感受聲音的世界
2021-04-21 15:25:32楊磊邱元陽劉宗凡金琦倪俊杰
中國信息技術(shù)教育 2021年7期
楊磊 邱元陽 劉宗凡 金琦 倪俊杰

編者按:隨著電子計算機和人工智能機器的廣泛應(yīng)用,利用機器學習算法處理音頻信號成為現(xiàn)實。使用人工智能來檢測和分類聲音可以克服人類感知限制的影響,并充分利用機器的感知和分類能力與人類的決策能力之間的優(yōu)勢互補。本期我們將圍繞聲音分類的應(yīng)用、聲音特征提取、聲音分類處理和音頻編輯原理等話題展開討論。
主持人:
楊磊 ?天津市第五中學
嘉 ?賓:
邱元陽 ?河南省安陽縣職業(yè)中專
劉宗凡 ?廣東省四會市四會中學
金 ?琦 ?浙江師范大學附屬中學
倪俊杰 ?浙江省桐鄉(xiāng)市鳳鳴高中
聲音分類的應(yīng)用領(lǐng)域
楊磊:利用機器對采集到的聲音進行分析,從而判斷有關(guān)聲音的來源、變化等重要信息的智能聲音分析系統(tǒng)逐步走入人們的生活。隨著人工智能應(yīng)用的不斷發(fā)展與進步,依靠機器學習算法對場景、環(huán)境等進行判斷從而輔助決策、音樂檢索和語音情感分析等成為新的技術(shù)發(fā)展方向,得到了廣泛的關(guān)注。
倪俊杰:聲音事件檢測是指對采集到的聲音數(shù)據(jù)進行分類與檢測,從而對當前發(fā)生的事件或發(fā)聲的物體進行判斷,目前主要是針對特定的應(yīng)用領(lǐng)域?qū)φ鎸嵣瞽h(huán)境中的聲音事件進行分類。由于聲音是全向傳播的,相比于圖像或者視頻,基于聲音的事件檢測不會受到光線以及被遮擋等問題的影響;同時,聲音信號的采集過程簡單且存儲需求較小,計算復雜度低,因此,基于聲音的事件檢測系統(tǒng)具備體積小、功耗低、易部署等優(yōu)勢,在智慧城市、智能家居及無人駕駛等領(lǐng)域有著極為廣闊的應(yīng)用前景。聲音事件檢測主要包括單聲音事件檢測和多聲音事件檢測兩個研究方向。單聲音事件檢測用于檢測每個時間最突出的聲音事件,而多聲音事件檢測則識別場景中重疊的聲音事件以及單個聲音事件。與單聲音事件識別相比,由于多聲音事件識別的錄音在同一時間存在大量重疊聲音事件,因此,多聲音事件識別呈現(xiàn)更多挑戰(zhàn)。而現(xiàn)實生活中,由于天氣、環(huán)境等原因,聲音的出現(xiàn)往往不是單獨的,在判斷場景時也需要綜合考慮多種聲音,因此,研究中更多地關(guān)注多聲音事件檢測。
音樂流派分類是音樂信息檢索的一個重要分支,正確的音樂分類對提高音樂信息檢索的效率具有重要的意義。音樂流派是對音樂的一種描述,有多種不同的劃分方式,但是各種流派沒有確切的定義概念,常見的有流行、古典、金屬等。近年來,互聯(lián)網(wǎng)音樂曲庫容量增加,按流派檢索音樂成為音樂信息檢索的主流方法。將音樂按流派分類,能夠滿足用戶針對某種特定風格音樂檢索的需求,方便用戶對感興趣的音樂類型進行快速檢索和高效管理,同時方便音樂經(jīng)銷商管理和標注音樂類型,向用戶推薦其感興趣的音樂類型。自動且精準地進行音樂流派分類識別可以有效減少人力成本。因此,提高音樂流派分類識別準確率可以推動音樂平臺的智能化發(fā)展,為音樂聽眾提供更好的服務(wù),提升聽眾的體驗,增加聽眾的選擇,這些都具有巨大的研究價值和經(jīng)濟價值。目前,音樂分類主要包括文本分類和基于作者、年代、音樂名稱等標注的文本信息分類。后一種分類方式的優(yōu)點是易于實現(xiàn)、操作簡單、檢索速度快,但缺陷也很明顯,它依賴于人工標注的音樂數(shù)據(jù),需要耗費大量的人力,并且人工標注很難避免音樂信息標注錯誤的問題。同時,這種文本分類方式并沒有涉及音樂本身的音頻數(shù)據(jù),音頻數(shù)據(jù)包括音樂的很多關(guān)鍵特性,如音高、音色、旋律和音調(diào)等,這些特性用文本是無法標注的;而基于內(nèi)容的分類正是對音樂的原始數(shù)據(jù)進行特征提取,用提取的特征數(shù)據(jù)訓練分類器,從而達到音樂分類的目的。因此,人工音樂流派分類逐漸被自動音樂流派分類取代,自動音樂流派分類主要依據(jù)提取特征,訓練分類器對音頻信號進行流派分類。基于內(nèi)容的音樂分類也成為近年來研究的熱點。
