基于改進粒子群算法的輪胎模型參數兩級辨識
2021-07-12 04:38:52張麗霞劉家琪潘福全張文彩鄭超藝
科學技術與工程 2021年16期
張麗霞, 劉家琪, 潘福全, 張文彩, 鄭超藝
(青島理工大學機械與汽車工程學院, 青島 266525)
計算機仿真技術在車輛領域廣泛應用,為提高分析速度,仿真分析整體模型中的部分復雜模型常采用經驗模型進行替代,因此對經驗模型的辨識速度和辨識精度有了越來越高的要求,對辨識方法的研究也顯得尤為重要。Cabrera等[1]利用協同進化算法對輪胎參數進行辨識,該方法同樣存在對初值敏感的問題。宋曉琳等[2]利用帶變異閾值的粒子群算法對PAC89(Pacejka’89 tyre model)輪胎模型直接進行參數辨識,其中縱向力辨識結果較差,均方根值在1 000以上。王前等[3]采用一種新型的自適應差分進化算法對魔術公式輪胎模型進行辨識,解決了差分算法控制參數為定值的問題,辨識結果較好,但算法收斂時的迭代次數較多,計算時間長。田煒等[4]利用Excel Solver對航空器拖車的輪胎模型進行了參數辨識。邊偉等[5]利用遺傳算法對魔術公式輪胎模型分兩級進行辨識,然而在辨識過程中,魔術公式的水平和豎向偏移被忽略,無法體現外傾角變化和簾線效應對輪胎力學特性的影響。趙凱旋等[6]利用遺傳算法對汽車懸架阻尼可調減振器進行參數辨識,適應度值均小于10,辨識結果較好,且通過實驗對比,驗證模型準確性。Liu等[7]采用逆向遺傳算法對不同充氣壓力下的輪胎參數進行辨識,遺傳算法魯棒性強,但收斂速度慢,辨識耗時長。Matsubara等[8]提出一種基于迭代聯立方程的三維柔性環模型的辨識方法。Lee等[9]結合智能輪胎內傳感器測量的信息,提出一種柔性化輪胎模型實時辨識與預測的方法。吳碧巧等[10]利用分層型免疫協同進化粒子群算法對雙饋異步電機進行參數辨識,實現電機中高度非線性系統的辨識工作,結果表明其策略有很好的全局收斂性。陳鼎等[11]通過廣義牛頓拉夫森算法對輪胎接地相互作用模型進行了參數辨識。
