基于語句分類模型的《紅樓夢》作者探析
2021-04-23 05:50:22秦貴秋顧長貴
軟件導刊 2021年4期
秦貴秋,顧長貴
(上海理工大學管理學院,上海 200093)
0 引言
古往今來存在許多作者存疑的文化巨著,比如:英國著名的戲劇文學《亨利八世》被稱為莎士比亞的最后遺作,但它的實際作者卻可能不止一位[1];明清代表性小說《紅樓夢》,同樣存在作者存疑,有人認為前80 章和后40 章不是同一人所寫[2]。本文采用文本卷積神經網絡(Text Convolutional Neural Networks,TextCNN)+長短期記憶網絡(Long Short-term Memory,LSTM)的改進型語句分類模型確定《紅樓夢》前后章回的寫作風格和文體特征是否存在明顯差異。
1 相關研究
以往對《紅樓夢》作者問題的研究都是基于統計學理論方法研究的。例如,2015 年,肖天久等[3]在《〈紅樓夢〉詞和N 元文法分析》一文中,利用虛詞、詞及詞類構建的N 元文法模型、實詞以及詞長進行聚類,并計算相似度,結果發現《紅樓夢》前80 回與后40 回不為同一人所寫;2018 年,馬創新等[4]在《從高頻詞等級相關角度探析〈紅樓夢〉作者》中,將語料中的詞型均按照出現頻次遞減排列并確定等級,然后計算出各語料之間等級的相關度,以推斷各語料的語言風格相似度,發現《紅樓夢》的作者不是同一個人;2019 年,陳城鈺等[5]利用《紅樓夢》文本中虛詞的頻率構建一元線性回歸模型,通過判斷前80 回與后40 回虛詞頻率之間的差異,判斷《紅樓夢》的作者不為同一人;同年,王曄等[6]在《紅樓夢》中選取10 個特征漢字分別統計在前80 回與后40 回出現的頻次構建特征向量,利用層次聚類模型和支持向量機方法,最終證明前80 回與后40 回作者不同;2011 年,施建軍[7]利用機器學習中的支持向量機技術,在《紅樓夢》中選取了44 個虛詞并將虛詞的頻率作為特征向量,訓練支持向量機,最終對《紅樓夢》的120 回作分類,發現前80 回與后40 回存在明顯差異,因此認為《紅樓夢》為兩人撰寫;2016 