一種卷積神經網絡結合后處理的車道線檢測算法
2021-08-02 07:40:00高海強萬茂松侯長軍
軟件導刊 2021年7期
高海強,萬茂松,侯長軍
(南京林業大學汽車與交通工程學院,江蘇南京 210037)
0 引言
世界衛生組織統計數據顯示,在全球范圍內,每年約有135 萬人因道路交通事故死亡。人們逐漸意識到,成熟的自動駕駛技術會使出行更加安全、便捷和高效。自動駕駛技術作為人工駕駛的輔助,可在一定程度上減少因駕駛員注意力不集中、操作失誤等因素造成的交通事故[1],甚至代替駕駛員實現無人駕駛。自動駕駛車輛需要有高精度的傳感器和嚴格的算法,其在規避闖紅燈、無故超車以及壓線等危險違規操作方面比人工駕駛車輛更加可控。車道線作為機動車安全行駛的一個重要指引,是傳感器的重點數據采集對象,也是車輛實現自動駕駛的基礎[2]。
傳統的車道線檢測方法包括手工提取特征和啟發式方法[3-5],提取的特征包括顏色[6]、條形濾波器[7]、脊線[8]等,提取特征后再與霍夫變換和卡爾曼濾波器相結合以識別車道線。郜瑞芹[9]提出一種針對車道線彎道的塔式梯度直方圖方法,利用支持向量機對各種場景的彎道進行檢測,增強了算法在霧天場景的魯棒性;Kang 等[10]使用Sobel算子邊緣檢測獲得帶有噪聲的車道線邊緣特征,沿著垂直方向將道路圖像分為多個子區域,采用動態規劃算法進行車道線提取;Suddamalla 等[11]采用自適應閾值法,結合像素強度與邊界信息提取車道線標記;門光文[12]提出一種基于Canny 算子的車道線檢測方法,使用中值濾波濾除干擾信息,并使用Canny 算子提取車道線邊緣信息;蔣玉亭[13]提出一種基于邊緣點投影的車道線快速識別算法,根據邊緣信息提取車道特征點以及梯度方向投影計數,根據置信度判斷檢測車道線;郭月停[14]提出一種基于區域特征MSER 的改進方法,并對累積概率的Hough 變換算法PPHT 進行了改進;葉美松[15]提出一種單目視覺的車道線檢測算法,通過簡單縮放與逐樣本均值消減的方法對IPM 圖像進行歸一化處理,然后使用高斯濾波對圖片進行去噪閾值化處理;Ding 等[16]提出一種基于鳥瞰圖的新型車道線檢測方法,并根據遙感圖像中提取的道路特征改進了RANSAC 算法。
目前深度學習在圖像分割與目標分類領域中廣泛應用,基于深度學習的車道線檢測方法已逐漸成為趨勢。該方法通過對大量樣本進行訓練,自主學習獲取特征,在光照陰影、夜間、彎道等復雜駕駛環境中均具有較強的魯棒性。胡忠闖[17]提出一種基于CNN 的線段分類器方法,通過消失點檢測對車道線進行全局篩選,具有較強的實時性和魯棒性;Neven 等[18]提出一種基于CNN 的LaneNet 網絡車道線實例分割方法,通過LaneNet 結合聚類算法完成對每條車道線的分割,提高了擬合精度;Pan 等[19]設計了一個新的結構,在長寬方向上對CNN 輸出的特征圖分別進行切片,并將卷積結果向后傳遞,以達到循環神經網絡的效果;Ghafoorian 等[20]將車道線檢測看作是圖像分割問題,采用生成式對抗網絡,其中生成器用于生成車道線的預測值,判別器判別生成器的輸出與真實標簽的差異,最終網絡能夠直接生成車道線標記位置;Kim等[21]結合CNN與RANSAC算法進行車道線預測,利用CNN 強大的表達能力進行復雜道路場景的特征提取,采用RANSAC 算法進行車道線擬合;王嘉雯[22]提出一種基于6 層CNN 的車道線分類方法,以Canny 算子結合Hough 變換的方式突出車道線特征,再通過CNN 網絡對圖片進行分類訓練。
針對傳統車道線檢測方法易受環境影響且需要手工提取特征的局限性,本文構建一種基于CNN 結合后處理算法的車道線檢測方法,該方法具有不需要人工調參、適用場景較為廣泛以及擬合效果較好等優點。
1 圖像數據預處理
車道線圖像數據預處理是為了增強圖像中目標的特征,使深度學習能更好地學習特征信息,獲得泛化能力更強的模型。
1.1 ROI 提取
為去除多余圖片信息,改善網絡訓練的速度與檢測效果,采用固定的ROI 區域提取方法,通過OpenCV 將分辨率為720×480 的原始圖像(圖1)裁剪為720×240 的ROI 區域(圖2)。

