基于MapReduce并行關聯挖掘的網絡入侵檢測
2021-07-06 02:10:24徐勝超
計算機技術與發展 2021年6期
徐勝超,宋 娟,潘 歡
(1.廣東財經大學華商學院 數據科學學院,廣東 廣州 511300;2.寧夏大學 寧夏沙漠信息智能感知重點實驗室,寧夏 銀川 750021)
0 引 言
隨著計算機網絡的發展及新型網絡協議的出現,近年來各類網絡入侵攻擊行為持續增加,普通的數據挖掘算法已經不能滿足網絡入侵檢測的需求。作為數據挖掘的重要分支,關聯規則挖掘已經成為了研究熱點[1-4]。關聯規則算法中,很多都能夠產生頻繁項集,在這些關聯挖掘產生頻繁項集的過程中,連接數據庫和產生侯選項集的數目非常大,這樣將大大增加了關聯規則算法的時間代價,降低了效率。例如經典的Apriori算法增強了豐富的顏色到數據的分析與處理,其目的是為了發現不同的數據項在歷史交易數據庫中的關系,核心功能是通過重復掃描數據項,獲得頻繁項集和研究項集之間的關系。目前,Apriori算法和并行化的Apriori算法都得到了很大的改善[5-7]。
關聯規則模型中的Apriori算法主要應用在大量的歷史交易數據中,用來發現頻繁模式和數據項之間的關聯性。盡管如此,考慮到Apriori算法的固有的特點,當數據容量十分大的時候,它的缺點和不足體現得更加明顯,此時使用Apriori算法來分析和處理數據將變得非常消耗時間與內存空間,效率低下[8]。所以為了快速處理大容量數據,文獻[9]提出了基于Apriori算法的重要狀態確定方法來完成網絡入侵檢測。文獻[10]提出了改進的Apriori算法來完成頻繁模式樹的建立,將其應用到數據挖掘領域。
針對早期的低效率的傳統Apriori算法而言,要處理網絡入侵檢測的海量大數據,目前比較常見的是Hadoop分布式計算框架。同時改進早期經典的Apriori算法,建立新的框架用來處理頻繁項集的挖掘的并行Apriori算法,用來加快計算速度,節省內存空間。該文提出的基于MapReduce云計算的并行關聯挖掘的網絡入侵檢測方法Cloud-Apriori就是基于這個思路。Cloud-Apriori的實驗通過構造Hadoop集群來完成。實驗結果表明改進的并行Apriori算法具有很高的檢測精度和更少的運行時間,提高了網絡入侵檢測效率。
