基于GBDT-LR融合算法的胎兒窘迫預診模型研究
2021-06-17 08:37:58曾冬洲鄭宗華謝婧嫻
自動化儀表 2021年5期
曾冬洲,鄭宗華,謝婧嫻
(1.福州大學電氣工程與自動化學院,福建 福州 350108;2.廈門大學附屬婦女兒童醫院,福建 廈門 361003)
0 引言
胎兒窘迫是指胎兒在子宮內因缺氧導致的呼吸窘迫綜合癥,是造成圍產期胎兒死亡的主要原因[1]。胎心監護是胎心胎動宮縮圖(cardiotocography,CTG)的簡稱,是一種對胎兒宮內健康狀況進行檢測評估的主要手段。臨床上的CTG信號采用胎心率電子監護儀實時監測并記錄下不斷變化的胎兒瞬間心率。CTG信號包含胎心率(fetal heart rate,FHR)信號曲線和宮縮(uterine contraction,UC)信號曲線。通過這兩條信號曲線,醫生能夠實時地了解胎動和宮縮時胎心的反應,并對宮內胎兒的缺氧程度進行評估。但是CTG評估的結果容易受到醫生主觀經驗的影響,導致漏診胎兒錯過最佳醫生干預時間或者誤診胎兒剖腹產出,使醫療資源得不到有效的利用。因此,為了降低胎兒窘迫的漏診和誤診率,臨床上有必要采用一種更為客觀的評估方法來輔助醫生作出準確、有效的診斷決策。
近年來,隨著機器學習技術的發展,機器學習的算法模型在醫療決策領域的應用也越來越多,因此有不少學者嘗試先利用計算機軟件自動化提取FHR信號特征和UC信號特征,然后引入機器學習技術對提取到的特征數據進行分類預測。文獻[2]將支持向量機算法應用到胎兒窘迫數據集上,取得了較好的分類預測效果。文獻[3]利用神經網絡模型,很好地克服了胎兒窘迫數據的非線性問題,也取得了較好的分類效果。文獻[4]提出使用XGBoost算法建立胎兒健康評估模型。該模型分類的準確率和效率較其他算法模型都有一定的提升。文獻[5]基于模糊算法對胎兒狀況進行分類評估,也取得了良好的診斷效果。綜上可以看出,這些胎兒窘迫診斷問題的單一模型已經有了相對廣泛的應用與研究,而對于多模型融合的診斷方法還有進一步研究的空間。文獻[6]通過采用梯度提升決策樹(gradient boosting decision tree,GBDT)和邏輯回歸(logistic regression,LR)模型相互融合的方法對個人信貸風險進行了預測。預測結果表明,融合后的模型較單個模型的預測效果有顯著的提升。本文將這種模型融合的方法應用到胎兒窘迫預測中,基于真實的CTG信號數據建立胎兒窘迫分類模型,并對分類結果進行評估。
1 模型介紹
1.1 邏輯回歸模型
