基于輕量化深度學習Mobilenet-SSD網絡模型的海珍品檢測方法
2021-05-07 08:04:34俞偉聰郭顯久劉鈺發劉婷李雅薇
大連海洋大學學報 2021年2期
俞偉聰,郭顯久,2*,劉鈺發,劉婷,李雅薇
(1.大連海洋大學 信息工程學院,遼寧 大連 116023;2.遼寧省海洋信息技術重點實驗室,遼寧 大連 116023)
近年來,中國海珍品養殖量和需求量迅速增長,大規模商業化養殖對海珍品的檢測需要投入巨大的成本。基于計算機視覺的海珍品目標檢測技術可有效節約人力,降低運營成本,提高海珍品養殖自動化水平。因此,實現基于計算機視覺的目標檢測技術在海珍品養殖產業上的應用,對于提高海珍品養殖的信息化程度,改善養殖條件具有重要意義[1]。
目前,輕量級的目標檢測模型已經在各行業有著廣泛運用。如在車輛檢測領域,劉肯等[2]利用Tiny-YOLO模型實現了在真實環境下對車輛的自動識別。而目標檢測在漁業領域上的發展也趨向完善,French等[4]使用卷積神經網絡實現了魚類捕撈視頻監控識別;Chen等[5]采用卷積神經網絡實現了野外環境下魚類的分類和檢測。隨著目標檢測在漁業領域應用中的推進,基于深度學習的計算機視覺技術也運用到海珍品目標檢測上,并取得了一定效果。如袁利毫等[3]采用YOLOV3模型實現了水下小目標的識別并成功運用在水下海珍品抓取。
目標檢測技術應用在海珍品上主要存在以下問題:一是自然環境下,海珍品大多生長在泥沙多、水質混濁的區域,在水下攝像機鏡頭中呈現出一種深綠色,就需要對采集的圖像進行預處理;二是在大型服務器上運行的分類網絡如VGG[6]等,對設備要求較高,不便于在海珍品養殖場等區域部署;三是水下通信條件遠不及陸地,特別在遠離海岸的地方,信號延時較大。因此,構建輕量化模型并把模型運行在船載設備上,是解決此類問題的重要思路。基于上述原因,本研究中提出了基于輕量化深度學習模型的海珍品檢測方法,并對水下環境較暗、物體與背景分辨率低等特點,采用優化的Retinex算法[7]進行圖像增強,針對通信網絡環境復雜,構建低時延、高精度的輕量化網絡模型Mobilenet-SSD對海珍品進行檢測,旨在實現精確檢測多種水下海珍品,為科學養殖海珍品過程中掌握海珍品分布提供可靠保障。
1 輕量化深度學習網絡模型的構建
