基于二語習得的漢英量詞對比研究
2021-07-02 03:44:38向瓊
阜陽師范大學學報(社會科學版) 2021年3期
向 瓊
(澳門科技大學 國際學院,中國 澳門 519020)
引言
量詞是用來表示事物或動作單位的詞。相對于印歐語系而言,量詞是漢藏語系的一個特色詞類。在漢語中量詞定類較晚,這與西方沒有“量詞”這個獨立詞類在一定程度上有關系。早期漢語語法研究基本受西方語法理論模式的影響。《語言自邇集》將漢語量詞稱為“陪襯的字”(a associate or attendant noun),將量詞看作名詞的一個類別[1]344。《馬氏文通》的語法體系受西方語法框架影響而建立,也將量詞歸入一般名詞[2]34。《新著國語文法》同樣把量詞歸為名詞的附類[3]81。之后,圍繞量詞的名稱、定類及分類問題有諸多爭論。語言學界先后出現了“助名詞”“副名詞”“單位詞”等。1956年“暫擬漢語教學語法系統”正式定名為“量詞”。從此,“量詞”作為一個獨立詞類的術語廣泛用于教科書、辭典。量詞從名詞附類到獨立成類歷經了一個相當長的過程。
雖然西方語法沒有量詞這個詞類,但有表達數量概念的形式。英語中就有表量結構(classifier construction),通常是在與其搭配的名詞之間加介詞of,句法功能類似漢語“量詞”(以下將英語的表量詞表述為“量詞”)。呂叔湘說:“要認識漢語的特點,就要跟非漢語比較。”[4]4對比分析法有助于全面認識英漢量詞之間的差異并總結其對應及轉換規律。
一、量詞偏誤分布與偏誤類型
(二)量詞的使用及偏誤分布
漢語量詞數量大、類型多、使用頻率高。據《現代漢語常用量詞詞典》(殷煥先等,1991)統計, 現代漢語常用量詞有789個;《現代漢語量詞手冊》(郭先珍,1987) 共收量詞 558個;《漢語水平等級標準和語法等級大綱》中將量詞劃分了甲乙丙丁四個等級,收錄量詞 56個;《HSK漢語水平詞匯等級大綱》收錄量詞87個。可見,大綱要求掌握的量詞總數很少。下面以《漢語水平等級標準和語法等級大綱》中使用頻率較高的甲級量詞為主要調查對象,統計英語母語者在漢語習得過程中出現的量詞偏誤情況。
