人大報告內容的文本分類
2021-06-28 12:42:42李紅蓮呂學強
計算機工程與設計 2021年6期
喻 航,李紅蓮,呂學強
(1.北京信息科技大學 信息與通信工程學院,北京 100101; 2.北京信息科技大學 網絡文化與數字傳播北京市重點實驗室,北京 100101)
0 引 言
各級人大在不斷完善自身的工作方式,在人大建設的過程中,信息化建設[1]越來越受到工作人員的重視。人大相關工作的總結,所需要的信息量巨大,類別廣泛,想要準確找到相對應的工作內容,檢索起來并不容易。所以,人大報告輔助生成系統的建立,就需要對文本分類,把文本分成不同的內容寫入報告。
文本分類技術是自然語言處理學科領域中一項基本技術[2]。傳統機器學習中一般采用Naive-Bayes分類[3]、KNN[4]、SVM[5]、邏輯回歸[6]或者隨機森林[7]等分類方法。應當依據具體情況來挑選適當的文本分類器。如果遇到巨大數據量,特征向量也非常多時,就要用到神經網絡的深度學習模型。
本文對人大報告中必要的兩大部分進行文本分類,監督工作和代表工作是每年人大報告中最重要的兩大部分,其相關工作內容的資料在收集時較難區分資料的所屬類別,用結合TF-IDF的ERNIE文本分類模型可以幫助人大工作人員,在眾多的資料中快速準確地分辨監督工作和代表工作。采用了加入TF-IDF的ERNIE模型對人大報告文本分類,其準確率、召回率和F1得分有所提高,收斂速度明顯加快。
1 文本分類流程
人大報告的寫作內容較為固定。有以下特點,人大報告篇幅長,特征詞匯多,篇章結構格式鮮明。在分類之前先對文本預處理。預處理之后進行特征提取。人大報告都是中文語料,ERNIE模型處理中文語料效果好,選用此模型來訓練分類器。本文對人大報告中的監督工作和代表工作分類的框架如圖1所示。
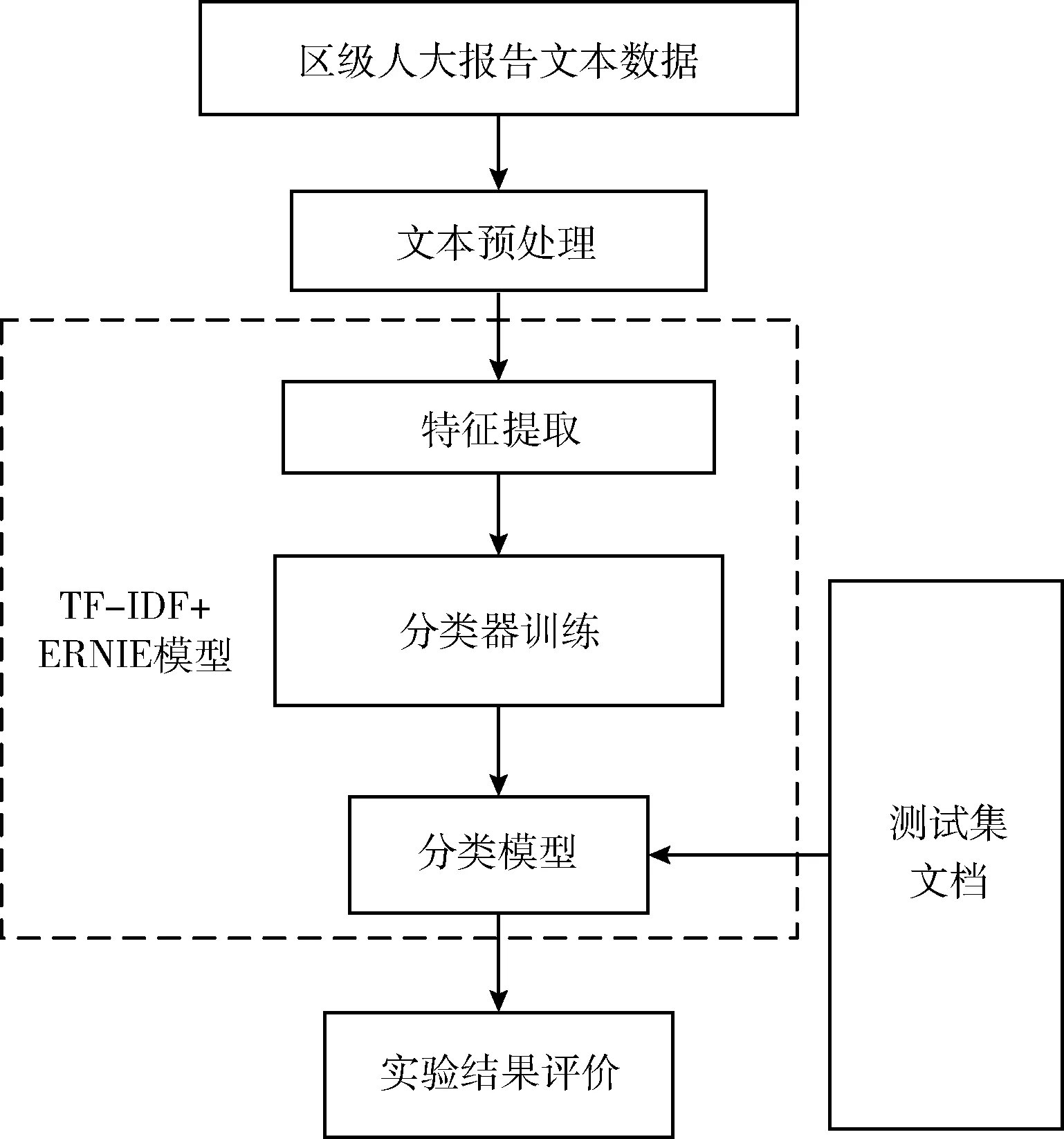
圖1 文本分類過程
