes have to them. These authorization rules or policies must be enforced when a process attempts to access an object.” (2)24個設計模式集合的問題[19]。 問題2:“One of the dominant strategies of object oriented design is the "open closed principle". Figure demonstrates how this is routinely achieved encapsulate interface details in a base class, and bury implementation details in derived classes. Clients can then couple themselves to an interface, and not have to experience the upheaval associated with change: no impact when the number of derived classes changes, and no impact when the implementation of a derived class changes.” (3)7個面向對象設計模式的問題[20]。 問題3:“Design a system for drawing graphic images: a graphic image is composed of lines, rectangles, texts, and images. An image may be composed of other images, lines, rectangles, and texts.” 4.2.1 46個安全設計模式集合的問題 文中使用三組參數在安全設計模式與實際問題的數據集上進行測試,實驗結果如表5所示。 表5 不同參數在前rank5中的匹配情況 文中設置三組參數和一組經過遺傳算法調優后得到的參數組,經過計算得相應的匹配率結果和各TopN-Rank的總匹配占比,如圖5所示。表中反映了在Rank為5時,所有實際問題中正確匹配的設計模式出現在前TopN-rank的個數和所有出現在Rank5的實際問題中在實際問題集中的占比率(即匹配率)。在經過遺傳算法調優的參數組合后,出現于前n的匹配數目明顯上升。Top1-Rank下,相對參數組1和參數組3,優化組的匹配個數上升至19,匹配率由原來的67.39%上升至76.09%,漲幅8.7%。相同匹配率的參數組2與優化組相比,優化組的Rank匹配率整體上漲了5.72%。 圖5 Top-n Rank匹配在總匹配中占比 整體上,優化組相比其他參數組的匹配率上升了5.72%至9.13%不等,匹配率占比也高于其他參數組,經過遺傳算法的調優參數,使得準確的結果明顯前移,讓更多的正確結果出現在了靠前的位置。 4.2.2 ChannaBou 2018的對比 在設計模式數量14,實際問題數量24的情況下,對比如表6所示。 