年,葉雷[8]利用字典字項構建矢量特征空間,用無督導的聚類方法方法對《紅樓夢》各章回的著作權進行分析,結果表明,后40 回和第67 回與其余的章回有明顯不同,因此后40 回和第67 回可能不是原作者所寫;2018 年,王陽陽[9]利用樸素貝葉斯和BP 神經網絡分類法分析了《紅樓夢》的文本特征,發現《紅樓夢》前80 回與后40 回文本特征存在顯著差異,得出《紅樓夢》不為一人所作的結論;同年,周靖[10]在《紅樓夢》中選取100 個高頻詞匯作為文本風格的詞特征,分別利用機器學習的Bagging、Adaboost、Rotation Forest 對《紅樓夢》作者問題進行分類研究,最終發現《紅樓夢》不為同一人所著。
上述對《紅樓夢》作者的研究方法均為傳統統計學方法,統計學方法需要手動提取出有用的表示(手動特征工程),例如選擇虛詞頻率、句類特征、語言風格“數量化”等。手動特征工程是一種傳統的特征工程方法,它主要利用領域知識構建特征,一次只能產生一個特征,是一個繁瑣、片面、費時又易出錯的過程。而深度學習采用的是自動化特征工程,這也是它發展如此迅速的原因。自動化特征工程可以一次性學習所有特征,而無需自己手動設計。將深度學習方法應用在語句分類上,使得語句分類任務變得更加簡單,準確率也不斷提升。本文采用Kim[11]提出的TextCNN 語句分類模型與Minar 等[12]在其綜述提到的LSTM 相結合的方法對《紅樓夢》作者問題進行探討,有效解決傳統方法人為特征提取片面、繁瑣等不足,提高驗證和測試準確率,使研究結果更可靠。
2 語句分類模型
2.1 Word2vec
基于深度學習的語句分類模型不會接受原始文本作為輸入,它只能處理數值張量。文本向量化就是將文本轉換為數值張量以便于模型對文本的識別。文本向量化首先將文本分解成單元(單詞,字符),單元也稱之為標記,其次將數值向量與生成的標記相關聯。關聯方法有多種,如對標記進行one-hot 編碼、標記嵌入(詞嵌入)。本文采用Word2vec 詞嵌入法[13-14]。