基于XGBoost的員工離職預(yù)測(cè)及特征分析模型
2021-05-07 10:44:44王志寧
數(shù)字技術(shù)與應(yīng)用 2021年3期
王志寧
(新疆財(cái)經(jīng)大學(xué)統(tǒng)計(jì)與數(shù)據(jù)科學(xué)學(xué)院,新疆烏魯木齊 830001)
0 引言
當(dāng)今就業(yè)環(huán)境、人力資源管理策略在科學(xué)技術(shù)發(fā)展的影響下呈現(xiàn)出新特點(diǎn):一方面,重要人才成為影響企業(yè)核心競(jìng)爭(zhēng)力、質(zhì)量效益的關(guān)鍵;另一方面,員工離職的影響也在加劇,關(guān)鍵性人才的主動(dòng)離職會(huì)對(duì)公司的運(yùn)營(yíng)造成損失,也增加了重新招聘及新員工培訓(xùn)的成本。而隨著數(shù)據(jù)挖掘技術(shù)的發(fā)展,人力資源策略數(shù)據(jù)化的價(jià)值不斷放大。基于員工情況、薪資等各項(xiàng)指標(biāo)數(shù)據(jù)建立機(jī)器學(xué)習(xí)算法模型,預(yù)測(cè)員工的離職傾向逐漸成為人力資源管理的新方向[1]。員工離職預(yù)測(cè)能協(xié)助管理者提前介入員工的離職意向,調(diào)整管理策略,為保留人才贏得時(shí)機(jī),也擴(kuò)大為員工留任提供解決方案的空間。
員工離職是人力資源領(lǐng)域的核心問題,有不少學(xué)者針對(duì)員工離職問題進(jìn)行研究[2-4]。而人力資源管理策略數(shù)據(jù)化的不斷發(fā)展,針對(duì)員工離職問題的預(yù)測(cè)研究也頗受關(guān)注[5],劉婷婷運(yùn)用C4.5決策樹算法選取IBM分析平臺(tái)樣例數(shù)據(jù),建模預(yù)測(cè)員工是否離職[6]。張紫君基于GBDT算法研究員工離職的預(yù)測(cè)問題,并根據(jù)特征重要性總結(jié)員工離職的影響因素[7]。李強(qiáng)等人結(jié)合Adaboost和Random Forest算法構(gòu)建員工離職預(yù)測(cè)模型,取得了高于單一算法模型的預(yù)測(cè)準(zhǔn)確性[8]。
