不平衡樣本集隨機森林巖性預測方法
2021-08-18 07:04:10王光宇宋建國陳飛旭
石油地球物理勘探 2021年4期
王光宇 宋建國* 徐 飛 張 文 劉 炯 陳飛旭
(①中國石油大學(華東)地球科學與技術學院,山東青島 266580; ②中國科學技術大學地球和空間科學學院,安徽合肥 230026;③中國石化石油勘探開發研究院,北京100083; ④中石油塔里木油田分公司勘探開發研究院,新疆庫爾勒 841000)
0 引言
目前,中國東部各油氣田的主力區塊已經達到中、高勘探程度,勘探方向從以構造油氣藏為主轉向以巖性地層油氣藏為主[1]。準確地預測巖性是巖性地層油氣藏勘探的重要環節,同時也是儲層特征研究、儲量計算和地質建模的基礎[2]。
在地震儲層預測領域,巖性預測主要有地震屬性分析和地震反演兩種方法。在地震屬性分析方面,趙謙等[3]利用地震波波形分類識別砂、泥巖;黃鳳祥等[4]利用均方根振幅屬性識別基性侵入巖。在地震反演方面,孫明等[5]應用疊后縱波阻抗反演預測目的層段的巖性;黃饒等[6]通過疊前同時反演預測目標層巖性。
以上列舉的地震巖性預測方法雖然在實際應用中都取得了較好的效果,但也存在著一定的局限性。洪忠等[7]基于大量實踐認為,不同巖相的地震振幅、頻率、相位、時間厚度等差異是應用波形分類方法的前提,當巖相間的地震響應差別不明顯或同一巖相橫向波形變化較快,而無法建立統一的巖相地震波形特征時,根據波形分類的結果不能準確地劃分巖相,也沒有明確的地質意義。基于地震屬性分析的巖性預測方法的局限性主要在于:所選取的地震屬性可能對巖性不敏感,通過單一屬性難以準確預測巖性。對于基于地震反演的巖性預測方法來說,在統計各種巖性的某一彈性參數范圍或進行彈性參數交會分析時,會受限于彈性參數重疊的情況[8]。此外,在利用交會圖劃分巖性時,一般都采取粗略的描述或者手工勾繪,這種方法存在很大的不確定性[9]。