LR是一種廣義的線性回歸模型,具有算法實現簡單、運行速度快和內存占用少等優點,因而被工業界廣泛地應用于分類問題中。對于二分類問題,邏輯回歸模型的基本實現思想是利用Logistic函數將由線性回歸計算得到的目標值映射至[0,1]區間,然后比較映射后的值與分類閾值間的大小:大于閾值的可歸為一類,小于閾值的歸為另一類。記輸入的訓練集為{(x1,y1),…,(xi,yi),…,(xN,yN)}。其中:xi∈R;yi∈{0,1};i=1,2,…,N。則可設xi屬于Y=0和Y=1的概率分別為:
P(Y=1|x)=π(x),P(Y=0|x)=1-π(x)
(1)
由式(1)可推導出其似然函數,即聯合概率分布函數設為:
(2)
對式(2)取對數,可得:
(3)
式中:w為權重向量;w×xi為w和xi的內積。
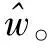
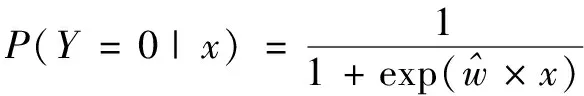
(4)
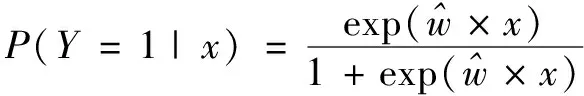
(5)
對于待分類數據x,只需把x分別代入式(4)和式(5)中。若P(Y=0|x)>P(Y=1|x),則x屬于Y=0類;否則,x屬于Y=1類。
1.2 GBDT模型
GBDT是一種迭代的決策樹算法,其基礎決策樹模型選用分類回歸樹(classification and regression tree,CART)。在采用原始的數據特征生成首棵決策樹后,GBDT模型在后續迭代生成決策樹的過程中,都是以當前合計損失函數最小化為目標生成新的決策樹,生成過程直至損失函數的殘差趨近于零時停止。此時將會得到若干棵決策樹。因此,當有新的數據樣本輸入GBDT模型時,將模型中所有決策樹的輸出結果進行線性加權,即可得到最終的分類結果[7]。
GBDT算法的核心流程如下。
輸入:訓練集記為{(x1,y1),…,(xi,yi),…,(xN,yN)}。其中:xi∈R,yi∈{0,1},i=1,2,…,N。
(1)對弱分類器進行初始化:
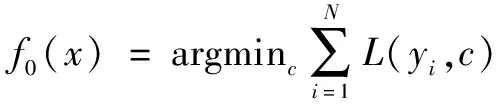
(6)
式中:f0(x)為初始決策樹;L(yi,c)為損失函數;c為滿足L(yi,c)最小化的常數。
(2)對于迭代輪數m=1,2,…,M,計算如下。
①逐個計算樣本i=1,2,…,N的負梯度如下:
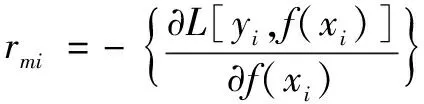
(7)
式(7)中,f(x)滿足:
f(x)=fm-1(x)
(8)
②利用所有樣本及其負梯度方向(xi,rmi)構建出決策樹Tm。其包含有J個葉子節點,且第j個葉子節點對應的區域為Rmj(j=1,2,…,J)。