輪胎作為與地面直接接觸的汽車部件,對整車的操縱穩定性有重要影響。然而由于輪胎的主要材料是超彈性橡膠材料,將輪胎完整的加入整車操縱穩定性仿真分析中時,對計算機性能要求較高,分析速度較慢。因此,在對汽車操縱穩定性進行仿真或輪胎智能控制系統的研究時,通常需要合理的輪胎數學模型來描述輪胎的力學特性。PAC89輪胎模型利用三角函數形式的公式描述了輪胎縱滑特性和側偏特性,是一種經驗模型,適用于低頻路面下的穩態工況,在車輛操縱穩定性研究中被廣泛應用。因此快速準確的PAC89輪胎模型參數辨識對整車操縱穩定性能分析有重要意義。
所辨識的PAC89輪胎模型具有參數多和高度非線性的特點,這是導致辨識速度慢和辨識精度差的主要原因。因此,提出一種采用加入自適應權重和自然選擇性的改進粒子群算法分兩級進行輪胎參數辨識的PAC89輪胎模型辨識方法。將改進的粒子群算法與兩級辨識相結合,發揮兩者的優點,快速得到準確的輪胎模型,并以側偏力辨識為例,通過迭代次數和辨識精度驗證該辨識方法的優越性。
1 PAC89輪胎模型
PAC89輪胎模型是魔術公式輪胎模型的早期版本,因其在操縱穩定性研究中能夠快速、準確地表達輪胎力學特性而被廣泛采用。圖1為PAC89輪胎模型的輸入輸出。
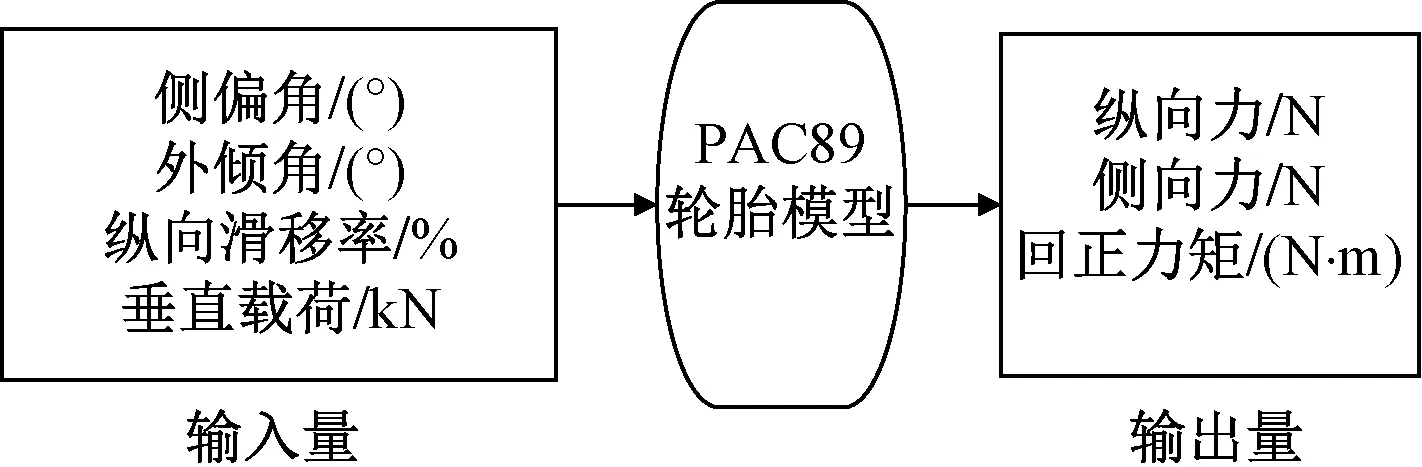
圖1 PAC89輪胎模型Fig.1 The PAC89 tire model
PAC89輪胎模型的魔術公式基本表達式為[12]
(1)
式(1)中:Y(X)表示縱向力、側偏力和回正力矩,相對應的x表示滑移率和側偏角;B為剛度因子,受曲線原點處斜率影響;C為形狀因子,控制曲線形狀;D為峰值因子,受曲線峰值影響;E為曲率因子,影響曲線的曲率;Sv為垂直偏移量;Sh為水平偏移量,由于簾線效應和外傾角等原因,兩個偏移量一般不為零,即曲線不過原點。
