權利要求特征驅動的專利關鍵詞抽取方法
2021-07-17 14:59:42俞琰尚明杰趙乃瑄
情報學報 2021年6期
俞琰,尚明杰,趙乃瑄
(1.南京工業大學信息管理與技術研究所,南京 210009;2.東南大學成賢學院電子與計算機學院,南京 211816)
1 引言
專利關鍵詞是表明專利文獻主題內容的一組詞或者短語,被廣泛應用于專利文獻自動文摘、分類、檢索、翻譯、聚類等專利分析之中。而專利文獻通常不包含關鍵詞,需要人工標引。由于專利文獻篇幅較長、內容專業,且近年來專利文獻的數量急劇增長,使得人工標引專利關鍵詞的方法已無法滿足專利分析的需要。因此,如何利用計算機自動、高效、準確地抽取專利關鍵詞成為一個重要的研究課題。
詞頻-逆文檔頻率(term frequency-inverse document frequency,TF-ⅠDF)[1]是目前使用較為廣泛的關鍵詞抽取方法之一。該方法首先通過詞性規則匹配選取候選關鍵詞,然后利用候選關鍵詞在文檔中的詞頻和數據集中的逆文檔頻率對候選關鍵詞重要性進行評估,選擇權重最大的若干候選關鍵詞作為關鍵詞。研究表明,該方法在專利關鍵詞抽取方法中具有有效性[2]。
然而,目前的專利關鍵詞抽取主要依據通用文本的關鍵詞抽取方法,沒有考慮專利文獻自身的特征,關鍵詞抽取結果仍有較大提升空間。具體來說,TF-ⅠDF方法在專利關鍵詞抽取中主要存在兩個問題。
問題1:基于人工制定的詞性規則匹配方法費時、費力,且選取的候選關鍵詞遺漏較多。例如,最常使用的詞性匹配規則為依據形容詞(a)和名詞(n)的詞性組合選取候選關鍵詞[3],這可能漏選包含動詞(v)的“前饋/v神經網絡/n”“命名/n實體/n識別/v”“自由基/n引發/v劑/n”,包含語素(g)“最大/a熵/g”,包含數詞(m)的“二/m羥基/n乙基/n二甲基/n乙烯/n”“喹賽/n多/m”等關鍵詞。
問題2:候選關鍵詞權重TF-ⅠDF不能很好地反映專利的創造性和新穎性。例如,在本文示例專利“基于最大熵和神經網絡模型的韓語命名實體識別方法”(申請號:CN201710586675.2)中,非專利關鍵詞“實體 標簽”“模板 選擇 規則”的TF-ⅠDF值高于專利關鍵詞“前綴樹字典”“神經網絡模型”和“實體 字典”的TF-ⅠDF值。
實際上,專利文獻包括標題、摘要、權利要求、說明書和附圖等部分內容。其中,權利要求既是技術文獻,也是法律文書,是專利文獻的核心,在內容和格式上不同于普通文獻,有其特定的要求。一方面,在內容上,權利要求需要包含體現專利新穎性、創造性與實用性的全部必要技術特征,以說明要保護的專利范圍,而專利關鍵詞正是體現專利新穎性、創造性與實用性的詞語或短語;另一方面,在格式上,權利要求至少包含一項獨立權利要求,還可以包含若干從屬權利要求。從屬權利要求通常會選出重要的、對申請專利新穎性、創造性和實用性起作用的必要技術特征加以限定,以增強專利的法律穩定性。因此,本文通過權力要求特征的分析,提出權力要求特征驅動的專利關鍵詞抽取方法,以提高專利關鍵詞抽取的準確性。
