一種基于自注意力機制的欠定盲信號提取算法*
2021-05-20 12:07:04陳美均武欣嶸
通信技術 2021年5期
陳美均,武欣嶸,鄭 翔,皮 磊
(陸軍工程大學,江蘇 南京 210007)
0 引言
盲信號提取(Blind Source Extraction,BSE)源于經典的雞尾酒會問題[1],研究如何從未知先驗信息的混合信號中分離出特定目標源信號的問題,是當前信號處理領域的研究熱點。根據觀測信號數量N與待分離源信號數量M之間的關系,可以將盲源提取模型分為超定(M<N)混合模型、正定(M=N)混合模型和欠定(M>N)混合模型。其中,欠定混合模型與實際情況最貼合,更具有實際應用意義。但是,早期盲信號處理的典型方法如獨立分量分析(Independent Component Analysis,ICA)都不適用于欠定混合模型。
Ozerov 等人提出多通道非負矩陣分解算法(Multichannel Non-negative Matrix Factorization,MNMF)[2],用于處理欠定混合模型的BSE 問題。該算法利用了多通道信號空間信息輔助進行BSE,在低混響簡單場景的欠定BSE 問題可以取得較為理想的結果,但當混響較高時無法以NMF 模型對源信號建模,致使算法結果不理想。
Nugraha 等人指出,可以利用深度網絡替代NMF 模型對源信號進行建模[3]。Kameoka 等人提出了多通道變分自動編碼器(Multichannel Variational Autoencoder,MVAE)[4]的BSE 算法。該方法預訓練條件變分自碼器(Conditional VAE,CVAE)[5]表示每個信號源的生成模型,將深度網絡表示能力用于源信號時頻圖建模,使基于深度網絡的數據驅動信號模型和具有可解釋性的迭代投影更新分離矩陣的盲源分離算法相結合。然而,MVAE 算法采用獨立低秩矩陣分析算法對部分參數進行更新,使其只適用于正定混合模型的BSE 問題。
為解決欠定混合模型的BSE 問題,本文將以MVAE 為基礎的改進算法擴展MVAE 算法[6](Generalized MVAE,GMVAE)和基于X-vector 的說話人識別模塊[7]結合,構建了一個兩步欠定盲信號提取算法,并引入了注意力機制,提升了識別準確率。利用GMVAE 算法分離盲信號后,將輸出的估計信號利用X-vector 系統進行目標語音提取。本文利用500 人清晰語音數據集訓練CVAE,以提高GMVAE 說話人無關的信號分離能力,并在X-vector系統引入自注意力計算機制,以增強特征提取時對關鍵幀的信息處理,并進一步利用語音信號的自相關特性。
1 相關工作
1.1 問題描述
本文信號提取在短時傅立葉變換(Short-Time Fourier Transform,STFT)域中進行。在時頻域中,卷積混合通常被近似地估計為每個頻帶線性瞬時混合模型。假設使用n個麥克風陣列捕獲m個信號源的信號混合模型,如圖1 所示。
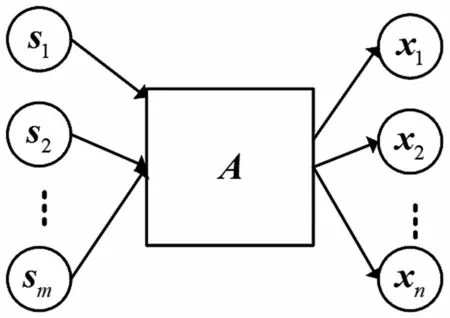
圖1 信號混合模型
信號經過短時傅立葉變換到時頻域并忽略噪聲后,將接收信號與源信號關系以線性瞬時混合模型表示為:
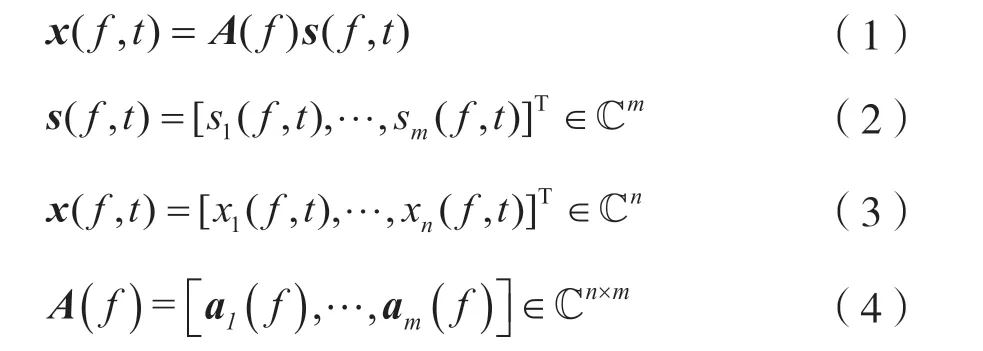
式中:f、t分別為頻率與時間索引;sm(f,t)和xn(f,t)分別由第m個源信號和第n個觀測信號經過STFT 得到;A(f)為n×m維混合矩陣。本文研究n<m的欠定混合情況。
在GMVAE 算法中,假設源信號符合局部高斯模型(Local Gaussian Model,LGM),即sm(f,t) 獨立服從方差為vm(f,t)=E[|sm(f,t)|2]的零均值復高斯分布:

當m≠m′時,sm(f,t) 與sm′(f,t) 相互獨立,s(f,t)分布為:
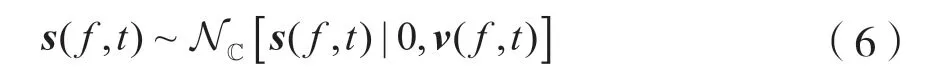
式中,v(f,t) 為對角矩陣,其對角元素為v1(f,t),…,vm(f,t)。根據式(1)和式(6),可以得到x(f,t)分布為:

式中,(·)H表示共軛轉置。給定觀測信號x(f,t)時,混合矩陣A(f)與源信號模型參數v(f,t)的對數似然函數為:
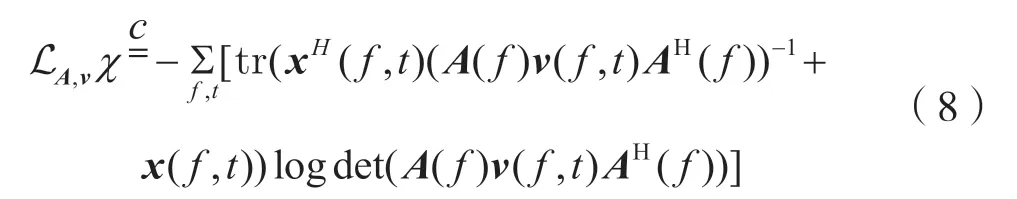
若不對vm(f,t)施加約束條件,則式(8)將轉化為多個按頻率劃分的源分離問題。由于m的排列不會影響對數似然的值,此時混合信號的分離將存在排列歧義問題,因此需要在得到A之后進行排列對齊,以解決排列歧義問題。
1.2 多通道非負矩陣分解算法(MNMF)
在MNMF 算法中,將式(7)中A(f)v(f,t)AH(f)改寫為:

式中,Rm(f)表示第m個源信號的空間協方差矩陣。MNMF 算法利用獨立向量分析的思想,通過將vm(f,t)建模為如式(10)所示Km個時變激活函數um,k(t)與頻譜模板hm,k(f)乘積的線性和,從而對vm(f,t)施加約束來解決估計信號的排列歧義問題。

