融合評分矩陣和評論文本的深度學習推薦模型
2021-08-27 06:38:20杜永萍
計算機技術與發展 2021年8期
王 艷,彭 治,杜永萍
(北京工業大學 信息學部,北京 100124)
0 引 言
隨著網絡的飛速發展,給人們的生活帶來了巨大的影響,在提供便利的同時也產生了很多問題。由于數據量成指數增長,人們想要從海量的數據中獲取有用信息變得越來越困難[1],因此推薦系統應運而生。推薦系統在很多領域都得到了廣泛的應用,例如:醫療健康[2]、交通出行[3]、學習教育[4]、電子商務[5]等。近年來,推薦系統在解決信息過載方面被證明是有效的,可以幫助人們快速地在海量數據中找到自己需要的信息;因此得到了學術界和工業界的廣泛關注。然而如何更高效地提高推薦系統的準確性是現在推薦領域的研究熱點。
傳統的推薦算法主要有協同過濾[6-7]和基于內容的推薦算法[8]。這兩種方法都是基于用戶的歷史行為來進行推薦的。基于內容的推薦算法[8]利用用戶對項目的評分信息來確定這些物品之間的共同特征,若是新物品也有這個特征,就會將該物品推薦給用戶;協同過濾[6]是利用歷史數據找到與該用戶喜好相同的用戶,然后將找到的這些相似用戶過去喜歡的物品推薦給該用戶。或者是找到和某一物品具有相同特征的物品,若用戶喜歡這一物品則將其他具有相同特征的物品推薦給用戶。
基于近鄰的推薦算法廣泛用于協同過濾中。該算法利用評分信息計算用戶或物品的相似度,根據和某一用戶相似的用戶對目標商品的評分來預測該用戶對目標商品的評分,或者根據用戶對和目標商品相似的物品的評分來預測該用戶對目標商品的評分。基于近鄰的方法易于實現,并且對于預測結果有一個直觀的解釋。
在協同過濾中,矩陣分解是最成功應用最廣泛的一種方法。Koren等人[9]最早提出了基于矩陣分解(matrix factorization,MF)的推薦算法,該算法在評分矩陣的基礎上,加入了隱向量,并將評分矩陣分解為用戶矩陣和項目矩陣乘積的形式,增強了模型對稀疏矩陣的處理能力,從而取得了很好的推薦效果。Salakhutdinov等人[10]提出了概率矩陣因子分解(probabilistic matrix factorization,PMF)模型,該模型通過添加用戶、項目隱式特征的高斯概率分布來改進算法。實驗研究表明,基于矩陣分解的算法在評分預測方面要好于基于近鄰的推薦算法。
雖然基于矩陣分解的推薦算法在推薦領域取得了不錯的推薦效果,但是數據稀疏性對推薦系統性能的影響仍是當下急需解決的問題。一些研究表明[11]引入評論文本信息能有效緩解數據稀疏性對推薦效果的影響,在一定程度上提高算法推薦的精確度。在推薦系統中,用戶除了可以直接進行評分外還可以寫評論信息,一般評論信息中會包含用戶給出這個評分的理由,相較于評分而言,評論信息包含的內容更加豐富。一方面可以得到用戶給出這個評分的原因,另一方面也可以體現用戶的偏好信息或商品的一些特征。