近年來,機器學習算法的飛速發展受到了各行業的關注。在地震儲層預測領域,一些學者將機器學習算法應用于巖性預測。李國和等[10]以全頻和分頻振幅數據作為輸入、以巖性數據作為輸出、以深度置信網絡(Deep Belief Networks)作為分類識別模型,利用地震數據識別巖性。張國印等[11]將測井數據和井旁地震道時頻譜分別作為標簽和輸入,訓練卷積神經網絡(Convolutional Neural Networks,CNN),充分挖掘地震數據高頻和低頻信息并預測巖性。楊璐等[12]建立多種地震屬性與巖性類別標簽之間的隨機森林(Random Forests,RF)分類模型并用于巖性預測。基于機器學習的巖性預測方法的優勢在于:①擴展了巖性劃分的特征空間維度,單一地震屬性或單一巖石彈性參數為一維,彈性參數交會分析方法為二維,而機器學習算法可在三維甚至更高維度的特征空間劃分巖性;②與在交會圖上采取粗略描述或者手工勾繪的傳統方法相比,機器學習算法降低了人為因素帶來的不確定性。
目前應用于巖性預測的機器學習算法主要是有監督分類算法,需要使用已經標記好類別的樣本訓練分類器,使分類器有能力預測未知類別的樣本。但這類方法存在一個缺陷,即在不同類別樣本數量差別很大的不平衡樣本集上訓練時,往往會出現分類面向多數類樣本偏倚的現象,而少數類樣本無法獲得理想的分類效果[13]。對于巖性預測而言,當樣本集中目標巖性(如砂巖)樣本過少,而非目標巖性(如泥巖)樣本過多時,將會使預測結果向非目標巖性偏倚,導致目標巖性的預測準確率較低。
為了解決這一問題,本文提出一種針對不平衡樣本集的隨機森林巖性預測方法。首先,以錄井巖性數據作為巖性樣本標簽,以井旁道地震屬性和巖石彈性參數作為巖性樣本特征構建巖性樣本集;其次,將近鄰清除算法(Near Miss, NM)[14]與合成少數類過采樣算法(Synthetic Minority Over-sampling Technique, SMOTE)[15]相結合,形成NM-SMOTE算法,對巖性樣本集進行平衡化;然后,用平衡化的巖性樣本集訓練隨機森林分類器,建立多種地震屬性、彈性參數與巖性之間的非線性關系;最后,將目標區的地震屬性和彈性參數輸入隨機森林分類器預測巖性,以期獲得與地震資料吻合程度更高的巖性數據體。
1 方法原理
1.1 井震數據匹配