語音情感識別主要是通過識別說話人當下的情緒來調(diào)整系統(tǒng)響應(yīng),它通常采用計算機系統(tǒng)作為情感信息的傳遞和處理媒介,使計算機能夠正確理解和應(yīng)用人類的情感信息。情感的理解對人與人之間的交互質(zhì)量至關(guān)重要,只有敏銳地把握交互對象的情感狀態(tài)才可能理解對方表達的真正含義并做出正確的應(yīng)對,進而獲得高質(zhì)量的溝通。交互過程中的情感可通過面部表情的變化、語音表述的語氣與措辭、身體行為的反應(yīng)、心理變化所產(chǎn)生的生理體征的波動等多種途徑表達。不同情感的表現(xiàn)往往具有相似性,即便是對具備復雜智慧系統(tǒng)的人類而言,精確判斷說話人的情感狀態(tài)也并非易事。這些問題引起了人們從心理學與生理學角度對情感進行分析與研究的興趣。信息技術(shù)的發(fā)展極大地增強了人類和計算機之間的聯(lián)系,推動了人工智能技術(shù)的進步。在計算機具備越來越高的推理能力和學習能力的同時,如何使計算機具有情感能力來構(gòu)建更為和諧自然的人機交互環(huán)境變得越來越重要。在人機交互技術(shù)的發(fā)展中,情感交互是人機交互更高級的階段。傳統(tǒng)的人機交互主要通過鍵盤、鼠標、屏幕等方式進行,只追求便利和準確,無法理解和適應(yīng)人的情緒或心境。如果計算機缺乏情感理解和表達能力,就很難期望人機交互達到真正的和諧與自然。語音情感分類綜合包括了情感機理的研究、情感信號的獲取、情感信號的分析與識別等內(nèi)容,作為一個交叉學科,這是一個不斷成長、快速發(fā)展的研究領(lǐng)域。
邱元陽:在生物識別技術(shù)專題中,我們提到過聲紋識別技術(shù),即依靠每個人發(fā)音的獨特個性特點來準確識別發(fā)音者。人的發(fā)聲器官的各個組成部分的形態(tài)和物理特點各不相同,如果用電聲學儀器記錄下發(fā)音者語言信息的聲波頻譜,會發(fā)現(xiàn)每個人的聲紋圖譜都有差異,但又有相對穩(wěn)定性,這就使得聲紋具有生物識別的基礎(chǔ)和價值。聲紋識別的可能性來自人對聲音辨識的實踐感受。對于熟悉的人來說,他不需要看到說話人,就能準確地判斷說話人是誰,這就為聲紋識別提供了可能。從物理學的角度來看,不同的人說話聲音之所以不同,是因為聲音的頻率和音色等各不相同。尤其是音色,因為有豐富的泛音和諧波,可以形成千萬種各不相同的音色,不同的樂器具有不同的音色,不同的人聲也具有不同的音色。但在實際的聲音特征采集中,會考慮到非常多的個性化特征,如聲學層面的頻譜、倒頻譜、共振峰等,解剖學層面的鼻音、呼吸音、沙啞音,以及生物學和心理學層面的韻律、節(jié)奏、速度、語調(diào)、音量,甚至社會學層面的方言、修辭、發(fā)音、言語習慣等。由此可見,聲紋識別與語音識別完全不同,后者考慮的是概括出共性的識別,前者考慮的是區(qū)別出個性的識別。聲紋識別的優(yōu)勢主要有語音獲取方便、識別成本低廉、使用簡單等。這些優(yōu)勢使得聲紋識別的應(yīng)用越來越廣,成為僅次于指紋和掌紋的生物特征識別。目前,在信息、銀行證券系統(tǒng)、公安司法等領(lǐng)域能應(yīng)用聲紋識別。但是聲紋識別也有缺陷,如身體狀況和情緒造成的聲紋特征變化、采集設(shè)備和信道對識別性能的影響、環(huán)境噪聲對識別的干擾、多人說話場景下的說話人識別(誰在說話)和說話人辨認(是誰的話)難度較大等,這些缺陷都會影響識別的結(jié)果。聲紋識別技術(shù)還需要進一步發(fā)展和完善。