通過以上數據分析發現:一是部分甲級量詞使用頻率較高,尤其是表1的前六個量詞,但后幾個量詞使用頻率明顯降低,甚至有的在統計范圍內呈現出未使用狀態,如“把、本、課”;二是表2中也有幾個使用率相對較高的非甲級量詞,有的甚至超過了部分甲級量詞;三有的量詞雖然使用率處于中間狀態,比如“份、首、項、口”等量詞,但是偏誤率卻極低;也有正好相反的情況,如“間”使用率處于中間狀態,但是偏誤率極高。
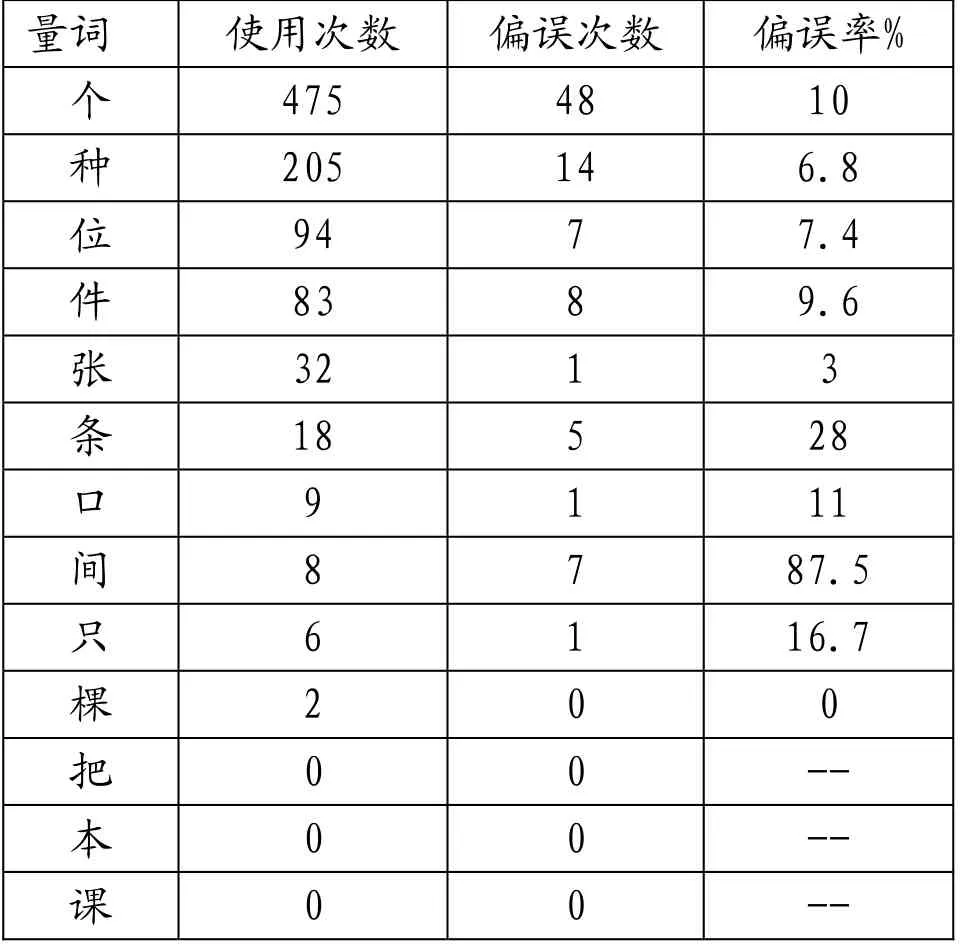
表1 甲級量詞使用及偏誤情況統計
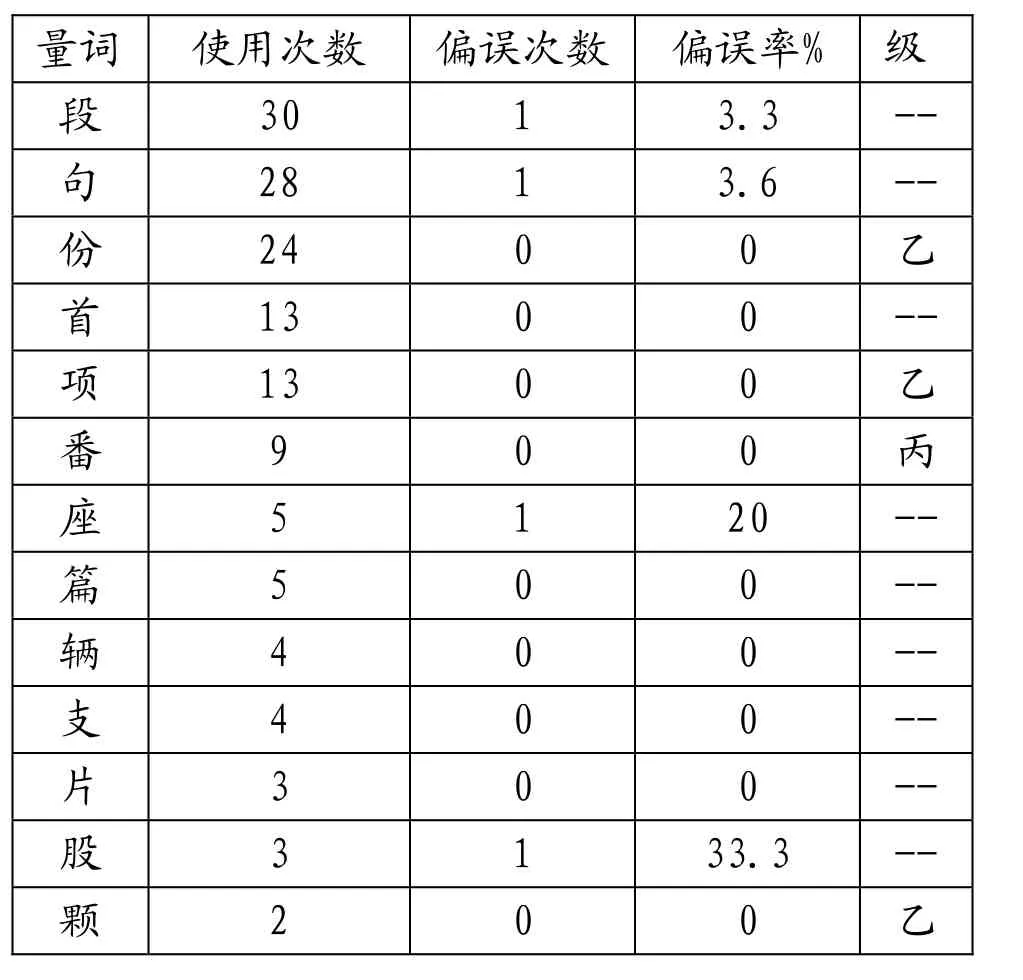
表2 其它常用量詞使用及偏誤情況統計
(二)量詞的偏誤類型
為了更全面地了解留學生的偏誤規律,我們擴大了語料收集范圍,對英語母語者在漢語習得過程中產生的大量偏誤語料(1)進行了分析。根據量詞偏誤性質將其分為六種類型:(1)誤用。指由于混淆而導致的應該用甲而用了乙。主要體現為:一量詞與名詞的搭配不匹配,如“*一頭給車輛輾至重傷的狗”;二是音義相近導致混淆使用,如“*一套襪子”等。(2)泛化。指過度地使用同一個量詞與名詞搭配。“個”是最常見的泛化量詞,如“*一個話”“*一個旅行”“*一個飛機事故”“*這個課文”等;其次是“條”,如“*這條問題”“*一條竹竿”等。(3)誤加。量詞的誤加是指不需要用量詞的地方用了量詞,如“*每一段時代的流行歌曲”;還有一種情況是量詞雜糅使用,其中一個量詞是冗余的。如“*我看過一個一本書”“*一件人生快樂幸福的一個經驗”。(4)遺漏。指應該用卻沒有使用量詞,這種偏誤在指示代詞后面出現得較多。“*那一假期我長了見識”“*我這來應考這中文水平考試”。(5)錯序。指數量短語在與名詞搭配時放錯了位置。如“*下雨一點點”“*一對音樂家的父母”。(6)與數詞的搭配問題。偏誤不在量詞本身,與量詞搭配的數詞出現冗余或殘缺現象。如“*另外個室友”“*代溝這一個問題”。
二、漢英量詞對比等級與偏誤分析
