基于圖像處理與卷積神經網絡的煤矸識別方法
2021-06-24 07:24:46武國平梁興國胡金良張秀峰
微型電腦應用 2021年6期
武國平, 梁興國, 胡金良, 張秀峰
(1.國家能源集團神華準格爾能源有限責任公司, 內蒙古 鄂爾多斯 010300;2.天津美騰科技有限公司, 天津 300385)
0 引言
卷積神經網絡(Convolutional Neural Networks, CNN)是機器學習中的重要分支,前饋神經網絡(Feedforward Neural Networks)涵蓋了卷積計算,而且具備了深度結構,是深度學習(Deep Learning,DL)的代表算法之一。卷積神經網絡在分類識別以及預測算法中,具有結構簡單、訓練高效、分類精度高的特點,是近年廣泛應用于計算機視覺(Computer Vision,CV)領域中圖像檢測、物體識別、姿態估計等,自然語言處理(NLP),以及自然科學場域中物理學、氣象學、地質學等的經典神經網絡[1-6]。
基于圖像的煤矸識別方法,是實現干法選煤的重要基礎。基于卷積神經網絡的煤矸識別算法,經過實驗、分析、驗證,是可以實現高精度的煤矸識別的可靠性算法,是具備實際應用價值的。
1 研究框架
本研究采用卷積神經網絡模型,以內蒙古準能集團哈爾烏素項目廠煤矸圖像為研究樣本,通過圖像處理后,運用卷積神經網絡模型ResNet18,將圖像數據在網絡模型中進行訓練,并通過該模型將圖像內的各種深層特征信息提取出來,從而達成煤矸分類以及識別的功能。總體研究框架的諸多流程如圖1所示。