1.1 數據預處理
本文以人大報告中監督工作和代表工作的相關內容作為訓練集和測試集。做文本分類工作,對數據進行預處理是必不可少的過程。對于中文文本而言,數據預處理包括:中文分詞、詞性標注(如果分類需要詞性特征)、去停用詞等等。其中的分詞是把文本分解成詞語的集合,去除停用詞是用來去掉一些沒什么含義的詞語,會對分類產生影響的詞,比如:你、我、他、的等等。本文對人大報告的預處理步驟如圖2所示。
1.2 基于TF-IDF的特征提取
加入特征提取,就是提取想要用作分類的特征,具體包括TF-IDF計算[8]、n-gram[9]、word2vec[10]、LDA[11]等。本文選用TF-IDF對詞向量進行加權平均,其中TF-IDF特征能夠在一定程度上表現詞的重要性,TF計算的常用式為
(1)
式中:nij表示詞i在文檔j中的出現頻次。IDF計算的常用式為
(2)
式中:|D|為文檔集中總文檔數,|Di|為文檔集中出現詞i的文檔數量。分母加一是采用了拉普拉斯平滑,以規避出現部分新詞沒有出現在語料庫中導致的分母為0的情形,使算法增加了健壯性。綜合使用公式為
(3)
這些作為基于TF-IDF提取出來的特征,作為額外的特征輸入。
2 ERNIE
本文提出了一種在ERNIE模型[12]中加入TF-IDF提取的特征來進行區級人大報告內容的文本分類工作。
2.1 Self-Attention機制
ERNIE模型,其建模過程中利用了多頭自注意力機制(multi-head attention),來算一個句子中的每個詞和這句中其它詞的相互聯系,Self-Attention機制在本質上是在網絡的各個部位對輸入向量進行加權,由此表示輸入文本中不同詞語特征對文本分類的不同影響力。文本的特征表示計算公式如下
at=Wxt
(4)
(5)
(6)