Word2vec 是從原始語料中學習字詞空間向量的預測模型,它有兩種實現模式:CBOW 和Skip-Gram,其中CBOW 是從原始語句中推測出目標詞;而Skip-Gram 相反,從目標字詞推測出原始語句,兩者都是簡單的神經網絡模型,具有一個隱藏層。實驗中所使用的詞向量是采用Skip-Gram 模型訓而練成,如圖1 所示,圖中V表示原始語句中有V 個唯一單詞,N 表示每個單詞用N 個特征表示,Skip-Gram 的輸入層是原始語句中唯一單詞的one-hot 碼,輸出層為Softmax 層,通過反向梯度傳播更新隱藏層權重,最終得到詞向量就是隱藏層的權重。
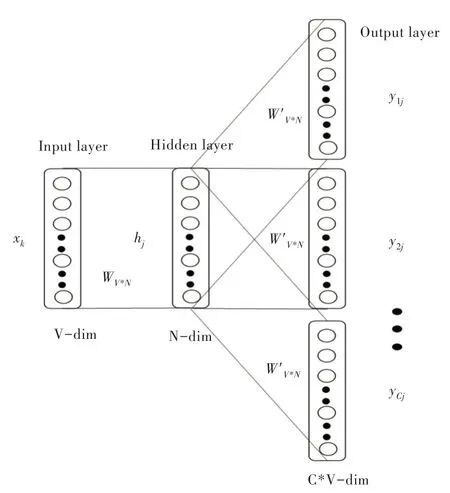
Fig.1 Model of Skip-Gram圖1 Skip-Gram 模型
2.2 TextCNN 語句分類模型
Kim 的TextCNN 語句分類模型如圖2 所示。令xi∈Rk代表句子中第i個單詞所對應的k維詞向量,一個長度為n的句子(不足的可以填充)可以表示為如式(1)所示。
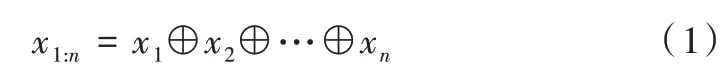
式中,⊕為拼接算子,通常讓xi:i+j表示為單詞xi,xi+1,…,xi+j的拼接。卷積運算將卷積核w∈Rhk應用到h個單詞組成的特征向量窗口產生一個新的特征。例如,特征ci是由h個單詞(xi:i+h-1)組成的特征向量窗口,通過式(2)生成,如式(2)所示。
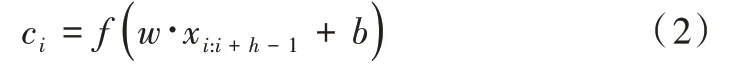
式中,b∈R是一個偏置項,f為非線性函數。將卷積核應用到句子每個可能的單詞特征向量窗口中生成一個特征向量圖c∈Rn-h+1,如式(3)所示。
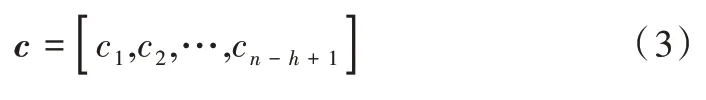
然后對得到的特征圖使用最大池化操作,得到該特定卷積核對應的特征最大值c?=max{ }c,其思想就是獲取特征圖中最重要的特征——最大特征值。
