基于動態語義網絡分析的主題演化路徑識別研究
2021-06-14 02:12:54倪興興劉家潤曹曉麗王長天
情報學報 2021年5期
關鍵詞:語義
陳 翔,黃 璐,倪興興,劉家潤,曹曉麗,王長天
(北京理工大學管理與經濟學院,北京 100081)
1 引 言
主題演化路徑識別是指通過對以詞語為表征的研究主題在時間序列上的發展、變化趨勢以及不同主題之間的交互作用進行跟蹤分析,揭示技術領域發展脈絡和演化規律的研究[1]。它可以幫助科研人員追溯具體學科領域的發展趨勢,識別研究熱點和可能的新知識增長點[2];也可以為政府和企業制定學科和領域發展規劃提供重要的情報支持[3]。通常,主題的演化路徑由“主題的前驅者—主題—主題的后繼者”構成[4],主題間的演化關系可以用主題間的相似度來度量,當相似度大于一定的閾值則被認為存在演化關系,即不同主題在相鄰時間段交界處存在新生、成長、衰減、合并、分裂以及衰亡六種演化方式[5]。
大量學者從網絡分析和詞頻分析兩方面入手開展主題演化路徑識別研究,主要包括信息熵、引文分析、突發詞分析和共詞分析等方法[6]。近年來,基于關鍵詞網絡的主題演化路徑識別方法被學者廣泛使用[7]。例如,Katsurai等[8]構建了動態共詞網絡,對心理學領域的主題演化過程進行分析;侯劍華等[9]利用共詞網絡和聚類分析識別了我國哲學領域研究主題的演化過程。其中,如何準確識別關鍵主題是該類研究的核心[10],大量學者已開展相關研究。例如,Song等[11]學者使用馬爾可夫隨機場對關鍵詞進行聚類進而識別主題;王曰芬等[12]使用LDA(Latent Dirichlet Allocation)模型識別出知識流領域的主題;張嶷等[13]采用主題詞簇法通過詞表清洗與合并、模糊語義處理等步驟對主題詞表進行深度處理,解決了主題詞表存在噪音和冗余的問題,實現了清洗、鞏固主題詞表的目的;有助于生成更有意義的核心聚類[14]。此外,社區發現算法逐漸興起,展現出比傳統聚類方法更大的優勢[15],例如,Blondel等[16]提出的Fast Unfolding算法可在不事先確定主題數的情況下更準確地進行主題識別。
然而,當前研究還存在一些不足。首先,這些方法均假定關鍵詞之間相互獨立,未充分考慮關鍵詞之間的語義關聯關系[17],影響了關鍵詞相似度分析的準確性。例如,關系密切的關鍵詞對因沒有共同出現在同一篇文獻而被忽略。其次,傳統主題演化路徑識別研究往往憑經驗或按照簡單平均的方法對時間段進行劃分,缺少科學依據。例如,時間段劃分過長,大量主題在設定時間段內已完成演化;時間段劃分過短,一個主題會被重復劃分在多個時間段,導致主題割裂[9],均無法科學呈現主題間的演化關系。
為有效挖掘關鍵詞之間的語義關系,準確識別領域中的熱點主題及發展趨勢,本文提出了基于動態網絡分析的主題演化路徑識別方法。首先,引入分段線性表示法(piecewiselinear representation,PLR)對時間段進行劃分,并利用Word2Vec模型[18]構建動態關鍵詞語義網絡來體現關鍵詞之間的語義聯系;其次,利用Fast Unfolding社區發現算法識別動態網絡中的社區,并基于Z-Score方法識別所有社區的主題標簽以代表某領域的研究主題;最后,通過度量相鄰時間段間的主題相似性來表現主題間的演化關系,進而識別主題的演化路徑。本文以信息科學領域為例開展實證分析,并對方法的有效性進行了驗證。
2 方法框架
本文的方法框架如圖1所示,包括動態關鍵詞語義網絡構建、基于社區發現的主題識別、主題演化路徑識別及可視化三大部分。
