融合知識特征與協(xié)同屬性的創(chuàng)新用戶群發(fā)現(xiàn)研究
2021-06-14 02:13:08唐洪婷李志宏張沙清
情報學報 2021年5期
唐洪婷,李志宏,張沙清,3
(1.廣東工業(yè)大學,廣州 510520;2.華南理工大學,廣州 510641;3.惠州市廣工大物聯(lián)網(wǎng)協(xié)同創(chuàng)新研究院有限公司,惠州 516025)
1 引 言
隨著用戶參與創(chuàng)新(user-engaged innovation)在產(chǎn)品創(chuàng)新流程中占據(jù)越來越重要的作用[1],眾多企業(yè)都設立了自己的開放創(chuàng)新社區(qū),以吸納用戶智慧、謀取創(chuàng)新靈感。研究表明,這種企業(yè)創(chuàng)新社區(qū)的設立對企業(yè)的產(chǎn)品創(chuàng)新、口碑傳播、品牌建設和市場營銷等活動均具有顯著的正向促進作用[2]。其中,用戶作為企業(yè)創(chuàng)新社區(qū)的關鍵組成部分,是社區(qū)生存的保證和價值的體現(xiàn)。聚集在社區(qū)中的用戶既是創(chuàng)意的傳播者,更是創(chuàng)意的生成者。對社區(qū)用戶進行合理的組織和利用,一方面,有利于提升用戶的歸屬感和參與度,保持社區(qū)活力;另一方面,也可以促進用戶內(nèi)容生成,保證社區(qū)的創(chuàng)意輸出。
然而,企業(yè)創(chuàng)新社區(qū)中的用戶作為獨立個體參與社區(qū)知識活動,其對產(chǎn)品的改進需求和創(chuàng)新痛點的看法常常局限于某個角度,用戶之間的知識碰撞與交互合作也存在較大的隨機性。已有文獻在開展用戶識別研究時,往往聚焦于獨立用戶以及其個體屬性[3]。研究表明,用戶在協(xié)作過程中的交互與討論能促進觀點的碰撞,通過品鑒和吸收他人的經(jīng)驗,可以激發(fā)用戶產(chǎn)生更具創(chuàng)意的想法[4]。因此,本文提出根據(jù)用戶的活動軌跡對社區(qū)中的用戶進行組群發(fā)現(xiàn),為用戶協(xié)同提高決策參考,激發(fā)群體智慧的涌現(xiàn)。
已有文獻對用戶的知識特征與行為屬性進行了一系列探索。為了最大化用戶群的協(xié)同效應,對企業(yè)創(chuàng)新社區(qū)這一知識密集型社區(qū)而言,創(chuàng)新用戶群的發(fā)現(xiàn)研究存在以下四個問題:其一,知識度量的局限性,即在知識度量時,常常利用知識存量等統(tǒng)計指標來表征知識特征[5],未對用戶的具體知識屬性進行深入探索;其二,用戶屬性考量的局限性,即在研究中聚焦于考查用戶個體的知識屬性[6],忽略了對用戶意愿及用戶間的協(xié)同屬性進行考量;其三,沒有考慮用戶行為的時變特征,企業(yè)創(chuàng)新社區(qū)是基于互聯(lián)網(wǎng)的用戶交互系統(tǒng),用戶流動及知識更替[7]適勢發(fā)生,進而干擾協(xié)同效果;其四,缺乏合理的用戶知識組織框架和量化工具,即面對企業(yè)創(chuàng)新社區(qū)中龐大的用戶群和海量的知識集,如何整合異質(zhì)要素并實現(xiàn)用戶屬性量化,也是課題研究中需要面臨的一大挑戰(zhàn)。
基于上述問題,本文提出在創(chuàng)新用戶群發(fā)現(xiàn)研究中,針對具體知識創(chuàng)新需求,利用超網(wǎng)絡這一表達與分析工具,充分考察動態(tài)情景下用戶的具體知識組成(知識質(zhì)量及創(chuàng)新潛力)與參與動機,并兼顧用戶間的協(xié)同潛力(知識互補性與知識協(xié)作能力),從而發(fā)現(xiàn)企業(yè)創(chuàng)新社區(qū)中的最具知識潛能與協(xié)同潛能的創(chuàng)新用戶群。本文對超網(wǎng)絡方法、用戶識別體系和知識量化方法的完善與融合具有重要的推動意義。同時,本文的研究成果對用戶組織、協(xié)同創(chuàng)新等社區(qū)運營實踐具有較好的指導意義。
2 相關研究介紹
2.1 企業(yè)創(chuàng)新社區(qū)
