基于結(jié)構化分析和語義相似度的食品安全事件領域數(shù)據(jù)挖掘模型
2021-05-19 02:22:04張景祥胡恩華吳林海
食品科學 2021年7期
陳 默,張景祥,胡恩華,吳林海,張 義
(1.南京航空航天大學經(jīng)濟與管理學院,江蘇 南京 211106;2.江南大學理學院,江蘇 無錫 214122;3.江南大學生物工程學院,江蘇 無錫 214122;4.江南大學商學院,食品安全風險治理研究院,江蘇 無錫 214122)
近年來,我國食品安全事件不斷涌現(xiàn),并以互聯(lián)網(wǎng)為主要載體快速傳播。根據(jù)中國互聯(lián)網(wǎng)絡信息中心發(fā)布的報告,截至2020年3月,我國網(wǎng)民規(guī)模達9.04億 人,網(wǎng)民使用手機上網(wǎng)的比例達99.3%,由于食品安全事件信息傳播具有參與人數(shù)眾多、傳播速度快、范圍廣、表現(xiàn)形式多樣等特點,加上傳播者與受傳者的意識形態(tài)、宗教文化、生活經(jīng)歷等存在種種差異,造成信息演化路徑多樣、不確定強、反復性高,都極大地推動了食品安全事件影響的深度和廣度[1]。因此,對互聯(lián)網(wǎng)上相關的食品安全數(shù)據(jù)進行挖掘與梳理,對食品安全的熱點問題進行跟蹤,不僅可以正確引導大眾的輿論方向,也可以避免由于不實食品安全報道引起的社會恐慌。
目前,針對我國食品安全事件的大數(shù)據(jù)分析方法還較少,且互聯(lián)網(wǎng)信息量巨大,關于食品安全的信息難以被有效提取和分析,只有通過對互聯(lián)網(wǎng)數(shù)據(jù)的挖掘,科學分析食品安全事件發(fā)生的內(nèi)外特征,為建立食品安全的預警機制奠定數(shù)據(jù)和理論基礎,才能進一步健全食品安全的保障機制[2]。因此,構建針對食品安全事件的大數(shù)據(jù)挖掘模型,不僅可以實現(xiàn)信息的高效利用,強化政府監(jiān)管、企業(yè)自律和公眾參與的有機結(jié)合,還可以通過分析食品安全事件在空間分布的規(guī)律性特征,對防范未來系統(tǒng)性、區(qū)域性的食品安全風險發(fā)揮重要作用,有利于形成食品安全管控無縫隙、精細化的全社會共治新模式。
1 食品安全概述及食品安全事件挖掘技術
1.1 食品安全風險及危害因素的解析
食品安全風險達到并超過一定的臨界點就可能誘發(fā)食品安全事件。Gratt[3]認為風險是風險事件發(fā)生的概率與事件發(fā)生后果的乘積。聯(lián)合國化學品安全項目中將風險定義為暴露某種特定因子后在特定條件下對組織、系統(tǒng)或人群(或亞人群)產(chǎn)生有害作用的概率[4]。由于風險特性不同,沒有一個完全適合所有風險問題的定義;針對特定問題,應依據(jù)研究對象和性質(zhì)的不同而采用具有針對性的定義。關于食品安全風險,聯(lián)合國糧農(nóng)組織與世界衛(wèi)生組織于1995—1999年先后召開了3 次國際專家咨詢會,提出了食品風險管理的框架和基本原理[5]。國際法典委員會認為,食品安全風險是指將對人體健康或環(huán)境產(chǎn)生不良效果的可能性和嚴重性,這種不良效果是由食品中的一種危害所引起的。國際生命科學學會提出食品安全風險主要是指潛在損壞或危及食品安全和質(zhì)量的因子或因素,這些食品安全風險的危害因素包括生物性、化學性和物理性的[6]。其中,生物性危害因素主要是指影響食品質(zhì)量與安全的有關細菌、病毒、真菌及其毒素、寄生蟲及其蟲卵、昆蟲等;化學性危害因素主要包括動植物固有天然毒素、農(nóng)藥、獸藥、化肥、環(huán)境污染物、食品添加劑、食品包裝浸出物;物理性危害因素主要指玻璃、鐵絲、鐵釘、石頭、金屬碎片、碎屑等各種各樣的外來雜質(zhì)[7-8]。除生物性、化學性和物理性危害因素外,吳林海等[9]進一步提出了人源性/人為性危害因素,即由于食品生產(chǎn)經(jīng)營者故意違反食品安全法律法規(guī)所進行的不當行為以及其他制度性原因而產(chǎn)生的食品安全風險危害因素,主要包括生產(chǎn)經(jīng)營者因素、信息不對稱性因素、消費者因素、政府規(guī)制性因素、國際環(huán)境因素等。需要指出的是,人源性因素也是通過物理性、化學性、生物性因素等體現(xiàn),并產(chǎn)生食品安全風險,但風險原因的本質(zhì)完全不同。總之,由于技術、經(jīng)濟發(fā)展水平差距,不同國家存在的食品安全風險及其危害因素不盡相同。
