電網多源大數據融合方法的研究與應用*
2021-05-21 01:20:18覃松濤黃超田君楊楊彥韋
電子器件 2021年2期
覃松濤黃 超田君楊楊 彥韋 恒
(廣西電網電力調度控制中心,廣西南寧 530023)
隨著智能電網的發展和普及應用,電力系統已經進入了大數據時代,由于大電網中含有大量的不相關以及冗余信息,嚴重降低了關鍵信息的主導作用,容易導致系統決策出現偏差[1-3]。目前已有的硬件設施和控制技術無法實現對電網大數據的有效分析和精準控制,因此,需要對電網大量冗余數據進行融合及刪減[4-6]。
國外內研究學者在電網大數據處理方面展開了大量的研究工作。王德文等[7]提出了一種基于Storm 的狀態監測數據流滑動窗口處理方法,通過采集系統節點監聽數據源變化并實時收集數據,利用消息訂閱模式對數據進行緩沖,既保證了數據的連續計算,又能夠滿足大電網異常狀態檢測與用電數據分析等快速處理需要;曲朝陽等[8]提出了一種基于云計算技術的電力大數據預處理屬性約簡方法,通過剖析粗糙集中相對正域理論的特性,利用MapReduce 模型構建了MP_POSRS 屬性約簡算法,計算出正域中元素個數,實現對電力大數據預處理屬性的約簡化處理;孫超等[9]基于混合數據采集模型和采集集群,提出了一種實現異構數據源采集任務的混合調度和管理方法,通過數據置信度標簽技術,實現了對原始數據的保留并對數據質量進行標識,能夠為后續大數據分析應用提供了便利;葉康等[10]通過引入數據標簽技術對數據物理表進行梳理,將業務專家的經驗與數據物理表結構融合,實現對數據信息進行高度精煉,方便機器或人對數據的識別。