基于分布式數據庫的大數據平臺動態頁面數據生成技術
2021-06-24 07:24:50蘇莉娜
微型電腦應用 2021年6期
蘇莉娜
(江蘇省第二中醫院, 江蘇 南京 210019)
0 引言
隨著網絡技術和計算機科學的發展,我國的計算機網絡用戶數量不斷攀升,根據2019年《中國互聯網絡發展狀況統計報告》顯示,截止到2019年底,我國互聯網用戶數量達到了9.87億,比2018年同期增長約9.4%[1-3]。互聯網用戶數量增長的背后是網絡數據爆發式增長,如何使網絡用戶在海量數據中集中篩選有用信息,節省時間提高上網查詢效率是一個突出問題,其次,現有的數據結構由傳統的嵌入式HTML 網頁靜態數據變成了以語音、視頻等為載體的動態數據,相比于靜態數據,其篩選難度更大[4-5]。因此,本文結合動態頁面特點,建立了動態頁面腳本提取系統,在分布式數據提取基礎上對動態頁面的腳本信息進行提取,最后對系統的功能進行了測試分析。
1 分布式數據處理
MapReduce是一種建立在分布式數據存儲基礎上的數據云計算方法[6-7],它是將分布式數據庫中的大量數據進行分解,將數據庫逐漸分解成需要的目標節點,之后從整合的目標節點中尋找需要的數據并將數據匯總。MapReduce數據處理流程如圖1所示。

圖1 MapReduce數據處理流程
由圖1可知,首先在數據輸入端將分布式數據庫中的數據分解為幾個splite集合,之后根據map函數對splite集合中的數據進行匹配計算,匹配后的數據經過middle result數據整合后以函數形式輸出結果,最后數據經過函數反解,以規定的表現形式輸出結果。
數據處理的前提是數據的安全性問題,為此本文專門開發了符合數據庫特點的數據安全訪問流程,如圖2所示。
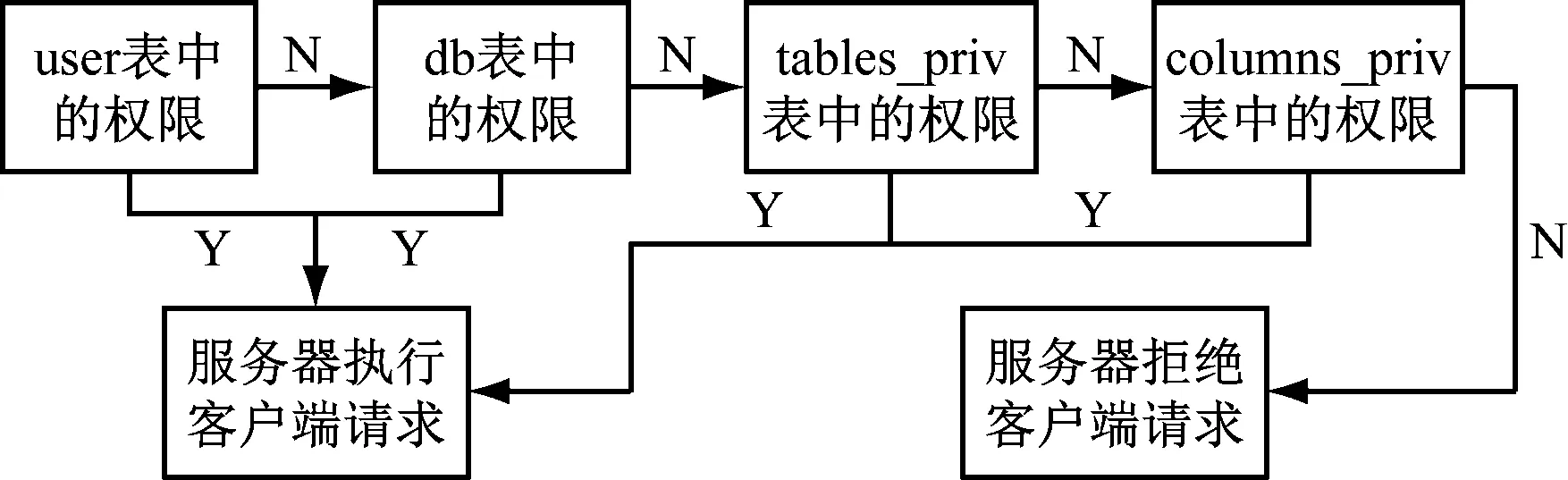
圖2 數據訪問流程
由圖2可知,用戶依次進行user權限、db權限、tables-prive權限、columns-prive權限認證,根據安全等級的不同,采取不同層級的認證訪問權限。
2 腳本提取子系統
為了對動態頁面實現信息采集,需要在動態頁面和系統數據庫間增設腳本提取系統,以處理提取數據的臨時存儲和數據篩選交換。
腳本解析系統的工作流程如圖3所示。

圖3 腳本解析流程