隨著互聯(lián)網(wǎng)社區(qū)的日益成熟,學者們對企業(yè)創(chuàng)新社區(qū)的相關特征的認識已然定型,具體包括:由企業(yè)出資設立并主導、由產(chǎn)品用戶及潛在用戶參與、社區(qū)中的主要活動為經(jīng)驗分享和信息交互[8]。企業(yè)創(chuàng)新社區(qū)作為以商業(yè)創(chuàng)新為導向的虛擬社區(qū),其創(chuàng)造價值的定位與能力一直都是學者們熱切關注的對象。研究表明,成功的企業(yè)創(chuàng)新社區(qū)在產(chǎn)品創(chuàng)新、口碑營銷、品牌建設和市場營銷等活動中均具有良好的表現(xiàn)[2]。其中,輔助產(chǎn)品創(chuàng)新作為社區(qū)設立的主要目的,其表現(xiàn)尤為亮眼[9]。不少社區(qū)實踐也佐證了這一點,如星巴克在經(jīng)營慘淡的瓶頸期,及時推出MyStarbucksIdea用戶交互平臺,通過“聆聽”用戶需求,最終實現(xiàn)革新、成功破局;小米借助MIUI社區(qū)與用戶“保持通話”,利用用戶反饋持續(xù)改進產(chǎn)品,使其保有日益龐大且活躍的用戶群。
鑒于企業(yè)創(chuàng)新社區(qū)中用戶參與創(chuàng)新表現(xiàn)出的巨大潛力,許多學者針對社區(qū)中的用戶及其知識等要素進行了多方探索,以期獲取用戶及其生成內(nèi)容的關鍵特征,為創(chuàng)新實踐提供決策參考。例如,相關文獻對用戶角色進行了識別與分析,如領先用戶、領域專家和意見領袖等[10-11]。然而,上述研究在衡量用戶的知識情況時,局限于簡單的統(tǒng)計指標及網(wǎng)絡分析,并沒有對知識內(nèi)容進行深度度量。同時,上述研究主要專注于利用抽離式思維獲取用戶特征,沒有對用戶及其知識間的碰撞的可能性進行研究。即便有部分文獻提出對社區(qū)中的社群進行挖掘,但相關研究更多的聚焦于同質(zhì)性高活用戶的發(fā)現(xiàn)[12]。為此,本文系統(tǒng)地考慮用戶的知識特征及用戶間協(xié)同屬性,以發(fā)現(xiàn)滿足協(xié)同創(chuàng)新任務需求的用戶群。
2.2 用戶特征
企業(yè)創(chuàng)新社區(qū)中,用戶基于自身的觀點、需求及偏好生成相應的活動軌跡。對這些活動軌跡進行挖掘與梳理,有助于企業(yè)制定科學的用戶管理策略,進一步促進用戶智慧的聚集與生產(chǎn)。目前,已有研究對用戶活動軌跡的挖掘可概括為5種用戶特征:①網(wǎng)絡位置;②活動特征;③內(nèi)容特征;④情感;⑤鄰接點得分[13-15]。其具體度量指標如表1所示。由表1可知,已有研究將用戶在社區(qū)中的活動軌跡刻畫得相對完整。但是,從用戶創(chuàng)新理論[16]及協(xié)同創(chuàng)新理論[17]的視角來看,上述指標尚未針對用戶參與協(xié)同創(chuàng)新的關鍵特征進行考察。
首先,基于用戶創(chuàng)新理論,用戶有效參與創(chuàng)新的關鍵特征在于:①對產(chǎn)品功能的需求處于市場趨勢前沿;②有強烈的動機去尋找滿足新興需求的解決方案[18]。結合本文的企業(yè)創(chuàng)新社區(qū)實踐,為了取得可觀的協(xié)同創(chuàng)新成效,用戶必須具備足夠的產(chǎn)品知識和經(jīng)驗,以及參與創(chuàng)新的積極意愿。因此,在上述特征度量的基礎上,本文提出對用戶的具體知識特征(知識質(zhì)量與知識結構)及參與動機特征進行度量。
其次,協(xié)同創(chuàng)新理論強調(diào)個體協(xié)作以實現(xiàn)“1+1>2”。在企業(yè)創(chuàng)新社區(qū)中,彼此獨立的用戶通過線上交互創(chuàng)造和獲取價值[19],實現(xiàn)協(xié)作。與傳統(tǒng)意義上的協(xié)作不同,這些用戶不一定彼此了解,而是“隱式”地“碰撞”以產(chǎn)生高質(zhì)量的創(chuàng)意[20]。然而,并非所有的“碰撞”都有意義,低效的交互不僅不利于創(chuàng)意的產(chǎn)生,還會引起用戶反感,甚至離開社區(qū)。因此,如何根據(jù)已有的用戶活動軌跡評價用戶間的協(xié)同可能性是本文要解決的問題。
2.3 超網(wǎng)絡
超網(wǎng)絡作為一種由多類型節(jié)點與關系構成的復雜網(wǎng)絡,為復雜系統(tǒng)的表達與分析提供了十分便利的工具。因此,超網(wǎng)絡在通信、交通、物流等諸多領域得到了廣泛的推廣和應用[21]。隨著線上平臺的發(fā)展和知識管理研究的推進,超網(wǎng)絡作為知識網(wǎng)絡的延伸,開始應用在知識管理領域[22]。