Fig.1 Original image圖1 原始圖像

Fig.2 Original image after ROI圖2 原始圖片經ROI 后的區域圖
1.2 亮度對比度變換
對比度即最白與最黑亮度單位的比值,調節對比度可使圖像更加生動。以RGB 格式圖像的一個顏色通道為例,以像素當前顏色深度值I為橫坐標,輸出變換的顏色深度值O為縱坐標建立坐標系,傳統RGB 格式圖像的每個像素點都可以用0~255 的數值表示其顏色深度。
對圖像的亮度和對比度同時進行修改時,其變換方程式為:

式中,J為圖像亮度增加值,K為原始顏色深度比例值。
根據實際情況多次嘗試,確定了圖片對比度與亮度調整增加值,未經調整的原始圖像如圖3 所示,原始圖像經過K=1、J=20 的調整處理后如圖4 所示。

Fig.3 Original picture圖3 原始圖像

Fig.4 Effect of brightness contrast conversion圖4 亮度對比度變換效果
2 車道線檢測算法
本文建立的車道線檢測算法主要分為兩個步驟,分別為網絡設計與模型訓練、車道線模型后處理,如圖5 所示。

Fig.5 Design steps of lane line detection algorithm圖5 車道線檢測算法設計步驟
2.1 模型結構設計
對VGG16 網絡進行微調(Fine-tuning),在已經在其他分類問題上訓練好的VGG16 基網絡上添加自定義網絡,然后凍結基網絡,再訓練之前添加的自定義部分并解凍基網絡的某些層,最后聯合訓練解凍層與自定義添加部分,如圖6 所示。在網絡模型輸出的最后一層加入Softmax 層對模型框架進行修改,以實現模型輸出結果多通道像素點的概率分布,便于后處理算法中的聚類算法對車道線進行聚類操作。
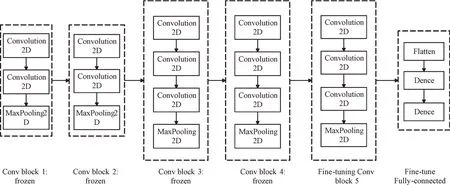
Fig.6 VGG16 network after adding fine-tuning圖6 添加fine-tuning 后的VGG16 網絡