由圖3可知,首先在HTML網頁文件中構建DOM樹,根據JavaScript中目標信息與DOM樹的關系,采取二元化的信息處理方式,解析環境初始化后提取HTML網頁文件中的腳本信息,腳本提取完成后運行腳本,若腳本是一個open()類函數,則保存URL,否則重構DOM樹,重復上述流程。腳本解析的難點是DOM 解析,它的原理是將對象按照模型樹的方式,在HTML網頁文件中將網頁信息用結構化的方式展現。
根據目前計算機軟硬件的發展特點,需要采用有針對性的數據調動方式和程序以克服不同軟件條件下作業命令和數據格式不兼容的弊端[8-9]。本文開發了適用于動態信息提取和MySQL數據庫特點的MapReduce 調度算法。算法架構如圖4所示。
由圖4可知,作業池是將所有的工作任務按照任務間的邏輯關系進行分類,在同一個工作任務下可按照時間順序、優先順序等進行任務細化分解。實時資源列表是為了提高調度效率設置的具有列表黑名單功能的信息篩選功能,它是根據作業池向資源池發送的Task Scheduling信息,采用兩次發送兩次接收的模式,若資源池只收到一次Task Scheduling請求,則表明該節點是非法的,將其列入黑名單。
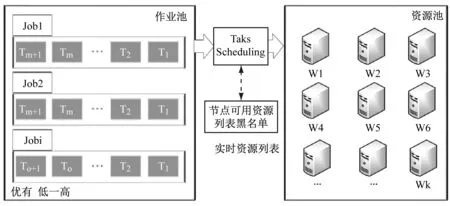
圖4 算法架構
按照以上算法架構,建立了調度算法流程,如圖5所示。
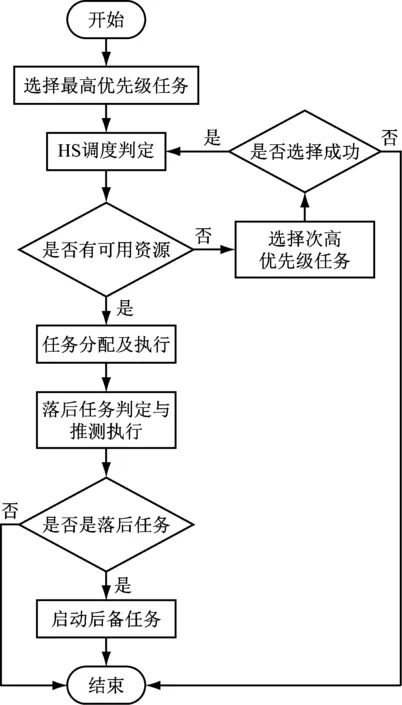
圖5 調度算法流程
由圖5可知,算法的第一步是選擇最優任務,算法按照預定的規則將作業池中的任務進行優先級別排序,同時根據任務特點從資源池匹配與之對應的節點。HS調度判定是作業任務和資源節點間的匹配調度過程,若資源池中節點無法匹配任務,則HS調度判定命令會選擇下一個緊鄰的任務進行資源池中節點的匹配。落后任務判定與推測執行是對于級別有所調整的執行任務進行優先級別的調整,并利用資源池節點進行匹配。
腳本提取系統數據文件存儲結構,如圖6所示。
由圖6可知,crawldb是系統連接的爬行數據庫,是對網頁的數據采集記錄進行跟蹤;jscrawldb數據庫包含兩個子系統,是對頁面中JavaScript文件進行存儲;Segments數據庫是對每一個完成訪問的頁面進行信息存儲,將每一個頁面存儲生成一個單獨的文件;Linkdb是一種網頁鏈接數據庫是對所有訪問的網頁地址進行存儲。
