X射線熒光光譜法結合優化k均值檢驗墨粉的研究
2021-06-24 04:43:14田師思齊恒慧王一端
激光技術 2021年4期
關鍵詞:優化
田師思,姜 紅*,齊恒慧,王一端,滿 吉
(1.中國人民公安大學 偵查學院,北京 100038;2.中國人民大學 統計學院,北京 100044;3.北京華儀宏盛技術有限公司,北京 100123)
引 言
隨著電腦的普及,人們的書寫習慣已經逐漸由傳統的手寫轉變為打印、復印。各種案件中打印或復印文件成為常出現的物證之一。通過對打印、復印墨粉成分進行分析,區分出不同品牌的墨粉,能為公安機關偵破案件提供有效線索[1]。
通常打印機所使用的墨粉是以荷電添加劑、染料、樹脂等成分為原料的復合產物[2]。不同的生產廠家采用不同的生產方式,使用不同的樹脂、染料、載體、荷電添加劑,導致不同品牌的墨粉在成分上存在差異,故可作為區分鑒別激光打印機打印文件的重要依據[3]。
目前,用來鑒別激光打印/復印墨粉成分的方法主要有喇曼光譜法[4]、掃描電鏡/能譜法[5]、紅外光譜技術[6]、裂解氣相色譜/質譜連用(pyrolysis gas chromatography mass spectroscopy, Py-GC/MS)法[7]等。喇曼光譜法因其所需樣品量小而廣泛應用于微量物證領域。但喇曼信號易受熒光干擾且靈敏度較低。在對有機化合物進行鑒定時,紅外光譜法優勢顯著,但樣品制備較為復雜。掃描電鏡/能譜法作為聯用技術,定性結果準確,但操作更為復雜。裂解氣相色譜/質譜聯用法則比較耗時。而X射線熒光光譜法具有樣品制備簡單,操作便利,分析速度快,且能同時分析復雜樣本中多種元素的優點。因其對輕元素的檢測具有局限性,目前對墨粉的檢測中大多用于測定墨粉中重金屬含量[8],將其應用于法庭科學中不同品牌墨粉的鑒別則是一種較為新穎的思路。