下面參照Ellis的語言對比等級理論框架[5]66,從英漢量詞對比的角度,分析各種偏誤類型的對比等級,進而考察學習難點,探討偏誤產生的根源。
(一)某個語言點漢英沒有差異
根據對應等級,在漢英中無差異的語言點屬于對比等級1級。經統計分析,大量偏誤主要集中在個體量詞的使用中。在漢語和英語中存在一些相對應的量詞(英語的表量結構在此統稱“量詞”)。具體對照情況如下:
從表3發現,漢語和英語有一些相對應的量詞,如度量衡量詞、部分群體量詞、部分借用量詞,尤其是器物量詞對應度很高。這部分量詞容易正遷移。此外,漢英量詞使用格式基本相同,一般出現在數詞的后面、所修飾的名詞前面。

表3 漢英量詞對照情況表
(二)英語兩個以上語言點對應漢語一個語言點
從L1(一語)多個詞變成L2(二語)一個詞,這類量詞屬于對比等級2級。漢語中有豐富的個體量詞,英語中則有豐富的集體量詞,相當一部分集體量詞是借用詞,與 of連用構成短語表達數量。如英語表“群”概念的量詞,可以根據不同動物和人群選擇(a pack of wolves,一群狼;a brood of chicks,一群小雞;a swarm of bees,一群蜜蜂;a school of fish,一群魚)。英語這類量詞與漢語相應的量詞體現為“多對一”的關系,由于在漢語中這類可對應的量詞數量減少,學習者相對容易掌握。但漢語量詞的復雜性也帶來了另一個問題,如a bar of soap (一塊肥皂),a lump of coal(一塊煤),a block of ice(一塊冰),a piece of cake(一塊蛋糕),英語里的四個量詞對應漢語一個量詞“塊”,同樣屬于對比等級2級,但在與名詞的搭配方面,量詞“塊”沒有“群”(主要搭配表人和動物的名詞)那么穩定。“塊”與名詞的搭配比較復雜,后面既有具體名詞又有抽象名詞。如:
由于文化及認知差異,漢語“塊”用來表達的概念與英語有差異。“塊”有時用于對舉表達整體的一部分(“一塊青,一塊紫”“紅一塊,黑一塊”“新一塊、舊一塊”);有時具有色彩附加義,如一般不說“一塊云”,但在描摹黑(烏)云時,也可用“塊”修飾。因此,2級的一部分量詞雖然簡化了,與名詞的搭配卻復雜了。這部分量詞學習者不容易掌握,出現了量詞泛化、搭配誤用,如“*一塊紙”“*每個土地”。
(三)英語某語言點在漢語中不存在
英語中有量詞的復數形式,漢語中沒有。這類量詞屬于對比等級3級。如a piece of paper(一張紙)、two pieces of paper(兩張紙)、a box of chocolates(一盒巧克力)、two boxes of chocolates( 兩盒巧克力)。對于母語為漢語的英語學習者來說,漢語中沒有量詞復數形式,容易產生負遷移,反之,不容易產生。
(四)英漢量詞分布不完全相同
英語量詞的使用取決于后面名詞的情況,可數名詞可以不用量詞,一般使用“數詞+名詞”結構來表達。英語不可數名詞要用量詞來表達數量,如a piece of glass;two pieces of glass。量詞分布不完全相同屬于對比等級4級。偏誤有兩種:一是英語可數名詞前可以不用量詞(或稱零形式),這種量詞分布的差異會導致留學生在學習漢語量詞時出現遺漏現象。如“*養第一第二孩子”(“個”漏用),“*出生以后,世界上第一所看到的人”(“次”漏用)。二是英漢量詞在句中的分布有結構差異,如“*下雨一點點”。這種屬于錯序,很大程度是英語結構的負遷移。
(五)英語沒有,漢語有的量詞
英語中沒有實際意義上的個體量詞,漢語部分借用量詞在英語中也無對應形式(表3),這些量詞歸屬于對比等級5級。上文(對比等級4級)提到,由于英語無個體量詞,一般用“數詞+可數名詞”結構表量,學習者因此會出現量詞漏用現象。漢語不僅有豐富的個體量詞,而且與名詞搭配關系復雜,有“一對多”和“多對一”的情況。
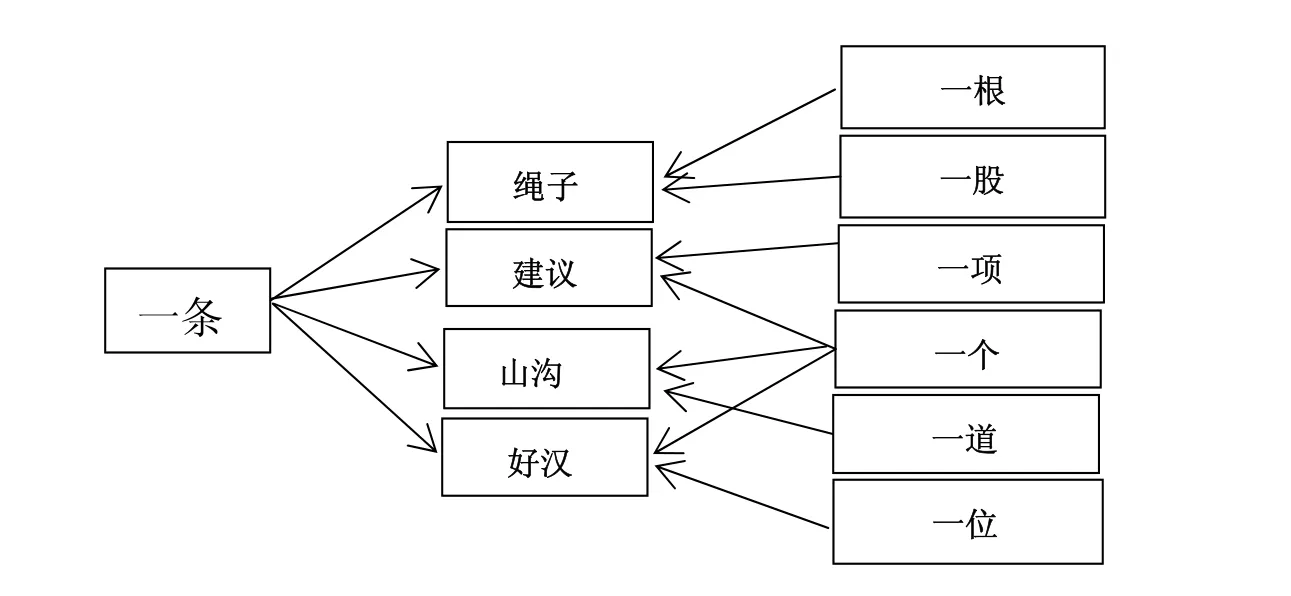
圖2 量詞與名詞“一對多”、“多對一”例舉
