基于GAN的刀具狀態(tài)監(jiān)測數(shù)據集增強方法*
2021-05-06 02:04:30牛蒙蒙沈明瑞厲大維王永青
組合機床與自動化加工技術 2021年4期
關鍵詞:深度
牛蒙蒙,沈明瑞,秦 波,厲大維,劉 闊,王永青
(大連理工大學機械工程學院,遼寧 大連 116024)
0 引言
隨著人工智能的發(fā)展,越來越多的學者將機器學習,尤其是深度學習應用在機械加工狀態(tài)的監(jiān)測中,如刀具狀態(tài)監(jiān)測、設備健康狀態(tài)監(jiān)測等。然而,和其它應用領域不同的是,大多數(shù)機械加工過程在正常狀態(tài)下運行,異常狀態(tài)下的樣本數(shù)據量相對較少,容易出現(xiàn)數(shù)據不平衡的問題[1]。訓練數(shù)據集不平衡會導致深度學習網絡在預測加工狀態(tài)時難以提高準確性,因此,如何解決數(shù)據不平衡問題成為提高加工狀態(tài)監(jiān)測準確性的關鍵。
解決該問題的辦法之一是增強數(shù)據集。一些學者對增強數(shù)據集的方法做了研究。Chawla N V[2]提出了一種合成少數(shù)類過采樣技術(Synthetic Minority Oversampling Technique, SMOTE),可以隨機插入虛擬樣本來平衡訓練集。Ramentol E等[3]提出了一種改進的基于粗糙集理論的SMOTE算法對少數(shù)樣本進行過采樣。Sun Y等[4]在AdaBoost學習框架中添加了一個成本項目,以調整少數(shù)樣本的權重。
通過上述研究可以看出,盡管上述這些方法獲得了良好的性能,但是它們仍然具有一些缺點,其中之一是缺乏適應性,即它們不能自動學習樣本的數(shù)據分布特性[5]。另外,過采樣只是對少數(shù)類樣本進行重復增加,不能添加新的數(shù)據信息,一定程度上會造成過擬合;欠采樣是從多數(shù)類樣本中提取或刪除數(shù)據,這種方法會造成數(shù)據信息丟失使模型無法充分利用已有的信息。這些方法并不能從根本上解決數(shù)據不平衡問題。
生成對抗網絡(Generative Adversarial Networks,GANs)[6]作為2014年提出的無監(jiān)督學習模型,在增強數(shù)據集、加工狀態(tài)監(jiān)測領域有著廣闊的應用前景。通過訓練生成對抗網絡產生新樣本,從而補充數(shù)據流形已達到近似真實分布,在不同類型的數(shù)據之間產生更好的邊界[7]。本文在鏜削加工實驗中,利用生成對抗網絡對刀具在異常狀態(tài)下的樣本數(shù)據進行生成,并在深度置信網絡上測試生成數(shù)據的可用性。實驗證明,該方法有效地提高刀具狀態(tài)監(jiān)測的準確性。
1 生成對抗網絡
