一種求解復雜優化問題的快速遺傳算法算子
2021-05-26 02:23:40付加勝韓霄松
吉林大學學報(理學版) 2021年3期
關鍵詞:優勢
裴 瑩, 蘇 山, 付加勝, 韓霄松
(1. 長春財經學院 信息工程學院, 長春 130122; 2. 吉林大學 計算機科學與技術學院, 符號計算與知識工程教育部重點實驗室, 長春 130012; 3. 中國石油集團工程技術研究院有限公司 鉆井工藝研究所, 北京102206)
遺傳算法(genetic algorithm, GA)是一種啟發式的搜索策略, 通過模擬生物進化論的自然選擇和遺傳學機理搜索最優解[1]. Holland[1]提出的模式定理和積木塊假說為GA提供了理論依據. GA源于一組候選解決方案的種群, 其中每個候選解決方案是該種群的個體或染色體, 染色體通過基因進行編碼得到. 根據優勝劣汰原則, 將種群中的染色體通過交叉、 選擇和變異等操作, 產生含有更好解決方案的新群體. 產生的新種群每一代都不弱于前一代, 直到滿足進化終止條件, 最優個體被解碼并被用于問題的最佳解決方案. GA由于結構簡單并具有強大的全局搜索能力, 廣泛應用于機器人與自動控制[2]、 交通調度[3]、 車間調度[4]和神經網絡訓練[5]等領域.
分析表明, GA的運行依賴于大規模的個體適應度計算, 當適應度計算較復雜時, GA尋優過程十分耗時. 很多優化問題(尤其在工業領域)需要優化的參數維度通常較高(high-dimensional), 適應度計算復雜(expensive-computationally), 且有些優化問題無法得到數學解析式, 解決方案的優劣依賴于其他工具(black-box), 這類優化問題的優化較困難, 被稱為HEB問題[6]. 針對HEB問題, 目前已有很多研究成果: Branke等[7]利用鄰近個體的適應度值通過插值和回歸估計個體的適應度, 取得了較好的實驗結果; Regis[8-11]將代理模型融合到粒子群等算法中, 得到了良好的實驗結果, 并將其應用到地下水除污等實際問題中[12-13]; 劉全等[14]提出了一種雙精英聯合遺傳算法避免了GA的早熟問題, 提高了收斂速度; Yoel[15-16]利用分類器預測能導致適應度計算失敗的參數組合, 通過篩選參數組合達到提升算法效率的目的; Han等[17]提出的EGA算法(efficient GA)中構建了聚類算法和模式理論的適應度估計策略, 通過減少適應度計算次數有效加速GA, 實驗結果表明, EGA算法在保證速度的同時具有與經典GA相似的優化精度, 并將該算法擴展到粒子群算法中, 取得了較好的效果[18].
上述研究大多數采用代理模型策略替代適應度函數, 從而通過減少調用真實適應度函數方法加快尋優速度. 通過提高算法收斂速度是解決HEB問題的另一種思路, 文獻[19]提出的基于全局最優預測的自適應變異粒子群優化算法(global prediction-based adaptive mutation PSO, GPAM-PSO), 利用主成分分析(PCA)算法對群體進行降維, 并在低維空間擬合曲面尋找更優粒子引導群體進化, 算法引入了自適應的變異策略避免陷入局部極值, 實驗結果表明, GPAM-PSO算法相比于經典粒子群算法可以更快地收斂. 本文將GPAM-PSO的核心思想擴展到GA, 提出通過聚集算子(aggregation operator)在GA進化中發現更優的個體引導種群進化, 從而使GA可以快速收斂.
1 聚集算子
對GA的算法流程分析表明, 種群中新個體的產生全部來源于交叉和變異操作, 其中絕大多數來源于交叉操作, 但兩兩交叉不是每次都產生更好的個體, 因而會使算法收斂速度緩慢, 且具有隨機性, 易產生早熟現象. 為解決該問題, 本文在GA中引入聚集算子, 該算子首先采用聚類方法對群體進行劃分, 然后對聚類后的每一簇個體用PCA算法進行降維, 再采用最小二乘法對降維后的種群個體分布進行擬合, 并求出低維空間下的優勢個體, 最后將該個體還原到初始空間保存到下一代種群. 聚集算子流程如圖1所示.