該方法具有指標口徑一致、節省計算資源、便于全局優化的特點,能夠大幅提高電網監控業務智能化水平;黃彥浩等[11]、彭小圣等[12]分析了大數據、云計算、電力系統三者間關系,給出具有通用性的電力大數據平臺總體架構,并從電力大數據的集成管理技術、數據分析技術、數據處理技術、數據展現技術等方面深入探討符合電力企業發展需求的大數據關鍵技術的選擇。
現有研究充分利用了大數據有效信息,對降低電網大數據的冗余性具有一定參考意義,但所用理論及算法復雜,操作難度較大。為此,對電網大數據的基本特性及現有研究策略進行深入研究,探究來自不同數據源同一對象數據的關聯性,充分利用現有大數據資源,提出了一種基于映射的電網大數據融合方法,以實現降低電網大數據冗余度的研究目的。
1 電網大數據的基本特性
大數據是一個龐大而復雜的數據集,具有不同的數據結構,如:非結構化、半結構化和結構化等等,不能在給定的時間內用傳統方法進行處理、存儲、管理和分析[13]。如圖1 所示,電網大數據具有4 項基本特性,分別是:規模性(Volume)、多樣性(Variety)、高速性(Velocity)以及有價值性(Value),又稱為4 V 特性[14]。
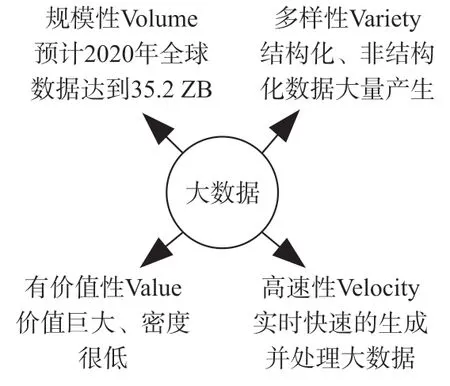
圖1 大數據的四項基本特性
(1)規模性:隨著電力系統規模的不斷擴大,在發電、變電、輸電、配電和用電等各個環節產生大量信息數據,將使得電網存儲數據容量的級別逐步從PB 向EP 飛躍。