生成式對抗網絡框架由一個生成器G和一個鑒別器D構成。生成器負責生成和真實數(shù)據維度相同的偽數(shù)據,鑒別器負責區(qū)分真實數(shù)據和生成數(shù)據;在對抗訓練過程中,生成器試圖用生成的偽數(shù)據去愚弄鑒別器,使其鑒別為真,而鑒別器通過提高自己的鑒別能力分辨生成數(shù)據和真實數(shù)據,兩者進行博弈,最終達到納什平衡狀態(tài),即生成器生成的樣本數(shù)據與真實的樣本數(shù)據無差別,鑒別器也無法區(qū)分生成的樣本數(shù)據和真實的樣本數(shù)據。GAN的架構如圖1所示。
本文中所采用的生成器和鑒別器均為三層全連接神經網絡。如圖2所示。設輸入的隨機噪聲序列為z=[z1,z2,…,zi,…zk],其中zi∈Rm,m為噪聲數(shù)據的維度,k為噪聲數(shù)據的個數(shù);原始樣本數(shù)據序列為x=[x1,x2,…,xj,…,xl],其中xj∈Rn,n為原始樣本數(shù)據的維度,l為原始樣本數(shù)據的個數(shù)。輸入層到隱含層以及隱含層到輸出層的映射公式如式(1)所示:
hi=fθ(w*zi+b)hj=fθ(w*xj+b)
(1)
式中,f為激活函數(shù),θ={w,b}是網絡的參數(shù)矩陣,其中w是輸入層、隱含層和輸出層神經元之間的連接權值,b是隱含層和輸出層神經元的閾值。
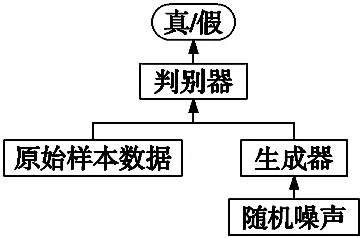
圖1 GAN架構示意圖
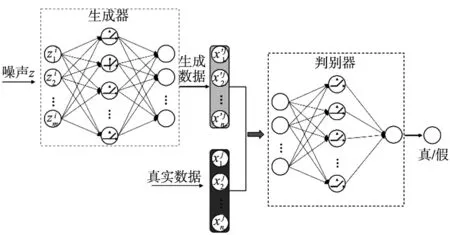
圖2 GAN的結構示意圖
生成器和鑒別器的隱含層的激活函數(shù)均為ReLU函數(shù),生成器的輸出層的激活函數(shù)采用Sigmoid函數(shù)。
生成對抗網絡的目標函數(shù)如式(2)所示:
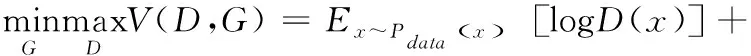
(2)
式中,Pdata(x)是真實數(shù)據的數(shù)據分布,Pz(z)是一個先驗噪聲分布(如高斯分布或者均勻分布);D(x)表示x來自真實數(shù)據的概率;D(G(z))表示G(z)來自生成數(shù)據的概率,其中G(z)是生成器由服從先驗分布的噪聲數(shù)據z生成的數(shù)據樣本;Ex~Pdata(x)表示x來自真實數(shù)據的數(shù)據分布的期望,Ez~Pz(z)表示z來自噪聲分布的期望。
亞當優(yōu)化算法能夠對每個不同的參數(shù)調整不同的學習率, 比標準的隨機梯度下降法更有效地收斂,因此本文采用亞當優(yōu)化算法來更新參數(shù)。
2 深度置信網絡
深度置信網絡(Deep Belief Network, DBN)[8]由多層限制玻爾茲曼機(Restricted Boltzmann Machine, RBM)堆疊構成。結構如圖3所示。
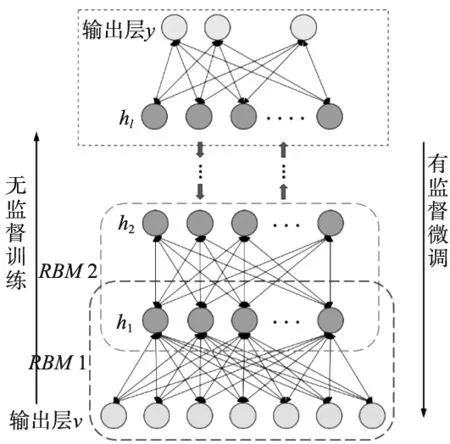
