基于圖像深度預測的景深視頻分類算法
2021-06-03 07:08:50錢立輝王斌鄭云飛章佳杰李馬丁于冰
浙江大學學報(理學版) 2021年3期
關鍵詞:深度
錢立輝,王斌*,鄭云飛,章佳杰,李馬丁,于冰
(1.清華大學 軟件學院,北京 100084;2.北京快手科技有限公司,北京 100085)
如今,短視頻由于較好地利用了娛樂生活中的碎片時間,受到了人們的追捧。其中,利用單反等相機拍攝的景深效果視頻因其高清、美觀,具有較好的藝術觀賞性,廣受大眾喜愛。用戶在視頻分享平臺上傳、分享視頻時,往往需要對景深視頻類型進行篩選,以方便后續進一步操作,如視頻推薦算法、視頻超分辨率去噪等應用。同時,在海量數據時代,靠人力在平臺后端服務器逐個鑒別、篩選是不現實的,因此,研究能自動檢測視頻數據庫中景深視頻的算法具有一定的現實意義和價值。
在視頻分析、分類中,傳統算法通常側重于啟發式特征設計,運行速度較快,但識別精度較低。深度學習技術能高效地學習視頻中的時空域特征和高級視覺特征,目前,已有較多應用深度學習的算法,并獲得了較傳統算法更優秀的性能。然而,將深度學習算法直接用于景深視頻檢測尚存在一些問題,第1,已有的應用深度學習的景深視頻算法[1-2]大多為分割算法(即逐像素分類算法),輸出的分割結果圖譜,不能直接應用于視頻分類檢測任務;第2,景深視頻數據集較少,而過小的訓練集易使網絡發生過擬合。由于數據集的數據分布(如視頻內容、風格)存在差異,當在某些數據集中訓練的深度網絡,在其他數據集中進行測試時,網絡性能通常會降低。
此外,在景深視頻中,幀圖像通常具有很強的視覺語義深度信息,圖像中各個物體隨其與相機焦平面的距離遠近出現的模糊差異具有一定的邏輯性。同時,在快手app 視頻數據集中,存在大量由某些編輯特效形成的與場景景深無關的偽景深視頻,即部分清晰、部分模糊,影響模型識別的性能。若在深度網絡訓練中,應用注意力機制,顯式地使模型“注意”到與圖像的場景深度相關的特征,則可在一定程度上提高景深視頻分類的性能。
針對上述問題,本文提出基于圖像深度預測的兩階段景深視頻檢測算法。第1 階段為預測視頻幀圖像中各個語義物體的深度,即其與相機的相對距離,然后利用該深度信息,輔助第2 階段構建景深分類網絡,以提升網絡模型的檢測速率。第1 階段使用的是DeepLens 圖像深度預測網絡模型[3],第2 階段使用的是經過輕量化處理的改善后的ResNet18網絡模型[4]。本文還設計了一種在新視頻數據庫中收集景深視頻數據的迭代算法,能快速地獲取新的同數據分布的景深視頻數據集,所需的人力成本較低;同時,這些新搜集的數據集還可用于提升本文網絡模型的性能。本文算法在快手線上的景深視頻數據集中識別準確率達85.7%。
1 相關工作
相關工作主要包括視頻質量評價(video quality assessment,VQA)算法和視頻分割(像素級分類)算法。
