基于信息增益的KNN 社交網絡異常用戶檢測
2021-04-23 05:50:28武海燕李坤明
軟件導刊 2021年4期
武海燕,李坤明
(鐵道警察學院圖像與網絡偵查系,河南鄭州 450053)
0 引言
隨著社交網絡平臺的迅速發展,國內的微信、微博,國外的Twitter、Facebook 等已經成為人們日常生活中重要的社交工具,越來越多的人們在社交網絡平臺上獲取信息[1-2]。當前社交網絡中存在著大量異常用戶,這些異常用戶通過創建大量的虛假賬號和盜用正常用戶的賬號,發布虛假廣告、散布謠言等行為擾亂社會穩定。同時,也存在著發布釣魚信息,操縱大量用戶進行互粉、點贊的惡意行為。因此,社交網絡平臺上的非法用戶檢測具有重要意義,不僅讓用戶在社交網絡上獲得真實信息、提升上網體驗,同時也是公安輿情和社交網絡研究領域的一個重要課題。
1 相關工作
近年來,研究者主要采用機器學習算法對社交網絡異常用戶進行檢測,比較常用的方法分為3 種:有監督學習的檢測方法、無監督學習的檢測方法和圖模型的檢測方法。其中,圖模型檢測方法是一種特殊的無監督檢測方法。
1.1 無監督學習的檢測方法
當樣本數據集不含標簽或者是僅僅擁有少量用戶的標簽時,研究者提出利用無監督學習算法解決異常用戶檢測問題。無監督學習檢測方法是基于聚類思想,將正常用戶和異常用戶聚集為不同簇的方法。Husna[3]等將垃圾郵件的發送者所發送郵件的內容、時間、頻率等作為特征,然后使用K 均值聚類算法進行聚類分析;為了提高聚類效果,陳莊等[4]通過引入信息熵,將各屬性權重進行排序后計算相似度,提升了檢測率;Miller 等[5]通過使用兩種聚類算法相結合的方式對Twitter 上的用戶進行聚類分析,以識別出正常用戶和異常用戶;Beutel 等[6]設計出CopyCatch 模型,該方法通過構建出社交網絡時間矩陣,最大化TNBC 核心中的異常用戶數量,以此進行聚類,檢測出Facebook 中的異常用戶。使用無監督方法的優點是不需要對數據進行標注,也不用提前訓練,可以很方便地構建出社交網絡異常用戶檢測模型。但是,構建出的模型準確率低、算法設計復雜。
1.2 圖模型檢測方法
基于網絡連接的圖模型檢測方法主要根據異常用戶與正常用戶所具有的不同拓撲結構,一般采用無監督學習檢測方法[7]。常用的兩種檢測方法是基于譜分解的檢測方法和基于隨機游走的檢測方法[8-10]。圖模型的優點是不需要提前訓練,只需要圖數據,由于對理論假設條件要求高,因而模型準確率較低。
1.3 有監督學習的檢測方法
使用機器學習監督算法對社交網絡異常用戶進行檢測是研究者常采用的一種方式。此時的數據集含有標簽并利用這些數據集訓練出分類模型,然后使用訓練好的模型對其他未被標注的數據集進行預測。Chu 等[11]通過提取社交網絡用戶的內容、行為和屬性特征,并結合信息熵使用貝葉斯(Naive Bayesian,NB)算法構建出分類模型,該方法對異常用戶檢測的準確率較高,但是計算量大,而且該方法假設所有的屬性之間互相獨立,普適性有所欠缺。