③對決策樹Tm的J個葉子節點,逐一計算最佳擬合值:
(9)
④本輪迭代可得分類器如下:
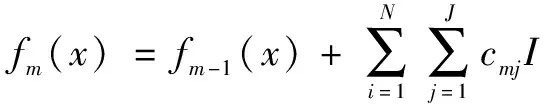
(10)
式中:I為訓練樣本i在第j個葉子節點區域的示性函數。
I滿足:
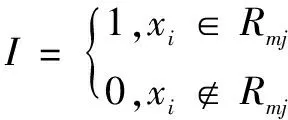
(11)
(3)將由步驟(2)中產生的M個分類器線性加權求和,可以得到最終的分類模型如下:
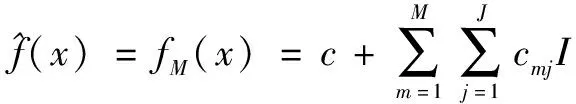
(12)
1.3 GBDT-LR融合模型
從1.1節邏輯回歸模型的算法原理中可以看出,對于特征關系簡單的數據集分類問題,邏輯回歸模型具有多方面的處理優勢。但是當數據集的特征關系較為復雜時,邏輯回歸這種線性模型相比于其他非線性模型來說,其對數據特征關系的學習表征能力有限,進而不能充分挖掘特征數據集中包含的潛在信息。因此,為了提升邏輯回歸模型對特征非線性關系的學習能力,在訓練該模型之前,需要人工進行復雜的特征工程,增加數據集的有效特征和特征組合,使特征關系趨于線性化。其缺點是有效的特征工程需要在與數據集相對應的業務背景專家指導下展開,這將增加數據處理的成本。
GBDT是基于Boosting方法的決策樹集成模型。而決策樹的每一個非葉子節點都對應數據的某一特征,自頂部根節點至底部葉子節點的所有路徑都代表著數據樣本集中可能存在的特征組合形式。且由1.2節中式(12)可知,所有決策樹在GBDT算法中都會被分配不同大小的權重。決策樹的權重越大,其內含路徑對應的組合特征重要度越大。為了從GBDT模型中獲得有效的組合特征,可以對數據樣本訓練所得GBDT模型的葉子節點分布情況進行觀察。當某數據樣本通過GBDT模型時,其在每一棵決策樹上都將激活一個葉子節點,記錄下所有被激活葉子節點的位置并進行編碼。按此方法對所有樣本激活的GBDT葉子節點位置編碼進行統計,挑選被激活次數較多的葉子節點作為組合特征加入至原始數據中。此外,對GBDT選取合適的決策樹棵數和最大葉子節點數,既可以對數據特征進行有效的組合,又可以避免其過擬合,從而充分挖掘數據中的隱藏信息。
綜合上述對GBDT模型和LR模型的分析,可采用GBDT與LR融合的方式建立有效的胎兒窘迫預診模型。首先,利用原始數據訓練GBDT模型,這樣得到的每顆決策樹上的每個葉子節點都將是新的特征向量的一個維度。如果對得到的所有決策樹上的葉子節點進行獨熱編碼,則在新特征向量中有樣本落入的葉子節點對應的特征位編碼值取1,其余特征位編碼值取0。GBDT-LR模型分類流程如圖1中所示。
