基于改進天牛群算法優化SVM的個人信用評估
2021-07-06 02:15:00陳靜靜
計算機技術與發展 2021年6期
陳靜靜,劉 升
(上海工程技術大學 管理學院,上海 201620)
0 引 言
隨著P2P網貸——新型金融服務模式迅猛發展,風險也逐漸顯露,其中個人信用風險在眾多風險中占據主導地位。因此,個人信用評估是保證這一行業健康發展的關鍵。近年來,人工智能逐漸興起,基于機器學習的評估模型逐漸成為信用評估的趨勢[1],常用的模型有貝葉斯網絡[2]、決策樹(decision trees,DT)[3]、神經網絡[4]和支持向量機(support vector machine,SVM)[5]等。由于SVM在解決小樣本、非線性問題上具有獨特的優勢,且能夠在樣本信息有限的情況下化解訓練精度與泛化能力之間的矛盾,因此被廣泛應用于信用評估領域。SVM的評估性能和泛化能力受參數的影響較大,到目前為止還沒有一套完備的理論去解決SVM參數優化問題。
近年來,隨著智能算法的飛速發展,越來越多的學者開始將智能算法應用到對SVM參數優化問題上。文獻[6]提出了遺傳算法優化SVM,但復雜的編碼解碼過程限制了該優化算法的適用性。文獻[7]提出收斂速度快的粒子群(PSO)算法優化SVM的參數,但算法存在易陷入局部極值的問題。文獻[8]利用能夠跳出局部極值的蟻群(ACO)算法對SVM的參數進行尋優,由于其龐大的計算量,在處理復雜問題時的效果并不佳。文獻[9-11]對上述基本算法進行改進,但是這些算法仍然存在容易陷入局部最優、尋優速度慢、對初始值敏感等問題。
天牛群算法[12](beetle swarm optimization,BSO)自提出以來,在眾多領域得到廣泛應用,如文獻[13]用BSO算法來規劃三維路徑,文獻[14]利用BSO算法優化對光伏最大功率點追蹤的速度和精確度。該文將天牛群算法用于對SVM參數優化的問題。為了改善傳統BSO算法迭代速度慢、尋優精度低等問題,該文對BSO算法進行了改進。為了協調尋優速度與解精度,引入了正態函數對步長進行優化;天牛速度更新時,不僅僅考慮了其向全局最優和個體最優學習的因素,還考慮到天牛通過自身判斷對速度更新產生的影響,并利用改進的收縮算子對學習因子進行了調整。最后將改進的天牛群算法用于SVM的參數尋優,將SVM訓練集分類準確率作為優化目標建立目標函數,選擇最優的SVM懲罰因子和核參數。利用UCI中的Wine、Iris、Ionosphere、Breast Cancer(BC)對改進模型的有效性進行了驗證。最后利用隨機森林算法,在不影響評估結果精度的前提下,剔除干擾數據,選取關鍵特征,并將處理過的信用數據German作為IBSO-SVM模型的輸入數據進行實例分析。
1 改進的天牛群算法(improved beetle swarm optimization,IBSO)
天牛須算法(beetle swarm algorithm,BSA)是基于天牛覓食規律而開發的一種新的人工智能算法,天牛覓食時,通過它的兩根觸須感受的食物濃度不同來決定下一步的運動方向,若左須感受到食物氣味較右須強,則天牛向左須方向移動。反之,則向右須方向移動。