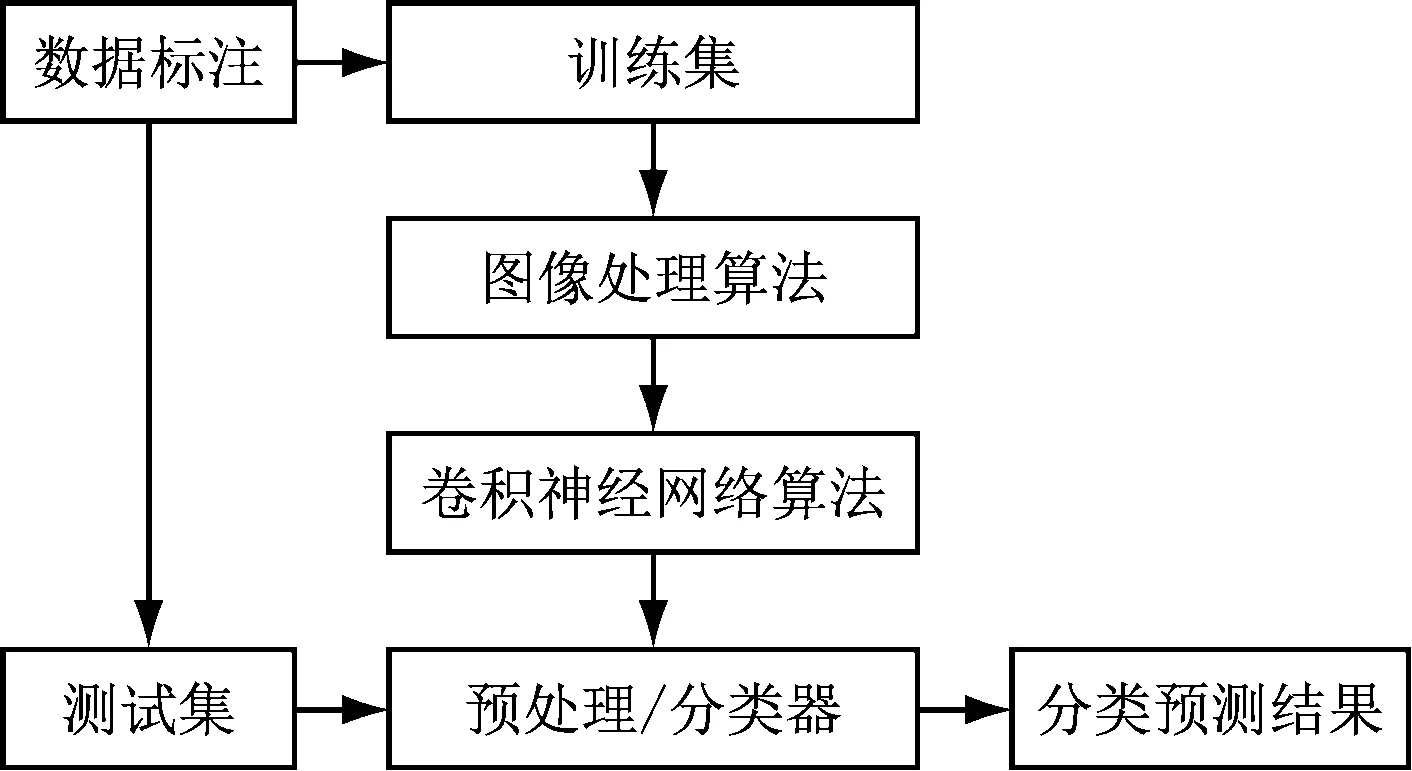
圖1 基于圖像的煤矸識別與分類研究框架流程
本研究針對煤矸進行的自動分類與識別應用監督學習的相關策略。首先,相關人員逐一標注工業相機采集的煤矸樣本數據,從中取出一些標注圖像數據當作訓練集,另外一些標注圖像數據被當作測試集。訓練過程中每迭代一次,則將此次迭代訓練過程中用到的圖像樣本當作驗證集。最后,自動識別測試集中諸多類型的煤矸,并進行自動分類。
2 樣本采集與標注
準能的原煤以含低/高灰,低/高熱值的動力煤為主,需實現三分類識別,分別為精煤、中煤、矸石。通過工業相機采集的樣本,如圖2所示。
圖2(a)為準能集團的精煤樣本,精煤顏色為黑色,其中部分鏡質組在燈光下會呈現鏡面反光特征,使得整體呈現黑亮,同時硬度較小導致形狀輪廓較為圓潤;圖2(b)為中煤樣本,中煤為精煤與矸石的混合物,顏色偏灰,總體特征介于精煤和矸石之間;圖2(c)為矸石樣本,矸石根據成分不同呈現不同的顏色特征,此處為白色,同時由于硬度偏大,棱角較為分明。

(a) 精煤樣本

(c) 矸石樣本
通過現場樣本采集,共采集80 000張煤矸圖像,后經過人工分選(經驗與化驗結合),對80 000張煤矸圖像進行人工標注,以指導監督式學習。
3 圖像處理
圖像處理是煤矸識別過程中一個非常重要的環節。由于采集的環境不同,如光線均勻度不夠、亮度變化、分辨率、采集設備自身變化等引起的煤矸圖像采集存在亮度不一致、對比度不夠、像素不足、圖像噪聲等問題存在。為了確保神經網絡學習與推理的圖像具有一致性,需對采集的圖像進行處理,避免環境不同導致的識別分類精度下降。該研究采用直方圖均衡、中值濾波、歸一化進行圖像處理,使得輸入給神經網絡模型的圖像質量相一致,增加分類以及識別精度。
