基于聯合注意力生成對抗網絡的自動文摘模型
2021-06-28 12:42:36董張慧雅
計算機工程與設計 2021年6期
董張慧雅,張 凡,王 莉
(1.太原理工大學 信息與計算機學院,山西 太原 030600; 2.太原理工大學 軟件學院,山西 太原 030600;3.太原理工大學 大數據學院,山西 太原 030600)
0 引 言
關于自動文摘的研究方法主要兩種方法:抽取式方法[1]和生成式方法。抽取式方法主要提取原文中的重要句子或段落組成摘要,需要考慮摘要內容的相關性和冗余性。而生成式方法是基于對文檔的理解,然后歸納總結生成摘要,所以它更接近摘要的本質,然而,在抽象概括方面仍有很大的改進空間,這也是我們研究的主要方向。Rush等[2]提出基于注意力的端到端網絡模型來生成摘要,在此基礎上許多工作都得到了改進;See等[3]提出了一種指針生成器網絡(pointer-generator network),該模型通過指針從文檔中復制單詞,解決了未登錄單詞(out-of-vocabulary,OOV)的問題,還增加了一種覆蓋機制來解決輸出重復的問題;Paulus等[4]提出一種目標函數,該函數結合了交叉熵損失與從策略梯度得到的獎勵,減少了暴露偏差[5];Liu等[6]將生成對抗網絡[7]與強化學習的策略梯度算法[8]結合起來并應用到自然語言處理領域,它采用對抗策略訓練網絡,并取得較高的ROUGE分數[9]。Hsu等[10]提出了提取式和抽象式結合的方法生成摘要,使得文檔的上下文向量表示更準確地反映了文檔主旨。
以上方法都是基于單詞層注意力對文檔進行表征,忽略了句子信息,這對于非頻繁但重要的單詞并不友好,很容易丟失文檔中的重要信息。事實上,關鍵的句子往往反映了句子中的單詞也非常重要。為此,本文提出一種基于聯合注意力的生成對抗網絡模型,將句子的信息融入對單詞向量的表示中,減少對非重要句子中單詞的關注度并提高重要句子中單詞的注意力,從而提高了對文檔上下文向量表示的合理性,使得最終生成的摘要質量更高。另外,為了更好的訓練效果,提出一種聯合損失函數訓練生成器。
為了驗證本文所提模型的有效性,在公共數據集CNN/Daily Mail 數據集上進行實驗,并與相關主流模型進行對比,實驗結果表明,該方法可有效提高自動文摘的質量。
1 基于分層注意力生成對抗網絡的文摘生成