1.2 食品安全事件概念界定與主要特征
現(xiàn)行的《食品安全法》中沒有“食品安全事件”這個概念,但對“食品安全事故”作出了界定,即“食源性疾病、食品污染等源于食品,對人體健康有危害或者可能有危害的事故”。世界衛(wèi)生組織將食品安全定義為,食品中有毒、有害物質(zhì)對人體健康影響的公共衛(wèi)生問題[10]。李清光等[11]認為基于食品安全的定義,食品中含有的某些有毒、有害物質(zhì)(可以是內(nèi)生的,也可以是外部入侵的,或者兩者兼而有之)超過一定限度而影響到人體健康所產(chǎn)生的公共衛(wèi)生事件就屬于食品安全事件。厲曙光等[12]將食品安全事件與食品或食品接觸材料關聯(lián),認為食品安全事件為所涉及食品或食品接觸材料有毒或有害,或食品不符合應當有的營養(yǎng)要求,對人體健康已經(jīng)或可能造成任何急性、亞急性或者慢性危害的事件。實際上,在可查閱到的國內(nèi)外研究文獻中,鮮見對食品安全事件的界定,而且近年來中國發(fā)生的影響人體健康的食品安全事件往往是由網(wǎng)絡新聞媒體(而且主要由網(wǎng)絡媒體)首先曝光,故在目前國內(nèi)已有的研究文獻中,學者們較多地選取媒體報道的與食品安全相關的事件進行研究[12-13]。
對于業(yè)已發(fā)生的食品安全事件,學者們主要對事件性質(zhì)、產(chǎn)生的影響、危害類型等進行了相關的研究。較為典型的是,He Zhongyue[14]、Dai Yunhao[15]、Liu Huan’an[16]等分別研究了食品安全事件產(chǎn)生的影響,包括對消費者購買意愿和對國際貿(mào)易產(chǎn)生的影響、食品生產(chǎn)經(jīng)營廠商對發(fā)生的食品安全事件的危機處理等。此外,學者們主要采用內(nèi)容分析法進行食品安全事件特征的研究,重點分析食品安全事件中所涉及的供應鏈環(huán)節(jié)、食品類別、危害類型與本質(zhì)原因等,且取得了一定的研究成果。如Li Qiang等[17]研究了2009年4月1日至2009年6月30日時段內(nèi)中國發(fā)生的600 起食品安全事件;Liu Yang等[18]分析了在2004年1月1日至2013年8月1日時段內(nèi)北京發(fā)生的295 起食品安全事件;張紅霞等[19]研究了2010—2012年間中國發(fā)生的由于生產(chǎn)企業(yè)不當行為產(chǎn)生的628 起食品安全事件;莫鳴等[20]分析了2002—2013年間中國發(fā)生的由于經(jīng)營與消費環(huán)節(jié)處理不當引發(fā)的359 個食品安全事件;而劉玉朋等[21]則研究了2001—2013年間中國發(fā)生的278 個類別畜產(chǎn)品食品安全事件。已有的食品安全事件研究多以人工為主,智能化不足,導致數(shù)據(jù)不全面、不精準,對防范食品安全事件意義不足,無法實現(xiàn)對食品安全事件的精準監(jiān)管和預警,甚至可能產(chǎn)生誤導。
1.3 網(wǎng)絡媒體報道的食品安全事件挖掘技術
對食品安全事件研究而言,至關重要的是事件的數(shù)據(jù)來源。傳統(tǒng)食品安全風險治理領域的數(shù)據(jù),例如全國性的食品監(jiān)管抽檢數(shù)據(jù),數(shù)量相對有限,難以起到食品安全風險治理中的預防、預警作用。而在大數(shù)據(jù)時代,獲取食品安全風險治理大數(shù)據(jù)以防范食品安全事件的條件日趨成熟。由于目前國內(nèi)在食品安全事件的分析方面尚沒有成熟的大數(shù)據(jù)挖掘工具,因此近年來有關食品安全事件的研究,其涉及的數(shù)據(jù)主要來源于各個研究團隊根據(jù)研究需要而基于網(wǎng)絡媒體新聞所進行的專門收集[16-18]。數(shù)據(jù)從國內(nèi)各相關網(wǎng)站收集,主要由人工進行重復性的檢驗和有效性的篩選,其中王東波等[22]通過條件隨機場模型對食品安全事件當中食品名稱與誘因的自動識別;沈思等[23]通過BilSTM-CRF模型構建基于深度學習的食品安全事件實體模型;鄭麗敏等[24]提出FSE_ERE這種基于依存分析的食品安全事件新聞文本的實體關系抽取方法。也有學者利用“網(wǎng)絡爬蟲”技術取代人工搜索,抓取網(wǎng)站中與食品安全事件相關的新聞[25]。目前網(wǎng)頁排序的典型算法是Page Rank算法,Page Rank是由Larry Page和Sergey Brin提出來的一種根據(jù)網(wǎng)頁之間相互的鏈接關系計算網(wǎng)頁排名的技術。