近年來,超網(wǎng)絡的相關研究主要包括:①用戶識別與分析。即通過對社區(qū)中的主要要素進行系統(tǒng)建模,發(fā)現(xiàn)其中的關鍵用戶[23]。如田儒雅等[24]通過構建包括社交子網(wǎng)、環(huán)境子網(wǎng)、心理子網(wǎng)和觀點子網(wǎng)的輿論超網(wǎng)絡,利用測度指標對輿論領袖進行了識別與分析。②知識研究。即利用超網(wǎng)絡對社區(qū)中的知識及知識載體進行系統(tǒng)建模,借助可視化分析發(fā)現(xiàn)知識特征。如遲鈺雪等[25]通過構建基于超網(wǎng)絡的線上線下輿情演化模型及其仿真框架,探索了同步率及速度對輿情演化的影響。由此可見,上述研究充分體現(xiàn)了超網(wǎng)絡表達及處理復雜關系的能力,也為本文利用超網(wǎng)絡進行用戶及其知識的表達及測度提供了依據(jù)。
本文擬利用超網(wǎng)絡的拓撲結構特性捕捉企業(yè)創(chuàng)新社區(qū)中用戶的知識特點、關聯(lián)、結構及其變化,對用戶的知識特征、用戶間的協(xié)同屬性等多種復雜異構關系進行探索,以發(fā)現(xiàn)具備知識能力與協(xié)作潛質(zhì)的創(chuàng)新用戶群。

表1 在線社區(qū)用戶屬性及其度量指標
3 融合知識特征與協(xié)同屬性的創(chuàng)新用戶群發(fā)現(xiàn)方法
3.1 用戶知識超網(wǎng)絡模型
為了給后續(xù)的用戶知識特征及協(xié)同屬性挖掘提供工具與素材,本文參考已有文獻,將企業(yè)創(chuàng)新社區(qū)中的異質(zhì)要素集成建模為用戶知識超網(wǎng)絡模型[26]。其中,節(jié)點包括用戶、帖子和知識點。同時,鑒于原有用戶知識超網(wǎng)絡模型將超邊直接表達為不同節(jié)點之間連線,容易丟失“用戶-帖子-知識點”間的對應關系等關鍵信息。因此,本文將三種不同節(jié)點之間的相互聯(lián)系(社區(qū)中用戶的主要知識行為)用超邊予以表達,構成發(fā)帖超邊與評論超邊[27]。相應的用戶知識超網(wǎng)絡可以表達為如圖1所示,圖1a為企業(yè)創(chuàng)新社區(qū)中的節(jié)點關系,圖1b為構建的用戶知識超網(wǎng)絡的示意圖。
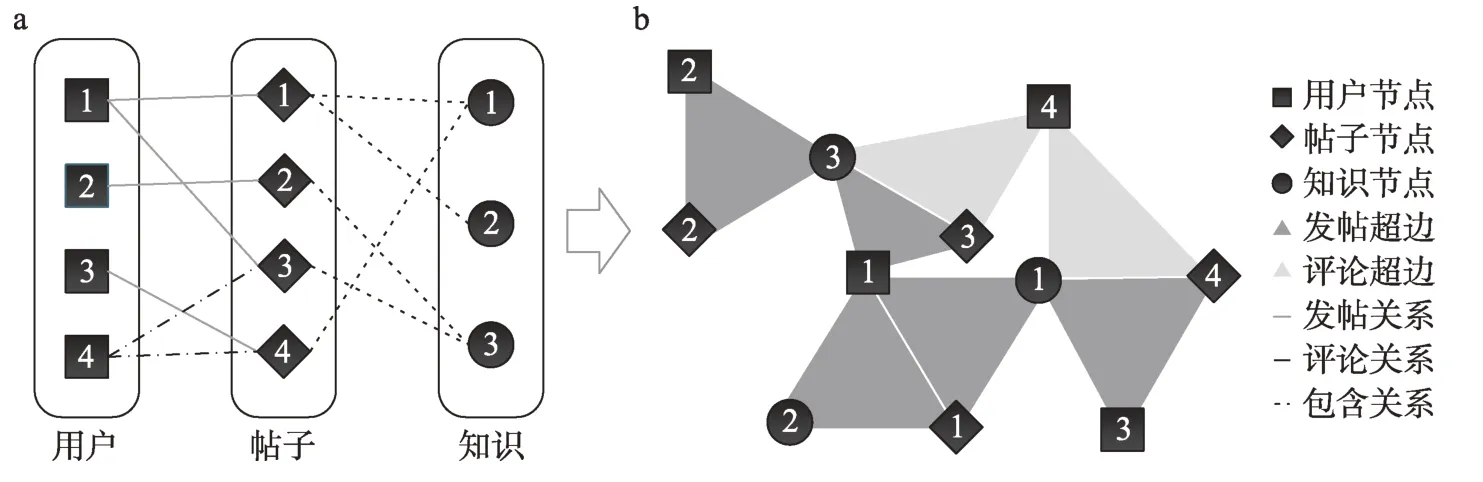
圖1 用戶知識超網(wǎng)絡
為了捕捉社區(qū)中用戶行為的時變特征,本文將時間維度納入了用戶屬性考量。據(jù)此,本文構建新的用戶知識超網(wǎng)絡模型(user knowledge super-net‐work model,UKSNM,)及其具體組成(表2):
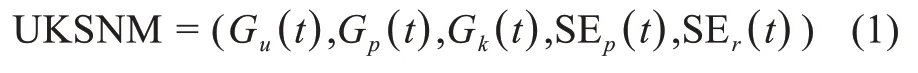
其中,t∈T表示時間;用戶Gu(t)、帖子Gp(t)和知識Gk(t)節(jié)點在模型中通過數(shù)學符號唯一標識,使其權重在不同時段內(nèi)彼此各異;發(fā)帖超邊SEp(t)與評論超邊SEr(t)均由三種不同的節(jié)點組成,其權重均為帖子p j隸屬于知識kz的概率θjz。

表2 用戶知識超網(wǎng)絡模型的要素組成
在已有文獻的超網(wǎng)絡構成中,知識節(jié)點kz常常由關鍵詞表示。本文為了從語義層面度量用戶的知識特征,將知識節(jié)點kz∈K表示為用戶生成內(nèi)容的知識主題,如圖2所示,利用LDA(latent Dirichlet allocation)主題模型[28],通過概率生成過程,生成S個知識主題,并確定每個帖子p j隸屬于不同知識主題的概率θj,以及每個知識主題kz的關鍵詞的概率組成φz。
通過將社區(qū)中的關鍵要素進行集成表達,本文構建的用戶知識超網(wǎng)絡模型可為后續(xù)的要素分析提供科學的工具,有效避免了用戶特征挖掘時指標映射困難、要素聯(lián)動遲鈍的現(xiàn)象。
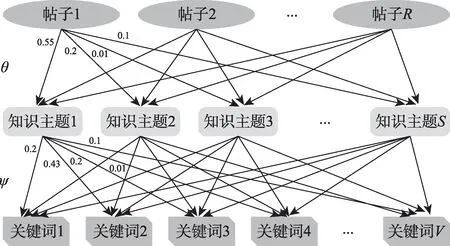
圖2 LDA主題模型的生成邏輯與結果
3.2 用戶特征分析
在第2節(jié)的分析中,本文基于用戶創(chuàng)新理論提出用戶有效參與創(chuàng)新在于是否具備:①超前需求;②創(chuàng)新動機。因此,下文是對用戶的知識質(zhì)量、知識結構以及參與動機進行考量。
3.2.1 知識質(zhì)量評價