本文使用生成對抗網絡機制[7]訓練兩個模型:生成器和判別器。生成器采用編碼器-解碼器結構,編碼器通過雙向長短期記憶網絡(bi-directional long short-term memory,Bi-LSTM)和聯合注意力機制得到文檔的上下文向量表示,解碼器使用長短記憶神經網絡(long short-term memory,LSTM)生成摘要,最后將生成的摘要和參考摘要(人工總結的摘要)共同輸入到判別器中,迭代訓練生成器和判別器。整體模型如圖1所示。
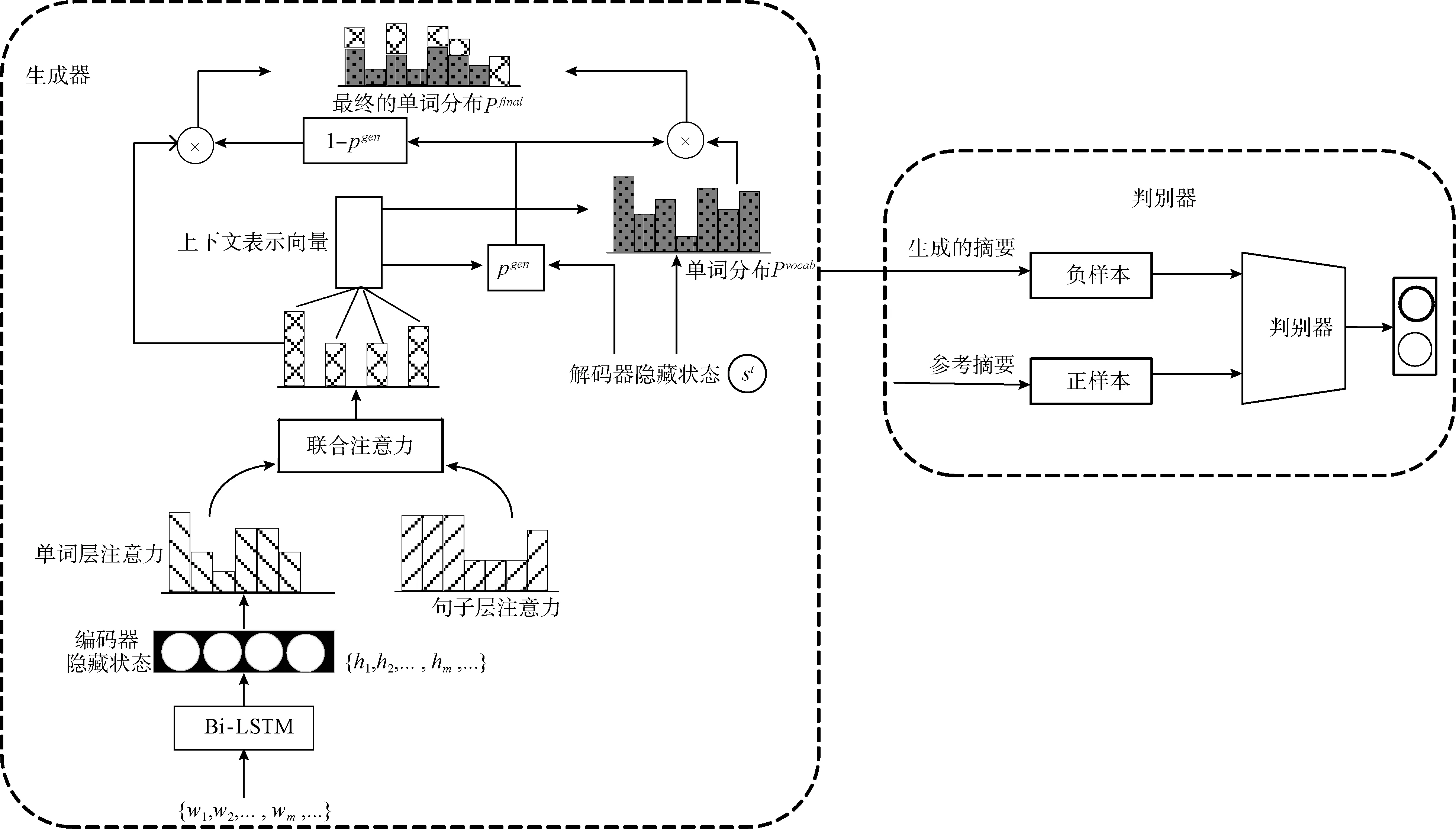
圖1 基于聯合注意力的生成對抗網絡訓練模型
1.1 聯合注意力機制
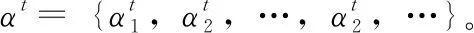
(1)
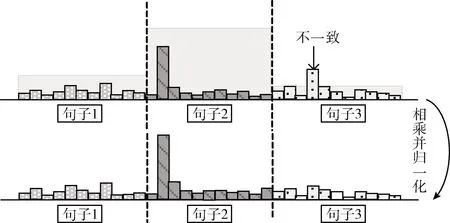
圖2 聯合單詞層和句子層注意力
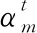
1.2 生成器生成摘要
生成器采用編碼器-解碼器結構,單詞序列w輸入Bi-LSTM轉換成編碼器隱藏狀態h={h1,h2,…,hm,…},在第t步時,解碼器(LSTM)接受參考摘要中的第t-1個單詞嵌入生成解碼器隱藏狀態st,根據編碼器和解碼器的隱藏狀態,得到在t時刻文本單詞的注意力分布為
(2)
αt=softmax(et)
(3)
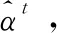
(4)
該上下文向量表示可以看作當前步對文檔的表征,再經過與解碼器隱藏狀態連接和兩個線性層,可以得到在固定詞匯表上的單詞分布,公式如下所示
(5)
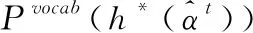
(6)
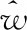
(7)
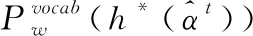
1.3 判別器判別摘要
判別器是一種二元分類器,其目的是區分輸入的摘要是由人產生的還是由機器產生的。因為卷積神經網絡在文本分類中顯示了極大的有效性[12],本文使用卷積神經網絡對輸入序列進行編碼。先使用不同大小的過濾器得到多種特征,然后對這些特征應用最大池化操作。這些合并的特征被傳遞給一個全連接的softmax層,最后輸出為真或為假的概率。
1.4 生成對抗網絡模塊