具體地,本文提出的權利要求特征驅動的專利關鍵詞抽取方法具有如下主要創新點:①從專利關鍵詞抽取任務出發,對權利要求特征進行分析;②基于權利要求特征,提出基于最長公共子串的候選關鍵詞選取方法;③引入信息增益比概念,提出一種去除冗余候選關鍵詞的方法;④基于權利要求特征,提出特指度指標,將其融入傳統的TF-ⅠDF候選關鍵詞權重之中;⑤通過實驗數據比較分析,證明本文所提出的方法的可行性與有效性。
2 相關研究
目前,關鍵詞抽取方法主要分為有監督方法和無監督方法兩大類。
有監督方法通常將關鍵詞抽取問題看作一個分類問題,使用機器學習方法,通過事先給定的包含樣本的訓練語料學習分類模型,然后使用學習得到的分類模型進行關鍵詞抽取。典型的有監督方法包括樸素貝葉斯[4]、支持向量機[5-7]、條件隨機場[8-9]等。近年來,隨著深度學習方法的興起,一些研究嘗試使用深度學習方法自動學習文本特征,并結合條件隨機抽取關鍵詞[10-11]。總的來說,有監督方法抽取關鍵詞優于無監督方法,但存在依賴訓練語料的規模與質量、大規模人工標注的訓練語料難以獲取、抽取效果受到訓練語料的領域性影響較大、模型較為復雜,可能存在過擬合等問題[12]。
無監督方法通常包括候選關鍵詞選取和候選關鍵詞權重兩個主要步驟。其中,候選關鍵詞選取通常采用詞性規則匹配方法,其認為關鍵詞的詞性序列遵循特定排列規則,如“形容詞+名詞”[3]等規則;候選關鍵詞權重則利用各種評分指標對候選關鍵詞的重要性進行評估,以選取排名最前的若干候選關鍵詞作為關鍵詞。由于無監督方法不需要事先標注數據,模型直觀明了,從而一直得到研究者的廣泛關注,是近年來研究和應用的重點。其中,候選關鍵詞權重主要包括基于統計的方法和基于圖模型的方法等。
基于統計的方法根據文本中詞語的詞頻、位置、詞性和長度等統計特征權重候選關鍵詞。其中,TF-ⅠDF方法[1]因其簡單有效而被廣泛使用。TF-ⅠDF方法認為詞語的重要性與其在目標文本中出現的次數正相關,與其出現的總文本負相關。然而,TF-ⅠDF單純以詞頻衡量一個詞的重要性,不夠全面。因此,有些研究者嘗試利用詞語的位置[13]、類內信息[14]、詞跨度[15]、詞性[16]、詞聚類[17]和國際專利分類號等[18]特征對其進行改進。
基于圖模型的方法將文本中的詞構建為圖模型,評估圖中起重要作用和中心作用的詞或者短語,將這些詞或者短語作為關鍵詞。其中,TextRank方法[19]因其簡潔有效、適應性強、無需訓練數據、擴展性強、速度快等特點而被廣泛應用。TextRank方法以詞作為圖模型的頂點,詞語間的關聯作為邊進行隨機游走,根據得分高低選擇關鍵詞。一些研究者嘗試利用詞位置[20-23]、主題[24-26]、語義[27-29]等信息,以提高TextRank方法的關鍵詞抽取準確率。