2.1 動態關鍵詞語義網絡構建
2.1.1 數據收集與預處理
本方法首先從WoS(Web of Science)中下載特定領域的文獻數據,并利用文本挖掘軟件Vantage‐Point①VantagePoint是面向文獻計量數據(如科技論文、專利以及學術項目申請書等)的文本挖掘與可視化軟件。更多詳情請訪問官網:https://www.thevantagepoint.com/抽取關鍵信息,包括關鍵詞、標題、摘要以及年份;之后,對抽取的數據進行預處理,主要包括:去除標題及摘要中的亂碼、去除帶有亂碼的關鍵詞以及關鍵詞中的XML標簽等[5]。
2.1.2 基于分段線性表示法的時間段劃分
本部分的目的是基于分段線性表示法對關鍵詞序列進行時間段劃分。首先,對關鍵詞在等時間區間(月、季、年等)內的數量變化進行統計,得到一條有效的關鍵詞數量序列,記為K={k1,k2,…,kt,…,kl},如圖2a所示,其中,kt表示某研究領域在第t(1≤t≤l)時間區間內的關鍵詞數量。在統計單位時間內的關鍵詞數量時,為了清除噪聲并使語義相同的關鍵詞不被重復統計,本文利用主題詞簇法[4]對關鍵詞進行清洗(包括基于專家知識整合同義詞、合并詞干相同的詞匯等)。
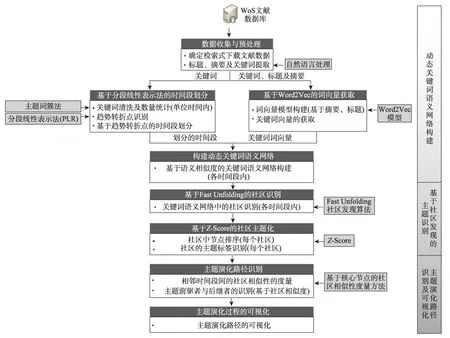
圖1 基于動態網絡分析的主題演化識別方法框架
其次,利用分段線性表示法將得到的關鍵詞數量序列K擬合為首尾銜接的分段線性結構KPLR,如圖2b中的折線所示。
這里,KPLR表示關鍵詞數量統計序列K的分段線性結構,其表達式為
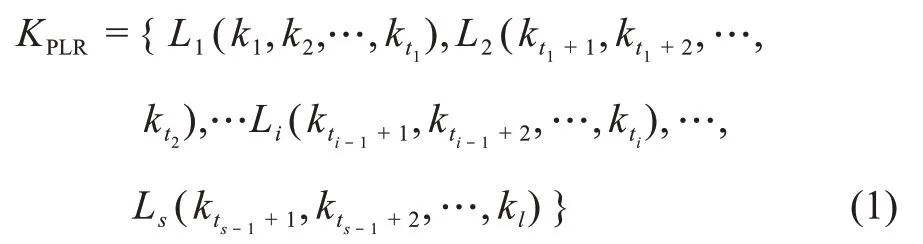
其中,Li(kti-1+1,kti-1+2,…,kti)表示KPLR中的第i(1≤i≤s)個線段,也是根據數據點kti-1+1,kti-1+2,…,kti擬合的線段(即趨勢段),這條線段的起始時間為ti-1+1,終止時間為ti。
圖2b中,折線的轉折點便是本文要識別的趨勢轉折點,用TTP(trend turning points)表示,表達式為
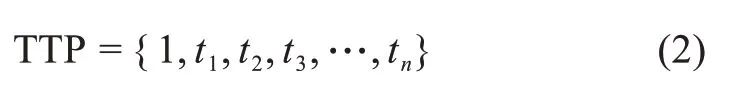
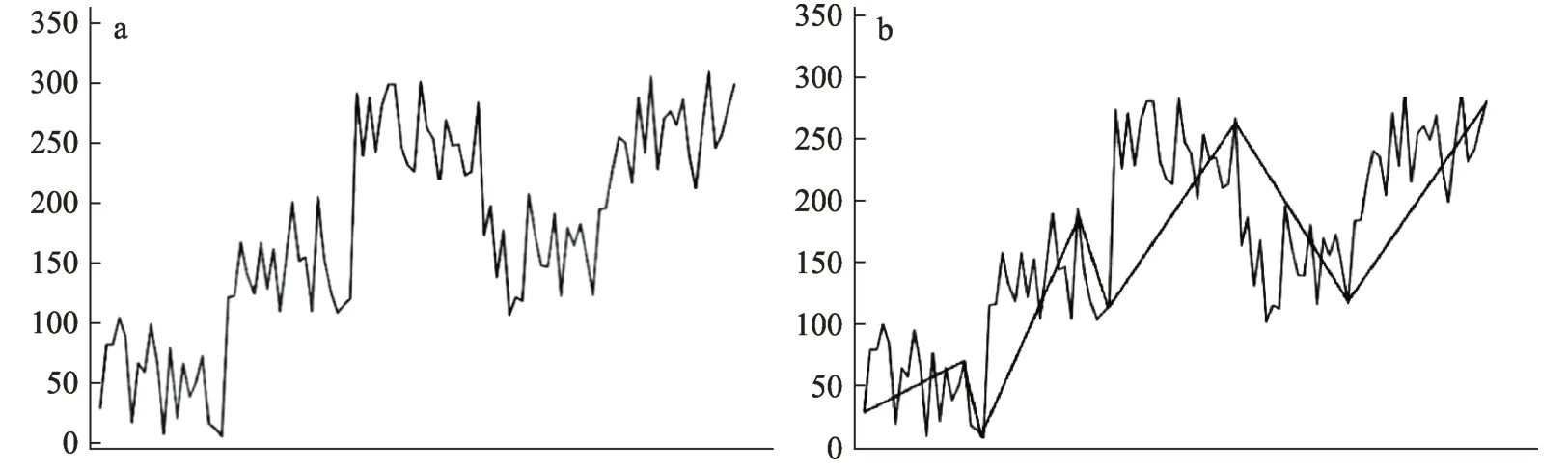
圖2 分段線性表示法示意圖
其中,t1表示第一個線段結束時的時間節點;t2表示第二個線段結束時的時間節點。這些時間節點標志著主題演化趨勢開始發生轉折,依據這些趨勢轉折點可以劃分時間段,
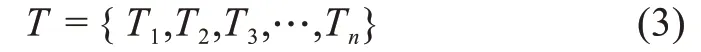
其中,T1表示起始時間點為1、終止時間點為t1的時間段;T2表示起始時間點為t1+1、終止時間點為t2的時間段;以此類推直到最后一個趨勢轉折點被劃入時間段內。
在分段線性表示法中,表示分段數量的參數s的設置非常關鍵,s越小會忽略越多的局部波動數據,導致較大的整體擬合誤差;而s越大保留的局部波動數據越多,引入的噪聲也越多。本文參考了陳虹樞[19]的參數設置方法來平衡擬合的可靠性與趨勢的可捕捉性。
首先,確定s的取值范圍,求出每個s對應的均值根誤差(root mean square error,RMSE)并存入均值根誤差序列。在該序列中,隨著s值的增大,均值根誤差值不斷減小。RMSE是用來衡量觀測值與真值之間偏差的指標,可以更加直觀地表現觀測值對于真實值的擬合效果,本文用該指標來衡量分段線性擬合后的曲線與原曲線之間的誤差,其計算公式為