表6 參數設置(syn,hyper,hypo)為(true,true,false)其他方法[16]與文中方法的對比 通過選取相同的設計模式集合[7]和實際問題集[19-20],在經過參數調優后獲得的數據如表6所示,Other和Article分別為其他方法和文中方法的表現,Differ表示兩種方法表現的差值。在參數syn,hyper,hypo設置為true,true,false時,Ps分別在0.2,0.4,0.6,0.8的情況下,使用文中的參數調優方法后,使得各TopN-Rank的數量明顯增加,Top1-Rank下,各Ps的值下漲幅8.33%,Top5-Rank下漲幅8.33%,整體漲幅4.16%至8.33%不等,效果可觀。 受人工設置參數的局限,通過遺傳算法尋找相對較優解替代人工設置參數。實驗一的結果表明,經過調優后文中方法得到的結果相對人工定義的參數組合表現較好,使匹配率得到了相應的提升,同時也使得更多正確的結果出現在了靠前的位置。實驗二的結果顯示,通過與本方法相近的方法的對比,在經過遺傳算法調優后,匹配率都得到了相應的提升,相同參數的情況下,Top1-Rank的匹配率均上調8.33%,Top5-Rank的匹配率相應的上調8.33%,比同類的方法能獲得更多的匹配結果,本方法的實驗表現總體較優。 提出了一種基于意圖的設計模式排序方法,定義了相關的詞對match規則,并定義了相關的相似度比較辦法,隨后針對參數取值依賴人工的問題,引入了遺傳算法對相應的參數計算相對優值,最后通過實際問題的數據集對所提出的方法進行了驗證和分析。實驗結果表明,該方法在經過遺傳算法的調優后,相對其他的方法有一定的提高,在其他相關設計模式上也表現較好。由于硬件和時間的限制,文中測試的程序和數據集有限,結論有一定局限性。下一步工作,一方面提高數據集的種類和數量,另一方面對意圖不易表達的設計模式進行深入的研究。2.5 示 例
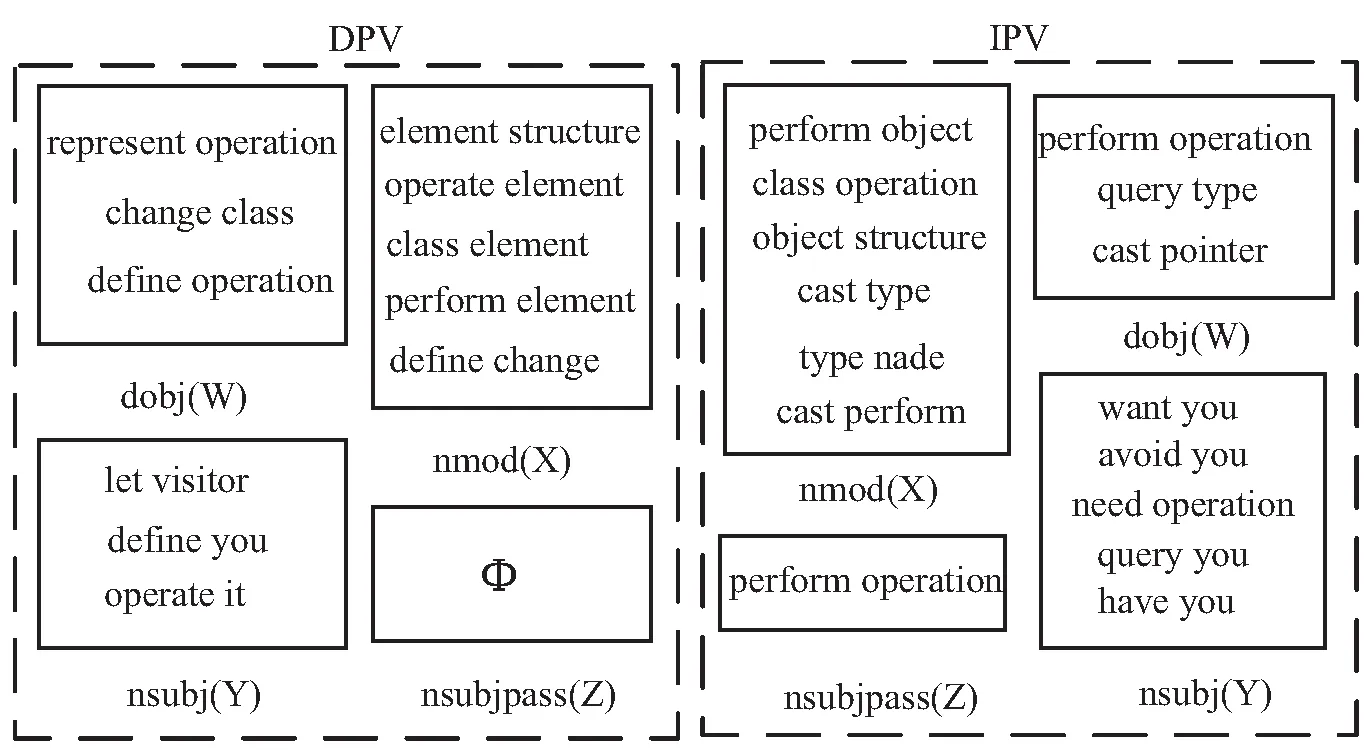
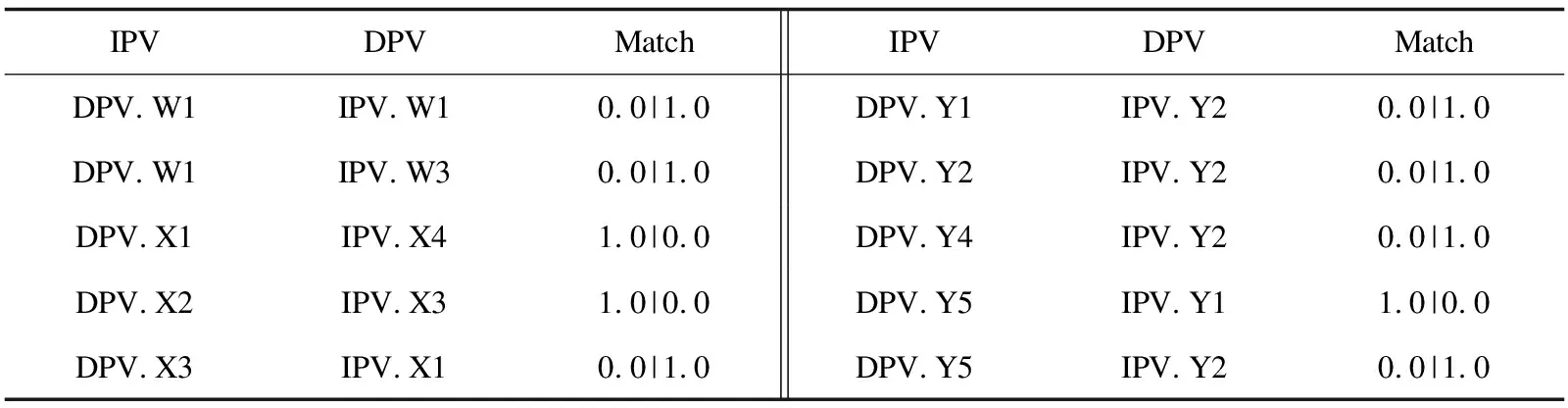
3 參數調優
3.1 編 碼(Encode)

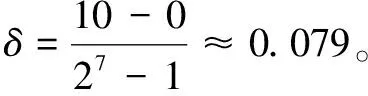

3.2 解 碼(Decode)
3.3 適應度函數(Fitness function)

4 實 驗
4.1 實驗數據集
4.2 對比實驗


5 結束語
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16制造技術與機床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18意林(繪英語)(2017年5期)2017-05-15 02:17:23意林原創版(2016年10期)2016-11-25 10:28:30Coco薇(2016年2期)2016-03-22 02:42:52小學教學參考(2015年20期)2016-01-15 08:44:38Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56