總之,目前的專利關鍵詞抽取通常沿用傳統通用文本的關鍵詞抽取方法,沒有充分考察和利用專利特征,抽取結果仍有較大提升空間。因此,利用專利特征以提高專利關鍵詞抽取的結果仍有待進一步深入研究。
3 權利要求特征分析
專利權利要求是一種法律文件,說明要求專利保護范圍,是專利申請文件的核心,在專利申請和專利訴訟中都起著至關重要的作用。
權利要求不同于一般文本,在內容和格式上都具有特定的要求。在內容上,權利要求需要包含體現專利新穎性、創造性與實用性的全部必不可少的技術手段或技術方案,即必要技術特征,以說明要保護的專利范圍。在格式上,至少包含一項獨立權利要求,還可以包含若干從屬權利要求。獨立權利要求從整體上說明專利權利范圍,從屬權利要求必須依從于一個獨立權利要求或者在前的從屬權利要求,用附加的技術特征對引用的權利要求作進一步限定。從屬權利要求通常會選出重要的、對申請新穎性和創造性起作用的必要技術特征作限定,以增強專利的法律穩定性。為了避免這些反復出現技術特征的歧義性,常冠以“所述”“所述的”(英文“the”“said”)等特指詞,確認所提技術特征。
圖1為示例專利的權利要求。其中,權利要求1是獨立權利要求,權利要求2~9為從屬權利要求。從屬權利要求2~4均引用獨立權利要求1,對獨立權利要求1中的技術特征進一步限定,從屬權利5則引用從屬權利要求4,對其中技術特征做進一步限定。圖1虛線表明引用權利要求使用特指詞“所述”對被引用權利要求做進一步限定,以避免歧義。
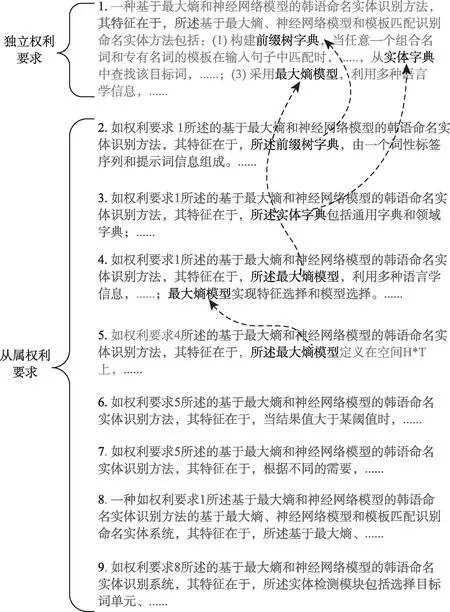
圖1 示例專利權利要求
4 權利要求特征驅動的專利關鍵詞抽取方法
根據權利要求特征,本文提出了權利要求特征驅動的專利關鍵詞抽取方法。該方法主要包括預處理(第4.1節)、基于最長公共子串的候選關鍵詞選取(第4.2節)、基于信息增益比的冗余候選關鍵詞去除(第4.3節)和融入特指度的候選關鍵詞權重(第4.4節)4個主要步驟。
4.1 預處理
預處理主要包括分詞、去除停用詞等工作。其中,由于中文文本詞與詞之間沒有明顯的切分標記,需要通過分詞把一個句子按照其中詞的含義進行切分。去除停用詞則通過通用停用詞表以及人工篩選去除頻率高但是信息量少的詞,如“發明”等詞。此外,預處理工作還包括英文大小寫格式轉換、去除特殊符號等工作。
4.2 基于最長公共子串的候選關鍵詞選取
根據第3節分析的權利要求特征,本文提出了基于最長公共子串的候選關鍵詞選取方法。該方法首先構建專利樹PatentTree,然后依據專利樹的父節點與子節點的最長公共子串選取候選關鍵詞。
具體地,PatentTree=(V,E,root),其中,V是PatentTree的節點集合;每個節點vi對應專利權利要求ci;E?(V×V)是PatentTree的邊集合;E中元素<vi,vj>表示權利要求cj引用權利要求ci;root表示PatentTree根結點,對應專利標題和摘要,與獨立權利要求相連。圖2為示例專利的PatentTree。