假設每個源的所有頻譜模板都是共享的,以數據驅動的方式確定第k個頻譜模板對第m個源信號的貢獻,式(10)也可改寫為:
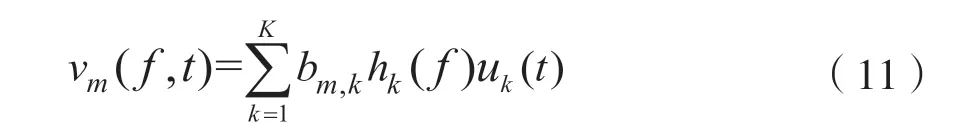
式中,bm,k表示第k個頻譜模板的貢獻指標,滿足條件bm,k∈[0,1]且∑kbm,k=1。
MNMF 算法中包含迭代更新空間協防差矩陣R={Rm(f)}m,f、源模型參數H={hm,k(f)}m,k,f與U={um,k(t)}m,k,t估計。
1.3 條件變分自編碼器(CVAE)
由于MNMF 算法處理信號只能處理能以NMF模型表示的信號,當信號頻譜模型不符合式(10)時,MNMF 算法不能完成信號處理任務。在GMVAE 中,使用預先訓練好的條件變分自動編碼器(CVAE)替代式(10)。令表示源信號的時頻圖模型,GMVAE 利用帶有輔助輸入條件c的CVAE對其進行建模。輔助條件c代表源信號的類標簽,使用one-hot 向量進行表示。
CVAE 包含了一組編解碼網絡,在用于分離前使用有標簽樣本進行訓練。編碼器分布為:

式 中,z表示隱層變量,和分別表示的第k個元素。
解碼器分布為零均值復數高斯分布:


2 盲信號提取算法
圖2 為提出的BSE 算法GA-X-vector 流程示意圖。GA-X-vector 需進行兩部分預訓練,先訓練CVAE 得到解碼器作為GMVAE 部分源模型,后利用通過基于注意力機制的特征提取模塊提取到的X-vector 訓練得到概率線性判別分析(Probabilistic Linear Discriminate Analysis,PLDA)模型,用于信號提取判別。算法將兩通道信號作為輸入,經過GMVAE 部分得到3 個估計信號,并對其進行X-vector 提取操作后輸入PLDA 模型。根據參考信號的注冊信息利用PLDA 模型進行判別,系統將輸出預提取的目標信號。
2.1 擴展多通道變分自動編碼器

圖2 GA-X-vector 算法流程
根據文獻[8],可以證明以下公式:
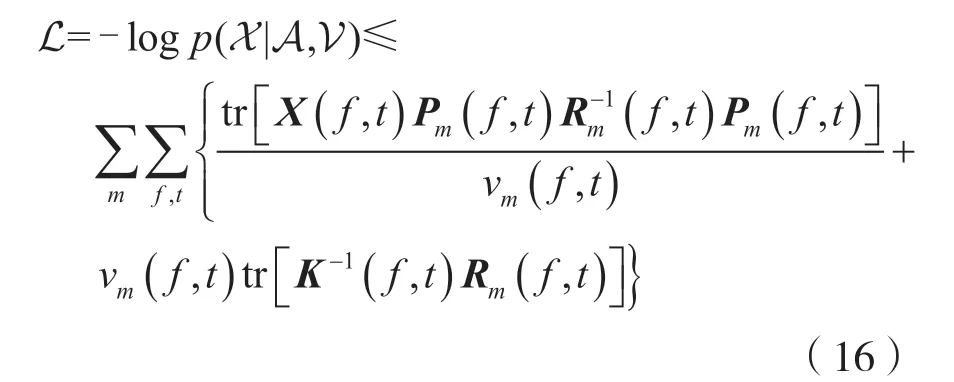
式(16)等號成立的條件為:

將式(16)右邊作為L的推廣,P={Pm(f,t)}m,f,t和K={K(f,t)}f,t是輔助變量。在對參數進行更新時,通過插入softmax 層對cm進行歸一化:

將dm作為待估計的參數,G 更新公式如下:
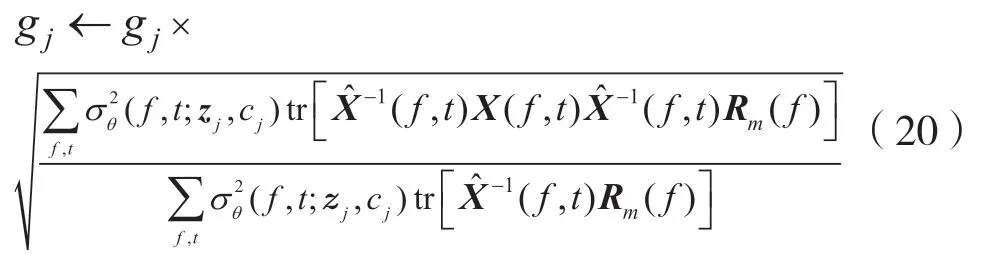
2.2 基于自注意力機制的X-vector 系統
X-vector 系統[9]是一種基于嵌入向量(embedding)由DNN 搭建的說話人識別系統。嵌入向量的本質是由訓練后的深度網絡提取到的說話人聲紋特征。此系統中將嵌入向量用X-vector 表示。X-vector提取網絡結構如圖3 所示。該網絡可以分為兩個模塊。第一個模塊為幀級別特征提取模塊,采用時延神經網絡處理存在時序關系的語音信號幀,輸出幀級別說話人特征。模塊一的輸出經過統計層計算均值與標準差,由幀級別特征過渡為語句級別特征輸入模塊二,即語句級別特征提取模塊的兩層全連接層中,將輸出輸入softmax 輸出層,最終輸出后驗概率,其中輸出神經元的個數和訓練集的說話人個數一致。從全連接層中提取的特征向量即為說話人特征X-vector。