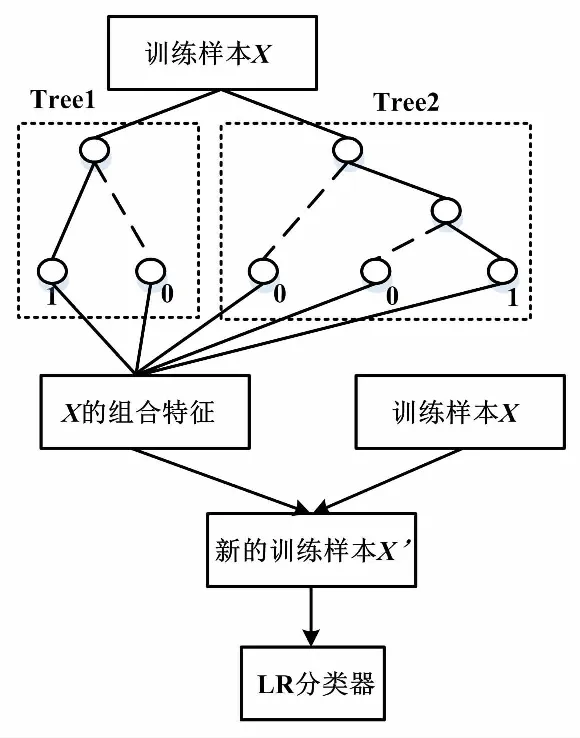
圖1 GBDT-LR模型分類流程圖
對于包含有Treel和Tree2兩棵決策樹的GBDT模型,當輸入某訓練樣本X時,假如其分別激活了Treel上的第一個葉子節點和Tree2上的第三個葉子節點,則與這兩個葉子節點位置相對應的新特征向量中的元素編碼為1,剩余元素編碼為0。因此得到的新特征向量可表示為[1,0,0,0,1]。最后利用合并后的新特征和原始特征一起訓練LR模型,得到最終的分類結果。
2 試驗數據與環境
2.1 數據描述
本試驗采用來自福建省某醫院的脫敏臨床數據。CTG信號曲線如圖2所示。

圖2 CTG信號曲線
通過廣州三瑞醫療器械有限公司開發的SRViewCTG軟件,可以基于國際婦產科聯合會(international federation of gynecology and obstetrics,FIGO)指南[8],對曲線特征進行提取。提取后的特征屬性和類別標簽描述如表1所示。其中的類別標簽Y為臨床醫生根據胎兒分娩后的真實情況進行的分類:0表示正常;1表示異常。特征提取后的數據集共含1 958個有效樣本,其中包括1 795個正常樣本和163個異常樣本。
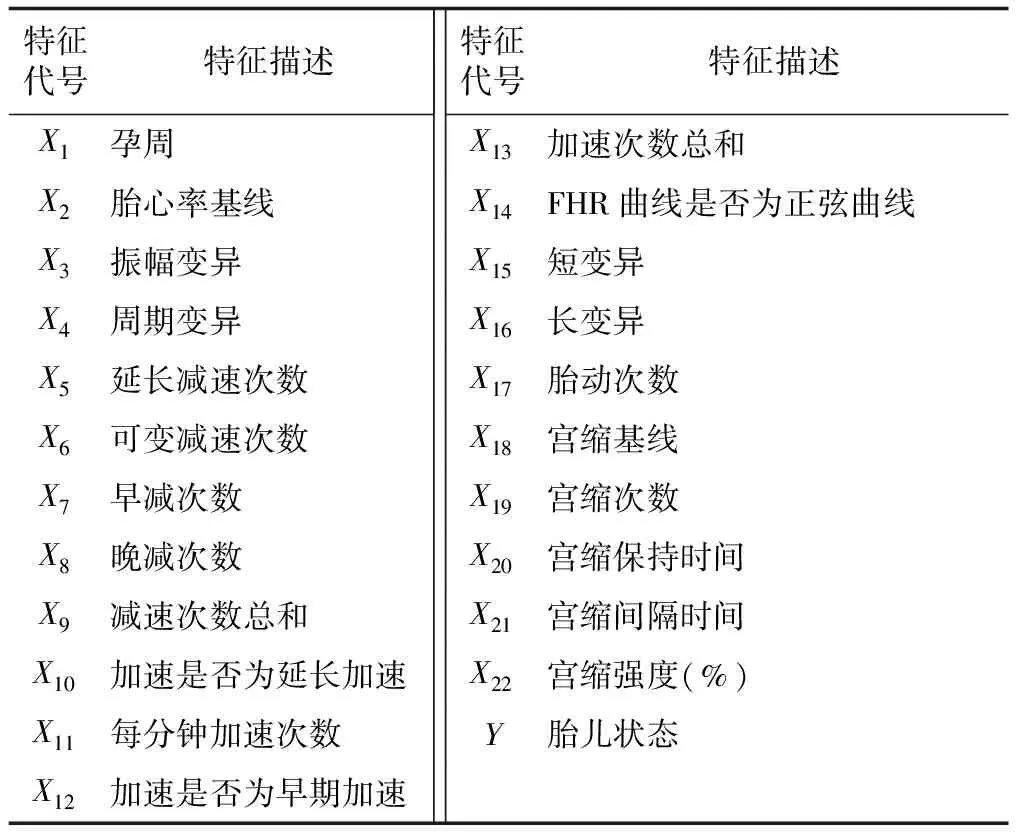
表1 胎兒CTG數據的特征描述和類別標簽
2.2 數據預處理
本文在試驗前對數據的預處理工作主要包括:對含有缺失值的樣本采用劃分正常和異常的方法通過各自特征屬性的均值分別進行填充;對二元屬性特征X10、X12和X14進行數據轉換。另外,為了消除各特征屬性間量綱的影響,對所有數據樣本采用零均值標準化的歸一化方法進行處理。歸一化公式如下:
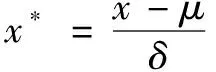
(13)
式中:μ和δ分別對應于原始數據的均值和方差。
2.3 樣本均衡處理
在醫療診斷領域中,一般定義異常樣本為正類樣本(少數類),正常樣本為負類樣本(多數類)。試驗過程中,在進行模型訓練之前需要對數據中的正負類樣本比例進行觀察。如果樣本類別不均衡時直接使用原始樣本進行模型訓練,則將使得模型傾向于關注占比高的那類樣本,即對醫療診斷問題的負類(正常樣本)的識別率高、對正類(異常樣本)識別率低。所以在訓練模型前需要對樣本進行均衡處理[9]。對于正負類樣本數量不均衡的情況,通常有兩類方法可以保持正負類樣本數量的平衡:使正類樣本的數量增加的方法稱為過采樣;使負類樣本數量減少的方法稱為欠采樣。本文采用Borderline-SMOTE算法[10]對正類樣本進行過采樣。Borderline-SMOTE算法的基本思想如下。