上述已經描述了從一個卷積核中提取一個特征的過程。該模型使用多個卷積核(卷積核大小各異)來獲取多個特征。這些特征經過最大池化后連接組合形成圖2 中倒數第二層,之后這些最大特征組合輸入到全連接的Softmax 層,最終輸出一組標簽的概率分布。
為了正則化,在倒數第二層采用權重向量l2范數約束的Dropout[15]。Dropout 用來防止模型過擬合,通過在前后向傳播期間隨機刪除(即設置為零)p% 的隱藏單元。因此,假設倒數第二層輸出為z=(使用了m個過濾器),對于輸出單元y而言,不采用Dropout,輸出y 如式(4)所示。

采用Dropout,輸出y如式(5)所示。

式中,°是逐元素乘法運算符,且r∈Rm是一個概率p為1 的伯努利隨機變量的掩碼向量。梯度反向傳播時不經過掩碼單元。
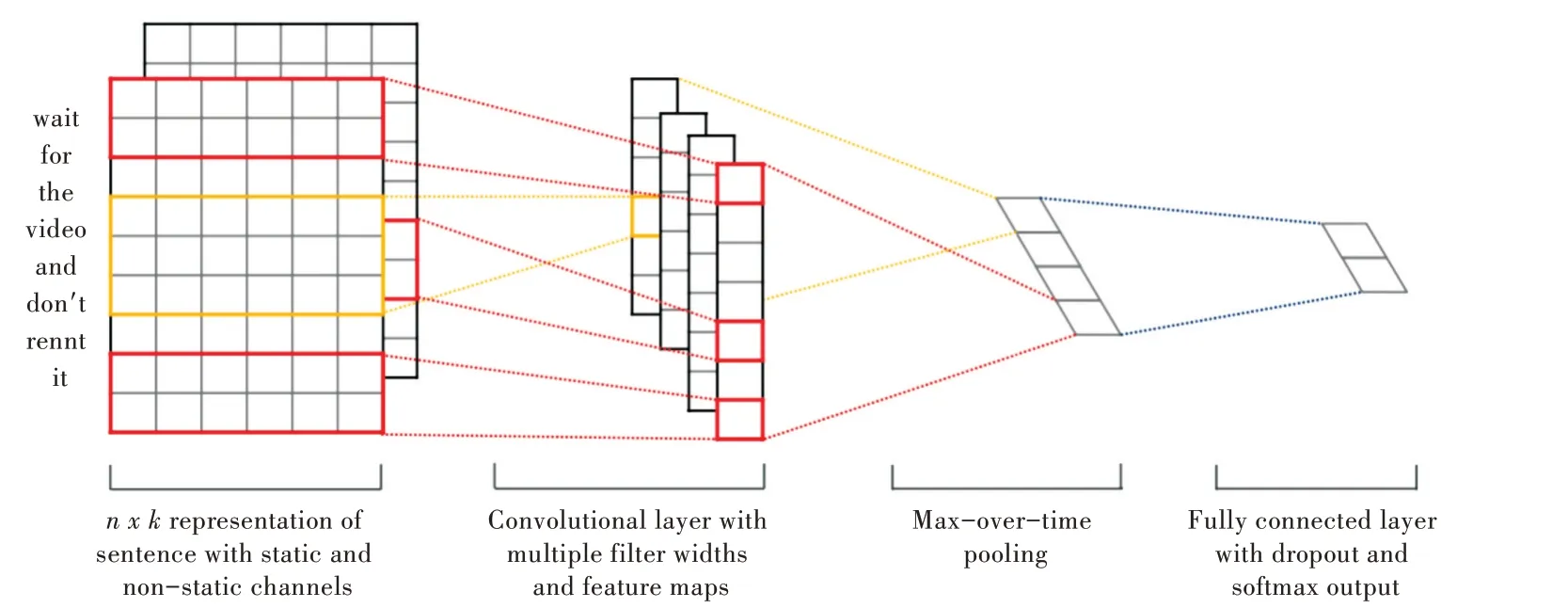
Fig.2 Kim's TextCNN statement classification model圖2 Kim 的TextCNN 語句分類模型
2.3 LSTM
循環神經網絡(Recurrent Neural Network,RNN)記憶單元無法篩選有用信息,導致無用的信息被存儲在記憶單元中,有用的信息卻被擠出去。文獻[12]中,長短期記憶網絡LSTM 是在RNN 基礎上優化而來,通過引入記憶單元和門機制,有效解決了信息篩選,以及反向梯度消失或爆炸問題。
如圖3 所示,在基本的LSTM 單元中,存在3 個門單元,分別稱為輸入門、輸出門和遺忘門。單元狀態更新實現和LSTM 輸出計算如式(6)—式(13)所示。
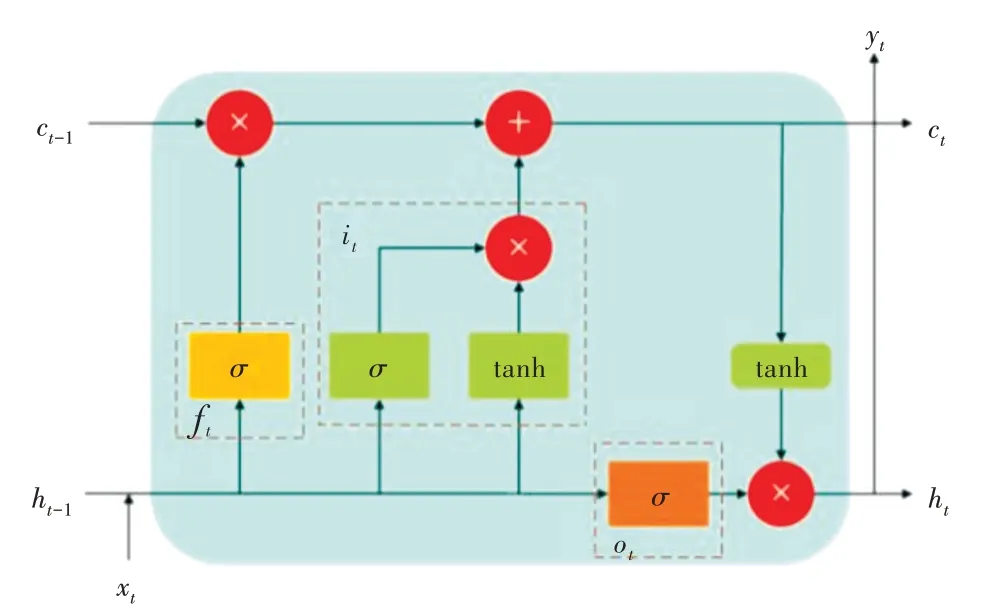
Fig.3 LSTM basic cell model圖3 LSTM 基本單元模型
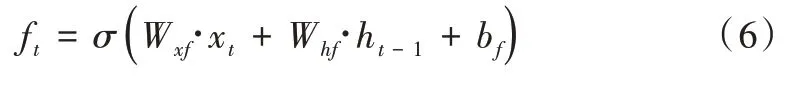
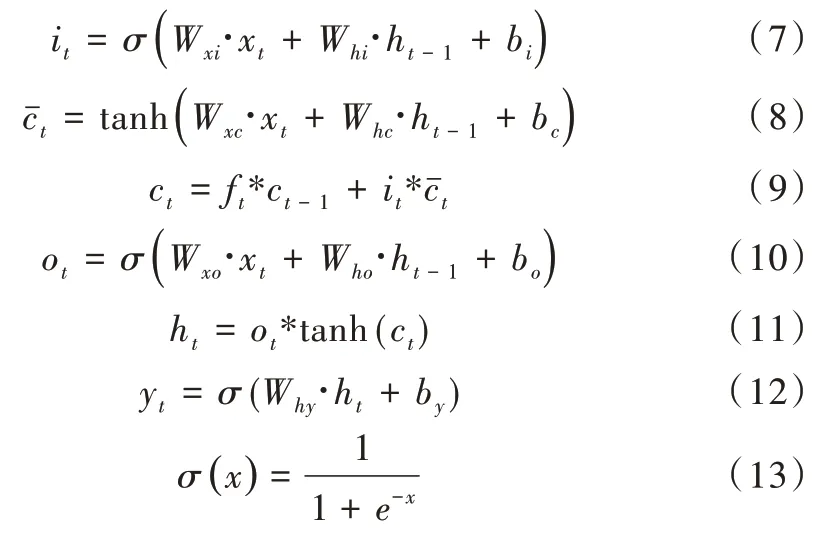
