采用梯度提升樹的戰(zhàn)機型號快速識別方法*
2021-07-28 10:04:36趙文彬
電訊技術(shù) 2021年7期
趙文彬
(中國西南電子技術(shù)研究所,成都 610036)
0 引 言
隨著軍事科技的快速發(fā)展,世界各軍事強國都在加緊研發(fā)速度更快、生存能力更強的新型戰(zhàn)機,期望以最小的代價和最優(yōu)的方式不斷壓縮敵方的預(yù)警時間,儼然成為克敵制勝的必要條件。在日益復(fù)雜多變的戰(zhàn)場環(huán)境中,空中高速高機動戰(zhàn)機的早發(fā)現(xiàn)、早識別、早預(yù)警變得越來越重要。如何自動、快速、甚至實時地識別出戰(zhàn)機型號,一直是軍事作戰(zhàn)領(lǐng)域關(guān)注的焦點和難點問題。
為了解決上述問題,許多科技工作者進行了大量的研究工作,提出了諸多解決方法。典型傳統(tǒng)模型方法[1-2]利用概率統(tǒng)計理論方法制定規(guī)則(如D-S證據(jù)理論),將目標(biāo)識別過程映射到規(guī)則集合中,最終完成目標(biāo)類型的辨識。然而,由于傳統(tǒng)模型方法的最終識別效果依賴于人工設(shè)計的特征模型好壞及統(tǒng)計規(guī)則的泛化性能,因此其普適性受到極大的限制。
隨著大數(shù)據(jù)時代的到來,機器學(xué)習(xí)和人工智能的興起為戰(zhàn)機型號識別帶來了新的生機[3-8]。然而真實環(huán)境中樣本數(shù)量和質(zhì)量的限制,需要海量數(shù)據(jù)的智能算法模型難以訓(xùn)練。而且模型參數(shù)數(shù)量較為龐大,不適用于嵌入式環(huán)境,且不可解釋。一旦模型應(yīng)用出現(xiàn)問題,不僅難以調(diào)試,而且可能造成不可估量的災(zāi)難性后果。
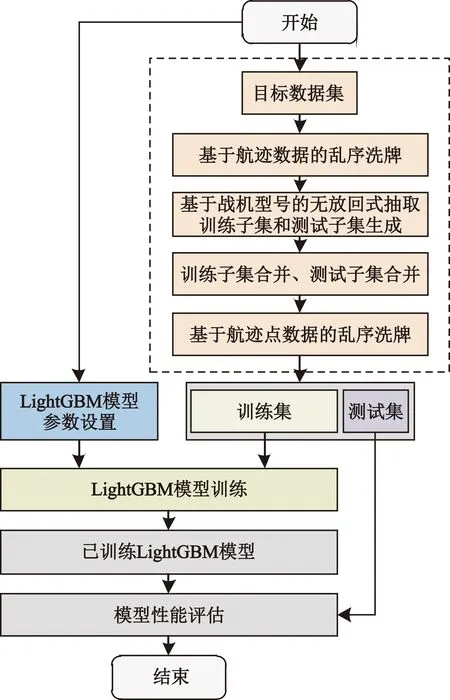
為了克服上述缺點,本文提出了基于梯度提升樹的戰(zhàn)機型號快速識別方法。首先,以多傳感器融合的戰(zhàn)機航跡解譯信息為數(shù)據(jù)基礎(chǔ),增加目標(biāo)信息的完整性、可靠性和可信性,以實時時序排列方式,充分刻畫目標(biāo)在空中運動的動態(tài)過程;其次,分析航跡數(shù)據(jù)特征,構(gòu)建戰(zhàn)機航跡數(shù)據(jù)特征工程;最后,利用boosting集成學(xué)習(xí)思想,訓(xùn)練基于梯度提升決策樹的分類器,可準(zhǔn)確識別每個航跡點對應(yīng)的戰(zhàn)機型號,從而同時滿足準(zhǔn)確性和實時性的實際應(yīng)用需求。
1 數(shù)據(jù)集與特征工程
1.1 目標(biāo)數(shù)據(jù)集
本文采用的數(shù)據(jù)集為已經(jīng)過脫密和偏移處理后的多傳感器融合戰(zhàn)機航跡解譯數(shù)據(jù)集,其組織結(jié)構(gòu)如圖1所示。數(shù)據(jù)集包含14種戰(zhàn)機型號,分別用字母A,B,…,N依次進行標(biāo)識。每種戰(zhàn)機型號數(shù)據(jù)包含眾多相應(yīng)類型的個體戰(zhàn)機航跡數(shù)據(jù),且航跡數(shù)據(jù)持續(xù)時間各不相同。每條航跡數(shù)據(jù)又由諸多具有點編號(pid)、目標(biāo)編號(tid)、經(jīng)度(lon)、緯度(lat)、高度(h)、速度(v)、航向(az)、Unix時間(t)等多維特征的航跡點數(shù)據(jù)組成。航跡點數(shù)據(jù)示例如表1所示。