在景深視頻幀圖像中,焦平面內(即景深內)被拍攝的物體是清晰的,焦平面外被拍攝的物體由于入射光線發生聚集和擴散,影像較模糊,形成一個圓形區域,通常稱為彌散圓[5]。這類幀圖像(包含模糊部分和清晰部分)與失真圖像(模糊)部分類似,所以可以借鑒VQA 算法的思路,通過視頻質量分數,判斷其是否為景深類型視頻。傳統的VQA 算法有:峰值信噪比(peak signal-to-noise ratio,PSNR)[6]法、結構相似性指數法(structural similarity index method,SSIM)[7]和三維數據可視化matlab 工具ViS3d[8]等。目前基于深度學習的VQA 算法較為流行,其性能亦不斷被優化,如文獻[9-10]。但由于景深模糊和壓縮失真模糊存在一定的視覺差異,前者往往為局部模糊,后者為整體模糊,因此,用此類算法篩選的景深視頻錯誤率較高。
也有一些可直接預測景深視頻像素的分割算法,如文獻[11-12]手工設計了景深像素敏感的特征描述子,其中,文獻[11]側重于模糊邊緣部分的特征提取,基于稀疏表示和圖分解,建立稀疏邊緣表示和失真估計之間的關系。文獻[13]利用端到端的全卷積網絡學習圖像中的高級視覺語義特征,預測圖像景深外模糊區域。考慮深層網絡特征更抽象,該方案選用了較深的網絡模型。然而很難將該方法直接應用于景深視頻分類,首先,其僅預測了模糊分割結果,與視頻是否有景深效果不相關(有可能為偽景深視頻),需要做進一步后處理,如利用分割結果圖譜或中間特征圖譜預測視頻類型。其次,分割算法需要人工進行精細標注,其收集成本遠高于分類任務所需的標注數據。文獻[1]通過訓練與U-Net[14]類似的深度網絡,檢測圖像中的景深外模糊和運動模糊。文獻[2]針對模糊的好壞提出了分類預測的統一框架(如景深效果中的模糊是好的,壓縮模糊是壞的)。此類算法屬于分割算法,預測了景深外側模糊像素,經改善,可將其應用于景深視頻分類篩選。但此類算法均未考慮景深視頻幀圖像中各語義物體的深度差異。
2 基于深度預測的視頻分類算法
本文在文獻[1-2]算法的基礎上,將幀圖像分割結果轉變為視頻類型預測,但在后處理過程中會導致精度降低。考慮景深視頻幀圖像中各語義物體與相機的相對距離存在一定的邏輯關系,本文利用注意力機制,提出了一種基于圖像深度預測的新的兩階段景深視頻分類算法,該算法的網絡模型如圖1 所示。此外,提出了可大幅降低人力成本的迭代式景深視頻數據集收集算法。
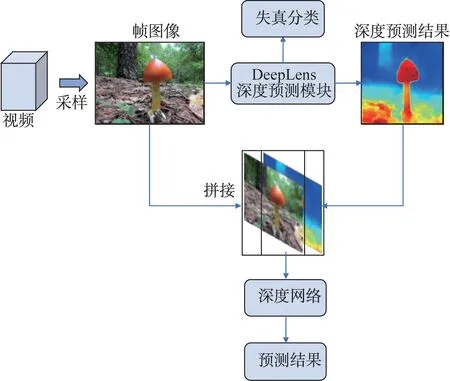
圖1 整體網絡模型Fig.1 Overview network model
2.1 兩階段景深視頻分類網絡
2.1.1 幀圖像深度與景深類型的邏輯關系