式中,ft代表遺忘門的輸出,it代表輸入門的輸出,ot代表輸出門的輸出,ht-1為上一個LSTM 單元的輸出,ct-1為上個單元的狀態信息輸入,保留了上個單元的狀態信息,σ代指Sigmoid 函數。
2.4 TextCNN+LSTM
本文將LSTM 加入到TextCNN 語句分類模型的倒數第二層后、Dropout 之前,如圖4 所示。可以認為多個不同尺寸的卷積核(窗口大小為2、3、4,漢語詞語主要由2、3、4字組成)產生的最大特征向量間也存在關聯,通過LSTM 捕捉最大特征向量之間的關聯性,提高分類準確性,最終通過模型驗證和測試準確率判斷模型優劣。準確率計算如式(14)所示。

式中,a為準確率,p為模型驗證數據集驗證正確的樣本個數,t為數據集中的樣本總數。
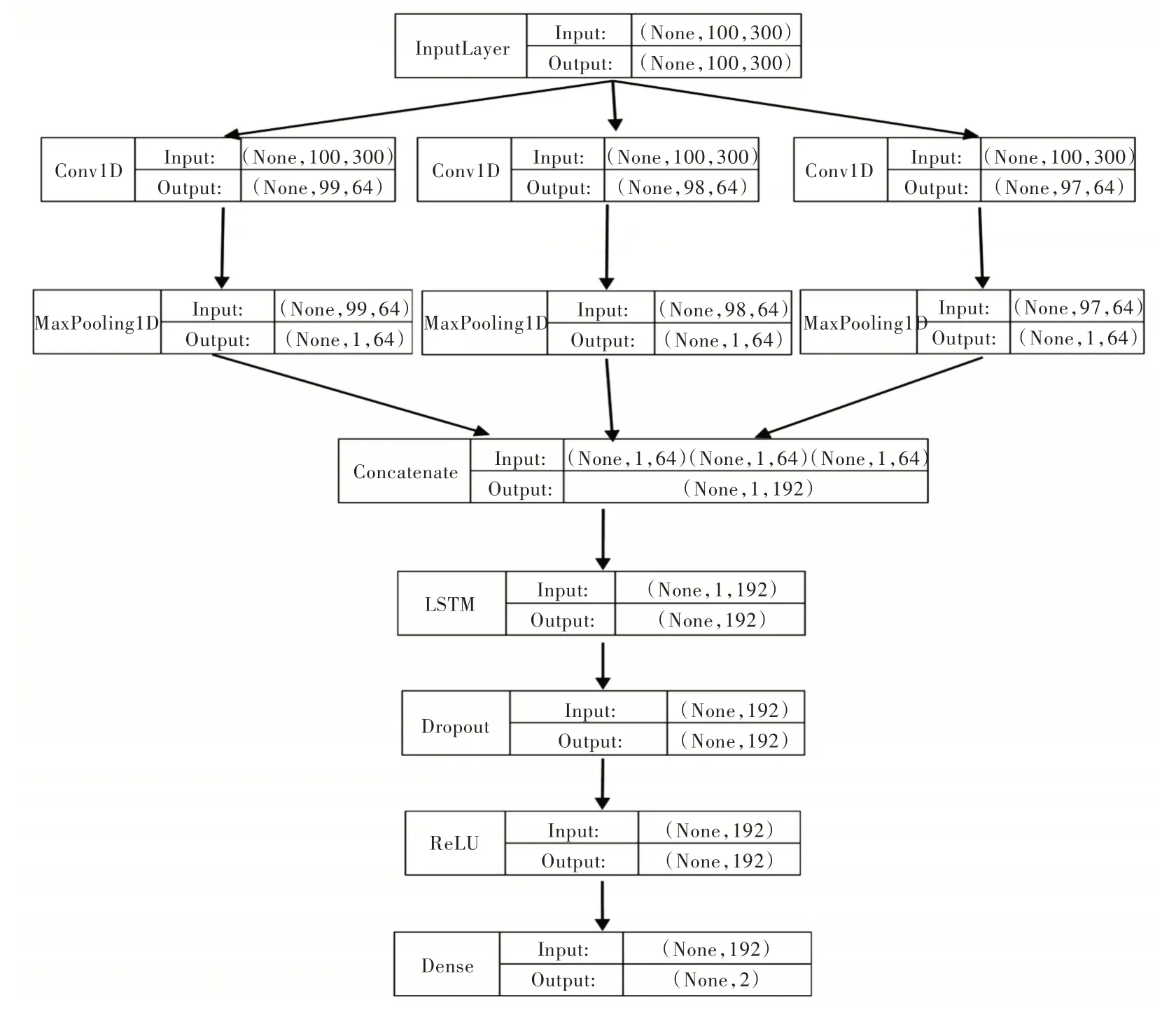
Fig.4 TextCNN+LSTM statement classification model圖4 TextCNN+LSTM 語句分類模型
3 實驗與結果分析
3.1 文本數據處理
分別對《紅樓夢》的每一章回,都以逗號、問號、分號、感嘆號為分割點進行語句分割,之后將句子以最小句子數合并成超過100 字符的長句子,例如,句子一長33,句子二長40,句子三長50,句子四長20……,將句子一、二、三合并,這是最少句子數合并。短句子在樣本少的情況下,模型并不能有效提取出不同的寫作風格和文本特征,因此將短句子合并成長句子。
為了探究《紅樓夢》作者在哪一章回出現明顯不同,為此,從第25 回開始將《紅樓夢》分割成兩個部分,前25 為樣本負例,后95 為正例。之后每隔5 章回依次將《紅樓夢》分割成前后負正例,所有分割點為25、30、35、40、45、50、55、60、65、70、75、80、85、90、95,共計15 個分割點。從分割前后部各自隨機抽取約1 200 例樣本作為訓練集,共計約2 400 個樣本。為了讓抽取的樣本均衡,從前后部每一章回都要均衡隨機抽取。例如以80 為分割點的前后部,對于前80 章采樣1 200 例,則每章隨機抽取1 200/80=15 例,后40 章每章隨機抽取1 200/40=30 例。對所有分割點的訓練集都是如此采樣,除不凈取下整。每個分割點的測試集也依次取剩余正負樣本各約250 例,共計約500例。這樣就產生了15 個不同分割點的訓練集和測試集,如圖5 所示。