3.1 直方圖均衡
直方圖屬于點操作,它逐點變更圖像的相應灰度值,盡可能讓不同灰度級別均呈現出數量相同的像素點,讓直方圖逐步達到平衡態勢。直方圖均衡能夠讓輸入圖像轉換為在各個灰度級上均有像素點數相同的輸出圖像(也就是說輸出了平的直方圖)。直方圖均衡用于提升全局對比度,這種方法對于背景和前景都太亮或者太暗的圖像非常有用,如圖3、圖4所示。

圖3 直方圖均衡處理前

圖4 直方圖均衡處理后
3.2 中值濾波
中值濾波處理信號時采取了非線性的方法,所以中值濾波器具有非線性的特征。從一定程度上來講,中值濾波能夠消除線性濾波導致的圖像細節模糊問題,很有效地濾除圖像掃描噪聲以及脈沖干擾。中值濾波的進行,既能夠除掉孤點噪聲,又能夠使圖像保持自身的邊緣特性,圖像不會出現顯而易見的模糊,更適宜于本科研的煤矸識別,如圖5、圖6所示。
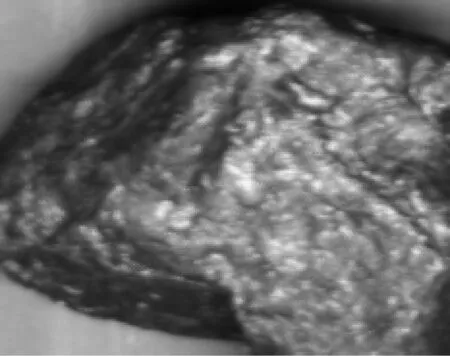
圖5 中值濾波處理前

圖6 中值濾波處理后
3.3 歸一化
圖像的歸一化,歸一化就是將原始數據歸一到相同尺寸,目的是使不同成像條件(拍攝距離)下獲取的煤矸圖像尺寸具有一致性。根據不同的現場應用中需要識別的煤矸粒度大小,以及采用全卷積的ResNet18網絡結構,將圖像尺寸歸一至224pixels×224pixels,以適應現場應用與網絡模型,如圖7、圖8所示。