1.1 天牛群優化算法
隨著研究的不斷深入,學者發現BSA算法處理高維函數時的性能并不強,且對初始位置敏感。受群體優化算法的啟發,將粒子群的思想融入到BSA算法中,提出了天牛群算法。用粒子群的飛行速度來代替天牛的方向,產生天牛種群并加入了向個體極值和群體極值學習的思想。生成的n只天牛用X=(X1,X2,…,Xn)表示,在m維空間中的第i只天牛的速度可表示為vi=(vi1,vi2,…,vis),第i只天牛的個體極值為pi=(pi1,pi2,…,pim),全局極值為pg=(pg1,pg2,…,pgm),第i只天牛的位置更新如公式(1)所示:
(1)

(2)
(3)
公式(2)中的c1和c2為學習因子,取值為2,r1和r2為[0,1]范圍內的隨機數。w為慣性權重,更新公式如式(4)所示:
w=wmax-(wmax-wmin)*t/maxt
(4)
其中,wmax=0.9,wmin=0.4,maxt為最大迭代次數。
1.2 改進的天牛群算法
傳統的天牛群算法在速度更新時只考慮個體向全局極值和局部極值學習的行為,而忽略了天牛個體對周圍環境所做出的判斷,該文在對天牛速度更新時綜合考慮了各種影響因素。為了更好地協調全局和局部搜索,引入了改進的收縮因子對學習因子進行調整,速度的更新表達式如公式(5)所示,收縮因子的表達式如公式(6)所示。
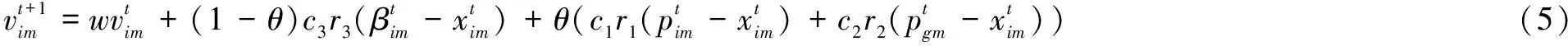
θ=1-1/(e-1)*(et/maxt-1)
(6)
為了兼顧尋優速度與解精度,該文引入正態分布函數作為調整步長的算子。該函數前期緩慢減少,有利于提高尋優速度,后期高速下降,達到提高解精度的目的,函數表達式如公式(7)所示:
g(t/maxt)=e-π*t/maxt
(7)
改進后的步長調整公式可表示為:
δt+1=δt*e-π*t/maxt
(8)
2 IBSO-SVM及混合模型的建立
2.1 IBSO優化SVM的參數
由于該文主要優化的參數為懲罰因子(C)和核參數(g),因此將IBSO種群放置到二維空間進行尋優,每個天牛的位置都代表著一對參數(C,g),將分類正確率作為尋優的目標函數,利用IBSO算法優化SVM的參數,選取最優的(C,g)組合來訓練SVM,使得訓練后的模型在測試集上能取得較高的分類準確率。
2.2 隨機森林特征選擇
隨機森林(random forest,RF)在以決策樹為基學器構建Bagging集成的基礎上,進一步在決策樹的訓練過程中引入了隨機屬性選擇。
利用隨機森林計算某個特征的重要性的具體步驟如下:
(1)計算每棵決策樹的袋外數據(out of bag,OOB)誤差,記為erro1。
(2)對所有OOB數據的特征X加入干擾信息,重新計算袋外數據誤差,記為erro2。
(3)特征X的重要性為∑(erro2-erro1)/k,k為袋外數據的個數。之所以這么表示特征重要性,是因為加入噪聲之后,OOB的準確率若出現大幅度減少,則說明該特征對預測結果有很大的影響,即該特征的重要性較大。
2.3 隨機森林融合IBSO-SVM