聲音數(shù)據(jù)集與特征提取庫介紹
楊磊:算法、數(shù)據(jù)、算力是人工智能底層的三要素。深度學習算法本身是建構(gòu)在大樣本數(shù)據(jù)基礎(chǔ)上的,而且數(shù)據(jù)越多,數(shù)據(jù)質(zhì)量越好,算法結(jié)果表現(xiàn)越好。這意味著對數(shù)據(jù)的需求將會持續(xù)增加,尤其對細分場景數(shù)據(jù)的獲取和標注難度不斷增高。那么,聲音分類領(lǐng)域有哪些公開的數(shù)據(jù)集呢?
劉宗凡:環(huán)境聲音分類數(shù)據(jù)集(ESC)是在一個統(tǒng)一的格式下提供短環(huán)境記錄的集合(5秒長的片段,44.1千赫)。所有剪輯均摘自Freesound.org項目提供的公共現(xiàn)場記錄。根據(jù)知識共享許可條款,可以使用該數(shù)據(jù)集。該數(shù)據(jù)集包括三個子部分:①ESC-50。帶有標簽的2000個環(huán)境聲音記錄集,包含50個聲音類別,每一類別含有40個剪輯。②ESC-10。帶有標簽的400個環(huán)境聲音記錄集,包含10個聲音類別,每一類別有40個剪輯,它實際上是ESC-50的子集,最初創(chuàng)建為概念證明/標準化選擇的簡單記錄。③ESC-US。250000個不帶有標簽的環(huán)境聲音記錄(5秒長的剪輯)數(shù)據(jù)集,它適用于無監(jiān)督的預訓練。ESC-US數(shù)據(jù)集雖然沒有人為手動標注,但它包含一些原始用戶上傳音樂時提交的有關(guān)音樂流派的信息標簽,這些標簽可能會用于弱監(jiān)督學習(嘈雜和/或丟失標簽)。ESC-10和ESC-50數(shù)據(jù)集中的所有數(shù)據(jù)已被劃分到五個大小均一的文件中,而且從同一原始聲音源中提取的剪輯始終被安排放在同一個文件中。
GTZAN數(shù)據(jù)集是音樂流派分類的一個實驗樣本庫,它包含10個音樂類型,即布魯斯、古典、鄉(xiāng)村、迪斯科、嘻哈、爵士、雷鬼、搖滾、金屬和流行音樂,共計1000條音頻文件,它們是采樣頻率為22.05kHz、16bit單聲道、時長為30s的音頻文件。音頻是在2000—2001年從各種來源收集的,包括個人CD、收音機、麥克風錄音等,可以反映各種錄音條件。
CASIA漢語情感語料庫由中國科學院自動化所在純凈的錄音環(huán)境下選取錄音人男聲、女聲各兩人,每人按照不同的情感朗讀文本2500句,共9600句,以16khz采樣率、16bit、pcm格式存儲。錄制四個專業(yè)發(fā)音人的音頻文件(有相同文本和不同文本)。通常選取7200條發(fā)音文件,其中每個人的每一種情感的300條是相同文本,也就是說對相同的文本賦予不同的情感來閱讀,用來對比分析相同話語在不同情感狀態(tài)下的聲學特征以及韻律表現(xiàn)。其中每個人都包含六種不同的情緒情感狀態(tài):生氣、害怕、快樂、中性、悲傷和驚訝。
另外,還有百萬歌曲數(shù)據(jù)集、AudioSet等大型的聲音數(shù)據(jù)集,這些聲音數(shù)據(jù)集為深度神經(jīng)網(wǎng)絡(luò)模型的訓練提供了數(shù)據(jù)支持,使得訓練出有效的網(wǎng)絡(luò)成為可能。
楊磊:數(shù)據(jù)集中包含的數(shù)據(jù)都是音頻原始數(shù)據(jù),而音頻所包含的數(shù)據(jù)信息太多,一般無法直接將原始數(shù)據(jù)作為訓練數(shù)據(jù)使用。因此,從音頻數(shù)據(jù)中提取出具有代表性的音樂特征成為必要手段。那么,是否有這方面的相關(guān)工具可以使用呢?