(2)多樣性:隨著電力系統信息化建設的飛速發展,相比于傳統電力系統的單一化信息數據,電網大數據結構及其表現形式開始變得多樣化,如:視頻、文本、圖像等。
(3)高速性:由于電力系統大數據流存在實時性、易失性、無序性等基本特性,且數據之間的關聯性錯綜復雜。因此,需要對電力系統生產、運行期間所產生的數據做出高效處理,以滿足電網對電力調度、負荷預測以及故障診斷等問題的快速性要求。
(4)價值大密度低:在海量的監測或檢測的數據中隱含著大量的信息。對其進行挖掘分析可以提供給生產、運行、管理、用戶等有價值的信息。這些數據不僅僅反映電力行業內部的信息,而且關系到整個經濟社會的情況,對國家的經濟宏觀調控、資源的合理利用、減少污染。大數據中隱藏著巨大經濟以及社會價值。
2 電網大數據的融合
2.1 數據融合的層次
電網大數據融合的過程是對數據進行多級處理的過程,包括對數據進行采樣、提取、篩選以及合并等等,都是對原始信息的抽象化處理。根據數據處理過程中的抽象化程度,將數據融合又分為:像素級融合、特征級融合以及決策級融合,如圖2 所示。
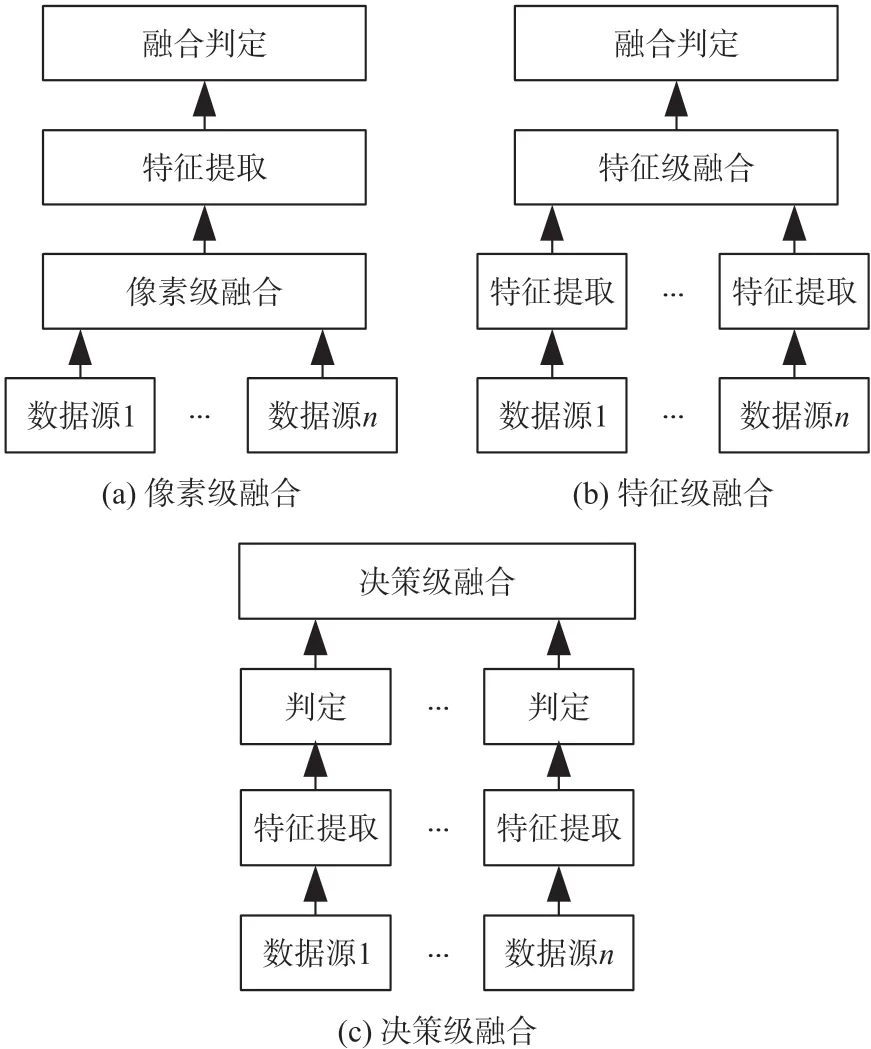
圖2 數據融合的不同層次
3 種數據融合層次的優缺點如表1 所示,可以看出:像素級融合,其輸入數據為所有的原始數據,信息覆蓋面廣,但信息處理的計算耗時巨大,通信量大且抗干擾能力差,所以應當對原始數據做預處理。特征級融合,由于其輸入數據是經過處理得到的特征向量,僅保留了有需要的重要數據,不可避免地會存在數據流失的情況,造成準確精度下降。決策級融合,在特征級融合的基礎上,決策級融合綜合了各個數據源的決策信息,具有容錯率高、抗擾性強、適應性高以及通信量小的優點,但數據前期處理的花費高且信息損失量大。由此來看,特征級融合是像素級融合和決策級融合的綜合。