當前主流的深度學習目標檢測網絡模型有SSD[8]和YOLO模型[9]。為了選擇一種適合邊緣計算的輕量化網絡模型,本文對比了Tiny-YOLO網絡模型的主干網絡YOLOV2和SSD網絡模型的主干網絡Mobilenet[10]。Mobilenet模型是當前最流行的輕量化網絡模型之一,相比于Mobilenet模型,YOLOV2模型有兩點明顯的缺點:一是其屬于端到端的訓練方式,對于訓練結果不容易進行科學調試;二是YOLOV2模型只做了7層的卷積尺度變換,特征損失較大,MobileNet和YOLOV2網絡模型參數的比較如表1所示。
針對海珍品檢測,本文利用Mobilenet網絡檢測到目標海珍品后,再用SSD的分類網絡進行目標分類,組成MobileNet-SSD輕量化深度學習網絡模型,以便達到提高海珍品檢測準確率和實時性的要求。

表1 Mobilenet與YOLOV2網絡模型參數的比較
1.1 Mobilenet分類網絡模型
本研究中使用的網絡模型是Mobilenet-V1版本,Mobilenet核心思想是引入了深度可分離卷積[10](圖1),將標準的卷積過濾器拆分成深度卷積和逐點卷積兩個結構。假設輸入與輸出的長×寬不變,標準的卷積過程是將輸入為DF×DF×M的輸入層轉化為維度為DF×DF×N的輸出層,其中DF×DF為輸入或輸出feature map的長×寬,M為是輸入通道數,N為輸出通道數。 假設卷積核過濾器的尺寸為DK×DK,則標準卷積核的計算量為DK×DK×M×N×DF×DF。對于深度可分離卷積來說,卷積執行次數的計算分為2步,第一步深度卷積計算中,有M個DK×DK的矩陣移動DF×DF次,第二步1×1卷積計算中,有N個1×1×M的卷積核移動DF×DF次,因此,將以上2步執行次數相加,得到總的卷積執行次數,深度可分離卷積的計算量為DK×DK×M×DF×DF+1×1×M×N×DF×DF,深度可分離卷積和標準卷積的計算量比值為
(1)
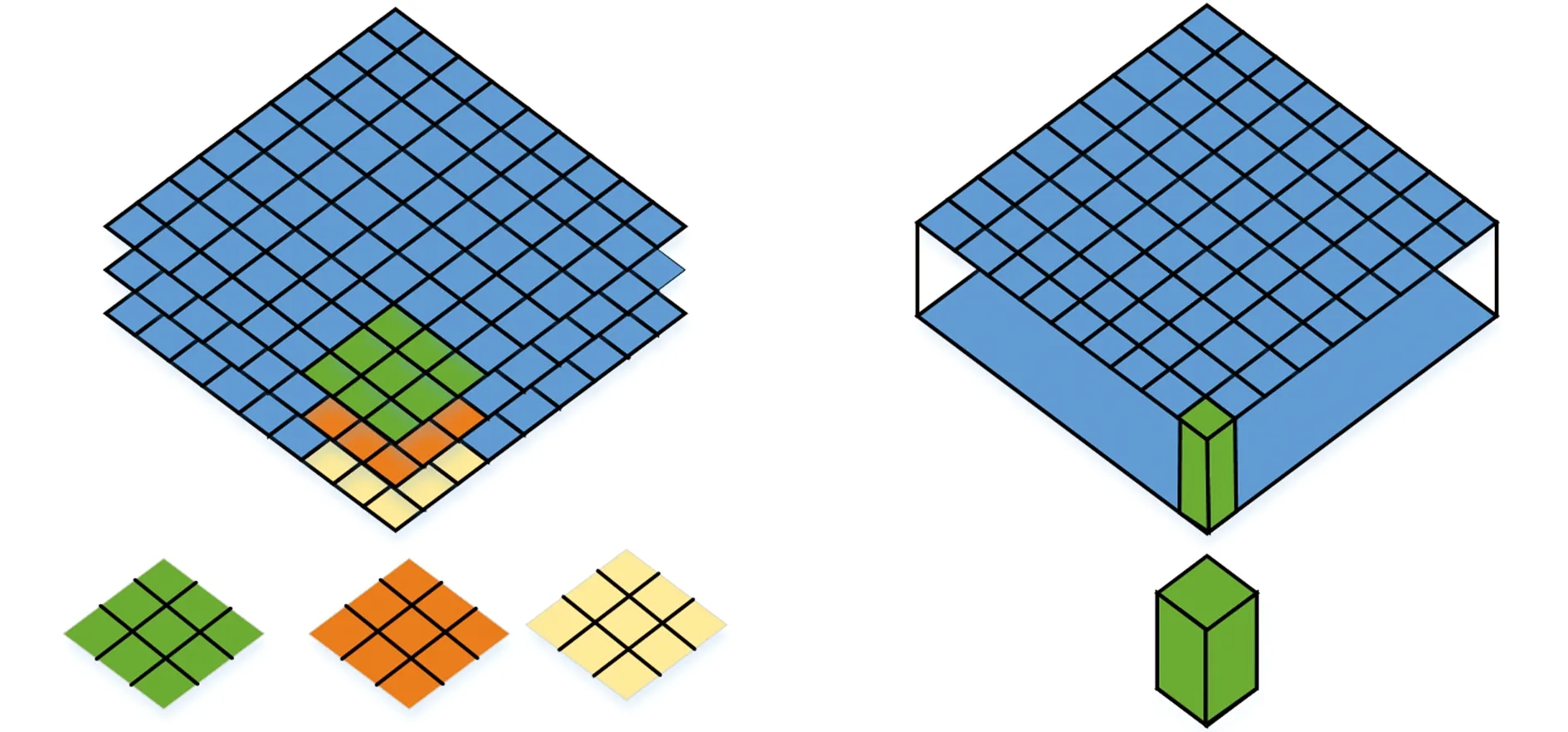
圖1 深度卷積和逐點卷積Fig.1 Deep convolutional neural networks and point by point convolution neural networks
Mobilenet的卷積核尺寸選用DK×DK=3×3,帶入式(1)得到深度可分離卷積的計算量是標準卷積的1/8~1/9,從而達到提升網絡模型運算速度的目的。
1.2 Mobilenet-SSD檢測網絡模型