在景深視頻幀圖像中,各語義物體與相機的相對距離不同,在景深范圍內的物體成像較為清晰,而在景深范圍外的物體成像較為模糊。這意味著,在景深類型的視頻幀圖像中,包含較為明顯的深度特征信息,如圖2 所示。圖2 中,紅框為景深范圍內物體的成像,藍框為景深范圍外物體的成像。可見,兩個框中的物體具有明顯的距離差,紅框中的物體與相機的距離更近。

圖2 景深類型圖像樣例Fig.2 Depth-of-field image samples
根據相機成像原理[5],不同物距的物體成像后清晰度不同。因此,在景深視頻幀圖像中,清晰部分對應的物距是類似的。這為深度網絡預測幀圖像景深類型提供了新思路,即在深度網絡預測幀圖像類型時,如果事先得到該圖像的景深信息,并將其作為顯式特征指導后續預測算法,那么可進一步降低誤檢率。通過顯式的圖像景深信息,新網絡能判定的邏輯關系更豐富,見表1。
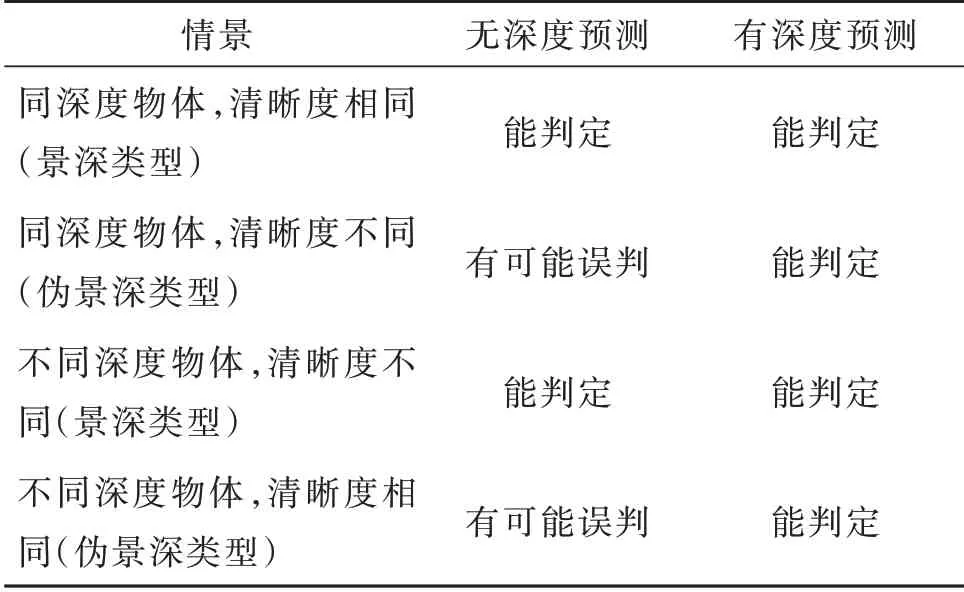
表1 判定邏輯比較Table 1 Decision logic comparison
例如,在圖2(a)中,葉尖(紅框部分)與葉根(藍框部分)具有不同的物距深度,如果均為高清像素,則可判定其為非景深視頻幀;而以往的深度網絡如果僅學習到了中間部分為高清,邊緣部分為模糊,就會判定其為景深視頻幀,則出現了誤判。
2.1.2 幀圖像深度預測網絡
幀圖像的深度預測模塊選用的是DeepLens 網絡模型中的深度預測模塊。輸入某圖像后,該模塊將輸出對應的深度預測熱力圖,部分結果如圖3 所示,其中,左側為輸入的圖像,右側為對應的深度預測結果熱力圖,偏紅的區域表示深度較小,偏藍的區域表示深度較大。

圖3 深度預測網絡結果示意Fig.3 Depth prediction results
分割任務中的深度網絡模塊包含編碼器和解碼器兩部分,編碼器采用預訓練的ResNet 50 架構[4],解碼器則由一系列上采樣模塊構成,同時包含來自編碼器的跳躍連接。與跳躍連接對應的2 個層分辨率相同,分別用于減少在網絡正向計算時下采樣操作中的特征損失和防止網絡梯度傳播中出現梯度消失現象。該模塊采用多任務訓練方式,同時訓練網絡預測深度估計和前景分割數據集,以提升網絡的泛化能力。
考慮景深檢測任務和失真問題的相似性,本文借鑒多任務聯合訓練的方法,在將該模塊用于景深深度提取的同時,預測圖像是否失真(獨立于景深類型的一個人工標簽),即增加一個分類損失,從而進一步增加多任務訓練的多樣性,提升性能。其損失函數為

其中,Loss 表示該模塊的總損失;Lossdeep表示深度預測的損失[3],λ表示協調損失權重的參數,y1表示樣本是否為失真類型的標簽,Y1表示網絡該分支的輸出。因此,此處深度預測模塊有2 個輸出:深度預測結果熱力圖和圖像失真情況分類。
2.1.3 視頻景深類型預測網絡
通過幀圖像深度預測模塊得到幀圖像深度信息,并將其用于執行景深分類任務,以提高預測網絡性能。這里并不需要為景深設計特定的特征描述子,只需將其作為指導性特征,輸入景深分類網絡。
