早期糖尿病風險預測模型的比較研究
2021-07-11 18:44:26王成武晏峻峰
智能計算機與應用 2021年1期
王成武 晏峻峰


摘?要:糖尿病是一種比較常見的慢性疾病,并且存在較長的無癥狀階段。本文主要介紹了機器學習中的5種分類算法,分別是樸素貝葉斯、支持向量機、邏輯回歸、決策樹和集成分類器Random Forest,并在Weka數據挖掘平臺上,對糖尿病數據進行挖掘分析,根據混淆矩陣、Kappa系數、ROC曲線、均方根誤差以及相對絕對誤差這幾個性能指標對分類器效果進行分析,找到最適合糖尿病疾病預測的算法,為當今醫療行業其他疾病數據的挖掘分析提供思路。
關鍵詞: 糖尿病;機器學習;集成分類器;數據挖掘;Weka
文章編號: 2095-2163(2021)01-0064-05 中圖分類號:TP391 文獻標志碼:A
【Abstract】Diabetes is a relatively common chronic disease, and there is a long asymptomatic stage. This article mainly introduces five classification algorithms in machine learning, which are Naive Bayes, Support Vector Machine, Logistic Regression, Decision Tree, and Random Forest, an integrated classifier. On the Weka data mining platform, the diabetes data is mined and analyzed. The effect of the classifier is analyzed according to the confusion matrix, Kappa coefficient, ROC curve, root mean square error and relative absolute error, and the most suitable algorithm for diabetic disease prediction is achieved, which could provide ideas for the current medical industry data mining.
【Key words】diabetes; machine learning; integrated classifier; data mining; Weka
0 引?言
糖尿病是一種終身疾病,可引發心臟病、血管疾病等并發癥[1],不僅影響了患者的生活質量,也會帶來相應的經濟負擔,所以進行早期糖尿病風險預測具有十分重要的意義。
作為重要的數據挖掘技術,機器學習等人工智能技術,在糖尿病預測與治療上應用得很多。例如,Purushottam等人[2]分別用C4.5算法和Partial Tree算法自動提取糖尿病預測規則來預測患者的糖尿病風險。Santhanam等人 [3]用遺傳算法對糖尿病數據集進行維數約簡并利用支持向量機進行了糖尿病的預測。胡瑋[4]基于改進鄰域粗糙集和隨機森林算法進行了糖尿病的預測研究。黃艷群等人[5]利用患者相似性建立了個性化糖尿病預測模型。
本文將機器學習技術應用在早期糖尿病風險預測數據集上,構建多種分類模型,通過各種性能評價指標對模型進行分析,選擇最優分類模型,該模型可通過評估癥狀來檢查用戶患糖尿病的風險。
1 基本原理及方法
1.1 實驗數據