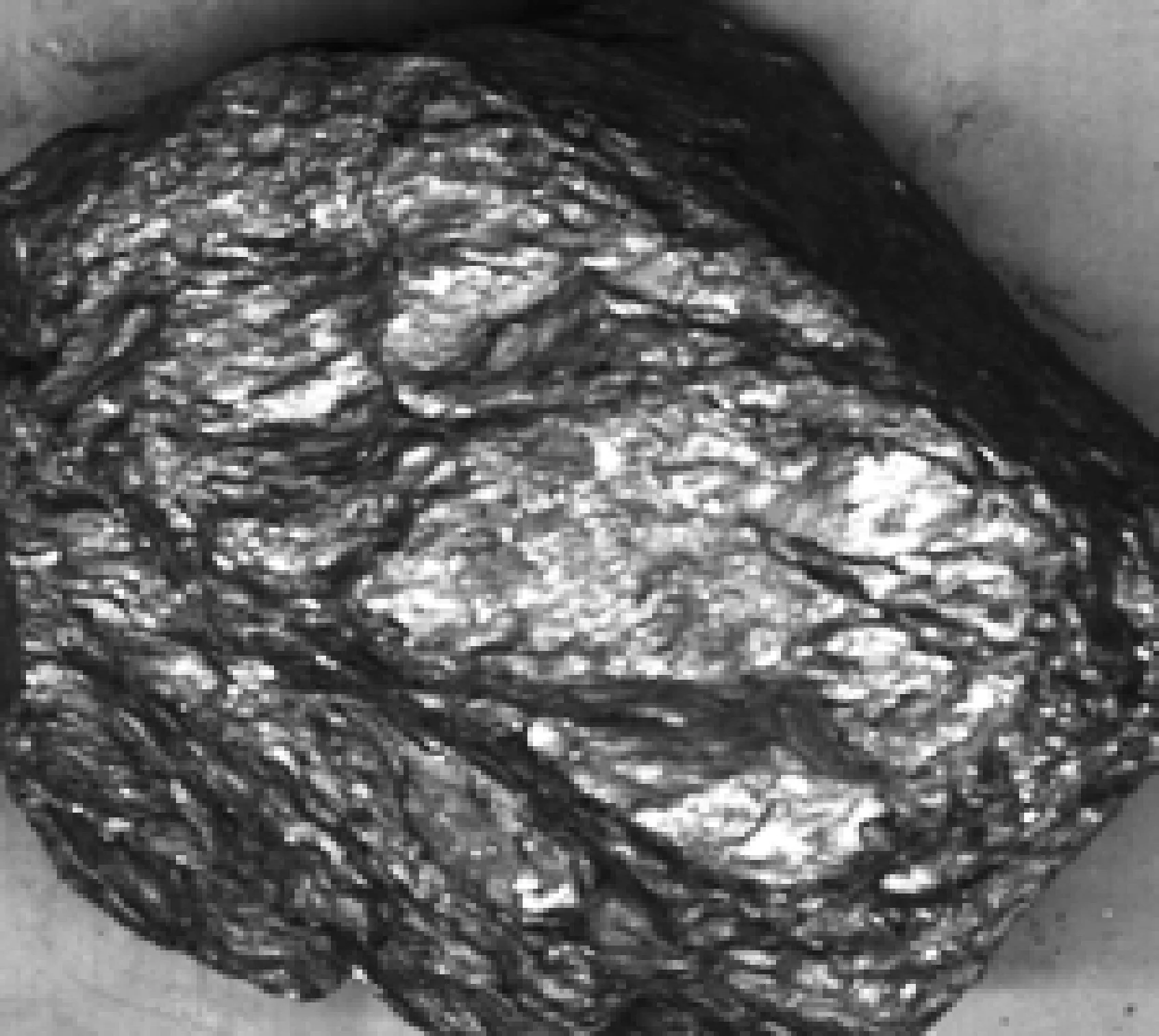
圖7 歸一化處理處理前

圖8 歸一化處理處理后
使用上述圖像處理方式,可以將圖像進行有效的質量提升,對模型識別分類精度有大幅提升。
4 神經網絡訓練與調參
Residual Block是ResNet18的基本結構,每組Block通過ShortCut將其輸入和輸出進行Element-Wise疊加。該加法比較簡單,網絡的計算量和參數不會額外增加,反而能夠提高模型訓練的效果以及速度。這個模型的結構比較簡單,但能夠非常有力地化解模型層數加深出現的退化現象。具體地,每個Residual Block中包含兩個相同輸出通道數的3×3卷積。假如存在不同的輸出、輸入維度,能夠針對Residual Block進行線性映射變換維度,并連接到接下來的層。ResNet18基本結構,如圖9所示。

圖9 ResNet18基本結構
設定輸入圖像尺寸為224×224×3。
第一步經過卷積核大小為7×7,步長為2,輸出為64個通道的卷積層,得到64個大小為112×112的特征圖。
第二步通過核大小為3×3,步長為2的最大池化后,卷積為64個56×56的特征圖。
第三步將64個56×56的特征圖依次輸入8個Residual Block,每兩組Block的通道數依次遞增,分別為64、128、256、512,第二、三、四組Block得到的特征圖分辨率依次降低2倍,經過四組block后特征圖大小變為7×7。
最后將512個7×7大小的特征圖經過平均池化后接全連接層,通過SoftMax輸出各類別的概率。