生成對抗網絡主要采用零和博弈的思想,生成器G與判別器D是博弈的兩方,判別器盡可能地區分輸入的摘要是由人生成的還是由機器生成的,而生成器盡可能地產生更真實的高質量摘要騙過判別器,這樣在博弈過程中生成器被訓練的越來越好,生成的摘要越來越真實,像人類寫的一樣,而判別器也被訓練的更加“聰明”,有更強的區分能力。生成器與判別器的最大最小博弈函數為式(8)
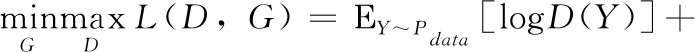
(8)
Y表示模型生成的摘要或者人工生成的參考摘要,D(Y)是判別器判別輸入摘要為真的概率,或者說是獎勵。越高的獎勵說明生成的摘要越好,判別器與生成器相互對抗,最后訓練的理想結果是判別器判別不出輸入的摘要是由人類生成的還是由機器生成的,同時生成器生成的摘要質量也很高。
2 損失函數
按照圖1所示的自動文摘生成模型,本文提出了由極大似然估計損失Lml、策略梯度損失Lpg、不一致注意力損失Linc以及句子層注意力損失Lsen構成的聯合損失函數用于訓練生成器。本節將依次介紹判別器、句子層注意力和生成器各自的損失函數。
2.1 判別器的損失函數
在生成器與判別器的對抗訓練過程中,判別器作為生成器的獎勵函數,它判別輸入的文本是由人工生成的還是由機器生成的。通過對判別器的動態更新,迭代地改進生成器,使其生成質量更好的摘要。一旦生成器生成高質量和更加真實的摘要,就重新訓練判別器,訓練判別器公式
Ldis=minΦ-EY~Pdata[logDΦ(Y)]-EY~GΘ[log(1-DΦ(Y))]
(9)
DΦ(Y)是判別器給輸入序列的獎勵,它代表輸入序列為真的概率,即判別輸入序列為人工生成的概率。Φ和Θ分別代表了判別器和生成器的參數集。該公式的含義是判別器給參考摘要盡可能高的分數,給生成器生成的摘要盡量低的分數,這樣損失函數的值才會小。
2.2 句子層注意力損失函數
為了鼓勵單詞層和句子層這兩個層的注意力在訓練過程中有一致的學習目標和一致性,即在該單詞注意力很高時該單詞所屬的句子注意力也很高,本文采用不一致注意力損失函數
(10)
在計算某個單詞的損失時,只選取其前k個單詞,對它們的單詞層注意力和所在句子的句子層注意力相乘并求和,依次計算T個單詞的損失函數,進行相加取均值得到整篇摘要的不一致損失,T是摘要的單詞總數。注意到如果采用兩階段的訓練方式,式(1)是唯一句子層注意力參與到編碼器的部分,不一致損失只有在端到端訓練時才加入到生成器的損失函數中。