聚類分析是通過比較各數據源的相似程度,并將數據源分類到不同的簇中。優化k均值(powerk-means)聚類分析[9]針對普通k均值算法初值敏感進行優化,既削弱了初值對聚類結果的干擾,同時提高了算法的高維度表現,并且維度越高其優勢更為明顯。
1 實 驗
1.1 實驗設備
X-MET7000e能量散射型X射線熒光光譜儀(英國Oxford牛津儀器 ),Rh為陽極靶;電壓40kV,電流60μA。測試時間110s。
1.2 實驗樣本
不同品牌、廠家的常見打印、復印墨粉樣本28個(樣品表略)。
1.3 實驗過程
測定最優實驗時間為110s后進行重現性實驗,確證實驗在110s時具有良好的重現性,故以之為最優測定時間。
使用脫脂棉蘸取酒精擦拭樣品盒后,依此將墨粉放入樣品盒中,封膜,測定。其結果見表1。
2 結果與分析
2.1 根據元素成分進行分類
由表1可知,Fe,Ti,Cr,Ca,Mn,Zn這6種元素幾乎存在于所有樣本中,而含有Co,Sn,Ba,Cu 4種元素的樣本數量則較少,故上述10種元素的有無對初步分類價值較低,但其含量可以作為進一步分組的依據。因此選用Sr和Ni兩種元素的有無對28種樣本進行初步分類,可劃分為4類,如表2所示。其中,“+”代表“含有”;“-”代表“不含”。
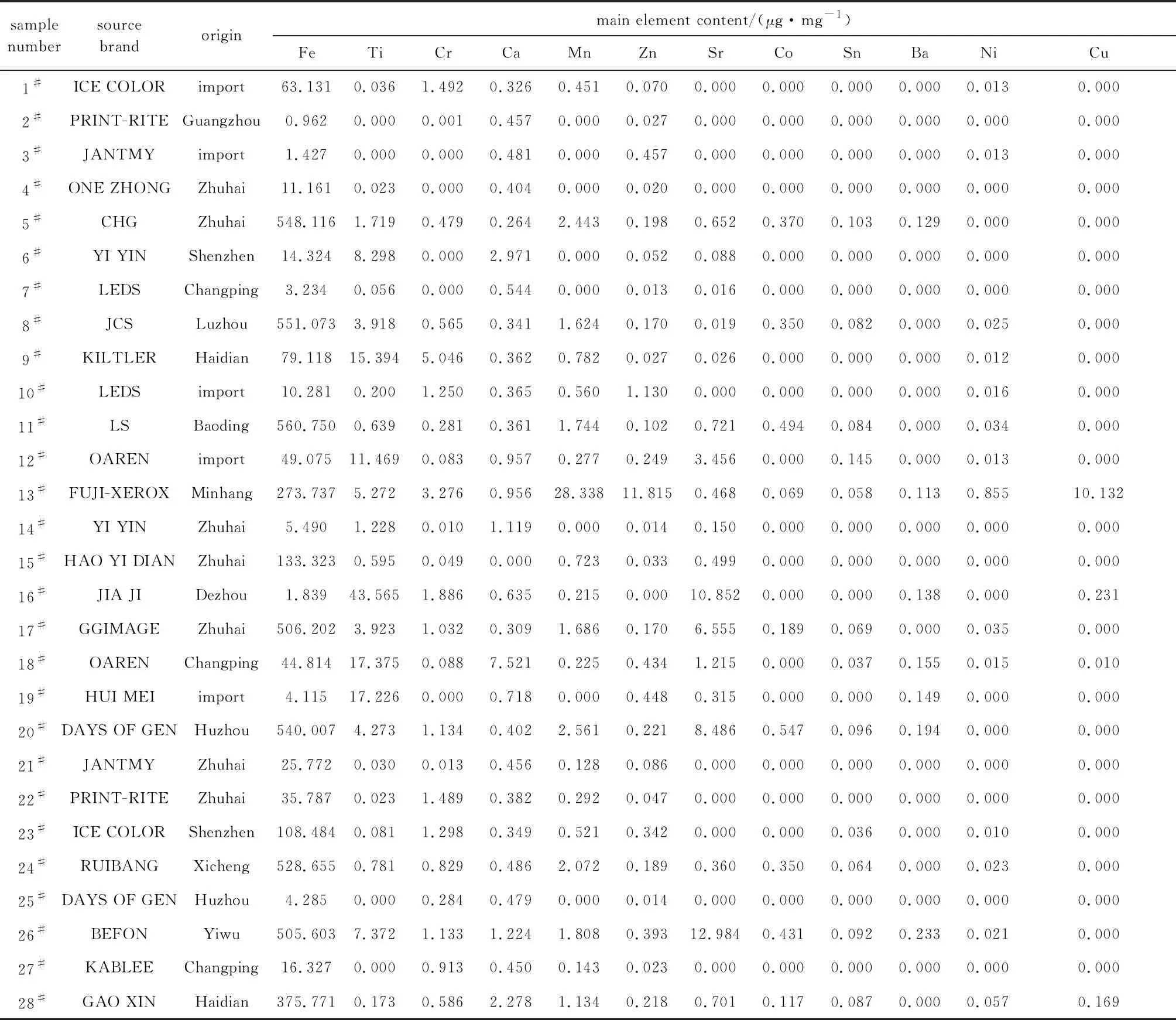
Table 1 The results of detection

Table 2 The classification results according to element composition
2.2 使用聚類分析法進行分組
2.2.1 數據分析 1類的12個樣本,2類的7個樣本和3類的6個樣本單純依賴人工分析,難以準確地以12種元素含量為變量將其進一步分組,得到可靠的分組結果,故而采用R語言[10],先利用肘方法[11]確定出最優簇的數目,再運用優化k均值算法以1~3類樣本的12種可穩定檢出的元素含量為變量分別進行聚類分析,獲得深入分組結果,最后采用矩積相關系數[12]驗證分組結果的可靠性。