金琦:在聲音信號處理領(lǐng)域中,一些現(xiàn)有程序可用于聲音信號特征參數(shù)的提取。下面給出幾種常用的語音特征參數(shù)提取工具:①openSMILE是一個可用于語音信號處理的特征提取器,且具有高度模塊化和靈活性等特點。它是一款以命令行形式運行的工具,通過配置config文件,主要用于提取音頻特征,下載網(wǎng)址:http://audeering.com/technology/opensmile/。②VOICEBOX是一個語音處理工具箱,它由英國倫敦帝國理工學院電氣與電子工程系的Mike Brookes維護并編寫,工具箱包含了MATLAB環(huán)境下語音處理的常用函數(shù),下載網(wǎng)址http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html。③Praat是一款跨平臺的多功能語音學專業(yè)軟件,主要用于對數(shù)字化的語音信號進行分析、標注、處理及合成等實驗,同時生成各種語圖和文字報表。下載網(wǎng)址:http://www.fon.hum.uva.nl/praat/。
當然,除應(yīng)用軟件和工具箱外,Python也有一些很好用的音頻處理庫,如Librosa和PyAudio。另外,還有一些基本的音頻功能的內(nèi)置模塊。下面筆者以Librosa庫為例演示提取音頻信號梅爾聲譜圖的過程。提取過程如上頁圖1所示。
步驟1:安裝,代碼如上頁圖2所示。
步驟2:導入音頻文件并顯示,如上頁圖3所示,代碼如上頁圖4所示。
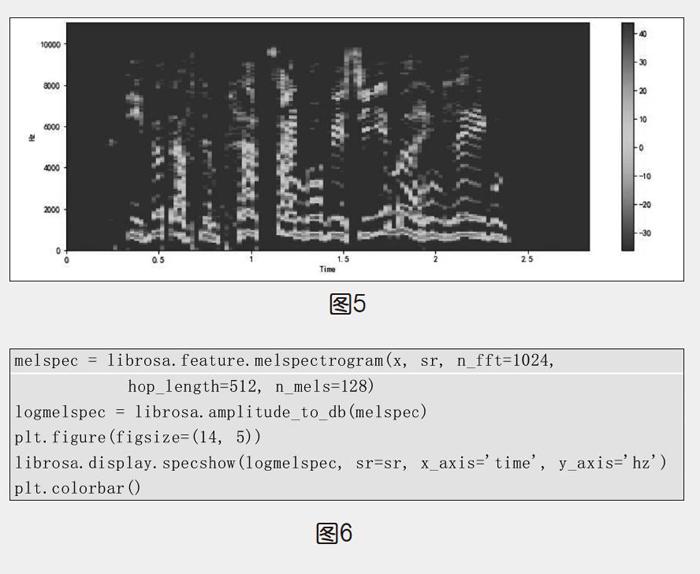
步驟3:提取并顯示梅爾聲譜圖,如圖5所示,代碼如圖6所示。
以上演示表明,盡管提取梅爾聲譜圖的原理和過程相對復雜,但是利用Librosa庫提取非常方便,每個庫函數(shù)都有一些參數(shù)設(shè)置,這需要查看相關(guān)文檔。
人工智能算法實現(xiàn)
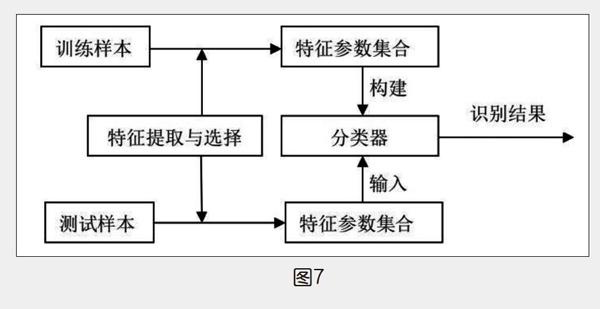
楊磊:基于人工智能算法的聲音分類系統(tǒng)由三個基本部分組成:信號預處理、特征提取和分類。首先進行聲音預處理,如去噪和分割,以確定信號的有意義的單元;然后進行特征提取,用于識別信號中可用的相關(guān)特征;最后將提取的特征向量通過分類器進行分類處理。用于聲音分類的簡化系統(tǒng)如圖7所示。在基于聲音的信號處理的第一階段,進行聲音增強,去除噪聲成分。第二階段包括兩個部分,即特征提取和特征選擇。從預處理的信號中提取所需的特征,并從所提取的特征中進行選擇,這種特征提取和選擇通常基于時域和頻域中語音信號的分析。在第三階段,各種分類器,如神經(jīng)網(wǎng)絡(luò)、支持向量機、決策樹等被用來對這些特征進行分類。
下面,利用tensorflow2.0和UrbanSound8K數(shù)據(jù)集簡單介紹一下利用卷積神經(jīng)網(wǎng)絡(luò)實現(xiàn)環(huán)境音分類的過程。利用Librosa庫提取梅爾聲譜圖,得到特征矩陣(64,174,1),如下頁圖8所示。