圖1 聚集算子流程
圖2對聚集算子的有效性進行了解釋, 其中紅色五角星位置為最優位置, 藍色三角星為每一代聚集算子產生的優勢染色體位置, 優勢染色體將引導種群向最優值靠近, 從而加速了搜索方法. 聚集算子主要包括GA種群劃分、 種群降維、 低維空間下種群分布擬合、 優勢染色體發現和優勢染色體返回五部分.

圖2 聚集算子特征
1.1 基于AP聚類的GA種群劃分
GPAM-PSO算法中每次迭代僅生成一個優勢個體, PSO算法的特點為保證所有粒子都會向優勢個體聚集. 但GA中如果每次進化僅產生一個優勢個體, 由于GA選擇操作的隨機性, 該個體不一定發揮作用, 為更大程度地利用優勢個體, 在GA中提出的聚集算子每次迭代將產生多個優勢個體. 方法是對GA臨時種群進行聚類, 每個聚簇產生一個優勢個體. 本文采用AP(affinity propagation)聚類對GA種群進行劃分, 基于數據點間的“信息傳遞”進行聚簇, 每次迭代計算并傳播每個數據點的吸引度和歸屬度[20], 計算公式為

(1)
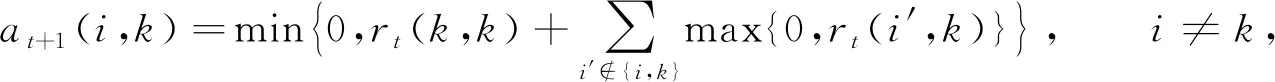
(2)

(3)
吸引度r(i,j)由數據點i傳向候選聚類中心j, 表示點j作為點i聚類中心的累積證據; 歸屬度a(i,j)由候選聚類中心j傳向數據點i, 表示以點j作為聚類中心的聚類包含點i的累積證據;s表示兩個數據點的相似性, 一般采用負的歐氏距離. 對上述步驟進行迭代, 若歸屬度和吸引度保持不變或者在一個小范圍內振蕩, 或者算法執行超過設定的迭代次數則算法結束. 為避免振蕩, AP聚類更新信息時引入了衰減系數λ, 則吸引度和歸屬度公式更新為
rt+1(i,k)←(1-λ)rt+1(i,k)+λrt(i,k),
(4)
at+1(i,k)←(1-λ)at+1(i,k)+λat(i,k).
(5)
相比于傳統聚類算法, AP聚類可根據數據分布自動確定聚類數目, 聚類中心是真實存在的點, 結果穩定且誤差小. 這些特征十分適合對沒有先驗信息的GA種群進行聚類, 可根據當前種群結構自適應地聚類從而達到有效劃分的目的. 在GA迭代過程中, 為保持聚簇內元素數量, 當元素數小于6時, 合并除主要聚簇外的聚簇. 這種處理方法的優點是: 在大型聚簇中進行了開發操作, 在多個小型聚簇上進行探索操作, 提高收斂速度的同時避免了早熟.
1.2 基于PCA的GA種群降維
主成分分析(principal component analysis, PCA)是經典的無監督降維算法, 通過正交變換將數據特征轉換為一組線性不相關的新特征, 選擇新特征在更小維度下展示數據的特征. 方法是對數據進行中心化后的協方差矩陣進行奇異值(SVD)分解, 原始數據通過SVD分解的旋轉矩陣得到新特征, 然后根據特征值大小選擇主成分進行降維, 利用旋轉矩陣的轉置可從新特征返回到原始數據. PCA是最簡單有效的降維方法之一, 且實現簡單、 算法復雜度低, 用在聚集算子中不會給算法帶來額外的開銷. 本文提出的聚集算子采用PCA可快速對種群進行降維, 在低維空間中可采用簡單的回歸算法擬合種群結構, 利用擬合曲面快速發現優勢個體, 并利用PCA將優勢染色體返回到原始空間.
1.3 基于WLS的GA種群結構擬合及優勢個體發現
最小二乘法(ordinary least squares, OLS)是一種解決數學優化問題的有效方法, 其計算方式是利用最小誤差平方和找到最符合所有數據的曲線或曲面. 為能在本文提出的聚集算子中快速發現優勢個體, 本文利用OLS在低維空間擬合一個二次曲面, 從而利用二次函數的求解公式得到曲面極值位置的數學解析解. 為提高OLS泛化能力, 本文采用加權最小二乘法(weighted OLS, WLS), WLS給每個觀測值分配一個反映測量不確定度的權重wi, 其最小二乘準則為