本文選取的是UCI機器學習庫中的早期糖尿病風險預測數據集,共包含520個樣本,其中陽性樣本為320個,陰性樣本為200個,每條樣本數據包含16個特征屬性和一個類屬性,分別是:Age(年齡)、Gender(性別)、 Polyuria(多尿癥)、 Polydipsia(煩渴)、 sudden weight loss(體重減輕)、weakness(虛弱)、Polyphagia(多食癥)、Genital thrush(生殖器鵝口瘡)、visual blurring(視覺模糊)、Itching(瘙癢)、Irritability(煩躁)、delayed healing(延遲康復)、partial paresis(部分偏癱)、muscle stiffness(肌肉緊張)、Alopecia(脫發)、Obesity(肥胖)、class(類別)。
1.2 算法原理
1.2.1 樸素貝葉斯
樸素貝葉斯算法(Naive Bayes,NB算法)是常用的概率分類算法[6],樸素貝葉斯具有一些明顯的特征,例如計算的速度非常快、準確率高、方法簡單等特點,在一般貝葉斯理論的基礎上,樸素貝葉斯中的‘樸素一詞就是假定樣本中的屬性彼此獨立地對其產生影響,并不考慮屬性之間的依賴關系,在實際應用中對于大部分比較復雜的問題都是很有成效的。
基于屬性條件獨立性假設,在樣本分類任務中,計算樣本w所屬類別的概率P(c|w),計算方式為:
其中,n表示屬性個數,Wi表示樣本w在第i個屬性上的取值。P(w)在所有類別中都是相同的,因此在公式(1)的基礎上知樸素貝葉斯分類器的基本表達式:
1.2.2 支持向量機
支持向量機(Support Vector Machine, SVM)是一種常用的二分類模型[7],通過使用給定的樣本數據集進行建模,在樣本空間中找到一個最優的劃分超平面,該平面產生的分類結果是最具有魯棒性的,并且對未見示例有最好的泛化能力。SVM是針對線性可分情況進行分析的,對于非線性分類問題,可以通過核函數將低維樣本空間映射到高維特征空間,這樣高維特征空間即可采用線性算法對樣本的非線性特征進行線性分析。常用的核函數有以下幾種:
1.2.3 邏輯回歸
邏輯回歸(logistics regression)屬于監督學習方法,是一種廣義的線性回歸分析模型,主要用于概率預測或分類。邏輯回歸最基本的學習算法是極大似然,即假設數據是伯努利分布,通過極大似然函數來推導損失函數,使用梯度下降來求解參數,以此來對數據進行二分類。邏輯回歸中常用建模函數的數學表達式如下:
其中,?f(x)指觀測個體患上糖尿病的概率,是一個Sigmoid函數;x1,x2,…,x16是糖尿病數據集的16個特征屬性;θ是權重參數。將Sigmoid函數與線性回歸兩者結合,使最終預測概率的值處于0~1之間:若大于0.5,將其歸為Positive類;若小于0.5,則歸為Negative類。
1.2.4 決策樹J48
ID3算法中根據信息增益評估和選擇特征,每次選擇信息增益最大的特征作為判斷模塊建立子結點,使用信息增益的缺點是偏向于具有大量值的屬性,而且該算法不能夠處理連續分布的數據特征,于是就有了C4.5算法,在WEKA中稱為J48算法,該算法是在ID3 算法的基礎上進行改進而產生的[8],算法中包含ID3 算法的所有功能, 除此之外,還可以利用信息增益率來選擇屬性, 合并具有連續屬性值、處理含有未知屬性值的訓練樣本等。
1.2.5 隨機森林
隨機森林(Random Forest)是由Breiman提出的[9],是一種組合分類器,其基本單元就是決策樹。將決策樹作為個體學習器,加入了隨機樣本選擇和隨機特征選擇策略。對于本文而言,即隨機地從16個屬性特征中選擇m個屬性(m<16),并且使用有放回的抽樣策略從數據集中選取樣本。在新數據集上訓練決策樹,通過每棵決策樹的預測結果來決定測試樣本最終的預測結果。算法的整體流程如圖1所示。
1.3 性能指標
1.3.1 混淆矩陣
混淆矩陣可用來判斷分類器的優劣,詳見表1。所有評價指標具體定義如下。
1)精確率(Precision):預測結果為正例樣本中真實為正例的比例,公式如下:
(2)召回率(Recall):真實為正例的樣本中預測結果為正例的比例,公式如下:
(3)F:為精確率(Precision)和召回率(Recall)兩者的調和平均值,公式如下:
1.3.2 Kappa系數
Kappa系數是一種計算分類精度的方法,用于衡量模型預測結果和實際分類結果是否一致,其計算公式為:
其中,Pa為實際一致率,Pe為理論一致率。Kappa系數的取值在0~1之間,若Kappa≥0.75,則表明分類器的一致性很好。
1.3.3 ROC曲線
受試者工作特征曲線receiver operating characteristic curve,ROC曲線),用來比較2個分類模型有效性的可視化工具,AUC表示ROC曲線下的面積,取值在0.5~1之間。AUC可以直觀地評價分類器的好壞,值越大越好。
1.3.4 均方根誤差
均方根誤差(RMSE)是對樣本數據集抽樣誤差的度量,其數值越小表示模型越穩定。
1.3.5 相對絕對誤差
相對絕對誤差(RAE)是預測數值與實際數值兩者差的絕對值,數值越小則表明模型越優。
2 實驗結果與分析
使用WEKA數據挖掘平臺對6個分類器進行分析。在Test options欄目下選擇十折交叉驗證法,依此選擇分類算法進行實驗,其中SVM算法的核函數選用徑向基核函數。實驗產生的各性能指標的結果見表2和表3。
由表2分析可知,精確率(Precision)為預測出的真陽性病例在預測為陽性病例中的比例,召回率(Recall)為預測出的真陽性病例在實際真陽性病例中的比例,精確率和召回率是相互影響的,理想情況下是兩者都高,但一般情況下是精確率高,召回率就低;反之,召回率高,精確率就低。在各種疾病的監測研究中,一般采用的方法是在保證精確率的條件下,提升召回率。精度指標中的F值綜合了精確率和召回率,可以用來綜合評價實驗結果的質量。可以看出Random Forest的精確率、召回率和F值遠遠高于Naive Bayes、Logistics 等分類器。
在此基礎上,對表3所得實驗結果進行分析,可得各項指標的闡釋分述如下。
(1)分類器準確率(Accuracy):由表3中數據分析可知,在這5個分類器中,Random Forest算法對樣本分類的準確率最高,其次是J48算法,Naive Bayes算法的準確率較差,于是通過屬性約簡的方式來優化Naive Bayes算法的預測結果,即找出預測效果最好的屬性集,使用CfsSubsetEval屬性評估器和GreedyStepwise搜索方法進行屬性選擇,根據最終的屬性集進行實驗,得出Naive Bayes算法的準確率為0.88,相比之前的準確率略有提升,但還是遠不及其它分類器的預測結果。總地來說,集成分類器Random Forest的識別準確率要高于一般的單一分類器。
(2)Kappa系數比較(Kappa):若分類器與隨機一個分類器的分類結果全一致,則Kappa系數為 1,反之為0。所以Kappa系數越大,表明分類的效果越好。由表3中數據可以得知Random Forest算法的Kappa系數值最大,故該算法相比其它算法在此數據集上建立的模型更好。
(3)均方根誤差比較(RMSE):由表3中數據可知Random Forest算法和J48算法所建立模型運行產生的RMSE值是最低的兩個,其次是Logistics和SVM,兩者的結果較為相近,5種分類器中的Naive Bayes的RMSE值最大,效果最差。
(4)相對絕對誤差比較(RAE):由表3中數據可知SVM和J48的RAE值較為相近,預測結果相差不大,5種分類算法中Random Forest的RAE值最小,表明該模型最優,所預測的數據值最為貼近實際值。
(5)ROC曲線面積比較(ROC Area):曲線圖的橫縱坐標分別表示模型預測數據的假陽性率和真陽性率,ROC曲線越靠近縱軸,表示模型越好。5類預測模型ROC曲線圖如圖2~圖6所示。