2.2 車道線像素聚類
DBSCAN(Density-based Spatial Clustering of Applica?tions with Noise)是一種基于密度的聚類算法,其通過對核心點、密度可達點進行聚類,將具有足夠高密度的區域劃分為一類。同時,DBSCAN 還能識別出稀疏的噪聲數據。
對車道線分割模型輸出圖像的像素分布進行聚類處理,將屬于同一車道線的圖像像素點歸為同一類。將車道線分割圖像的像素點概率分布轉化為3D 可視化圖像,如圖7 所示,其中x軸表示圖像寬度,y軸表示圖像長度。按照x軸值對車道線分割輸出的像素點概率分布圖像進行排序,分別取圖像模型位置x=240、250…480 對應的y 項準確率(Accuracy)數據,然后提取概率值大于0.5 的峰值點,對其進行聚類,車道線概率值大于0.5 的峰值點輸出圖像如圖8所示。
2.3 車道線擬合與回歸
車道線擬合即對經過重新分類的車道線分割模型的像素點概率峰值點進行擬合處理,進而求得車道線的軌跡參數方程。
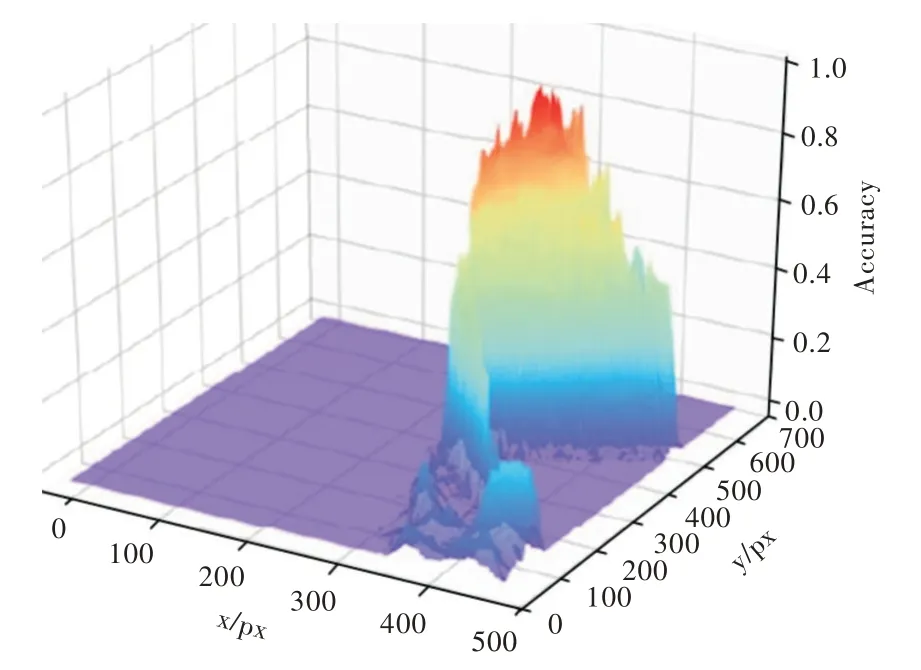
Fig.7 Probability map of pixel point probability distribution of lane line segmentation image圖7 分割圖像像素點概率分布圖
曲線擬合是指對給定的m個數據點Pi(xi,yi),i=1,2,…,m,求得一條近似曲線y=ρ(x),使曲線y=ρ(x)與真實曲線y=f(x)之間的偏差最小。y=ρ(x)在點Pi處的偏差δi的計算方式為:
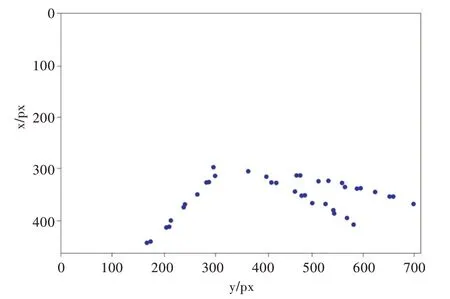
Fig.8 Output image of peak points with lane line probability value greater than 0.5圖8 概率值大于0.5 的峰值點輸出圖像