根據PatentTree,選取PatentTree的父節點與子節點的最長公共子串(longest common string,LCS)作為候選關鍵詞[30]。如示例專利父節點獨立權利要求1中經過預處理的連續詞串“構建前綴樹字典”,與其子節點權利要求2中經過預處理的連續詞串“所述前綴樹字典”的最長公共子串為“前綴樹字典”。表1為示例專利中父節點與子節點的最長公共子串。
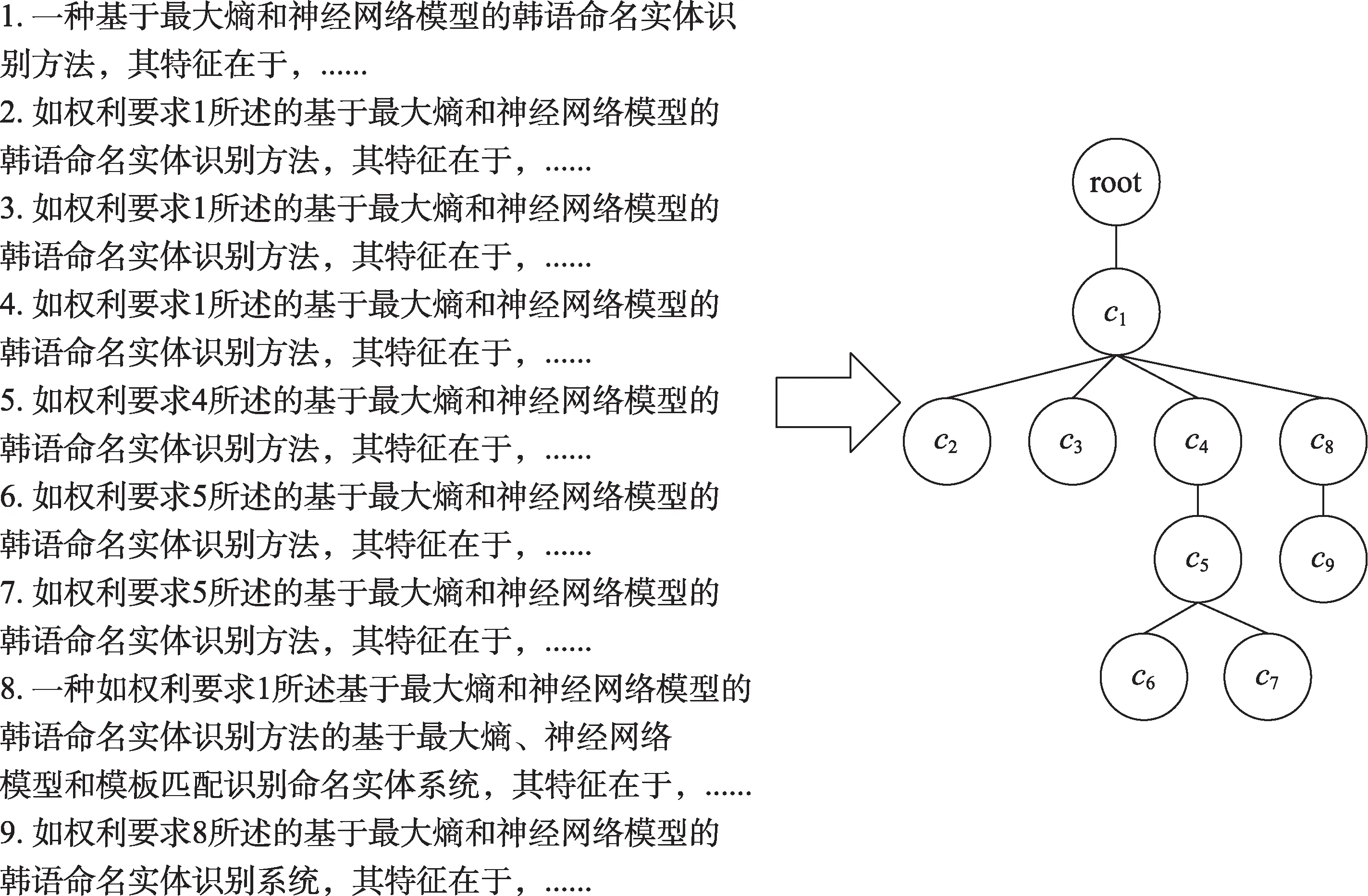
圖2 示例專利PatentTree

表1 示例專利最長公共子串
所有的最長公共子串構成了候選關鍵詞集合,表2為示例專利基于詞性規則匹配方法[3]與基于最長公共子串方法選取的候選關鍵詞比較,其中人工標注的關鍵詞使用粗體表示。由表2可見,基于最長公共子串選取的候選關鍵詞具有更高的關鍵詞覆蓋率、領域獨立性和簡單易行等優點。
4.3 基于信息增益比的冗余候選關鍵詞去除
第4.2節選取的候選關鍵詞中,存在較多嵌套候選關鍵詞,所謂嵌套候選關鍵詞,是指候選關鍵詞y(稱為父串)包含候選關鍵詞x(稱為子串),如“利用前綴樹”和“前綴樹”。表3第1列子串和第2列母串為示例專利中的部分嵌套候選關鍵詞。嵌套候選關鍵詞具有一定的普遍性,一些嵌套候選關鍵詞均具有較高權重值,如在示例專利中,“最大熵”“基于 最大熵”“最大熵 模型”等嵌套候選關鍵詞均具有較高權重,從而造成關鍵詞抽取錯誤。
在這些嵌套候選關鍵詞中,一方面,一些母串包含比子串更多信息,如母串“韓語命名實體識別”和子串“命名實體識別”,應予以保留;另一方面,一些母串并沒有比子串包含更多信息,甚至是錯誤的候選關鍵詞,為冗余候選關鍵詞,如母串“基于最大熵”相較于子串“最大熵”,應予以去除。

表2 示例專利候選關鍵詞選取比較
據此,本文提出指標I(Ⅰnformation),以衡量一個詞w的信息量:
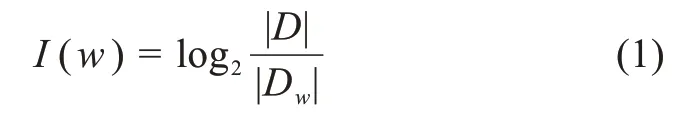
其中,|D|表示數據集文檔數;|Dw|表示詞w在數據集中出現的文檔頻率。一個詞在數據集中出現的文檔頻率越低,其包含的信息量越大。
基于信息量Ⅰ的定義,給定母串y和子串x,使用信息增益比(information gain ratio,ⅠGR)衡量母串相較于子串增加的信息量的多寡,其定義為
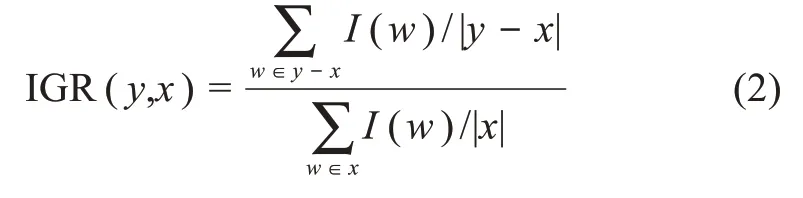
其中,|x|表示子串x中包含的詞語個數;y-x表示包含在y中但不包含在x中的詞語;|y-x|表示包含在y中但不包含在x中詞語個數。公式(2)分母表示子串x的平均詞語信息量;分子表示母串y相較于子串x新增加詞語的平均信息量。由公式(2)可知,ⅠGR是一個正實數,當其值小于1時,表示母串中新增加的詞語的平均信息量少于子串的平均信息量。ⅠGR的值越小,表明新增加詞語的平均信息量越少;反之,表明新增詞語的平均信息量越多。通過設定閾值(本文閾值設定為0.5),可以去除一些添加信息量少的冗余候選關鍵詞。表3為示例專利信息增益比,其中,母串相對于子串中新增的詞語使用粗體表示。由表3可知,通過信息增益比,可以保留“韓語命名實體識別”等嵌套候選關鍵詞,同時去除“基于最大熵”等冗余候選關鍵詞。