為進(jìn)一步提高離職預(yù)測(cè)模型的性能及可解釋性。本文基于數(shù)據(jù)科學(xué)競(jìng)賽平臺(tái)Kaggle中的員工分析數(shù)據(jù)集,運(yùn)用XGBoost算法構(gòu)建員工離職預(yù)測(cè)模型,與機(jī)器學(xué)習(xí)主流算法進(jìn)行相應(yīng)模型評(píng)價(jià)指標(biāo)的實(shí)驗(yàn)對(duì)比,驗(yàn)證XGBoost模型的效果,并結(jié)合SHAP方法提升預(yù)測(cè)模型的可解釋性,分析員工離職決策的成因。
1 模型方法
離職預(yù)測(cè)是二分類問題,設(shè)員工數(shù)據(jù)集為X,包含員工的工作滿意程度、相對(duì)薪資等特征,Y為目標(biāo)變量,即員工是否離職。基于XGBoost算法構(gòu)建員工離職預(yù)測(cè)模型,XGBoost是梯度提升決策樹的改進(jìn)算法,其完整的目標(biāo)函數(shù)如公式(1)所示,由損失函數(shù)和正則化懲罰項(xiàng)相加而成,正則化項(xiàng)用以控制模型的復(fù)雜度。其中yi為樣本真實(shí)值,為預(yù)測(cè)值,ft為每一輪迭代所建立的樹模型,最優(yōu)化目標(biāo)函數(shù)即求解出樹結(jié)構(gòu)。集成的基本思想是在每一輪迭代過程中,增加一棵決策樹,使模型的效果能夠提升,過程如公式(2)所示為第t輪迭代模型的預(yù)測(cè)值,為前t-1輪的模型預(yù)測(cè),ft(xi) 表示第t輪迭代新加入的樹模型。
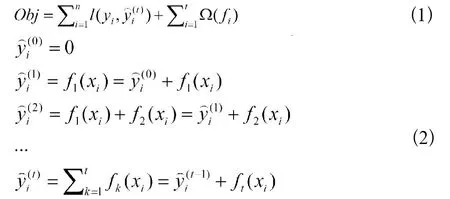
XGBoost利用二階泰勒級(jí)數(shù)近似目標(biāo)函數(shù),將目標(biāo)函數(shù)轉(zhuǎn)化為與樹結(jié)構(gòu)直接相關(guān)的形式,在節(jié)點(diǎn)分裂時(shí),預(yù)先按照特征值大小進(jìn)行特征排序,保存為block結(jié)構(gòu),迭代中會(huì)重復(fù)使用這個(gè)結(jié)構(gòu),減小計(jì)算量;并采用類似分位點(diǎn)選取的方式,僅選出常數(shù)個(gè)特征值作為其候選分割點(diǎn),從候選分割點(diǎn)中選出最優(yōu)的分割點(diǎn),以實(shí)現(xiàn)預(yù)測(cè)準(zhǔn)確、運(yùn)算快速的目標(biāo)。
2 實(shí)驗(yàn)測(cè)試及分析