{x1,x2,…,xp}是輸入的詞向量序列,t=1,2,…,p。每個詞向量都通過變換映射出q、k和v這3個矩陣,其中,d的取值為q的維數,然后使用歸一化函數計算權重s1,t,把每個權重和對應向量相乘再累加求和就得到第一個詞的向量。
2.2 ERNIE模型
ERNIE的建模方式與其它模型相比,可以更好捕捉中文之間的關系。如圖3所示,對于朝[MASK]區,通過“朝”與“區”局部的字詞搭配,就能夠較為容易地推斷出掩碼字為“陽”,但是,模型卻沒有學習與“北京市”相關的知識。而ERNIE通過引入對詞的整體遮蔽,使模型能夠從更長的距離建模出“朝陽區”與“北京市”的關系,學到“朝陽區”是“北京市”的一個行政區以及“朝陽區”是一個舉辦過奧運會的城區。
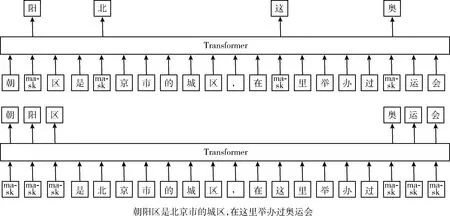
圖3 建模方式
在預訓練時,把知識圖譜的實體通過知識嵌入法與單詞相匹配,完成實體對齊任務。在預訓練的基礎上,ERNIE模型隨機mask單詞,除了用本地上下文預測單詞之外,還加入了實體信息,通過加入的實體信息可以預測單詞并學到詞之間的語義關系。
ERNIE的整個模型架構由兩個堆疊的模塊構成:①文本編碼器(T-Encoder),如圖4所示,負責從文本中捕獲基本的單詞和語義信息;②知識型編碼器(K-Encoder),如圖5所示,負責把額外的知識圖譜信息整合到來自T-Encoder的文本信息中,這樣就可以在一個統一的特征空間中表示詞匯信息和實體的信息了。其中,用N表示T-Encoder的層數,用M表示K-Encoder的層數。
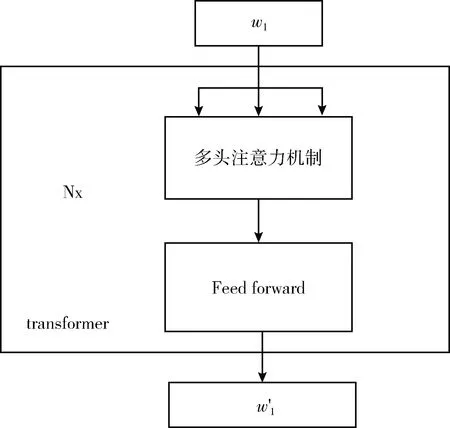
圖4 T-Encoder文本編碼器
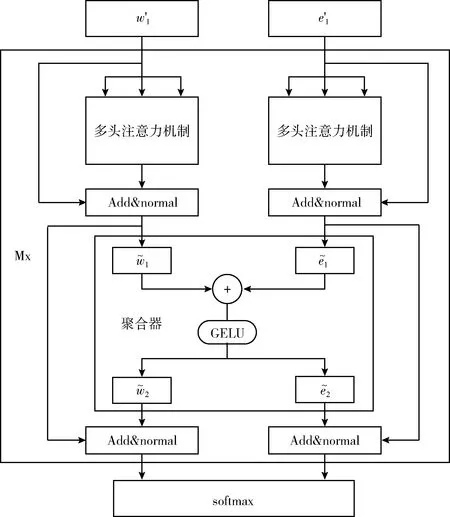
圖5 K-Encoder知識型編碼器
在T-Encoder這一部分的工作中,首先對詞嵌入向量、句嵌入向量、位置信息向量進行對應相加,作為T-Encoder的輸入,也就是圖4中的輸入。然后再計算詞法和語義特征,計算公式為