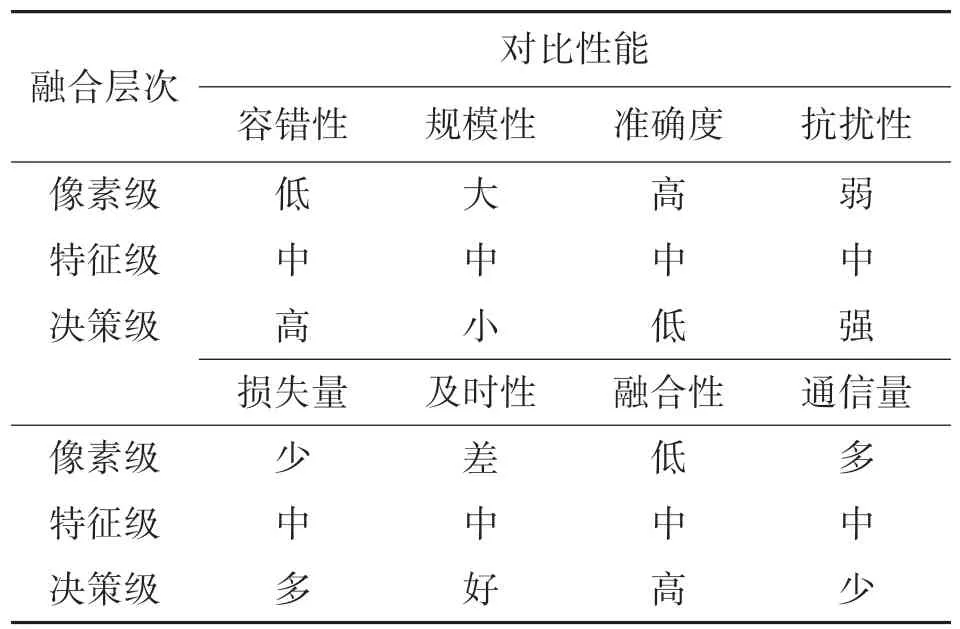
表1 不同融合層次的性能對比
2.2 數據融合的總體框架
大電網中存在許多存儲電氣設備相關信息的數據源系統,如:廣域相量測量系統(Wide Area Measurement System,WAMS)、數據采集與監視控制系統(Supervisory Control And Data Acquisition,SCADA)
以及保護故障信息管理系統(Management System of Relay Protection,RPMS)等,這些電力系統的生產調度、診斷監測系統中的數據具有相互獨立且結構各異,數據大量分散、冗余的特點,使得有效信息不能充分挖掘。因此,需要引入信息融合的方法,對電網大數據進行分析、挖掘、提取、融合等一系列操作,從不同層面對大電網數據進行高效化處理,降低電網數據冗余度、提高信息決策的精準性,為電網的信息預測、故障診斷等提供有效輔助決策。
電網大數據融合的總體框架如圖3 所示,以SCADA、RPMS、WAMS 等數據源系統提供的基礎設備信息作為數據層融合的原始數據輸入,經處理后輸出特征層需要的輸入特征數據,再以特征層融合后的特征數據作為輸入,經過處理后輸出得到決策,實現以少量的數據信息反映大部分特征的融合目標。
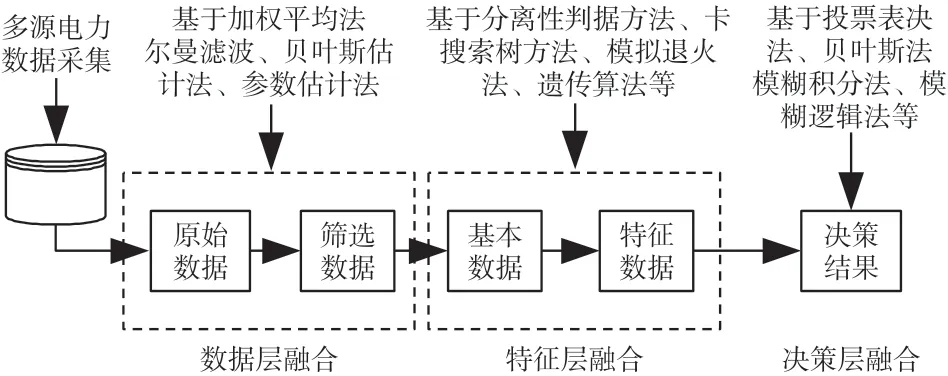
圖3 電網大數據融合的總體框架