水下海珍品目標檢測網絡模型Mobilenet-SSD的整體結構如圖2所示。模型將增強后的圖像統一調節長×寬至300×300像素,送入網絡結構,圖中綠色邊框組成的是Mobilenet網絡模型,圖像經過Mobilenet基礎分類網絡模型的底層網絡提取位置邊緣等信息,通過上層網絡提取更加具象的特征。圖中由黑色邊框組成的目標檢測器SSD是采用多尺度特征進行預測,取消預先提取候選區域這一步驟,對目標按照位置和類別置信度分別進行評價,評估總體的損失函數。在形成Mobilenet-SSD網絡模型后,分別在conv11、conv13、conv14_2、conv15_2、conv16_2、conv17_2卷積共6層上提取特征,將SSD檢測器的最小尺寸38×38改進為19×19尺寸的feature map,開始提取特征送給檢測器,同時在6層不同尺度的特征層生成多組對應先驗框(prior box),這些先驗框選取的長與寬比例分別為1、2、3、1/2、1/3,在6層特征層上各采用一次1×1卷積對每個先驗框進行位置和類別的預判別。令n為該特征層所需要的先驗框個數,則對于位置預測所需要的卷積核個數是n×4,對于類別預測需要的卷積核個數是n×c,其中c是類別數,本文中取為3。由于每個真實目標(ground truth)會匹配多個先驗框,最后要選擇交并比(IOU)最大的先驗框與真實目標做匹配成為真樣本,對于其余先驗框,如果交并比大于一定閾值,就將這些框刪除,這個過程就是非極大值抑制(NMS)算法,只留下得分最高的框然后輸出。非極大值抑制算法對于海珍品目標檢測十分必要,因為海珍品生長特點是密集性的,即使在1×1卷積核情況下,仍會受到其余海珍品的部分影響,非極大值抑制過濾多余先驗框,保證了分類網絡在卷積核中心分類的準確性。
在Mobilenet-SSD結構上,conv11、conv13、conv14_2、conv15_2、conv16_2、conv17_2卷積的先驗框的個數分別是3、6、6、6、6、6,對于某一類檢測目標,檢測器都有19×19×3+10×10×6+5×5×6+3×3×6+2×2×6+1×1+6=1917個先驗框負責檢測這個目標。圖2下半部分展示了將卷積提取特征至SSD檢測器并最后輸出的過程。
2 海珍品檢測網絡模型的訓練和測試
試驗數據來自ChinaMM2018水下機器人目標抓取大賽官方標注的海珍品數據集,由潛水員在特定養殖海域進行拍攝,拍攝對象為海參、海膽、扇貝三類目標,圖像格式為.jpg格式,固定分辨率為720×405像素,官方同時也提供了標注有圖像類別和位置的.xml文件,文件名與圖像名稱一一對應。
2.1 建立數據集