卷積神經(jīng)網(wǎng)絡(luò)在1984年由日本學者Fukushima提出,現(xiàn)在已經(jīng)被廣泛應(yīng)用于圖像處理和聲音處理等領(lǐng)域,并取得了突破性的成果。卷積神經(jīng)網(wǎng)絡(luò)主要有兩個特點:局部感知和權(quán)值共享。利用卷積操作進行局部感知,接收響應(yīng)后得到特征圖,所得特征圖共享卷積核參數(shù)。多次卷積后,感受視野擴大,逐步形成全局特性,進而成為高層表達。卷積神經(jīng)網(wǎng)絡(luò)一般包含卷積層、池化層和全連接層。卷積層和池化層用于輸入和提取特征,全連接層用于將特征映射到維度空間中。利用Tensorflow2.0可以方便地構(gòu)建卷積神經(jīng)網(wǎng)絡(luò),大大降低了深度學習的實踐門檻。上頁圖9所示為卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。本實例的參數(shù)設(shè)置如下:Dropout參數(shù)為0.2,激活函數(shù)為Relu,優(yōu)化器為Adam,批量數(shù)為256,迭代次數(shù)為200。構(gòu)建網(wǎng)絡(luò)代碼如上頁圖10所示。
訓練過程中訓練集的準確率和測試集上的準確率隨迭代次數(shù)的變化如上頁圖11所示。
最終利用混淆矩陣查看各個類別的訓練效果,如圖12所示。
音頻編輯的原理和難度
邱元陽:音頻的編輯比較特殊,在聲音的處理上,我們無法做到隨心所欲。
音頻的編輯不同于圖像和視頻,因為圖像和視頻本身是可以看到的,進行可視化操作是理所當然的,而聲音是不可見的,需要將用耳朵感受的現(xiàn)象變成可視化的操作,這樣就使難度大了很多。在音頻編輯軟件中可以很方便地添加音效,對聲音進行合成、疊加,粗略地去除音樂中的人聲,甚至通過不同的聲道來形成環(huán)繞立體聲。在AI的加持下,Adobe的音頻編輯已經(jīng)能做到直接修改語音內(nèi)容。但是很基本的聲音操作,我們往往無法實現(xiàn),如可視化地對聲音本身進行編輯修改、對每個聲音元素進行單獨處理、剔除混亂場景中的某種聲音、提取需要的聲音元素等。
視頻的編輯難度也會大于圖像編輯,但是因為視頻可以看作圖像在時間軸上的排列,復雜和很難完成的處理至少還有對逐幀圖片進行編輯的可能。音頻雖然也是各種聲音元素在時間軸上的排列,卻無法逐幀處理。因為我們對聲音的認識還有所欠缺,對聲音的直觀可視表達還無能為力。目前對聲音的物理學認識還停留在聲音三要素即響度、音調(diào)和音色層面,對聲音的可視化表達還停留在“波形”上。因此,音頻編輯的界面往往就是波形的顯示和編輯。
圖像是通過視覺經(jīng)視網(wǎng)膜轉(zhuǎn)換后在大腦形成的映像,而聲音則是通過聽覺經(jīng)鼓膜傳遞給聽覺神經(jīng)在大腦形成的映像。不同的人和不同的動物,對聲音的辨別都有差異,如海豚和蝙蝠能感受到超聲波,老鼠能感受到次聲波,而人卻感覺不到。
聲音三要素中的響度一般認為取決于聲波的振幅,音調(diào)取決于聲波的頻率,但這些感受是主觀的,實際上與物理原理相差較大。例如,音調(diào)主要由聲音的頻率決定,但同時也與聲音強度有關(guān)。對一定強度的純音,音調(diào)隨頻率的升降而升降;對一定頻率的純音,2000Hz以下低頻純音的音調(diào)隨聲強增加而下降,3000Hz以上高頻純音的音調(diào)卻隨強度增加而上升。