由圖二可知,漢語一個量詞可搭配多個名詞,多個量詞也可搭配一個名詞,學習者較難把握錯綜復雜的搭配關系,容易出現量詞泛化、誤用等,如“*每四分鐘有一個地鐵”“*一頭狗”。英語中沒有個體量詞,更無借用的個體量詞。學習者容易把漢語借用量詞看作名詞,出現不同量詞疊用及誤加雜糅。如“*一個天”,主要是由于學習者把“天”看作了名詞,同時,根據“一個月”、“一個星期”等表達形式類推而產生的目的語規則泛化。
(六)英語一個量詞對應漢語兩個以上量詞
英語一個量詞對應漢語兩個以上量詞,屬于對比等級6級。英語中的piece被稱為萬能量詞,意義由與其搭配的名詞而定。如:a piece of work(advice/glass/bread/wood/ information/ furniture etc.)漢語可以翻譯成“一項工作”(一個忠告、一塊玻璃、一塊面包、一截木頭、一則消息、一件家具等)。這里涉及L1表量范疇的詞與L2量詞的轉換選擇。漢語中也有類似的萬能量詞,如“個”。學習者常用“個”代替其它量詞,如“*一個旅游”“*一個工作”等,從而產生量詞“個”的泛化。
三、偏誤的難度等級與原因分析
(一)關于偏誤的難度等級
Ellis的對比等級理論為英漢量詞的對比提供了一個框架,由此可追溯到各種量詞偏誤產生的根源。通過對比等級分析,我們甚至可以一定程度預測可能產生的偏誤類型。
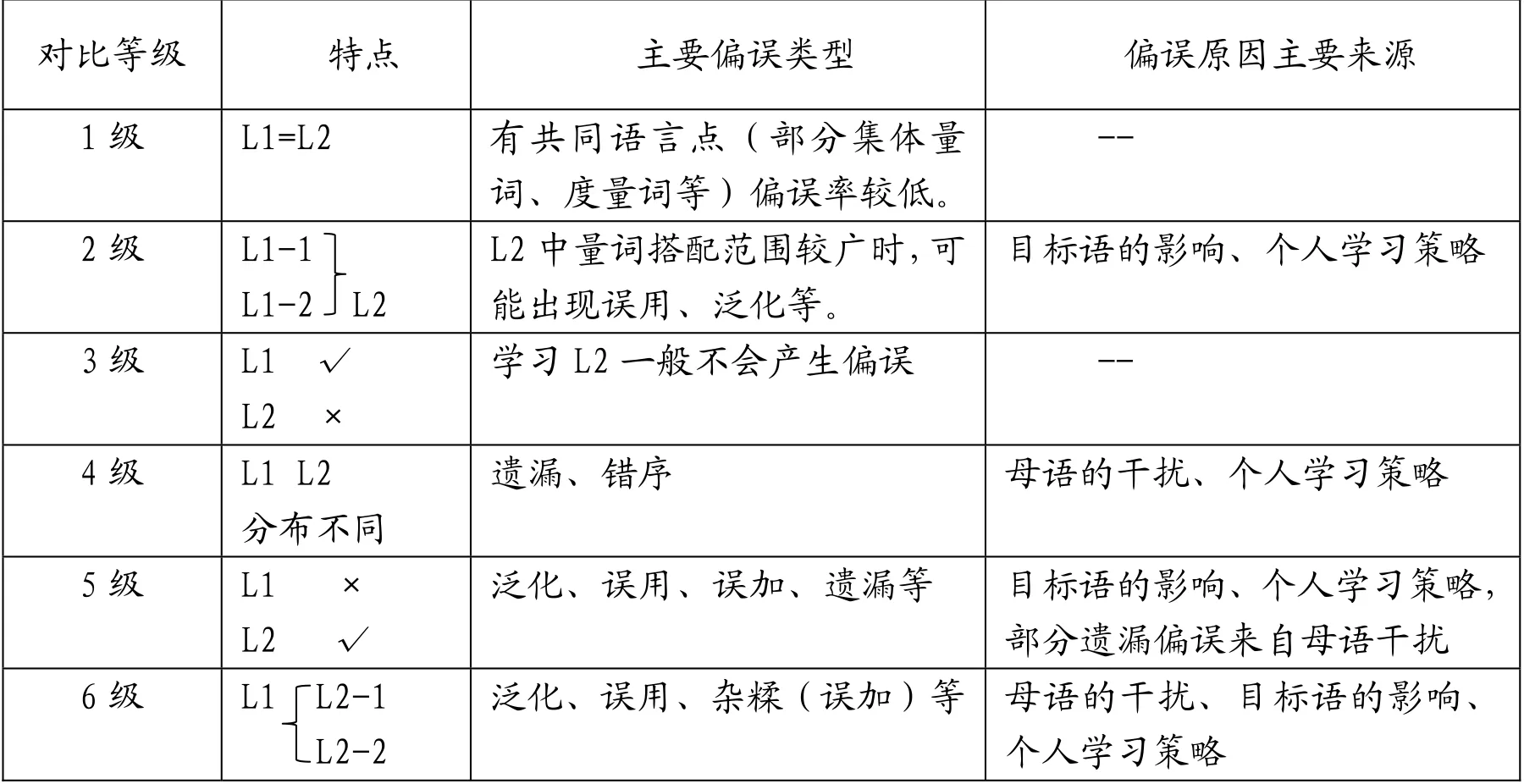
表4 不同對比等級量詞的偏誤情況
由上表可知,偏誤類型和對比等級并不是“一對一”的關系,一個偏誤類型可能出現在幾個對比等級里且難度不一,如出現在對比等級2級里的偏誤也可能出現在對比等級5級或6級。有語言學家根據兩種語言的差異度和人類學習心理基礎,對學習難度進行了等級分類,建立了多種困難等級模式。其中,Prator[5]提出對比等級1-6級,依次對應的難度等級是0-5級。這種難度等級分類偏重于語言的差異度和母語的影響度。由上文分析可知,隨著對比等級的增加,偏誤類型也在增加(1-3級量詞出現的偏誤較少,4-6級明顯增多)。Prator的難度等級理論可以一定程度解釋這種現象。但是,對比等級和難度等級并不是絕對對應的。