篩選通過Retinex算法增強后的圖像,選定5 606張圖像用于訓練和測試模型性能。由于海珍品的生長特性,往往是一張圖像中有多類海珍品,且每種海珍品的數量不止一個,因此,對于一個輕量化模型來說這個數據量是足夠的。按照VOC2012數據集的格式規范化數據,將80%的數據量用于訓練驗證,20%用于測試。在與圖像對應的信息文件中,包含了圖像名稱、海珍品類別名稱、標注框的位置信息、標注框的長和寬。
2.2 網絡模型的訓練和測試
訓練數據集圖像大小均為統一的720×405像素,訓練平臺是Windows10操作系統,型號為2070的顯卡,12G內存條。全局訓練次數為30 000次,初始學習率(rL)設置2組候選值,分別為0.004、0.04,動量系數(α)設置3組候選值,分別為0.5、0.9、0.99。針對這些候選值設計了多組對比試驗,序號為1、2、3的試驗在固定學習率為0.04的情況下改變動量系數,序號為4、5、6的試驗在固定學習率為0.004的情況下改變動量系數,超參數組合試驗情況如表2所示。

表2 不同超參數組合對應的平均準確率
由表2可以看出,設置學習率為0.04對于模型的梯度下降過程不能較好地收斂到全局最小值,在網絡模型訓練初始階段,設置學習率較大有助于模型盡快收斂,但是在訓練后期,較大的學習率會讓梯度下降在權重更新的時候出現波動影響收斂。據此在第4組試驗時,把學習率定在0.004,對比第4組、第5組、第6組試驗,發現當α取值為0.9時的平均準確率最高。動量系數是避免梯度下降時模型陷入局部最小值時引入的一個超參數,α設置為0.5時過小,不能使模型逃脫局部最小值陷阱,α設置為0.99時過大,可能使模型跳過局部最小值。綜合以上考慮,最終選擇初始學習率為0.004,動量系數為0.9。
根據上面最佳參數組合(rL=0.004,α=0.9)訓練模型的權重參數。訓練使用的參數初始化方式是載入在Imagenet數據集上已預訓練的參數,訓練開始后可以通過卷積層的名稱固定底層的參數不進行訓練,解凍上層卷積結構,針對海珍品的特征進行參數微調。最終在測試集上的損失率固定在0.9~1.1范圍內,如圖3所示,模型的平均準確率為85.79%,檢測一幅海珍品圖像用時0.2 s。

圖3 網絡模型損失函數的變化情況Fig.3 Change in network loss function
3 結果與討論
為了進一步說明提出的Mobilenet-SSD模型的有效性,本試驗中選擇了VGG-SSD模型作為參照,對比兩種模型的檢測效果。VGG與Mobilenet都是基礎分類網絡模型,相比Mobilenet,VGG網絡卷積核尺寸較小,但是參數量更多。從海珍品的大小和海珍品的品種2個方面分別做比較,每個評價指標均設置3組對比試驗。為了對比兩種檢測模型的效果,需要先確定模型的評價指標。