1 Hadoop框架分析
1.1 分布式框架
文中關聯挖掘的網絡入侵檢測采用了Hadoop云計算平臺,這樣可以并行處理頻繁項集,以進一步提高大數據處理的速度與效率[11]。
Hadoop是一種開源并行大數據處理的總體支撐平臺,一般基于MapReduce的并行算法中采用了6個步驟來表示任務流Job stream的流程情況。每個任務流都表示為一系列的Map任務或者Reduce任務,并行關聯挖掘的Apriori算法作為一個應用程序,其包括的所有子任務組成了一個有向無環圖,如圖1所示[12]。在部署Hadoop的時候,主控節點部署為JobTracker,工作機一般部署為TaskTracker。因特網上有很多關于Hadoop的文獻,由于篇幅原因這里不再過多累述,這6個具體步驟如下:
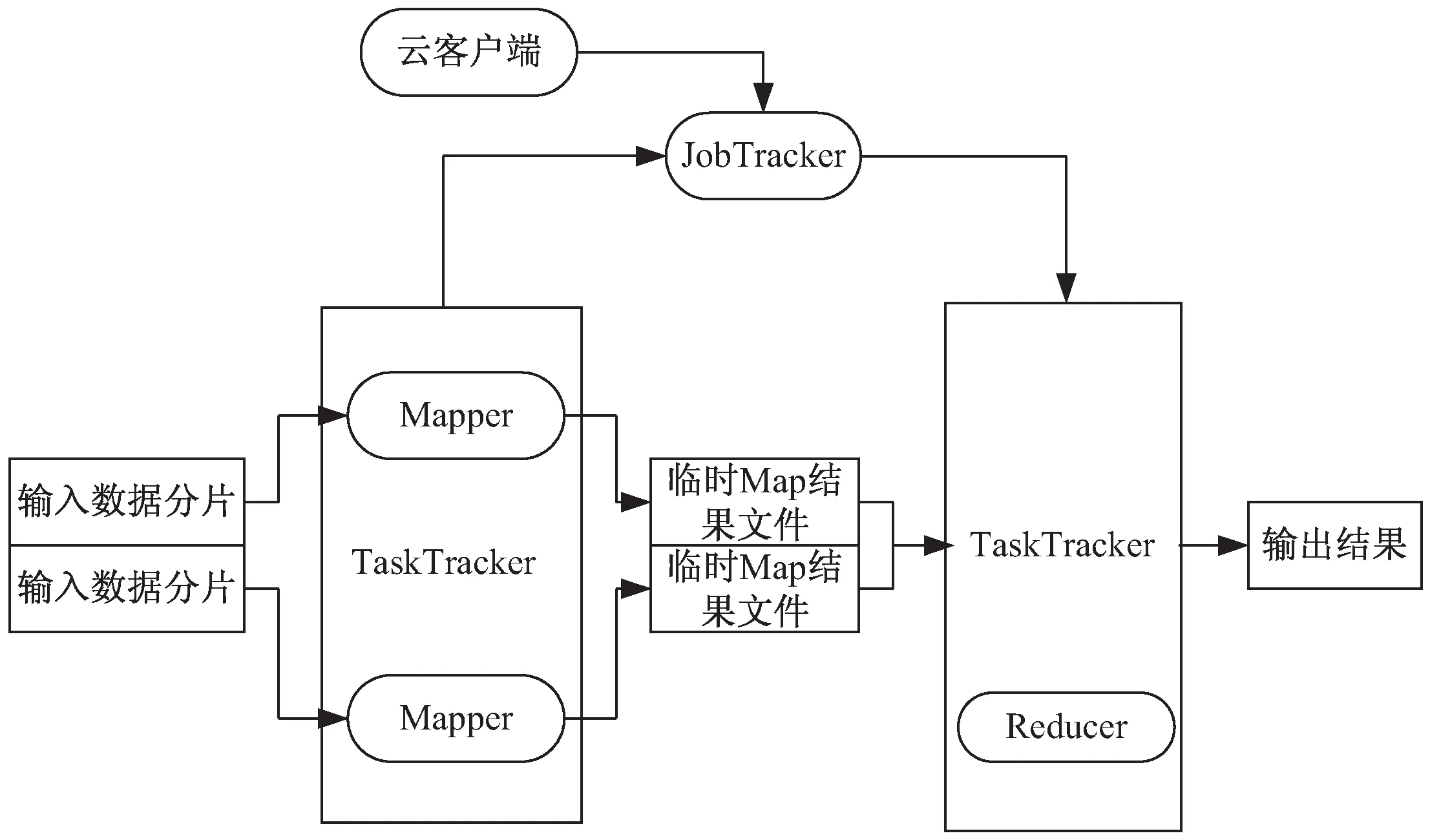
圖1 基于MapReduce的并行關聯挖掘任務流
(1)對輸入的大數據的樣本數據集文件進行設置與分片;
(2)主節點(JobTracker)調度從屬節點(TaskTracker)執行Map子任務;
(3)從屬節點讀取輸入源片段;
(4)從屬節點執行Map子任務,并將臨時結果文件保存在本地;
(5)主節點調度從節點執行Reduce子任務,Reduce階段的從屬節點讀取Map子任務的輸出文件;
(6)執行Reduce子任務,將最后的結果保存到HDFS分布式文件系統當中。
有了這6個步驟,并行關聯挖掘的Apriori算法的編程人員就可以擺脫本身分布式計算的編程細節,可以使用高級語言在很短的時間內,完成分布式計算的編程。
1.2 MapReduce模型分析
Map操作和Reduce操作是MapReduce并行編程模型的關鍵操作,所有的任務流必須經過這2個階段。MapReduce中的任務流可以通過下面的公式表示:
DAG=(W,E,DAGinfo)
(1)
W={Wname,{Map},{Reduce},Param,Input,
Output}
(2)
其中,W表示被并行處理后的任務的集合,Wname表示子任務的名稱;Map和Reduce分別表示映射和規約操作;Param表示任務執行所需要的參數信息;Input和Output分別表示輸入任務和輸出任務相關的數據信息;E表示在DAG圖中的兩個任務之間的邊;DAGinfo表示DAG圖中的特殊鑒別信息。