(6)
其中ε表示誤差, 即要最小化的量, {Xi,Yi}為觀測量,a和b分別為回歸線的截距和斜率.
算法1融合聚集算子的遺傳算法(genetic algorithm with aggregation operator, aGA).
步驟1) 初始化: 指定AP聚類P值, 設置PCA特征選擇數目n或特征累計占比閾值θ, 進化代數計數器t=0, 設置最大進化代數T及適應度評價函數f, 函數隨機生成M個染色體作為初始種群P(0);
步驟2) 個體評價: 利用適應度函數f計算種群P(t)中每個染色體的適應度;
步驟3) 傳統算子作用在種群上;
① 選擇運算: 將選擇算子作用于種群;
② 交叉運算: 將交叉算子作用于種群;
③ 變異運算: 將變異算子作用于種群;
步驟4) 種群P(t)經過選擇、 交叉、 變異運算后得到臨時種群P(t0);
步驟5) 聚集算子作用在臨時種群P(t0), 合并較小聚簇;
① AP聚類算法將種群P(t0)劃分成N簇;
② PCA算法對每簇進行降維, 保存n個最大成分, 或者累加占比超過θ的n個主成分;
③ WLS算法將每簇擬合成二次曲面并求得極值, 發現優勢染色體;
④ 將N個優勢染色體利用PCA旋轉矩陣返回原始空間加入臨時種群P(t0);
步驟6) 選擇算子從臨時種群P(t0)選擇個體產生新種群P(t+1);
步驟7) 終止條件判斷: 若t=T, 則以進化過程中所得到的具有最大適應度個體作為最優解輸出, 終止計算.
2 數值實驗
2.1 實驗設計
為驗證算法聚集算子的效率, 本文選取10個Benchmark函數和經典GA對比, 包括3個單峰函數和7個多峰函數, 測試函數信息列于表1. 算法實驗的種群大小為100, 最大迭代次數為50次, 優化參數采用30維. 為對比方便, 將適應度規約為0~100.
2.2 實驗結果分析
針對表1中的每個測試函數, aGA和GA分別運行10次, 每種算法的平均迭代曲線如圖3所示, 平均最優適應度和收斂位置列于表2.

表1 測試函數

表2 測試函數結果

圖3 測試函數迭代曲線
由圖3和表2可見: 在單峰函數實驗中, aGA都快速達到近似最優解, GA緩慢達到最優解; 在多峰函數中, 3個函數Weierstrass,Ackley,Rastrigin在aGA中不僅快速收斂, 而且最優值優于GA, 其他函數雖然最終收斂值未超過GA, 但優化精度接近, 除Schwfel函數外收斂速度明顯提升. 盡管由于引入聚集算子使每次迭代比較耗時, 但聚集算子可使GA迭代幾次后快速收斂. 實驗結果表明, 當適應度計算十分耗時時, 如當適應度計算超過10 ms時或將算法終止條件設為連續5代適應度不發生改變時, aGA的優勢明顯.
綜上所述, 本文在遺傳算法中引入了聚集算子, 該算子利用AP聚類對群體進行劃分后, 通過PCA對每一聚簇進行降維, 在低維空間利用加權最小二乘法將聚簇分布擬合成二次曲面, 并將求得的極值作為優勢染色體返回到原始群體, 從而引導遺傳算法快速收斂. 10個標準測試函數的測試結果證明了該算法的有效性.
猜你喜歡
我愛學·笑話與口才(2025年3期)2025-02-24 00:00:00
華人時刊(2020年13期)2020-09-25 08:21:30
趣味(語文)(2020年3期)2020-07-27 01:42:46
意林·全彩Color(2019年8期)2019-09-23 02:12:36
作文與考試·初中版(2017年12期)2017-04-19 20:26:27
中國衛生(2015年2期)2015-11-12 13:13:54
中國火炬(2014年11期)2014-07-25 10:31:58
中國體育(2004年3期)2004-11-11 08:53:02
棋藝(2001年19期)2001-11-25 19:55:34
棋藝(2001年23期)2001-01-06 19:08:36