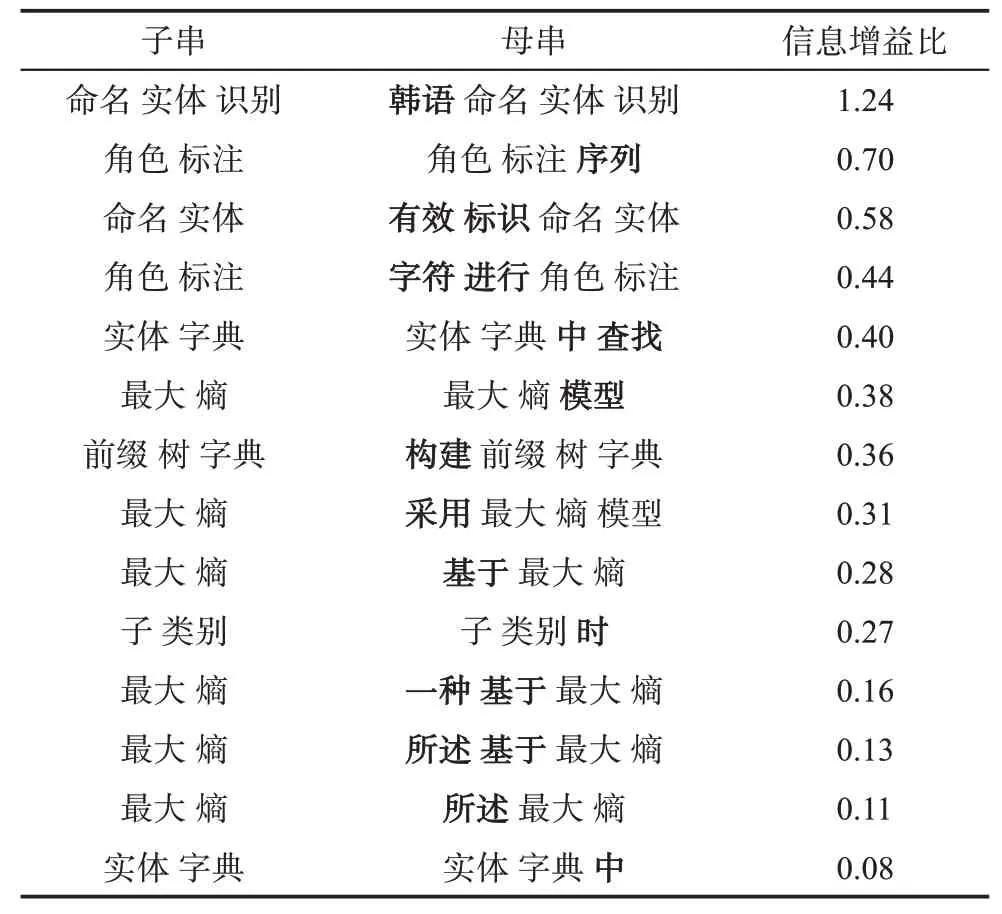
表3 示例專利信息增益比
4.4 融入特指度的候選關鍵詞權重
TF-ⅠDF[1]是一種常用的度量候選關鍵詞重要性的方法,該方法假設一個候選關鍵詞在目標文本中出現頻次越多,在文本集中出現越少,則越能夠表示目標文本的主題思想,從而作為目標文本的關鍵詞。其計算公式為
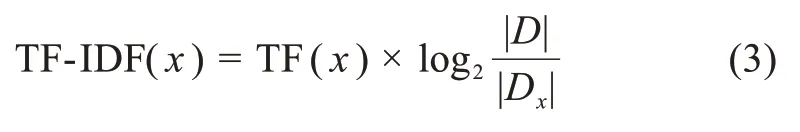
其中,TF(x)表示x在文本中的出現頻次。
但TF-ⅠDF指標不能很好地反映專利中具有新穎性和創造性的候選關鍵詞,如示例專利中反映創新性和新穎性的候選關鍵詞“前綴樹字典”的TF-ⅠDF值,低于候選關鍵詞“模板選擇 規則”。根據第3節權利要求特征的分析,本文提出特指度(specific degree,SD)度量候選關鍵詞被特指詞特指的次數,并將特質度信息融入候選關鍵詞權重之中,形成TF-ⅠDF-SD候選關鍵詞權重指標:
TF-ⅠDF-SD=TF-ⅠDF(x)×(SD(x)+1) (4)
在示例專利中,“前綴樹字典”“神經網絡模型”和“實體字典”等候選關鍵詞具有較高的特指度,使得其TF-ⅠDF-SD權重值大于候選關鍵詞“模板 選擇 規則”“實體 標簽”的TF-ⅠDF-SD值。
5 實驗
5.1 數據
目前,由于沒有正式公開的專利關鍵詞標注數據集,本文的實驗從國家知識產權局網站分別檢索主題為“命名實體識別(named entity recognition,NER)”的計算機領域相關中文發明專利和主題為“納米”的化學領域相關中文發明專利,分別隨機下載1500篇作為目標專利。以“命名實體識別”和“納米”為相關主題分別隨機下載20000篇專利作為輔助數據集。每個數據集的目標專利分別由3位領域專家獨立人工標注5~10個關鍵詞,使用兩兩交集作為目標文本最終關鍵詞標注結果[31-32],并對人工標注結果使用kappa值進行評測,兩個數據集上的kappa得分均大于0.8,當kappa值超過0.8則被認為數據集標注是有效的[33]。數據集信息如表4所示。
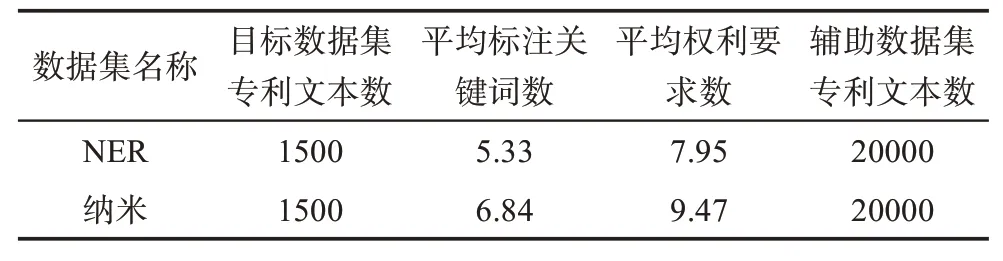
表4 數據集信息
5.2 步驟與評估指標
本實驗采用結巴分詞工具[34]對實驗數據進行分詞與詞性標注,使用哈爾濱工業大學停用詞表[35]去除停用詞等進行預處理工作,對目標專利進行候選關鍵詞選取,再利用輔助數據集,計算信息增益比,去除冗余候選關鍵詞,并計算候選關鍵詞權重。對抽取的專利關鍵詞使用準確率(precision,P)、召回率(recall,R)和F值(F1-score,F)進行評估,計算公式為


5.3 結果
5.3.1 基于最長公共子串的候選關鍵詞選取評估