①對每個正類樣本,確定m最近鄰樣本(包括正類樣本和負類樣本)。
②對每個正類樣本,計算其最近鄰的m個樣本中負類樣本的個數n。
由上述思想可以看出,該算法利用正負類間邊界附近的正類樣本隨機生成若干新的正類樣本。
本試驗原始數據的正負樣本比接近1∶11。將原始數據集的70%劃分為訓練集和驗證集、剩下的30%作為測試集,在劃分的同時選用了分層劃分法保證這70%的數據和30%的數據中正負樣本比接近相等,防止測試集中出現少數類樣本占比極低的情況。然后,利用Borderline-SMOTE算法對上述70%的數據進行均衡處理。處理完成后,其正負樣本比接近1∶1。
2.4 試驗環境
本試驗的軟件環境為Windows10_64 bit,Python 3.5,Jupyter Notebook 5.6.0。硬件環境為Intel(R)6 Core(TM)i3-3240 3.39 GHz CPU,8.0 GB內存。
3 試驗與分析
3.1 模型評估指標
模型評估指標需要針對具體問題進行選取。有效的評估指標將有助于各模型在分類性能上的對比分析。本文結合胎兒窘迫漏診率和誤診率兩個指標的物理意義,采用靈敏度(Sensitivity)和特異度(Specificity)作為模型評估的指標。其計算公式如下:
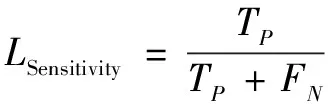
(14)
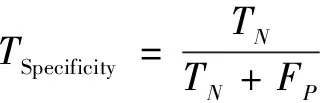
(15)
式中:TP為真陽性(true positive,TP);FP為假陽性(false positive,FP);TN為真陰性(true monegative,TN);FN為假陰性(false negative,FN)。
TP代表在測試集中真實標簽為1(異常胎兒),模型預測結果也為1的樣本個數。FP代表在測試集中真實標簽是為0(正常胎兒),模型預測結果卻為1(異常胎兒)的樣本個數。TN代表在測試集中真實標簽為0(正常胎兒),模型預測結果也為0的樣本個數。FN代表在測試集中真實標簽為1(異常胎兒),模型預測結果卻為0(正常胎兒)的樣本個數。模型的靈敏度越大,表示模型對異常樣本的識別能力越強,即模型的漏診率越低;模型的特異度越大,表示模型對正常樣本的識別能力越強,即模型的誤診率越低。
為了綜合考慮上述兩個指標,本文也采用接受者操作特性(receiver operation characteristre,ROC)曲線下面積(area under the roc curve,AUC)的大小對模型性能進行評估。模型分類性能越好,則AUC值越大。最大AUC值為1,最小為0。另外,為了比較各個算法模型在胎兒窘迫數據集上的時間復雜度,本文將調用Python的第三方庫函數time計算各模型運行所需消耗的時間。