3 基于映射的多源數據融合方法
如圖4 所示,將數據融合當做是原始數據向成熟數據轉變的一個映射過程。定義映射F:X→Y,X為原始數據集,Y 融合后的數據集,映射F 為數據融合過程,其具體步驟如下:
步驟1 對不同數據源的信息進行規范化處理;
步驟2 提取各個數據源的特征向量;
步驟3 對各個數據源的特征向量進行檢驗后進行數據融合,求取綜合特征向量。
步驟4 根據求解得到的綜合特征向量,再經過還原得到融合后的數據。
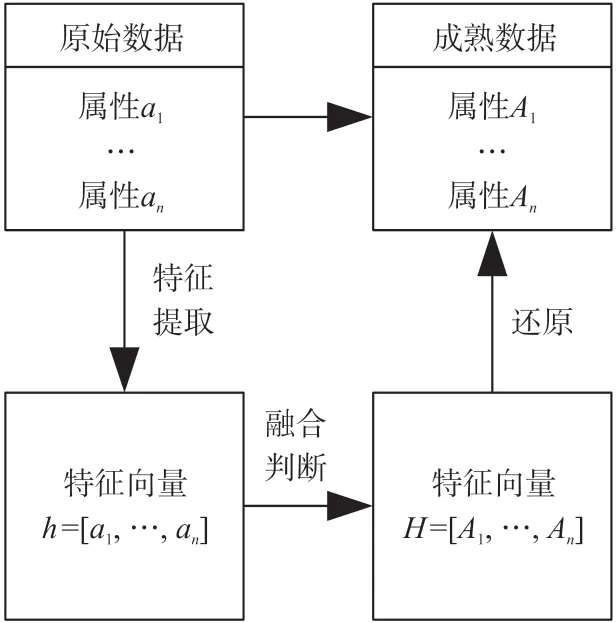
圖4 基于映射的數據融合方法
本研究主要對具有不同數據源信息的同一對象數據融合方法進行。不同數據源其所存儲的設備數據內容各不相同,需要對不同數據源信息進行融合,以實現多源數據的交互與轉化,并降低數據的冗余度[15]。通過文章2.2 小節的介紹可知,宜采取特征級融合策略對來自不同數據源的同一對象數據進行融合。
如圖5 所示,對來自不同數據源的數據進行特征向量的提取,特征提取是一個信息采集與壓縮的過程,每一個數據源都要與之對應的唯一的特征向量Hi(i=1,…,n),且這唯一的特征向量能夠充分反映該數據源的重要信息。對這些特征向量進行標準化運算、數據校核修正、融合判斷等一系列處理后,求得該研究對象的的標準特征向量H,即能反應該電氣設備數據融合后的基本屬性。需要說明的是,在特征向量的提取和融合過程中,應遵循以下原則:

圖5 特征向量的提取
首先進行數據的校驗,若各個特征向量同一基本屬性均有內容且不完全相同時,需對該特征向量進行數據校驗,若發現數據錯誤,則進行校正;若數據無誤,則進行以下操作步驟:
(1)若各個特征向量具有相重疊的基本屬性,則僅保留一份該特征向量對應的數據信息即可;
(2)若各個特征向量同一基本屬性不完全相同時,則按照完善程度、優先級別等特性來進行選擇,如:更新后的數據信息優先級別高于更新前的數據信息;
(3)若某一特征向量具備其他特征向量沒有的基本屬性,則保留該特征向量具備的這一基本屬性。
4 算例驗證
本小節以某220 kV 變電站為例,選取來自生產管理系統(Production Management System,PMS)以及調度自動化系統OMS 2 種不同數據源的變電站數據的數據融合具體過程,以檢驗本文所提數據融合方法的實用性,各數據源提供的基礎數據如表2以及表3 所示。
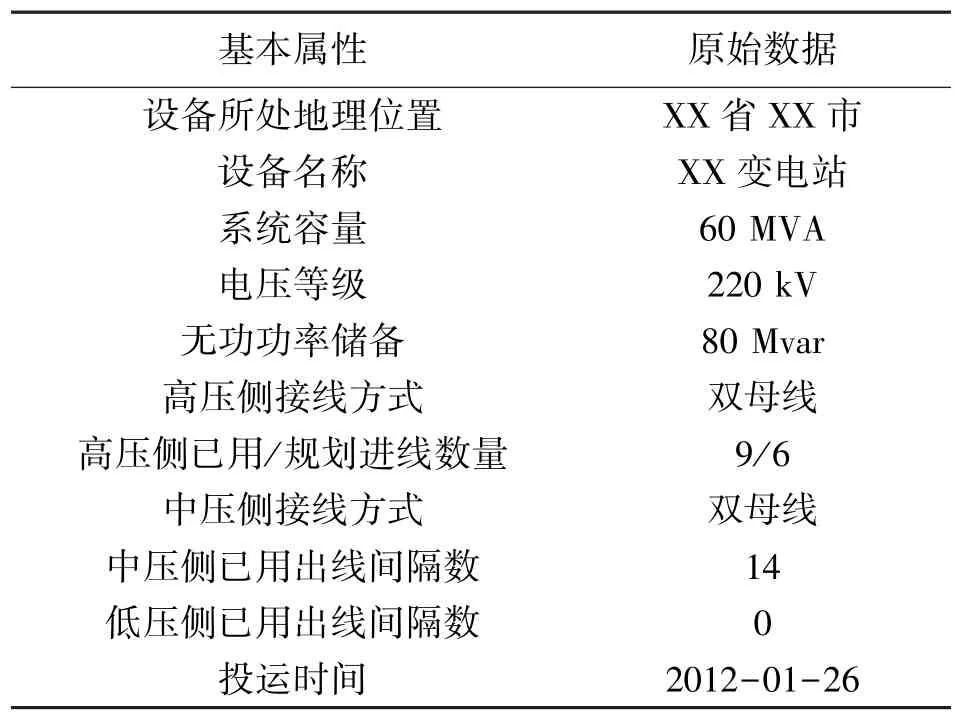
表2 PMS 中變電站的基本信息
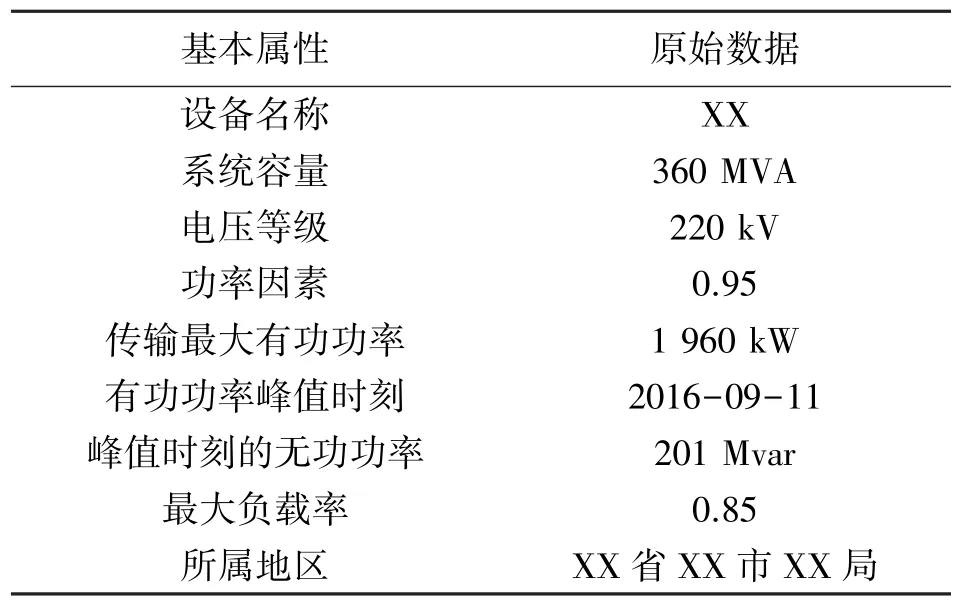
表3 OMS 中變電站的基本信息
從表2、表3 所提供的原始數據來看,對于同一變電站,不同數據源所提供的數據信息既有互相重復的部分,又有相互補充的部分。即使是同一個基本屬性,2 種不同數據源的表述方式都各不相同,因此需要對表中的原始數據進行規范化處理,使得變電站基本屬性的描述規范,單位統一,數據精度一致,即對數據進行清洗。生產管理系統以及調度自動化系統經規范化處理后得到的數據如表4、表5 所示。
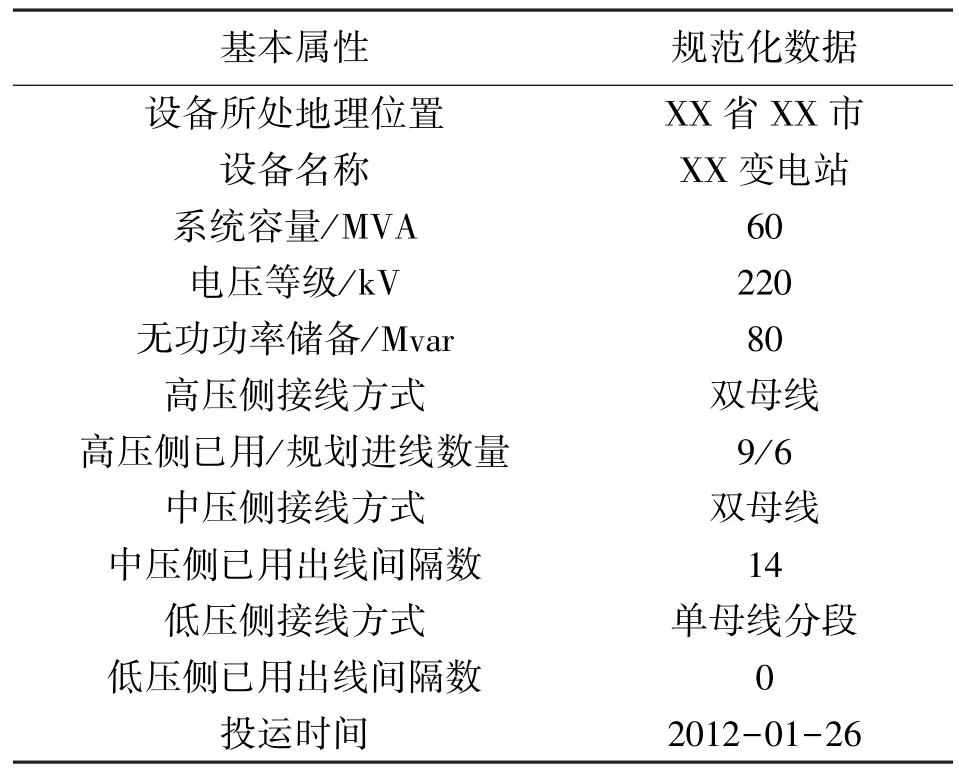
表4 規范化數據處理后的PMS 數據