實驗首先評估基于最長公共子串的候選關鍵詞生成方法。為此,通過實驗比較表5所示的兩種關鍵詞抽取方法。

表5 兩種候選關鍵詞選取方法的比較
實驗結果如圖3所示。從圖3可知,在兩個數據 集 中,LCS+TF-ⅠDF方 法 的P、R和F值 均 高 于Rule+TF-ⅠDF方法。在NER數據集中,LCS+TF-ⅠDF方法的P、R和F值比Rule+TF-ⅠDF方法分別高7%、8%和7.5%;在納米數據集中,LCS+TF-ⅠDF方法的P、R和F值比Rule+TF-ⅠDF方法分別高6%、8%和7.2%。實驗結果表明,使用最長公共子串方法比基于規則的方法生成的候選關鍵詞具有更好的候選關鍵詞生成結果。
5.3.2 基于信息增益比的冗余候選關鍵詞去除評估
實驗評估了基于信息增益比去除冗余候選關鍵詞的有效性。為此,通過實驗比較如表6所示的兩種方法。
實驗結果如圖4所示。由圖4可知,兩個數據集結果類似。LCS+R+TF-ⅠDF的P、R和F值均高于LCS+TF-ⅠDF方 法。在 納米數 據集,P、R和F分 別提高了7%、6%和6.5%;在NER數據集,P、R和F分別提高了8%、5%和6.3%。LCS+R+TF-ⅠDF比LCS+TF-ⅠDF增加了去除冗余候選關鍵詞的步驟,表明通過去除冗余關鍵詞可以提高關鍵詞抽取的準確率、召回率和F值。
表7列出了示例專利中使用兩種方法抽取的關鍵詞,其中人工標注關鍵詞使用粗體表示。由表7可知,如果不去除冗余候選關鍵詞,一些冗余候選關鍵詞會具有較高的TF-ⅠDF,如“基于 最大 熵”“最大熵模型”等,造成錯誤抽取。而通過去除冗余候選關鍵詞,可以使得其他正確關鍵詞有機會被正確抽取,從而提高關鍵詞抽取的準確性。
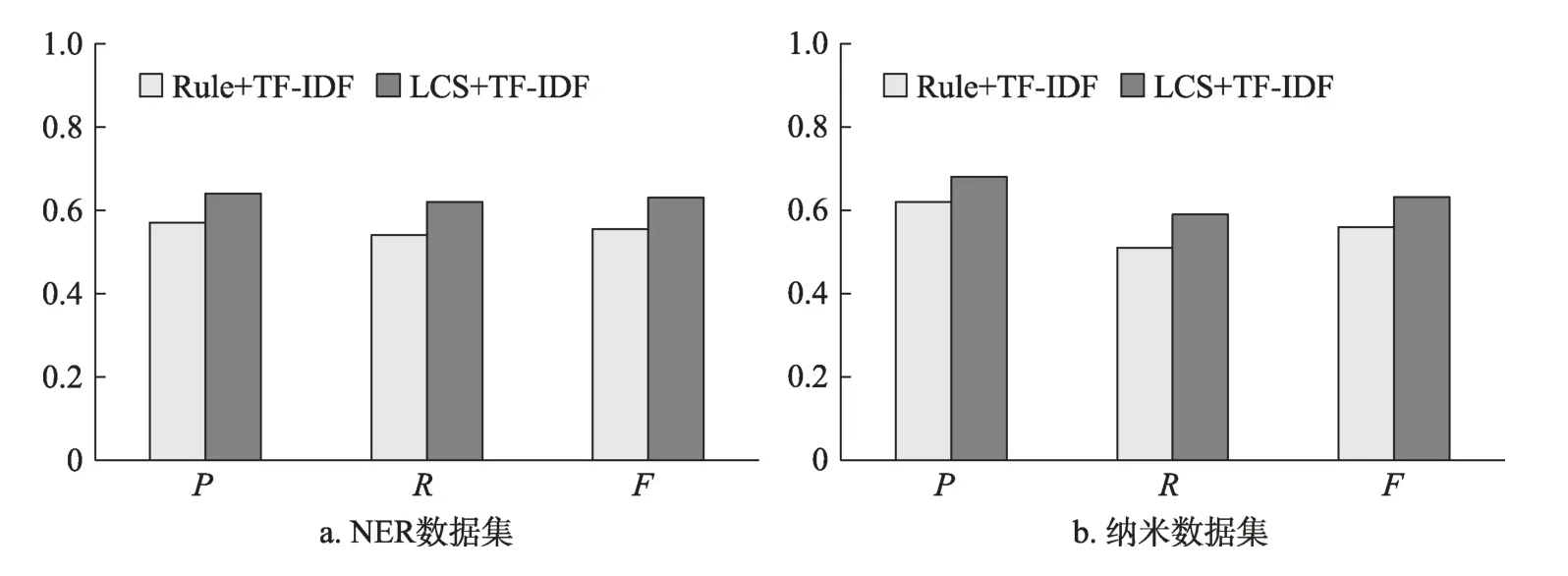
圖3 候選關鍵詞選取方法比較結果

表6 兩種去除冗余候選關鍵詞方法的比較
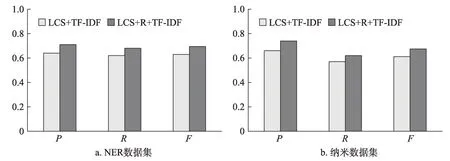
圖4 基于信息增益比去除冗余候選關鍵詞有效性評估結果
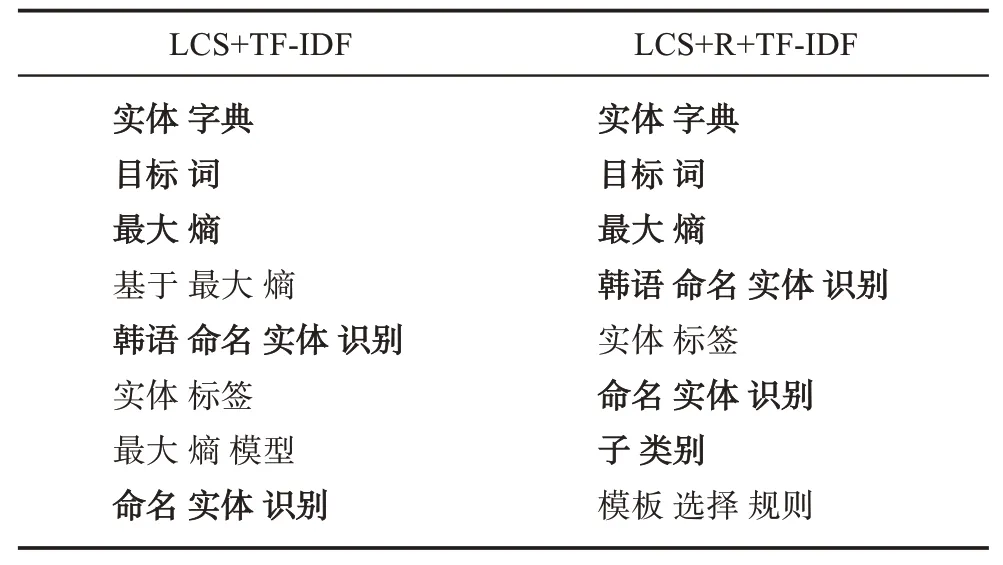
表7 示例專利基于信息增益比去除冗余候選關鍵詞有效性評估
5.3.3 融入特指度的候選關鍵詞權重評估
實驗評估了融入特指度的候選關鍵詞權重有效性。為此,通過實驗比較如表8所示的兩種方法。
圖5為兩種方法比較結果。由圖5可知,在兩個 數 據集 中,LCS+R+TF-ⅠDF-SD方 法 的P、R和F值均高于LCS+R+TF-ⅠDF的P、R和F值。其中,在NER數據集中,LCS+R+TF-ⅠDF-SD方法的P、R和F較LCS+R+TF-ⅠDF提高了6%、5%和5.5%;在納米 數 據集 中,LCS+R+TF-ⅠDF-SD方 法 的P、R和F值較LCS+R+TF-ⅠDF提高了8%、5%和6.3%。LCS+R+TF-ⅠDF-SD方 法 相 較 于LCS+R+TF-ⅠDF方 法,在計算候選關鍵詞時融入了特指度特征SD,用于提高專利中被反復特指的候選關鍵詞的權重。實驗結果表明,該特征能夠有效地提高專利抽取的準確率、召回率和F值。