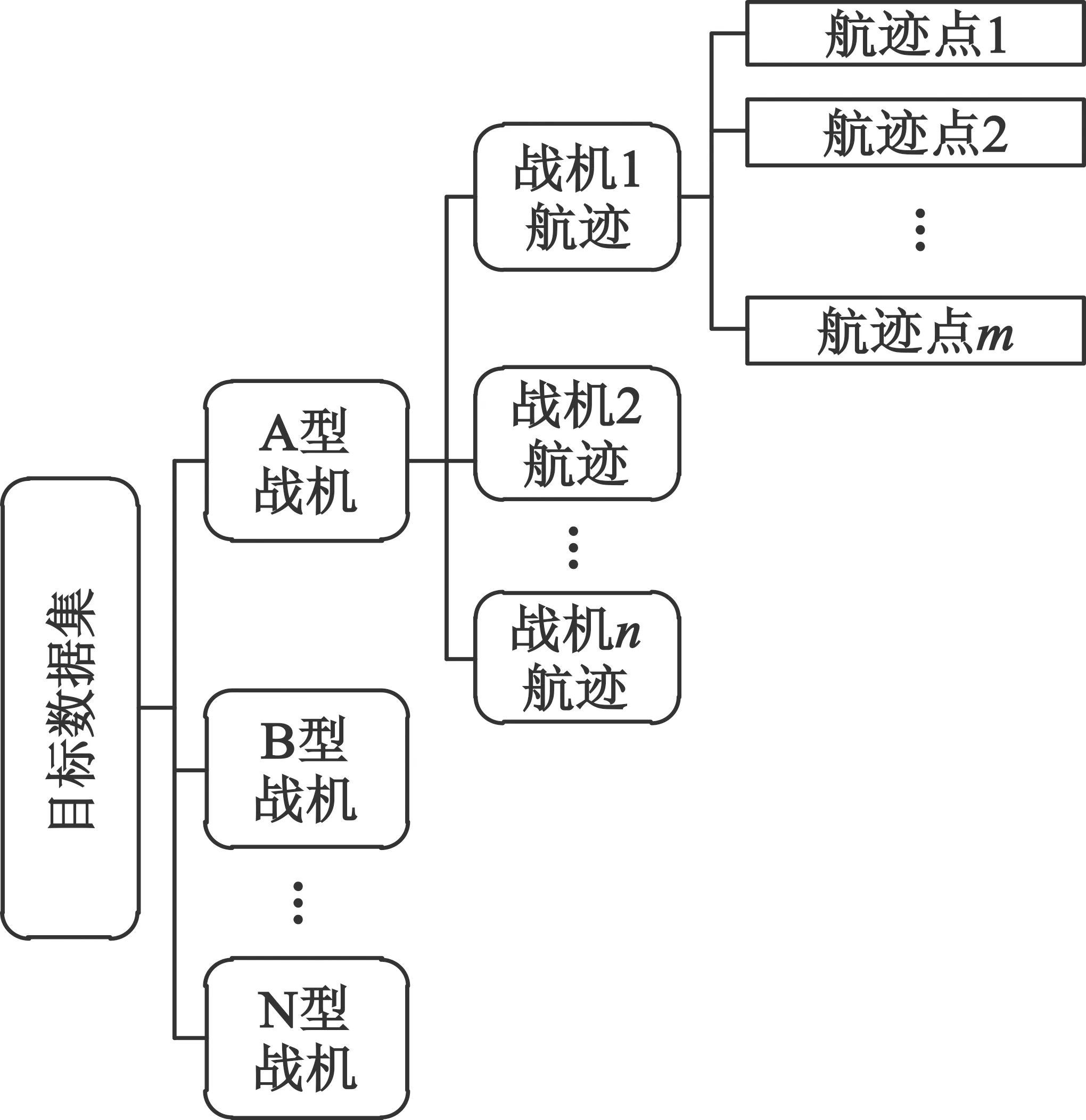
圖1 數(shù)據(jù)集結(jié)構(gòu)示意圖
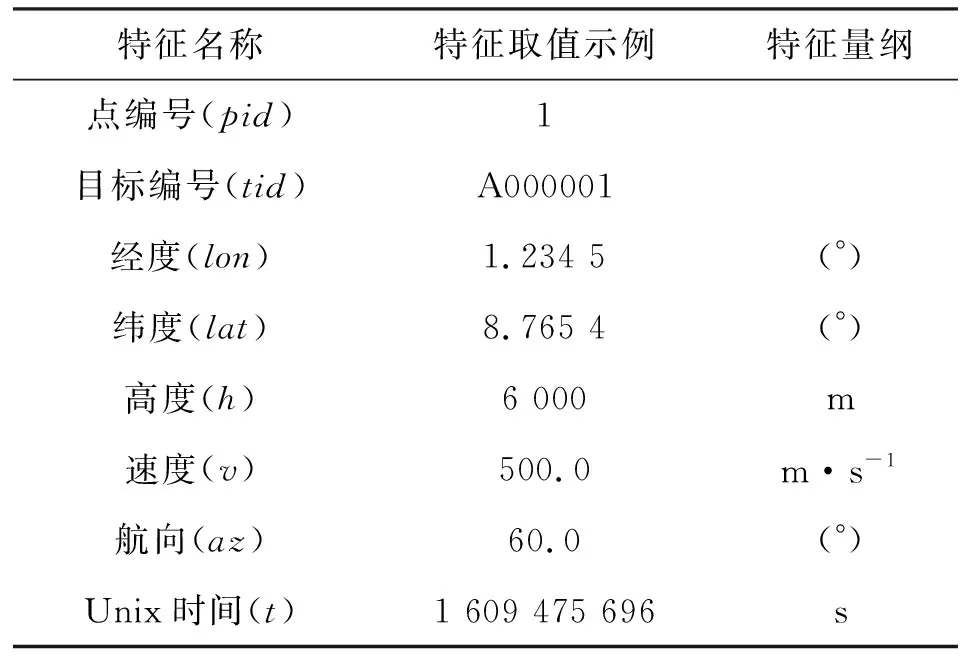
表1 航跡點數(shù)據(jù)示例
由于多傳感器戰(zhàn)機航跡數(shù)據(jù)在融合過程中未考慮去重、異常值剔除等數(shù)據(jù)預(yù)處理,因此需要對原始數(shù)據(jù)進行數(shù)據(jù)清洗,其流程如圖2所示。
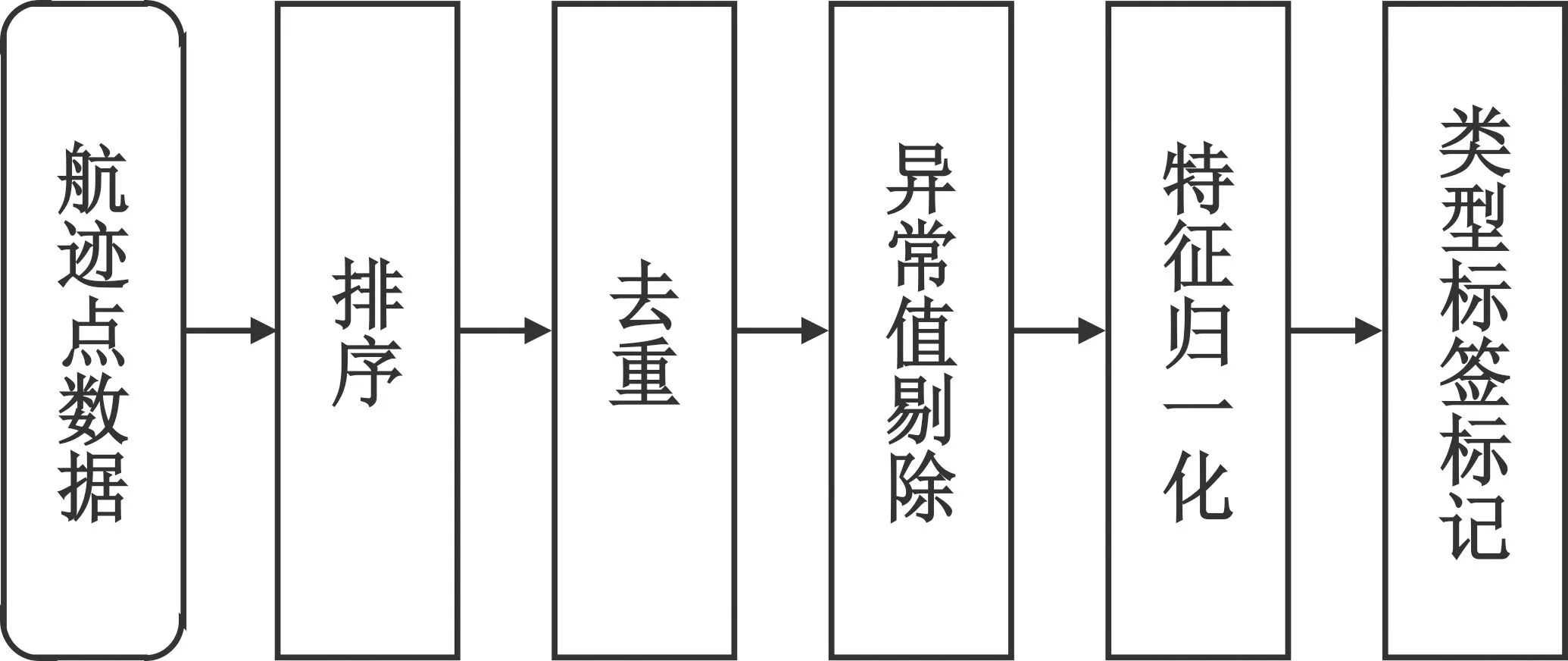
圖2 數(shù)據(jù)清洗流程圖
第一步,針對數(shù)據(jù)集,分別按目標(biāo)編號和Unix時間特征進行分組和升序排序,將相同個體目標(biāo)的航跡點以時間先后順序排列形成航跡數(shù)據(jù)。
第二步,針對每個個體戰(zhàn)機航跡數(shù)據(jù)執(zhí)行去重操作。通過比較相鄰兩個航跡點數(shù)據(jù)是否完全相同來進行重復(fù)判斷。若判決為真,則刪除后一個航跡點數(shù)據(jù),并對點編號進行相應(yīng)的更新。
第三步,檢查去重后的個體戰(zhàn)機航跡點數(shù)據(jù)是否存在異常。由于多源融合戰(zhàn)機航跡數(shù)據(jù)位置屬性已經(jīng)過充分的去噪和判證,故直接采信經(jīng)度和緯度的特征數(shù)值。但是由于受傳感器測量精度的影響,高度和速度特征存在較為嚴(yán)重的數(shù)值抖動問題。因此,針對高度和速度兩個連續(xù)型特征,按照式(1)和式(2)所示的3σ規(guī)則進行異常值剔除清洗,使得航跡高度和速度特征更加平滑。
(1)
(2)
第四步,針對已經(jīng)過異常值剔除后的目標(biāo)數(shù)據(jù)集,獲取經(jīng)度、緯度、高度、速度等特征的最值,對所有航跡點數(shù)據(jù)對應(yīng)特征值進行歸一化處理,即
(3)
第五步,經(jīng)過前述預(yù)處理后的全體個體戰(zhàn)機航跡點數(shù)據(jù)均添加“目標(biāo)類別”標(biāo)簽屬性,其取值為個體戰(zhàn)機所屬的14種戰(zhàn)機行型號代碼。本文使用數(shù)字1~14來標(biāo)識戰(zhàn)機型號A~N,便于后續(xù)識別模型的訓(xùn)練。
至此,目標(biāo)數(shù)據(jù)集清洗完成,數(shù)據(jù)集中的航跡點樣本數(shù)目情況如表2所示,部分航跡樣本如圖3所示。
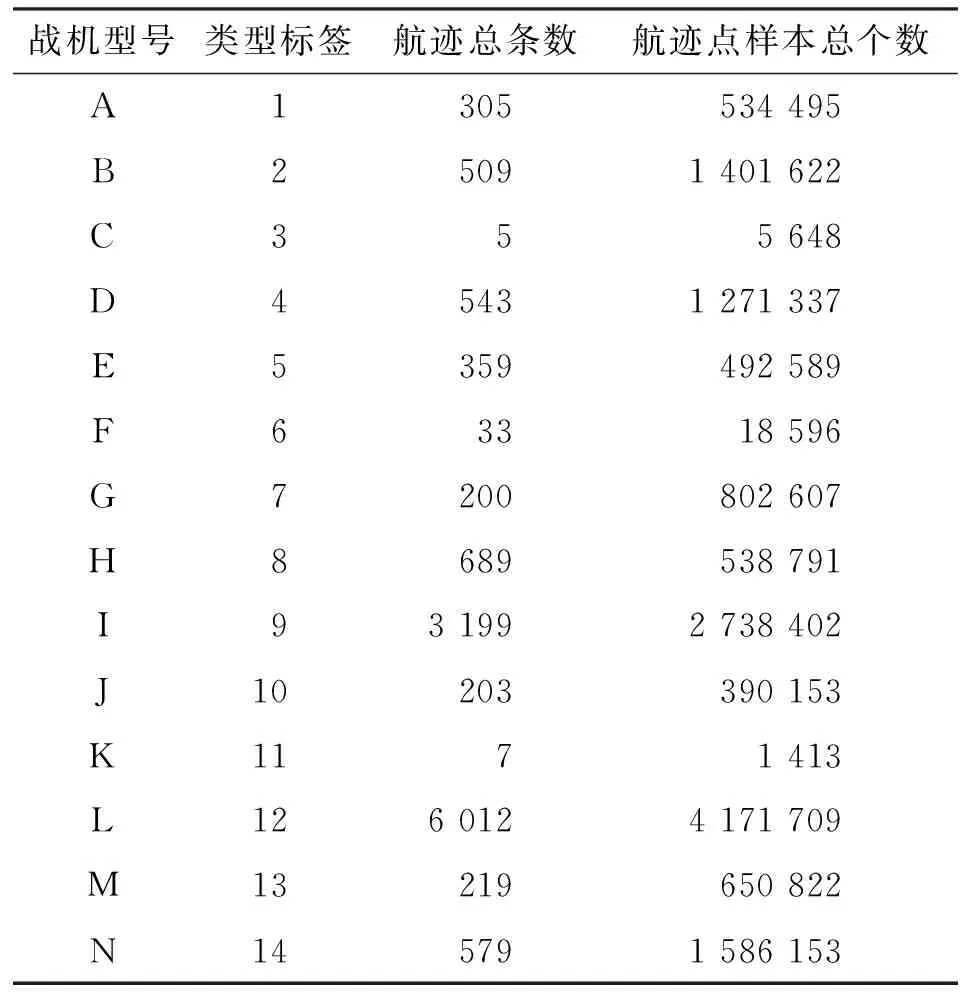
表2 清洗后的目標(biāo)數(shù)據(jù)集總覽
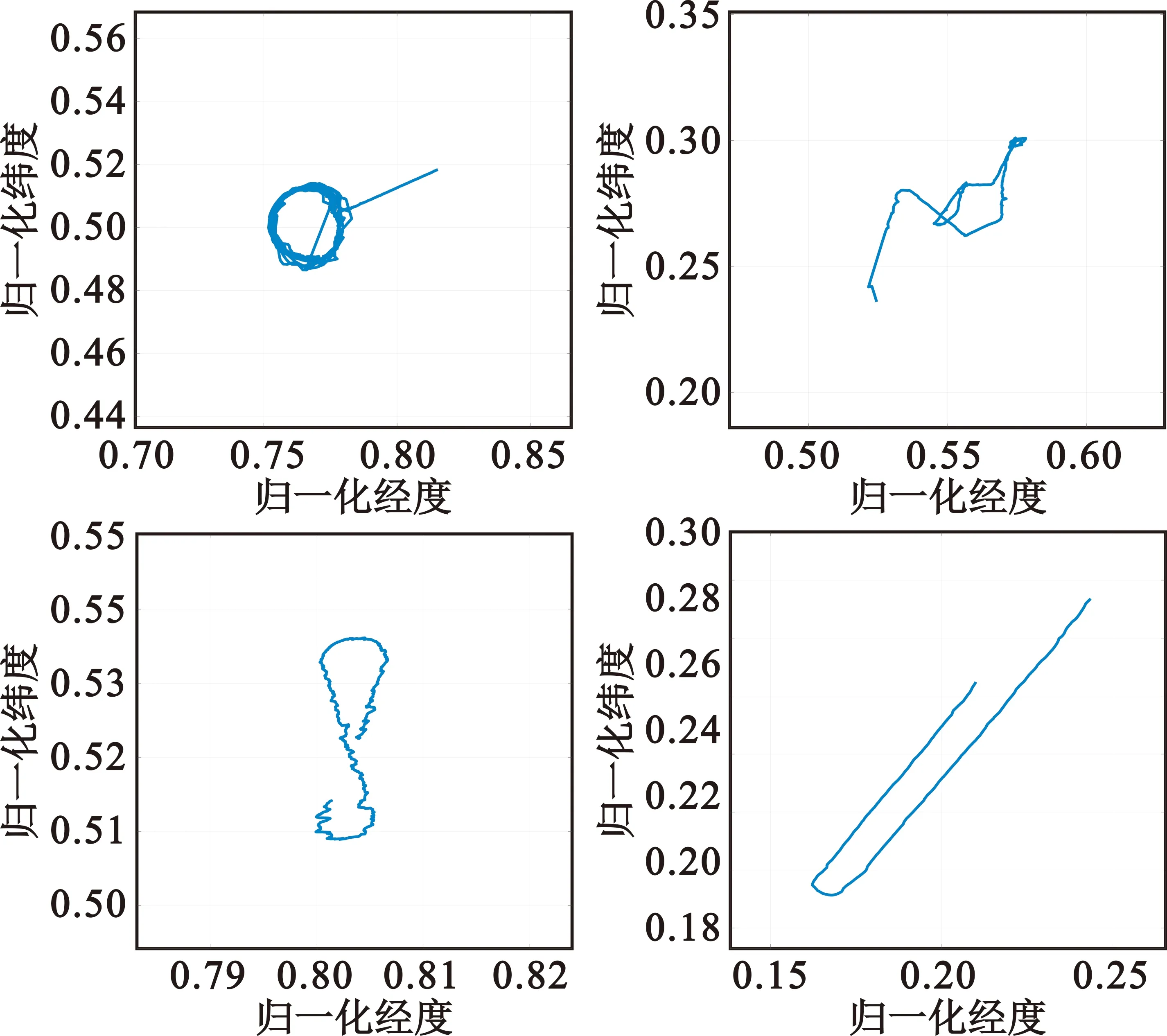
圖3 部分航跡數(shù)據(jù)展示
1.2 特征構(gòu)造