選取錄井巖性數據作為巖性樣本標簽。一般來說,錄井數據中記錄的是各種巖性的頂、底界深度。為了獲得足夠多的巖性樣本,需要在各種巖性的頂、底界之間按照測井數據的采樣率(以0.125m為間隔)均勻插值。然后,通過井震標定獲得準確的時深關系,將錄井巖性數據從深度域轉換到時間域。由于地震數據與錄井巖性數據的時間采樣率不同,因此還需要對錄井巖性數據重采樣,將其轉換為與地震數據相同的采樣率(2ms)。
前人研究[3-6]表明,利用地震屬性和反演所得的彈性參數皆可預測巖性。因此,本文從井旁道中提取多種地震屬性和彈性參數作為巖性樣本特征,與轉換到時間域且重采樣后的錄井巖性數據組成樣本集。巖性樣本特征與標簽的匹配方式為“點—點”匹配,即對于某一口井來說,將同一時間采樣點上的地震屬性、彈性參數和錄井巖性數據進行匹配,形成該井的巖性樣本集,如圖1所示。

圖1 巖性樣本特征與標簽的“點—點”匹配方法將泊松比、能量半衰時、瞬時振幅等作為不同特征
1.2 NM-SMOTE平衡化算法
NM-SMOTE算法是一種對多數類樣本欠采樣(Under-sampling)、同時對少數類樣本過采樣(Over-sampling)的平衡化算法。由于NM-SMOTE算法需要計算特征空間中樣本之間的距離,因此引入特征空間中樣本距離的概念,即在由m個特征組成的特征空間中,任意兩個樣本的坐標可以表示為x1(f11,f12,…,f1m)和x2(f21,f22,…,f2m),x1和x2的距離為
(1)
式中:f1i和f2i分別表示樣本x1和x2的各個特征;m為特征個數。NM-SMOTE算法的步驟如下。
(1)根據樣本不平衡比例,設置多數類樣本欠采樣后的數量NU和少數類樣本過采樣后的數量NO,NU與NO應相對平衡。
(2)對于少數類樣本,利用SMOTE增加樣本數量。SMOTE算法為:①在特征空間中,隨機選取一個少數類樣本x,利用式(1)計算x與其他所有少數類樣本的距離,得到與x距離最近的k個少數類樣本;②在k個少數類樣本中隨機選取一個少數類樣本x',在x與x'之間的某一點上合成新的少數類樣本xnew,即
xnew=x+rand(0,1)×(x'-x)
(2)