為了評價文本的知識質(zhì)量,Dong[29]結合知識的多維特征設計了情景知識質(zhì)量、可操作知識質(zhì)量和內(nèi)在知識質(zhì)量三個評價維度。Valaei等[30]在此基礎上加入可訪問知識質(zhì)量并構建了一套四維指標體系。然而,這些評價大多數(shù)基于問卷的方式進行,其量化路徑不適用于數(shù)據(jù)科學研究。本文綜合考慮企業(yè)創(chuàng)新社區(qū)的知識特征與協(xié)同創(chuàng)新需求,提出從情景知識質(zhì)量、內(nèi)在知識質(zhì)量和可訪問知識質(zhì)量三個方面考察用戶的知識情況,即用戶應當具有與協(xié)同任務相關、準確且足夠的知識存量。
3.2.2 知識結構評價
在企業(yè)的產(chǎn)品創(chuàng)新實踐中,知識創(chuàng)新任務包括兩種:設計型任務與技術型任務[31]。前者是指存在大量潛在解決方案的非結構化任務,這需要參與者具有更為廣泛的知識面以產(chǎn)生跨領域創(chuàng)新;后者是指具有明確操作流程的結構化任務,其需要參與者擁有相關領域下深入的專業(yè)知識以完成常規(guī)性挑戰(zhàn)。本文利用知識廣度和知識深度來評價用戶的知識結構,以應對不同知識創(chuàng)新任務的需要。
3.2.3 參與動機評價
基于自我決定理論,用戶的參與動機可以分為:內(nèi)在動機、外在動機和內(nèi)化的外在動機[32]。在社區(qū)研究中,考慮到數(shù)據(jù)量化需求,學者們聚焦于量化內(nèi)化的外在動機。內(nèi)化的外在動機是行為外部的結果,但用戶可以將其內(nèi)化,常常表現(xiàn)為社區(qū)中設置的積分及其他互動機制。在理論研究中,這些機制被學者概化為:互惠、自我形象和聲譽。其中,互惠是用戶參與社區(qū)活動的重要決定因素,其表示收到幫助的用戶更愿意參與合作[33];自我形象描述用戶在社區(qū)中的自我感知,這種感知能積極推動用戶參與[34];聲譽表示用戶從外界獲取的反饋,其對用戶的知識參與行為具有較低的預測能力[35]。因此,這里對社區(qū)中的互惠和自我形象機制進行考慮。
在協(xié)同創(chuàng)新任務中,除了用戶的知識特征與參與動機,用戶之間的配合情況也會影響到最終的協(xié)同效果。基于協(xié)同創(chuàng)新理論,協(xié)同創(chuàng)新是一個“溝通-協(xié)調(diào)-合作-協(xié)同”的過程,包括各種知識資源的交互[17]。因此,對用戶間的知識互補情況及協(xié)作潛力等協(xié)同屬性進行考察十分必要。
3.2.4 知識互補性評價
在一般知識創(chuàng)新任務中,研究者常常選擇具有最多知識儲備的用戶。但在協(xié)同創(chuàng)新任務中,盲目追求知識存量最大化不利于創(chuàng)新工作的開展。若創(chuàng)新用戶群的知識過于相似,則知識的重疊將阻礙用戶間的思維碰撞,難以產(chǎn)生創(chuàng)新成果;若創(chuàng)新用戶群的知識差異過大,則將會增加用戶協(xié)商成本,甚至阻礙用戶間的知識溝通。因此,合理的知識互補特征十分重要。
3.2.5 知識協(xié)作能力評價
研究表明,人們在建立協(xié)作關系時,更傾向于選擇歷史合作伙伴[36]。而在企業(yè)創(chuàng)新社區(qū)中,用戶間的協(xié)作主要表現(xiàn)為評論行為。這種行為既反映了用戶的知識興趣,又反映出用戶間的知識交互能力。因此,本文通過用戶間的共同興趣程度與知識交互能力來度量用戶的知識協(xié)作能力。
創(chuàng)新用戶群發(fā)現(xiàn)研究的屬性特征可總結為如表3所示,其具體衡量指標將在下文中予以說明。
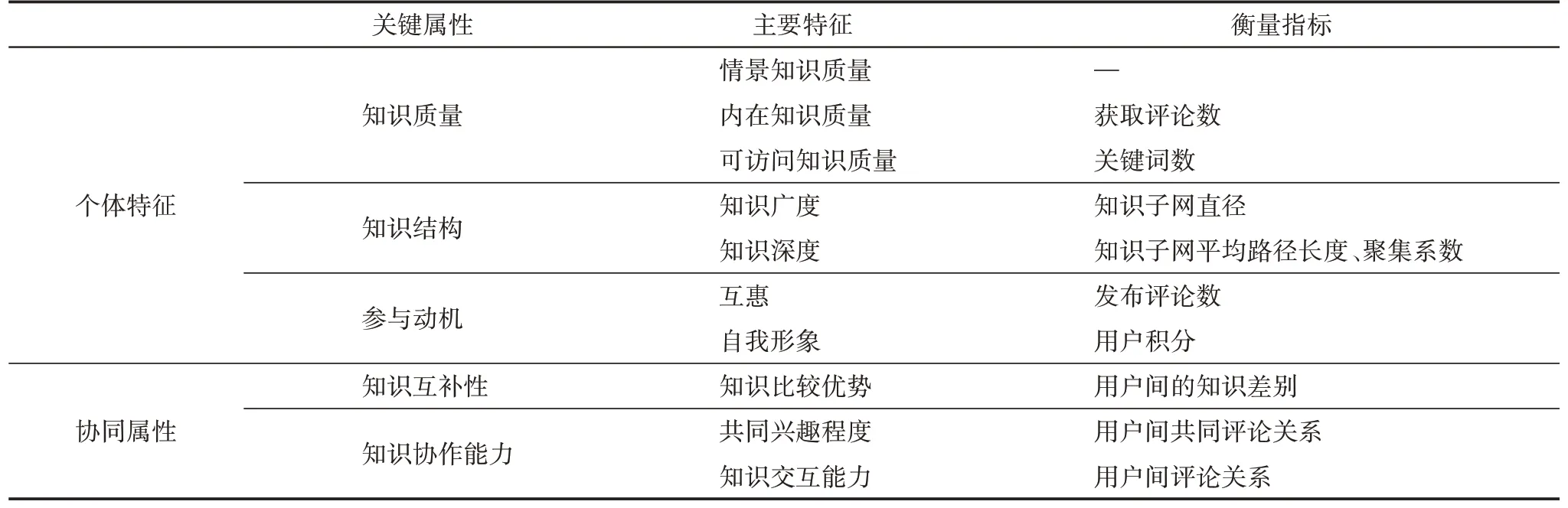
表3 協(xié)同創(chuàng)新用戶群發(fā)現(xiàn)的關鍵屬性特征
3.3 用戶的個體特征評價
3.3.1 知識質(zhì)量
協(xié)同創(chuàng)新任務的知識需求與用戶的知識儲備的匹配程度是決定協(xié)同成效的關鍵因素。本文將用戶生成內(nèi)容的知識主題作為具體知識領域。為了捕捉情景知識質(zhì)量特征,帖子p j與知識領域kz的匹配程度可以表示為
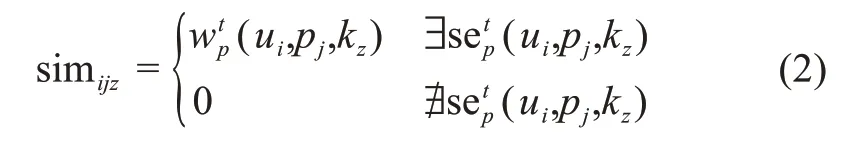
