基于深度學習的意圖識別與語義槽填充聯合建模研究
2021-06-29 10:33:38王明星
數字技術與應用 2021年5期
王明星
(北方工業大學,北京 100144)
0 引言
近年來,對話系統被應用于各方各面,比如Siri、Echo、天貓精靈等,通過對話交互幫助用戶完成任務。自然語言理解(NLU)是對話系統的核心模塊,其目的是提取出用戶表達中的用戶意圖和與意圖相關的重要語義信息,并將其表示成計算機能夠理解的結構化形式。在特定領域類,自然語言理解可以拆分成兩個子任務,即意圖識別和語義槽填充。
意圖識別是一個預測意圖標簽yi的分類問題,語義槽填充是一個序列標記任務,將輸入單詞序列x=(x1、x2、…、xT)映射到語義槽標簽序列YS=(YS1,YS2,…,YST)。基于遞歸神經網絡(RNN)的方法,特別是門控遞歸單元(GRU)和長短期記憶(LSTM)模型,在意圖分類和插槽填充方面取得了最先進的性能。最近,研究者們提出了幾種意圖分類和語義槽填充的聯合學習方法來利用和建模這兩個任務之間的依賴關系,并提高了獨立模型的性能[1]。先前的工作表明,注意力機制[2]有助于循環神經網絡處理遠程依賴關系。因此,基于注意力的聯合學習方法被提出,并實現了聯合進行意圖識別和語義插槽填充得最好的性能[3]。
由于缺乏NLU 和其他自然語言處理(NLP)任務的人工標記數據,導致泛化能力較差。為了解決數據稀缺的問題,提出了各種技術來訓練。通用語言表示模型,使用大量未注釋的文本,如ELMo[4]和GPT[5]。預訓練的模型可以在NLP任務上進行微調,并很多自然語言處理領域取得了顯著的效果。最近,一種預訓練模型BERT被提出,它在各種各樣的NLP任務都取得了最好的效果,包括問題回答、自然語言推理等。然而,沒有人在自然語言理解任務上使用BERT模型進行聯合建模。本文的貢獻包括以下兩個方面:第一,使用BERT預訓練模型,以解決自然語言處理任務泛化能力差的問題;第二,提出了一種基于BERT-crf的意圖識別和語義槽填充聯合模型,并通過實驗證明了該模型在意圖識別和語義槽填充上取得了顯著的提高。
1 相關工作
深度學習模型在自然語言理解上有很多的探索,主要包括兩種方法來解決自然語言理解問題,分別是獨立建模方法和聯合建模方法。
針對意圖識別任務,主要有基于規則模板、統計機器學習、深度學習幾種方法。Kim 等人首次使用CNN 來處理意圖識別問題,并且獲得了很好的效果。Al-Sabahi K等人通過引入自注意力機制來獲得句子表示,使用多個句向量來表示不同的語義信息,通過在雙向的LSTM上執行,最終得到的句子向量通過對雙向LSTM的隱藏層狀態加權求和獲得,在意圖識別任務上取得了不錯的效果。Xia等人首次將膠囊網絡應用在意圖識別任務上,使用路由機制將貢獻度不同的各種語義聚合起來,形成更有代表的語義表示向量,進而達到意圖識別的目的。針對語義槽填充任務,主要有基于字典、規則、統計、深度學習的方法。Lane等人使用兩個RNN模型來構建編碼和解碼器,實現輸入和輸出的對齊,并應用在語義槽填充任務上,取得了很好的效果。Yao 等人使用LSTM 來解決語義槽填充問題,并且在LSTM 模型中加入CRF機制,這種建模方式極大地提升了語義槽填充的效果。Zhu等人使用雙向的LSTM 模型作為編碼器,同時加上注意力機制,在語義槽填充任務上取得了極大的進步。
