運用數據挖掘技術開展醫療保險基金審計
2021-05-27 01:46:40
審計月刊 2021年2期
在大數據時代背景下,醫療保險基金信息化管理已較成熟,醫療保險基金數據呈現數據類型多樣、數據量大、專業性強等特點。而傳統的醫療保險基金審計,面對海量醫療診療、門診住院結算業務數據,只能抽審部分病例檔案,既難以實施全面核查,又難于接觸到深層次問題,導致審計存在較大的風險。應用數據挖掘技術開展醫保基金審計能提高問題查找的精準度,實施精確打擊,找到住院醫療報銷業務中的薄弱環節,順利實現審計目標。
一、審計思路
本文利用數據挖掘技術里面的SPSS Statistics標識異常點模型和SPSS Modeler支持向量機回歸算法(即Svm建模)來建立住院單病種病例模型。通過數據挖掘技術,查找明顯不符合常規的疑問數據,同時建立預測分析模型,將預測值和實際值差異較大的記錄列為疑點;通過建模篩選疑點再進一步審計核查,分析單病種住院情況下是否存在超范圍、超比例、超標準支付醫療保險基金的情況,可以大大提高審計效率。
二、數據挖掘技術審計應用實例
(一)運用SPSS Statistics標識異常點模型分析實例
模型概述:SPSS Statistics標識異常點模型可以發現和分析明顯偏離數據總體、不符合被審計單位業務規律的異常數據,從而找到對完成審計工作有價值的信息的一種數據挖掘方法。
審計思路:標識異常點模型是從被審計單位海量的財務數據中發掘出少部分的不符合整體規律的或明顯存在異常的數據進而進行審計任務的模式。通常來說這種異常的數據通常會比大多數的數據更具有審計價值。
分析步驟:
第一步數據預處理。獲取的醫療保險基金行業數據存放在sql sever數據庫中,提取字段(住院序號、醫院編碼、醫院名稱、住院科室編碼、出院時間、入院時間、出院病種名稱、姓名、身份證號、總費用、藥費、項目費、統籌范圍費用金額、統籌支付、個人支付、年齡、本年住院次數)整理成所需的報銷明細表excel表格導出存放。
第二步標識異常點模型建立。第一種方法利用SPSS Statistics軟件篩選出異常值,“數據-標識異常個案”,將住院時間、出院病種名稱、總費用、統籌范圍報銷金額作為分析變量,將身份證號作為個案識別變量,直接輸出異常個案索引列表,得到異常值個案結果。將身份證號標識的個案異常點列為疑點重點,核查其檔案資料,分析該病人住院期間有無異常費用支出。第二種方法利用SPSS Statis?tics軟件中的“圖形-圖表構建程序-箱圖”篩選出離群值,編輯元素屬性,設置X變量為出院病種名稱、Y變量為統籌范圍費用金額,直接輸出箱圖離群值結果,改離散點所代表的住院記錄作為疑點重點分析,核查其檔案資料,分析該病人住院期間有無異常費用支出。
(二)運用SPSS Modeler支持向量機回歸算法模型分析實例
模型概述:支持向量機回歸算法模型是一種對線性和非線性數據進行分類的算法,使用一種非線性映射,把原訓練數據映射到較高的維上;在新的維上,搜索最優分離超平面。Svm通過海量數據訓練后得出的最優化算法,可以用于任何線性或非線性的高級分類。
審計思路:SPSS Modeler支持向量機回歸算法模型是基于住院患者的病種、住院時間、年齡等詳細數據,在學習海量數據中挖掘醫療報銷費用和各相關因素之間的隱含聯系,從而預測患者合理的醫保報銷金額,篩選出實際值與預測值差異較大的疑點。
分析步驟:Svm建模需要利用SPSS Modeler軟件來分析建模。具體流程見下圖。
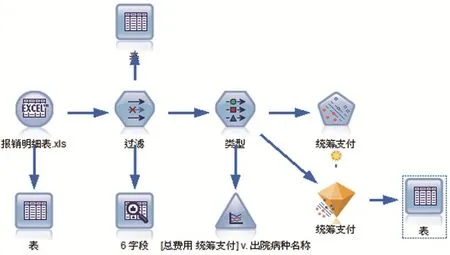
第一步:數據預處理,提取字段(住院序號、醫院編碼、醫院名稱、住院科室編碼、出院時間、入院時間、出院病種名稱、姓名、身份證號、總費用、藥費、項目費、統籌范圍費用金額、統籌支付、個人支付、年齡、本年住院次數)整理成所需的報銷明細表excel表格導出存放。
第二步:將表中不需要的字段利用過濾功能把住院序號、住院科室碼、出院時間、入院時間、姓名、身份證號等字段過濾。
第三步:添加字段選項類型節點,將統籌范圍費用金額字段設為目標,其他字段除醫院名稱外設置為輸入。
第四步:導入支持向量機(Svm)模型,選擇Svm模型節點建模節,運行生成結果,輸出表查看;并輸出一個多重散點圖查看各個單病種統籌支付平均金額結果。
第五步:將單病種報銷表中統籌支付金額與該病種統籌支付平均金額相差較大的記錄列入疑點,重點核查。
Svm模型篩選出來預測值與實際值比例相差過大的疑點,都是值得重點關注的對象。該數據挖掘分析作為模擬性研究,具有前沿參考價值,在實際工作中,應不斷結合真實數據進行模擬預測,經實踐檢驗之后,可運用于實際。
三、方法小結
隨著信息時代數據的海量增長,我們在審計工作中需要運用更加多樣化的技術,從繁雜的數據中發現有用的審計線索,并將這些數據轉化成有組織的、可利用的信息。SQL Server、Oracle等大型數據庫軟件對數據具有高效的批量管理和語句查詢功能;SPSS Modeler等分析平臺軟件能夠體現對數據分析的描述性和預測性,能夠運用聚類、回歸、離群點檢測等數據挖掘技術反映數據內在信息。本次醫療保險基金審計中應用數據挖掘技術,在海量數據中輕松鎖定審計疑點,極大地提高了審計效率,推動了審計信息化的發展,在大數據審計方式上取得了新的突破。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