除了知識間的匹配程度,用戶知識的內(nèi)在質(zhì)量作為知識質(zhì)量的基礎,是為創(chuàng)新活動提供信息的根本源泉。為了量化內(nèi)在知識質(zhì)量,本文參考Matei等[37]的研究,利用第三方評估指標(即評論數(shù))表示用戶ui的內(nèi)在知識質(zhì)量。其中,帖子的評論數(shù)為

那么,結合具體知識領域kz,用戶ui在時間t的內(nèi)在知識質(zhì)量可表達為
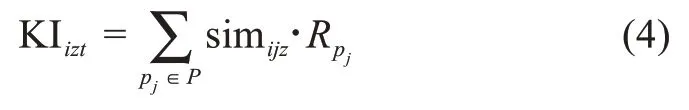
此外,研究表明,用戶生成內(nèi)容的增加,能夠提高創(chuàng)意生成的概率[38]。因此,考察用戶生成內(nèi)容的體量(即可訪問知識質(zhì)量)十分重要。針對企業(yè)創(chuàng)新社區(qū)的數(shù)據(jù)特征,本文擬利用用戶發(fā)帖內(nèi)容的知識存量,即有效詞組數(shù)予以衡量。那么,在時間t內(nèi)用戶ui在知識領域kz的可訪問知識質(zhì)量表達式為
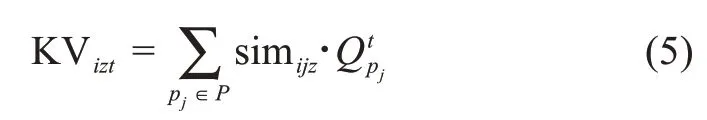
根據(jù)衰退理論[39],在決策實踐中,用戶行為的參考價值會隨著時間流逝而減小。本文在衡量用戶知識質(zhì)量時,引入知識衰退系數(shù)D,并用知識衰退率e-t/D表征其時間價值變化。基于上述評述,用戶ui在相應情景下的知識質(zhì)量可以表示為
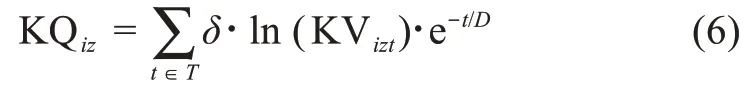
其中,δ=ln(KIizt)表示價值系數(shù)。
為了保證用戶的知識質(zhì)量在區(qū)間[0,1]內(nèi),將其進行歸一化處理:
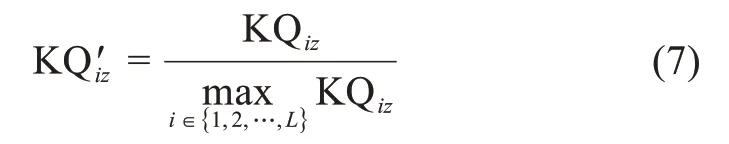
3.3.2 知識結構
針對知識結構(知識廣度與知識深度)評估,目前最具代表性的指標包括知識多樣性、Herfindahl指數(shù)等[40]。然而,這些指標大多為專利等線下知識的評估而設立。針對線上知識,本文借鑒鞏軍等[41]的研究,利用知識網(wǎng)絡的拓撲特征進行結構評價。具體來說,本文利用知識點之間的相似關系構建用戶知識子網(wǎng)(相似度計算利用圖2所示的φ矩陣,即各個知識主題的關鍵詞概率分布向量,并取相似閾值為0.01)。進而,本文利用直徑刻畫用戶的知識廣度,利用節(jié)點的平均路徑長度和度中心性評估用戶的知識深度。其中,直徑描述了網(wǎng)絡中任意兩點的最遠距離;平均路徑長度和度中心性表征某節(jié)點與周邊節(jié)點的緊密程度。那么,用戶ui的知識廣度可以表示為
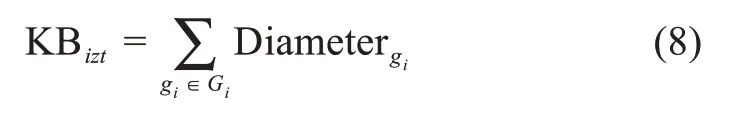
其中,gi為知識子網(wǎng)Gi的連通圖。
知識深度可以表示為
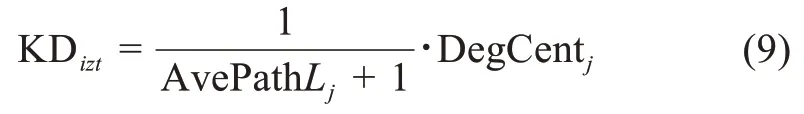
用戶ui在時間t的知識結構水平可以表達為
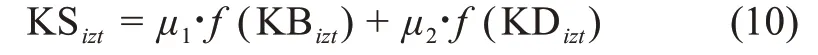
其中,μa為調(diào)節(jié)參數(shù),且在評價用戶的知識結構時,本文根據(jù)創(chuàng)新任務的實際特征(設計或技術型任務)給定不同的參數(shù)比例。同時,為了統(tǒng)一知識廣度與知識深度的量級,f(x)表示對x進行歸一化處理。
考慮知識的時間衰退特征,用戶ui的知識結構水平可以表達為
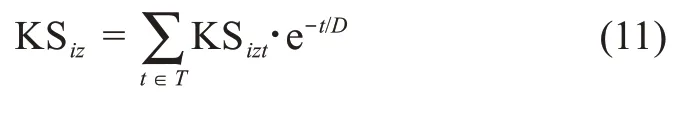
3.3.3 參與動機
本文利用互惠規(guī)范和自我形象來評價用戶的參與動機。首先,在企業(yè)創(chuàng)新社區(qū)中,若用戶獲取了其他用戶的知識,那么其更愿意在社區(qū)中參與知識貢獻,本文通過用戶的評論行為表征其知識獲取事實,其計算公式為
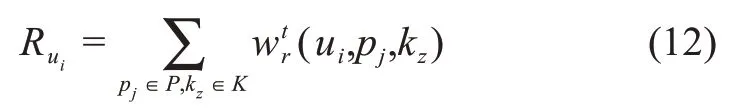
其次,社區(qū)中用戶參與行為的獎勵信號機制主要是積分,本文用積分值表征用戶的自我形象描繪,那么用戶ui在時間t的參與動機可以量化為
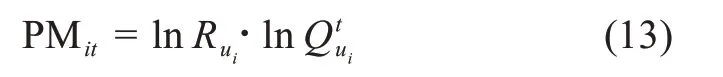
考慮知識的時間衰退特征,用戶ui的參與動機可以表達為
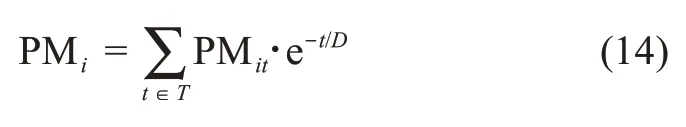
3.4 用戶的協(xié)同屬性評價
3.4.1 知識互補性
為了最大限度地激發(fā)用戶間的協(xié)同潛能,本文對協(xié)同用戶之間的知識情況進行對比考察。本文參考蘇加福[42]研究結果,首先,衡量用戶ui與用戶uj在時間t的知識比較優(yōu)勢:
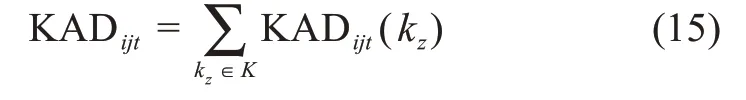
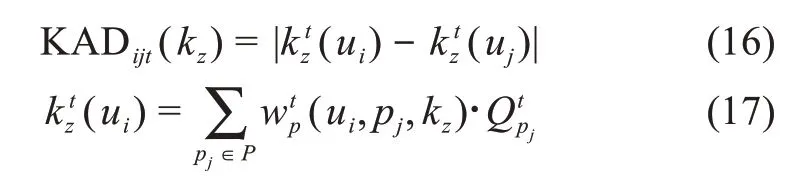
其中,KADijt(kz)為知識主題kz下用戶ui與用戶uj在時間t的知識比較優(yōu)勢;k tz(ui)為用戶ui在相應知識領域下的知識存量。
用戶ui與用戶uj的知識互補性可以表達為

3.4.2 知識協(xié)作能力
目前,對用戶知識協(xié)作能力的評價方法主要有指標法和社會網(wǎng)絡分析。本文主要利用上述方法對用戶的共同興趣程度與知識交互能力進行評價。首先,參考學者Newman[43]的研究成果,利用回帖共現(xiàn)情況度量用戶間的共同興趣程度,即用戶ui與用戶uj在時間t的共同興趣程度可以表示為
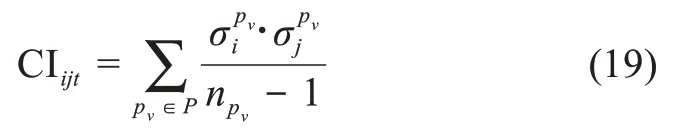
同樣地,可獲得排除時間因素影響的用戶共同興趣程度為:
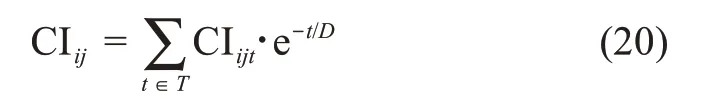
為了將用戶間的共同興趣程度落在區(qū)間[0,1]內(nèi),進行歸一化處理:
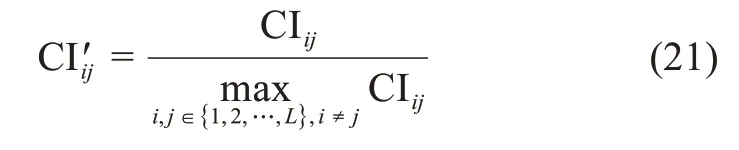
針對用戶間的知識交互能力,本文通過用戶對之間的交互情況予以評價。知識交互能力既體現(xiàn)為用戶生成內(nèi)容能夠引起他人共鳴,又體現(xiàn)為用戶能夠對其他人的貢獻內(nèi)容進行反饋。本文將用戶間的知識交互能力表示為

綜上,結合用戶間的共同興趣程度與知識交互能力,用戶間的知識協(xié)作水平可以定義為

3.5 創(chuàng)新用戶群的發(fā)現(xiàn)
為了發(fā)現(xiàn)企業(yè)創(chuàng)新社區(qū)中的協(xié)同用戶群,本文綜合考量用戶的知識特征及用戶間的協(xié)同屬性。具體包括:用戶的知識質(zhì)量、知識結構、參與動機、用戶間的知識互補性和知識協(xié)作能力。為了簡化問題,本文提出對用戶群的知識質(zhì)量與知識協(xié)作能力進行最優(yōu)化求解,并將待選用戶的知識結構水平、參與動機及用戶間的知識互補程度控制在有效區(qū)間內(nèi),即

針對滿足上述特征區(qū)間的用戶,聚焦用戶的知識質(zhì)量與用戶間的知識協(xié)作能力,構建協(xié)同用戶群發(fā)現(xiàn)的多目標決策模型:
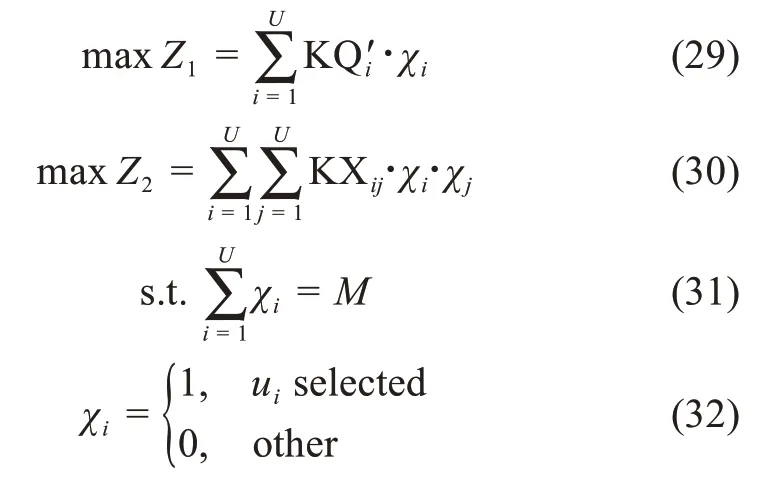
其中,公式(29)和公式(30)為優(yōu)化目標,即選擇用戶的知識質(zhì)量總和最高、用戶間的協(xié)作能力最佳。公式(31)和公式(32)為約束條件,表示從待選用戶集合中選擇M個用戶作為協(xié)同創(chuàng)新任務的成員。值得注意的是,本文結合企業(yè)創(chuàng)新社區(qū)知識協(xié)同任務的具體需求構建了相應的用戶屬性特征及求解模型。在其他知識系統(tǒng)中,本文可以根據(jù)實際需求調(diào)整目標函數(shù)及約束條件,構建適用于特定情景的協(xié)同創(chuàng)新用戶群發(fā)現(xiàn)模型。
上述多目標決策模型顯然是一個0-1整數(shù)規(guī)劃問題,為了解決這一問題,這里利用遺傳算法進行求解(其流程如圖3所示)。具體來說,本文利用理想點法將兩個目標函數(shù)進行總體評價,使各個目標盡可能接近“理想值”。那么,其適應度函數(shù)可以表達為
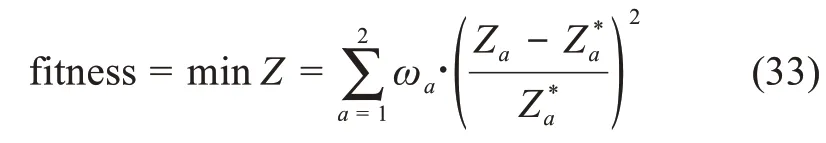
其中,Z*a表示為第a個目標函數(shù)的理想值,即相應單目標函數(shù)的最優(yōu)值;Za為第a個目標函數(shù)的當前值;ωa為調(diào)節(jié)參數(shù),且有
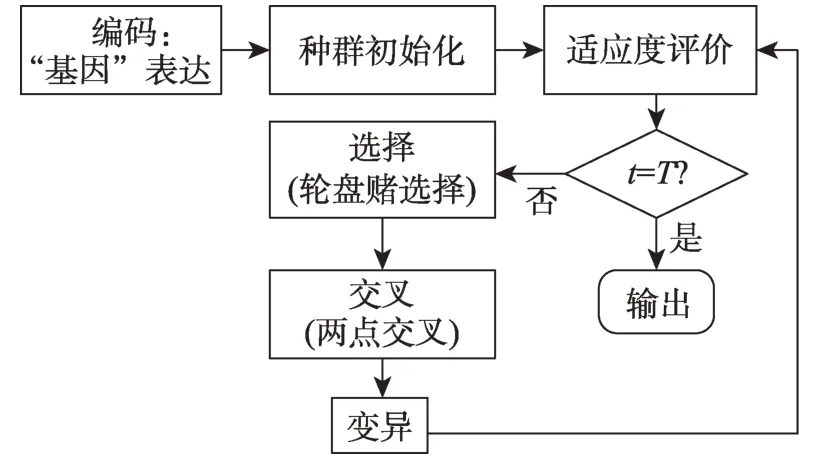
圖3 遺傳算法求解流程
在此基礎上,本文對用戶進行“基因”表達,并通過選擇、交叉和突變,實現(xiàn)多目標問題求解。由于遺傳算法的應用不是本文的創(chuàng)新內(nèi)容,故這里不予贅述。Goldberg等[44]對遺傳算法的遺傳搜索機制進行了全面的介紹,讀者可以參閱。
4 實例分析
4.1 數(shù)據(jù)介紹