數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)通過參數(shù)化方法構(gòu)建結(jié)構(gòu)化模型,使模型具備擬合數(shù)據(jù)共性統(tǒng)計規(guī)律特征的能力。因此,根據(jù)數(shù)據(jù)特點進行特征設(shè)計和選擇是影響模型學(xué)習(xí)性能的重要因素之一。
為了提升識別效果,需要對空中目標(biāo)航跡統(tǒng)計規(guī)律進行精細化描述,以便識別模型能夠精準(zhǔn)捕捉航跡統(tǒng)計規(guī)律和細節(jié)特征。基于此,本文在經(jīng)過清洗的目標(biāo)數(shù)據(jù)集航跡點特征基礎(chǔ)上,構(gòu)造了如下所列特征。
1.2.1 三角化航向
具有角度單位的航向具備連續(xù)循環(huán)性質(zhì),即對任意航向θ,都存在如下關(guān)系:
(θ+360°k)mod360°=θ,θ∈[0,360°),k∈Z。
(4)
由于實際使用中通常限定θ∈[0,360°),因此原始航向數(shù)據(jù)在0°處存在跳躍間斷點,破壞了航向的連續(xù)性。
因此,本文將數(shù)據(jù)中每個航跡點的角度制航向進行三角化,生成正弦航向以及余弦航向兩個特征,通過特征組合,共同表征航向的連續(xù)循環(huán)性。航向三角化特征生成流程如圖4所示。
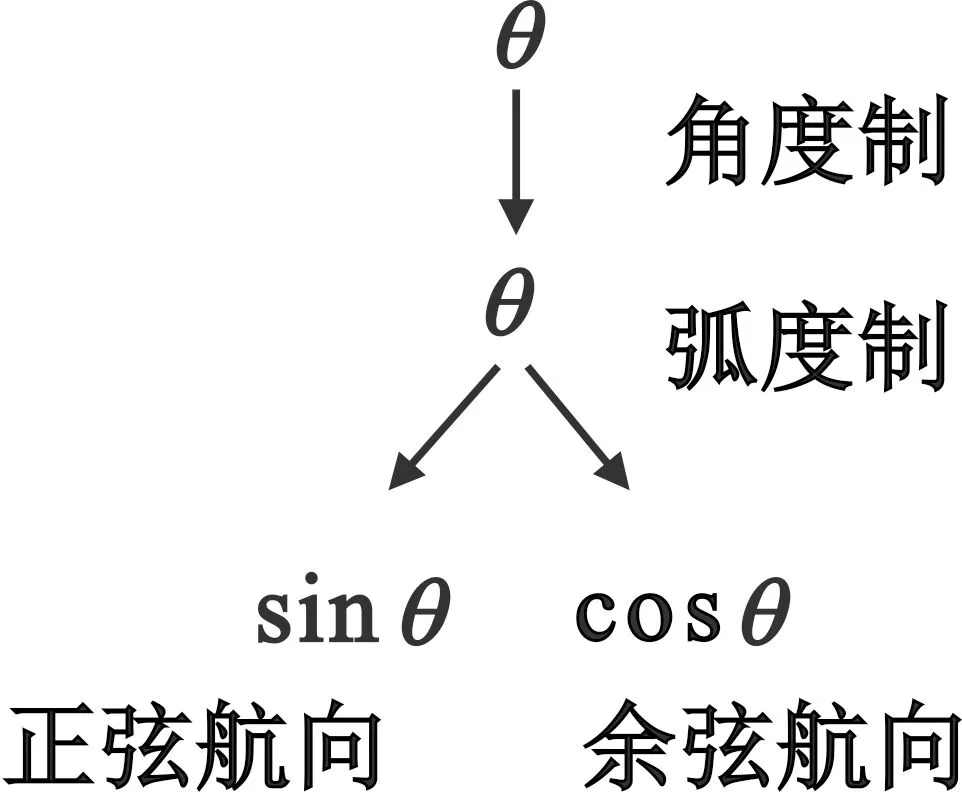
圖4 三角化航向
1.2.2 大圓距離
對于航跡數(shù)據(jù)來說,兩航跡點間的距離是最為顯著的運動學(xué)特征。為了度量兩個航跡點之間的距離,一種方法是采用歐式距離。但是在地理空間分析中,歐式距離存在諸多問題,關(guān)鍵在于歐式距離適用于直角坐標(biāo)系,而地球可近似于一個球體,因此需要使用適用于球面的距離度量。在地理空間數(shù)據(jù)分析領(lǐng)域,大圓距離即為度量兩個給定經(jīng)緯度地理坐標(biāo)點下的弧線距離,亦稱為Haversine公式,形如式(5)所示:
(5)
式中:p1和p2為地球球面上的兩個點,它們的經(jīng)緯地理坐標(biāo)分別記為(λ1,φ1)和(λ1,φ1),符號λ表示經(jīng)度,φ表示緯度;Rearth表示赤道地球半徑,取值約6 370.856 km;參數(shù)C定義為
C=sin2A+cosφ1cosφ2sin2B,
(6)
(7)
(8)
由此本文根據(jù)式(5),通過計算目標(biāo)航跡數(shù)據(jù)相鄰兩個航跡點的相對大圓距離來表征目標(biāo)的實際航程,記為
di=d(pi,pi-1),i=2,3,…,m。
(9)
式中:d1=0,即以航跡起始點為大圓距離原點,單位為km。
1.2.3 時間差
時間差是衡量目標(biāo)運動狀態(tài)的時間尺度,因此,本文基于Unix時間特征,計算相鄰兩個航跡點之間的Unix時間秒差,如式(10)所示。由于觀察到目標(biāo)航跡數(shù)據(jù)Unix時間特征數(shù)值基本在幾十秒,同時考慮到后續(xù)模型計算的數(shù)值穩(wěn)定性,本文將時間差單位換算成分鐘(min)。
Δti=ti-ti-1,i=2,3,…,m。
(10)
令Δt1=0,即以航跡起始時刻為時間基準(zhǔn)。