2.2.2 最優簇數目的確定 在實現聚類算法時需要預設一個k值,即將數據源分為k個類別,k值的確定影響整個算法。在k值接近于真實值時,誤差平方和(sum of squares due to error,SSE)的斜率會發生驟變,從而在圖像上形成一個“肘部”,該拐點即為真實的k值。其中SSE可以作為評價聚類結果好壞的標準[13]。
運用R語言來確定真實k值,以1類為例,如圖1所示。折線在簇的數目為2時由陡直變為平緩,故而可以確定k=2。依此方法依此可得2類、3類的k值亦為2。
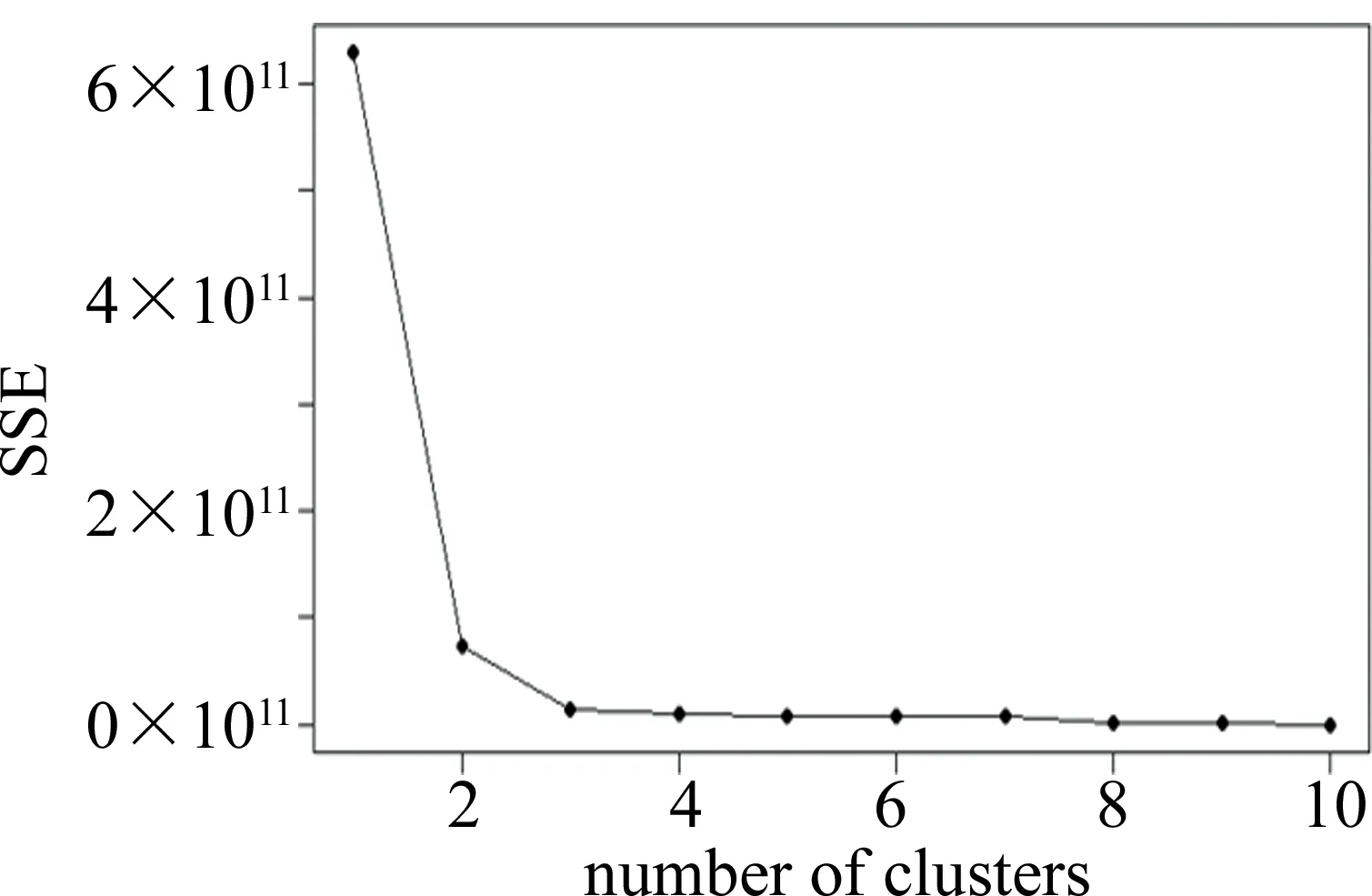
Fig.1 The first group inflection point graph
2.2.3 優化k均值聚類分析 經典的k均值算法進行聚類分析時有著簡單高效的優點[12],但是該種方法對初值十分敏感,倘若初值選擇不當,將會導致聚類結果無效。并且當數據維度非常高時,計算速度則會明顯下降。而優化k均值聚類分析能夠提升高維度表現力并且弱化對初值的要求[14]。
經典k均值算法是一種無監督分類算法,使用貪心策略,多重迭代求得近似解。其目標函數如下式所示:
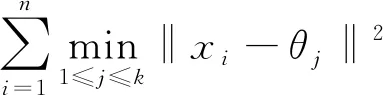
(1)
式中,k為簇的個數,xi為第i個樣本點,θj為第j個簇心。每次迭代,通過最小化歐幾里得距離‖xi-θj‖將每個樣本點xi分配到指定簇Ci。k均值算法得到的聚類結果比較依賴于簇心的初始值選擇,如果初始化不好,則可能僅得到局部最優解。
優化k均值算法在形成簇心的過程中使用加權算法,其目標函數如下:
‖xi-θk‖2)
(2)