為了驗證本文的有效性與可行性,本文選取了國內(nèi)典型的企業(yè)創(chuàng)新社區(qū)——MIUI社區(qū)(現(xiàn)已更新至小米社區(qū))中的用戶數(shù)據(jù)進行了實例分析。MIUI社區(qū)是小米科技為其產(chǎn)品MIUI系統(tǒng)設立的用戶交互平臺,并以此將用戶內(nèi)化到小米的產(chǎn)品創(chuàng)新流程中。本文選取MIUI社區(qū)中最具創(chuàng)新代表的“新功能建議”板塊中的數(shù)據(jù)進行研究,具體采集字段信息與相關統(tǒng)計信息如表4和表5所示。

表4 實例數(shù)據(jù)的字段信息
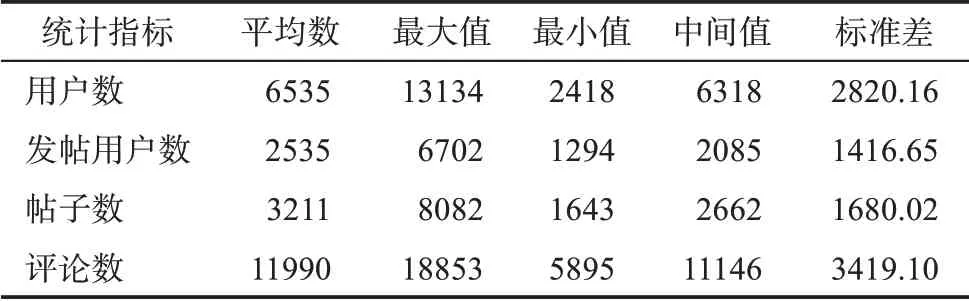
表5 實例數(shù)據(jù)的統(tǒng)計信息(按月統(tǒng)計)
4.2 超網(wǎng)絡模型的構建及用戶特征統(tǒng)計
基于上述數(shù)據(jù),本文利用LDA主題算法識別社區(qū)中存在的知識主題,其具體參數(shù)設置為:α=0.1,β=0.01。結合困惑度[45]的變化情況,將主題數(shù)設定為60,最終構建用戶知識超網(wǎng)絡模型。
為了評價用戶的不同屬性特征,首先,本文確定目標知識領域。通過統(tǒng)計不同知識主題的用戶關注度,這里選取用戶關注度較高、且當前熱門的知識主題K31(即“小愛同學語音助手”,用戶關注度為4630)作為目標知識領域。該領域下,發(fā)表過相關帖子的有效用戶共2196位。其次,在知識結構評價部分,本文暫不考慮知識創(chuàng)新任務的具體屬性,將知識廣度與知識深度的比重設定為0.5∶0.5。而在知識協(xié)作能力部分,本文將共同興趣程度與知識互動能力的重要性等同,并將其比重設定為0.5∶0.5。此外,參考已有文獻,本文將用戶行為的時間衰退系數(shù)設置為1。相關用戶的屬性特征的統(tǒng)計信息如表6所示。
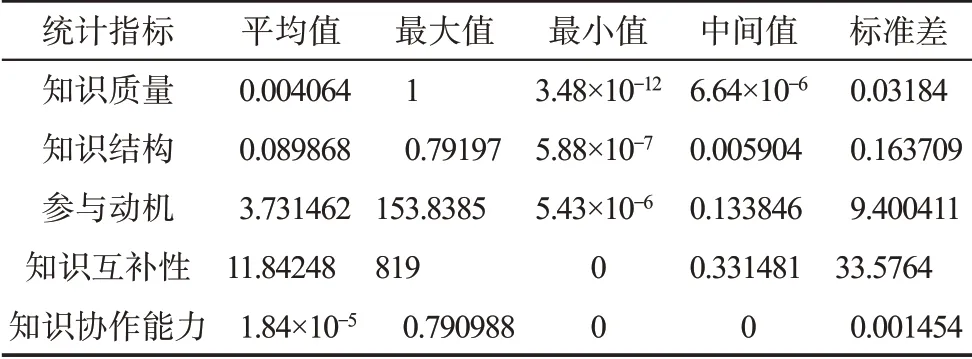
表6 相關用戶的協(xié)同創(chuàng)新屬性的統(tǒng)計信息
4.3 創(chuàng)新用戶群的發(fā)現(xiàn)與分析
為了切實描述用戶屬性和用戶間屬性的變化情況,并且確定用戶知識結構等指標的取值范圍,在圖4中展示出了相應的指標分布情況(降序排列),各指標值均呈長尾分布,這與已有研究結論一致:社區(qū)中極少數(shù)的用戶承擔了絕大多數(shù)的內(nèi)容貢獻任務[37];同時,用戶間的協(xié)同指標的快速下降進一步表明了用戶間匹配的必要性。為了保證選取創(chuàng)新用戶群的協(xié)同效果,本文將用戶知識結構的取值下界確定為0.2,參與動機的取值下界確定為20,知識互補性的取值區(qū)間確定為(200,400)。最終獲得滿足上述屬性的目標用戶集,共計92位用戶。
在實例研究中,本文設定創(chuàng)新用戶群的目標成員數(shù)為8。基于模型(29)~模型(32),本文可以得到MIUI社區(qū)的創(chuàng)新用戶群發(fā)現(xiàn)模型,并利用遺傳算法對其進行求解。為了確定求解過程中各類參數(shù)設置,本文給出了相關文獻的常用取值范圍,并根據(jù)以往經(jīng)驗確定本文的參數(shù),具體設置如表7所示。
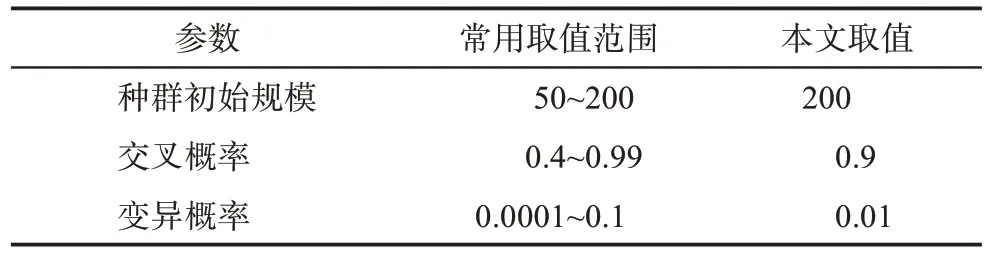
表7 遺傳算法求解的部分參數(shù)
本文分別計算公式(29)和公式(30)的兩個目標函數(shù)的最優(yōu)值,并將其作為多目標求解的理想點,這里理想點為:(Z*1,Z*2)=(2.76,2.25)。
綜上所述,本文利用遺傳算法進行最后求解,具體操作流程見圖3,其運行結果如圖5所示。從圖5可以看出,當?shù)螖?shù)達到250次左右時,可獲得參與協(xié)同的創(chuàng)新用戶群的最佳組合方案,相應的用戶群組合為[U27,U94,U247,U1039,U924,U1,U2634,U296]。該組合方案下,創(chuàng)新用戶群的各屬性特征的具體情況如圖6所示。在圖6中,選中集表示最終的創(chuàng)新用戶群;有限隨機集為限定知識結構等指標的隨機用戶集合;隨機集為發(fā)表過相關帖子的隨機用戶集合。從圖6還可以發(fā)現(xiàn),創(chuàng)新用戶群在各個指標上較原有用戶群和隨機用戶群均有更好表現(xiàn),表明了該方法的有效性。