通過對網(wǎng)頁抓取技術獲取相關數(shù)據(jù),其主要技術方法都是將來源網(wǎng)站的網(wǎng)頁解析成樹,在樹的基礎上,再利用網(wǎng)頁結(jié)構信息或視覺信息從中提取出網(wǎng)頁正文內(nèi)容。如Zhang Cheng等[26]構建了基于DOM樹結(jié)構匹配和視覺一致性的新聞信息構造的算法;王俊峰[27]又改進提出了結(jié)合結(jié)構一致性和視覺一致性的新聞提取算法。基于關鍵詞匹配的網(wǎng)頁抓取技術也有較為廣泛的研究,如Cai Xinbao等[28]提出基于網(wǎng)頁關鍵詞的主題相關性爬蟲技術。Zhao Xu等[29]用語義本體代替?zhèn)鹘y(tǒng)關鍵詞庫,通過本體中詞匯的層次關系計算網(wǎng)頁的主題相關度。陸玉昌等[30]基于網(wǎng)頁詞匯共同分布進行了相關研究。Bollegala等[31]通過統(tǒng)計淺層關鍵詞和語義分析技術,估計詞匯間語義相似度和詞匯共現(xiàn)頻率,但此方法缺陷在于沒有考慮外圍語義成分及語義結(jié)構。隨著研究的深入,學者們在選取文檔特征碼中也逐漸兼顧詞語的語義信息,Chowdhury等[32]提出有選擇性地挑選詞語來生成文檔特征碼的策略;Theobald等[33]提出Spot Sigs算法,按特定規(guī)律提取網(wǎng)頁特征值;Andoni等[34]根據(jù)內(nèi)容相似度提出的局部敏感哈希(locality sensitive Hashing,LSH)算法;黃承慧等[35]提出按倒排序生成文檔特征碼的算法。
上述研究雖然在文本抓取和語義分析上取得了一定的成功,但目前針對食品安全事件的大數(shù)據(jù)研究方法尚不足以達到精準監(jiān)管與預警的作用。長期以來,中國食品安全風險與由此誘發(fā)產(chǎn)生的食品安全事件歷史數(shù)據(jù)非常匱乏,而網(wǎng)絡媒體所報道并形成的食品安全事件大數(shù)據(jù)并沒有為人們所綜合利用。因此,對于網(wǎng)絡媒體對中國食品安全事件的研究,迫切需要基于大數(shù)據(jù)技術,從食品安全事件的食品種類、事件在食品供應鏈環(huán)節(jié)上的分布、誘發(fā)事件發(fā)生的風險因子、事件的空間分布等各個方面來研究食品安全事件的演化規(guī)律,科學闡述食品安全事件的基本特征與發(fā)生機理。針對上述問題,本文全面分析了食品安全事件的基本特征,對食品安全事件關鍵詞進行有序語義重構,構建了食品安全事件的多層多級語義模板,通過比較不同食品安全事件與語義模板的相似度,得到食品安全事件多層多級語義結(jié)構排序策略(strategy of multi-layer and multi-level semantic structure of rank,MMSS-Rank)算法。
2 基于結(jié)構的多層多級語義分析
2.1 語義模板
食品安全事件的報道應該包含的信息量很多,包括事件發(fā)生的區(qū)域、食品安全事件的類型以及危害程度等。為了更加準確描述一個食品安全事件的語義模板,做出如下定義:
定義1:設YRi是描述某一個食品安全事件Ri的一個詞語,稱YRi為語義關系詞語。
定義2:YRi是語義關系詞語;YR={YR1,YR2,...,YRn}為所有食品安全事件Ri的語義關系關鍵詞集合。
定義3:滿足食品安全事件條件下兩個關鍵詞YRi、YRj之間存在一動詞DRij,且YRj后 為 名 詞mRij, 則 稱YRi、DRij、YRj、mRij4 個詞組成一個語義結(jié)構體。
定義4:對語義結(jié)構體中的各個關鍵詞YR={YR1,YR2,...,YRn}進行有序重構,次關鍵詞為DRij,mRij可以描述關鍵詞YRi、YRj間的語義關系,則稱<YRi,DRij,YRj,mRij>為滿足食品安全事件Ri的標準語義模板。
示例:2016年5月26日新華社報道:海口破獲一起特大銷售假冒白酒案。由定義4可知,<海口, 報道, 白酒,假冒>對應<YRi,DRij,YRj,mRij>是滿足食品安全事件的語義模板。
2.2 食品安全事件的語義分層