由于本文構建的Mobilenet-SSD網絡模型的主干網絡Mobilenet最大的優點是網絡參數量小,對運行速度有顯著提升,因此,在選擇評價指標的時候,除了采用在各類檢測物體的準確率和調和平均值(F1)指標外,還加入了對每張圖像的運算時間指標(t)。F1的計算公式為
(2)
其中:P為準確率,P=TP/(TP+FP);R為召回率,R=TP/(TP+FN),公式中TP、FP、FN、TN參數含義如表3所示。

表3 分類結果混淆矩陣Tab.3 Classification results of the fuscate matrix
為了獲得真正例和假反例,需要先計算交并比(IOU),交并比是預測框與真實值的交集和并集的比值,本文參考PASCAL VOC數據集所用的指標,設置交并比的閾值為0.5,如果IOU>0.5,認為檢測結果是真正例,否則認為是假正例。真正例確定后,漏檢的物體數即假反例就可以由所有正例減去真正例求出。
3.1 不同大小海珍品的檢測結果
在實際測試集當中,海珍品的大小往往對最后的檢測結果有較大的影響。大目標遮擋較少,識別難度低,小目標較為密集遮擋程度大,識別難度高。根據目標在整幅圖像中所占的比例把目標分為大、小兩類,同時將模型對大、小兩類目標海珍品的檢測結果進行了評價。定義占全圖面積5%~20%為小目標,超過20%為大目標。圖4為Mobilenet-SSD和VGG-SSD 2種模型在大、小兩類目標海珍品上的檢測效果,表4是對檢測結果進行統計。表4中總體的計算方法是:統計大、小兩類目標試驗的總樣本數、所有正樣本數、所有檢測到的樣本數和所有檢測到的正樣本數量,采用相同的試驗方法計算總體的準確率、召回率和F1值。分析顯示,Mobilenet-SSD模型在檢測結果優于VGG-SSD的同時,更明顯的提升是檢測速度比VGG-SSD快了近4倍,說明Mobilenet-SSD模型在不損失性能的同時,通過優化卷積之間的連接結構,使參數量下降并加快了運算速度。
3.2 不同種類海珍品的檢測結果
為了進一步分析在不同種類海珍品上的檢測效果,本文用Mobilenet-SSD和VGG-SSD 2種模型分別對海參、海膽和扇貝3類海珍品目標檢測效果進行對比。在原始數據中3類海珍品生長區域往往高度混合,海參和扇貝顏色相近,海膽顏色區分度最大但生長也最為密集,完全被檢測到難度較大。圖5為2種模型在不同種類海珍品上的檢測效果。