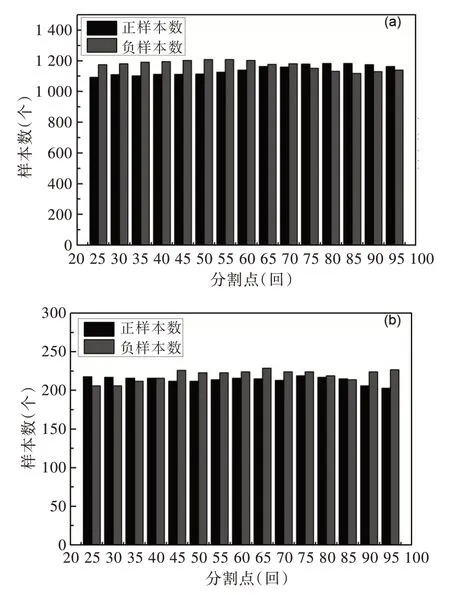
Fig.5 Sample size distribution of training set and test set圖5 訓練集與測試集樣本數分布
由于《紅樓夢》作者存在爭議,因此不采用《紅樓夢》訓練詞向量,因此文本的詞向量采用GitHub 上已處理好了的文學文本的詞向量,采用Cun 等[16]提出的Skip-Gram with Negative Sampling 法而生成,單字的向量維度為300,圖6為部分詞向量的二維可視化圖。
Fig.6 Two-dimensional visualization of word embedding圖6 詞向量二維可視化
將上述15 個訓練集輸入到TextCNN+LSTM 模型中,每個訓練集在模型中迭代20 次并且隨機選取10% 的訓練樣本作為驗證集,重復3 次,選取驗證準確率最高的作為次分割點的最優模型,訓練出15 個語句分類模型。
3.2 實驗結果分析
如圖7(a)所示,圖中橫坐標為《紅樓夢》章回的15 個分割點的取值范圍,縱坐標代指模型在數據集上的準確率,方點折線由15 個模型各自的驗證準確率連接,圓點折線由15 個模型各自的測試準確率連接。
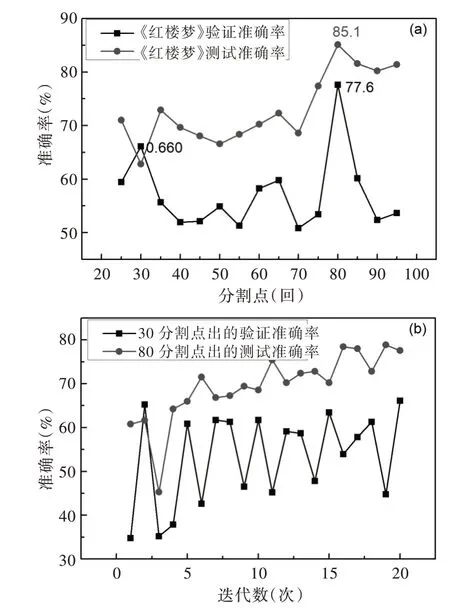
Fig.7 Comparison embedding the verification and test accuracy of A Dream of Red Mansions and the iteration verification accuracy of two segmentation points圖7 《紅樓夢》驗證和測試準確率與兩分割點迭代驗證準確率對比