式中,s為控制系數,Ms(y1,y2,…,yk)為借助連續且嚴格單調的指數函數g(y)取柯爾莫戈洛夫均值:
g(y)=ys
(3)
Ms(y1,y2,…,yk)=
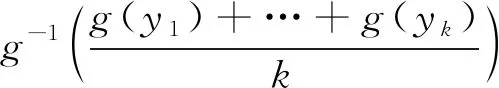
(4)
具體聚類步驟如下:
(1)在樣本中隨機選取k個樣本點充當初始聚集各個簇的中心點,選擇控制系數s的值。
(2)通過距離,計算第i個樣本對第j個簇心的權重ωij,其中:
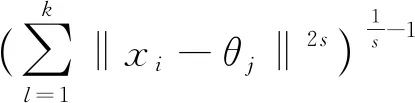
(5)
(3)計算完所有樣本點對所有簇心的權重后,更新新的第j個簇心θj,其中:
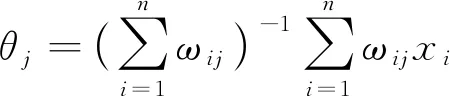
(6)
(4)反復迭代第(2)步和第(3)步直至收斂。
優化k均值算法在保持了原k均值算法的簡潔和時間復雜性的同時,降低了對簇心初值的依賴性。
2.2.4 分組結果 借助肘方法獲得的k值,分別使用優化k均值聚類分析對1~3類內的樣本進一步分類,將每一大組又分別分為兩小組,共將28個樣本分為7組,分組結果如表3所示。

Table 3 The classification results of power k-means
2.3 聚類效果驗證與結果分析
2.3.1 聚類效果評估 為驗證分組結果的有效性,計算組內數據的矩積相關系數。矩積相關系數用以描述兩個定距變量間聯系的緊密程度,當矩積相關系數越接近1時,表明兩個變量相關度越高。隨機抽取1#樣本,選取2-2組組內樣本,各組內抽取1個組間樣本,計算矩積相關系數。結果如表4所示,1#樣本與同一組內的10#、23#樣本相關度均在0.001水平上呈顯著相關[15],與組間樣本的矩積相關系數小于組內樣本,表明分組結果較為理想。