食品安全數(shù)據(jù)經(jīng)過去重、清洗等預處理后,轉(zhuǎn)化為非結(jié)構化的文本數(shù)據(jù),用分詞技術和詞頻統(tǒng)計方法將文本轉(zhuǎn)化為可處理的結(jié)構化形式。針對食品安全事件的語義特征,語義關鍵詞出現(xiàn)在文本的位置不同,所起到的作用就不同,按文本結(jié)構可分為3 層:第一層是標題層,如標題、小標題等,已初步表達文本的主題概念,若食品安全事件的語義結(jié)構完整地出現(xiàn)在標題層,該文本數(shù)據(jù)被識別為食品安全事件作用明顯;第二層是段落層,食品安全事件在不同段落中表達的語義結(jié)構體的內(nèi)容較為完整,其作用與段落數(shù)、段落長度有關;第三層是關鍵詞層,對于食品安全事件而言,包括食品種類、供應鏈環(huán)節(jié)、風險因子、空間分布等語義關系中的關鍵詞,且與關鍵詞的詞頻、關鍵詞出現(xiàn)的位置、詞長等屬性有關。通過對食品安全數(shù)據(jù)的文本進行結(jié)構化分析,對文本數(shù)據(jù)進行抽象處理,進而建立描述食品安全事件的數(shù)學模型,通過對模型計算,實現(xiàn)計算機對大規(guī)模文本的挖掘和識別。
2.3 食品安全事件的多級語義模板
在主流媒體新聞報道中描述詳盡的食品安全事件應該包含空間分布、食品種類、供應鏈環(huán)節(jié)、風險因子等信息,空間分布以省、直轄市、自治區(qū)為父類,下轄地級市為子類。食品安全事件中食品種類分類方法按照食品生產(chǎn)許可管理辦法(征求意見稿)分類,共計32 類,見表1。食品安全事件的風險因子主要是指潛在損壞或危機食品安全和質(zhì)量的因素,這些因素包括生物性、化學性和物理性,以及人的行為不當、制度性等因素,包括生產(chǎn)經(jīng)營者因素、信息不對稱性因素、消費者因素、政府規(guī)制性因素等,食品安全的風險因子詞庫見表2。根據(jù)定義4和文本數(shù)據(jù)中語義結(jié)構信息量,定義食品安全事件的一、二、三、四級語義模板,見表3。通過分詞技術獲得食品安全文本數(shù)據(jù)中的結(jié)構和語義信息,遍歷結(jié)構化的文本數(shù)據(jù),計算文本數(shù)據(jù)信息與食品安全事件語義模板的匹配度,可以有效提高語義分析處理粒度,從而降低語義分析處理的規(guī)模,同時也有助于將無規(guī)則的數(shù)據(jù)信息轉(zhuǎn)化為標準化數(shù)據(jù)。

表1 食品安全事件的信息分類Table 1 Classification of information about food safety incidents

表2 食品安全事件風險因子Table 2 Risk factors for food safety incidents
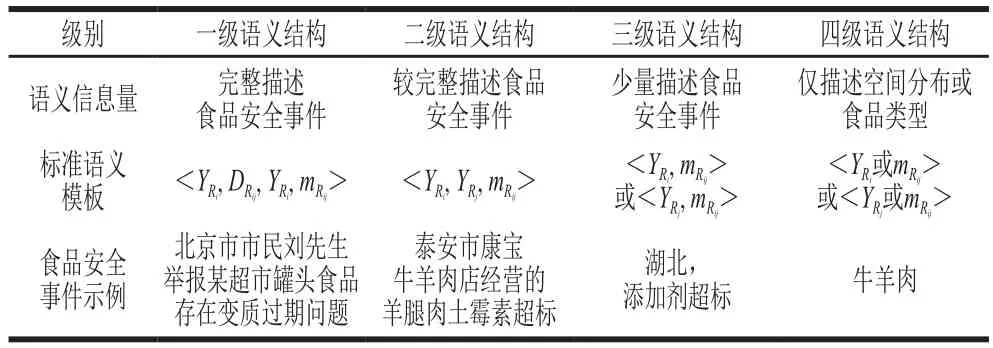
表3 食品安全事件的多級語義模板Table 3 Multi-level semantic template of food safety incidents
3 MMSS-Rank算法
3.1 MMSS-Rank算法流程
選擇合適的網(wǎng)絡媒體作為食品安全事件的來源網(wǎng)站,在確保所抓取數(shù)據(jù)來源真實可靠的基礎上實現(xiàn)去重和清洗;利用分詞技術提取數(shù)據(jù)中關鍵詞的位置、詞頻、總字數(shù)等內(nèi)容信息,并識別標題、首段、尾段等位置信息,根據(jù)數(shù)據(jù)的語義結(jié)構體在文本分層結(jié)構的位置,進一步與多層多級語義模板進行相似度計算,由相似度得分對文本數(shù)據(jù)進行排序,選擇適當閾值判別并輸出食品安全事件的精度,MMSS-Rank算法流程圖如圖1所示。
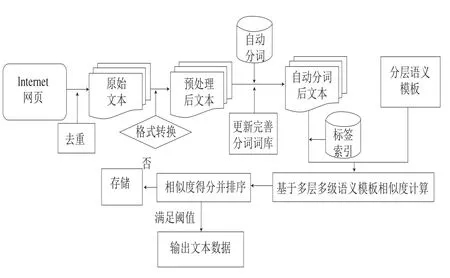
圖1 基于多層多級語義模板相似度的網(wǎng)頁排序框架Fig.1 Web page ranking framework based on multi-layer, multi-level semantic template similarity
3.2 文本數(shù)據(jù)與標準語義模板相似度算法
首先將抓取的文本數(shù)據(jù)集合進行預處理,轉(zhuǎn)化為文本數(shù)據(jù),利用分詞技術確定文本數(shù)據(jù)中關鍵詞的位置,然后計算與多層多級語義模板的相似程度,其相似度計算如式(1)所示。
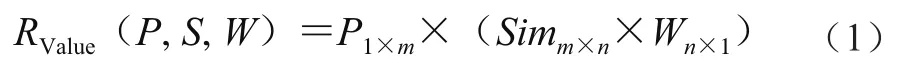
式中:P1×m=(p1,p2,...,pm)表示語義結(jié)構體在文本中不同結(jié)構位置的權重;Wn×1=(w1,w2,...,wn)表示不同級別語義模板的權重;Simij表示食品安全事件語義結(jié)構體與第i個語義模板和第j個文本層次的關鍵詞密度,i=1,...,m,j=1,...,n。