1.2.4 大圓相對速度
已有的目標(biāo)航速特征是目標(biāo)根據(jù)慣性導(dǎo)航系統(tǒng)和地面多傳感系統(tǒng)計算得出的自身運動速度狀態(tài),其數(shù)值存在相當(dāng)?shù)钠睿尚哦容^低,不宜作為后續(xù)識別模型的輸入特征。為了更進一步準(zhǔn)確描述目標(biāo)在地理空間中的運動狀態(tài),本文利用大圓距離和時間差特征,導(dǎo)出大圓相對速度,作為速度特征的信息補充,其計算公式為
(11)
式中:d為兩個相鄰航跡點間的大圓距離,單位為km;Δt為相應(yīng)航跡點間的時間差,單位為min;vd的單位為m/s。
1.2.5 五點大圓距離的百分位數(shù)
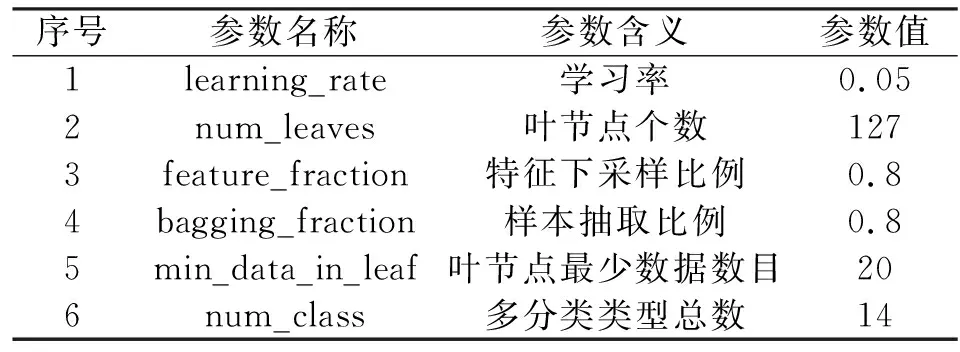
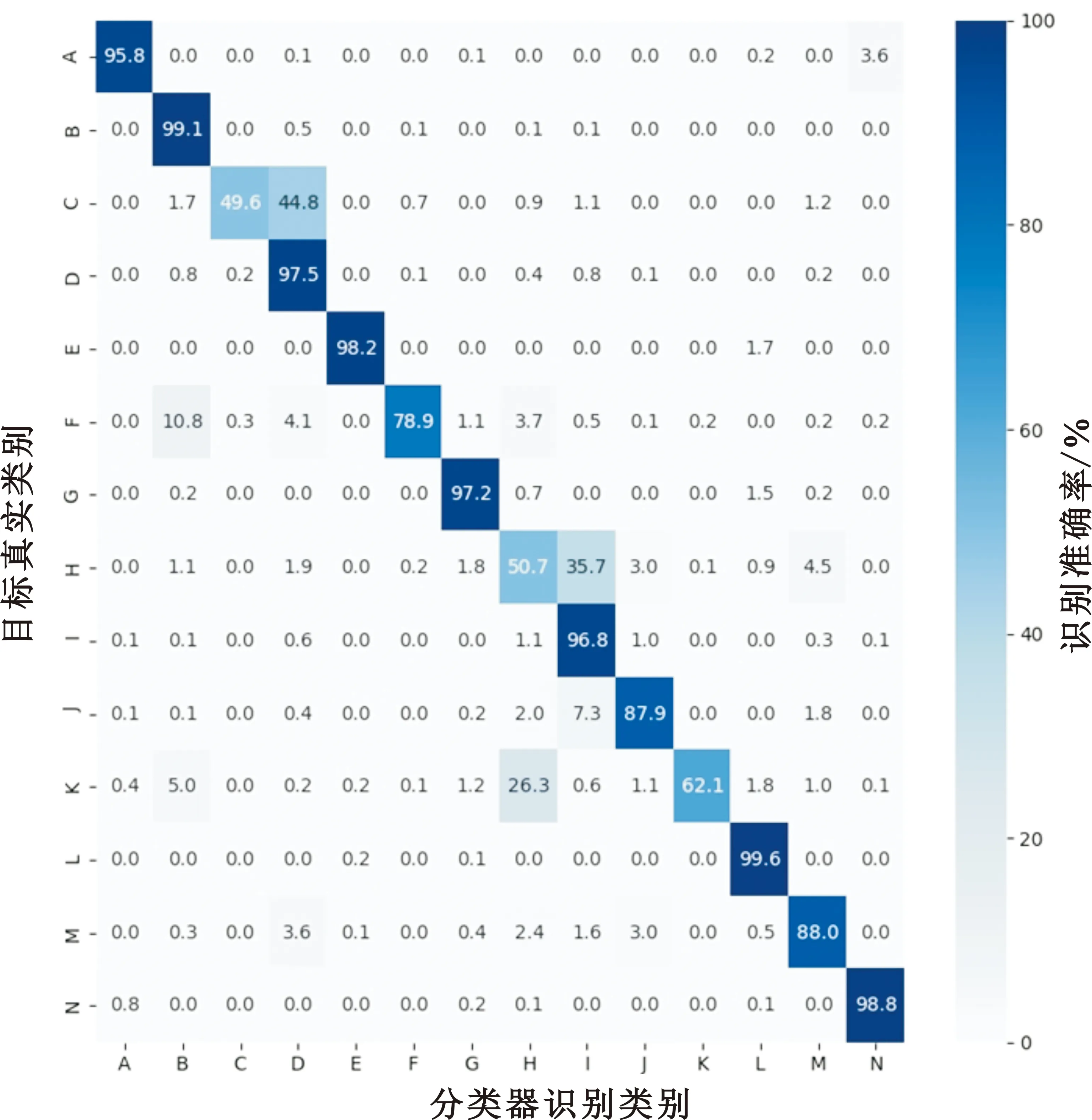
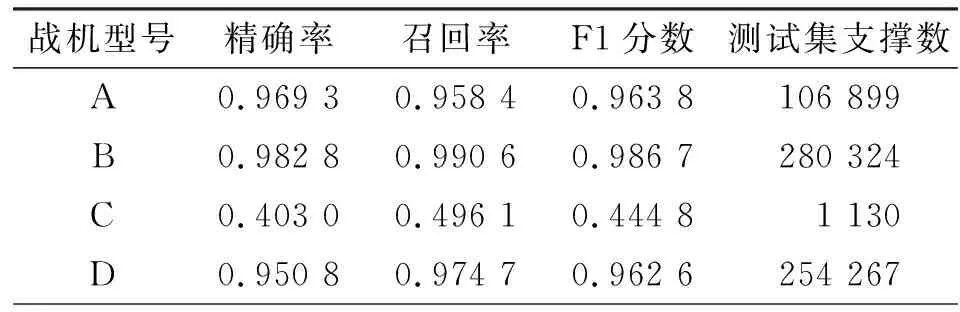
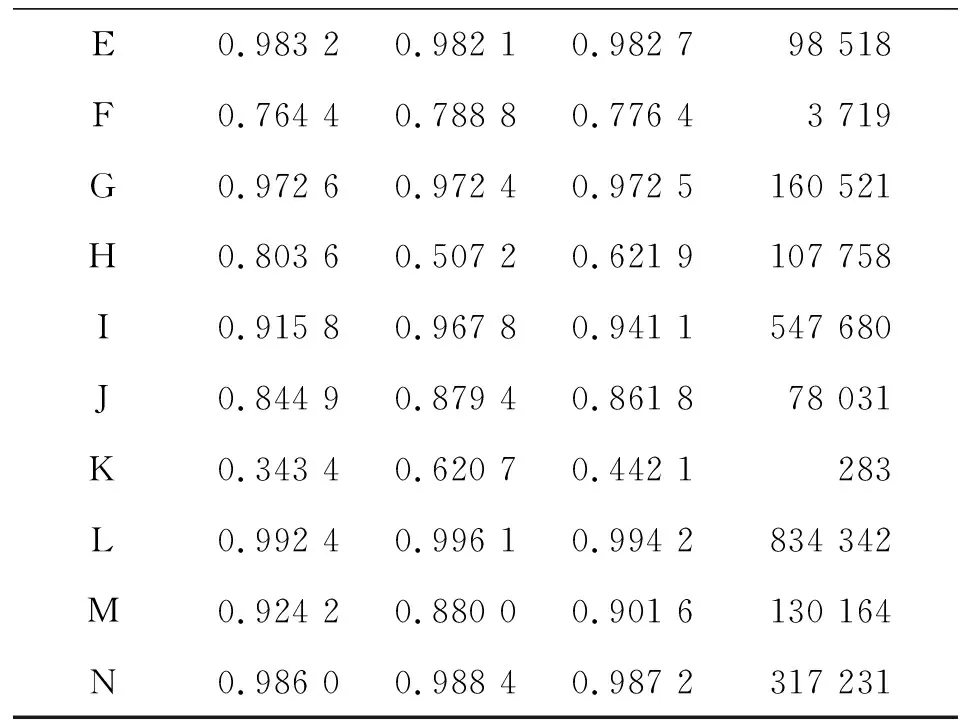
分位數(shù)是統(tǒng)計學(xué)中重要的概念,用于描述數(shù)據(jù)取值概率的分布,直觀上可表征數(shù)據(jù)概率分布函數(shù)的形狀,即若概率0 為了更加準(zhǔn)確地反映目標(biāo)運動狀態(tài),同時兼顧實時性,本文采用五點大圓距離百分位數(shù)來動態(tài)地刻畫大圓距離特征的概率分布。具體地,以5個目標(biāo)航跡點為窗長,計算窗內(nèi)大圓距離數(shù)值的11個百分位數(shù),即z10%、z20%、z30%、z40%、z50%、z60%、z70%、z80%、z90%,以及z25%和z75%。 考慮到真實航跡起始時,窗內(nèi)點數(shù)不足5點,故僅在此情況下只計算當(dāng)前窗內(nèi)有效點數(shù)對應(yīng)的百分位數(shù)。 1.2.6 五點大圓相對速度的百分位數(shù) 同1.2.5節(jié)中原理相似,以相同百分位數(shù)統(tǒng)計方法,對大圓相對速度特征進行百分位數(shù)統(tǒng)計,生成11個統(tǒng)計特征,具體過程不再贅述。 1.2.7 大圓距離的五點均值 均值是用來描述統(tǒng)計分布重要的數(shù)字特征之一,反映了數(shù)據(jù)取值的平均水平。同理,為了兼顧目標(biāo)運動狀態(tài)統(tǒng)計準(zhǔn)確性以及實時性,本文采用五點均值來刻畫大圓距離特征取值的平均水平。具體地,以5個目標(biāo)航跡點為窗長,計算窗內(nèi)大圓距離數(shù)值的均值。 同理,考慮到真實航跡起始時,窗內(nèi)點數(shù)不足5點,故僅在此情況下只計算當(dāng)前窗內(nèi)有效點數(shù)對應(yīng)的均值。 1.2.8 大圓相對速度的五點均值 同1.2.7節(jié)中原理相似,以相同均值統(tǒng)計方法對大圓相對速度特征進行均值統(tǒng)計,生成均值統(tǒng)計特征,具體過程不再贅述。 至此,特征構(gòu)造過程完畢,總特征數(shù)目為32個(不包含點編號、目標(biāo)編號和原始速度特征)。 