孟祥飛等[12]通過將社交網絡用戶的粉絲數量、評論數、互粉數等作為特征,使用C4.5 決策樹(Decision Tree,DT)算法構建分類模型,實現對用戶的檢測,這兩種方法在分類精度上均存在不足;袁麗欣等[13]使用XGboost 方法對特征進行選擇,構建集成分類器實現對異常用戶的檢測;徐華露等[14]使用蜜罐收集數據集,然后使用隨機森林算法對社交網絡中的僵尸用戶進行檢測;Bo 等[15]對微博數據集的內容以及用戶行為進行抽取并將其作為特征,使用支持向量機(Support Vector Machine,SVM)構建分類模型,該方法可達到較高的分類精度;王越等[16]將微博的數量、轉發率等內容特征和用戶信息特征,如粉絲數量、人體指數等作為特征,使用模擬退火算法對特征進行處理,然后用BP 神經網絡構建分類模型,通過對5 000 個測試集進行測試得到該模型準確率達93%。使用SVM 和神經網絡時算法時間復雜度較高。
對此,本文提出一種基于信息增益的KNN 社交網絡異常用戶檢測模型,首先使用信息增益特征選擇方法對數據集進行屬性約簡,選擇出重要性較高的特征屬性,去除冗余屬性,然后使用特征選擇后的數據集訓練出KNN 分類器模型,該方法有效提高了分類精確率和召回率。
2 相關概念
2.1 信息增益特征選擇
在使用機器學習方法對社交網絡中的異常用戶進行檢測時,需要其準確地發現異常行為,但是在文本數據處理過程中會產生很多冗余特征,這就需要使用特征選擇方法去除重復多余的特征,挑選出關鍵特征。當前屬性約簡算法有主成分分析(PCA)法、奇異值分解(SVD)法和信息增益(IG)等,其中PCA 和SVD 可能會損失部分重要信息。信息增益是一種過濾式特征選擇方法。數據樣本屬性特征之間的信息越多,則這些特征之間的聯系也越緊密,同時特征之間的信息增益也就越大。一般情況下,屬性特征的信息增益越大,其對分類結果的影響也越大[17]。因此,可以通過信息增益的方法確定數據集中較重要的屬性特征,并選擇信息增益大的屬性特征。此外,信息增益主要通過信息熵實現,信息熵是熵在衡量信息變量中無序度的度量。對于一個給定的數據集D,假設D 中第i類樣本所占比例為pi(i=1,2,...,|Y|),假定樣本屬性均為離散型。對于每個屬性A,假定根據其取值將D 分成了V 個子集{D1,D2,D3,...,Dv},每個子集中的樣本在A 上取值相同,則屬性A 的信息增益為:

對于任何一個離散的數據集,可以通過計算每個屬性在該數據集中的信息增益,然后根據需要選擇相應的屬性。

Fig.1 Flow of feature selection based on information gain圖1 基于信息增益的特征選擇流程
2.2 KNN 算法
K 近鄰算法(K-Nearest Neighbor,KNN)是一種常見的分類算法。其基本思想是:假設給定一個訓練數據集,其中的實例類別已定,KNN 算法通過計算待分類樣本相似度最大的K 個鄰近樣本,然后通過這K 個鄰居樣本的類別采用投票方法確定待分樣本所屬類別。這K 個實例的多數據屬于某個類,就將該實例分為這個類[18-19]。其算法如下:
輸入:訓練數據集T={(x1,y1),(x2,y2)…(xN,yN)}
其中,xi∈χ?Rn為實例的特征向量,xi∈y={c1,c2...ck}為實例類別,i=1,2,…,N;實例特征向量x;
輸出:實例x所屬的類y。
(1)根據給定的距離度量,在訓練集T 中找出與x最近鄰的k個點,涵蓋這k 個點的x的鄰域記作Nk(x);
(2)在Nk(x)中根據分類決策規則(如多數表決)決定x的類別y:
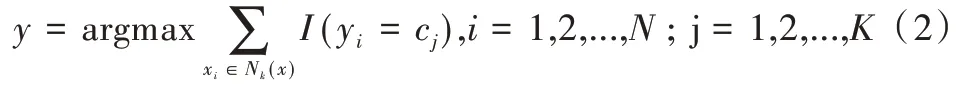
式(2)中,I 為指示函數,即當yi=cj時I 為1,否則為0。
3 檢測模型
由于社交網絡異常用戶的多類特征均與正常用戶有所區別,傳統的特征提取方法會對用戶原始數據進行提取,沒有對初始數據集的特征作約簡處理,在所保留的特征屬性中存在著很多冗余屬性。這對高維特征的檢測效果非常有限,不僅影響分類器的工作效率,同實也降低了分類器的分類精度。鑒于此,本文通過對社交網絡用戶初始數據集進行特征選擇,刪除特征集中的冗余特征。
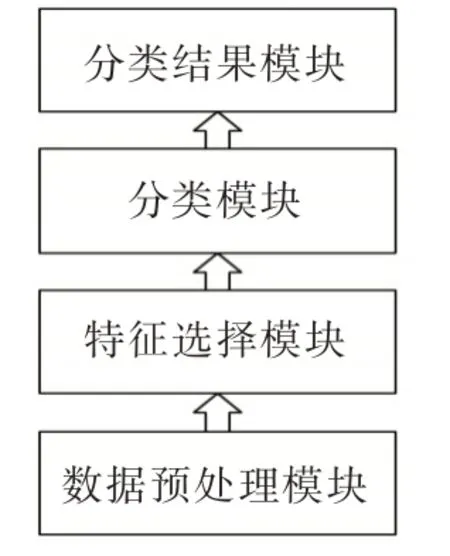
Fig.2 Classification module after feature selection圖2 特征選擇后的分類模塊
分類算法設計是文本分類全部流程中最重要的環節,分類算法的優劣,將直接影響到分類性能的高低。一方面,隨著機器學習技術的不斷發展,越來越多高精度的分類算法被提出,分類準確性越來越逼近文本的真實類別分布,當然這些復雜算法的時間開銷也很可觀;另一方面,隨著在線應用的普及,互聯網對處理算法的時間開銷要求越來越苛刻,決策樹、樸素貝葉斯等輕量級的文本分類算法,分類效率較高,但在分類準確率上的不足使它們很難適應高性能應用場景。深度學習等人工神經網絡方法和支持向量機等高準確率算法的時間復雜度較高,很難給在線應用帶來滿意的用戶體驗。KNN 算法作為一種典型的基于實例的分類方法,可以通過非常簡單的分類機制達到可媲美復雜算法的分類準確率,是社交網絡文本挖掘領域值得深入研究的算法。
信息增益特征選擇算法既可以對社交網絡用戶初始數據集進行特征降維處理,刪除數據集中的冗余屬性,避免高維特征引發噪聲,同時又能保留初始數據中的關鍵要素。因此,本文提出了一種基于信息增益的KNN 社交網絡異常用戶檢測模型,如圖3 所示。
具體步驟如下:
輸入:社交網絡用戶數據集D。
輸出:分類結果。
Step1:對原始數據集進行特征抽取。
Step2:計算數據集D 的經驗熵H(D):
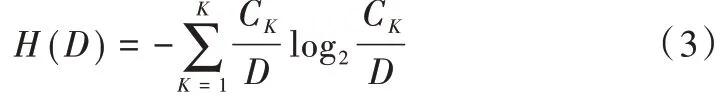
Step3:計算特征A 對數據集D 的經驗條件熵H(D|A)。
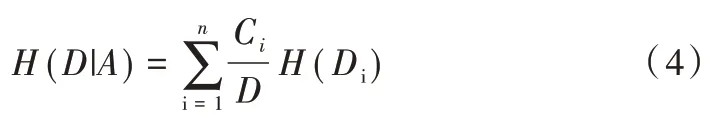
可進一步優化為:
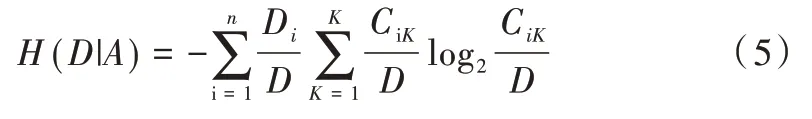
Step4:計算信息增益。
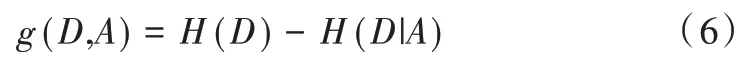