為了進一步表征創(chuàng)新用戶群選擇的有效性,本文利用用戶知識超網(wǎng)絡截取了部分用戶特征。首先,利用超邊關系構建了協(xié)同創(chuàng)新用戶群之間的評論關系,如圖7所示。圖7中創(chuàng)新用戶群之間的互動非常頻繁,且隨著時間的推移,其關系愈加緊密。同樣地,本文對用戶之間的共同興趣程度進行了表達。即若兩位用戶在評論了同一帖子,那么用戶對之間存在一條邊。如圖8所示,創(chuàng)新用戶群的知識興趣存在較高的一致性,且其隨著時間的推移愈加明顯。
針對選擇用戶群的具體知識情況,本文基于其生成內(nèi)容給出了相應的詞云圖,如圖9所示。從圖9中可以看出,用戶之間的知識具有一定的相似性,如“小愛同學”“通知”等。同時,用戶之間的知識也存在一定的差異性。基于上述分析,本文發(fā)現(xiàn)的創(chuàng)新用戶群在知識互補及互動潛能方面均有較好的表現(xiàn)。
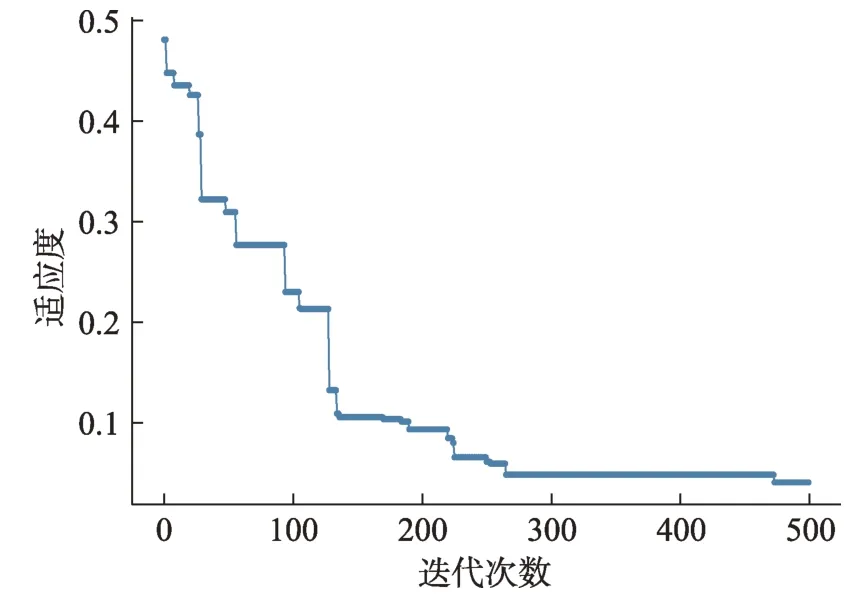
圖5 多目標識別模型求解的迭代收斂情況
5 討論與結論
隨著市場環(huán)境的轉變,將用戶置于研發(fā)中心,與用戶交流創(chuàng)新需求,成為企業(yè)尋求產(chǎn)品解決方案的最佳途徑。然而,也正是因為市場環(huán)境的快速變化,企業(yè)創(chuàng)新社區(qū)中的用戶交互行為與用戶生成內(nèi)容也應適時更迭變化。現(xiàn)有的用戶識別常常聚焦于某個時間截面的靜態(tài)數(shù)據(jù)開展,這種研究結果難以適應后續(xù)的工作需求。同時,針對參與協(xié)同的創(chuàng)新群體的組建,已有研究常常聚焦于用戶的交互行為,而忽略了對用戶的具體知識內(nèi)涵、用戶間知識異同、協(xié)作潛能等協(xié)同屬性的考量。因此,本文提出綜合考慮用戶行為的動態(tài)變化、并融合用戶的知識特征與用戶間協(xié)同屬性,發(fā)現(xiàn)對產(chǎn)品創(chuàng)新卓有助益的創(chuàng)新用戶群,為社區(qū)中的協(xié)同創(chuàng)新實踐提供決策支持,加速群體智慧的有效聚集與涌現(xiàn)。
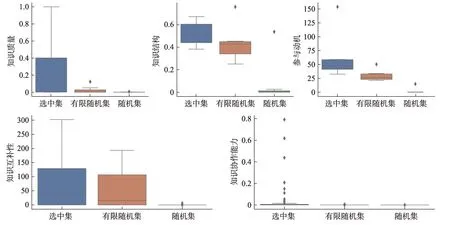
圖6 選取用戶群與隨機用戶群的指標特征
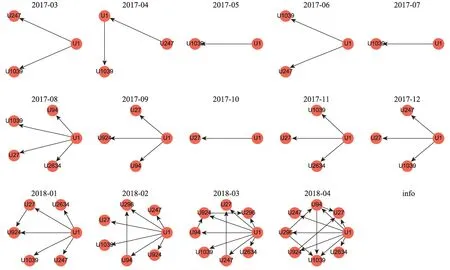
圖7 用戶評論關系時變圖
具體來說,本文構建了用戶知識超網(wǎng)絡模型,將企業(yè)創(chuàng)新社區(qū)中的異質(zhì)要素進行集成表達,為后續(xù)研究提供有效的表達工具與分析素材。利用這一網(wǎng)絡模型,本文對用戶的個體屬性(知識質(zhì)量、知識結構和參與動機)與協(xié)同屬性(知識互補性和知識協(xié)作能力)進行分析與量化,并將不同時段下用戶行為對當前決策的參考價值納入考量。最后,結合具體創(chuàng)新需求構建并求解協(xié)同創(chuàng)新用戶群發(fā)現(xiàn)的多目標決策模型。通過實際數(shù)據(jù)分析,驗證了本文提出方法的可行性和有效性。
另外,本文針對協(xié)同創(chuàng)新用戶的屬性度量提出了一套完整的指標體系,包括知識質(zhì)量評估、知識互補性度量等,并結合超網(wǎng)絡模型給出了利用客觀數(shù)據(jù)的指標量化方法。本文的研究對超網(wǎng)絡方法、用戶識別體系和知識量化方法的完善與融合具有重要的推動意義。結合實踐場景的實際需求,本文的研究成果可以為社區(qū)中的用戶組織及推薦提供決策參考;通過幫助決策者獲取更符合創(chuàng)新任務需求的創(chuàng)新用戶群,對協(xié)同創(chuàng)新等社區(qū)運營實踐具有重要的指導意義。與此同時,本文提出的方法對其他知識系統(tǒng)中協(xié)同創(chuàng)新團隊的組建也具有一定的參考意義。
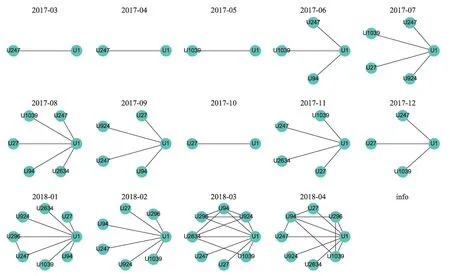
圖8 用戶共同興趣時變圖

圖9 創(chuàng)新用戶群的發(fā)帖關鍵詞分布
誠然,本文尚存在一些不足之處,有待在未來工作中進一步完善。其一,由于自然語言處理技術的有限發(fā)展,本文在知識主題發(fā)現(xiàn)和用戶知識衡量中的準確性有待進一步提升。其二,雖然超網(wǎng)絡為本文的表達與分析提供了很好的工具,但其應用具有相對的局限性,超網(wǎng)絡中有許多拓撲特性值得進一步研究,這將更為有效地輔助復雜知識系統(tǒng)的表達與分析。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