偏誤的產生可能是母語干擾、目的語復雜度及個人學習策略等各種因素綜合影響的結果。如對比等級5級,這種對比差異很大,但對于學習者來說,來自母語的干擾反而大大降低,難度主要取決于目標語復雜度的影響和個人學習策略的實施情況,對學生A來說難度等級1級,對B可能是難度等級6級。再如對比等級2級的量詞(圖1),雖然在漢語里量詞簡化了,但與名詞的搭配卻復雜了,母語語干擾因素下降,但目標語影響大大增加,這里難度等級取決于漢語的復雜度和個人的學習策略。由此,難度等級是相對的,須具體情況具體分析。
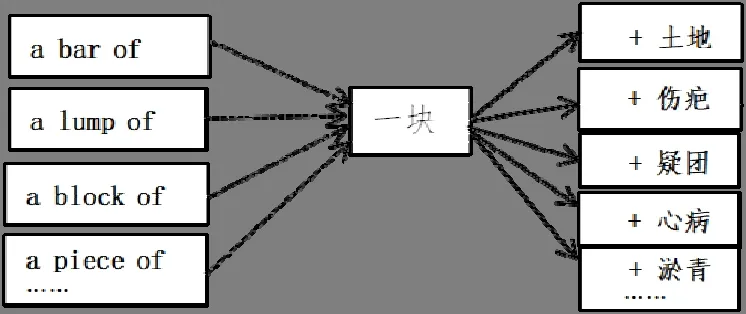
圖1 “多對一”量詞在漢語中的搭配例舉
(二)偏誤原因分析
通過上文的偏誤及對比分析,我們發現量詞使用偏誤的原因呈現多樣化,如母語的干擾、目標語的影響、個人因素、文化因素等。引起偏誤的各個因素在權重上是相對的、變化的,有時多個原因共同起作用,有時此消彼長,如上文提到的對比等級2級(圖1),母語干擾因素下降,目標語影響增加。下面重點分析三個方面的因素:
1.母語的干擾
母語的干擾主要指母語系統的特點在二語習得過程中的負遷移。如上文(對比等級4級)提到的由于量詞分布差異導致的量詞漏用、錯序等,就屬于母語負遷移。廣義的母語方面的干擾,還包括母語文化及認知的遷移。當文化存在差異,學習者認知能力與某種語言規則產生矛盾時,會出現文化及認知偏誤。如英語中的pair對應漢語中的量詞屬于“一對多”的情況(對比等級6級)。a pair of glasses(scissors/trousers/socks/ chopsticks ),可譯成“一副眼鏡”(一把剪刀,一條褲子,一雙襪子,一雙筷子)。由于認知遷移,會出現“*兩個眼鏡”“*兩把剪刀”“*兩個褲子”等偏誤。
2.目標語的影響