本文選用準(zhǔn)確率、F1值和AUC值三項(xiàng)分類算法評(píng)價(jià)指標(biāo)衡量模型的優(yōu)劣性。是否離職分類結(jié)果混淆矩陣如表1所示。準(zhǔn)確率是指對(duì)于給定測(cè)試數(shù)據(jù)集,分類器正確分類的樣本數(shù)與總樣本數(shù)之比;F1值是綜合評(píng)價(jià)指標(biāo),F1值越接近1,表明模型預(yù)測(cè)越準(zhǔn)確。準(zhǔn)確率和F1值是由混淆矩陣計(jì)算得到。可利用混淆矩陣?yán)L制出ROC曲線,AUC值是由該曲線求得。AUC值越大,模型精度越高。準(zhǔn)確率和F1值的計(jì)算公式如公式(3)、(4)所示。

本文所選取數(shù)據(jù)集包含的特征如表2所示,是否離職作為標(biāo)簽。預(yù)處理后的樣本總量為14999,特征總數(shù)為9。將特征變量與目標(biāo)變量輸入模型,劃分訓(xùn)練集與預(yù)測(cè)集數(shù)據(jù),建模訓(xùn)練預(yù)測(cè)。模型最優(yōu)超參數(shù)組合為:n_estimators=60,learning_rate=0.1,max_depth=5,其余參數(shù)為默認(rèn)值。將所建立的離職預(yù)測(cè)模型與Logistic算法、樸素貝葉斯、支持向量機(jī)分類、線性判別分析算法進(jìn)行相應(yīng)評(píng)價(jià)指標(biāo)的交叉驗(yàn)證實(shí)驗(yàn)對(duì)比,對(duì)比結(jié)果如表3所示。
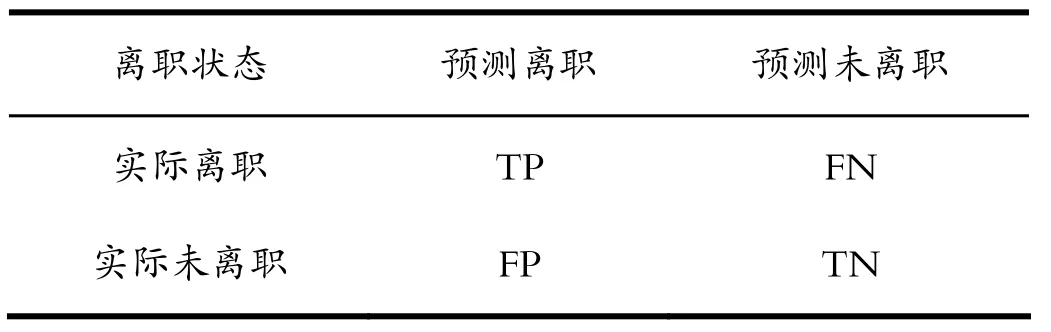
表1 分類結(jié)果混淆矩陣Tab.1 Confusion matrix of classification results

表2 數(shù)據(jù)集特征屬性Tab.2 Data set characteristic attributes
分析對(duì)比實(shí)驗(yàn)結(jié)果,本文建立的XGBoost模型的預(yù)測(cè)準(zhǔn)確率為95.6%,F1值為92.8%,AUC值為93.6%,在三項(xiàng)指標(biāo)上,相較于其他四種算法模型,都具有最佳表現(xiàn)。員工是否離職與其相對(duì)薪資水平、工作內(nèi)容、滿意度等特征之間存在復(fù)雜的非線性關(guān)系,基于集成方法的XGBoost平衡模型的復(fù)雜度與精確性,并基于貪心算法尋找最佳分裂點(diǎn),具有優(yōu)越性。
3 基于SHAP的模型解釋分析