式中rand(0,1)表示0~1之間的隨機數;③重復步驟①~②,直到少數類樣本的數量增加到預設值NO為止。
(3)對于多數類樣本,利用NM算法減少樣本數量:①在特征空間中,由式(1)計算每個多數類樣本和與之距離最近的k個少數類樣本的平均距離;②刪除與最近的k個少數類樣本平均距離最短的多數類樣本;③重復步驟②,直到多數類樣本的數量減少到預設值NU為止。
圖2展示了當m=2時,利用NM-SMOTE算法對一個不平衡樣本集進行平衡化的過程。由圖2a可以看出,受樣本數量不平衡的影響,在特征空間中無法正確地劃分兩類樣本的分類區域。若在此不平衡樣本集上訓練分類器,則少數類樣本會被誤分為多數類樣本。根據NM-SMOTE算法步驟,首先對少數類樣本進行SMOTE過采樣(圖2b),增加樣本數量(圖2c);然后對多數類樣本進行NM欠采樣(圖2d),減少樣本數量(圖2e)。在使用NM-SMOTE平衡化算法后,樣本集中的兩類樣本數量達到平衡狀態,并且在特征空間中能夠更好地區分。利用該樣本集訓練分類器,可有效地降低少數類樣本被誤分的風險。
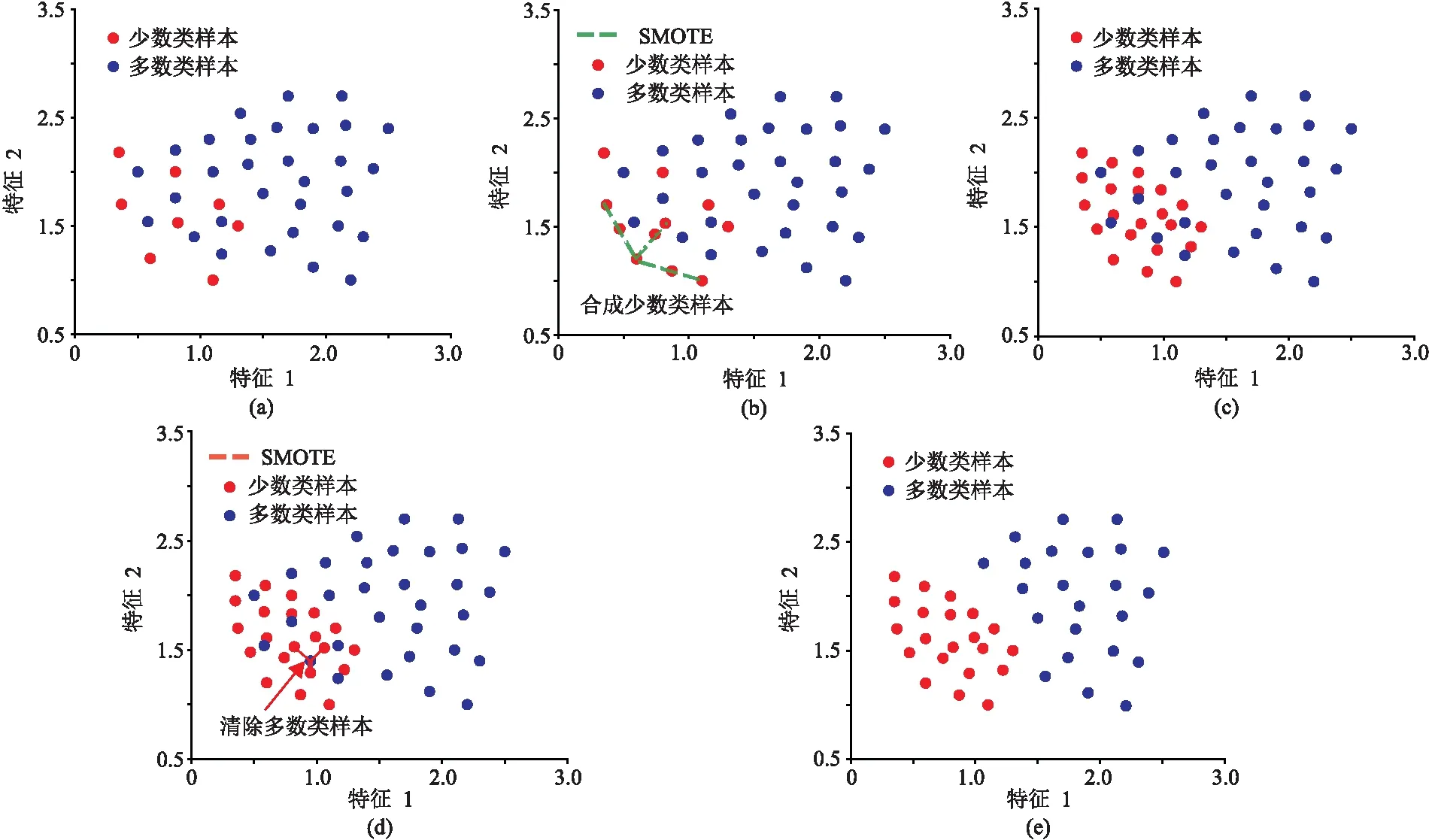
圖2 NM-SMOTE算法步驟
1.3 隨機森林訓練及優化方法
隨機森林分類器(Random Forests Classifier, RFC)[16]是一種集成了多個決策樹的機器學習算法。RFC通過Bootstrap抽樣[17](有放回地隨機抽樣)從原始樣本集中抽取多個子集用于構建決策樹,每一個決策樹在節點分裂時都通過隨機特征選取的方式尋找最優的分割方案。與單個決策樹分類器相比,RFC具有預測精度高且不容易出現過擬合的優點。RFC在訓練過程中,可以同時計算每一種樣本特征的重要性,重要性越高的樣本特征對RFC的預測準確率影響越大。在此基礎上,本文設計了一種根據樣本特征重要性優化RFC的方法,可以在訓練RFC的同時優選樣本特征,提升RFC的預測準確率。