將抓取的文本數(shù)據(jù)按PValue(P,S,W)數(shù)值由大到小排列,并選擇適當?shù)拈撝递敵鑫谋緮?shù)據(jù)。關鍵詞密度計算如式(2)所示。
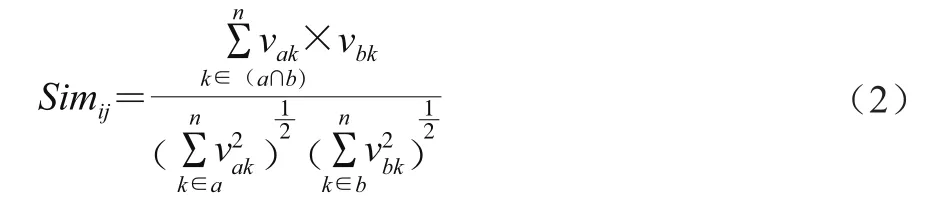
式中:a為描述食品安全事件語義結(jié)構體的關鍵詞集合;b為抓取的文本集合;vak為文本集合a中關鍵詞k對食品安全的重要程度;vbk為文本集合b中關鍵詞k對食品安全的重要程度。vak和vbk均采用式(3)計算,以vak為例。
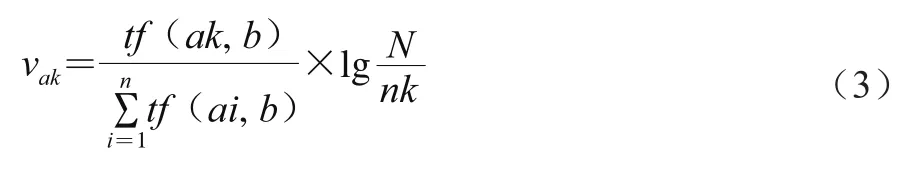
式中:tf(ak,b)為文本集合a關鍵詞k在文本集合b中出現(xiàn)的頻率;為關鍵詞i在文本集合b中出現(xiàn)的總數(shù);N為文本集合中字數(shù);nk為文本集合a關鍵詞k出現(xiàn)的所有文檔數(shù)。
根據(jù)上述描述,設計MMSS-Rank算法,步驟如下:
輸入:數(shù)據(jù)D={title, content},文本層次權重P(簡稱層權重,共3 層權重),語義模板權重W(簡稱級權重,共4 級權重),文本層次級別數(shù)量m,語義模板級別數(shù)量n
輸出:文本數(shù)據(jù)得分Score
1.根據(jù)系統(tǒng)設定的語義模版(地區(qū)行為學術標簽風險標簽)對文章進行分詞和統(tǒng)計處理,得到文章字符數(shù)量、關鍵詞列表和分段信息(區(qū)分是標題還是正文),關鍵詞需要包含所在段落、所在段落中的排序和類型
2.keywordMap=[關鍵詞: 密度值(關鍵詞字數(shù)/全文關鍵詞總字數(shù))]
3.根據(jù)關鍵詞和分段信息,采用最短路徑和系統(tǒng)設定的語義模版組合各段落語義,劃分標題語義列表、同段落語義列表、不同段落語義列表,每個語義需要含有(語義內(nèi)容、語義關鍵詞密度之和、語義級別(1級(4 類信息)、2級(3 類信息)、3級(2 類信息)、4級(1 類信息)、語義層次(1標題、2同段、3不同段))
取分段語義列表
標題中的語義計入標題語義列表中
正文段落區(qū)分同段語義列表和不同段語義列表,默認同段是第一段,判斷各段落中語義級別最高且語義中各類關鍵詞之和最大的段落作為本文同段
sameNum=1;
for all段落do
if段落語義級別最高且語義中各類關鍵詞之和最大 then
sameNum=;
end if
end for
for all段落do
if段落Num == sameNum then
sameList=[段落語義]
else
differList=[段落語義]
end if
end for
4.文章語義關鍵詞密度矩陣Cij=[0],同一層次將相同級別語義的關鍵詞密度和相加后除以個數(shù)
for all m do
i按照標題、同段、不同段的順序取出各層級語義列表
for all n do
if語義級別為jthen
cij=其中a為該文本層次語義集合,vk為語義k的關鍵詞密度,n為a集合的個數(shù);
end if
end for
end for
5.更加公式計算得分:Score=P×(Cmn×WT)
6.return Score
輸出:Score
得分的高低進行排列,輸出檢索網(wǎng)頁的重要程度,按得分數(shù)值高低進行排序。
3.3 示例
為說明MMSS-Rank算法,以單獨一段的文本數(shù)據(jù)為例,計算過程如下:
標題:抽檢嘉興市嘉利、五福奶糖存在多批次不合格
正文:近日,嘉興市工商行政管理局公布2019年4季度對海寧市流通環(huán)節(jié)銷售的部分奶糖產(chǎn)品進行了質(zhì)量監(jiān)測抽檢。本次監(jiān)測主要對奶糖的衛(wèi)生指標(如菌落總數(shù)、大腸菌群等)以及酸價、過氧化值、苯甲酸或山梨酸、蘇丹紅等項目進行了檢測。監(jiān)測結(jié)果顯示,奶糖內(nèi)在質(zhì)量較好,個別產(chǎn)品存在甜蜜素、還原糖等指標不符合國家有關標準要求的問題。此次抽查49 批次產(chǎn)品,其中2 批次不合格。晉江市嘉利食品有限公司生產(chǎn)的五福多彩軟飴,糖精鈉、甜蜜素不合格,海寧市嘉利食品廠生產(chǎn)的五福酥糖(裹皮型),還原糖不合格。
計算過程:
1.從文章中提取關鍵詞
keywordList:奶糖(4), 嘉興(2), 公布(1),海寧(2)