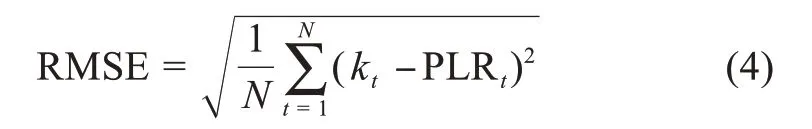
其中,kt表示原曲線上t時刻的點;PLRt表示擬合后曲線上t時刻的點;N表示數據點的總個數。
其次,利用求導的方式,選取在RMSE不斷減小過程中顯著放緩的那一點,以其對應的s作為最優結果,即求出RMSE序列近似導數最大值所對應的s值。本文用sAD表示最優分段數,其計算公式為

2.1.3 基于Word2Vec的詞向量獲取
劃分好時間段后,本文先對各時間段內的摘要和標題文本進行分句和分詞處理,然后將分詞后的語句序列作為語料庫輸入到待訓練的Word2Vec模型中,并選用skip-gram模型對語料進行訓練,最后,將得到的關鍵詞通過訓練好的Word2Vec模型映射為詞向量。由于該詞向量是基于關鍵詞與上下文之間的關系得出的,既包含每個詞從上位詞繼承來的公有屬性,也包含自身的私有屬性,可以體現關鍵詞的多重語義信息[20]。Word2Vec模型訓練過程如圖3所示。
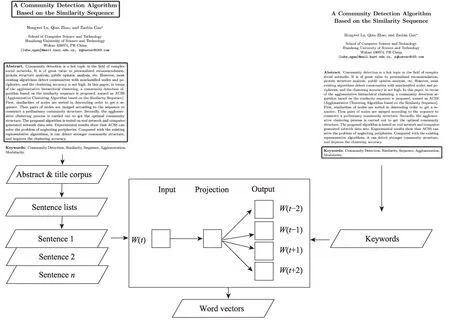
圖3 Word2Vec模型訓練示意圖
2.1.4 構建動態關鍵詞語義網絡
本部分主要是構建動態關鍵詞語義網絡。首先,基于關鍵詞的時間信息將抽取得到的關鍵詞分到劃分好的時間段內,并利用主題詞簇法對每個時間段內的關鍵詞進行清洗。
接下來,依次在各時間段內,利用清洗后的關鍵詞與其對應的詞向量構建關鍵詞語義網絡,構建過程闡述如下:
(1)定義某領域在時間段Ti內清洗后的關鍵詞集為表示屬于關鍵詞集WTi的第i個關鍵詞。
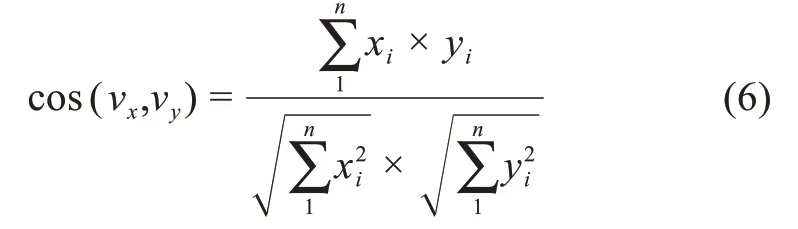
最后,所有時間段內的關鍵詞語義網絡組成了本文的動態語義網絡G,計算公式為
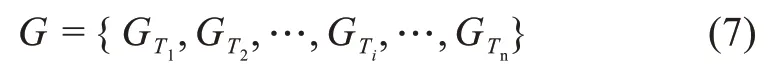
其中,GTi為時間段Ti內的關鍵詞語義網絡。
2.2 基于社區發現的主題識別
本部分將識別動態關鍵詞語義網絡中的主題。首先,利用Fast Unfolding算法識別語義網絡中的社區。Fast Unfolding是基于模塊度最大化的社區發現算法,模塊度是衡量社區劃分效果的指標,可以度量社區內部連接的緊密度以及社區之間連接的稀疏度,模塊度越大,社區劃分的效果越好[21]。本文用R表示模塊度,計算公式為
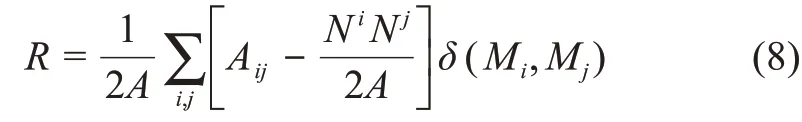
其中,A表示網絡中所有連邊的權重之和;Aij表示節點i和節點j之間的連邊權重;Ni為節點i所有連邊的權重之和,Nj為節點j所有連邊的權重之和;δ(Mi,Mj)用來表示節點i和節點j是否在同一社區,如果在同一社區,取值為1,否則,取值為0。
為了避免弱關聯和負關聯(向量余弦值為負數)的關鍵詞對在識別社區時引入噪聲,本文參考曾慶田等[17]的研究對構建的關鍵詞語義網絡進行適當剪枝,去掉部分關系較弱關鍵詞對之間的連邊。本文將δ依次從0增至0.5(步長為0.05),利用Fast Unfolding算法識別δ對應剪枝后網絡中的社區,并計算最后的模塊度。這里,本文將模塊度最大值對應的δ作為剪枝的閾值。識別出動態網絡中的社區后,參考Wang等[4]的方法,利用Z-Score指標為每個社區的內部節點排序,選出Z-Score值最高的節點作為該社區的主題標簽,計算公式為
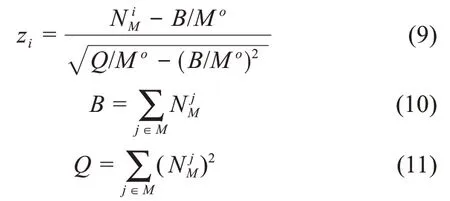