針對不平衡巖性樣本集,從中隨機選取一部分(如75%)樣本作為訓練樣本集,記為Ωa,剩余樣本作為測試樣本集Ωb。假設Ωa中共有m個巖性樣本特征,對Ωa進行NM-SMOTE平衡化,得到Ω'a,用于訓練RFC,獲得m個巖性樣本特征的重要性。然后,基于RFC輸出的特征重要性優化分類器,同時優選巖性樣本特征,主要步驟為:
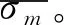
(2)根據特征重要性,剔除重要性最低的一種特征,記特征個數m=m-1,執行步驟(1)。
(3)重復步驟(2),直到m=1。
最后,用測試樣本集Ωb測試最優RFC模型的準確率,若滿足要求(如不低于80%)則可用于巖性預測;否則調整RFC參數或更換訓練樣本集,重新訓練RFC。針對不平衡樣本集的隨機森林巖性預測流程如圖3所示。
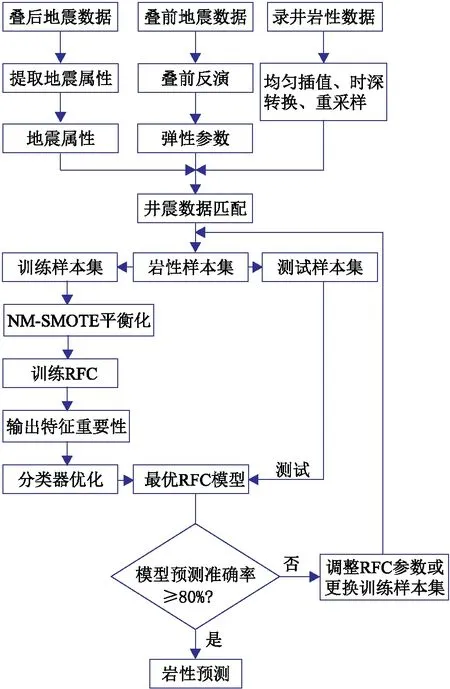
圖3 不平衡樣本集隨機森林巖性預測方法流程
在分類問題中,準確率是一種用于衡量分類器預測性能的常用指標,即
(3)
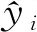
(4)
其中
(5)
式中:i和j都表示樣本編號;ωi表示第i個樣本對應的類別所占的樣本比例。簡單來說,平衡準確率計算分類器對每一類樣本預測準確率的均值,不會受到樣本類別數量不平衡的影響,更加適用于衡量分類器對不平衡樣本集的預測效果。本文算法程序使用Imbalanced-learn、Scikit-learn、NumPy和Pandas等工具包在Python3.6上編程搭建。
2 實際資料應用
選取濟陽坳陷渤南地區某工區的三維疊前、疊后地震數據以及工區內14口井的錄井數據資料,應用本文方法預測巖性。
研究區發育湖相沉積,具有地層薄、巖性垂向變化快、巖性復雜等特點。錄井數據揭示區內主要有泥巖、灰巖、白云巖、砂巖、頁巖和石膏巖等六類巖性,目標巖性為砂巖和頁巖。巖石物理特征非常復雜(圖4),在彈性參數交會圖上各種巖性參數重疊在一起,因此無法應用常規地震反演方法預測巖性。
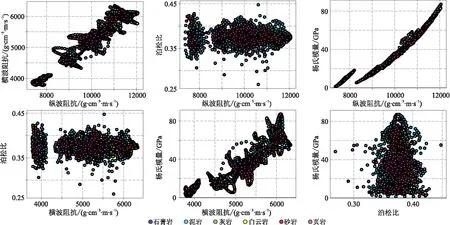
圖4 巖石彈性參數交會分析