SHAP以博弈論思想為基礎(chǔ),被廣泛用于解釋復(fù)雜算法。核心是計(jì)算特征的歸因值,每個(gè)特征計(jì)算的歸因值反映該特征影響模型預(yù)測(cè)值的程度。歸因值是特征對(duì)預(yù)測(cè)結(jié)果的作用力,正值表明該特征對(duì)模型預(yù)測(cè)有提升作用,負(fù)值表示該特征對(duì)模型預(yù)測(cè)構(gòu)成負(fù)向作用,模型的預(yù)測(cè)值由模型預(yù)測(cè)的平均值與每個(gè)特征的作用力相加而得。
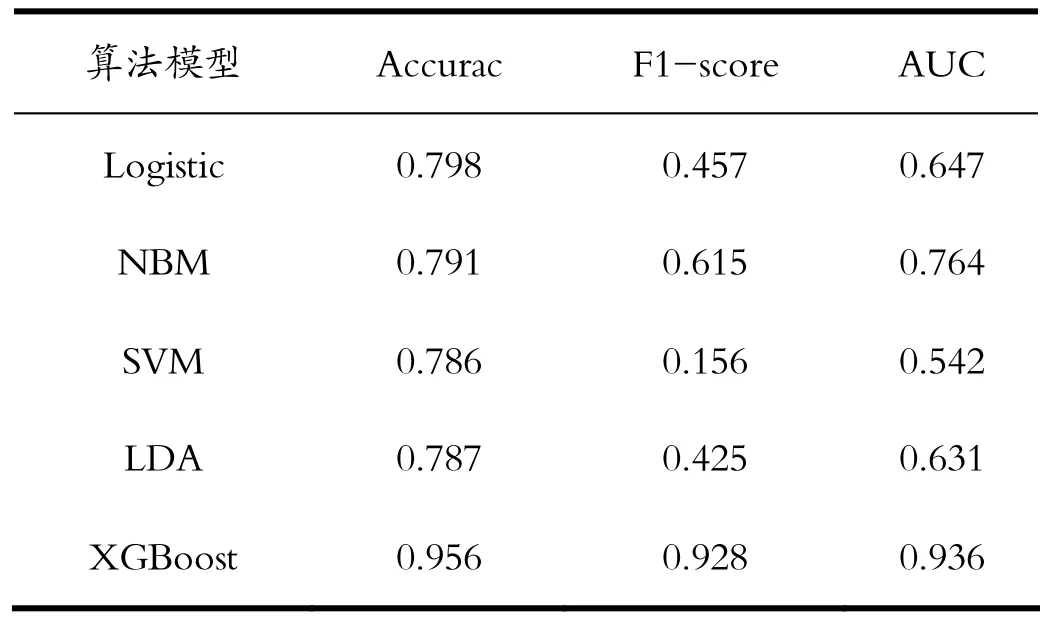
表3 模型性能對(duì)比結(jié)果Tab.3 Model performance comparison results
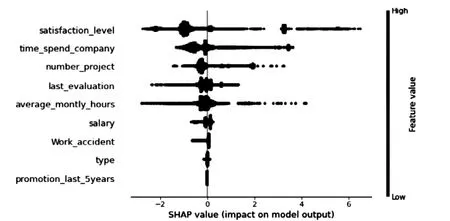
圖1 SHAP特征摘要圖Fig.1 SHAP feature summary diagram
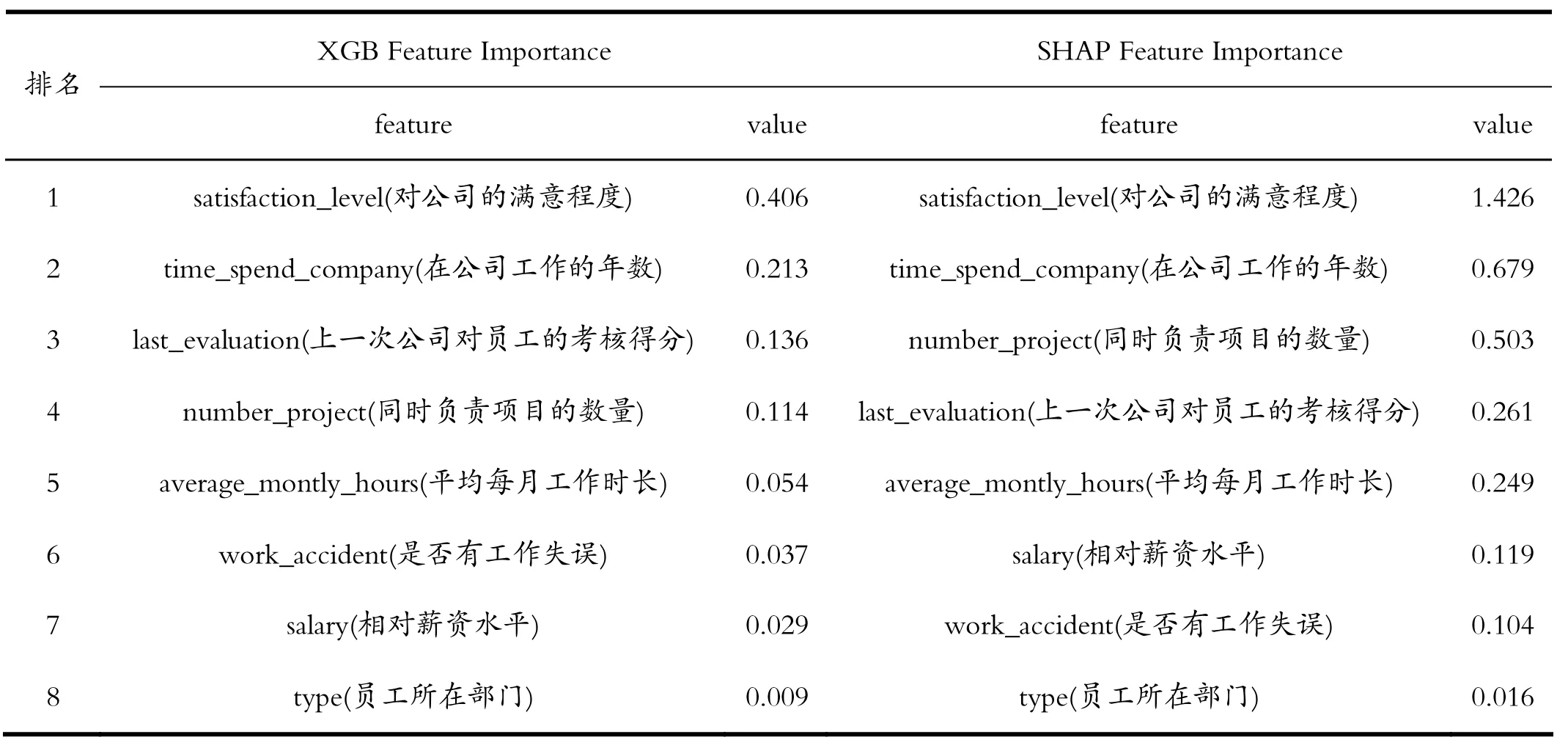
表4 XGBoost,SHAP算法特征重要度對(duì)比Tab.4 XGBoost, SHAP algorithm feature importance comparison
如圖1所示SHAP摘要圖,根據(jù)每個(gè)特征對(duì)于員工是否離職的影響程度重要性進(jìn)行排序繪制,顏色表示特征的具體數(shù)值,越接近紅色,特征數(shù)值越大,越接近藍(lán)色,數(shù)值越小;圖中每個(gè)點(diǎn)為一個(gè)樣本。如表4所示XGBoost特征重要度與SHAP特征重要度排序?qū)Ρ取?/p>
綜合分析得出,對(duì)公司的滿意程度、在公司工作的年數(shù)、同時(shí)負(fù)責(zé)項(xiàng)目的數(shù)量、平均每月工作時(shí)長(zhǎng)、相對(duì)薪資水平是影響員工離職的關(guān)鍵因素。員工的滿意程度、相對(duì)薪資水平越高,離職的可能性越低,符合員工期望的工作內(nèi)容及狀態(tài),能夠滿足員工的認(rèn)同感與獲得感,并具有不錯(cuò)的薪資收入水平,是員工在工作崗位上長(zhǎng)久、穩(wěn)定付出的重要基礎(chǔ)。工作年數(shù)較短如2至3年的員工,正處在發(fā)展適應(yīng)階段,對(duì)于當(dāng)前工作的感受尚未完全,離職的可能性較低;員工在公司工作的年數(shù)越長(zhǎng),越趨于穩(wěn)定,在公司工作7年以上的員工已經(jīng)成為公司中的重要一員,離職可能性也較低。