提升樹是一種利用boosting策略生成決策樹學(xué)習(xí)器的集成學(xué)習(xí)經(jīng)典方法。其基本思想是通過前向分步算法多輪迭代生成多棵殘差子決策樹,使得所有子決策樹的輸出和越來越逼近最終的決策目標(biāo)。因此,提升樹在機器學(xué)習(xí)算法族的應(yīng)用中具有很高的準(zhǔn)確率。然而,提升樹在不同任務(wù)學(xué)習(xí)過程中需要使用不同的損失函數(shù)。當(dāng)面臨分類任務(wù)常用的交叉熵損失函數(shù)時,提升樹的學(xué)習(xí)優(yōu)化過程將變得更加困難[10]。因此,梯度提升樹算法[11](Gradient Boosting Decision Tree,GBDT)應(yīng)運而生,通過對擬合函數(shù)初始化由0改為待擬合函數(shù)的均值分量,使決策樹學(xué)習(xí)過程收斂速度加快,以及利用最速下降的數(shù)值近似方法,將提升樹中的殘差替換為損失函數(shù)當(dāng)前模型值的負梯度,大幅降低計算量,提升算法普適性。但面臨大數(shù)據(jù)樣本集時,由于計算殘差時需要遍歷樣本集,算法時間復(fù)雜度巨大,計算效率大大降低。 為此,Ke等[12]提出了LightGBM模型,是目前實現(xiàn)GBDT算法速度最快、占用空間最小的決策樹計算模型,如圖5所示。其特點在于: 圖5 由LightGBM計算得到的決策樹示意圖 (1)使用直方圖統(tǒng)計替代預(yù)排序方法,利用直方圖做差等技巧,將連續(xù)特征屬性值按bin分組,提高緩存命中率,由level-wise策略轉(zhuǎn)變?yōu)閘eaf-wise策略,減少各中間決策節(jié)點分割增益計算量,使計算效率大為提升; (2)提出基于梯度的單邊采樣策略(Gradient-based One Side Sampling,GOSS)對樣本數(shù)據(jù)實施采樣抽取,僅獲得對梯度下降貢獻大的大梯度樣本數(shù)據(jù),進一步降低計算時間開銷,減少內(nèi)存空間消耗,同時防止了模型的過擬合; (3)提出特征捆綁策略(Exclusive Feature Budding,EFB)有效利用了高維特征空間數(shù)據(jù)的稀疏性,降低了特征維數(shù),在保證學(xué)習(xí)精度的同時,加快了計算速度,進一步降低了計算開銷。 本文使用LightGBM計算模型作為分類器,對14類戰(zhàn)機型號進行分類識別,流程如圖6所示。 圖6 分類器設(shè)計流程 2.2.1 形成訓(xùn)練集與測試集 首先,針對清洗后的目標(biāo)數(shù)據(jù)集進行劃分,形成訓(xùn)練集與測試集,其步驟如下: Step1 以戰(zhàn)機航跡數(shù)據(jù)為統(tǒng)計細粒度,對各戰(zhàn)機型號數(shù)據(jù)以隨機亂序方式分別進行洗牌。 Step2 依據(jù)每種戰(zhàn)機型號所含戰(zhàn)機航跡總條數(shù),以8∶2的比例,無放回地抽取形成對應(yīng)型號的訓(xùn)練子集與測試子集。 Step3 將所有戰(zhàn)機型號對應(yīng)的兩類子集合分別進行合并,形成用于分類器訓(xùn)練和測試的初步訓(xùn)練集與初步測試集。 