本文將原幀圖像和預測的深度預測結果熱力圖按通道合并作為輸入。由于深度預測模塊輸出的維度與圖像輸入的維度不同,如果對輸入幀圖像做縮放處理,易導致變形,使圖像語義發生變化,混淆網絡提取特征,為此,首先,將輸入圖像以其短邊為基準,裁剪成長、寬相等,再縮放至224×224×3 的特定尺寸。隨后將深度預測結果的尺寸也縮放為224×224×3,按照通道維度合并拼接,得到新的輸入圖像,維度為224×224×6。考慮在景深類型分類任務中需要一定的高級語義特征,但較深的網絡運行速率低,本文選擇ResNet 18 架構[4],對其做一定修改后作為本文的深度網絡,結構見表2。表2中,Bottleneck 代表殘差模塊,重復次數表示相同殘差模塊的連接個數。該深度網絡相對于ResNet 18結構的主要不同在于輸入、輸出的維度和中間各殘差模塊的重復次數。在實際應用中,網絡消耗越深,計算資源越多,而預測性能的提升卻有限,因此,做了折中處理。
該模塊的損失函數為預測的景深分類結果和真實標注之間的交叉熵,記為
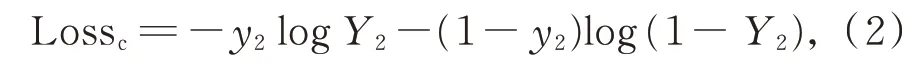
其中,Lossc表示景深分類預測損失,y2為樣本是否為景深類型的標簽,Y2表示網絡的輸出。
2.2 迭代式景深視頻數據集收集算法
通常,公開的景深數據集很少,大多為圖像類數據集,且規模較小,與實際應用中的待測試數據分布差異較大。如數據集CUHK[1]幾乎全為風景類,而在快手線上,人物影像類視頻居多。然而,由于景深視頻在線上出現的概率較低,如果直接用人工篩選打標則費時費力,因此需要一種可以在新的數據集上低成本地收集打標所需數據的方法。為此,提出迭代式景深視頻數據集收集算法,流程如圖4 所示。
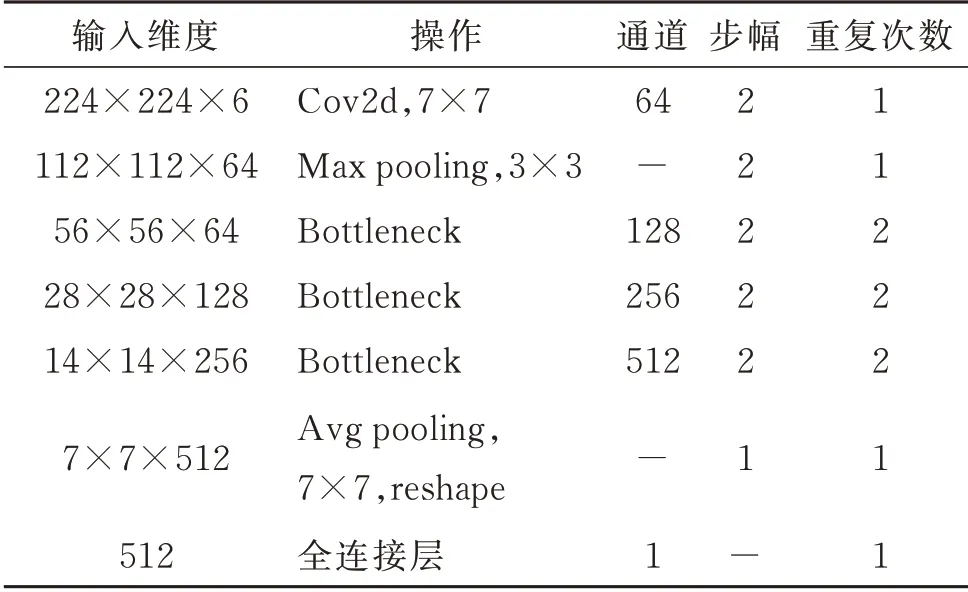
表2 深度網絡結構Table 2 Depth network structure

圖4 迭代式景深視頻數據集收集流程Fig.4 Iterative depth-of-field video collection
記隨機初始化的模型參數為M0。首先,將模型在其他數據分布的公開數據集S0中訓練,使用Early Stopping[15]的思想訓練若干代數,得到模型參數M1。隨后在快手線上隨機篩選K個數據視頻集S1作為測試集,這時將模型M1對S1中預測判定為“景深”的視頻數據,即其子集Z1做人工篩選。相較于直接在S1中做人工篩選,Z1中出現景深視頻的概率p更大(p等于模型對于S1預測的正確率),從而降低了人力成本。隨后將新搜索得到的有標數據(包括景深視頻和非景深視頻)加入S0中,重新訓練網絡模型,得到M2,繼續以同樣方法,在新的一批線上視頻S2中做預測、搜索和打標,依次迭代,直至網絡性能無明顯提升或不再提升。通過該算法迭代實際完成了2 個任務:(1)通過增加訓練數據和改善訓練數據分布,進一步提升了深度網絡的性能;(2)以較低成本得到了大量景深視頻數據,用于進一步研究。