2.計算提取的關鍵詞分數(shù)
keywordMap:奶糖(2*4/254=0.0315), 嘉興(2*2/254=0.01575), 公布(2*1/254=0.00787), 海寧(2*2/254=0.01575)
3.計算出標題、同段和異段中語義的分數(shù)
標題:{"2":[{"density":"0.04725","content":"海寧奶糖"}]};
同段:{"2":[{"density":"0.02362","content":"嘉興公布"},{"density":"0.04725","content":"嘉興奶糖"}],"1":[{"density":"0.0315","content":"奶糖"},{"density":"0.0315","content":"奶糖"},{"density":"0.01575","content":"海寧"}]};異段:{};
4.計算文章語義關鍵詞密度矩陣
cmn=[ [0, 0, 0.04725, 0],[0, 0, 0.035435, 0],[0, 0, 0, 0]]
5.得出分數(shù):score=[5, 3, 1]*(cmn*[[10][8][5][1]])=[5, 3, 1]* [ [0.23625][0.177157][0]]=1.7127
4 實驗分析
4.1 實驗設計與說明
4.1.1 數(shù)據(jù)準備
目前,針對國內(nèi)外還沒有關于食品安全事件的大規(guī)模數(shù)據(jù)作為公共測試集,因此,本文選擇中國食品報網(wǎng)、中國食品監(jiān)督網(wǎng)、食品安全快速檢測網(wǎng)、39健康網(wǎng)、中國食品科技網(wǎng)、中國質(zhì)量新聞網(wǎng)、浙江消費維權網(wǎng)、第一食品網(wǎng)、山東美食網(wǎng)、FT中文網(wǎng)、四川新聞網(wǎng)、東方網(wǎng)、光明網(wǎng)(食品頻道)等58 家主流網(wǎng)站的食品版塊,從2009—2019年間的720 000 條相關報道數(shù)據(jù)中通過科學地抓取、去重和清洗得到的數(shù)據(jù)作為實驗文本數(shù)據(jù)。再借助分詞技術對食品安全文本數(shù)據(jù)進行分詞,通過對文本數(shù)據(jù)的語義分析、關鍵詞識別、結(jié)構化分解、分層化標注等預處理,進一步得到不同文本數(shù)據(jù)的結(jié)構化信息。其中語義分析工具使用了哈爾濱工業(yè)大學社會計算與信息檢索研究中心研發(fā)的“語言技術平臺”,該平臺提供包括中文分詞、詞性標注、命名實體識別、依存句法分析、語義角色標注等豐富、高效、精準的自然語言處理技術。少量食品安全事件特定的目標詞識別和結(jié)構工作是通過人工進行標注及矯正。
4.1.2 評價指標
本文中MMSS-Rank算法的測試效果采用判別食品安全事件準確率來評價,具體做法為:從實驗文本數(shù)據(jù)中隨機抽取N條數(shù)據(jù),通過人工判別是否為食品安全事件,標記為labeli,i=1, 2,...,N,當labeli=1時表示文本數(shù)據(jù)是食品安全事件,當labeli=0時表示文本數(shù)據(jù)不是食品安全事件;再從標注清楚的數(shù)據(jù)集中隨機選取N1條文本數(shù)據(jù)作為訓練集,剩余N-N1條作為測試集。設定不同層、級和閾值參數(shù),按本文提出的語義模板相似度算法計算訓練集中每一條文本數(shù)據(jù)的得分,將訓練集中所有文本數(shù)據(jù)按分值由大到小排列,得到分值大于和等于閾值α的N2(N2≥N1)條文本數(shù)據(jù),并定義此時的判別準確率P和召回率J。
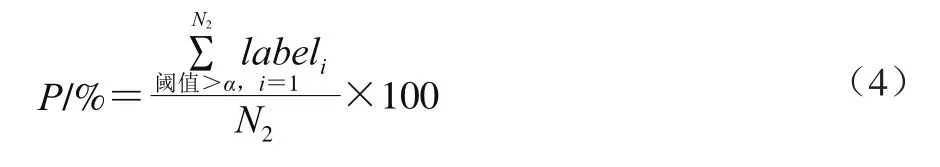
在食品安全事件準確率最優(yōu)的條件下,得到層、級和閾值權重參數(shù),在N2個文本數(shù)據(jù)中,得分大于和等于閾值α的文本中的確是食品安全事件的所占比例為P,P用于測試算法的判別準確率。
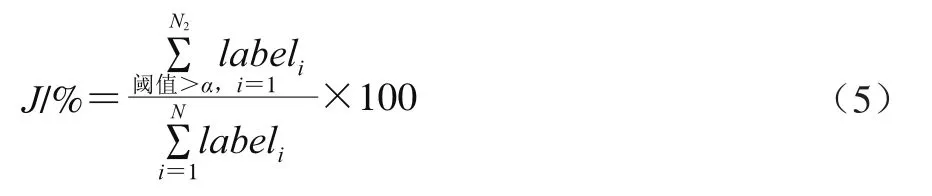
在N個文本數(shù)據(jù)中,得分大于和等于閾值α的文本占全部文本數(shù)據(jù)的比例為J,J用于測試算法的召回率。
4.1.3 對比算法及參數(shù)設置