最終人耳感覺到的聲音是否好聽,還取決于音色,即音頻的泛音或諧波成分。相對于某一頻段的音高是否具有一定的強度,在頻率范圍內(nèi)的同一音量下各頻點的幅度是否均衡飽滿、頻率響應(yīng)曲線是否平直、音準是否穩(wěn)定、頻率的畸變和相移是否明顯、泛音是否適中、諧波是否豐富等,都決定了聲音是否優(yōu)美動聽。
有這么多的物理特性之外的生理感覺,使得聲音效果的控制和處理難度更大,而在聲音處理之前,還要對聲音進行數(shù)字化,又涉及各種采樣、量化和壓縮處理。音頻的量化過程就是將聲音數(shù)字化,也就是模擬音頻的數(shù)字化過程,包括采樣、量化、編碼等。
因為聲音具有時間延續(xù)性,音頻編輯也需要在時間軸上進行。自然的聲音是連續(xù)的,數(shù)字化的聲音則是離散的,這就需要確定間隔多少時間采樣,即采樣頻率。采樣頻率越高越能真實地反映音頻信號隨時間的變化,聲音的還原就越真實越自然,但存儲體積也越大。為了復原波形,一次振動中必須有2個點的采樣,人耳能夠感覺到的最高頻率為20kHz,因此要滿足人耳的聽覺要求,則需要至少每秒進行40k次采樣,即40kHz的采樣率,因此,CD的采樣率確定為44.1kHz。一般8000Hz可用于電話通話,11025Hz能用于AM調(diào)幅廣播,而22050Hz和24000HZ用于FM調(diào)頻廣播,44100Hz是CD音質(zhì),48000Hz則是更加高精的高清晰音質(zhì),一些藍光音軌甚至采用了96000Hz或192000Hz的高采樣頻率。音頻編輯軟件在處理不同采樣頻率的素材時,往往需要先進行采樣頻率統(tǒng)一。
除了在時間軸上采樣,還需要量化音頻信號的幅度變化,即位深或位寬。量化位數(shù)越多,越能細化音頻信號的幅度變化。量化之后,還需要編碼,也就是按一定格式記錄采樣和量化后的數(shù)據(jù)。對記錄音頻的文件進行播放,就是解碼的過程,音頻編輯軟件還要識別和適應(yīng)不同的編碼。為了更好地跟傳輸線路匹配,編碼之后的數(shù)據(jù)會用音頻碼率的形式來描述所需要的最低傳輸速度,這就是碼率,也就是1秒內(nèi)編碼或傳輸?shù)囊纛l數(shù)據(jù)量。采樣率、位寬、聲道數(shù)相乘,就得到碼率。
音頻數(shù)據(jù)本身是流式的,沒有明確的“幀”概念,在音頻編輯軟件中為了方便,一般取2.5ms~60ms為單位的數(shù)據(jù)量為一幀音頻。所以,音頻的幀跟視頻的幀不同,也不像視頻幀那樣可以單幀編輯。
像視頻處理一樣,處理好的音頻在存儲時也需要壓縮體積。當一個頻率的聲音能量小于某個閾值(最小可聞閾)時,人耳就聽不到,這就是信號的掩蔽效應(yīng)。而當能量較大的聲音出現(xiàn)時,其頻率附近的閾值會提高很多,即頻域掩蔽效應(yīng)。如果強音信號和弱音信號同時出現(xiàn),也會發(fā)生掩蔽效應(yīng),即時域掩蔽效應(yīng)。這些特點就是聲音壓縮的原理和依據(jù)。