公式(2)中的Map操作可以更詳細地表達如下:
Map=(Mname,InK,InVal,OutK,OutVal,
Propereties)
(3)
其中,Mname表示Map操作的名稱;InK和InVal分別表示在輸入Map操作過程中Key-value關鍵字與關鍵字值之間的映射對;OutK和OutVal分別表示在輸出Map操作過程中Key-value關鍵字與關鍵字值之間的映射對;Properties表示在Map操作過程中的屬性參數。公式(2)中的Reduce操作可以更詳細地表達如下:
Reduce=(Rname,InK,InVal,OutK,OutVal,
Propereties)
(4)
其中,Rname表示Reduce操作的名稱,后面的參數InK和InVal等的含義都與Map操作中是一致的。E表示在DAG圖中的兩個任務之間的邊。E的詳細描述如下:
E=(Path,StartTK,EndTK)
(5)
其中,Path顯示了數據流的傳輸路徑,StartTK表示當前的任務,EndTK表示任務的子任務。
2 Cloud-Apriori并行關聯規則挖掘模型
2.1 基本模快
Cloud-Apriori的關聯規則數據挖掘如圖2所示。
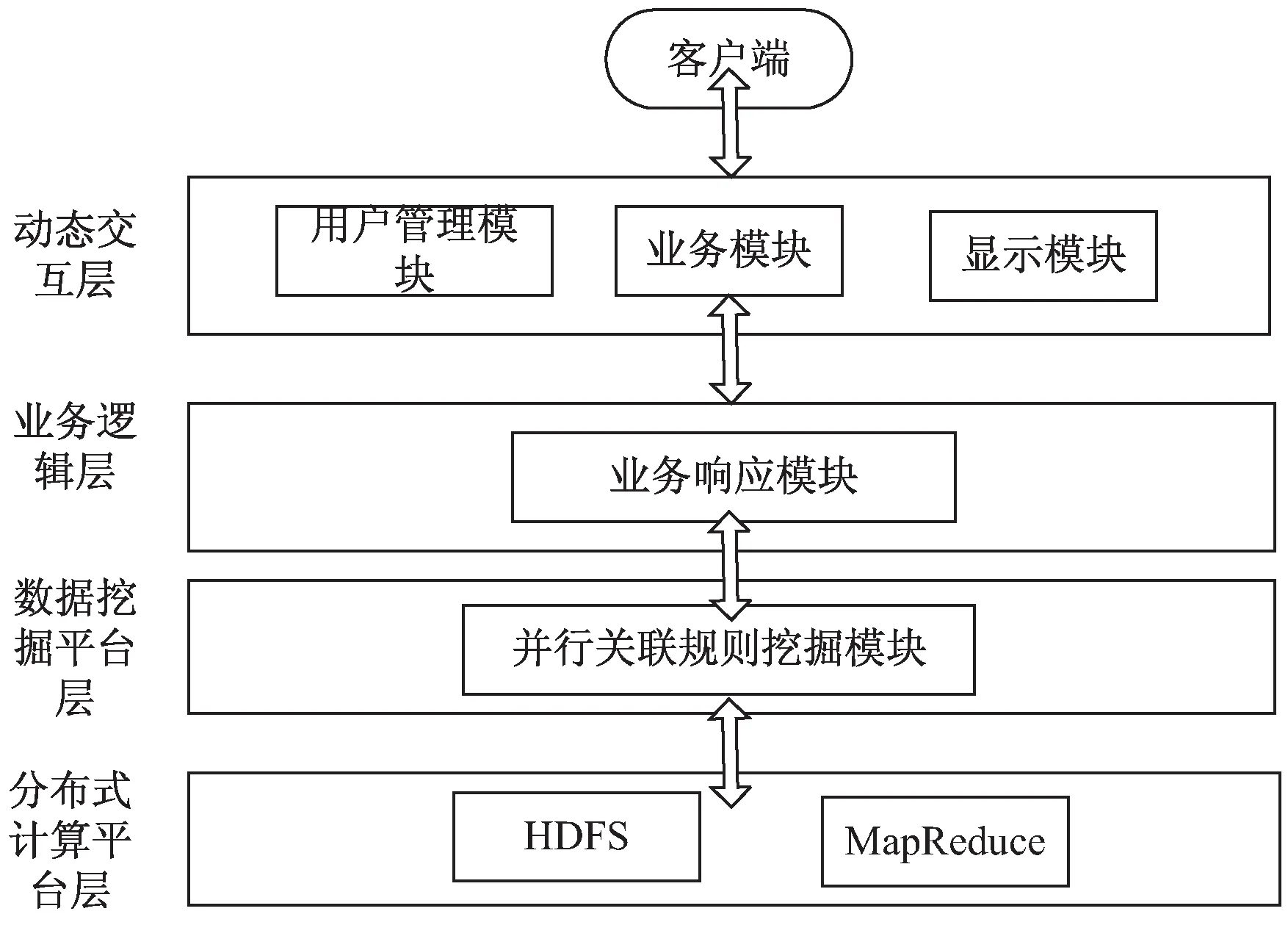
圖2 基于Cloud-Apriori的并行關聯挖掘模型
主要包括:
(1)動態交互層:用來與客戶端通過接口進行交互;
(2)業務邏輯層:用來完成針對交互層和數據挖掘平臺層的所有業務處理操作的命令和控制;
(3)數據挖掘平臺層:是該文基于Hadoop的關聯規則算法的核心層,具體完成大數據的處理,包括并行數據挖掘算法,工作流模塊,數據裝載模塊和存儲模塊;
(4)分布式計算的平臺層:它是利用Hadoop框架來獲得HDFS分布式文件的存儲和MapReduce的工作的執行。
2.2 關聯規則Apriori算法原理
關聯規則表示兩個實體在某種規則下的一些隱藏信息,關聯挖掘的目的是發現這些隱藏的關系[13]。關聯規則可以通過數據模型來描述,例如X表示關聯規則的前提假設,Y表示后續的關聯規則。另外,關聯規則算法有一個關于支持度(support)和置信度(confidence)的定義,如公式(6),這里A和B分別表示了不同的事件。