{w′1,…,w′n}=T-Encoder({w1,…,wn})
(7)
式中:{w1,…,wn}為n個輸入詞語。
在K-Encoder這部分中,通過知識圖譜嵌入法(TransE)將實體{e1,…,em}轉為對應向量表示{e′1,…,e′m}。然后將{e′1,…,e′m}和{w′1,…,w′n}作為K-Encoder的輸入,計算公式為
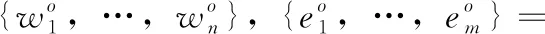
(8)
2.3 TF-IDF+ERNIE人大報告分類算法
綜上所述,本文所提TF-IDF+ERNIE對人大報告內容分類的算法,步驟如下:
步驟1 用TF-IDF算法首先對訓練集進行特征詞抽取,并將得到的特征詞ti作為額外的特征輸入。
步驟2 把訓練集進行預處理,得到經過預處理的訓練集D={(x1,y1),(x2,y2),…,(xp,yp)},其中,xp是經過預處理的人大報告文本,yp是每段經過預處理人大報告所屬類別,p=1,2,…m。
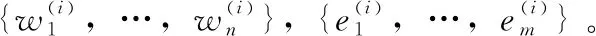
步驟4 將得出的特征表示輸入進Softmax模型中,對人大報告文本進行分類。
3 實驗以及結果分析
3.1 實驗環境
本實驗的實驗環境為Intel Core i5-8250U處理器,主頻為1.6 GHz,內存為8 G、64位的PC電腦。操作系統為Windows10,編程使用Python語言,編譯環境使用JetBrains PyCharm Community Edition 2017.3.4 x64。
開發平臺為PyTorch 1.1.0,此外,主要用到的工具包還包括numpy等等。
3.2 數據集和參數設置
為測試此項文本分類方法的性能,本次使用全國20個城市所屬的各個區縣的人大報告數據進行實驗。本次的數據集包含了從2009到2019年一共5584段報告內容,實驗用4472段作為訓練集來訓練模型,使用1112段語料作為測試集測試性能好壞。實驗數據分布見表1。