為了驗證文本所提MMSS-Rank算法的有效性,基于標準測試數(shù)據(jù)集,用不同方法進行性能評估,實驗部分采用如下比較算法:1)傳統(tǒng)的機器學習方法支持向量機(support vector machine,v-SVM),通過訓練和測試已有的數(shù)據(jù),得到較好的訓練參數(shù)用于對新數(shù)據(jù)類別判別;2)基于主題的網(wǎng)頁排序算法T-rank。v-SVM采用LibSVM參數(shù),選擇程序包的默認設置;基于主題Page-rank算法設置參數(shù)。MMSS-Rank算法有結(jié)構層、語義模板和閾值權重,因此,設置不同參數(shù)來研究結(jié)構層、語義模板和閾值權重系數(shù)的影響,見表4。

表4 MMSS-Rank權重算法參數(shù)設置Tale 4 MMSS-Rank parameters
4.2 同層級權重實驗及結(jié)果分析
為了說明本算法中不同層級權重對多層多級語義模板語義影響的差異,首先從第一級開始,依次逐層級權重取值0.1,其他層級權重全部取值為[1, 1, 1, 1],來說明改變層級單一權重對算法影響的情況,計算結(jié)果如圖2所示;然后將層級權重全部取值為[1, 1, 1, 1],來對比說明若僅考慮層級中一個因素取不同權重時對MMSS-Rank算法的影響,計算結(jié)果如圖3所示。
從圖2可以看出,在MMSS-Rank算法中僅改變層級中單一權重,或者層級權重相近時,準確率和召回率沒有顯著變化,說明對于MMSS-Rank算法若不考慮數(shù)據(jù)的文本位置信息和語義結(jié)構特征,由于對食品安全事件缺少比較完整的描述,因此,對于數(shù)據(jù)挖掘的準確率和召回率較低,說明對于MMSS-Rank語義分析算法而言,用不同權重系數(shù)反映層級間的重要程度是必要的。
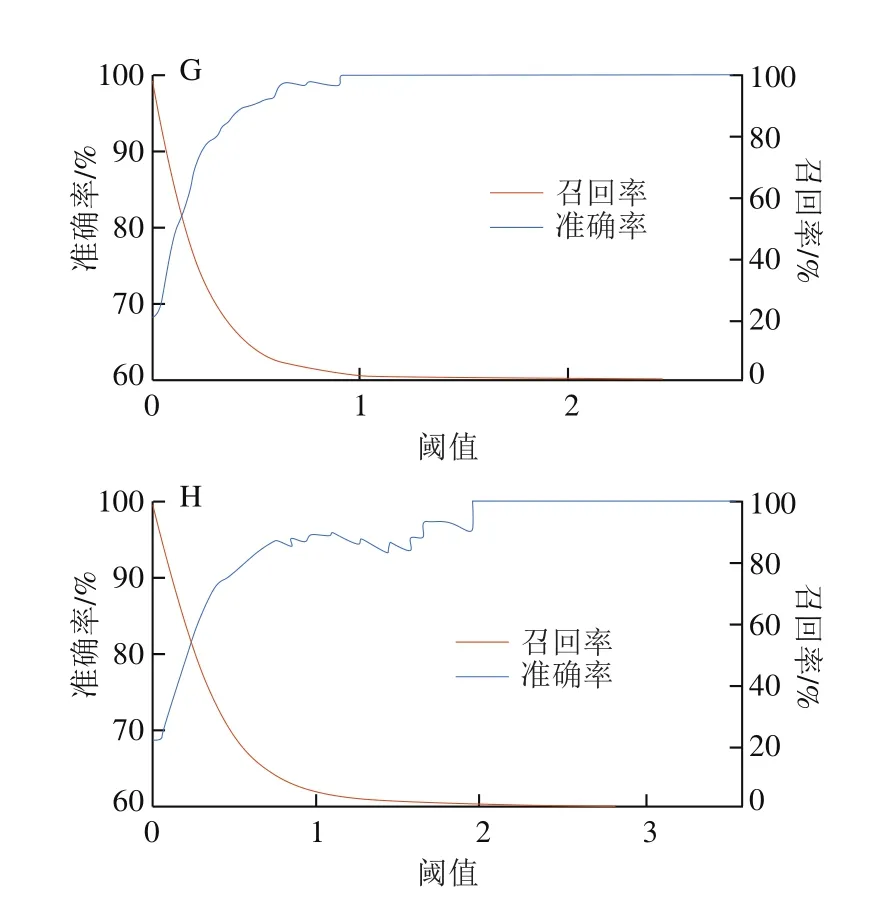
圖2 改變層級單一權重的準確率和召回率曲線Fig.2 Accuracy and recall rate curves determined by changing a single layer and level weight

圖3 單層和單級權重準確率和召回率曲線Fig.3 Accuracy and recall rate curves of single layer and single level weights
從圖3A可以看出,將MMSS-Rank算法中的級權重相同時,層權重越小準確率上升越快,召回率下降越快;從圖3B可以看出,層權重相同時,級權重越小準確率上升越快,召回率下降越快。同時,準確率都隨著閾值的增加而增加,召回率隨閾值增加而減小。當閾值足夠大時,準確率可以達到100%,召回率趨近于0。進一步說明通過適當層級權重可以反映數(shù)據(jù)結(jié)構關系和語義特征,進一步提升MMSS-Rank算法的精度。
4.3 不同層級權重實驗及分析結(jié)果
為了更直觀說明不同層級權重系數(shù)對準確率和召回率的影響,使用表4中已設定的參數(shù)對測試集進行評分測試,計算結(jié)果如表5所示。取準確率80%,當層權重參數(shù)為[1, 0.5, 0.1]和級權重參數(shù)為[10, 3, 1, 0.5]時,閾值經(jīng)計算可得0.092 555,此時召回率達到68.24%;將層級參數(shù)設置為[1 000, 100, 10]和[1 000, 100, 10, 1]時,閾值取值較大且準確率有所下降。

表5 不同準確率下不同參數(shù)的召回率與閾值Table 5 Recall rates and threshold values of different parameters showing different accuracies
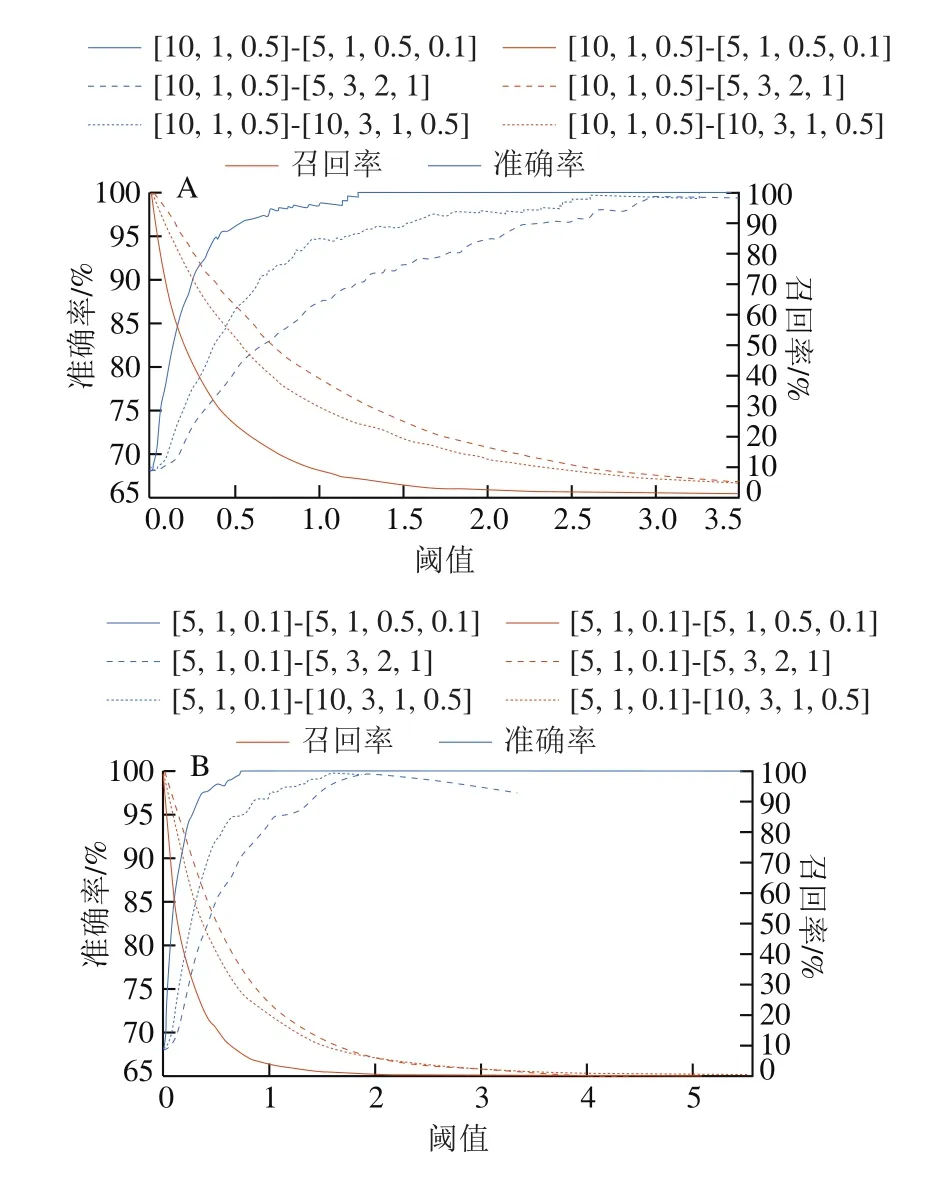
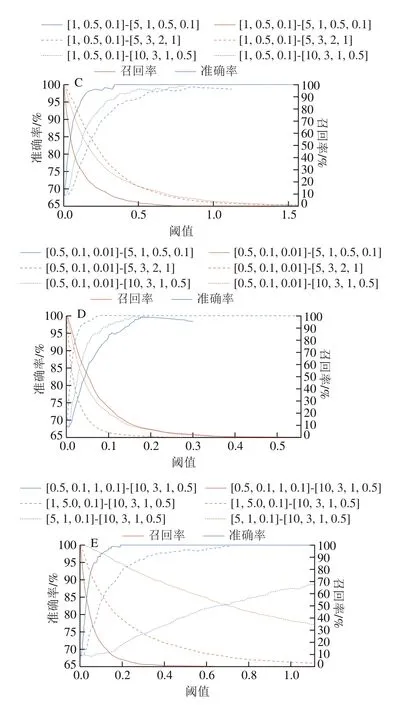
圖4 層和級權重不同時準確率和召回率曲線Fig.4 Accuracy and recall rate curves for different layer and level weights
從圖4A~D可以看出,在MMSS-Rank算法中當權重逐漸增大時,層數(shù)降低,層數(shù)越小,準確率和召回率均快速上升,這表明在MMSS-Rank算法中層權重的重要性高于級權系數(shù),尤其是在標題結(jié)構和食品安全事件數(shù)據(jù)的一級語義結(jié)構基本可以描述食品安全事件數(shù)據(jù)的結(jié)構關系和語義特征時。因此,層權重重要性高于級權重。