針對聯合建模,Jeong等人采用三角鏈條件隨機場模型捕獲了意圖識別和語義槽填充這兩者的內在聯系,雖然該模型在聯合識別上作出了一定的貢獻,但是卻有著傳統機器學習方法的不足,并且需要足夠多的訓練語料。Guo等人使用遞歸神經網絡和Viterbi算法聯合解決意圖識別和語義槽填充任務,該方法將句子以語法樹的形式表示出來,利用RNN學習數中每個節點的特征,極大地提高了聯合識別的性能,然而在語義槽填充任務中會產生一定的信息損失。
2 方法提出
本章首先簡要介紹了BERT 模型進行介紹,然后介紹了所提出的基于BERT-CRF 的聯合模型。
BERT的模型架構是一種多層的雙向transformer編碼器,每個單詞的輸入表示有三部分構成,即詞向量token embedding,句子向量(segment embedding)和位置向量(position embedding)。使用一個特殊的分類嵌入([CLS])作為第一個標記,并添加一個特殊的標記([SEP])作為結尾標記。對于給定輸入序列x=(x1,…,xT),BERT的輸出為H=(H1,…,hT)。BERT利用MLM進行預訓練并且采用深層的雙向Transformer組件來構建整個模型,因此最終生成能融合左右上下文信息的深層雙向語言表征,并可用于各種任務,比如本文的研究內容,意圖識別和語義槽填充。
本文提出的聯合模型結構圖,如圖1。將待理解的句子向量化后輸入到BERT模型中,BERT模型將句首[CLS]標記對應的隱藏狀態輸出出來,通過soft max函數,獲得意圖標簽的概率分布,根據概率分布獲得最終的意圖;同時BERT 模型將其余的隱藏狀態輸入到CRF 層中,CRF 層負責尋找語義槽標簽之間的關系,最后從CRF層中輸出語義槽標簽。
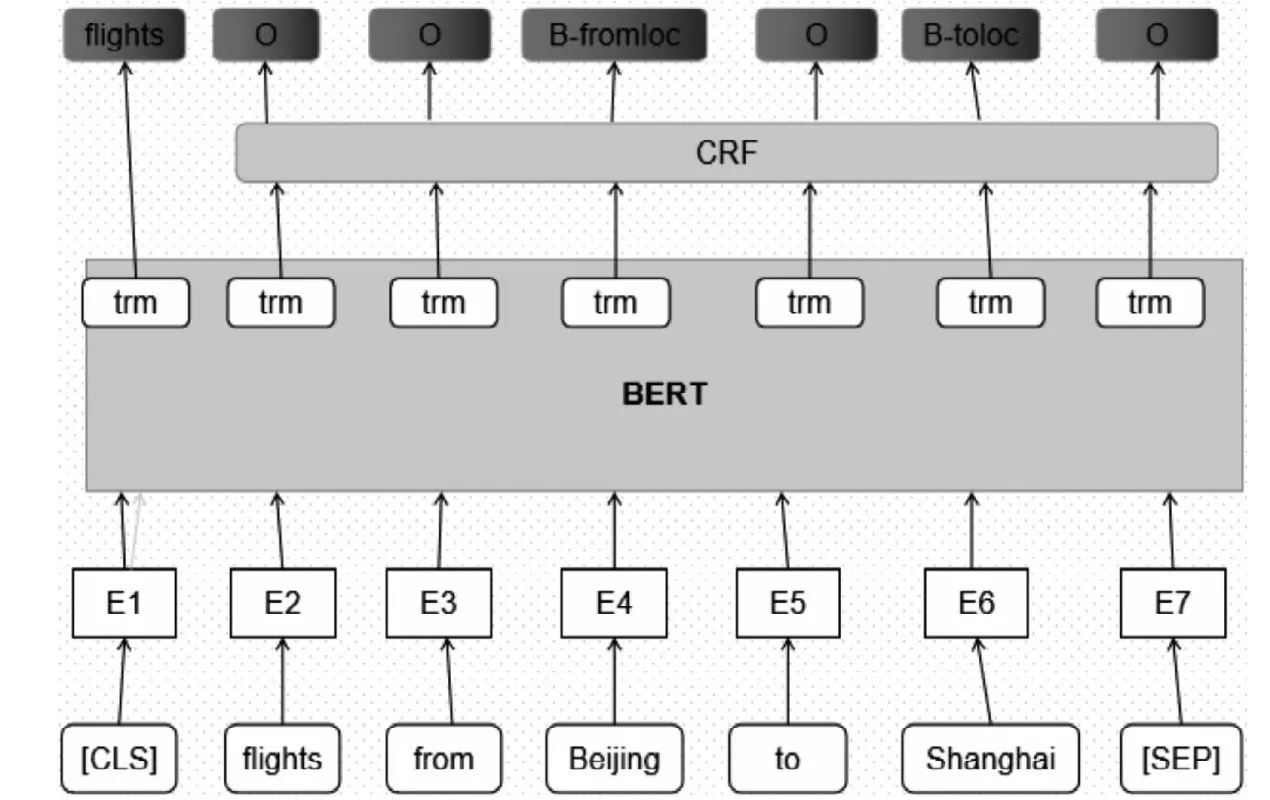
圖1 BERT-CRF 聯合模型Fig.1 Bert-crf joint model
BERT可以很容易地被擴展到一個意圖識別和語義槽填充聯合模型。根據第一個特殊標記([CLS])的隱藏狀態h1,預測意圖為:
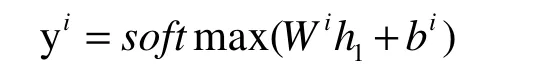
對于語義槽填充,其預測取決于對周圍單詞的預測,CRF能夠很好的解決該問題,于是將h2,…,ht的最終隱藏狀態輸入到crf層,以便在槽填充標簽上進行分類。為了使此過程與單詞序列中標記相兼容,這里將每個標記化的輸入字輸入到一個單詞標記器中,并使用與第一個標記對應的隱藏狀態作為輸入,其最大似然函數為
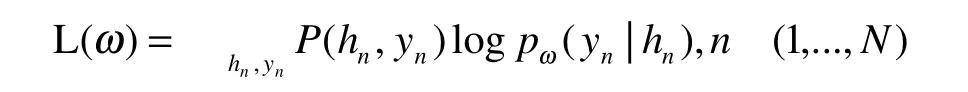
其中,hn對應輸入xn之后得到的隱藏狀態。
對于意圖識別與語義槽填充聯合模型的目標函數,可以設定為:
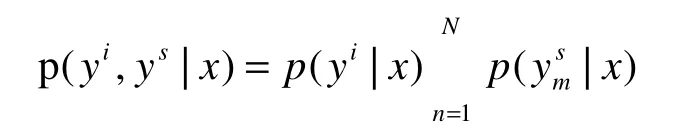
通過不斷的進行訓練使條件概率p(yi,ys|x)最大化,該模型是通過最小化交叉熵損失來實現對模型參數的調整。
3 實驗與分析