在音頻處理中,根據(jù)噪聲的特點,可以用濾波器進行過濾,達到回聲消除(AEC)、噪聲抑制(ANS)等目的。將聲音的時域信號轉(zhuǎn)成頻域信號進行分析,從頻域的角度看,濾波器就是刪除一些不需要的頻率,達到過濾效果。在自然聲音中,當眾人同時講話時,采集進來的語音信號就包含了遠端的回聲和近端的語音,兩者混合在一起,出現(xiàn)回聲,就會有漏尾和切字,這個回聲的消除就十分困難,因為既要保護近端的語音信號,又要盡量把混合進來的遠端回聲消除干凈。音頻編輯軟件一般會根據(jù)參考信號與遠端回聲信號的相關(guān)性,盡量將遠端回聲信號進行消除(線性處理),同時根據(jù)殘留量進行殘留回聲抑制和剪切(非線性處理)。當環(huán)境噪音太大時,可以對帶噪語音進行VAD判斷、噪聲估計,用維納濾波達到降噪效果。
所以,音頻編輯中涉及非常多的因素,而且很多是非線性的,處理起來難度很大,甚至很多基本元素都不能分離處理。而我們覺得比較神奇的部分,如變聲、立體聲,處理和實現(xiàn)起來反而比較簡單。變聲(語音變調(diào)),簡單地提高主要頻率,就是升調(diào)。因為一段聲音實際上就是多種頻率正弦聲波的疊加。男女聲的變化則還要考慮音色。混響更簡單,可以使原始聲音波形的輸入產(chǎn)生多個延遲波形(模擬反彈),再把多個延遲波形和原始的波形進行疊加,產(chǎn)生最終有混響效果的聲音波形。延遲波形的個數(shù)越多,疊加產(chǎn)生的聲音波形越豐滿,產(chǎn)生層次感、空間感,混響的效果也越好。
3D立體聲的實現(xiàn),是增加了聲音的方位,通過聲音辨別出方位,從而增強聲音的空間感。在音頻處理算法上,可以通過頭部相關(guān)傳輸函數(shù)HRTF使用人耳和人腦的頻率振動預知來合成3D音效。具體來說,人的大腦分辨聲源的方向是通過ITD(兩耳時間延遲量差)和IAD(兩耳音量大小差)來達到的。但是ITD和IAD不能描述聲源從正前方和正后方傳來的區(qū)別,人的耳朵卻能。這個問題是由耳廓來解決的:聲波遇到耳廓會反彈,經(jīng)過反彈之后,它們在鼓膜上產(chǎn)生了不同的頻率振動。正是因為耳廓的存在,才造成了從前面和從后面?zhèn)鱽淼穆曇艚厝徊煌K裕瑢崿F(xiàn)立體聲還要加上耳廓頻率振動這一變量。通過ITD、IAD和耳廓頻率振動這三個特征量,就可以合成3D音效了。把這三個元素作為頭部相關(guān)傳輸函數(shù)(HRTF)的參數(shù)進行處理,對于音頻編輯軟件來說就不是難事了。
結(jié)語
希望本期討論可以讓讀者朋友們了解人工智能算法如何處理簡單的聲音分類任務(wù),感受聲音的世界。聲音作為傳遞信息的媒介,依然有很多待挖掘的潛力。隨著人工智能領(lǐng)域不斷突破瓶頸,相信會有越來越多的應(yīng)用走進我們的生活,智慧生活值得期待。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
中國生殖健康(2020年5期)2021-01-18 02:59:48
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
電子制作(2018年11期)2018-08-04 03:25:42
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