圖3 X-vector 提取網絡結構
在傳統X-vector 系統中,統計層在計算均值與標準差時,認為不同幀的權重相同和語音信號的每一幀重要性相同。Zhu Y 等人指出不同幀能提供的區分信息量是不同的[10],如同人耳對一段聲音的關注也有差異。本文在X-vector 系統的幀級別特征提取模塊與統計層間引入多頭自注意力機制,通過引入多頭自注意力機制來解決統計池化算過程語音幀特征權重相同的問題。自注意力機制是一種特殊的注意力機制,通過對序列本身進行注意力計算,給不同元素分配權重來獲得序列內部的聯系,而多頭的目的是關注信號的多個子空間信息。
圖4 為引入注意力機制后幀級別特征提取后到統計層的流程。
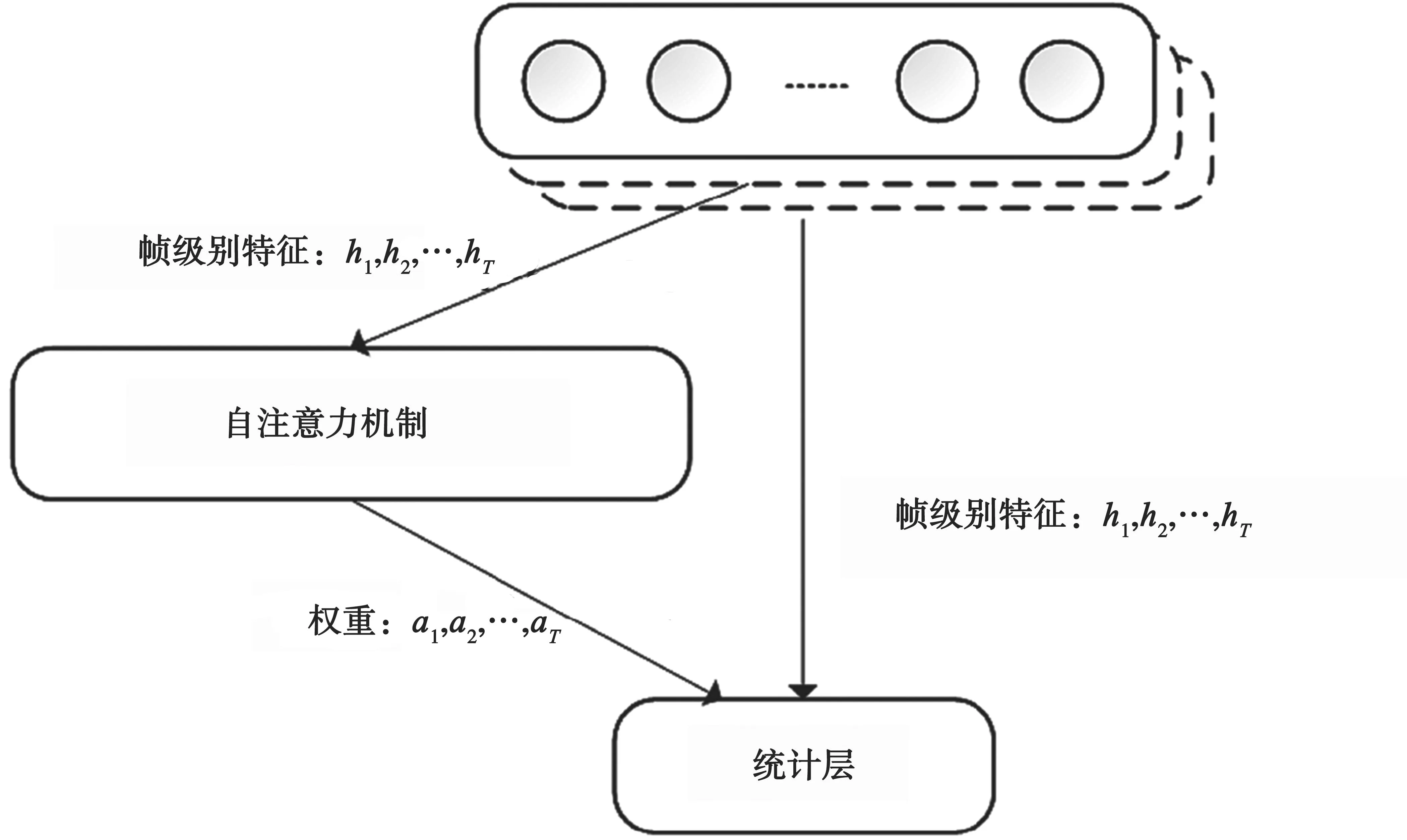
圖4 基于自注意力的統計層
引入自注意力機制[11]后,需要計算不同幀之間的權重。假設統計層輸入T幀H={h1,h2,…,hT},每幀特征維度為dh,H維度為dh×T,注意力機制中利用縮放點積注意力(Scaled Dot-product Attention,SDA)計算權重,計算式如下:

式中,Q、K、V分別為查詢向量、鍵矩陣和值矩陣,dk表示鍵的維度。分母中的對權重進行縮放,防止向量維度太高時計算出的點積過大。在多頭自注意力機制中,有Q=K=V=H。對H做線性變換如下:

3 仿真實驗
3.1 數據集及處理
本文利用VoxCeleb1 數據集[12]進行仿真分析。VoxCeleb1 數據集中數據屬于自然環境下的真實場景,全部音頻來源于YouTube 網站,是真實的文本無關的英文語音數據集。數據集內涉及場景多樣,男女性別比例均衡,年齡、職業、口音等都具有多樣性。該數據集音頻的采樣率為16 kHz,格式為16 bit單聲道的wav文件。語音中帶有真實場景噪聲。
實驗目標為從兩個觀測信號中分離出3 個源信號并提取出目標語音信號。利用RIR-Generator[13]工具準備測試用的混合信號數據,圖5 展示了在混合源信號得到待處理信號時,信源與麥克風的模擬位置。“+”表示麥克風,“○”表示信號源。測試用兩通道混合語音信號采樣頻率為16 kHz,短時傅立葉變換幀長為256 ms,跳長為128 ms。