充分發揮機器學習算法在高維度特征空間中劃分巖性的優勢,綜合地震屬性分析和地震反演兩種巖性預測方法,從三維疊后地震數據中提取與地層巖性相關的振幅、均方根振幅、振幅加速度、弧長、能量半衰時、品質因子、平均頻率、頻率變化率、瞬時振幅、瞬時頻率和瞬時帶寬等共11種地震屬性[20],并應用基于Zoeppritz方程的縱橫波模量反演方法[21]得到縱波阻抗、橫波阻抗、楊氏模量和泊松比,與地震屬性一起組成15種巖性樣本特征。根據本文的井震數據匹配方法,將工區內14口井的錄井巖性數據作為巖性樣本標簽,與井旁道的15種巖性樣本特征匹配,然后形成巖性樣本集。
隨機選取一口井的巖性樣本作為測試樣本集,其余井的巖性樣本作為訓練樣本集,重復這一過程,直到每一口井都完成了一次測試,得到14組訓練樣本集和測試樣本集。14組訓練樣本集的平均巖性樣本數量為2686個,分布如圖5a所示,其中,泥巖樣本為2089個,占比高達78%,石膏巖、灰巖、白云巖、砂巖、頁巖樣本分別為41、113、52、162、229個。每一組訓練樣本集都屬于不平衡樣本集,樣本不平衡比例最高達到50∶1。將泥巖視為多數類樣本,其余巖性視為少數類樣本,通過NM-SMOTE算法對每一組訓練樣本集進行平衡化,平衡化后所有訓練樣本集中各類巖性樣本的平均數量如圖5b所示。
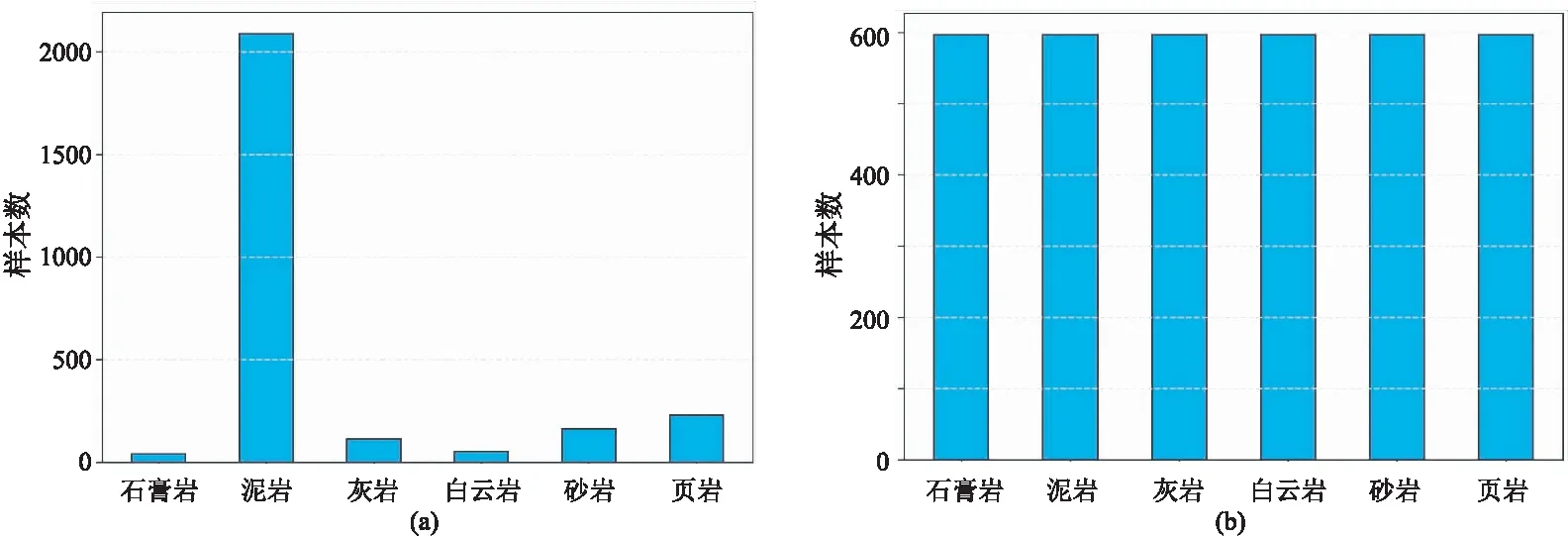
圖5 原訓練樣本集(a)和NM-SMOTE平衡化后訓練樣本集(b)巖性樣本分布
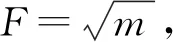
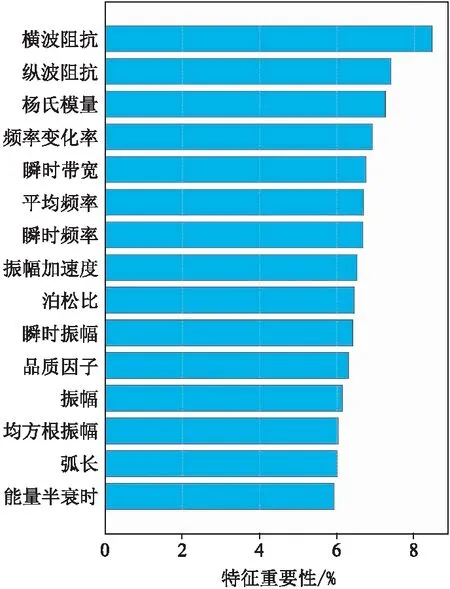
圖6 巖性樣本特征重要性
由于巖性樣本特征較多,一些冗余的特征會使RFC的預測準確率降低,因此使用本文提出的RFC優化方法優選巖性樣本特征組合,得到最優的RFC模型。圖7為巖性樣本特征優選與RFC優化過程,當選擇重要性排名前八位的巖性樣本特征(即橫波阻抗、縱波阻抗、楊氏模量、頻率變化率、瞬時帶寬、平均頻率、瞬時頻率和振幅加速度)對RFC進行十折交叉驗證時,RFC的平均準確率最高。若選取的特征過少,則由于有效特征信息的丟失,RFC的預測準確率將會下降。