從圖7(a)可以發現,無論是驗證準確度,還是測試準確度,在《紅樓夢》章回80 分割點處都取得了最大準確度值,而且明顯異于其它分割點。在方點折線中除80 分割點處的最高點外,還有一處次高點的異常值在30 分割點處。如圖7(b)所示,此圖為30 和80 分割點處的訓練集在20 次迭代中驗證準確率對比圖,圖7(b)的橫坐標為迭代值的范圍,縱坐標為驗證準確率,方點折線為30 分割點處的驗證準確率連線,圓點折線為80 分割點處的驗證準確率連線。從圖7(b)中可以發現黑色折線波動異常不穩定,而紅色折線穩步波動上升并趨于平穩,也即模型在30 分割點處并沒有學到有效的寫作風格和文本特征。因此前80 章回與后40 回在寫作風格上有著較為顯著的變化。
由于在Kim[11]的模型中加入了一層LSTM,為了檢驗加入LSTM 層對分類模型是否有改進,在不改變其他參數的情況下,將LSTM 層刪除,重新訓練15 個二分類模型。如圖8 所示,其中橫坐標為《紅樓夢》章回15 個分割點的取值,縱坐標代指模型在數據集上的準確度,正三角和倒三角點折線分別由無LSTM 層的15 個模型各自的驗證和測試準確率連接,方點和圓點折線分別由帶有LSTM 層的15 個模型各自的驗證和測試準確度連接。由圖8 可以發現,在80 分割點處兩種模型的驗證和測試準確率都取得了最大值,且同樣明顯異于其他分割點。但兩模型在80分割點處的測試準確率上,帶有LSTM 層模型的測試準確率要高于無LSTM 層模型的測試準確率3.6%。因此帶有LSTM 層模型在提取寫作風格和文本特征上要略勝一籌,具有更好的泛化能力。
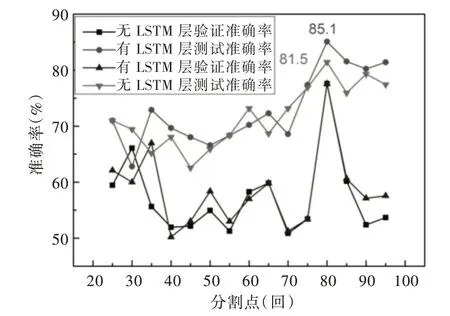
Fig.8 Accuracy comparison of models with or without LSTM layer圖8 模型有無LSTM 層準確率對比
為了驗證模型是否真的能在一本作品中提取出不同作者寫作風格,還選取了一本無作者爭異的《西游記》用來測試模型,對《西游記》用上述同樣的方法進行數據預處理。西游記只有100 章回,因此其分割點為25、30、35、40、45、50、55、60、65、70、75,共計11 個分割點。