(6)
關于支持度和置信度的通信關系可以通過公式(7)來計算:
(7)
關聯挖掘的Apriori算法的基本思想是使用頻繁項集的優先知識信息來完成迭代計算,該過程是層對層的搜索進行的[14]。
為了實現在Apriori算法下的關聯分析,一般的關聯挖掘的步驟如下:
步驟1:設置最小的需求支持度min_Sup和最小的置信度min_Conf;
步驟2:順序地連接和掃描數據集,確定每個數據項的支持數量,選擇出在步驟1中的最小支持度min_Sup的頻繁項集1;
步驟3:隨機地結合2個頻繁項集1來生成侯選的頻繁項集2,然后順序地連接數據集和完成對侯選的頻繁項集2的支持度的計算,最后根據步驟2過濾頻繁項集2;
步驟4:重復步驟3直到產生了空的最高序號的頻繁項集;
步驟5:輸出關聯挖掘的結果,算法結束。
2.3 Cloud-Apriori挖掘算法的設計
前面提到MapReduce編程模型采用了主-從(Master/Slave)模式,即主控節點上可以部署Job Tracker,在從節點上可以部署Task Tracker。在DAG的有向無環圖中,為了更好地分配正確的任務流到所有的處理節點,該文采用并行MapReduce的任務流處理技術,具體的實現機制如圖3所示。

圖3 MapReduce的并行關聯挖掘工作機制
2.4 Cloud-Apriori挖掘算法的實現
(1)產生頻繁項集。
文中算法采用了自頂向下的方式,從概念的第一層開始到最后一層,利用MapReduce產生大量的頻繁項集,包括在不同的概念層之間的層次交互。對于每一層來說,MapReduce操作產生一個頻繁集的數據項,包括特殊層的交互,這種操作將一直迭代,直到在本層中不能發現更多的頻繁項集為止。
在數據入口的處理中,主要使用了三個類:輸入格式Input format、輸入分片Input split和記錄閱讀器Record Reader。在這三個類中,輸入格式又被輸入數據處理一次,每個輸入的分片在后面的類中處理。記錄閱讀器的功能是對數據塊的輸入分片進行分析,并將其信息對接到多個key-value關鍵字和關鍵值的映射對中,并發送到Map函數。與任務相關的關鍵字和關鍵值的映射