由于信用數據紛繁復雜,特征多且有連續與離散兩種類型,故從高維數據中挑選出有效的特征對最終的信用評估結果起著至關重要的作用。該文首先利用隨機森林對信用數據進行預處理,剔除干擾特征,而后將處理過的數據作為IBSO-SVM模型的實驗數據。混合模型進行信用評估的具體步驟如圖1所示。
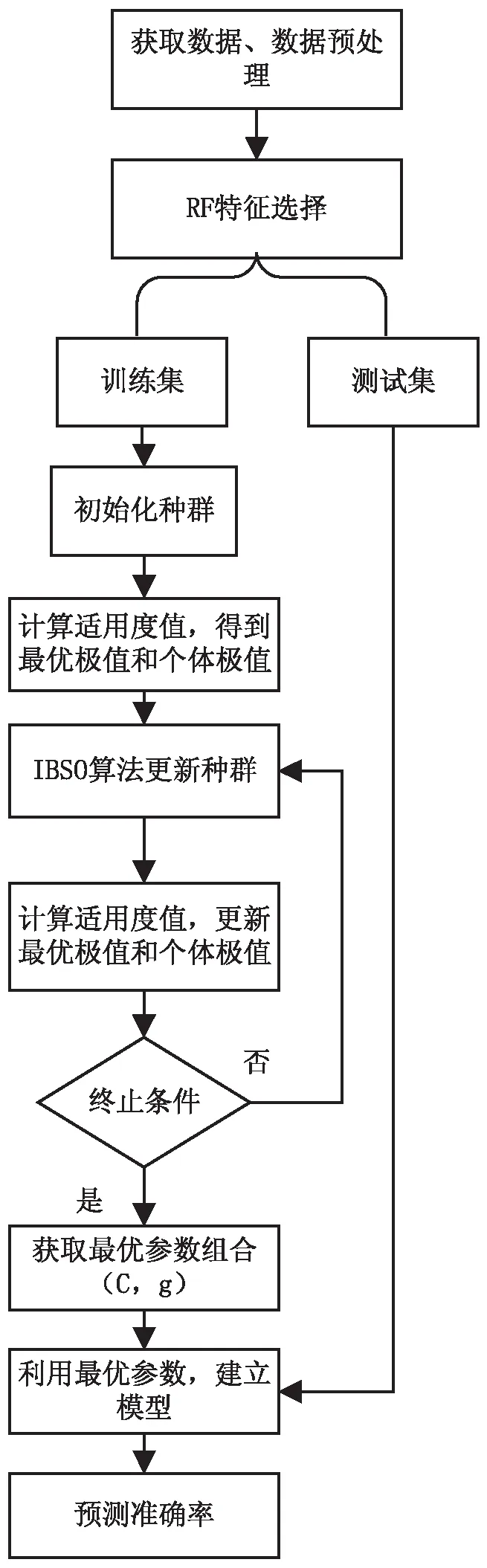
圖1 隨機森林融合IBSO-SVM的流程
步驟1:獲取信用數據German,設置種群數量n、最大迭代次數maxt,設定C和g的取值范圍。
步驟2:數據預處理。預處理數據是為了消除量綱,規范化數據。
步驟3:利用隨機森林進行特征篩選。
步驟4:數據集劃分。將數據集劃分為訓練集和測試集兩部分。訓練集用于選擇較優性能的SVM模型;測試集用于檢驗優化后的SVM模型的分類性能。
步驟5:初始化天牛群位置。由于該文需要優化的參數為SVM的懲罰參數(C)和核參數(g),因此將天牛群搜索的空間設置為二維,每個天牛的位置代表一對參數(C,g)。
步驟6:由K折交叉驗證法計算每個天牛個體的適應度值,記錄當前個體及種群最優值。
步驟7:利用改進后的IBSO對天牛位置進行更新。
步驟8:計算位置更新后的適應度值,通過適應度值的比較,更新個體位置,并獲取新的種群。
步驟9:判斷算法是否滿足終止條件;若滿足,則轉到步驟10,否則,轉到步驟7。
步驟10:獲取最優參數(C,g)。
步驟11:采用最優參數對訓練樣本進行訓練建模。
步驟12:采用建好的模型對測試樣本進行檢測。
步驟13:輸出最優參數(C,g)及分類準確率。
3 仿真實驗及分析
為了驗證IBSO優化SVM參數的有效性,與遺傳算法(GA)、粒子群算法(PSO)、烏鴉算法(CSA)、天牛群算法(BSO)的SVM參數尋優性能進行對比。利用UCI中公開的信貸數據對隨機森林融合IBSO-SVM的模型進行實例分析,并將實驗結果與基本算法及其他文獻算法進行對比分析。
3.1 實驗數據來源
實驗數據來源于UCI庫中的公開數據。實驗環境為Windows 10操作系統,CPU為 Intel 3.20 GHz,8 GB內存,編程工具為Matlab 2018b。所有的實驗都采用了5折交叉驗證。數據集描述如表1,考慮樣本差距較大,對數據進行歸一化處理。德國的信貸數據特征描述如表2所示。

表1 數據集描述

表2 德國信貸數據集描述
3.2 參數設置
種群數量的大小均為20,最大迭代次數為100。BSO初始步長step=10,兩須間距d=2,速度范圍V=[5.12,-5.12];GA算法的交叉率為0.8,變異率為0.05;PSO算法的慣性權重、學習因子與BSO算法的設置相同;CSA飛行長度F=2.5,辨識率AP=0.1。
3.3 評價標準
對IBSO-SVM模型的評價主要以分類正確率為依據,將混淆矩陣作為混合模型的評估工具,混淆矩陣見表3。依據混淆矩陣,該文選取整體正確率(Accuracy)、Recall值、特異度(Specificity)三個評價指標來評估模型的效果。指標的計算方法如下:

表3 混淆矩陣
3.4 實驗結果及分析