以PAC89輪胎模型的側偏力魔術公式辨識為例進行研究分析。側偏力魔術公式為
(2)
(3)
(4)
C=a0
(5)
(6)
E=a6Fz+a7
(7)
Sh=a8γ+a9Fz+a10
(8)
Sv=a11Fzγ+a12Fz+a13
(9)
式中:Fy為側偏力;x為側偏角;BCD為側偏力零點處側偏剛度;Fz為垂直載荷;γ為輪胎外傾角;a1~a13為待辨識的二級參數。PAC89輪胎模型側偏力辨識需要有至少3組不同載荷和外傾角下的實驗數據為依據。采用205/55R16半鋼子午線輪胎在不同載荷和外傾角下進行了3次側偏角到達12°的輪胎純側偏工況實驗,依據實驗結果辨識該半鋼子午線輪胎的PAC89輪胎模型。3次實驗的條件如表1所示,實驗結果曲線如圖2所示。

表1 半鋼子午線輪胎實驗Table 1 Experiment of semi-steel radial tire
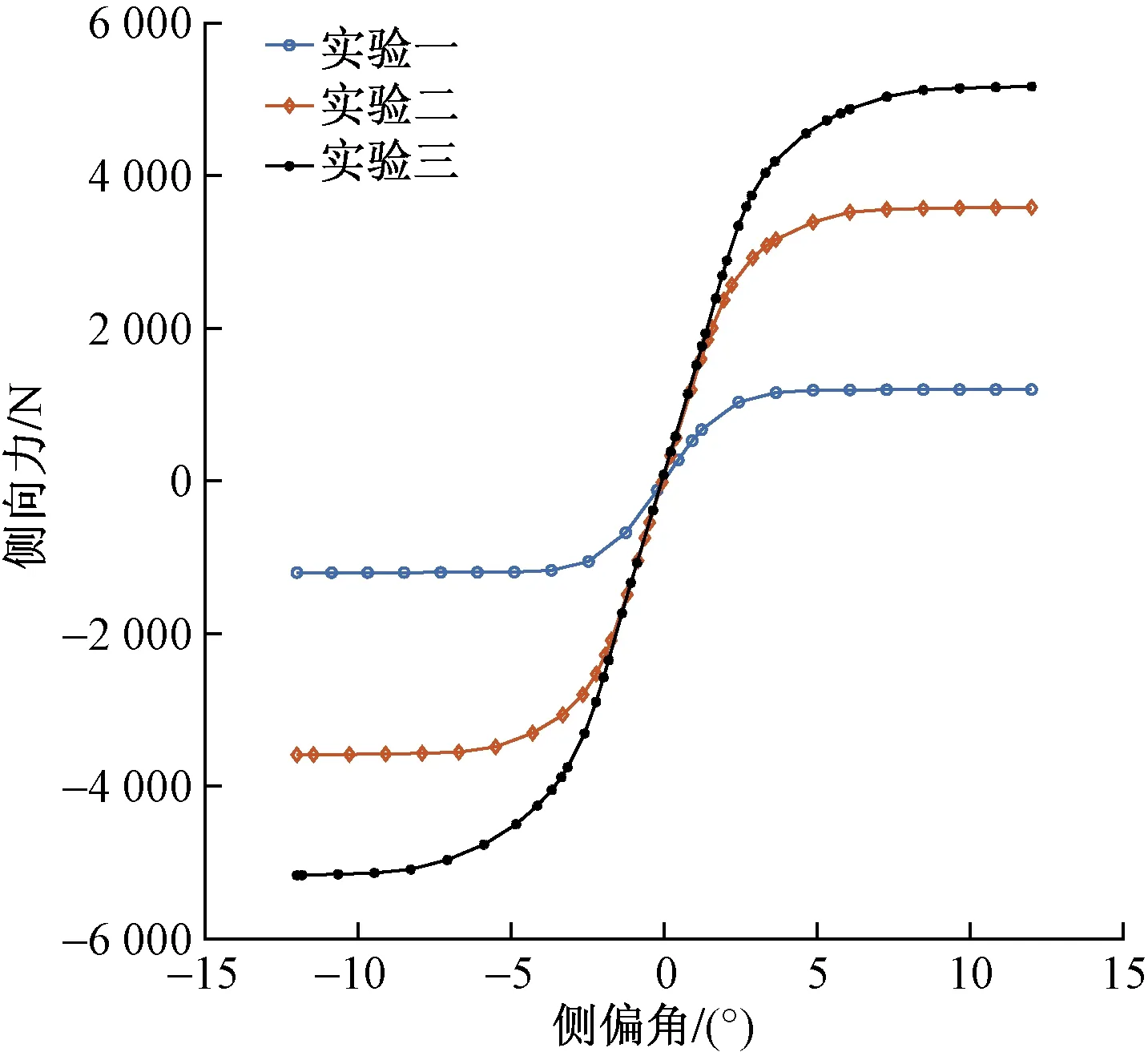
圖2 側偏力實驗曲線Fig.2 Experimental curve of lateral force
2 基于改進粒子群算法的兩級辨識
2.1 改進粒子群算法
粒子群算法將初始粒子群隨機地分布在空間內,通過模擬種群覓食的行為規律,根據群體和自身經驗來尋找整個空間中的最優解[13]。圖3為粒子位置更新過程。

圖3 粒子位置更新過程Fig.3 Particle position update process