圖5 麥克風與信號源位置示意
3.2 實驗結果分析
針對本文提出的提取算法實驗分析,目標信號提取質量評價主要使用BSS_Eval 工具[14],評估指標為信號失真比(Signal-to-Distortion Ratio,SDR)、信號干擾比(Signal-to-Interference Ratio,SIR)以及系統誤差比(Sources-to-Artifacts Ratio,SAR),使用等錯誤率(Equal Error Rate,EER)評價目標語音提取存在誤判的情況。
圖6 展示了一組由本文提出算法提取的目標信號與干凈源信號的時頻圖對比。可以看出,算法提取出的目標信號與源信號相似度極高,提取效果良好。
表1 展示了所提算法提取信號質量與基準模型的評估指標對比,對比采用的基準模型為基于使用式(10)作為源模型的MNMF-X-vector 系統結合的盲信號提取算法。GMVAE-X 表示GMAVE 與傳統X-vector 系統結合算法,實驗混響時間T60分別設置為78 ms 和351 ms。從表1 可以看出,與基準模型相比,應用GMVAE 的BSE 算法在各項指標都優于基于MNMF 的BSE 算法,各項指標提高2 dB。尤其在較高混響條件下,GA-X-vector 算法提取質量也高于基準算法在低混響條件下的提取質量。可見,利用VAE 建模提升了信號提取質量,增強了對復雜場景的盲信號處理能力,且表1 中數據也體現了增加注意力機制可以提升目標信號提取的質量。

圖6 源信號與提取出目標信號時頻圖

表1 目標信號提取質量比較
表2 反映了所提的多頭注意力算法中注意力頭數量對信號提取準確率的影響,其中attn-k 中k表示自注意力機制中的注意力頭數量。從表2 可以直觀看出,注意力頭數量增加能夠提升提取準確率。相較于不增加注意機制的算法,當注意力頭數為5時,等錯誤率指標降低了1%。結合檢測錯誤權衡(Detection Error Tradeoff,DET)曲線進一步分析自注意力頭數量對X-vector 系統的目標信號提取準確率的影響,圖7 展示了4 種算法的DET 曲線。DET 曲線刻畫了算法“漏查”和“誤查”兩種錯誤的權衡。曲線越接近左下角,則表示判別算法越好。圖7 中顯示注意力頭數量為5 時,判別算法的曲線最接近左下角,此時判別算法最優。結合圖7 與表2,注意力機制中注意力頭的數量與提取準確率呈正相關。每一個注意力頭都能單獨學習信號的不同依賴性,從模型訓練的角度來看多頭注意力,使模型能夠處理來自不同子空間的信息,并利用幀與幀間的關聯性來增強關鍵幀的信息,以達到提升識別性能的目的。

表2 注意力機制對于目標信號判別準確率的影響

圖7 不同注意力頭數的算法DET 曲線
4 結語
在復雜場景中準確提取特定信號具有重要的現實意義和研究前景。針對欠定混合模型的BSE 問題,本文提出了GA-X-vector 算法。將GMVAE 與引入自注意力機制的X-vector 目標信號判別系統相結合,利用深度網絡的表示能力,使用CVAE 對源信號進行建模,提升了高混響復雜場景的信號提取性能,并利用MNMF 替代低秩矩陣分析對參數進行初始化,使其能夠用于欠定混合模型的信號提取。在X-vector 系統中引入自注意力機制,增強特征提取時對關鍵幀的信息處理,并進一步利用語音信號的自相關特性提高目標信號提取的準確度。仿真結果表明,與基準算法相比,本文提出算法的信號提取質量指標均高2 dB 以上,提取準確率提高了1%。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
文苑(2018年21期)2018-11-09 01:23:06
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
電子制作(2018年11期)2018-08-04 03:25:42
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國衛生(2015年9期)2015-11-10 03:11:12