激活函數可以看作卷積神經網絡模型中一個特殊的層,即非線性映射層。卷積神經網絡在進行完線性變換后,都會在后邊疊加一個非線性的激活函數,在非線性激活函數的作用下數據分布進行再映射,以增加卷積神經網絡的非線性表達能力[7]。激活函數選用Relu函數。該函數有兩個優點,一是在輸入為正數的時候,不存在梯度飽和問題;二是Relu函數只有線性關系,不管是前向傳播還是反向傳播,計算速度都很快,如圖10所示。
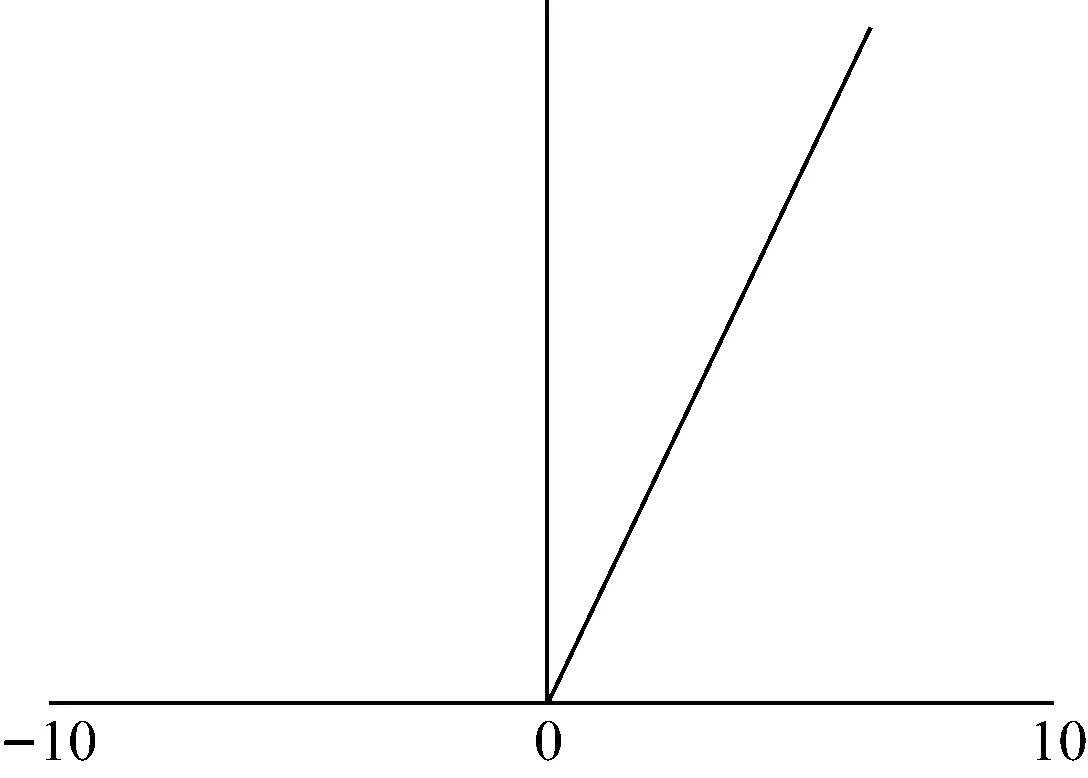
圖10 f(x)=max(0,x)
損失函數借助交叉熵。交叉熵能夠描述期望輸出(概率)以及實際輸出(概率)的相應距離,即交叉熵本身的數值越低時,兩個概率分布反而更加接近。假設概率分布p為期望輸出,概率分布q為實際輸出,H(p,q)為交叉熵,如式(1)。
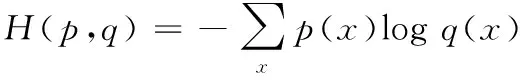
(1)
5 研究實驗過程
5.1 研究實驗數據準備
將兩組標注后的樣本進行拆分,分為訓練樣本以及測試樣本,如表1所示。

表1 樣本分類表
其中,訓練樣本為50 000張,測試樣本為30 000張。
用于訓練的數據組成為:數據集共50 000張,分為三類。每類數據分別為煤樣本20 000張,矸石樣本20 000張,中煤樣本10 000張。
用于測試的數據組成為:數據集共30 000張,分為三類。每類數據分別為煤樣本10 000張,矸石樣本10 000張,中煤樣本10 000張。
5.2 研究實驗模型調參