統計每類海珍品被正確分類的樣本數TP、被分入正例的負樣本數FP和被分入負例的正樣本數量FN,并計算相關評價指標,結果顯示,Mobilenet-SSD模型的F1值比VGG-SSD高10.69%,平均準確率比VGG-SSD高9.58%(表5),這表明Mobilenet-SSD模型在識別精度上表現得更為優異。兩種模型同時在扇貝識別上表現最好,在海參識別上表現次之,在海膽識別上表現最差(表5)。推測導致這種情況的原因可能是:扇貝生長分布較為分散,遮罩較少,所以檢測效果最好;部分海參埋在泥地下,可提取特征區域小,交并比小,導致假正例多,影響準確率;海膽分布太過密集,遮擋大,導致很多海膽未被檢測到,召回率最低。
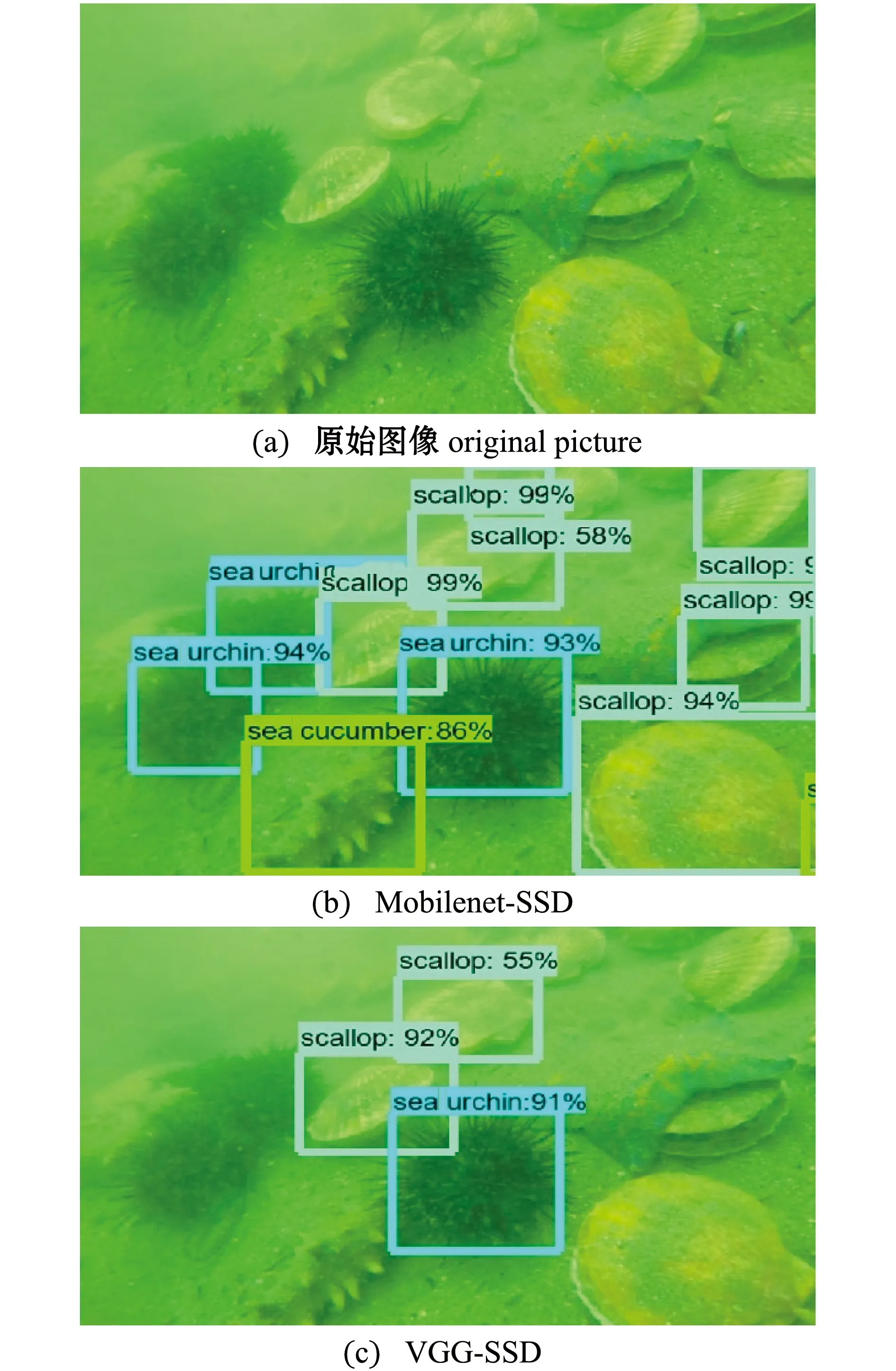
圖5 2種網絡模型對不同種類海珍品的檢測效果Fig.5 Detection effect of two network on different kinds of high value marine food organisms

表5 Mobilenet-SSD與VGG-SSD網絡模型對不同種類海珍品的檢測結果統計
圖6展示了部分識別遺漏或誤判的場景,圖6(a)把背景海草識別為扇貝,圖6(b)左側存在一塊扇貝漏檢的情況,圖6(c)因為檢測目標過于密集反而遺漏了稀疏部分的目標。

圖6 部分存在錯誤識別的圖像Fig.6 Part of the misidentified image
4 結論
1) 提出了基于卷積神經網絡的輕量化模型Mobilenet-SSD,在構建適合自己數據集的結果上確定了適用于海珍品檢測的學習率0.004和動量系數0.9,最終輸出的模型在3類海珍品檢測上的平均精度為85.79%,測試一張海珍品圖像用時0.2 s,在大、小兩類海珍品目標檢測上,較VGG-SSD模型在準確率和實時性上都有明顯提升。
2) 對比因不同種類海珍品而產生的準確率、召回率差異,表明Mobilenet-SSD模型能夠滿足在自然海域里對海參和扇貝的檢測,而海膽因為密集型的生長分布情況,容易造成目標丟失的情況。
3)在使用相同數據集的已報道文獻中,與使用YOLOV2網絡模型相比,本文中提出的Mobilenet-SSD網絡模型更加輕量化,為搭載在功率更低的水下設備上提供了條件;與使用Tiny-YOLO模型相比,Mobilenet-SSD模型增加了網絡層數,使得目標特征得到充分利用,同時模型的訓練結果更容易調試,為未來的更新升級創造了空間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