表1 關鍵詞和關鍵值的映射表描述
(2)Map和Reduce的處理。
當使用Hadoop來完成大數據處理的時候,在文件中的每行都被作為交易記錄對待,在行中的每個入口都被一個空格符號分離開。在客戶端提交了文件到HDFS后,文件中的數據塊的默認尺寸是64 MB,每個迭代的輪次都執行一個MapReduce任務。每個Map節點同時處理多個數據塊,處理完后輸出到候選集及其對應的支持度。
Reduce操作持續地處理Map操作階段的結果,所有的具有相同的鍵值的關鍵字-關鍵值對都將完成規約操作,最后完整的頻繁項的支持結果將完成。這些并行的規約過程都采用MapReduce結構設計,包括Map()函數和Reduce()函數,它們都運行在Hapdoop平臺上,加快了關聯規則挖掘的計算速度。下面是Map()函數和Reduce()函數的偽代碼,這些代碼經過少量的修改即可在Java語言環境下執行。
下面的Map_Class是Map階段的類描述代碼:
Map_Class{
1. map(key,value){
2. Sort=0;
3. Dis=Max_Value;
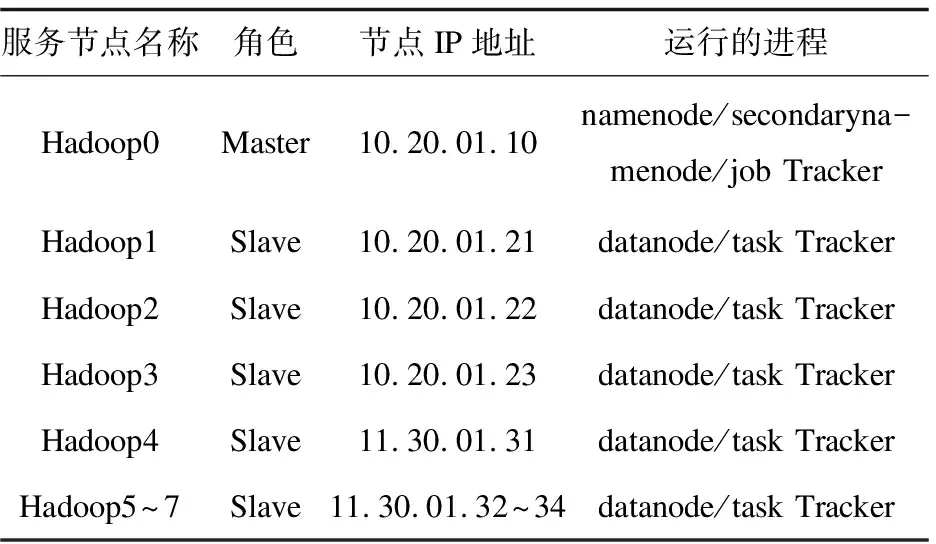
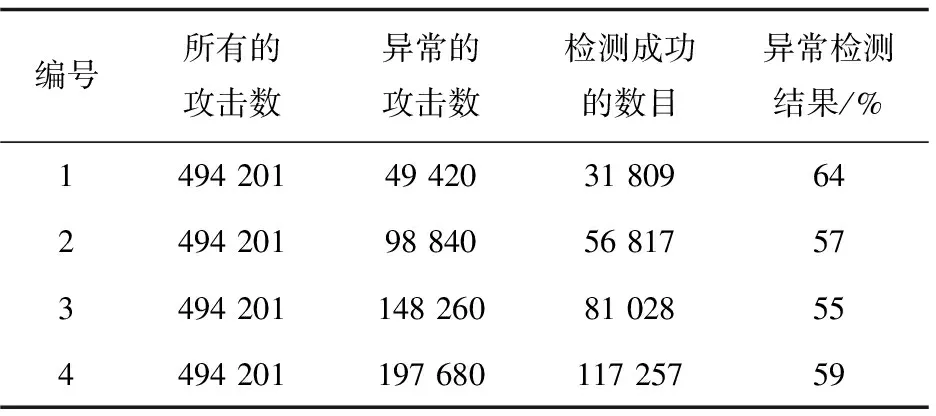
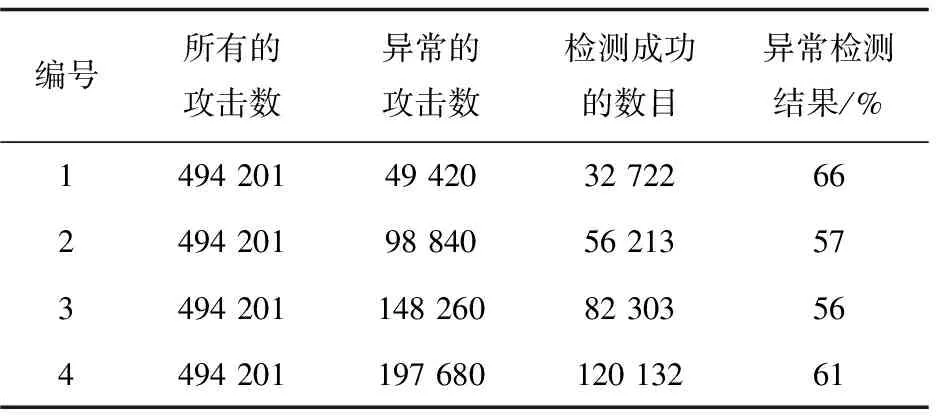
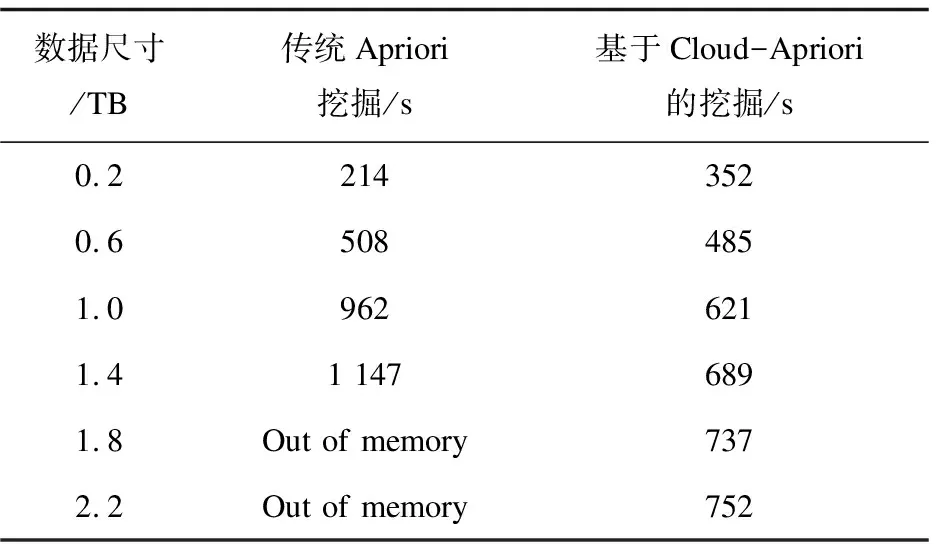
4.for(int i=1;i 5.Records Dis=dis(i,pointer); 6.if(Records Dis 7. Sort=i; 8.min Dis=Records Dis; 9.} 10. } 11.produce<"Sort" , value>; 12. } 13. } 下面的Reduce_Class是Reduce階段的類描述代碼: Reduce_Class{ 1.reduce(key,value){ 2. D1=0; 3. Sort=k; 4. Temps=new int[D1]; 5. for(int i=0;i 6 . for(int D1=0; D1 7. D1++){ 8. Temps[i]=value[D1][i]; 9. } 10. } 11. for(int j=0;j 12.pointer+=Temps[j]; 13. } 14.produce 15. } 16. } (3)計算復雜度分析。 