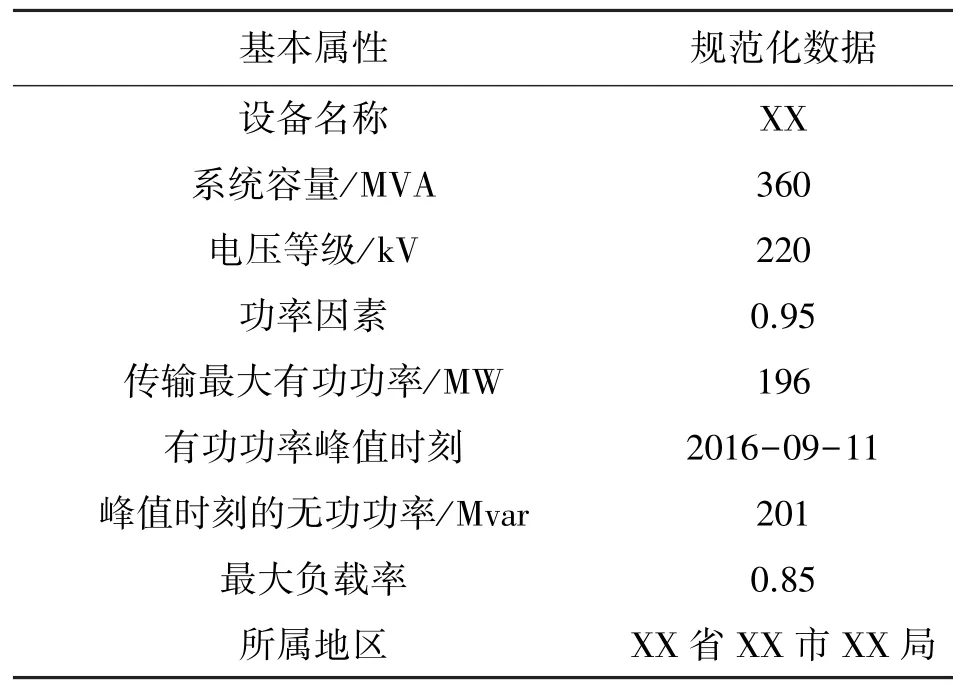
表5 規范化預處理后的OMS 數據
在對數據進行規范化處理后,根據電網業務需要對變電站基本屬性提取基本特征向量。基本特征向量的維度可以是一維或是多維,其所包含的數據類型較廣,有:字符串、數字等等,當變電站缺失某一基本屬性時,其所對應基本特征向量的那一項為0。對該變電站提取基本特征向量列于表6 中,由于該變電站的數據信息較為簡單,因此用一維向量即可清晰展示其基本屬性。
從表6 中可以看出,特征向量A1是表4 中的“設備所處地理位置”和表5 中的“所屬地區”這同一屬性規范化后的融合描述結果;還新增了特征向量A18這終期基本屬性,使得變電站運行數據庫信息更加全面完善,其余特征向量均是表4 和表5 已有基本屬性的規范化融合結果。

表6 變電站的基本特征向量
基于表6 所給出的基本特征向量模式,求取PMS 數據的特征向量H1以及OMS 數據的特征向量H2,各特征向量的具體數值為:
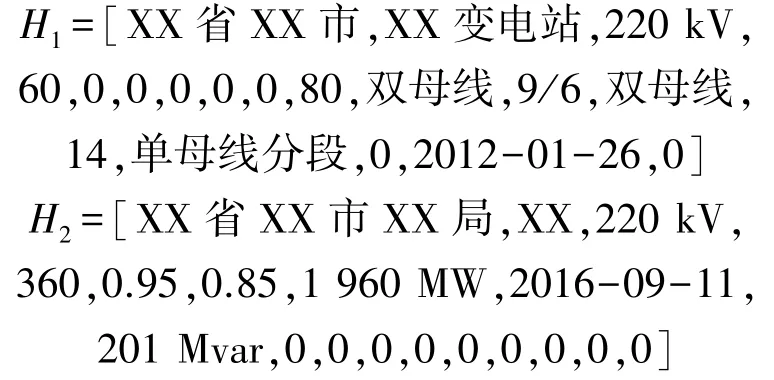
首先,對H1和H22 個特征向量各基本屬性進行校驗,可以看到對于所屬地區和系統容量這2 個基本屬性,2 個特征向量均有數據但存儲內容不完全相同,經檢驗后確認H1、H2特征向量的所屬地區屬性的相關數據無誤,僅完善程度不同;而對于系統容量這一基本屬性,由工作人員進行核實后證實H1特征向量的該基本屬性存在錯誤,予以更正為360。對于得到校驗更正后的特征向量H1、H2為:
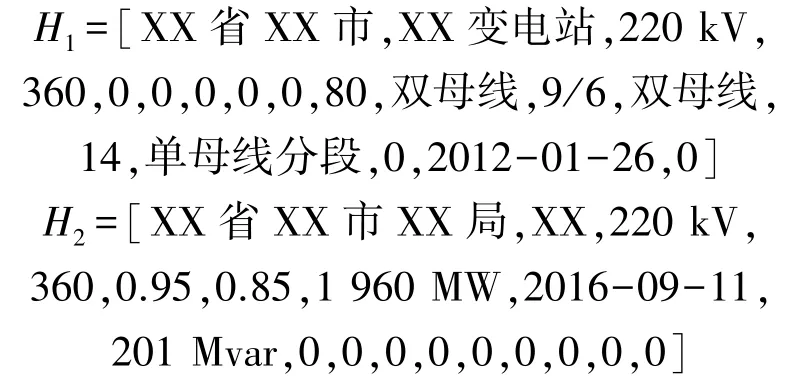