Step4 針對兩類初步數(shù)據(jù)集合,以航跡點為細粒度,以隨機亂序方式再次進行洗牌,形成最終可用于模型訓(xùn)練和測試的訓(xùn)練集及測試集。其中,訓(xùn)練集包含11 683 470個航跡點樣本,測試集包含2 920 867個航跡點樣本。 2.2.2 設(shè)置LightGBM分類模型參數(shù) 本文采用基于python語言的LightGBM包,通過調(diào)用模型算法模塊,實現(xiàn)戰(zhàn)場空中目標(biāo)的快速準(zhǔn)確識別。該模型算法需要設(shè)置的主要參數(shù)如表3所示。 表3 LightGBM算法模塊主要參數(shù)設(shè)置 其中,關(guān)鍵參數(shù)num_leaves,即決策樹葉節(jié)點個數(shù),該值控制了決策樹的深度(如果值越大,那么由于模型leaf-wise生長策略,將導(dǎo)致LightGBM模型趨于過擬合);min_data_in_leaf,即每個葉節(jié)點最少能夠容納數(shù)據(jù)的個數(shù)(當(dāng)該值越小,LightGBM模型就越趨于過擬合狀態(tài))。 learning_rate、num_leaves、min_data_in_leaf等參數(shù)可通過網(wǎng)格搜索方法(Grid Search)在訓(xùn)練階段進行自動搜索。 2.2.3 開始模型訓(xùn)練過程 本文采用五折交叉驗證方式,將訓(xùn)練集進一步分割為訓(xùn)練子集和驗證子集,用以全面評估模型的分類能力。評估的準(zhǔn)則采用精確率P、召回率R以及F1分?jǐn)?shù)F1,其定義分別為 (12) (13) (14) 式中:TP表示標(biāo)簽為當(dāng)前戰(zhàn)機型號且分類器預(yù)測結(jié)果也為當(dāng)前戰(zhàn)機型號的所有航跡點樣本的總個數(shù),FP表示標(biāo)簽不為當(dāng)前戰(zhàn)機型號且分類器預(yù)測結(jié)果卻為當(dāng)前戰(zhàn)機型號的所有航跡點樣本的總個數(shù),FN表示標(biāo)簽不為當(dāng)前戰(zhàn)機型號且分類器預(yù)測結(jié)果也不為當(dāng)前戰(zhàn)機型號的所有航跡點樣本的總個數(shù)。從式(14)看出,F(xiàn)1分?jǐn)?shù)實質(zhì)上是精確率P和召回率R的調(diào)和平均數(shù),只有當(dāng)P值和R值都接近于1時,F(xiàn)1值才會接近于1,否則F1值下降,如圖7所示,所以F1值能夠充分反映分類器的分類性能。 圖7 精確率與召回率引起F1分?jǐn)?shù)變化的規(guī)律 2.2.4 識別決策輸出 最后,將生成的5個交叉驗證分類子模型的識別結(jié)果以多數(shù)投票方式進行集成決策,最終得到唯一的戰(zhàn)機型號識別決策輸出。 本文所提模型的訓(xùn)練及測試過程均在如下的試驗環(huán)境進行:DELL Z840工作站采用2個Intel Xeon Gold 6136型號的CPU,總共包含內(nèi)核24個,線程48個;主頻均為3.00 GHz。操作系統(tǒng)為CentOS 7.3 64位,算法開發(fā)環(huán)境使用python3.7、anaconda以及sklearn,分析平臺使用pycharm2020。 