表9列出了示例專利使用兩種方法抽取的關鍵詞。由表9可知,通過在權重候選關鍵詞計算時添加特指度信息,可以提高反映專利創新性和新穎性的必要技術特征的候選關鍵詞權重,如“前綴樹字典”“神經網絡模型”和“實體字典”,從而提高專利抽取的準確性。

表8 兩種候選關鍵詞權重方法的比較
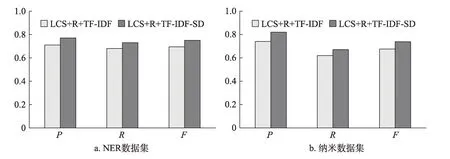
圖5 候選關鍵詞權重方法比較結果

表9 示例專利候選關鍵詞權重方法比較
5.3.4 與其他無監督關鍵詞抽取方法比較
實驗將本文提出的方法與常見的無監督關鍵詞抽取方法進行比較。欲比較的方法如表10所示。

表10 三種無監督關鍵詞抽取方法的比較
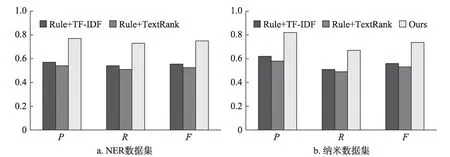
圖6 與其他無監督關鍵詞抽取方法比較結果
實驗結果如圖6所示。由圖6可知,兩個數據集中,Ours方法均獲得了最高的P、R和F值。在NER數據集中,Ours方法的P、R和F值比Rule+TF-ⅠDF分別 提高 了20%、19%和19.5%;比Rule+TextRank方法分別提高了23%、22%和22.5%;在納米數據中,Ours方法的P、R和F值比Rule+TF-ⅠDF方法分別提高了20%、16%和17.8%;比Rule+TextRank方法提高了24%、18%和20.6%。實驗結果表明,本文提出的專利關鍵詞抽取方法具有有效性。通過專利關鍵部分權利要求特征的分析,利用權利要求特征,采用最長公共子串選取候選關鍵詞、基于信息增益比去除冗余候選關鍵詞,以及在TF-ⅠDF方法中融入特指度信息,能夠有效提高專利關鍵詞抽取的準確率、召回率和F值。
表11為示例專利使用3種方法抽取的關鍵詞,其中人工標注的關鍵詞使用粗體表示。由表11可知,使用本文提出方法抽取的關鍵詞的準確率明顯高于傳統的無監督關鍵詞抽取方法,表明本文提出方法的有效性。
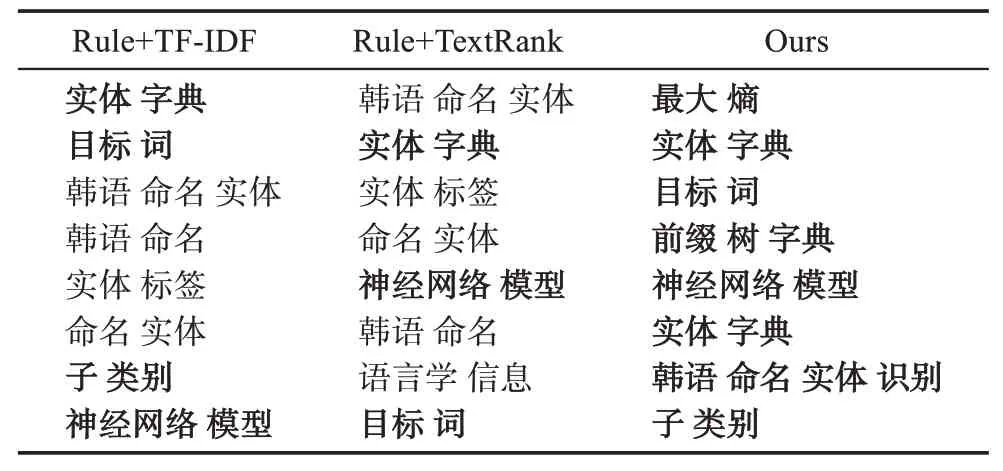
表11 示例專利與其他無監督關鍵詞抽取比較
5.3.5 與有監督關鍵詞抽取方法比較
實驗將本文提出的關鍵詞方法與一些有監督關鍵詞抽取方法進行比較,數據集按照5∶1隨機分為訓練集與測試集,進行交叉驗證。欲比較的方法為:
(1)NB[4]:使用詞性規則匹配[3]選取候選關鍵詞,使用樸素貝葉斯模型,選擇TF-ⅠDF特征和候選關鍵詞首詞出現的位置特征。
(2)SVM[6]:使用詞性規則匹配[3]選取候選關鍵詞,使用支持向量機模型,選擇與NB方法一樣的特征,核函數參數為RBF。
(3)BiLSTM+CRF[11]:使用word2vec模型中的skip-gram模型訓練詞向量,使用BiLSTM網絡,得到包含前后文本序列的雙向表達,通過CRF預測最終的標簽序列。定義B、M、E和O作為標簽集合,其中B表示關鍵詞的開頭、M表示關鍵詞的中間、E表示關鍵詞的結尾、O表示其他。預訓練的詞向量大小為200維,學習速率為0.001,BiLSTM模型層數為2,隱藏層為128,激活函數為tanh。