由圖2~圖6可看出,Random Forest預測模型的ROC曲線最為靠近縱軸,所以該算法的建模效果最優,其次是Logistics預測模型。同樣地,該結果表明集成分類器的建模效果要高于一般的單一分類器。
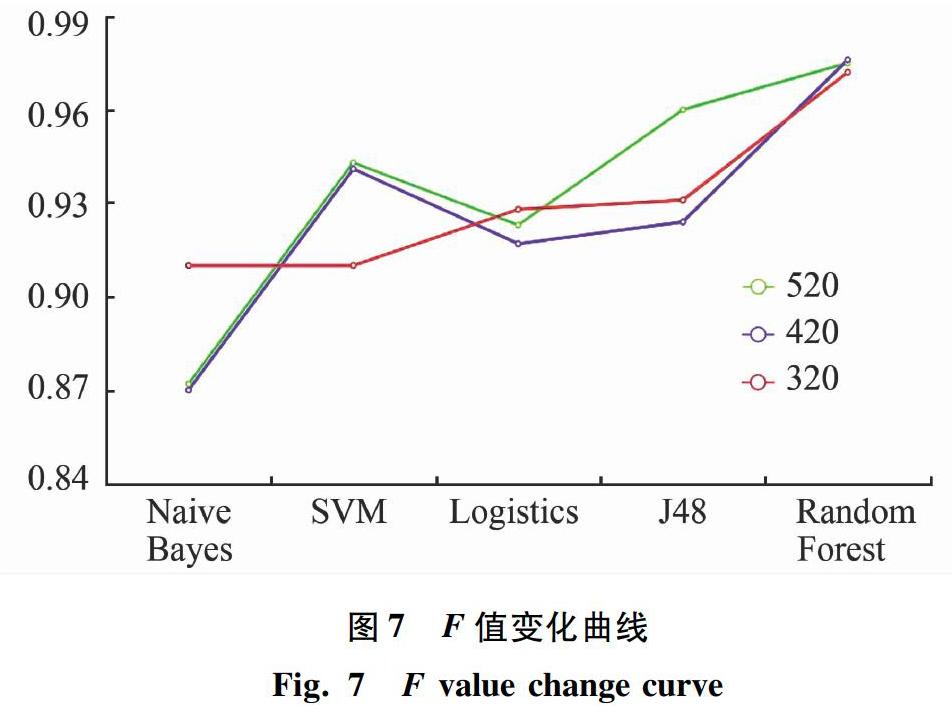
為了驗證這幾種模型在不同數據量的數據集上的表現是否具有一致性,分別隨機抽取320,420個樣本,重復以上實驗,選取F-Measure作為此次實驗中模型的性能評價指標,最終的訓練結果如圖7所示。
從圖7中可以看出,隨著數據集的減少,各模型的分類效果是有所變化的,在樣本數據集數量為320的時候,樸素貝葉斯算法的分類效果相比之前有較大的上升幅度,而支持向量機算法在數據集減少到320的時候分類效果相比之前有較大的下降幅度。數據集大小為520和420時,各模型分類效果的變化趨勢基本一致,而數量為320的時候Logistics的分類效果是勝于SVM算法的,但總地來說,不論數據集是多少,分類效果最優的還是集成分類器Random Forest。
3 結束語
本文基于WEKA數據挖掘平臺,使用5種分類算法對早期糖尿病風險預測數據集進行分析,并利用多種評價指標來確定分類效果。從實驗結果可以看出,集成分類器Random Forest在該糖尿病數據集上的分類效果最佳。故今后醫療行業其它疾病的預測,可根據實際情況,通過結合策略將多個單一分類器整合起來形成集成分類器,以此來提升模型的分類精度。
參考文獻
[1]劉月. 基于數據挖掘技術的2型糖尿病的預測與健康管理研究[D]. 秦皇島:燕山大學,2018.
[2]PURUSHOTTAM, SAXENA K, SHARMA R. Diabetes mellitus prediction system evaluation using C4.5 rules and partial tree[C]// 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions). Noida, India:IEEE, 2015:1-6.
[3]SANTHANAM T, PADMAVATHI M S. Application of K-means and genetic algorithms for dimension reduction by integrating SVM for diabetes diagnosis[J]. Procedia Computer ence, 2015, 47:76-83.
[4]胡瑋. 基于改進鄰域粗糙集和隨機森林算法的糖尿病預測研究[D]. 北京:首都經濟貿易大學,2018.
[5]黃艷群,王妮,張慧,等. 利用患者相似性建立個性化糖尿病預測模型[J]. 醫學信息學雜志,2019,40(1):54-58.
[6]KONONENKO I. Seminaive bayesian classifier[C]// Proc. of the 6th European Working Session on Learning. Berlin, Heidelberg:Springer, 1991:206-219.
[7]蘭欣,衛榮,蔡宏偉,等. 機器學習算法在醫療領域中的應用[J]. 醫療衛生裝備,2019,40(3):93-97.
[8]高海賓. 基于Weka平臺的決策樹J48算法實驗研究[J]. 湖南理工學院學報(自然科學版),2017,30(1):21-25.
[9]劉文博,梁盛楠,秦喜文,等. 基于迭代隨機森林算法的糖尿病預測[J]. 長春工業大學學報,2019,40(6):604-611.
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
信息通信技術(2015年6期)2015-12-26 01:16:46