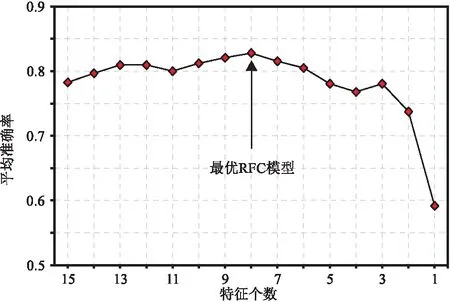
圖7 巖性樣本特征優選與RFC優化
3 應用效果
以優選的巖性樣本特征作為輸入,使用RFC預測研究區的巖性。將NM-SMOTE算法與兩種常用的樣本集不平衡問題解決方法,即懲罰系數法[22](在訓練過程中提高少數類分類錯誤的成本)和隨機欠采樣(Random Under-sampling,RUS)-SMOTE[23]算法作對比,分析單井和三維空間巖性預測效果。
3.1 單井巖性預測效果
計算14口井數據分別作為測試樣本集時預測巖性與實際巖性的混淆矩陣,取平均值得到最終結果,如圖8所示,矩陣中的數字表示預測巖性數量占實際巖性數量的比例,對角線元素即為每類巖性的預測準確率。圖8a為用未經平衡化的樣本集訓練RFC得到的預測結果,由于訓練樣本集中泥巖樣本過多,大量少數類巖性被誤分為泥巖,RFC對頁巖和砂巖這兩種目標巖性的預測準確率分別為24%和20%,六類巖性平均預測準確率僅為38%。樣本集經NM-SMOTE平衡化后,RFC對少數類巖性的誤分類得到改善,頁巖和砂巖的預測準確率分別提升至89%和75%,六類巖性平均預測準確率提升至83%(圖8b)。在訓練RFC時用懲罰系數提高少數類巖性的誤分代價,也可以提高RFC對少數類巖性的預測準確率,效果與NM-SMOTE算法相當,六類巖性平均預測準確率為79%(圖8c)。RUS-SMOTE算法在欠采樣過程中采用隨機減少多數類樣本的策略,雖然能夠使少數類樣本與多數類樣本的數量達到平衡,但與NM算法相比,RUS算法不能保證欠采樣后,在特征空間中能很好地區分多數類樣本與少數類樣本。因此,與NM-SMOTE算法相比,應用RUS-SMOTE算法平衡化訓練樣本集后,RFC對少數類巖性的預測準確率較低,頁巖和砂巖的預測準確率分別為67%和50%,同時RFC對泥巖的預測準確率也降低了4%,六類巖性的平均預測準確率為66%(圖8d)。

圖8 不同方法預測單井巖性效果
3.2 三維巖性預測效果