為了得到句子層的注意力分布,本文參考了Nallapati等[11]的方法,采用雙層的循環神經網絡結構,第一層得到句子的表征,第二層作為分類器得到每個句子的注意力大小。首先第一層輸入句子中每個單詞的單詞嵌入,經過雙向的GRU(gated recurrent unit)網絡得到每個單詞的隱藏狀態,再經過向量求和得到每個句子的表征。第二層輸入剛剛得到的每個句子的表征,經過雙向GRU網絡和一個sigmoid函數,最終得到每個句子的注意力β,該網絡結構如圖3所示。
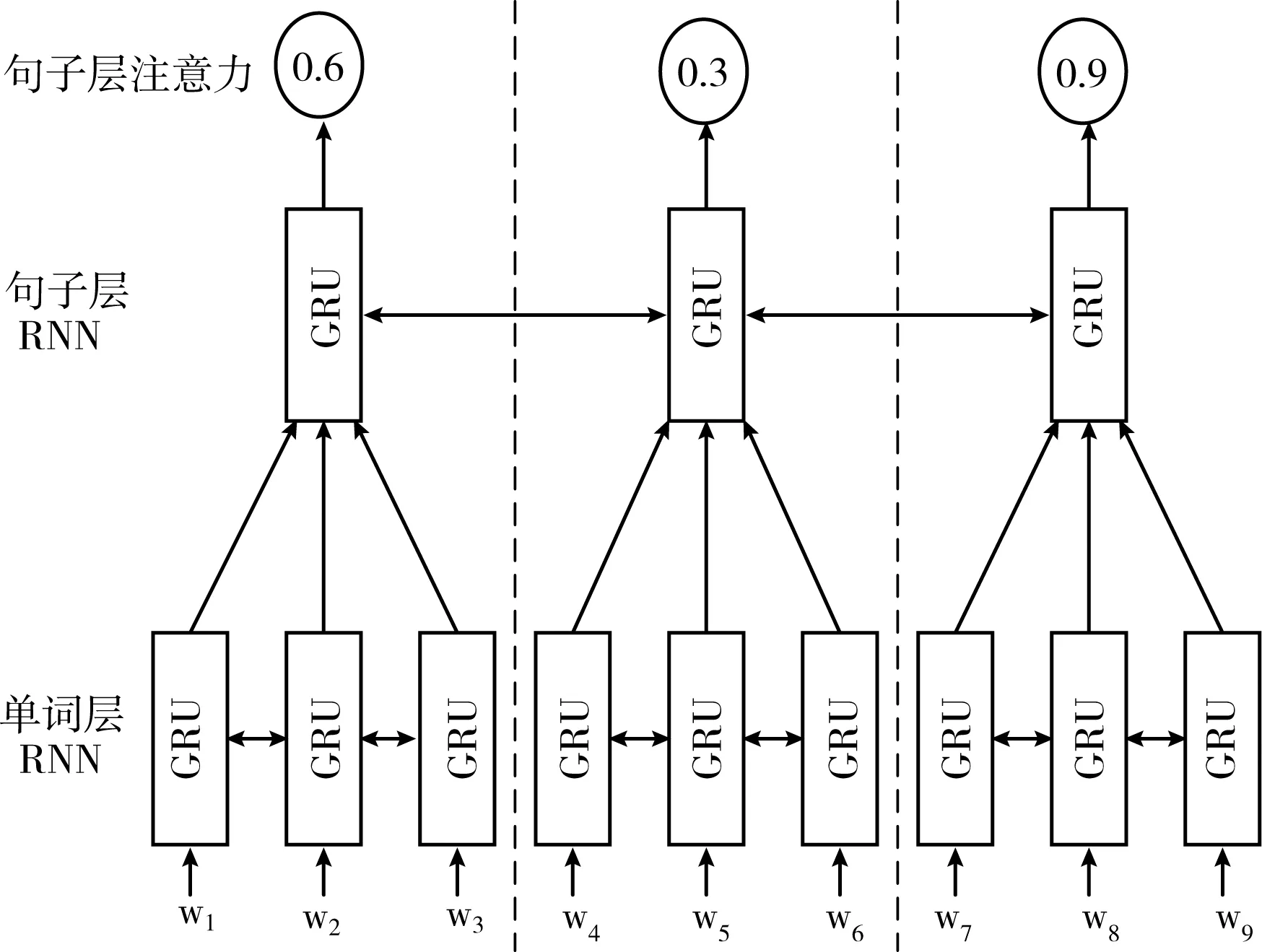
圖3 句子層注意力結構
在訓練句子層注意力網絡時,由于在頂層采用了sigmoid激活函數,所以本文采用交叉熵損失函數訓練網絡,損失函數如下
(11)
式中:gn∈{0,1}是第n個句子的真實標簽,N是參考摘要中的句子總數。當gn=1時,表示第n個句子含有的信息量高,若gn=0,則表示第n個句子含有的信息量少。而句子層注意力就是為了得到具有高信息量的句子,所以準確地為句子打標簽至關重要。為了獲得真實標簽g={gn}n,首先,通過計算句子sn和參考摘要的ROUGE-L值獲得文檔中每個句子sn含有的信息量,然后我們根據ROUGE-L值對句子排序并從高到低選擇信息含量豐富的句子。如果新句子可以提高已經選擇的句子的信息量,則把該句子的標簽gn置為1,并加入已經選擇的句子集合中,最后通過式(11)訓練句子層注意力網絡。
2.3 生成器的損失函數
當判別器更新后,再訓練生成器G,生成器的損失由極大似然估計損失Lml、策略梯度損失Lpg、不一致注意力損失Linc以及句子層注意力損失Lsen組成,分別賦予λ1,λ2,λ3,λ4權重,極大似然估計損失為式(12)
(12)
通過最小化極大似然估計損失,使得生成器生成的文本越來越接近參考摘要。由于極大似然估計存在兩個重要問題。第一,評價指標為ROUGE評價指標,而損失函數為極大似然估計損失,評估指標和訓練損失不同。第二,解碼器在訓練過程中每個時間步的輸入往往是參考摘要中的單詞表征,但在測試階段解碼器的輸入是上一步的輸出,一旦上一步出現錯誤,會影響下一步的輸出結果,這樣造成錯誤累計,形成暴露偏差。為了緩解上述問題,本文使用策略梯度算法對ROUGE-1進行了直接優化。生成器經過訓練,使判別器給的最終獎勵最大化,策略梯度損失如下
(13)
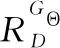
(14)
b(X,Y1∶t)是基線值以減少獎勵的方差。由于生成器加入了句子層注意力來更新單詞層注意力,需要再加上不一致注意力損失和句子層注意力損失,構成生成器的聯合損失函數如下