而工作年數(shù)在4至6年的員工,具有跳槽、尋找新工作環(huán)境的潛在傾向,其離職的可能性較大。此外,平均每月工作時(shí)長(zhǎng)在300小時(shí)左右的員工,日常休息時(shí)間多被工作所占用,離職的可能性較大。同時(shí)負(fù)責(zé)項(xiàng)目越多的員工,對(duì)于工作的滿意程度越低,員工的工作壓力會(huì)受到同時(shí)負(fù)責(zé)項(xiàng)目數(shù)量的影響,較多的項(xiàng)目帶來的工作壓力較大,占用員工休息時(shí)間的可能性更大,員工的離職傾向也越高。
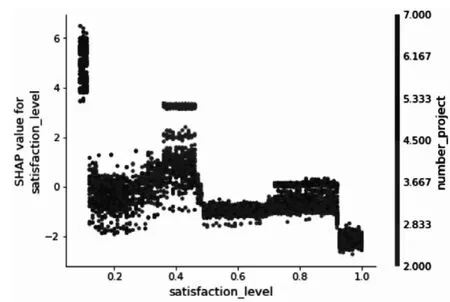
圖2 SHAP特征交互圖Fig.2 SHAP feature interactive diagram
SHAP模型不僅可以對(duì)樣本特征總體分析,還可以顯示兩個(gè)特征的交互作用關(guān)系對(duì)于目標(biāo)變量的影響。如圖2所示satisfaction_level(對(duì)公司的滿意程度)特征依賴圖為基礎(chǔ),number_project(同時(shí)負(fù)責(zé)項(xiàng)目的數(shù)量)的特征數(shù)值大小著色表示的特征交互圖。分析發(fā)現(xiàn),同時(shí)負(fù)責(zé)項(xiàng)目越多的員工,對(duì)于工作的滿意程度越低,其離職的可能性較大。員工的工作壓力會(huì)受到同時(shí)負(fù)責(zé)項(xiàng)目數(shù)量的影響,較多的項(xiàng)目帶來的工作壓力較大,占用員工休息時(shí)間的可能性更大,員工的離職傾向也越高。
4 結(jié)語
人力資源策略管理數(shù)據(jù)化不斷發(fā)展,員工離職預(yù)測(cè)問題的研究愈發(fā)重要。本文基于員工分析數(shù)據(jù)集運(yùn)用XGBoost算法建立離職預(yù)測(cè)模型,與Logistic、樸素貝葉斯、支持向量機(jī)分類、線性判別分析算法進(jìn)行相應(yīng)分類算法評(píng)價(jià)指標(biāo)的實(shí)驗(yàn)對(duì)比,并結(jié)合SHAP模型提高可解釋性,分析影響員工離職決策的因素。下一步工作可以考慮增加新特征,進(jìn)一步提升預(yù)測(cè)模型對(duì)于員工離職問題的應(yīng)用意義。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