通過隨機森林挖掘出了German中的重要信用評估指標,各個指標的重要性排序如圖2所示,其中X軸表示占比值,Y軸表示變量。

圖2 隨機森林挑選出的German特征及其重要性排序
該文選取的特征為:A1(0.147 7)、A2(0.139 2)、A3(0.077 7)、A4(0.216 9)、A5(0.066 6)、A6(0.039 7)、A8(0.033 7)、A9(0.060 0)、A10(0.135 9)、A12(0.013 0)、A13(0.021 6)、A16(0.013 191 985)、A17(0.014 9)。
表4所示為GA-SVM、PSO-SVM、CSA-SVM、BSO-SVM、IBSO-SVM在UCI數據上的分類正確率。IBSO-SVM基于隨機森林處理過的German數據進行信用評估,并選取SVM、KNN、樸素貝葉斯、決策樹、Bagging、AdaBoost、隨機森林、信用評分的多目標粒子群優化[15](multi-objective particle swarm optimization for credit scoring,MOPSO-CS)、BP神經網絡與AdaBoost混合模型[16](hybrid model of AdaBoost and BP neural network,BP-AdaBoost)作對比實驗,得到相應的評價指標數據如表5所示。

表4 各算法的測試集準確率 %
由表4可知,文中算法IBSO-SVM對UCI庫中挑選的四個標準數據的分類正確率最高,對數據Wine和Iris的分類正確率甚至達到了100%,可見該改進算法的有效性。
如表5所示,使用上述不同的算法,得到德國信用數據集驗證結果。文中提出混合模型的信用評估總精度優于其他算法。在Specificity準確率方面,與其他分類算法相比,提出的混合模型表現最好,即在對德國數據集預測“壞”客戶方面,提出的混合模型是最好的,具有令人滿意的準確率。對比文中使用所有模型的Recall值和Specificity值,Recall精度明顯優于Specificity精度,說明由于信用風險的復雜性,將信用狀況較差的客戶與信用評價模型良好的客戶進行分類比較困難。
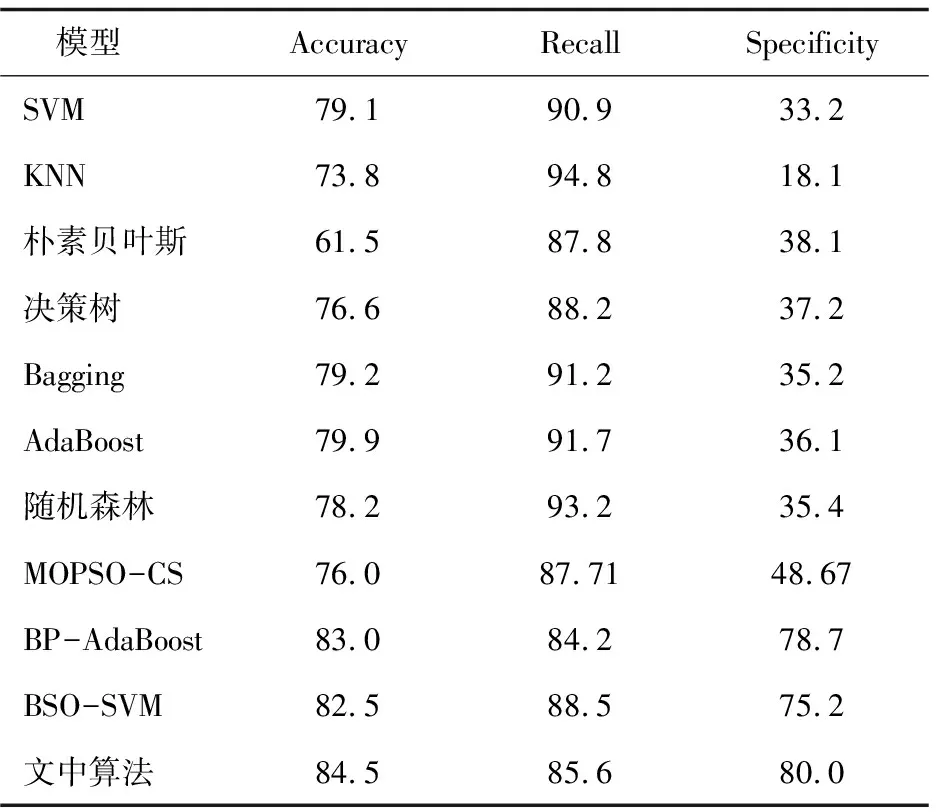
表5 各算法對信用數據的評估結果 %
4 結束語
由于參數選取對SVM的預測性能影響較大,提出改進的天牛群算法(IBSO)優化SVM的參數。速度更新時,增加了天牛的自身判斷,并加入改進的收縮因子對學習因子進行調整;利用正態分布函數自適應地調整尋優步長,既保證了尋優速度也提高了解的精度。最后將IBSO參數尋優性能與基本的BSO、GA、PSO和CSA的參數尋優性能進行對比,結果表明IBSO算法具有較好的尋優能力,IBSO-SVM的分類準確率明顯高于其他算法。為解決信用風險評估問題,首先利用隨機森林對信用數據的特征進行了篩選,并在此基礎上,運用IBSO-SVM模型對復雜的信用數據進行評估,實驗結果證明了混合模型的有效性,為個人信用評估提供了一種新的可行方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