LG(Θ)=λ1Lml+λ2Lpg+λ3Linc+λ4Lsen
(15)
需要注意的是在分階段訓練時生成器的損失不包含不一致注意力損失和句子層注意力損失。
3 實驗結果與分析
3.1 數據集
本文實驗使用CNN/Daily Mail數據集[3,11],它收錄了大量美國有限新聞網(CNN)和每日郵報(Daily Mail)的新聞數據。每篇文章都有人工總結的參考摘要與之對應。本數據集有匿名版本和非匿名版本兩種,前者把所有的命名實體替換成特殊的標記(例如@entity2),后者保留原始的新聞內容。我們使用非匿名版本,其中包含287個、226個訓練對、13 368個驗證對以及11 490個測試對。固定詞匯表的大小是50k。
3.2 評估指標
實驗采用ROUGE評估指標,將生成摘要與參考摘要相對比,其中ROUGE-1和ROUGE-2指標是分別是1元詞(1-gram)和2元詞(2-gram)的召回率,ROUGE-L指標計算的是最長公共子序列(longest common subsequence)的得分,具體計算方法參見文獻[9]。
3.3 實驗及結果分析
為了獲得更好的實驗結果,本文實驗對獲取句子注意力模型(圖2)和整體模型進行了預訓練,詞嵌入均為128維,學習率設置為0.15,隱藏層大小分別為200和256。在預訓練獲取句子注意力模型時,限制原始文本的句子數和每個句子的長度為50。在預訓練整體模型時,把信息量高的句子(gn=1)作為模型的輸入,限制原始文本的長度為400,摘要的長度為100,批次大小為32。
為了探究句子層注意力對實驗結果的影響,本文設置兩種訓練方式:①分階段訓練;②端到端訓練。
實驗1:分階段訓練
實驗設置句子層注意力β為硬注意力,此時句子層注意力模型為一個二元分類器,把βn>0.5的句子作為整體模型的輸入,而β是通過預訓練得到的。實驗參數設置見表1。
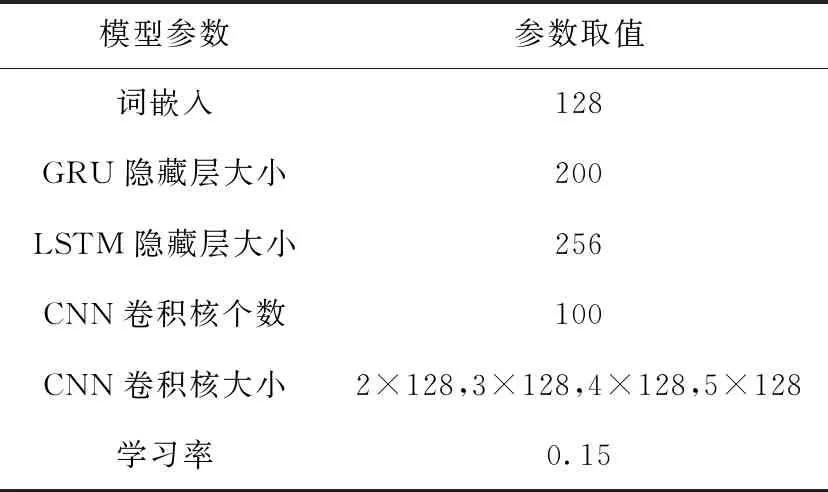
表1 本文模型參數
實驗2:端到端訓練
要最小化聯合損失函數(式(15)),其中λ1=λ3=1,λ2=λ4=5,在計算Linc損失時設置k=3。學習率降到0.0001,這樣可以保證訓練的穩定性,神經網絡模型采用Adagrad優化器進行優化。端到端訓練時模型的輸入為整篇文檔。實驗將本文提出的方法與主流方法進行對比,包括pointer-generator[3]、abstractive deep reinforce model(DeepRL)[5]、GAN[6]、unified model[10]。不同的方法進行實驗得到的ROUGE-1、ROUGE-2和ROUGE-L值見表2。