式中,δi為偏差。
偏差最小化計算公式為:
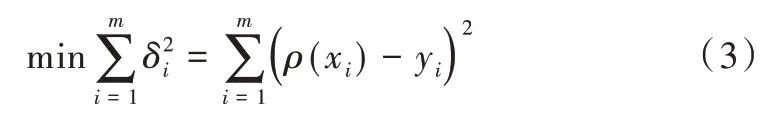
最小二乘法將二次方程作為擬合曲線,并選擇偏差平方和最小的擬合曲線。采用最小二乘法對給定的m個樣本點進行多項式擬合,使yi=f(x)的近似曲線δi=ρ(xi)-yi經過這些樣本點。
假設車道線需擬合的多項式為:
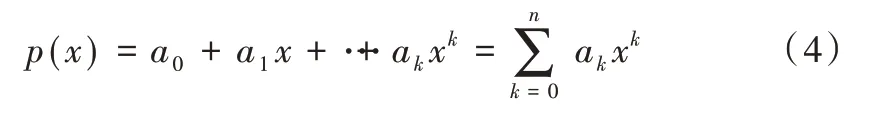
所有像素點到達近似曲線的偏差平方和為:
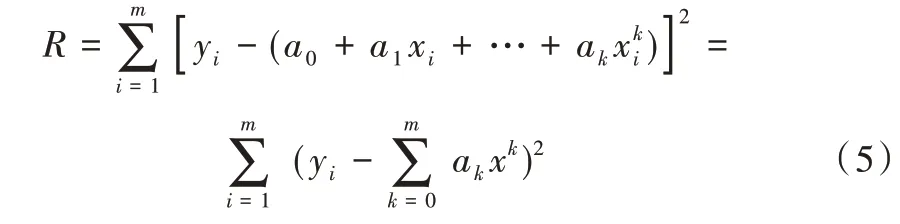
解多項式ai=(i=1,2,…,k),使式(6)取得最小值,表示為:
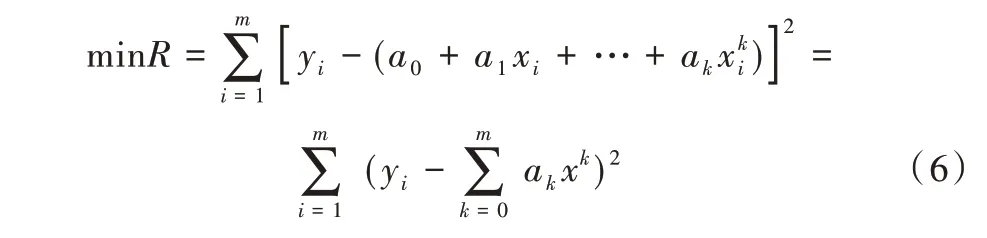
為求解參數a1,a1,…ak的多元函數極值,對變量ai=(i=1,2,…,k)求偏導公式得:

將等式變為矩陣形式:
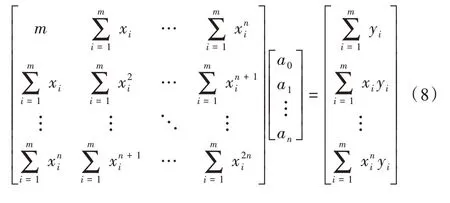
將范德蒙矩陣化簡后得到:

求解得系數矩陣Q公式為:

式(10)即為擬合曲線的關系式,利用最小二乘法對經過聚類分類的車道線像素點概率峰值點進行二次曲線擬合,擬合圖像如圖9 所示。將擬合曲線回歸到原始車道線圖像,示例效果如圖10 所示。
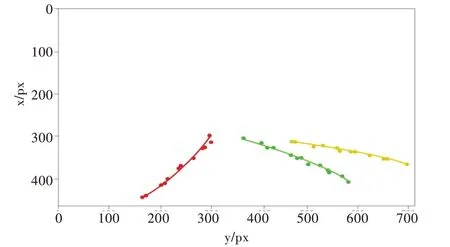
Fig.9 Conic fitting image圖9 二次曲線擬合圖像
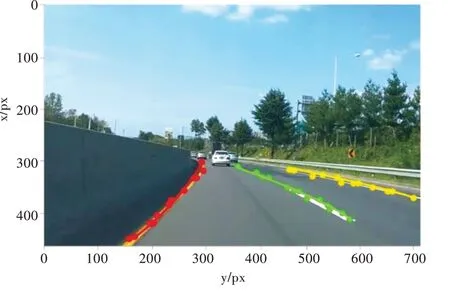
Fig.10 Lane line fitting effect diagram圖10 車道線擬合效果
3 實驗結果
本文算法基于Keras 深度學習框架,使用Python 語言,采用OpenCV 計算機視覺處理庫,在Ubuntu18.04L TS 系統上進行測試。
采用隨機梯度下降法對神經網絡模型進行訓練,初始學習率設為0.01,批處理大小(batch_size)設置為16,訓練循環(Epoch)設置為100。在訓練過程中會輸出一些反映模型訓練狀態的參數,根據迭代輪數,提取訓練過程輸出參數中訓練集和驗證集的平均準確率與損失量,利用OpenCV 繪圖函數分別繪制訓練過程中平均準確率與損失量隨迭代輪數變化的曲線。模型100 次迭代訓練的損失量隨迭代輪數變化的曲線如圖11 所示,模型100 次迭代訓練的平均準確率隨迭代輪數變化的曲線如圖12 所示。