(4)Ours:本文提出的無監督關鍵詞抽取方法。
實驗結果如圖7所示。由圖7可知,在兩個數據集中,本文提出方法的P、R和F值均取得了最高值。在NER數據集中,Ours方法的P、R和F值比NB方法分別提高了15%、15%和15%;比SVM方法提高了13%、12%和12.5%;比BiLSTM+CRF-1方法分別提高9%、11%和10.1%。在納米數據集中,本文提出的方法比NB方法分別提高14%、11%和12.3%;比SVM方 法 提 高15%、9%和11.6%;比BiLSTM+CRF方 法 提 高12%、6%和8.6%。實驗結果表明,本文提出的方法通過利用專利權利要求的特征,可以獲得比有監督方法更好的關鍵詞抽取準確率、召回率和F值,且相比于有監督方法,本文提出的方法更加簡單可行,具有更高的可行性和實用性。
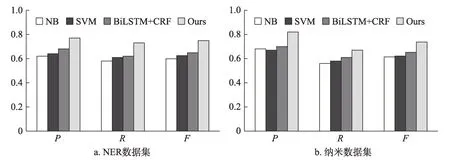
圖7 與有監督關鍵詞抽取方法比較結果
表12列出了示例專利與有監督關鍵詞抽取方法的比較。由表12可知,在NB和SVM方法中,候選關鍵詞首次出現的位置特征以及TF-ⅠDF特征對關鍵詞抽取起到了重要作用。然而,在考慮這些特征屬性時,很多錯誤緣于這些特征值較高,但本身并不是關鍵詞的候選關鍵詞,而BiLST+CRF則與訓練集數據選取有較大關系。相比而言,利用權利要求特征的關鍵詞抽取方法則更具有針對性,簡單易行,具有更好的關鍵詞抽取效果。
6 結論
專利關鍵詞是表明專利文獻主題內容的一組詞或者短語,被廣泛應用于專利分析之中。目前,專利關鍵詞抽取主要依據通用文本關鍵詞抽取方法,沒有充分利用專利特征,專利關鍵詞抽取的結果準確性仍有較大提升空間。專利文本既是一種技術文獻,也是一種法律文書,具有嚴密獨特的邏輯表述。因此,本文著眼于分析專利權利要求特征,并利用專利權利要求特征,提出一種權利要求特征驅動的專利關鍵詞抽取方法,以提高專利關鍵詞抽取的準確性。具體地,方法包括預處理、基于最長公共子串的候選關鍵詞選取、基于信息增益比的冗余候選關鍵詞去除和融入特指度的候選關鍵詞權重4個主要步驟。實驗結果表明,本文提出方法具有可行性與有效性。
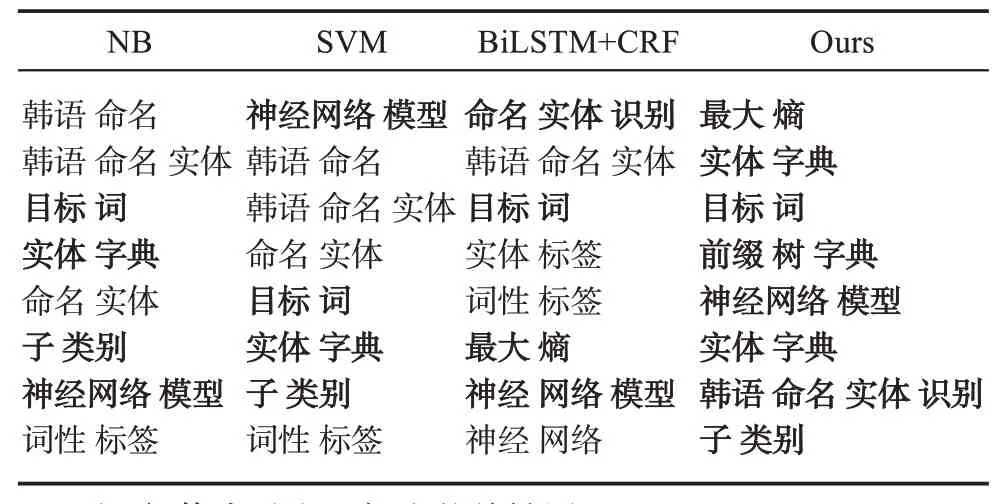
表12 示例專利與有監督關鍵詞抽取方法比較
在實驗中,本文所提出的方法存在一定的局限,主要體現在無法正確選取一些包含特殊字符的候選關鍵詞,如“2,2′-聯吡啶”。此外,在計算特指度時,由于語言描述的靈活性,目前的特指度指標還不夠精準,無法正確評估一些候選關鍵詞的特指度,這將是本課題組后續研究的重點。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