最初使用評論文本進行建模的推薦算法大都是基于主題模型,Devid等人[12]提出了LDA(latent Dirichlet allocation)模型,該模型用于推測文本中的主題分布,然后利用推測的主題分布獲取用戶、項目的相關信息從而提高推薦的準確度。LDA是主題模型研究領域最具有影響力的模型。Ganu等人[13]提出從評論文本主題中推導出基于文本的評分方法。然后,使用聚類技術將文本中的主題和情感相似的用戶分為一組。McAuley等人[14]提出將評論文本和評分數據相結合的HFT模型,將用戶評論集或商品評論集作為輸入,將評論文本主題和評分數據中的隱因子結合。HFT是將評論文本和評分數據相結合的最經典的模型。基于主題的模型在推薦效果上取得了很好的結果,但是該方法不能很好地保留文本信息中的詞序信息,從而忽略了上下文之間的邏輯對應關系[15]。
近年來,深度學習在很多領域被廣泛應用,特別是在自然語言處理[16]方面更取得了突破性的進展。利用自然語言在文本內容挖掘方面的優勢,將其運用到推薦系統中對評論文本進行處理,這也為推薦系統提供了新的研究方向[1];目前在推薦系統中使用的深度學習技術主要有CNN[17]、RNN[18]、注意力機制[19-20]、RBM[21]、自編碼器[22]等。
深度學習中的CNN、RNN網絡在處理文本信息時能夠很好地保留詞序信息,近年來逐漸取代了主題模型。Kim等人[23]提出的ConvMF(convolution matrix factorization)模型將卷積神經網絡和概率矩陣分解相結合,利用卷積神經網絡處理評論文本信息,從而有效地保留詞序信息。但是該模型僅僅利用了項目的評論文本信息,而忽略了用戶的評論信息。隨后Zheng等人[24]提出了DeepCoNN(deep cooperative neural network)模型,該模型利用兩個并行的CNN來分別處理項目的評論信息和用戶的評論信息,在最后一層利用因子分解機來進行評分預測。Chen等人[25]提出的NARRE(neural attentional regression model with review level explanations)模型,將評分矩陣和評論文本作為輸入,同時融合評分數據中的隱向量,極大地提高了推薦系統的預測性能。
上述模型中在與評論文本特征融合時僅用到了評分的潛在特征,沒有對評分數據進行深度建模,學習評分數據的深度特征。因此文中提出了融合評分矩陣和評論文本的深度學習推薦模型,利用深度學習技術提取評分中的深度特征,并和評論信息中提取的用戶偏好、項目特征進行融合。通過更好地對用戶項目特征進行表示,從而提升推薦性能。用MSE作為評價指標,在亞馬遜6個不同領域的公開數據集上進行對比實驗,結果表明所提出的算法優于目前多個優秀的公開模型。
1 模型結構