3 實驗及數據分析
實驗比較的數據集包括在快手線上收集的景深視頻數據集和文獻[1]中的景深圖像數據集CUHK,其中,快手線上收集的景深視頻共350 個,包含171 個景深類型視頻和179 個普通視頻。在景深視頻類型中,對光圈大小和焦深不作要求,唯一標準是景深;而普通視頻類,包括模糊視頻和清晰非景深視頻兩類。
3.1 參數選擇和訓練細節
模型訓練的批大小(batch size)設置為32,網絡模型使用Adam[16]優化器訓練,初始的學習率設置為0.001,后續每50 個epoch 學習率降為之前的0.1倍。大量實驗表明,宜將式(1)中的λ設置為0.9。在快手線上的視頻數據集中,用140 個景深視頻和140 個非景深視頻作為訓練集,余下數據用于測試。訓練中,首先對視頻做采樣幀處理,對于輸入的視頻,每間隔10 幀采樣一幀,以降低計算量。測試時,將所有采樣幀輸入網絡,并將所有結果的均值作為網絡對視頻的分類預測。而CUHK 圖像數據集則無須該處理。網絡為回歸輸出,即為(0,1)內的分數,值越大表示為景深視頻的概率越高,以T=0.4作為閾值。在迭代式數據集收集訓練中,迭代次數設為4,每次迭代收集的數據集大小為K=1 000。
首先,需加載DeepLens 模塊預訓練的參數,以提高初始參數分布的有效性,同時,快手線上景深視頻數據不包含分割網絡所需要的標注,無法計算該模塊的損失函數,模型僅在首次訓練時以學習率0.000 1 微調DeepLens 模塊,在后續的迭式訓練中凍結DeepLens 模塊中的參數,只訓練分類網絡模塊。
3.2 快手線上數據的測試對比實驗
由于文獻[1]和文獻[2]均為分割算法預測像素分類,無法直接預測視頻類型。為公平比較,本文先對預測結果做進一步處理,然后再進行預測視頻分類。對于文獻[1],由于其預測圖像中每個像素模糊的種類(未失真、運動模糊、景深外模糊)不同,因此將其預測結果中景深范圍外模糊占比高于20%或沒有運動模糊只有景深范圍外模糊的幀圖像判定為景深視頻幀;對于文獻[2],將預測結果為“好模糊”的幀圖像判定為景深幀。此外,考慮快手線上數據無分割標簽,無法用于訓練文獻[1]和文獻[2],因此僅在CUHK 數據集中做了比較。所有實驗均重復20 次,取均值作為最終結果,見表3。

表3 快手線上景深視頻數據實驗結果Table 3 Experimental results of Kuaishou depth of field video
表3 中,本文算法表示與其他方案一致的訓練數據集(即訓練中沒有加入快手數據集),本文算法+表示迭代式地利用快手視頻數據訓練網絡。由表3可知,本文算法在準確率和召回率上均較文獻[1]方法和文獻[2]方法好。其中,文獻[1]方法表現較差的主要原因是其只做了分割任務的訓練學習,不適用于直接視頻分類任務。同時,在訓練集中加入快手線上數據后,可看到本文算法的性能得到了進一步提升,這也證實了迭代式景深數據集收集算法的作用。