如果i是原始數據集D的交易數,j表示每個交易記錄的平均長度,采用傳統的Apriori關聯挖掘算法,在L1層中計算時間復雜度為T1=O(i*j),整個算法的時間復雜度為: O(|Ck|*|Lk-1|)+O(i*|Ck|)] (8) 如果采用基于MapReduce的并行關聯挖掘的Apriori算法,Hadoop集群有a個節點,每個節點都操作1個數據塊,則獲取頻繁項集的整個時間復雜度可以表示為: O(|Ck|*|Lk-1|)+O(i*|Ck|)]}/a (9) 從公式(8)和公式(9)比較可以看出,從理論上講,基于MapReduce的并行Apriori關聯挖掘算法可以很好地降低執行時間。集群的物理節點個數越多,則執行時間越短,效率越高。 測試平臺的具體參數包括:8個計算節點(Intel i7的3.2 GHz主頻處理器,8 GB內存。節點之間的通訊為Intel 82574L芯片組主板,雙網卡,帶寬為1 GB/S。 Hadoop分布式平臺的版本為2.2,JDK的版本為1.8.0。其中一個節點上部署JobTracker,另外7個節點上部署TaskTracker。每個TaskTracker上有1個reduce工作slot和2個map工作slot,每個物理主機的IP地址配置如表2所示。 表2 Hadoop云平臺的物理主機的配置 所有物理主機上都安裝Linux操作系統,Hadoop的主目錄安裝在usr/local/hadoop,同時在profile文件中修改和配置好環境變量: # /etc/profile export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH 為了比較普通的關聯規則挖掘Apriori算法和基于MapReduce的并行關聯挖掘Apriori算法的性能,文中采用了Kddcup數據集。Kddcup數據集是在網絡入侵檢測中采用的最常見的標準Benchmark數據集[15],它也是一個在國內外最有代表性和影響性的網絡入侵檢測數據集。