如圖3所示,t時刻下的第i個粒子擁有速度vi(t)和位置xi(t)這兩個基本信息,以及個體最優位置pi(t)這一歷史信息,并能通過與其他粒子交流獲取當前全局最優位置g(t)的信息。然后粒子根據個體和全局最優位置不斷改變速度的大小和方向,來更新自身位置。在N維空間內,粒子的各信息均以n維向量的形式存在,第i個粒子通過式(10)、式(11)更新自己在第n維的信息,可表示為
vin(t+1)=wvin(t)+c1r1[pin(t)-xin(t)]+c2r2[gn(t)-xin(t)]
(10)
xin(t+1)=xin(t)+vin(t+1)
(11)
式中:n為維度,n=1,2,…,N;xin為第i個粒子在第n維的位置;vin為第i個粒子在第n維的速度;gn為第n維全局最優位置;pin為第i個粒子在第n維的最優位置;w為慣性的權重因子,c1、c2為學習因子;r1、r2為[0,1]的隨機數,稱為種子數。其中慣性權重因子和學習因子的設置對算法性能有很大影響。
2.1.1 自適應權重
慣性權重因子對粒子群算法搜索最優解的能力有很大影響,慣性權重因子較大時,粒子群算法的全局搜索能力強,搜索速度快,但搜索結果精確度低;慣性權重因子較小時,粒子群算法的搜索結果精確度高,但搜索速度慢,且更容易陷入局部最優解。
自適應權重能夠依據收斂程度和適應度值自動調整慣性權重因子大小,當適應度值小于平均適應度值時[14]有
(12)
當適應度值大于平均適應度值時有
w=wmax
(13)
式中:w為慣性權重因子;wmin為慣性權重因子的最小值;wmax為慣性權重因子的最大值;f為當前適應度值;favg為平均適應度值;fmin為最小適應度值。
自適應權重的加入使得算法能夠更好地平衡全局與局部搜索的能力,提高了算法的性能。
2.1.2 自然選擇
基本粒子群算法隨迭代次數的增加,陷入局部最優解的可能也逐漸增大[15]。為解決這一問題,將源自遺傳算法的自然選擇機制引入粒子群算法。