3.3 深度預測特征的有效性
為驗證深度預測模塊的有效性,進行消融對照實驗,即刪去DeepLens 深度預測模塊,在網絡模型中只輸入224×224×3 的原始幀裁剪圖像,結果如表4 所示。進一步,在文獻[1]方法中,嘗試將深度預測的結果,如本文方案中的按通道合并,加入輸入中,即只改變網絡的輸入和第1 層的輸入維度,并在同樣的景深像素分割任務中進行訓練測試,觀察其分割性能指標的變化,結果如表4 所示。
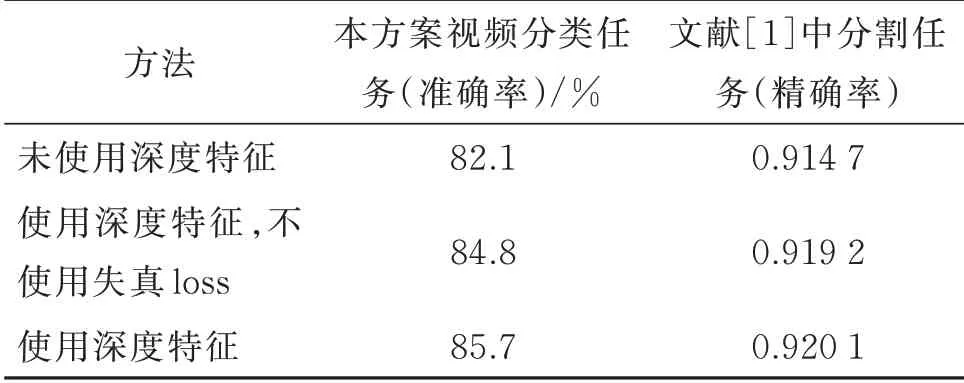
表4 深度預測特征有效性實驗結果Table 4 Experimental results of the validity of depth features
由表4 可知,在與景深強相關的任務中,加入景深深度信息可有效增加模型特征的感知能力,從而提高模型的性能。
3.4 深度預測特征的有效性
為驗證迭代式景深收集算法的性能,收集了不同迭代次數的算法性能,如表5 所示。隨著迭代次數的增加,算法的性能得到逐步提升,迭代之初提升較快,之后提升變慢。多次迭代后,算法訓練的數據集瓶頸得到消除。

表5 迭代式景深視頻收集算法性能變化Table 5 Performance versus number of iterations in the iterative depth-of-field video collection algorithm
同時,按照本文算法在較短時間(2 h,只統計人工篩選的時間)內在快手線上收集到了105 個景深視頻。
3.5 可視化結果比較
表6 可視化地展示了迭代式景深視頻收集算法帶來的性能提升(分數越高,為景深視頻的概率越大)。表6 中,第1 和第3 行為景深視頻截圖,2 個方案都預測準確。第2 行為偽景深視頻幀,臉部同時存在清晰、模糊,未使用深度特征的算法發生了誤判。第4 行也為偽景深視頻幀,場景有較強層次感,但遠、近處清晰度相似。

表6 本文算法預測分數可視化比較Table 6 Visualization of prediction score
可見,本文算法可較好地識別景深深度邏輯存在問題的偽景深視頻幀。
4 結論
研究了景深視頻分類算法的線上應用問題和深度學習分類應用的幾個問題。針對景深視頻分類任務,由景深成像原理,在景深視頻幀圖像中,根據景深預測結果,可解決預測邏輯問題,從而降低誤檢率。針對線上數據集較少的問題,設計了迭代式景深視頻數據集收集算法,以較低的勞動成本實現快速收集所需數據,具有一定的應用價值。
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