該數據集中的記錄主要被劃分為兩個部分:用于訓練的數據集和用于測試的數據集。訓練數據集具有一個具體的鑒定符,測試數據集沒有鑒定符。測試數據集也包括不在訓練數據集中的一些攻擊類型,這樣就使得系統的網絡入侵檢測能力更加的真實可信。 (1)精確度比較。 模擬地攻擊數據包,并將其保存到日志文件中,實驗中一個大約有2 000個攻擊數據包,用來測試并行關聯挖掘算法的有效性。算法的預檢測引擎可以丟棄那些認為是正常的數據包,減少沒有必要的異常檢測。 公式(10)很好地體現了網絡入侵檢測系統的錯誤檢測率(error detection rate,EDR)[16]: (10) 其中,MP表示丟棄的攻擊包的數量,DP表示網絡入侵中所有攻擊包的數量。文中關聯規則挖掘Cloud-Apriori算法完成網絡入侵檢測的結果見表3和表4(分別表示傳統的Apriori算法和基于Cloud-Apriori算法并行關聯挖掘的結果)。 表3 傳統的關聯挖掘的網絡入侵檢測 表4 基于Cloud-Apriori的關聯挖掘的網絡入侵檢測 通過比較表3和表4可以看出,基于Cloud-Apriori算法的網絡入侵檢測的性能只有少量的改善,不是很明顯,這是因為文中的并行關聯挖掘算法只是在任務執行階段完成了并行處理操作,所以整個算法的檢測精度只有少量提高。 (2)入侵檢測速度和效率的比較。 前面的實驗主要針對檢測精度,這部分完成傳統的Apriori關聯規則挖掘算法和基于MapReduce的Apriori并行關聯挖掘的算法的時間比較,如表5所示。 表5 傳統和并行的網絡入侵檢測速度的比較 從表5可以看出,當需要檢測的數據尺寸比較小的時候,MapReduce的Apriori關聯挖掘的優勢還體現不出來,它的消耗時間有時比傳統的Apriori關聯挖掘還要多。盡管如此,隨著數據容量的不斷增加,基于Cloud-Apriori算法的關聯挖掘逐步體現出它的優勢,特別是當遇到海量大數據的時候,傳統的Apriori關聯挖掘甚至無法完成網絡入侵檢測,而基于Cloud-Apriori算法的關聯挖掘可以充分利用分布式并行計算的優點,它的執行過程不受數據容量的限制,這也是早期很多傳統的軟件都被淘汰的原因,不適應近年來的大數據、云計算技術的發展。 