2.3.2 結果分析 聚類分析法分組結果中,3#、21#這兩個簡特美(JANTMY)的樣本均在2-1組,1#、23#這兩個冰彩(ICE COLOR)的樣本均在2-2組,穗彩(OAREN)、佳彩(JCS)、頤印(YI YIN)樣本亦與本品牌樣本歸為一類,沒有同一品牌的樣本被分為不同組。由此可知,上述5種品牌的打印、復印墨粉在元素的種類及含量上具備較強的同源性。領盛(LEDS)品牌的兩個樣本被分在不同組別中,可能由于產地不同所致。其余不同品牌的樣本,也可因墨粉元素含量的差異而被區別成若干組別。
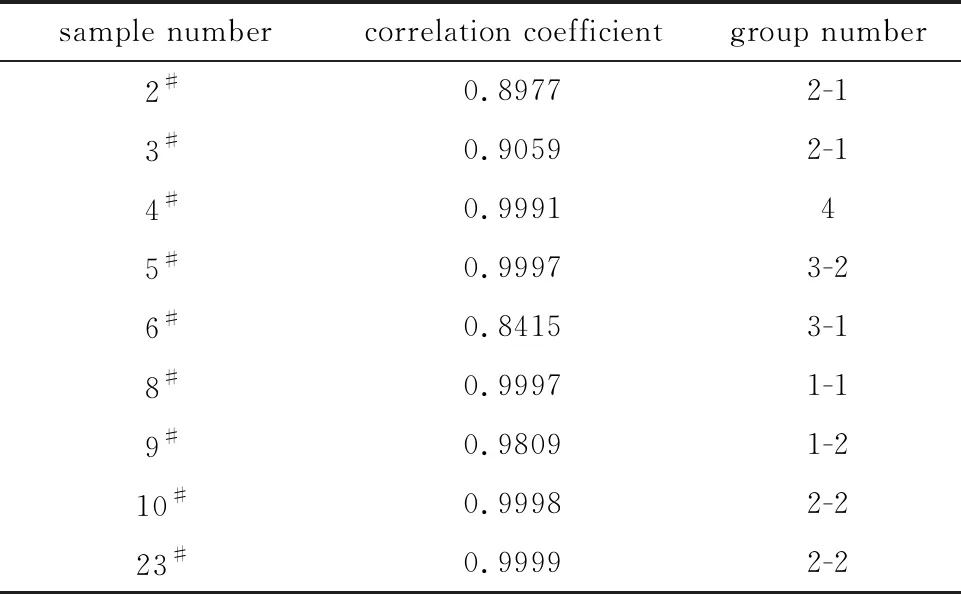
Table 4 The correlation coefficient of sample 1#
以所含樣本數量最多的1-1組為例,根據Ti/Cr值的大小可以繼續劃分為3組,如表5所示。再以1-1-1組為例,24#樣本Ca/Mn值為12.20,28#樣本Ca/Mn值
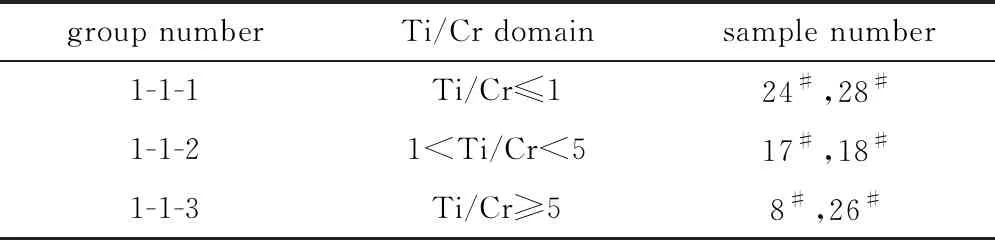
Table 5 The classification results based on Ti/Cr
為1.99,差距較大,所以根據Ca/Mn值的大小能將組內2種樣本區分開來。依照該方法,根據元素含量比值的差異可以分別將7組樣本繼續分組,能夠達到對打印、復印墨粉細化區分目的。
3 結 論
首先采用X射線熒光光譜法對墨粉樣本的金屬元素含量進行測定。而后依據元素成分的不同進行分類,又通過聚類分析法進一步分組,經矩積系數驗證后證明,該分組方法科學有效,且分組后各組數據特征明顯,能夠達到一定程度上區分不同品牌打印、復印墨粉的目的。構建了一種快速、無損對墨粉檢材進行鑒別的模型,分組效果理想,為司法鑒定墨粉物證提供了思路。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