表1 區級人大報告分類實驗數據
在ERNIE神經網絡模型中,不同參數的設置對最后得到的實驗結果影響很大,所以通過參閱相關文獻,對參數進行微調,本次實驗使用的主要參數見表2。
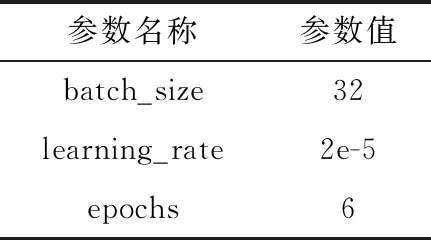
表2 ERNIE分類模型主要參數
3.3 評價指標
對本文的文本分類的方法進行評價,使用準確率(Precision)、召回率(Recall)并且使用F值(F-Measure)來對模型進行綜合評價。其中,準確率和召回率是檢索(IR)系統中的概念,也可使用于對分類器的性能進行評價。將正確分到某類的文本數記為A,錯誤分到該類別的文本數記為B,把錯誤地分到了其它類的文本數記為C。其中,各個指標的計算公式如下
(9)
(10)
(11)
準確率和召回率是相互影響的,一般情況下準確率高、召回率就低;召回率低、準確率高。指標P和R有時可能出現矛盾的情況,這就需要將它們進行平衡,最常見的方法為F1-Measure(又稱為F1-Score)。F1-Measure是Precision和Recall的加權調和平均。
3.4 結果分析
為測試模型的有效性,實驗使用多種方法進行比較,對比實驗是在分類器之前,采用不同方法對文本提取特征,分別為基于詞袋模型特征的方法,以及基于TF-IDF的方法來計算特征權重,對比模型使用的3種分類器分別為貝葉斯、邏輯回歸和支持向量機,對人大報告中的監督工作和代表工作進行分類。8組實驗都是在同一個數據集上進行實驗。文本分類的結果見表3和表4。
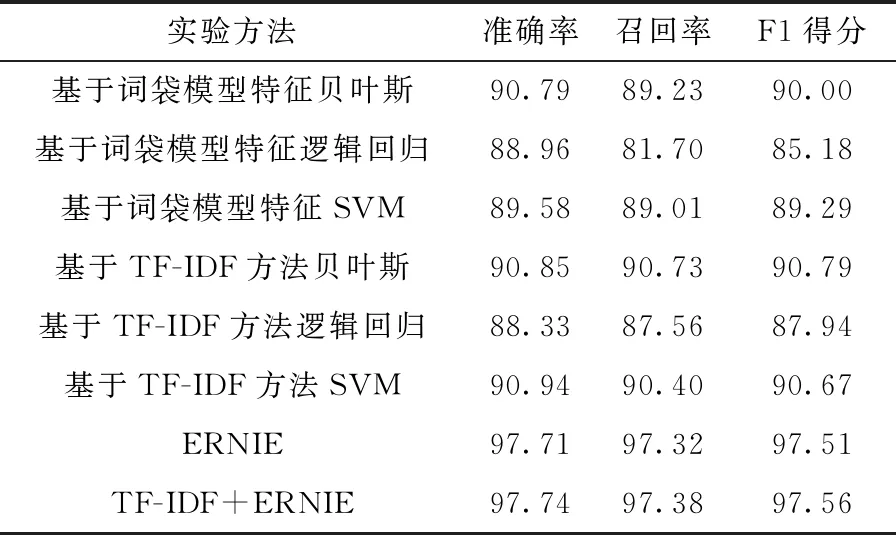
表3 監督工作分類結果/%
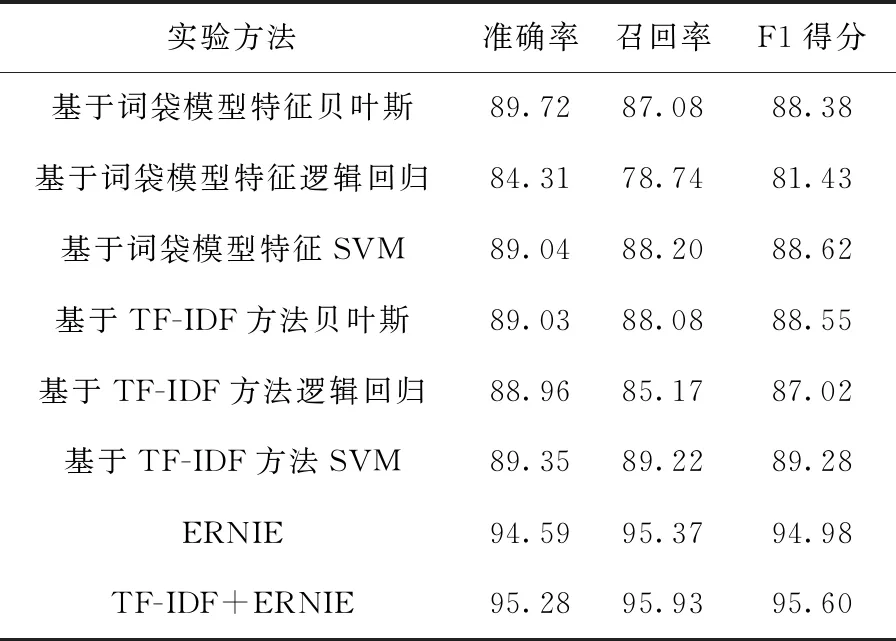
表4 代表工作分類結果/%