在MMSS-Rank算法中,顯著增加食品安全數(shù)據(jù)層權系數(shù)時,準確率和召回率變化情況如圖4E所示,MMSS-Rank算法不僅兼顧文本位置信息,還融入了語義結(jié)構特征,因此能夠完全描述一個食品安全事件,較好地克服了僅使用文本關鍵字來表達的句子語義信息的限制。
4.4 對比算法實驗及分析結(jié)果
本部分實驗選擇v-SVM算法、T-rank算法對食品安全文本數(shù)據(jù)集進行判別,并與本文提出的MMSS-Rank算法進行性能比較,使用平均值作為算法對應的準確率,選擇從2007—2018年主流媒體報道中食品安全事件發(fā)生較多的3 種食品類型進行對比實驗,得出v-SVM、T-rank和MMSS-Rank 3 種算法對食品安全數(shù)據(jù)判別準確率,如表6所示。
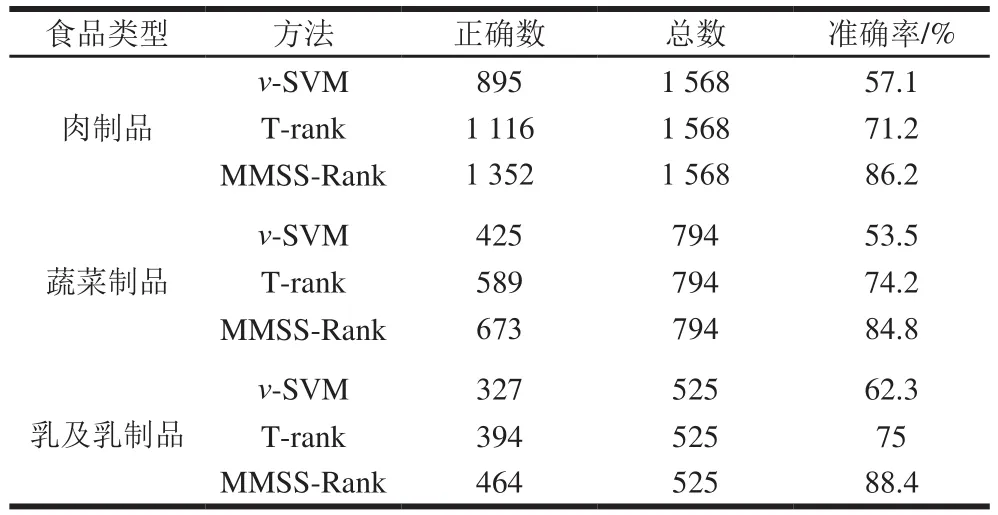
表6 三類食品安全事件判別準確率Table 6 Accuracy in discriminating FSI-related data
由表6可知,對于食品安全事件數(shù)據(jù),相比之下,傳統(tǒng)v-SVM方法的準確率均遜于其他方法,說明傳統(tǒng)的分類學習方法處理文本數(shù)據(jù)時,僅通過提取文本詞頻、句長等信息,無法全面獲取食品安全事件語義信息;基于主題的網(wǎng)頁排序算法T-rank雖然對食品安全事件主題內(nèi)容進行分割,能夠在一定程度上避免v-SVM抽取方法的局限,但是由于食品安全事件具有時空特性,T-rank算法不考慮事件結(jié)構信息,特別是忽略食品安全事件語義特征,因而準確性不高。MMSS-Rank算法在充分考慮食品安全事件數(shù)據(jù)結(jié)構信息的基礎上,又兼顧了食品安全事件發(fā)生地點、時間和環(huán)節(jié)等語義信息,通過與標準食品安全事件的語義模板進行相似度比對,從而較好地實現(xiàn)文本數(shù)據(jù)語義分析;因此,MMSS-Rank算法在肉制品、乳及乳制品上判別準確率明顯優(yōu)于其他兩種方法。
5 結(jié) 語
本文提出的MMSS-Rank算法不僅能夠高效提取不同食品安全事件的語義結(jié)構信息,還通過計算不同事件與語義模板間相似度,實現(xiàn)食品安全事件排序。實驗結(jié)果表明,MMSS-Rank算法對食品安全事件的判別具有較好的準確性和高效性。較之于現(xiàn)有的相關方法,該算法的特色之處在于:1)從食品安全事件的食品種類、供應鏈環(huán)節(jié)、風險因子、空間分布等特征,全面梳理食品安全事件的關鍵詞,構建食品安全事件多層多級標準語義模板。2)將主流來源網(wǎng)站數(shù)據(jù)清洗后,算法分別從橫向和縱向提取食品安全數(shù)據(jù)的語義結(jié)構信息,粒度更小。3)創(chuàng)新地融合食品安全數(shù)據(jù)的分層結(jié)構信息和語義特征,實現(xiàn)在食品供應鏈環(huán)節(jié)上,應用大數(shù)據(jù)挖掘技術研究食品安全事件的演化規(guī)律。
利用MMSS-Rank算法開發(fā)的中國食品安全事件大數(shù)據(jù)分析平臺,不僅可以分析食品安全風險產(chǎn)生的動因和傳播方式,還可以基于信息收集、分析評估、預警預報、預案實施、效果評價等制定相應的措施,探索覆蓋食品供應鏈全程動態(tài)安全預警系統(tǒng),以及研究中國食品安全事件的空間分布特點和變化趨勢。
在實驗過程中,由于不同網(wǎng)站報道形式和內(nèi)容表述的差異,特別是結(jié)構松散的食品安全事件文本數(shù)據(jù)、關鍵詞抽取、分詞、切詞等問題不準確,直接影響了算法精度,這是本算法本身設計特點所決定的。對于未來的工作,可以從下面幾個方面考慮:1)結(jié)合食品安全事件特點,需要尋找一種新的語義模板間相似度的計算方法。另外對于特殊食品安全數(shù)據(jù)和文本,如單句、單段或多關鍵詞交叉,尋找一種高效率、高準確率的食品安全關鍵詞和句抽取方法至關重要。2)食品安全事件關鍵詞切詞、分詞方法也有待改進,本文事先將食品安全事件新聞報道中的關鍵事先設定好,但隨著新聞報道和事件的變化,關鍵詞會不斷變化,因此需要開發(fā)一種動態(tài)的優(yōu)化機制,提升食品安全事件語義分析的準確率。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
當代修辭學(2011年6期)2011-01-29 02:49:50