目標語系統內部的特點也會對學習者產生影響及干擾。上文提到漢語不僅有個體量詞(對比等級5級),而且還極其豐富,存在“一對多”和“多對一”的情況,學習者難以把握名量互選的規律,引發了各種偏誤。漢語量詞中有很多同音、近義詞,這些詞學習者容易產生混淆,如“*一套襪子”“*這片短文”,其中,“套”與“雙”在表“兩個”的意義上有相似性,“片”與“篇”則是音近導致的。此外,滲透在目標語中的文化及認知因素也會影響留學生的語言習得,比如漢語中借用身體部位的量詞(表3)等。
3.學習者的因素
學習者在學習量詞時為了促進學習、回憶語言形式和內容會采取各種技術、方法和行動,也就是說,會使用各種學習策略。而偏誤往往是在學習者運用各種學習策略而尚未達到自動化的過程中產出的。如:
(1)語塊輸入、語塊輸出
英語中沒有個體量詞,初級學習者最常用的策略是熟背常用搭配。表2顯示一些非甲級詞出現頻率高。結合語料分析,這很大程度上是學習者語塊輸入的結果。如我們統計了含有量詞“句”的28個句子,其中超過一半是以“一句話”的語塊形式出現的。再如“輛”,出現了7次,均與“車”搭配;“首”出現了11次,其中10次均以“一首歌”的形式出現;“一段時間/時光”出現了20次。主要原因是學習者在學習過程中以語塊整體輸入,在使用過程中則以語塊形式輸出。雖然語塊使用不會出現量詞偏誤,但量詞的搭配范圍有局限性,一旦將某個量詞與常用名詞拆開,學習者則無法選擇其他搭配,甚至出現用語塊代替部分的情況。如“*對于這一個問題”(這個問題),這是學習者把“一個問題”作為語塊輸入導致的。
(2)先輸入、先輸出
標記理論認為,各種語言中某些語言成分比其它的更基本、更自然、更常見是無標記的;相應地,其他的語言成分是有標記的[6]276。一般來說,先習得的是無標記的,后習得的是有標記的。學習者傾向于用無標記的量詞代替后學的量詞。較之其它量詞,“個”是較早習得的,加上使用頻率高、適用范圍廣,標記性弱,因而出現了“個”的泛化現象。表1中的甲級詞“間”出現了8次,7次偏誤形式均表現為“一間學校(公司)”。主要原因是“間”比“所”“家”等量詞先習得,留學生初級班就學習了“一間教室”“一間宿舍”,之后學習“一家公司”“一家醫院”,第二學期才開始學習“所”。
(3)簡化、類推