通過實驗結果可以看出,基于ERNIE模型進行區級人大報告內容的文本分類方法,相較于貝葉斯、邏輯回歸和SVM,在準確率、召回率和F1得分上都有大大提升。傳統的分類器,性能都遠遠落后于ERNIE。由于ERNIE在T-Encoder和K-Encoder里都引入了多頭注意力機制,注意力機制更加強化了重點信息的權重,從而可以在特征選擇方面取得更出色的效果。
此外,ERNIE模型輸入是以詞為單位,標記的內容也是以詞為單位,不但利用局部上下文預測標記,而且同時學習了上下文和知識圖譜的信息,通過預測標記,來構建的知識化語言模型。所以該模型可以充分利用詞語、句子和知識信息,通過對知識圖譜的利用,能更全面對語言進行理解。
使用ERNIE模型進行監督工作和代表工作的文本分類時,加入TF-IDF提取出的特征作為額外補充后,加快了模型的收斂速度,提升了其準確性。
為了更全面展示基于TF-IDF的ERNIE模型在算法收斂性上的優越性,記錄了ERNIE模型和TF-IDF+ERNIE模型不同Epoch下的損失值情況,ERNIE模型和TF-IDF+ERNIE模型的損失值變化分別如圖6和圖7所示。
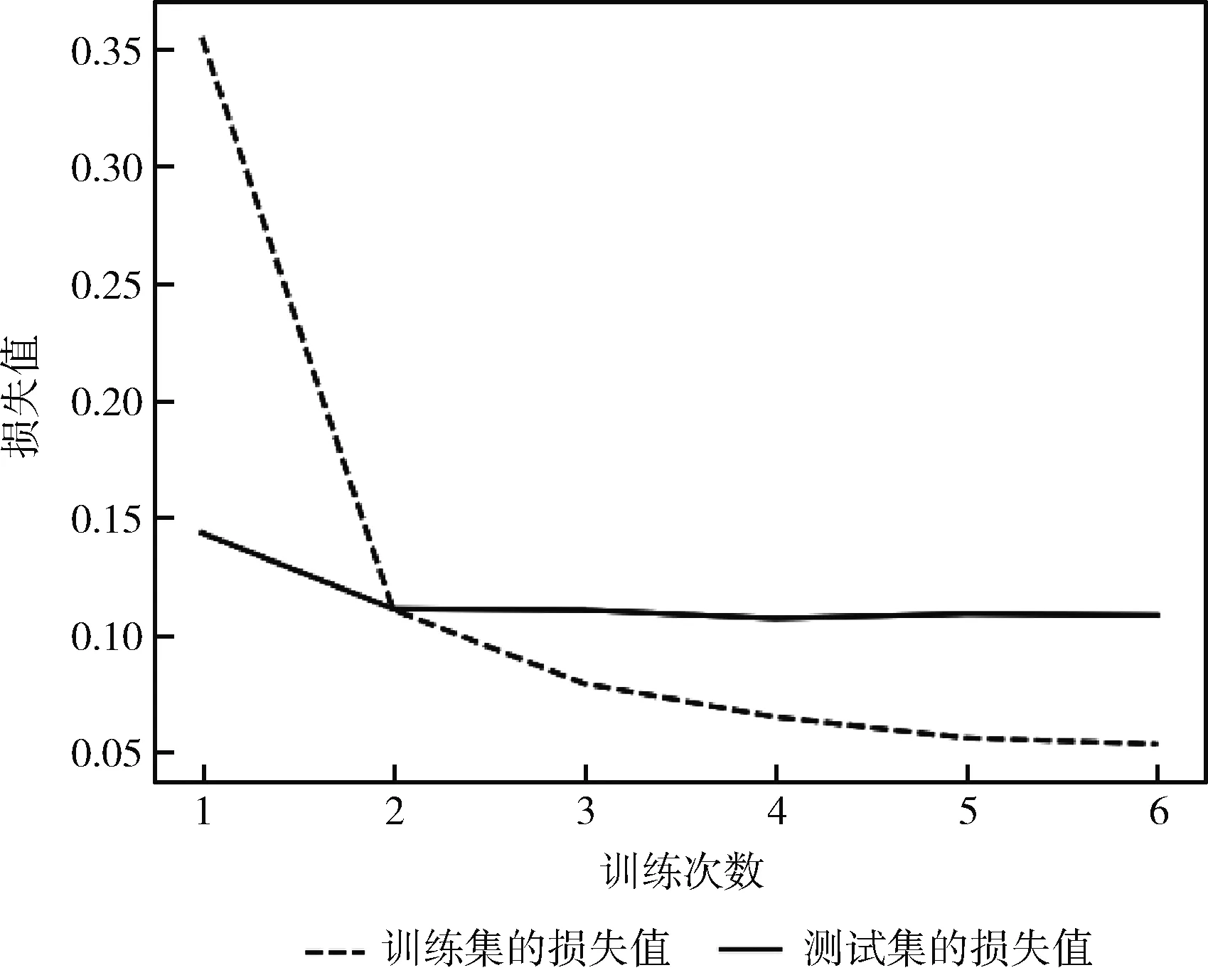
圖6 ERNIE模型的損失值變化
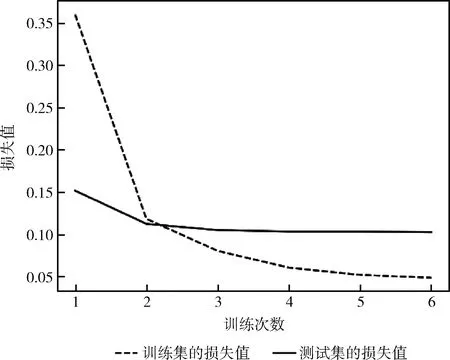
圖7 TF-IDF+ERNIE模型的損失值變化
兩種方法的訓練集和測試集的損失值在第2個Epoch都有明顯下降。在測試集上兩個模型的損失值對比如圖8所示。其中,ERNIE模型在第6個Epoch上達到了0.1080。而TF-IDF+ERNIE模型在第6個Epoch上就達到了0.1024,其收斂速度快,模型計算效率高。
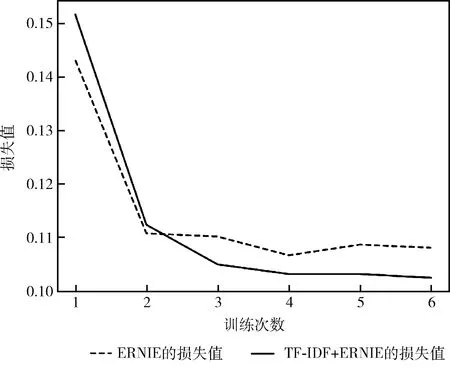
圖8 損失值對比