自然選擇發生在迭代過程的末尾,粒子每次更新位置后,將所有粒子按照適應度值排序,根據適應度值篩選出粒子群中1/2的粒子,用較好的1/2粒子的速度和位置替換較差的1/2粒子的速度和位置,并保留個體最優位置的信息。
自然選擇的加入提高了粒子群算法對搜索區域信息的利用率,因此改善了搜索性能,降低了陷入局部最優解的可能。
2.2 輪胎側偏力參數辨識
2.2.1 側偏辨識目標函數
目標函數應使得辨識曲線與實驗曲線之間的差值最小,輪胎參數辨識的目標函數為
(14)
式(14)中:xi為側偏角;YPAC89(xi)為通過魔術公式計算得到的側向力;YTest(xi)為通過實驗得到的側向力或回正力矩。通過算法尋優,使Z為最小值。
2.2.2 兩級參數辨識
將改進的粒子群算法寫入MATLAB,根據PAC89輪胎模型側偏力魔術公式,將B、C、D、E、Sh、Sv作為一級參數,通過一級辨識得到,組成一級參數的a0~a13為二級參數,通過二級參數辨識得到。輪胎模型的側偏力魔術公式參數辨識流程如圖4所示。
圖4中,先對3組實驗進行一級辨識,然后綜合三組實驗的一級辨識的參數,進行二級辨識。二級辨識中,BCD需要根據式(3)進行計算,因此組成BCD的a3、a4、a5單獨進行辨識,其他二級參數一同辨識。
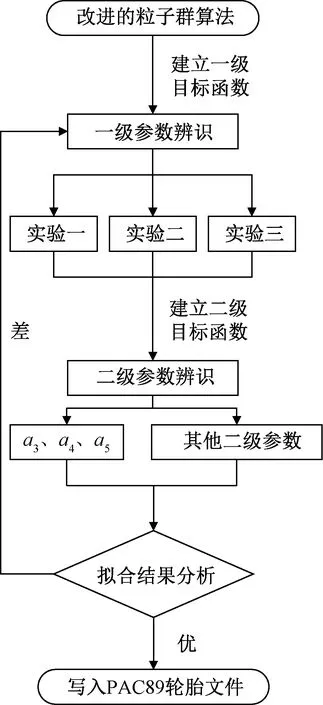
圖4 參數辨識流程Fig.4 Parameter identification process
兩級辨識中粒子群均采用相同的初始設置,其中粒子數目設置為1 000;兩個學習因子均設置為2;最小慣性權值為0.4;最大慣性權重值為1;最大迭代次數為300。
3 辨識結果分析
3.1 一級辨識結果
一級辨識的目標函數單一且復雜,并分3組進行,3組均收斂才可以進行二級辨識,因此一級辨識對整個輪胎辨識工程中的辨識速度有較大影響。圖5為3組實驗一級辨識的迭代曲線,對6個一級參數的辨識中,實驗一在38次迭代后收斂,實驗二在35次迭代后收斂,實驗三在迭代34次后收斂。說明輪胎參數的一級辨識速度很快。