Step5:通過信息增益對數據集進行屬性約簡,確定優化后最終的特征集。
Step6:使用優化后的數據集構建KNN 分類器模型。
Step7:測試分類模型效果,得到測試結果。
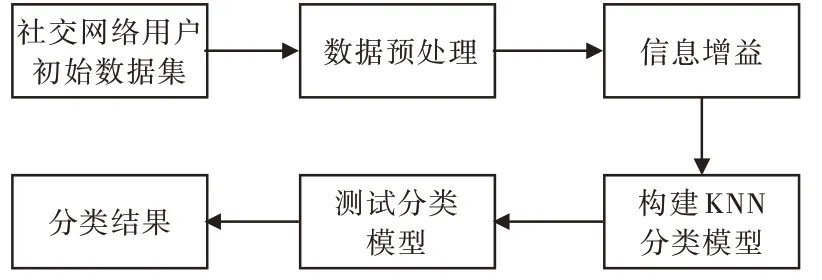
Fig.3 Information gain-based abnormal user detection model in KNN social network圖3 基于信息增益的KNN 社交網絡異常用戶檢測模型
4 實驗分析
4.1 實驗數據集
實驗過程中使用的數據集來自Apontador 數據集[20],該數據集包含了正常用戶和異常用戶,其中異常用戶又被分為3 種。表1 展示了本次實驗數據集情況,在實驗過程中將數據集分為正常用戶和異常用戶兩類,對于Apontador中的廣告發布者(LM)、內容污染者(PL)和不良言論發布者(BM)統一定義為異常用戶。
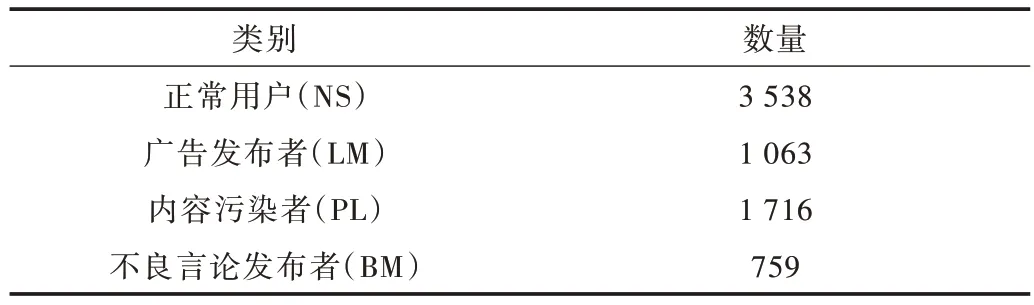
Table 1 User classification of Apontador dataset表1 Apontador 數據集用戶分類
4.2 評價指標
在使用機器學習算法構建分類模型進行二分類時,常用評價指標有準確率、召回率、F 值。對于社交網絡用戶檢測而言,在實驗過程中更希望檢測出更多的異常用戶,避免異常用戶逃避分類模型檢測,因此需要將召回率作為評價指標。同時為了所構建模型的可用性,還需考慮分類結果的準確率。為此,將分類模型的精確率和召回率作為此次實驗的評價指標。分類結果混淆矩陣如表2 所示。
其中,準確率表示為:


Table 2 Confusion matrix of classification results表2 分類結果混淆矩陣
4.3 實驗結果
實驗在開源的機器學習分析工具Weka3.9.2 環境下進行,分類結果比較如表3 所示。

Table 3 Comparison of classification results表3 分類結果比較
可以看出,使用信息增益對數據集進行特征選擇后,所構建的分類模型在分類精確度和召回率上均優于傳統的KNN 分類模型。其中,精確度由最初的91.3%上升到92.9%,提升了1.6%;召回率提升了2.3%。可以得出,本文提出的方法能夠有效提升對社交網絡異常用戶的效果。
5 結語
本文將信息增益特征選擇方法與KNN 算法相結合,提出了一種基于信息增益的KNN 社交網絡異常用戶檢測模型。該模型在對社交網絡異常用戶的檢測效果上優于傳統檢測方法,在使用機器學習算法對社交網絡異常用戶進行檢測時,需要去除數據集中的冗余屬性以達到提升分類效果的目的。
本文所構建的模型僅僅考慮了社交網絡中的常規數據集,模型魯棒性問題未予以考慮,在接下來的研究中可將多種算法相結合以構建分類模型,提升模型魯棒性,使得模型的可用性更加廣泛。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