接著,按照本文所提數據融合規則,對特征向量H1、H2求取綜合特征向量H為:

最后,以表6 為基準對綜合特征向量H做數據還原,還原結果如表7 所示。
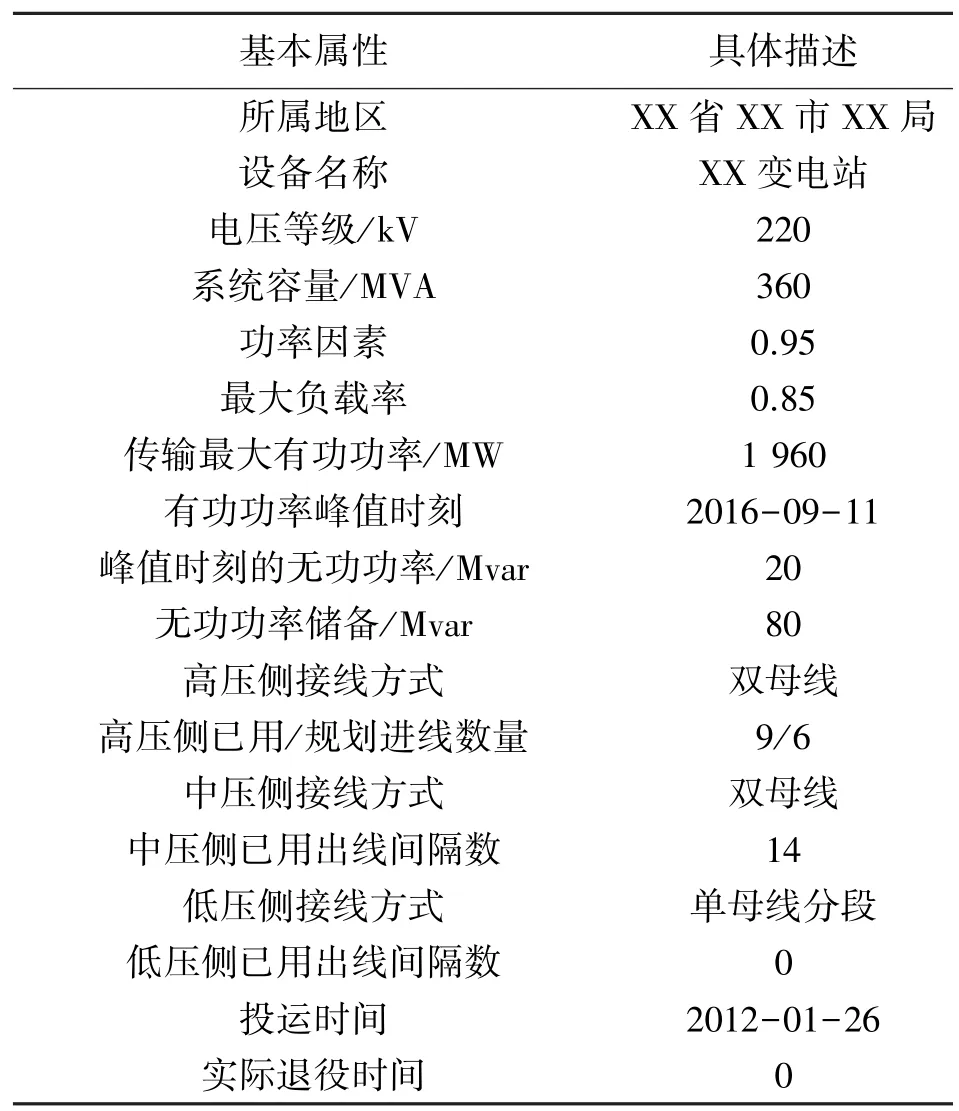
表7 數據融合后的變電站數據
將表7 融合后的數據與表2、表3 的原始數據對比可知,變電站經過數據融合后的信息更加綜合、系統、規范,融合后的基本屬性含概了所有數據源的基本屬性,剔除了各個數據源基本屬性中重復冗余的部分,且每個基本屬性描述更加規范統一完善。
5 結論
提出了一種基于映射的數據融合方法,通過對來自不同數據源的基本數據屬性進行規范化處理、提取特征向量、求取綜合特征向量、特征向量還原等操作。從數據融合的結果來看,該方法不僅能夠全面反饋各個數據源的重要屬性,而且能夠降低多源數據的冗余度,融合后的數據信息更加規范、系統、全面,證明了所提數據融合方法對電網數據處理的實用性。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
電子制作(2018年8期)2018-06-26 06:43:34
中華手工(2017年2期)2017-06-06 23:00:31
電子制作(2017年8期)2017-06-05 09:36:15
現代工業經濟和信息化(2016年5期)2016-05-17 05:35:57
河南電力(2015年5期)2015-06-08 06:01:45
中外會展(2014年4期)2014-11-27 07:46:46