其中,zi表示社區M中第i個節點的Z-Score值;N iM表示社區M的第i個節點與社區M其他節點連邊的權重之和;M o表示社區M的節點數量;B表示社區M內所有節點與其他節點連邊的權重和的總和;Q表示社區M中所有節點與其他節點連邊的權重和的平方的總和。節點的Z-Score值越高,說明該節點與社區內其他節點的關系越緊密,越能代表整個社區。參考Guimerà等[22]的研究,Z-Score值大于等于2.5的節點可以作為社區的核心節點。
2.3 主題演化路徑識別及可視化
本部分將識別主題的演化路徑并進行可視化。首先,基于對應社區之間的相似度識別主題之間的演化關系。核心節點是社區內最具代表性的節點,也是社區發展變化的關鍵[4]。因此,本文利用核心節點度量社區之間的相似性,定義t+1時間段內的某個社區為Mt+1,t時間段內的某個社區為Mt,則Mt+1與Mt的相似度為HS(Mt,Mt+1),計算公式為
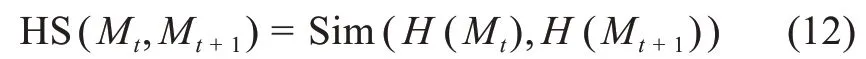
其中,H(Mt)表示Mt中核心關鍵詞節點集,H(Mt+1)表示Mt+1中核心關鍵詞節點集;Sim(H(Mt),H(Mt+1))表示H(Mt)與H(Mt+1)之間的相似度。
考慮到主題之間的相似度很大程度上依賴于主題之間的語義相似性,本文基于核心關鍵詞節點的詞向量,并利用關鍵詞節點對應的Z-Score值賦予權重,采用向量余弦值加權平均的方法度量Sim(H(Mt),H(Mt+1))。為了統一量綱,本文對每個社區的Z-Score值進行標準化處理。以社區Mt為例,設該社區的核心關鍵詞節點集H(Mt)中的某個關鍵詞為Wt,則Wt對應的Z-Score值的標準化過程為
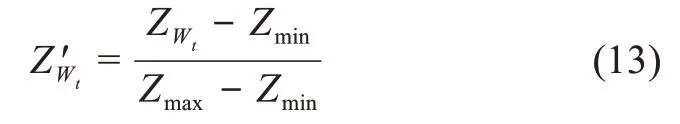
其中,Z'Wt表示關鍵詞Wt對應的Z-Score標準化后的值,ZWt表示Wt對應的Z-Score值;Zmax表示標準化前H(M t)對應的Z-Score值中最大值,Zmin表示標準化前H(M t)對應的Z-Score值中最小值。
對Z-Score值標準化處理后,Sim(H(Mt),H(M t+1))的計算公式可以表示為
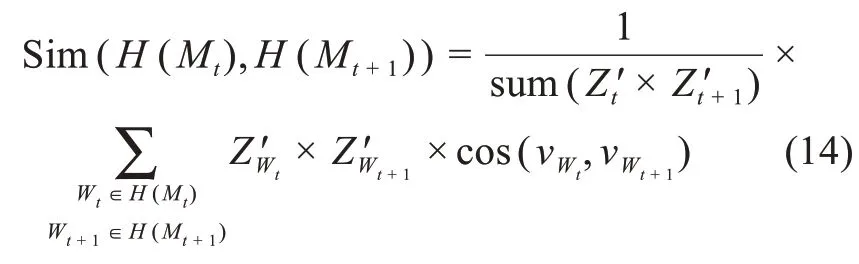
其中,Z't表示核心關鍵詞節點集H(Mt)對應的Z-Score值標準化后的集合;表示H(Mt)對應標準化后的所有Z-Score值與H(Mt+1)對應標準化后的所有Z-Score值之間的兩兩乘積的總和;vWt表示Wt由Word2Vec模型映射后的詞向量;cos(vWt,vWt+1)則表示向量v Wt與向量vWt+1之間的余弦值。
計算得到主題間的相似度后,可以剖析相鄰時間段中兩個主題之間的演化關系,即確定每個主題的前驅者與后繼者,以及由“前驅者—主題—后繼者”構成主題的演化路徑。定義t+1時間段內的某個社區為Mt+1,它的前驅者為Pre(Mt+1),則Mt+1為Pre(Mt+1)的后繼者,Pre(Mt+1)的表達式定義為
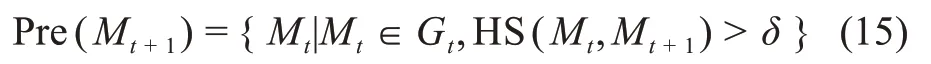
其中,Gt表示t時間段內的關鍵詞語義網絡;Mt表示Gt中的某個社區;δ為人工設定的閾值。
最后,對整個領域的主題演化路徑進行可視化。本文以矩形代表主題,矩形上的文字代表主題標簽,矩形的高度與主題對應社區的節點數量成正比,且同一時間段內的主題按照矩形的高度從大到小排成一列。再利用一條從前驅者指向主題的弧線表示主題間的演化關系,弧線上標出兩個主題之間的相似度,不存在演化關系的主題將被描繪成淺灰色,演化路徑示意圖如圖4所示。