總之,通過實驗結果數據可以得出結論,本文提出基于TF-IDF加ERNIE模型的文本分類方法,在區級人大報告的內容分類工作中得到了不錯的效果,該方法在準確率、召回率和F1得分上都有明顯提升。將不同模型的分類效果進行結果比對,部分分類結果對比見表5。

表5 分類結果對比
其中,TF-IDF+ERNIE對這6段文本的分類預測為監督和代表工作的概率分別達到了96.69%、96.40%、95.33%、95.23%、94.93%、94.78%,由此可以看出該模型的分類效果不錯。
4 結束語
本文將基于TF-IDF的ERNIE模型應用于區級人大報告內容分類,通過對監督工作和代表工作這兩部分內容進行分類實驗,驗證了基于TF-IDF+ERNIE模型的優越性和有效性。在同一個數據集下TF-IDF+ERNIE模型與ERNIE、傳統的貝葉斯、邏輯回歸和SVM分類器模型進行實驗比對,表明了ERNIE模型不但學習了上下文的語義特征,還考慮了知識圖譜的信息,能夠理解連續詞語的相關關系。使得最大程度地理解了文本的原始信息,通過TF-IDF加入額外特征讓模型收斂更快。雖然模型引入了TF-IDF,但是加入的特征還比較單一,導致在實驗過程中的訓練時間還是無法與傳統學習方法的速度相媲美,以后還可以研究更多方面的特征。此外,由于語料的限制,算法性能還可以繼續提升。總之,區級人大報告內容的文本分類是一個重要且很值得投入研究的方向,針對智慧人大的研究還很少,有許多工作都需要繼續完善。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
南方人物周刊(2017年32期)2017-10-28 22:48:36
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
南風窗(2016年26期)2016-12-24 21:48:09
南風窗(2015年22期)2015-09-10 07:22:44