ResNet18網絡訓練基于Caffe深度學習框架[8],BatchSize為32,Base_LR為0.001,激活函數借助Relu來強化非線性,損失函數借助交叉熵損失函數,采取Poly學習策略。訓練數據包含50 000張圖像,煤、中煤和矸石樣本接近2∶1∶2。
6 實驗結果
此實驗模型處于測試集以及訓練集層面的精度,展示了損失函數的需要變化狀況,如圖11、圖12所示。

圖11 訓練精度結果
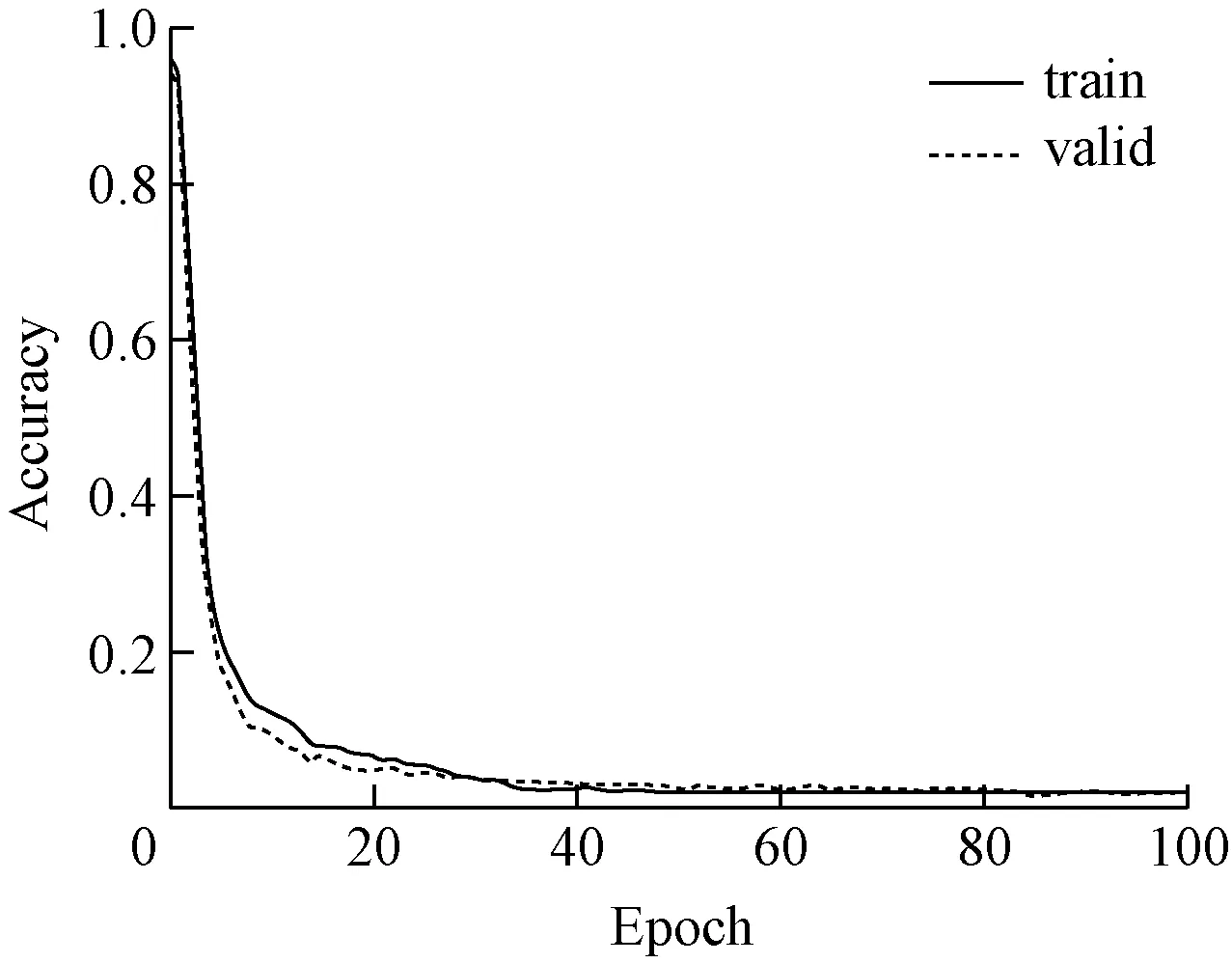
圖12 訓練損失結果
由此可知,模型訓練時,訓練次數越多其精度也就越大,模型本身的損失函數隨之持續降低。
測試集圖像中各煤矸識別精度,如表2所示。
由表2可以看到,測試集的測試精度能夠超過99%,識別分類精度非常高,超過了傳統的煤矸識別工藝,滿足工業應用的要求。
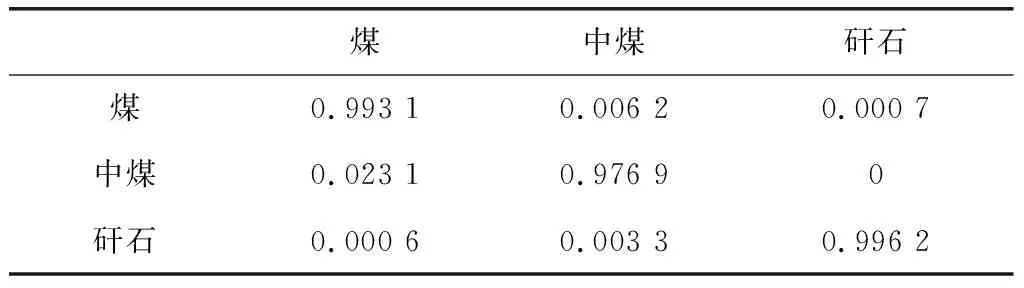
表2 測試精度結果表
7 總結
本研究實驗顯示,ResNet18模型可以用來建立煤與矸石的自動分類以及識別模型。眾所周知,神經網絡系統的學習必須要借助高水平、數量足的標注數據,用于訓練和測試。本研究針對寧夏與內蒙古的煤矸圖像設計的圖像處理方法與訓練的卷積神經網絡模型,準確識別煤矸的比例超過99%,模型的分類準確性能夠滿足工業應用的需要,具備多煤種良好的魯棒性,可以在不同的原煤煤質下得到相同的分類精度,具備推廣應用條件。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