本文在自然語言理解兩個比較公認的數據集ATIS和Snips上評估了所提出的模型并加以分析。
ATIS 數據集有航空飛行方面相關的對話構成,該數據集中共包含4478條數據訓練數據,500條驗證數據,893條測試數據。Snips數據集是通過收集Snips虛擬個人語音助手中的數據得到的,是一個開源的語料庫。該數據集中有諸多領域的查詢話語,比如天氣查詢和酒店預訂,該數據集中共包含13084條訓練數據、700條驗證數據、700條測試數據。
本文使用的BERT版本是BERT-Base,它有12層,768個隱藏狀態,12個頭部,參數規模110M。對于微調,所有超參數都在驗證集上進行調優。最大長度為50。批量大小為128。adam用于優化,初始學習率為5e-5。dropout率為0.1。訓練輪數分別為[1,5,10,20,30,40]。
表1顯示了在Snips和ATIS數據集上,本文的模型和其他聯合模型的效果比較,其中用準確率作為意圖識別的評價標準,使用F1分數作為語義槽填充的準確率。

表1 在ATIS 和Snips 數據集上,不同模型效果對比Tab.1 On ATIS and snips datasets,the effects of different models are compared
在表1中,與本文模型進行對比的模型都是現在表現最好的模型,其中包括基于BiLSTM 的聯合模型、基于注意力機制的循環神經網絡聯合模型以及基于門控機制的聯合模型。
在ATIS 數據集上,本文提出的BERT+CRF 聯合模型在意圖識別任務上的意圖識別準確率為97.8%,語義槽填充F1分數為96.0%;在Snips數據集上的意圖識別準確率為98.4%,語義槽填充F1分數為96.7%。從中可以看出,本文提出的聯合模型不管是在意圖識別還是語義槽填充上效果都要比其他模型更好。
如圖表2顯示的是在不同訓練輪數下,本文提出的聯合模型在意圖識別的準確率和語義槽填充的F 1 分數對比,可以發現在意圖識別任務上,隨著訓練輪數的增加,會產生過擬合現象,在到第20輪的時候效果達到最佳。然而在語義槽填充任務上,模型的效果隨著訓練輪數的提高而不斷提高,說明語義槽填充任務相對意圖識別來說更加復雜,需要更多的數據量。
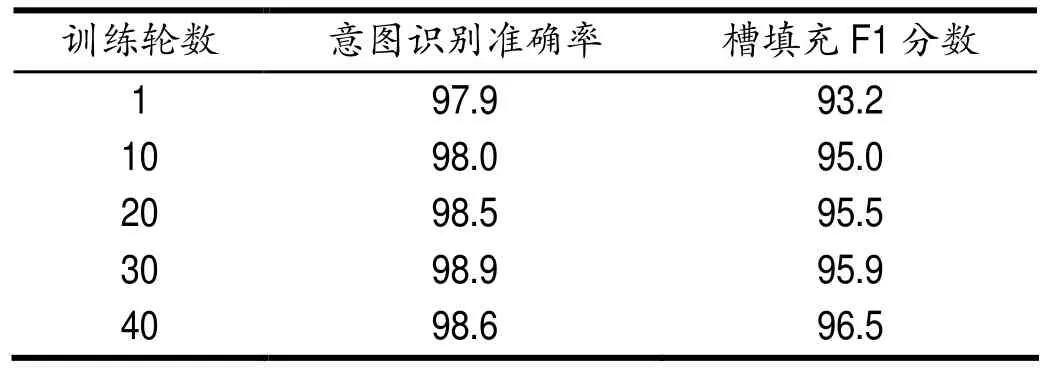
表2 不同訓練輪數下的效果對比Tab.2 Effect comparison of different training rounds
4 結語
本文提出一種基于BERT-CRF的意圖識別和語義槽填充聯合模型,不僅解決了自然語言理解任務的泛化能力問題,而且實驗結果表明,本文提出的聯合模型在意圖識別和語義槽填充任務上都有出色的表現,證明了利用這兩個任務之間關系的有效性。與之前表現最好的模型相比,本文提出的模型在ATIS和Snips數據集上對意圖識別和語義槽填充任務都有顯著的提高。未來的工作會集中在探索將外部知識與BERT模型相結合的有效性以及在其他更大規模和更復雜的數據集上進行評估和分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
現代語文(2016年21期)2016-05-25 13:13:44