3.2 試驗結果與分析
經過對試驗數據預處理、數據集劃分、數據均衡處理和基于網格搜索法調參的GBDT-LR模型訓練后,利用訓練好的最優參數GBDT-LR模型對測試集進行分類。另外,本次試驗也分別比較了邏輯回歸(logistic regression,LR)、支持向量機(support vector machine,SVM)、反向傳播(back propagation,BP)神經網絡梯度提升決策樹(gradient bossting decision tree,GBDT)和XGBoost等單模型在測試集上的分類效果。以上所有單模型都經過網格搜索法調參達到最優。同時,為了保證各模型分類效果的穩定性,所有指標數據均為十折交叉驗證后取平均值的結果。不同模型性能對比結果如表2所示。
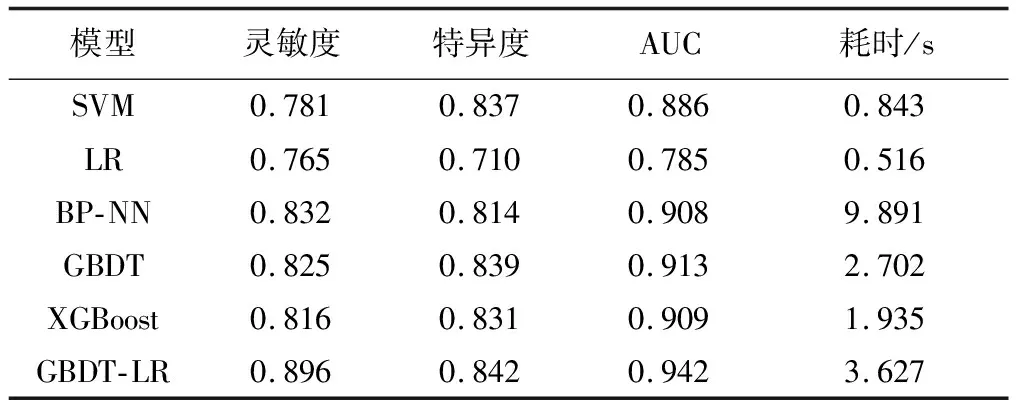
表2 不同模型性能對比結果
圖3為處于最優參數時,訓練集和測試集上的GBDT-LR模型的ROC曲線。
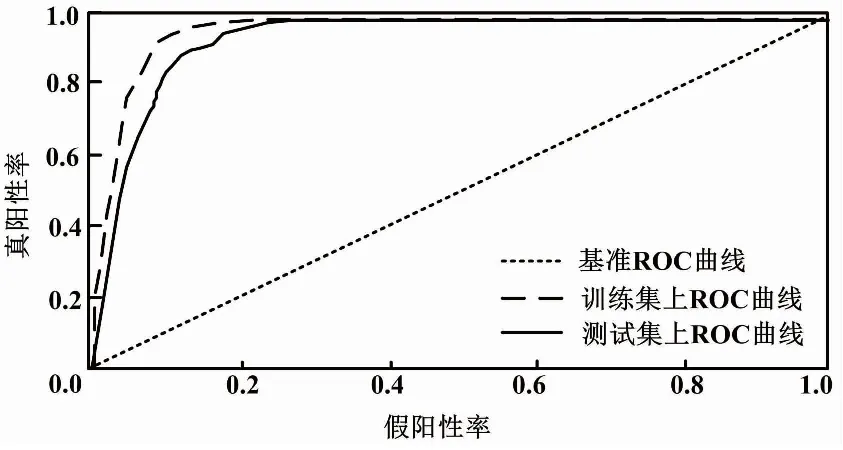
圖3 GBDT-LR模型的ROC曲線
從表2可以看出,GBDT-LR融合模型在測試集上的靈敏度為0.896,特異度為0.842,AUC值為0.942,優于其他5種單模型算法的這3個指標,但耗時方面僅優于BP神經網絡。另外,從圖3可以觀察到,GBDT-LR模型在測試集上的ROC曲線被訓練集的ROC曲線包裹,測試集上的AUC值為0.942,訓練集上的AUC值為0.968,表明GBDT-LR模型在胎兒窘迫樣本數據上存在輕微的過擬合學習問題。
4 結論
本文利用GBDT和LR融合的方法構建了胎兒窘迫預診模型。該方法通過GBDT算法從原始數據中獲得組合特征,并將組合特征與原始數據特征合并后再提供給LR模型訓練,從而得到最終的GBDT-LR模型。試驗結果表明,相較于已有的單個算法模型,GBDT-LR融合模型有效降低了胎兒窘迫的誤診率和漏診率,能夠輔助產科醫生對宮內胎兒窘迫程度作出更有效的評估。同時,本文所提方法也存在不足的地方,如GBDT-LR融合模型會因數據量過少而產生輕微的過擬合現象。因此,筆者未來將繼續保持與醫院間的合作,以期在更大的數據集上進一步提升胎兒窘迫的診斷效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