圖3 深度置信網絡結構
RBM是基于能量的模型,其聯(lián)合概率分布由能量函數(shù)指定。對于一組特定的(v,h),RBM能量函數(shù)的定義為:
(9)
其中,vi和hj是可見單元i和隱藏單元j的二進制狀態(tài),θ={w,b,a}是模型的參數(shù),wij是可見單元i和隱藏單元j之間的連接權值,bi和aj是分別表示其偏置值,V和H是可見單元和隱藏單元個數(shù)。式(10)和式(11)是RBM中的學習過程和推理過程。
(10)
(11)
其中,f(x)=1/((1+e(-x)))是激活函數(shù)。
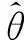
(12)
其中,〈·〉data表示一個期望的數(shù)據分布,〈·〉model表示由模型定義的期望分布。在實際應用中,使用對比散度方法計算梯度,即利用吉布斯采樣取代〈·〉model。
DBN采用逐層訓練的方式,并利用Back propagation (BP)對網絡權值進行調整[9],因此訓練方式為無監(jiān)督和有監(jiān)督相結合[10]。本文中,DBN的輸出層采用Softmax分類方式對刀具狀態(tài)進行分類。
3 基于GAN的刀具狀態(tài)監(jiān)測
本文所提出的基于GAN的刀具狀態(tài)數(shù)據集增強方法實施步驟如下:
(1) 采用傳感器采集系統(tǒng)獲取刀具切削過程中的振動信號和噪聲信號;
(2) 將服從先驗分布的噪聲數(shù)據輸入到生成器生成數(shù)據,并將生成數(shù)據和采集的真實樣本數(shù)據輸入到鑒別器進行鑒別,生成器和鑒別器兩者之間進行對抗訓練,直到訓練完成;
(3) 利用訓練好的生成器生成樣本數(shù)據,并判斷生成的樣本數(shù)據和真實的刀具狀態(tài)樣本數(shù)據的分布是否相似;
(4) 結合深度學習網絡模型預測刀具狀態(tài)的準確性檢驗生成數(shù)據的可用性。流程如圖4所示。
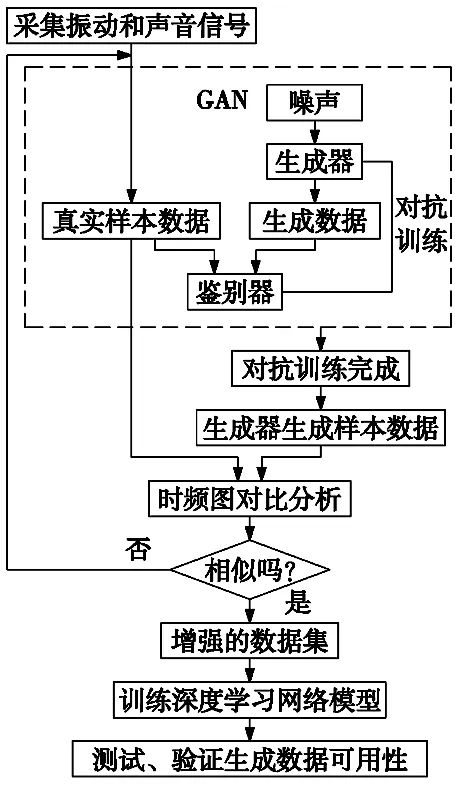
圖4 流程圖
4 實驗驗證
4.1 數(shù)據獲取
本次試驗采用國產某型號深孔鏜床,刀具為硬質合金YT15刀加工深孔工件,并采集了鏜削過程中的振動和聲音數(shù)據。傳感器的安裝位置示意圖如圖5所示。
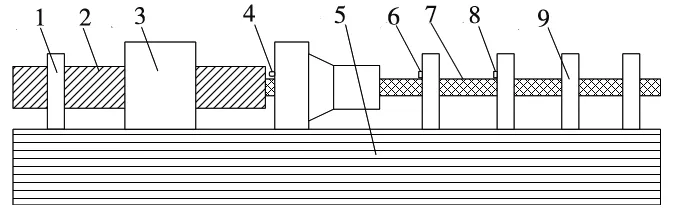
1.工件保持架 2.工件 3.機床齒輪箱 4.傳聲器 5.床身 6.1#三向加速度傳感器 7.刀桿 8.2#三向加速度傳感器 9.刀桿保持架圖5 傳感器安裝位置示意圖
按照刀具狀態(tài)將數(shù)據分成三類,第一類是正常,第二類為斷刀,第三類為磨鈍。三類樣本個數(shù)如表1所示。每個樣本中振動信號的數(shù)據點為6000,噪聲信號的數(shù)據點為1000,因此每個樣本的數(shù)據點為7000。