文中提出了融合評分矩陣和評論文本的深度學習推薦模型RMRT(rating matrix and review text based recommendation model),模型結構如圖1所示。該模型包括兩個部分,左側部分對用戶進行建模,提取用戶偏好信息;右側部分對項目進行建模,提取項目特征。將提取的用戶特征和項目特征融合后送入預測層,得到預測評分。

圖1 融合評分矩陣和評論文本的深度學習推薦模型
在用戶、項目建模過程中又分別包含了兩個部分:(1)從評論文本中提取特征,輸出用戶、項目的深層特征表示為Tu、Ti;(2)從評分矩陣中提取用戶項目特征,輸出為Xu、Xi;將得到的用戶特征和項目特征分別送入交互層得到用戶、項目的最終特征表示,最終在預測層得出用戶對項目的預測評分。在對用戶、項目建模時所用網絡結構相同,只有輸入不同。因此文中重點介紹項目建模部分,用戶建模過程與之相似。
1.1 文本特征提取模塊
用戶對項目的評論信息能夠反映出項目的特征信息。給定某項目i的評論集{Ri1,Ri2,…,Rik},k表示模型允許輸入的最大評論數,經過嵌入層后,每條評論信息被映射為d維的向量,得到固定長度的詞嵌入矩陣。嵌入層之后為卷積神經網絡層,該層以嵌入層得到的詞向量矩陣作為輸入,得到特征向量。設卷積層由m個神經元組成,使用大小為s的滑動窗口上的卷積濾波器來提取上下文特征,具體如公式(1):
kj=Relu(Mi*fj+bj)
(1)
式中,*表示卷積操作,bj表示偏差。
進入卷積模塊中的最大池化層,max-pooling能夠捕獲重要的具有高價值的特征,并且將卷積層的輸出壓縮成一個固定大小的向量,即:
cj=max(k1,k2,…,kd-s+1)
(2)
卷積層最終輸出的特征向量可表示為:ci1,ci2,…,cik。
對同一項目來說,不同用戶會有不同的評論信息,有些用戶的評論準確描述了項目的相關特性,而有些用戶寫的評論可能和項目沒有太大的關聯性。不同評論信息所作的貢獻是不同的。為了選擇更能代表項目特征的評論信息,引入了注意力機制[20],對相應的評論文本使用一個注意力層,得到注意力得分為:
gik=Relu(wi×cik+b)
(3)
式中,Relu表示激活函數,wi,b分別為網絡自動學習的權重和偏移量。
使用softmax函數對注意力得分gik進行歸一化處理,得到最終的評論權重aik如下式所示:
(4)
利用評論權重來突出當前評論集中第n條評論對項目i的特征的影響,將評論的注意力分數aik一一作用在對應的卷積層輸出的特征向量上,得到項目i特征向量的加權和:
(5)
然后將其送入到全連接層,得到項目i基于文本信息的最終特征表示:
Ti=WiCi+bi
(6)
式中,Wi,bi分別是全連接層的權重和偏差量。同理對用戶建模可以得到用戶u基于評論信息的特征表示Tu。
1.2 評分數據處理模塊
用戶對項目的評分數據是一種顯性反饋,可以直接反映出用戶對項目的喜愛程度,不同的評分說明用戶對項目的喜好程度不同,因此利用神經網絡根據評分數據獲取用戶的偏好和項目的特征表示。
以項目i的評分數據作為輸入pi={yi1,yi2,…,yin},其中網絡的模型定義為:
(7)
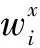
1.3 特征融合
在本層對文本特征提取模塊和評分數據處理模塊得到的用戶特征和項目特征進行交互,通過線性和高階交互建模來獲取項目的最終特征表示:
I=(Ti+Xi)⊕g
(8)
特征向量I中包含了從評論信息和評分數據中獲取的項目特征,其中⊕表示拼接,g表示高階交互建模。此處借鑒了因子分解機中的二階項來獲取高階特征,首先將因子分解機中的二階項進行轉換:
(9)
其中,?表示元素積,在執行sum()之前,就已經包含了二階交互項的所有信息。因此,只需要求和前的部分,將評論信息中得到的特征和評分數據中得到的特征進行拼接z=Ti⊕Xi,利用下面的網絡結構來獲取高階特征:
(10)
g能進一步增強潛在特征的交互,同理可以得到用戶的最終特征表示U。
1.4 評分預測
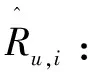
(11)
式中,W表示預測層的權重參數,bu、bi分別表示用戶的偏差量、項目的偏差量,bg表示全局偏差量。

2 實驗結果與分析
2.1 數據集與實驗設置
在實驗中,使用了6個不同領域的公開數據集來評估文中提出的模型,這些數據集來自Amazon 5-core,分別為:Toys_and_Games、Office_Product、Musical_ents、Instant_Video、Digital_Music、Kindle_Store,下面簡稱(TG,OP,MI,IV,DM,KS)。這些數據集中主要包含了以下內容:用戶對項目的評分信息(1-5分)、用戶對項目的評論信息、用戶ID和項目ID。具體統計信息如表1所示。
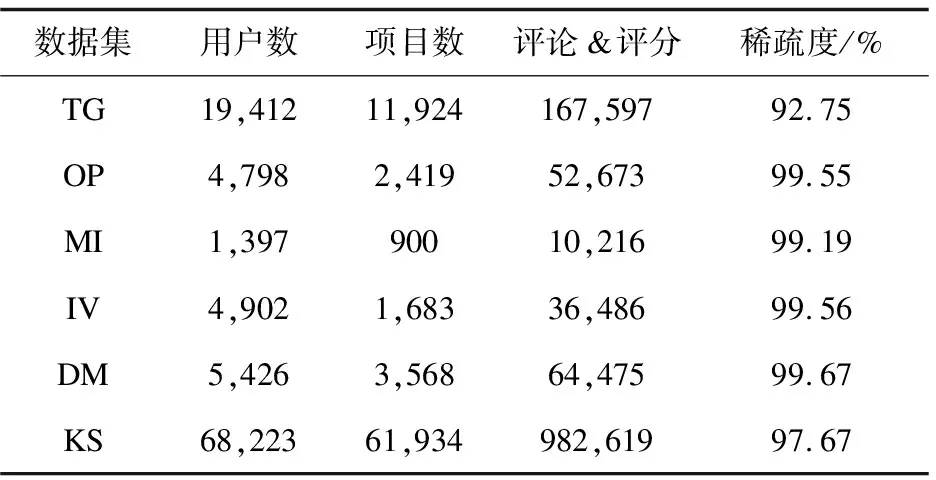
表1 數據集基本信息
在實驗中將數據集劃分為訓練集、測試集和驗證集,所占比重分別為80%,10%,10%。其中,驗證集主要是用來調整參數,在測試集上對模型的性能進行評估。
在實驗過程中,使用Google新聞上訓練的300維的word2vec向量來初始化詞嵌入并在訓練的過程中進行微調。使用Adam函數優化目標函數,默認初始化學習率設置為0.005,卷積核大小設置為3。為了防止過擬合,在實驗中采用了dropout策略,將值設置為0.5。
2.2 評價指標
在實驗中,模型的性能評價指標選用了均方誤差MSE,該值越小表示模型的性能越好,計算如下:
(13)

2.3 對比模型
為了驗證文中提出模型的有效性,選擇了基于評分和評論數據相關的推薦模型進行對比,具體如下所示:
· MF[9]:矩陣分解模型,這個模型中只用到了評分數據,是協同過濾中最常使用的方法。
· PMF[10]:概率矩陣分解模型,該模型在推薦建模時用到了高斯分布,來獲取用戶和項目的隱特征。