具體來看,t-1時間段內的主題A與C是t時間段內主題D的前驅者,弧線上標了主題間的相似度,t+1時間段的主題F是t時間段內主題D的后繼者。t+1時間段內的主題H與其他主題不存在演化關系。
根據學者Palla[23]的研究,社區的發展過程可以分為六種模式:新生、成長、合并、衰減、分裂以及衰亡。
(1)新生:在t時間段內不存在的社區,在t+1時間段內出現。
(2)成長:在t時間段內存在的社區,繼續在t+1時間段內存在且社區節點增多。
(3)合并:兩個或者多個存在于t時間段內的社區在t+1時間段內合并為一個社區。
(4)衰減:在t時間段內存在的社區,繼續在t+1時間段內存在且社區節點減少。
(5)分裂:存在于t時間段內的社區在t+1時間段內分裂成兩個或者多個社區。
(6)衰亡:存在于t時間段內的社區在t+1時間段內消失。
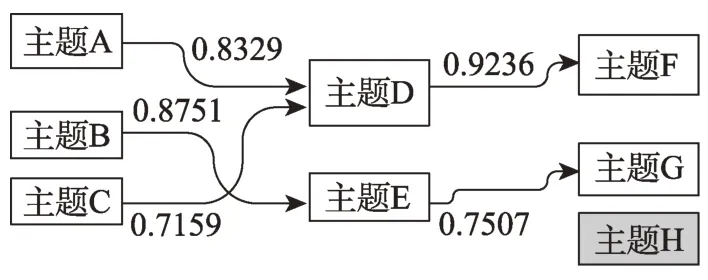
圖4 主題演化路徑示意圖
2.4 方法驗證
本文設計了定性與定量相結合的驗證方法。在定性驗證部分,我們將本文的分析結果與權威期刊文獻的結果進行了對比;在定量驗證部分,本文既對比了分段線性表示法與平均時間劃分法的分析結果,又將本方法與K-means和LDA兩大方法在主題識別中的效果進行了比較,并將準確率、召回率和F1值作為評價指標[24],用來驗證本方法的有效性。相關指標計算公式為

3 實證分析
信息科學是一門典型的交叉學科,近年來該領域文獻增長迅速,新的科學概念大量涌現[25],這使得該學科的主題演化過程更加復雜,其主題演化路徑識別研究更有意義。本文選擇信息科學領域作為實證分析對象,參考Hou等[25]學者的最新研究確定了信息科學領域的9種期刊,從WoS下載了2010—2019年10108條文獻數據,如表1所示。
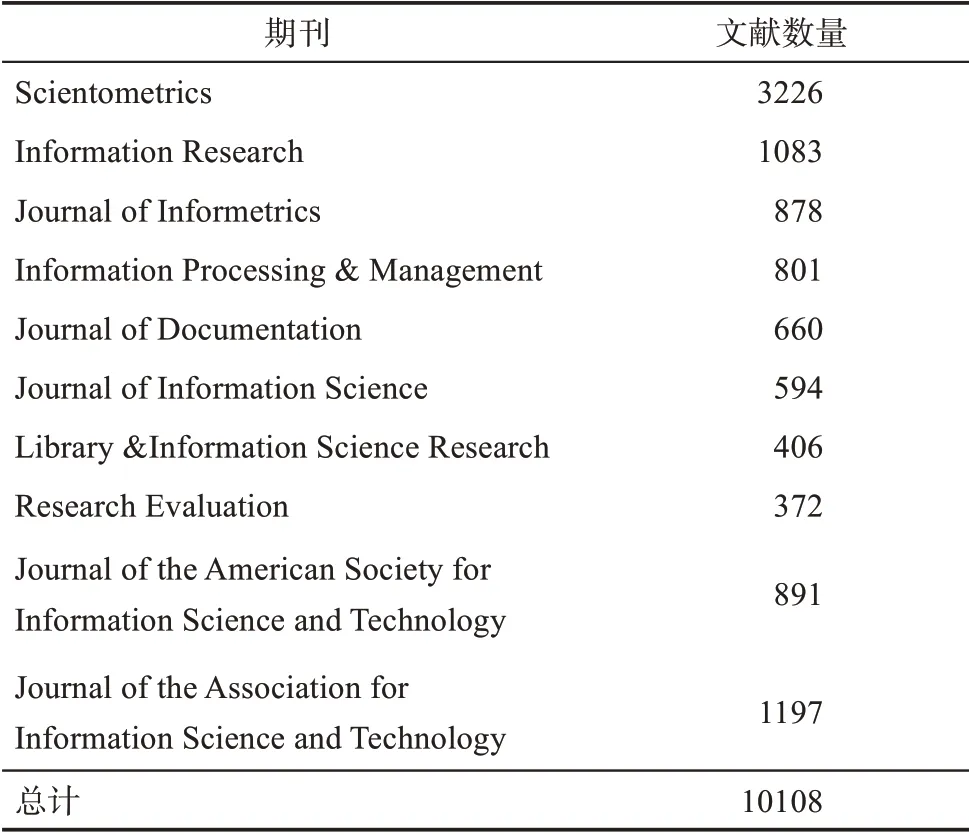
表1 信息科學領域期刊文獻統計
通過Vantage Point軟件提取得到31523個作者關鍵詞,去除帶有亂碼的關鍵詞和XML標簽后,獲得31276個有效關鍵詞;之后,將有效關鍵詞按月份劃分為120個關鍵詞子集,利用主題詞簇法進行清洗,得到一個隨時間變化的關鍵詞數量序列。這里,本文以2018年11月的關鍵詞子集為例來演示清洗過程,如表2所示。

表2 2018年11月的關鍵詞清洗步驟(主題詞簇法)
接下來,本文利用分段線性表示法中常用的三種方法(滑動窗口法、自上而下法以及自下而上法),對關鍵詞數量序列進行分段線性擬合,并將參數s的取值范圍設置為2到20[19]。遵循第2.1.2節的分析步驟,可以得到三種方法對應的最優分段數目s及其對應的均值根誤差RMSE。最后,利用綜合加權平均法對三種方法的擬合結果進行評估。為統一量綱,本文對s及RMSE兩個指標進行標準化處理,使其均處于0到1之間,標準化的過程為

其中,as表示某指標標準化后的值;ai表示該指標標準化前的值;amin表示所有指標的最小值;amax表示所有指標的最大值。然后,對標準化后的s和RMSE指標加權求和(本文認為這兩個指標同等重要,權值均為0.5),并用作評估指標。三種方法的擬合結果如表3所示。
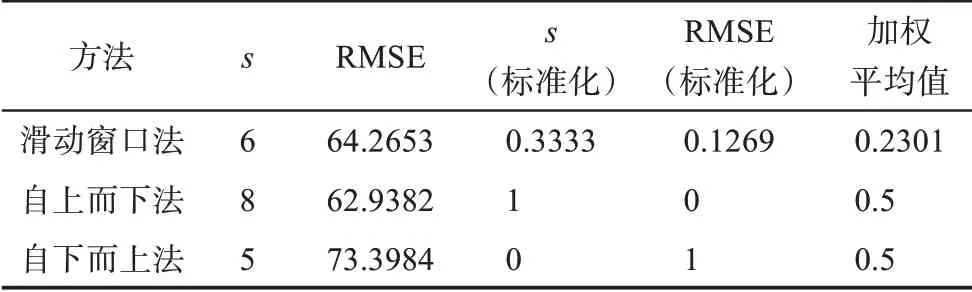
表3 三種分段線性表示法的分段擬合結果
為了平衡趨勢可捕捉性和擬合可靠性,本文傾向于分段較少以及均值根誤差較小的擬合方法[19],故選擇了加權平均值最小的滑動窗口法(取值0.2301),該方法的擬合結果如圖5所示。