表1中刀具磨鈍狀態(tài)的樣本數(shù)據明顯少于正常狀態(tài)和斷刀狀態(tài)的樣本數(shù)據,因此我們對磨鈍狀態(tài)的樣本數(shù)據進行生成。

表1 樣本數(shù)量
4.2 生成對抗網絡的訓練與數(shù)據生成
本發(fā)明采用的生成對抗網絡模型中,生成器和鑒別器都采用三層全連接神經網絡模型,其中生成器和鑒別器的隱含層的神經元個數(shù)設置為125個,生成器的輸入神經元個數(shù)為100個。學習率設為0.001,批量大小為12個,迭代次數(shù)設置為100次,輸入的噪聲分布服從區(qū)間為[-1,1]的均勻分布。磨鈍狀態(tài)真實樣本數(shù)據和生成樣本數(shù)據的比例為1:3。平衡后的樣本數(shù)量如表2所示。

表2 平衡后樣本數(shù)量
4.3 深度置信網絡的訓練與測試
深度置信網絡模型的參數(shù)設置如下:學習速率為0.001;無監(jiān)督訓練過程的迭代次數(shù)為100,微調過程的迭代次數(shù)為200。隱含層為三層,每一層的神經元的個數(shù)分別為100、60、30。由于動量梯度下降法優(yōu)于梯度下降法,因此我們采用動量梯度下降法來優(yōu)化參數(shù),動量項為0.9。利用增強的數(shù)據集訓練深度學習網絡,并在測試集上進行測試。這里測試集由真實數(shù)據組成且和訓練集沒有任何交集。
4.4 刀具狀態(tài)監(jiān)測結果與分析
4.4.1 生成的樣本分析
利用MATLAB做出真實樣本數(shù)據和生成樣本數(shù)據的時頻圖,如圖6所示。從時域圖和頻譜圖可以看出,真實的樣本數(shù)據和生成的樣本數(shù)據分布相似度較高。
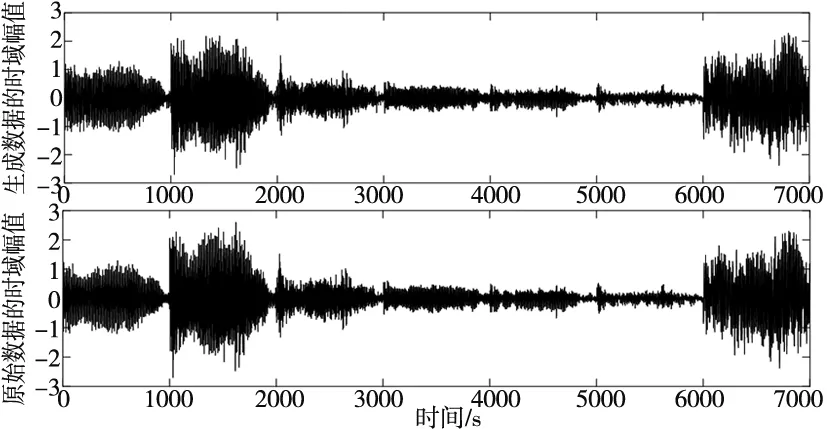
(a) 時域圖
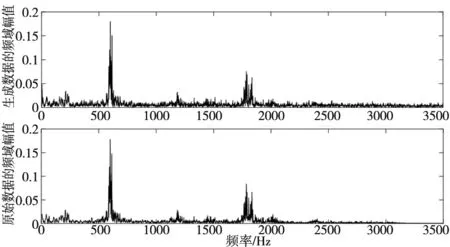
(b) 頻譜圖圖6 時頻圖
4.4.2 增強數(shù)據集前后對比分析
本文對比了增強數(shù)據集前后,刀具狀態(tài)監(jiān)測結果,如表3所示。由表可以看出,增強的訓練數(shù)據集在分類精度方面具有較好的性能。

表3 試驗結果
5 結論
本文提出一種基于生成對抗網絡的刀具狀態(tài)數(shù)據集增強方法。利用生成對抗網絡能夠自動學習原始數(shù)據的分布的特點,生成和原始數(shù)據分布相似的樣本數(shù)據,增強訓練數(shù)據集。并用深度置信網絡測試生成數(shù)據的可用性。由結果可知,增強數(shù)據集有效提高了刀具狀態(tài)監(jiān)測準確性。因此,該方法在增強數(shù)據集、加工狀態(tài)監(jiān)測領域有著廣闊的應用前景。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