圖5 一級辨識迭代曲線Fig.5 First order identification of iterative curve
一級辨識得到的參數辨識結果會作為二級辨識的基礎數據被應用,因此一級辨識精度對二級辨識的收斂速度和最終輪胎模型精度有很大影響。為更好研究模型擬合效果,引入相對殘差作為辨識精度評價指標[5],其表達式為
(15)
式(15)中:G為相對殘差;SSE為殘差平方和;Ib為某點的實驗數據;n′為各實驗中實驗測試點的總數。一級參數辨識結果如表2所示,辨識曲線如圖6所示。
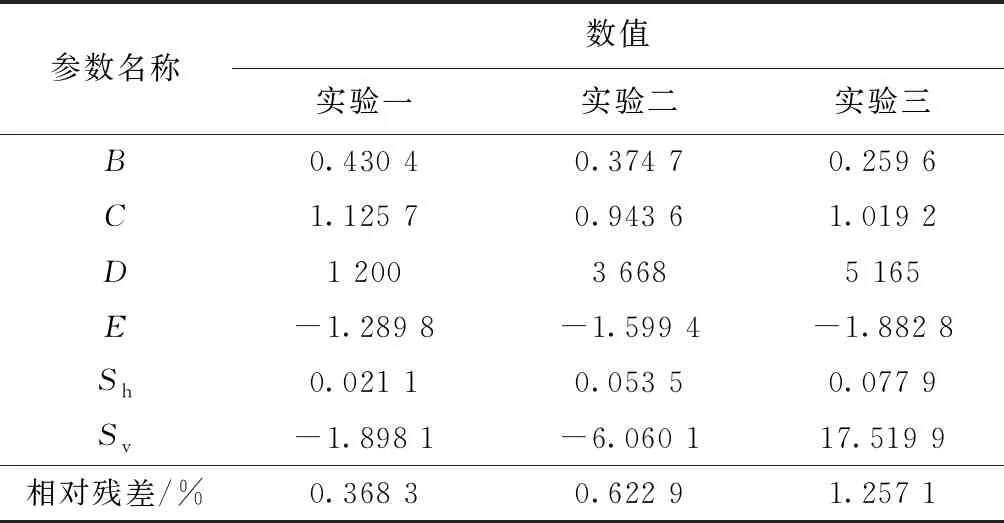
表2 一級參數辨識結果Table 2 First order parameter identification results
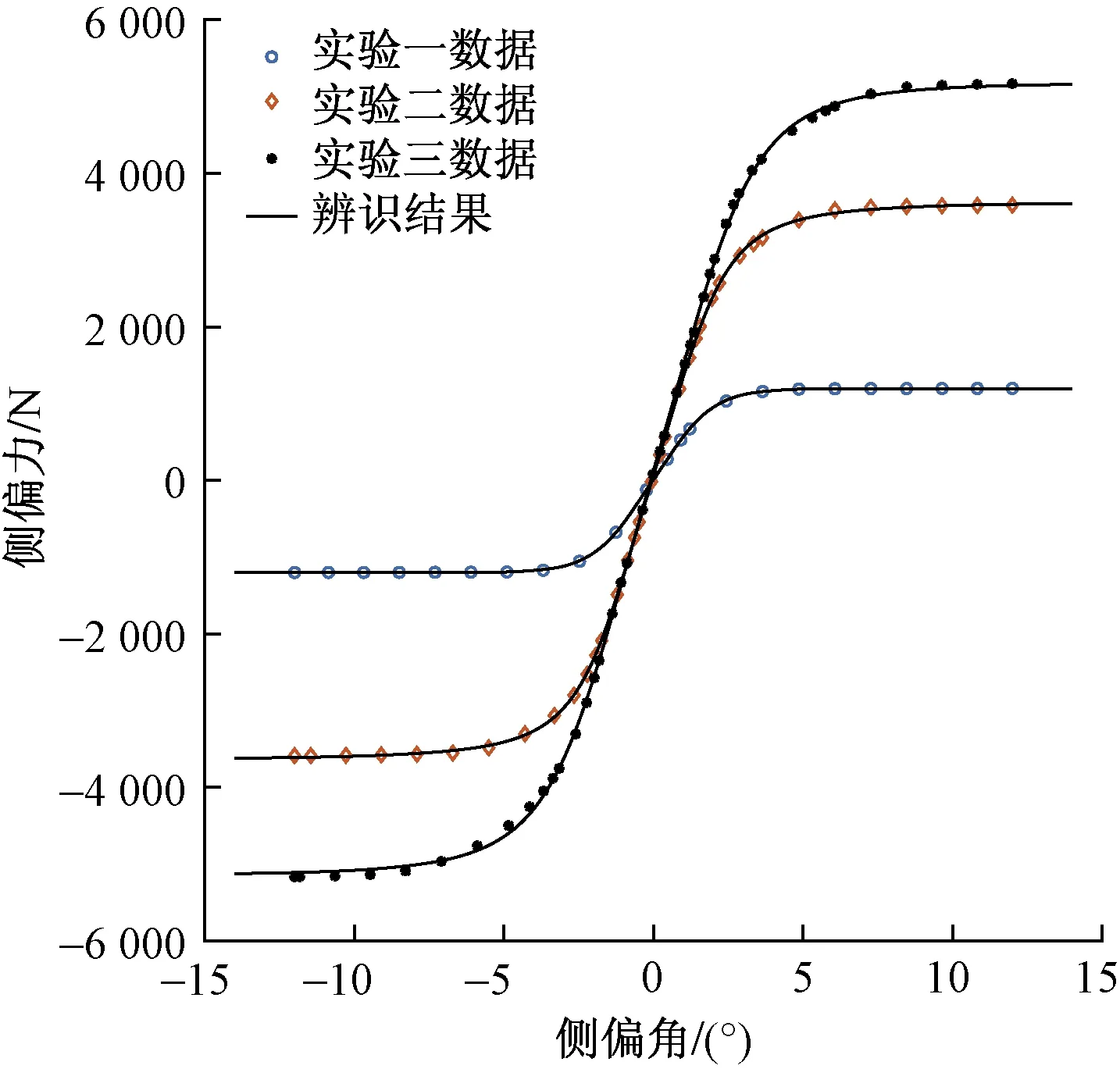
圖6 一級辨識結果Fig.6 First order identification result
如圖6所示,實驗數據與辨識曲線吻合情況良好,辨識結果與3組實驗的相對殘差分別為0.368 3%、0.622 9%、1.257 1%,3組實驗平均相對殘差為0.749 4%,相對殘差越小,說明辨識精度越高,輪胎一級辨識整體精度符合二級辨識的要求。
3.2 二級辨識結果
側偏力二級辨識共辨識14個參數,這14個參數也是最終組成PAC89輪胎模型側偏力部分的參數,因辨識參數較多,相較于一級辨識,收斂速度更慢,需要更長的辨識時間。圖7為三組實驗二級辨識的迭代曲線,其中a3、a4、a5在迭代10次左右便收斂,其他11個二級參數的辨識在迭代100次左右便收斂,迭代速度略慢于一級辨識。