· HFT[14]:該模型結合評分數據和評論文本信息,在建模時有兩種組合方式,用戶評論文本和評分HFT(user),項目評論文本信息和評分HFT(itme)。文獻中顯示HTF(item)的效果要優于HFT(user),文中在對比時HFT指的是HFT(itme)。
· ConvMF[23]:該模型結合卷積神經網絡和概率矩陣分解,利用CNN來處理評論文本信息,保留了文本中的詞序,但是僅僅只用到了項目的評論信息。
· DeepCoNN[24]:深度協同神經網絡模型,是首個同時利用了用戶和項目的評論文本信息的深度學習模型,使用兩個并行的卷積神經網絡來處理文本數據,并在融合層利用因子分解機進行評分預測,取得了很好的結果。
· NARRE[25]:該模型在建模時用到了評分數據和評論文本,并在DeepCoNN的基礎上引入了attention機制,來識別評論的有用性,預測性能有一定的提高。
2.4 實驗結果分析
使用亞馬遜數據集進行對比實驗,在6個不同的數據集上對不同模型的性能進行了比較,實驗結果如表2所示。
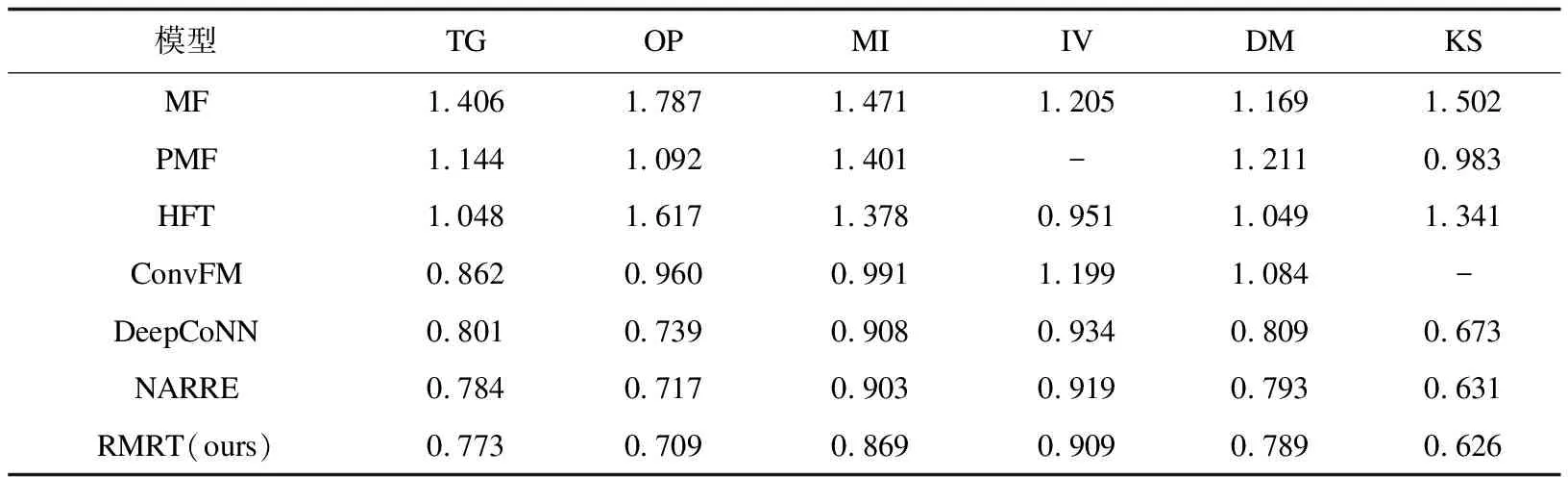
表2 在Amazon數據集上不同模型的結果對比(MSE)
由上面的對比結果可以看出,基于評分的推薦模型,由于數據稀疏性問題其推薦性能要差于基于評論文本的推薦模型。融合評分矩陣和評論文本的推薦模型性能要優于單獨采用評分數據或者評論數據模型的推薦性能。因為評論能夠反映用戶的偏好,項目的特征,而評分數據僅反映了用戶的偏好情況。引入文本信息能夠在一定程度上緩解數據稀疏性對性能的影響;一般情況下,基于深度學習的推薦模型在推薦性能上優于常規的推薦模型,因為深度學習可以更好地學習特征表示。從表2結果可以看出RMRT在不同的數據集上均取得了優于其他模型的效果。
2.5 評分處理模塊有效性驗證
為了驗證模型中利用深度學習技術對評分處理模塊的有效性,將評分部分的處理方式替換為其他模型中常用的矩陣分解,其他部分保持不變,將替換后的方法表示為RMRT-D+MF。在亞馬遜數據集上進行對比實驗,結果如圖2所示,可以看出利用深度學習技術處理評分數據得到了更優的MSE值。

圖2 評分處理模塊有效性驗證性能比較
3 結束語
提出了融合評分矩陣和評論文本的深度推薦模型RMRT。該模型可以同時從評分數據和評論文本信息中學習用戶和項目的特征。在處理評分矩陣時利用深度學習算法進行深度特征學習,提取用戶和項目的特征表示,將其和評論信息中提取的特征進行融合。對比實驗結果表明,文中提出的方法在不同的數據集上均取得了優于其他模型的效果,因此提取深度特征能夠在一定程度上提高預測的準確性。
文中工作主要關注的是評分數據和評論文本信息的特征提取,沒有考慮時間因素及文本情感對推薦性能的影響,在今后的工作中將考慮引入時間變化對用戶偏好及商品特征的影響,以及潛在特征的權重和文本中的情感信息對推薦性能的提升。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