學習者建立中介語規則的策略包括簡化、推斷,這兩種方式極易產生創造性話語。“有學者認為一語遷移和目的語規則泛化實質上是一種簡化策略。”[5]102-103比如“*下個年”是“下個月”“下個星期”等規則泛化類推導致的。另一種最常見的形式是基于母語遷移而產生的有意識回避。如上文(對比等級3)提到的由于量詞分布不完全相同導致的量詞漏用、錯序等,就是個人回避策略和母語干擾同時作用的結果。
結語
參照 Ellis的語言對比等級,我們對漢英量詞進行了系統性地分層、分等級對比,厘清了兩種語言在表達“量”這個概念時不同的語言呈現形式及對應關系。同時,在對比分析的過程中,結合英語母語者在二語習得過程中產生的偏誤,考察了偏誤類型、習得難度、偏誤原因。產生偏誤的原因是多方面的,既有社會文化差異導致的,也有來自母語干擾及個人認知方面的因素。總地來看,雖然西方語法沒有量詞這個詞類,但有表達數量概念的形式。漢英表量形式既有相同之處,也有各自的特點,在句法功能和表達形式上存在一些明顯的差異。加強漢英量詞的對比研究,不僅對于英語母語者習得漢語、漢英量詞互譯等具有一定的現實意義,而且對研究東西方語言的異同、數量概念理解的差異、數量范疇的認知與文化的關系等,都具有一定的理論意義。
注釋:
(1)語料來自北京語言大學HSK動態作文語料庫及BCC語料庫、暨南大學留學生書面語語料庫、南京大學漢語中介語口語語料庫。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
新東方英語·中學版(2017年9期)2017-09-25 20:25:46
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學生導刊(低年級)(2016年2期)2016-02-24 23:02:11
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
小天使·五年級語數英綜合(2014年5期)2014-06-25 05:22:42
語文知識(2014年10期)2014-02-28 22:00:56