根據(jù)2.2節(jié)的模型訓(xùn)練流程,對LightGBM進行訓(xùn)練,模型關(guān)鍵參數(shù)及對應(yīng)參數(shù)值如表3所示。經(jīng)過訓(xùn)練后,最終模型占用的存儲空間為1 MB。在測試集上,識別模型的最終分類性能由圖8所示的混淆矩陣以及表4所示的類別識別性能分?jǐn)?shù)表給出。其中,表4中的測試集支撐數(shù)是指測試集中對應(yīng)戰(zhàn)機型號的航跡點樣本個數(shù)。 圖8 戰(zhàn)場空中目標(biāo)快速識別模型混淆矩陣 表4 戰(zhàn)場空中目標(biāo)快速識別模型測試集識別性能 表4(續(xù)) 從圖8混淆矩陣以及表4所列分?jǐn)?shù)中可看出以下幾種誤識別情況:(1)戰(zhàn)機型號C有相當(dāng)概率被誤識別為戰(zhàn)機型號D;(2)戰(zhàn)機型號F有一定概率被識別為戰(zhàn)機型號B和D;(3)戰(zhàn)機型號H有大概率被識別為戰(zhàn)機型號I;(4)戰(zhàn)機型號K有大概率被識別為戰(zhàn)機型號H。 識別模型產(chǎn)生誤識別的主要原因有兩點: 一是訓(xùn)練樣本集中樣本數(shù)目過少,即“小樣本”問題,這對應(yīng)于誤識別情況(1)、(2)和(4)。“小樣本”問題使得所訓(xùn)模型的學(xué)習(xí)方向偏向于樣本數(shù)目較多的類別,造成了模型學(xué)習(xí)的偏差,故在測試階段模型表現(xiàn)出誤識別特點。 二是所學(xué)特征在特征空間中的可分性不強,對應(yīng)于誤識別情況(3),即不存在一個超平面足以將兩類目標(biāo)特征空間完全區(qū)分開,造成目標(biāo)類別識別的高虛警率,從而在測試階段模型出現(xiàn)誤識別情況。 另一方面,為了測試所訓(xùn)模型計算的實時性,本文還對所訓(xùn)模型的識別速度在測試集上進行了統(tǒng)計。其過程是,將測試集數(shù)據(jù)轉(zhuǎn)換為高維航跡點數(shù)據(jù)流,以10 000點數(shù)據(jù)流長度為單位,以第1點灌入所訓(xùn)模型的時刻為起點,以模型輸出第10 000點識別結(jié)果時刻為止,計算所有萬點數(shù)據(jù)的模型計算耗時平均值,然后再除以10 000,結(jié)果作為所訓(xùn)模型最終的單點計算時間。經(jīng)過測試,所提模型的平均單點計算時間為408.1 μs。 為了證明所提方法的性能優(yōu)勢,本文還與文獻[13]中的卷積神經(jīng)網(wǎng)絡(luò)(Convolution Neural Network,CNN)方法進行了比較,具體流程如圖9所示。 圖9 基于CNN的性能比對模型設(shè)計流程 Step1 針對清洗后的目標(biāo)數(shù)據(jù)集,以戰(zhàn)機航跡數(shù)據(jù)為統(tǒng)計細粒度,對各戰(zhàn)機型號數(shù)據(jù)以隨機亂序方式分別進行洗牌。 Step2 依據(jù)每種戰(zhàn)機型號所含戰(zhàn)機航跡總條數(shù),以8∶2的比例,無放回地抽取形成對應(yīng)型號的訓(xùn)練子集與測試子集。 