這里,信息科學領域被劃分為6個時間段,各個時間段的起始點與終止點如表4所示。
本案例中的關鍵詞集中有大量短語,如“Infor‐mation Retrieval”“Citation Analysis”等,而Word2Vec模型不能直接得出這些短語的向量,因此,我們將短語形式的關鍵詞轉換為相應的駝峰形式進行模型訓練,如將短語“network analysis”轉換為“Net‐workAnalysis”,并將關鍵詞通過訓練好的Word2Vec模型映射為相應的詞向量。這里,我們參考Wang等[26]的工作,將向量設置為300維,窗口大小設置為7,最小詞頻設置為3。之后,在每個時間段內構建關鍵詞語義網絡。首先,將關鍵詞集進一步劃分為6個時間段內的關鍵詞子集,刪除詞頻小于3的關鍵詞(去除噪聲關鍵詞)并使用主題詞簇法進行清洗,清洗后的各時間段的關鍵詞數量如表5所示。
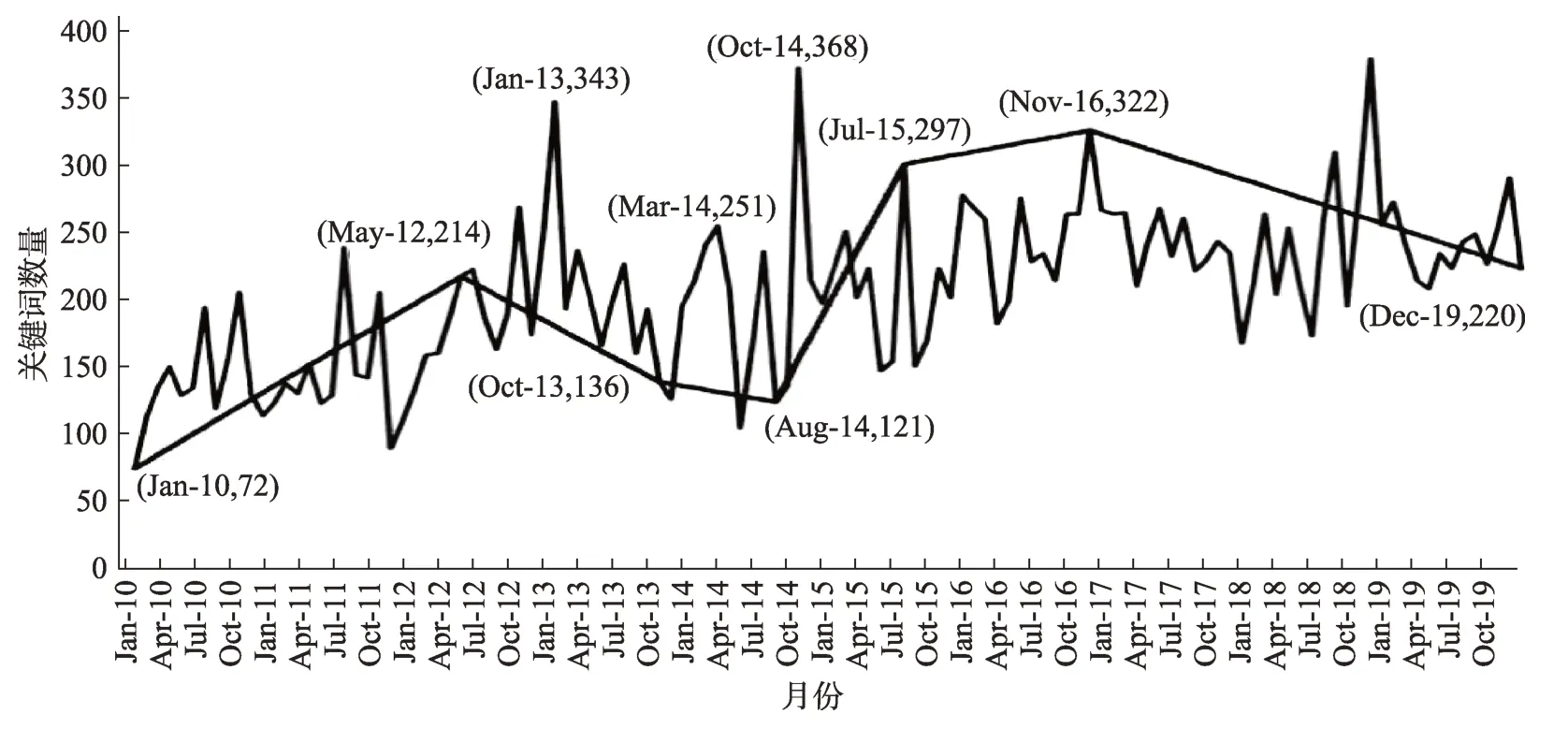
圖5 關鍵詞數量序列的分段線性擬合結果
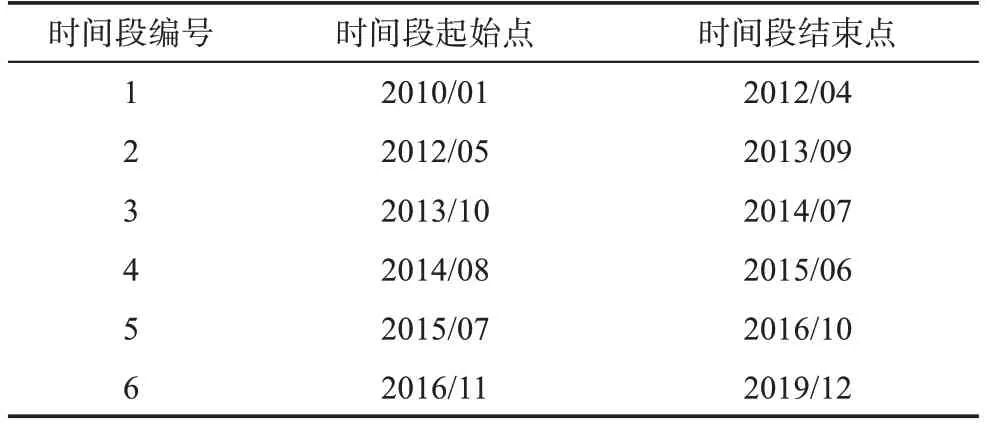
表4 關鍵詞數量序列的時間段
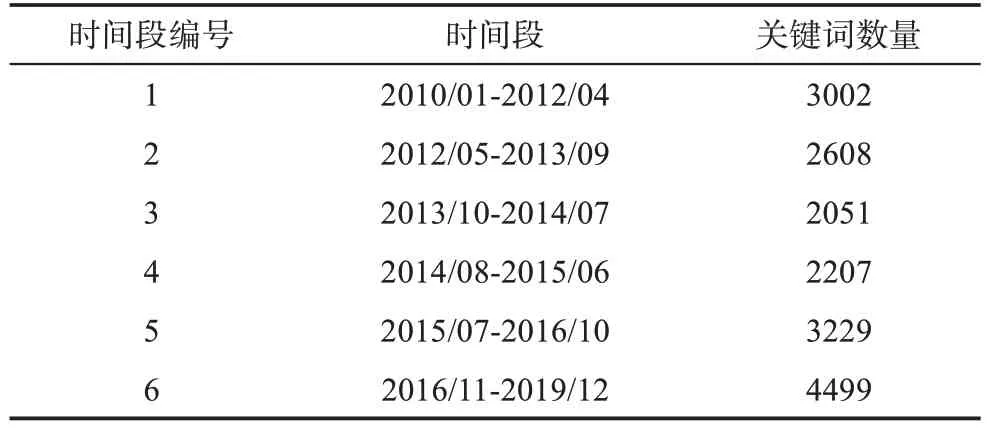
表5 各時間段內的關鍵詞數量
其次,依次在每個時間段內計算關鍵詞對應詞向量之間的余弦值,并以余弦值作為元素構建關鍵詞關系矩陣。基于此可得到6個關鍵詞關系矩陣,作為關鍵詞語義網絡。由于篇幅原因,這里只展示2010/01-2012/04時間段部分關鍵詞關系矩陣,如表6所示。
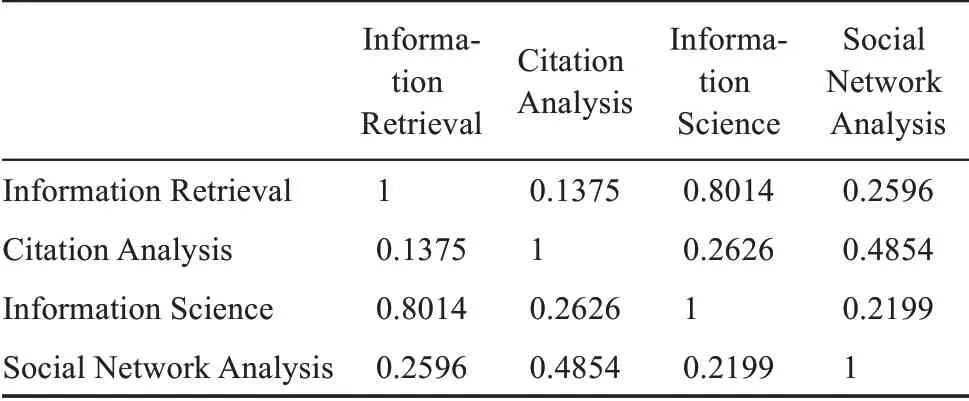
表6 2010/01-2012/04關鍵詞關系矩陣(部分)
得到動態關鍵詞語義網絡后,利用Fast Unfold‐ing進行剪枝并識別網絡中的社區,最終輸出代表社區的關鍵詞列表。整個動態網絡共識別出154個社區,各時間段網絡的剪枝閾值、社區數量以及對應的模塊度如表7所示。

表7 各時間段內關鍵詞語義網絡的社區劃分結果
這里需要為每個社區賦予主題標簽。首先,利用Python語言為154個社區中的每個節點計算其相應的Z-Score值,選擇社區中Z-Score值最大的節點作為該社區的主題標簽,并以Z-Score值超過2.5的節點為該社區的核心節點。之后,基于社區的核心節點度量相鄰時間段間的社區相似度,參考Schwartz等[27]的研究,將主題相似度閾值δ設為0.7,即相似度大于0.7的主題存在演化關系。圖6顯示了信息科學領域2010—2019年的主題演化路徑圖。
我們可以發現,近十年間信息科學領域存在明顯的主題演化現象。例如,2013/10-2014/07時間段內的“Collaboration Analysis”(合作分析)、“Col‐laboration Network”(合作網絡)、“Social Network Analysis”(社交網絡分析)、“Co-authorship Net‐work”(合著網絡)以及“Network Analysis”(網絡分析)五個研究主題融合為2014/08-2015/06中的“Network Analysis”(網絡分析),體現了主題合并;2013/10-2014/07時間段內的“Text Mining”(文本挖掘)主題分裂成2014/08-2015/06中的“Text Mining”與“Social Media Analysis”主題,體現了主題的分裂;又如,2016/11-2019/12時間段內產生了新的研究主題“Big Data”(大數據),2015/07-2016/10時間段內的“Epistemology”主題在2016/11-2019/12中消失,這體現了主題的新生與衰亡;同時,“Cita‐tion Analysis”(引文分析)貫穿了整個過程,其對應社區的大小也在不斷發生改變,體現了主題的成長和衰減。