如圖9 所示,橫坐標為章回分割點的取值范圍,縱坐標代指模型在數據集上的準確度范圍,圓點折線由《西游記》11 個模型各自的驗證準確率連接,方點折線由《紅樓夢》15 個模型各自的驗證準確率連接。《西游記》各分割點處的驗證準確度一直處于波動狀態,并不像《紅樓夢》那樣出現一個非常突出的80 章回分割點,這是由于《西游記》是由一人所寫,語句分類模型無法提取《西游記》各處分割點前后的章回中能體現出不同寫作風格的特征。因此,語句分類模型確實可以應用在一本作品中以區分作者的寫作風格。
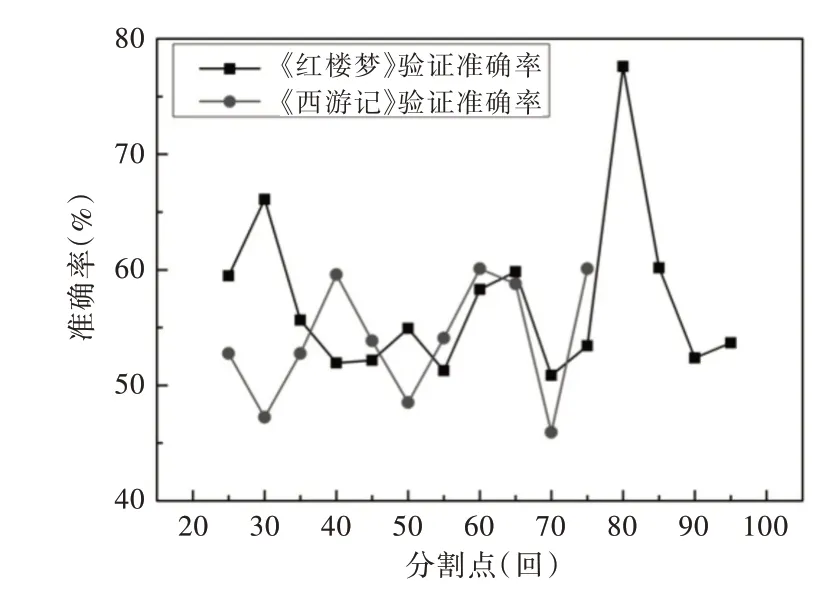
Fig.9 Verification and comparison between A Dream of Red Mansions and Journey to the West圖9 《紅樓夢》與《西游記》驗證對比
4 結語
通過運用改進型語句分類模型,自動地提取文本特征,解決了人為提取文本特征片面、繁瑣等不足。在《紅樓夢》的15 個章回分割點處分別訓練語句分類模型,通過15個模型的驗證準確度和測試準確度折線圖發現,在《紅樓夢》第80 章回分割點處的驗證準確度和測試準確度明顯高于其余分割點處的準確度,且帶有LSTM 層的語句分類模型具有更好的泛化能力,在準確度上提升了3.6%。結果表明,《紅樓夢》前80 回與后40 回在寫作風格上存在明顯差異性。換言之,《紅樓夢》的前80 回與后40 回不是同一人所寫,與大多數前人的研究結論相符合,也為佐證其它作者存疑作品提供了新的解決思路或判定方法。同時,通過該研究可以發現不同作者間的語言風格不同,該研究僅對單個漢字做了詞向量,這樣割裂開了詞語間的聯系,而且分類準確率還有待提高,今后可以引入注意力模型,同時訓練新的結合字詞的詞向量。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