Step3 將所有戰(zhàn)機型號對應(yīng)的兩類子集合分別進行合并,形成用于分類器訓(xùn)練和測試的初步訓(xùn)練集與初步測試集。 Step4 對初步訓(xùn)練集與初步測試集以戰(zhàn)機航跡數(shù)據(jù)為統(tǒng)計細粒度,使用隨機亂序方式分別再次進行洗牌,從而獲得訓(xùn)練和測試CNN模型所需要的訓(xùn)練和測試數(shù)據(jù)集。 然后,按照文獻[13]中的方法構(gòu)建和訓(xùn)練CNN模型。形成的CNN模型占用空間為25.6 MB。 最后,利用測試數(shù)據(jù)集對已訓(xùn)好的CNN模型進行測試。具體地,沿航跡數(shù)據(jù)時間維度,將每個測試集樣本依次送入CNN網(wǎng)絡(luò),對每個航跡點的戰(zhàn)機型號識別結(jié)果進行記錄,統(tǒng)計每個型號的平均識別準(zhǔn)確率。同時,以3.1節(jié)所述的方法計算單點平均計算時長。 經(jīng)過上述訓(xùn)練和測試步驟后,得到CNN模型的戰(zhàn)機型號平均識別正確率為90.32%,F(xiàn)1分?jǐn)?shù)加權(quán)平均值為0.824 9,單點平均計算時長為5 385.5 μs。 通過表5所示的模型性能對比可以證明,在相同試驗環(huán)境、相同數(shù)據(jù)集條件下,所提梯度提升樹識別模型在識別正確率、F1分?jǐn)?shù)和識別速度等性能上較CNN方法更優(yōu)。 表5 模型性能比較 本文針對作戰(zhàn)戰(zhàn)機型號快速識別的焦點和難點問題,提出了一種基于梯度提升樹的戰(zhàn)機型號快速識別方法。以多傳感器融合的戰(zhàn)機航跡解譯信息為數(shù)據(jù)基礎(chǔ),分析了航跡數(shù)據(jù)特征,構(gòu)建了戰(zhàn)機航跡數(shù)據(jù)特征工程,利用boosting集成學(xué)習(xí)思想,訓(xùn)練了基于梯度提升決策樹的分類器。基于實測數(shù)據(jù)的實驗表明,所提方法可準(zhǔn)確識別每個航跡點對應(yīng)的戰(zhàn)機型號,識別準(zhǔn)確率達到95.76%,較CNN方法的90.32%提高了5.44%;所提方法F1分?jǐn)?shù)加權(quán)平均數(shù)達到0.955 4,而CNN模型的F1分?jǐn)?shù)加權(quán)平均數(shù)為0.824 9。此外,所提方法平均單點計算時間為408.1 μs,較CNN方法的5 385.5 μs快13.19倍,驗證了所提算法能夠快速有效地辨識戰(zhàn)機型號,滿足準(zhǔn)確性和實時性需求。然而,由于樣本數(shù)量的不均衡、小樣本識別以及特征空間的不可分等問題的存在,所提方法在識別精確性方面還需要進一步改進。2 基于梯度提升樹的快速識別方法
2.1 梯度提升樹基本原理
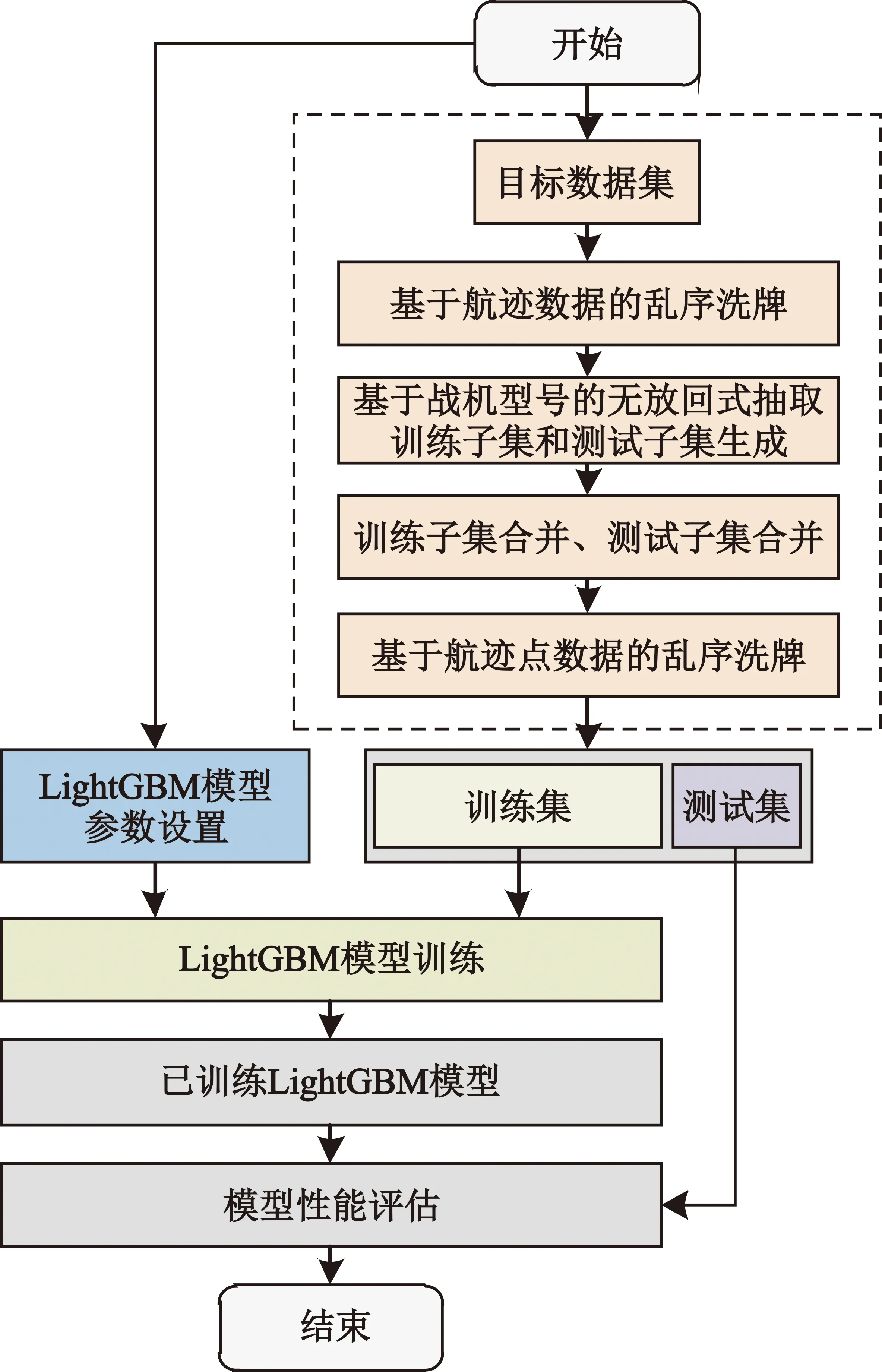
2.2 基于LightGBM的分類器訓(xùn)練流程

3 實驗及結(jié)果
3.1 LightGBM識別效果
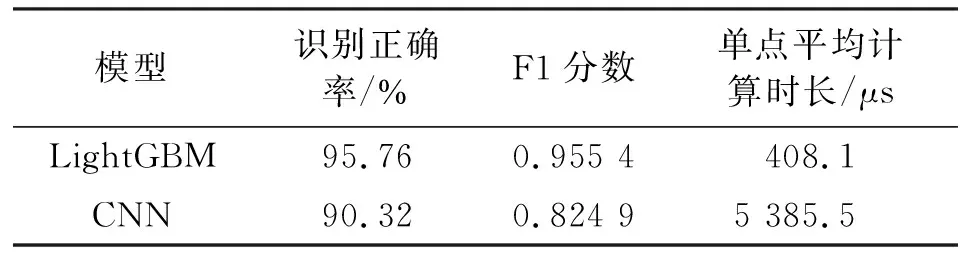
3.2 CNN識別效果
4 結(jié)束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