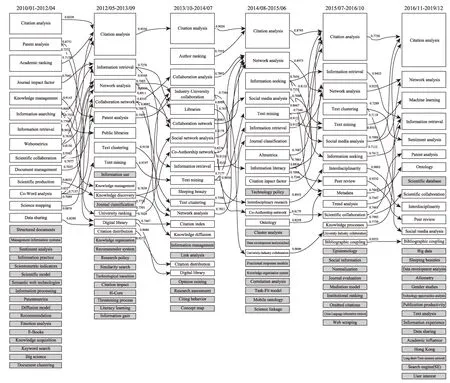
圖6 信息科學領域主題演化路徑圖(2010—2019年)
基于圖6所示結果,我們可將近十年信息科學領域的研究主題劃分為計量、管理和技術三部分。①計量維度包括文獻計量、信息計量、科學計量以及網絡計量等定量化研究,如一直貫穿信息科學領域的“Citation Analysis”,以及演化過程中與其合并的“Academic Ranking”(學術排名)、“Author Ranking”(作者排名)等,它們是文獻計量學中的常用方法,致力于對期刊、學者以及科學研究的影響性進行定量化評估。可以看出,定量化研究是信息科學領域的重要研究方向與必然趨勢;②管理維度是管理學在信息科學領域進一步深化和拓展,如圖中的“Knowledge Management”(知識管理)、“Document Management”(文檔管理)及其演化出來的“Information Retrieval”(信息檢索)等;③技術維度是指信息科學領域不斷引入數學模型、計算機算法等工具展開新的研究,包括數學模型、深度學習等主題,如圖中的“Text Mining”(文本挖掘)、“Text Clustering”(文本聚類)、“Machine Learning”(深度學習)以及“Scientific Model”(科學模型)等。該維度的主題是信息科學領域重要的新興趨勢,應當予以重視。
下面,我們以“Citation Analysis”研究主題相關演化路徑(圖7)為例進行重點探討,并與權威期刊文獻的分析結果進行對比驗證。
從圖7可以看出,2010/01-2012/04時間段中有“Citation Analysis”“Academic Ranking”“Journal Im‐pact Factor”(期刊影響因子)以及“Webometrics”(網絡計量學)四個研究主題,在2012/05-2013/09時間段內融合為“Citation Analysis”,這說明越來越多的學術、期刊影響性以及網絡計量學研究用到引文分析方法,使四個主題之間的關系越來越緊密,進而融合。我們的結論也與很多學者的研究相一致,例如,學者Vaio等[28]明確指出,引文分析是評估期刊和學術研究的重要工具,并用引文分析研究經濟學相關期刊的排名;同時,2014/08-2015/06中的“Text Mining”主題融入2015/07-2016/10中的“Citation Analysis”,例如,學者Kralj等[29]明確提出通過結合文本挖掘技術與引文網絡分析為研究問題帶來了新視角,利用“Text Mining”構建新型的引文網絡;此外,2014/08-2015/06時間段內的“Alt‐metrics”(替代計量學)和2015/07-2016/10的“So‐cial Media Analysis”(社交媒體分析)均融入了“Citation Analysis”,這表明基于網絡媒體文本的新式計量學為“Citation Analysis”帶來了“新鮮血液”,例如,學者Sud等[30]指出通過挖掘轉發、評論等社交媒體關系可以準確地識別意見領袖。