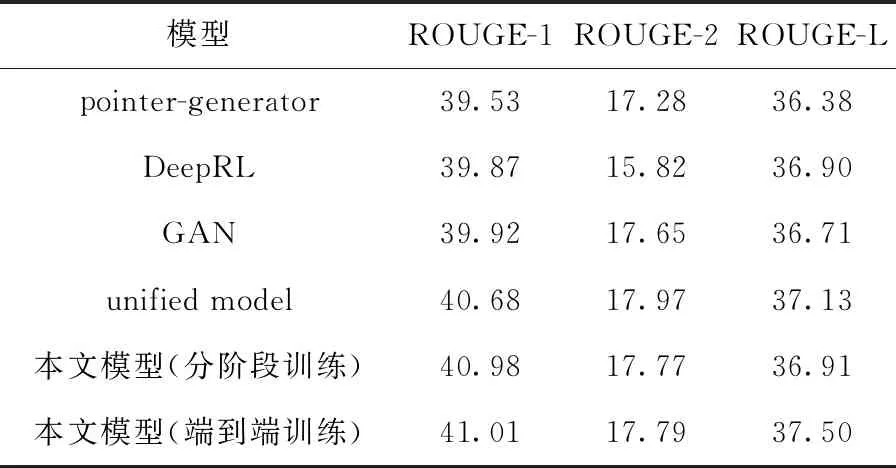
表2 不同算法的ROUGE值
每一行顯示了一個算法的結果,可以看出,主流方法表現較好的是unified model,ROUGE-1和ROUGE-L值分別為40.68和37.13,而本文模型采用分階段訓練方式時ROUGE-1值有所提高,為40.98,采用端到端訓練方式時ROUGE-1和ROUGE-L值均有所提高,分別為41.01和37.50,表明端到端的訓練方式可以獲得更好的訓練結果。綜上所述,本文提出的模型有效提高自動文摘的質量,同時由于結合了句子層注意力,從而可以準確捕捉重要單詞,表達的中心思想更加準確。
下面對這幾種模型和本文提出的模型生成的摘要進行比較,選取了其中一篇文檔作為實驗結果的展示,文檔內容與其匹配的參考摘要如圖4所示。對圖4所示文本,幾種不同模型生成的文摘如圖5所示。

圖4 樣例文檔和參考摘要
圖5給出了幾種不同模型的實驗結果,本文用下劃波浪線標示原文的重要信息,用粗體標示參考摘要與本文模型重合的部分,從結果可以看出,本文提出的模型可以生成更加準確的摘要,與參考摘要更加匹配,而其余幾種模型存在重復問題或者缺乏重要信息的問題(如下劃直線所示)。總體來看,本文提出的模型對自動文摘生成有改進作用。

圖5 幾種模型生成的文摘
4 結束語
本文根據越重要的句子包含越多的關鍵字,在生成對抗網絡的基礎上,加入句子層注意力,通過句子層注意力對單詞層注意力的調節,使得獲取的上下文向量表示更準確地表達了當前狀態的文檔信息,從而使得后續的文摘生成更加準確。另外本文在原有的生成對抗網絡損失函數上加入單詞層與句子層注意力的不一致性損失,反過來協調了句子層注意力。生成對抗網絡生成的句子具有很好的連貫性,再加上句子層注意力幫助生成的主旨更加準確,最終使得生成的摘要具有更好的連貫性和可讀性,實驗結果表明,聯合注意力對結果有了一定改進。本文提出的模型在自動文摘領域效果良好,能提升文摘的質量。在大規模文檔理解、分析和總結方面有廣泛用途。本文采用LSTM得到文檔的上下文向量表示,未來可考慮更好的方法對文檔進行表征,以使向量容納更多的文本信息。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