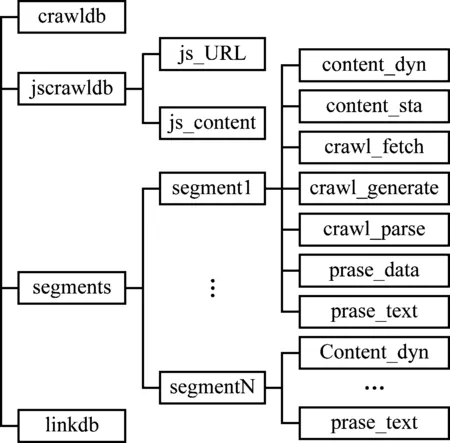
圖6 數據存儲結構
根據以上腳本提取方式,建立了動態頁面信息采集系統架構,如圖7所示。

圖7 動態頁面信息采集系統架構
由圖7可知,首先系統根據篩選種子從系統白名單中對數據進行抓取,對于抓取的網頁,利用腳本提取系統對網頁腳本進行提取,按照頁面腳本信息對頁面數據進行解析處理并篩選,最后根據篩選結果對篩選數據進行翻轉,以數據及網頁信息的形式將篩選結果進行保存。
3 系統測試分析
動態頁面數據生成系統是針對音視頻等動態數據進行提取的以對象為目標的信息捕捉系統,根據系統數據處理流程和腳本提取方式對系統的性能進行了測試分析,測試中選擇某市科技局網站為對象,對網站中的動態信息進行采集,并與其他采集方式對比。
3.1 測試環境
系統集成模擬系統由4臺并聯的計算機組成。系統測試軟硬件的組成如表1所示。

表1 測試軟硬件
3.2 測試結果
系統完成測試后對科技局網站進行了靜態數據提取,提取結果如圖8所示。
由圖8可知,相比較于動態網頁數據,靜態數據提取技術能有效提取頁面的有效信息。
本文以對比的方式分析了系統在腳本加入前后系統抽取有效信息數量和提取效率,測試結果如表2所示。
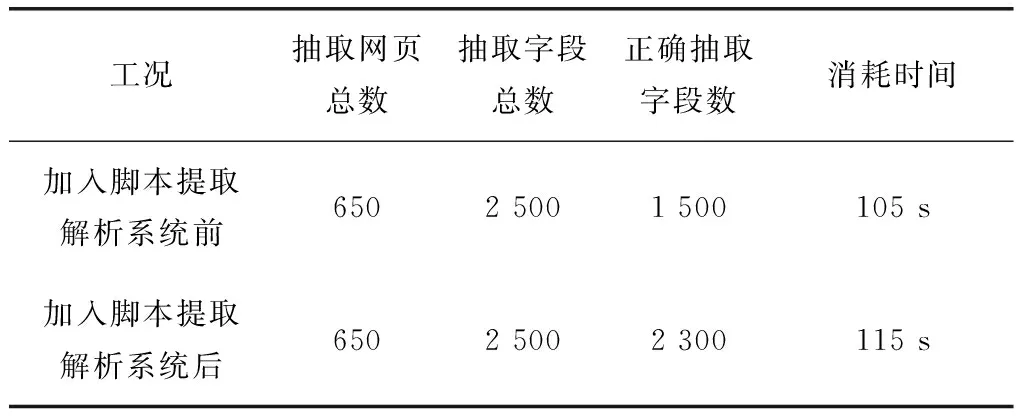
表2 數據提取效果
由表2可知,在抽取網頁總數和字段總數相同的前提下,加入腳本提取解析系統后其提取的準確率上升了32%,而系統消耗的時間與原來相比只增加9.5%,因此該腳本提取解析系統達到了預定功能需求。
4 總結
隨著動態網頁信息的豐富,網頁中的數據類型也有所豐富,用戶的上網體驗效果更佳,與此同時,動態網頁中的信息采集難度也隨之增加。本文以從分布式數據庫為基礎,開發了適用于動態網頁的腳本解析系統和數據調度方式,在分析了分布式數據庫類型基礎上對動態頁面信息采集系統進行了架構分析,最后對系統的應用效果進行了測試,結果表明加入腳本提取解析系統后其提取的準確率上升了32%,而系統消耗的時間與原來相比只增加9.5%。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