接下來,本文采用傳統的平均時間段劃分法對主題演變的時間段進行劃分,并對2010—2019年信息科學領域的主題演化路徑進行描繪,結果如圖8所示。可以明顯看出,圖8與圖6相比丟失了很多主題,如圖6中2012/05-2013/09時間段內的“Tech‐nological Transition”(技 術 轉 型)、“Information Gain”(信息增益),2013/10-2014/07時間段內的“Citing Behavior”(引用行為)、“Concept Map”(概念圖)以及2014/08-2015/06時間段內的“Technolo‐gy Policy”(技術政策)、“Knowledge Organization System”(知識組織系統)等主題均沒有在圖8中出現,這也進一步體現出本文提出的分段線性法的優越性。
我們還將本方法與K-means和LDA兩類方法同時進行對比,以驗證本文在主題識別上的有效性。參照林江豪等[24]的研究,我們首先依據信息科學領域專家意見建立一個標準“主題-關鍵詞”集(標準集),作為各類方法分析結果的對照標準;其次,分別基于本文方法、K-means和LDA得出相應的關鍵詞集,并把分析結果與標準集進行對比。由于篇幅原因,這里只展示部分結果,如表8所示。首先,我們邀請了5名信息科學領域專家從6個時間段內分別隨機挑選2個主題,共得到12個研究主題(表8第2列);然后,由專家確定與主題對應的關鍵詞集(表8的第3列);接下來,我們分別使用本文方法、K-means和LDA三種方法進行主題識別,結果如表8的第4~6列所示。
之后,我們以準確率、召回率和F1值作為評價指標將三種方法的分析結果與人工建立的標準集進行比較,對比結果如圖9所示。
從圖9可以看出,本文方法分析結果所在的值基本都在圖的上部,這表明對于6個時間段內的12個主題,本文方法的3個驗證指標值大多優于Kmeans和LDA方法,顯示了本文提出的動態語義網絡分析方法具有更好的主題識別效果。
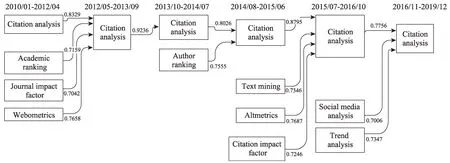
圖7 以“Citation Analysis”主題為主的演化路徑圖
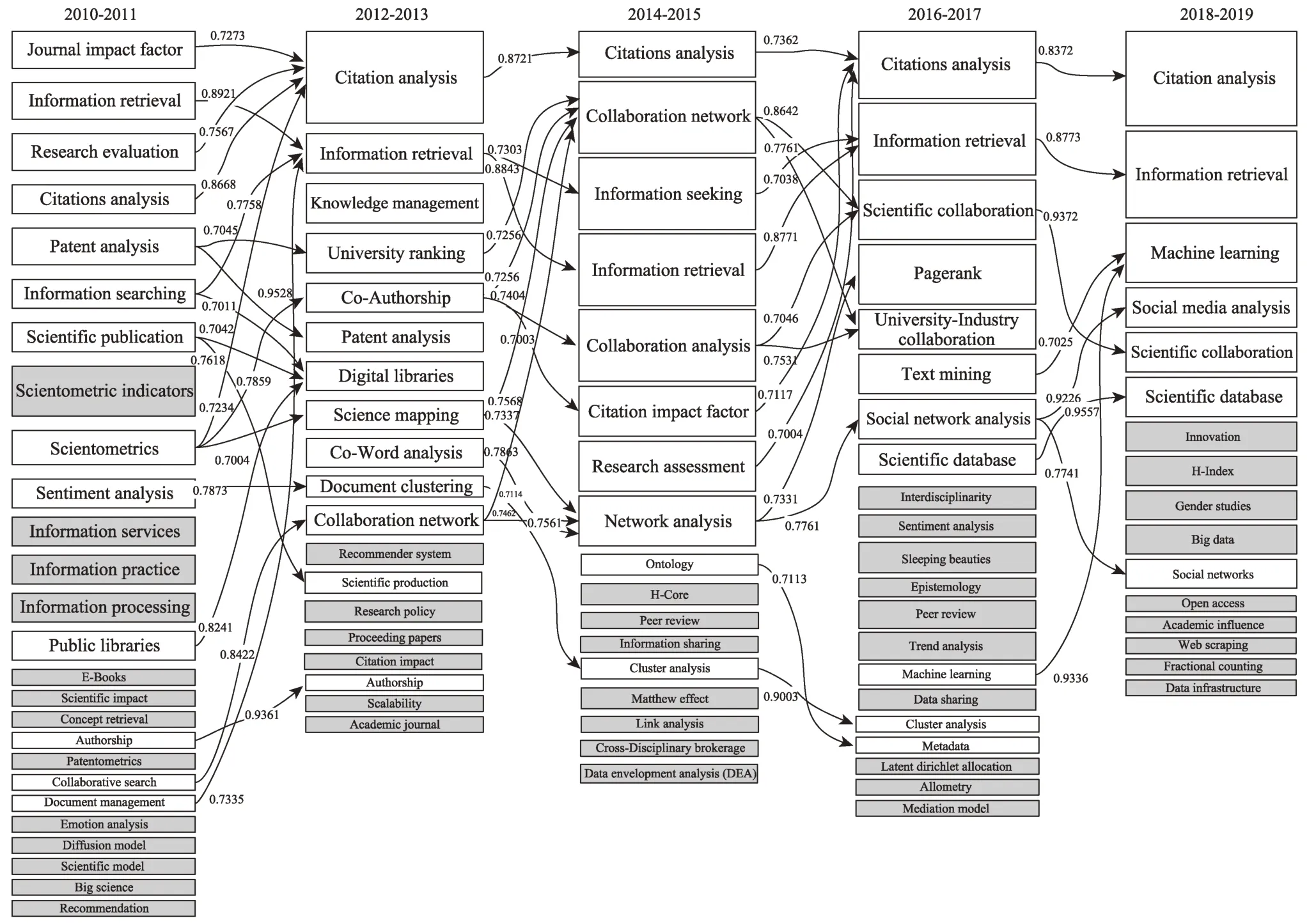
圖8 信息科學領域主題演化路徑圖(平均時間段劃分法)
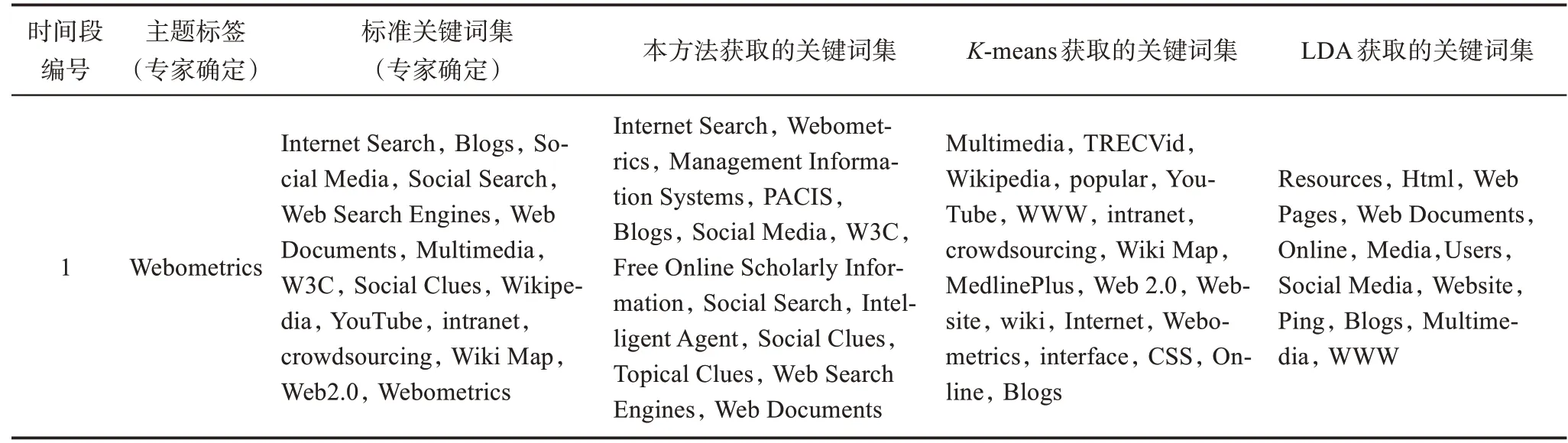
表8 主題詞分析結果示例
4 結論與不足
本文提出了一種基于動態網路的主題演化路徑識別方法,一方面,引入分段線性表示法對主題演變的時間段進行劃分,解決了傳統主題演化路徑識別研究劃分時間段不合理的問題;另一方面,基于Word2Vec模型構建動態網絡,并利用社區發現算法在動態網絡中識別主題,充分考慮了關鍵詞之間的語義關系以使分析結果更加準確。
本研究也存在一些不足。首先,分段線性表示法仍可以繼續改進,例如,最新的基于時序趨勢的分段線性化算法,在數據集上展現了分段少、逼近性好等優點;其次,本文通過將短語形式的關鍵詞轉換為駝峰形式,對語料庫中相應的關鍵詞進行了替換處理,這樣可能會因為改變語料庫的文本結構而降低關鍵詞向量識別的準確度,在未來的研究中可以考慮利用Phrase2Vec模型對關鍵詞向量進行訓練。
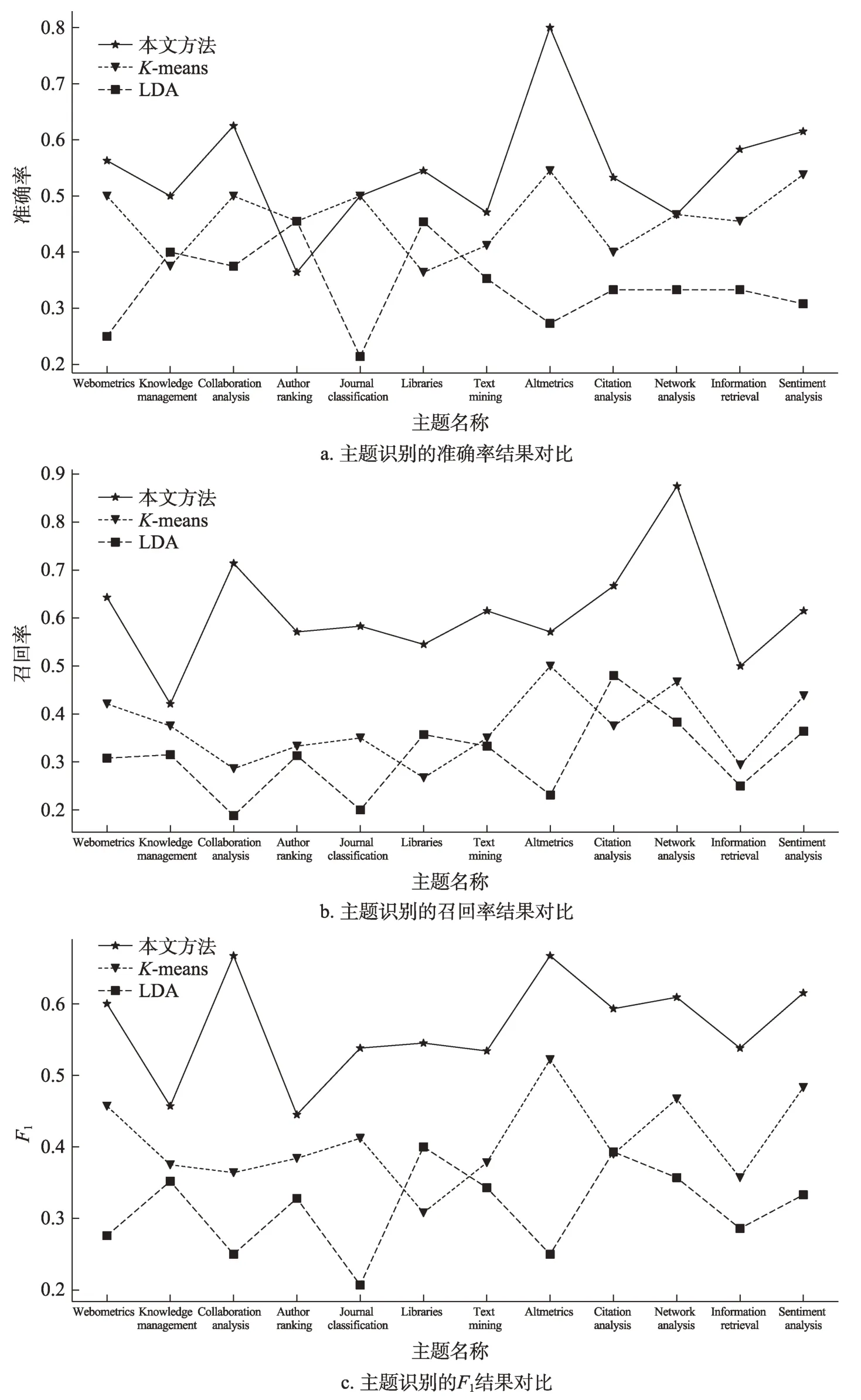
圖9 主題識別的結果對比
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