為了進一步驗證和分析基于MapReduce的并行關聯挖掘的網絡入侵檢測方法的執行時間,改變了物理主機的數量,圖4顯示了在相同的數據容量條件下,不同的物理主機數目的執行時間比較。 圖4 隨著物理主機個數變化的執行時間比較 從圖4可以看出,當數據容量相同的時候,物理主機從2增加到7個,執行時間平緩減少,執行效率也平穩增加。 當物理主機個數到了6~7個的時候,執行時間越來越平穩,表明Cloud-Apriori算法并行關聯挖掘的算法可以很好地提高網絡入侵檢測的速度。它也證明Hadoop集群計算雖然可以提高速度,但是加速的比例是緩慢的,因為大數據處理是一種數據密集型應用,不能線性地降低處理時間。 該文提出了基于MapReduce并行關聯挖掘的網絡入侵檢測算法,利用Benchmark數據集和網絡入侵檢測這種大數據應用對算法效果進行了仿真。結果表明,Cloud-Apriori算法比傳統的Apriori算法有更好的分類精度和更少的運行時間。但是,Hadoop是一個比較低版本的開源的云平臺,下一步的工作將關聯挖掘Apriori算法移植到更高級別的云計算平臺,以進一步提高關聯規則挖掘算法的速度與效率。
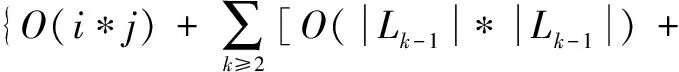
3 系統測試與性能分析
3.1 測試環境
3.2 實驗數據
3.3 入侵檢測的性能分析

4 結束語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42當代陜西(2021年17期)2021-11-06 03:21:36數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14大眾投資指南(2021年35期)2021-02-16 01:06:26學苑創造·A版(2018年11期)2018-02-01 06:29:20Coco薇(2017年11期)2018-01-03 20:59:57電力與能源(2017年6期)2017-05-14 06:19:37讀者(2017年5期)2017-02-15 18:04:18暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02信息通信技術(2015年6期)2015-12-26 01:16:46