圖7 二級辨識迭代曲線Fig.7 Second order identification of the iterative curve
二級辨識的參數作為最終的輪胎模型參數,其辨識精度便是PAC89輪胎模型的辨識精度。二級參數辨識結果如表3所示,辨識曲線如圖8所示。

表3 二級參數辨識結果Table 3 Second order second order parameter identification results
如圖8所示,實驗數據與PAC89輪胎模型曲線的吻合情況良好,PAC89輪胎模型與實驗數據的相對殘差分別為2.345 1%、1.470 1%,1.273 0%,平均相對殘差為1.696 1%,辨識精度高。
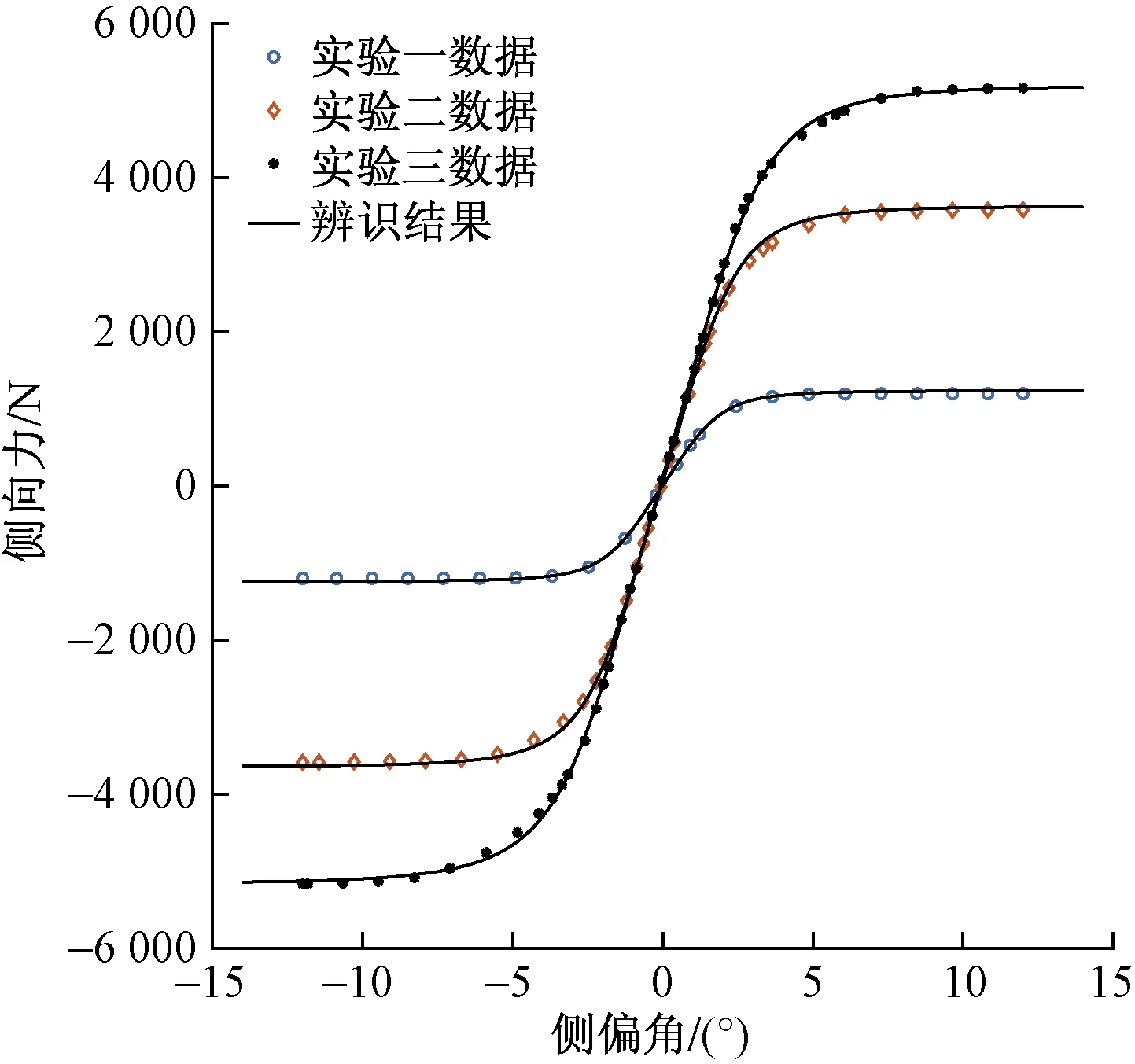
圖8 二級辨識結果Fig.8 Second order identification result
4 結論
(1)改進粒子群算法結合參數分級,對PAC89輪胎模型進行了兩級辨識。其中,一級辨識在迭代40次以內便收斂,且平均辨識精度為0.749 4%,辨識準確。與文獻[5]相比,本文方法在所需辨識參數更多的情況下,有與文獻[5]相當的辨識速度,以及更高的辨識精度。
(2)在對側偏力的二級辨識中辨識了完整的14個特性參數,包括由于外傾角和簾線效應等原因造成的曲線水平和豎直偏移,因此二級辨識在迭代100次左右收斂,通過與三組實驗數據比對,PAC89輪胎模型側偏力曲線的平均辨識為1.696 1%。
(3)辨識結果表明,采用改進粒子群算法分兩級進行辨識的方法能夠快速、準確地得到PAC89輪胎模型的辨識結果,有利于縮短仿真研究周期并為智能輪胎研究中所需的實時參數辨識提供支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