Fig.11 Training loss curve圖11 訓練損失量變化曲線
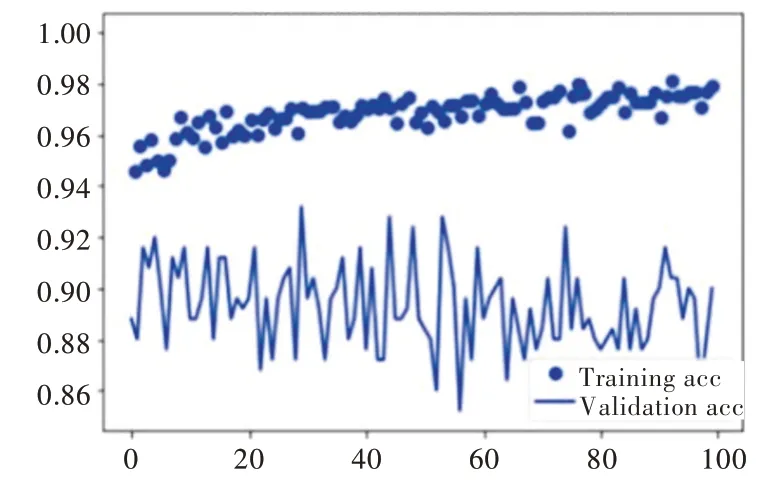
Fig.12 Training accuracy rate change curve圖12 訓練準確率變化曲線
將模型準確率與召回率定義為評判模型分割效果好壞的依據,即準確率與召回值越大,模型分割效果越好。平均準確率acc的計算公式為:

式中,Cimg為分割正確的像素點數,Timg為整個圖像標注的總像素點數。
將標注為車道線圖像區域的所有像素點分為車道線像素點與非車道線像素點,兩者的比值即為召回率recall。計算公式為:
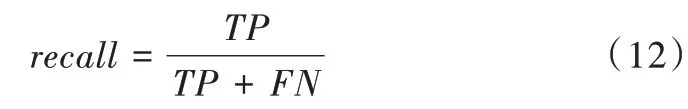
式中,TP為被正確預測的車道線像素點,FN為被錯誤預測的車道線像素點。
經過計算,最終模型驗證集的平均準確率、召回率分別為91.3%、90.6%,說明模型具有較好的分割效果。然后對不同場景下的車道線進行檢測識別,夜晚場景的車道線回歸如圖13 所示,陰天場景如圖14 所示,陰影場景如圖15所示,雨天場景如圖16 所示。

Fig.13 Lane line returnat night圖13 夜晚場景的車道線回歸

Fig.14 Lane line return in cloudy day圖14 陰天場景的車道線回歸

Fig.16 Lane line return in rainy day圖16 雨天場景的車道線回歸
針對同一實驗樣本,比較本文模型與其他模型的檢測準確率與單幀圖像耗時,結果如表1 所示。

Table 1 Comparison of accuracy and time of single frame image among different models表1 不同模型準確率與單幀圖像耗時對比
實驗結果顯示,傳統車道線檢測方法K-means 的準確率遠不如其他結合深度學習的模型方法。CNN 結合Hough變換的方法雖然提升了檢測準確率,但其處理單幀圖像的平均耗時最長,與該方法相比,SegNet 模型的車道線檢測準確率和平均耗時均有較大改善。相較于其他3 個模型,VGG16 模型在準確率以及單幀圖像處理速度方面均有明顯提升,達到了較好的圖像分割效果。
4 結語
本文利用CNN 在圖像特征提取領域的優勢對車道線特征進行學習,并利用DBSCAN 聚類算法對車道線分割模型進行后處理,提升了該模型的準確率,優化了車道線的擬合效果。實驗結果表明,與傳統車道線檢測算法相比,CNN 結合后處理的算法具有更高的準確性和可靠性。因此,本文提出的車道線檢測算法具有一定應用價值。但該算法仍存在一些不足之處:一方面,圖像在訓練過程中由于自身硬件條件的限制,可能導致訓練時間較長且訓練結果存在一定誤差,使網絡模型不能充分學習到圖像特征;另一方面,在進行車道線分割模型輸出數據后處理時,可能會濾除少部分像素點數據,導致不能對其進行擬合,造成部分車道線漏檢等情況。以上問題是下一步研究的重點方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