圖9為研究區的三維地震數據體,可見右側發育有一條正斷層。使用未經平衡化的樣本集訓練RFC會使巖性預測結果向泥巖嚴重偏倚,無法反映頁巖、砂巖等少數類巖性的分布情況(圖10a)。在使用NM-SMOTE算法(圖10b)、懲罰系數法(圖10c)和RUS-SMOTE算法(圖10d)解決樣本集不平衡問題后,RFC對少數類巖性的預測準確率得到提升,預測結果展現出多種巖性的空間分布情況,三種方法均能改善巖性預測效果。從細節來看,與懲罰系數法和RUS-SMOTE算法相比,NM-SMOTE算法對應的巖性預測結果與實際地震資料吻合程度更高,地層連續性更好,斷層構造更清晰,反映的巖性信息也更豐富。
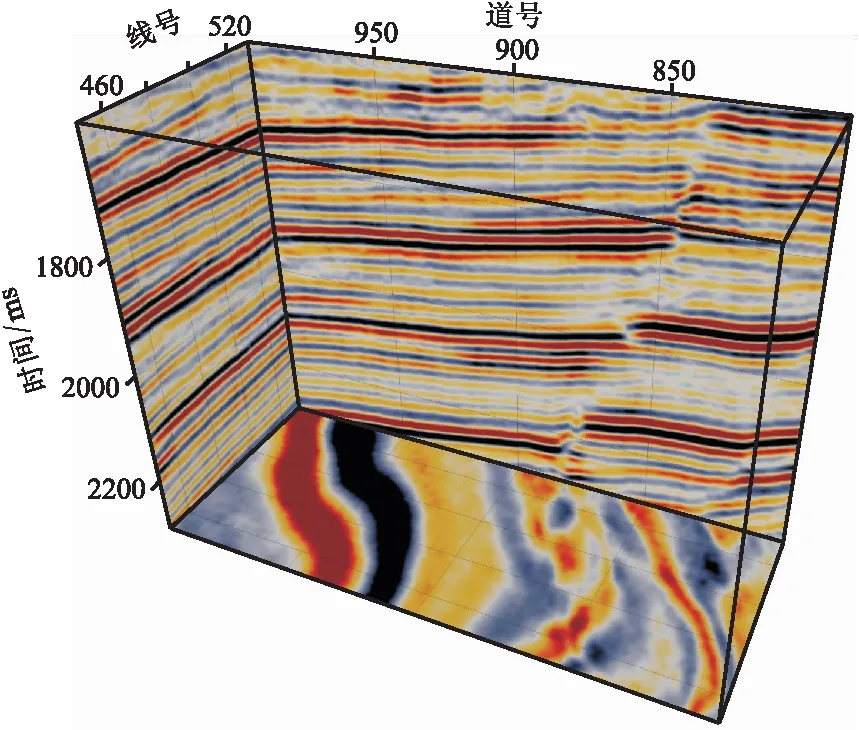
圖9 研究區三維地震數據體
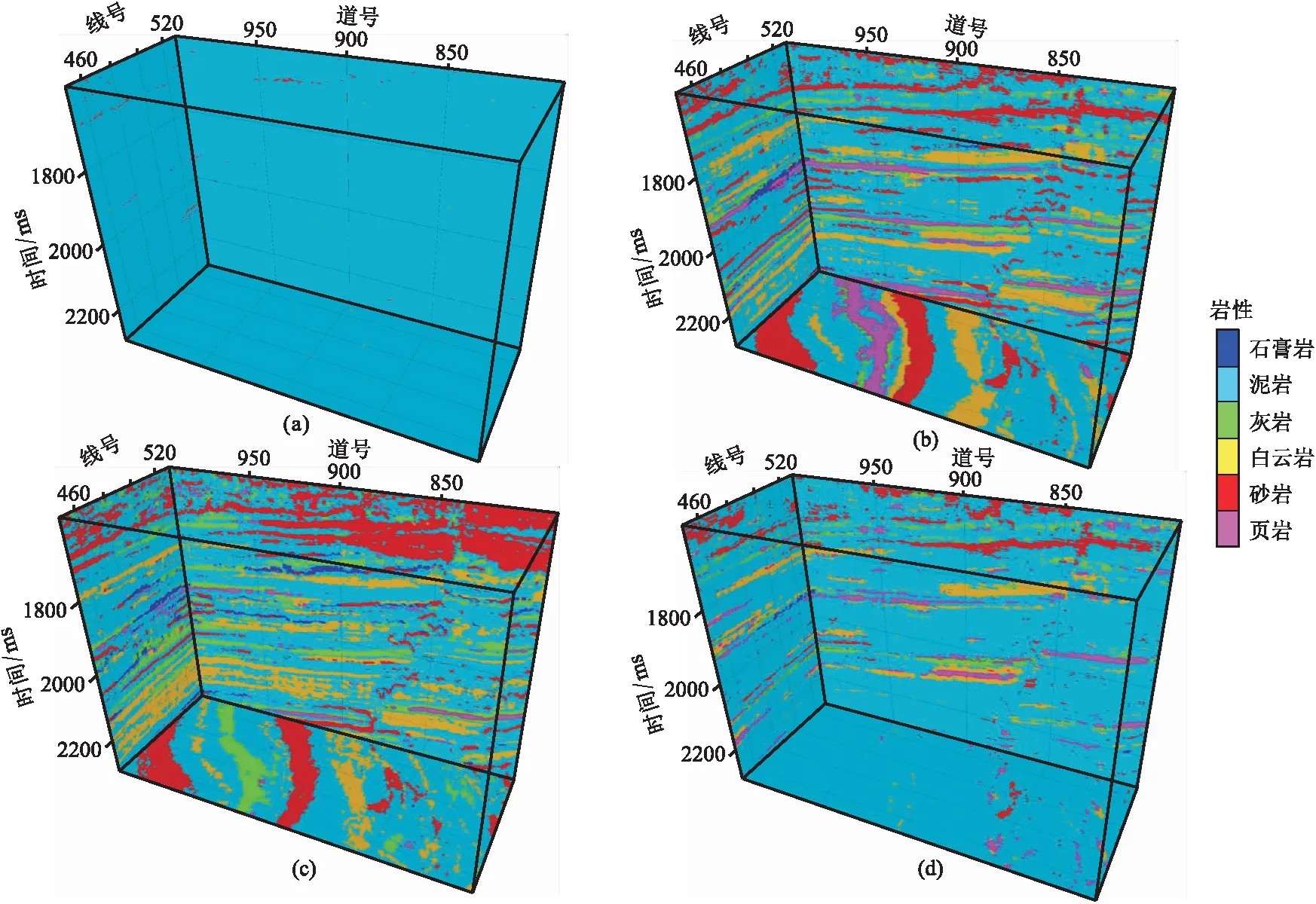
圖10 不同方法預測三維巖性效果
4 結束語
隨機森林算法可以建立多種地震屬性、巖石彈性參數與巖性之間的非線性關系,是在巖石物理特征復雜區域預測巖性的有效手段。然而,隨機森林算法受訓練樣本的影響較大,在目標巖性樣本遠少于非目標巖性樣本的不平衡樣本集上訓練時,巖性預測結果將向非目標巖性嚴重偏倚,無法準確預測目標巖性。
本文提出的針對不平衡樣本集的隨機森林巖性預測方法,通過應用NM-SMOTE平衡化算法解除了不平衡樣本集對隨機森林巖性預測的限制,拓寬了隨機森林巖性預測方法的適用范圍。實際數據測試結果證明,即使在樣本集中目標巖性樣本遠少于非目標巖性樣本,應用該方法也可準確預測目標巖性,并且效果優于解決樣本集不平衡問題常用的懲罰系數法和RUS-SMOTE算法,獲得的巖性數據體與地震資料吻合程度更高。
NM-SMOTE算法作為一種樣本集平衡化方法,也可配合除隨機森林外的其他機器學習分類算法預測巖性。該方法也存在缺陷,即對于多分類問題,目前只能在特征空間中減小多數類樣本與少數類樣本的重疊區域,而沒有考慮不同類別的少數類樣本間也存在重疊的情況。如何應用機器學習算法高效且準確地預測巖性,還需要進一步更深入地研究。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
