多源期刊元數據匯聚研究*——以世界衛生組織西太平洋地區醫學索引為例
2021-04-19 14:33:58王蕾方安楊雨生范云滿王茜
數字圖書館論壇 2021年1期
關鍵詞:內容
王蕾 方安 楊雨生 范云滿 王茜
技術與應用
多源期刊元數據匯聚研究*——以世界衛生組織西太平洋地區醫學索引為例
王蕾 方安 楊雨生 范云滿 王茜
(中國醫學科學院醫學信息研究所,北京 100020)
基于世界衛生組織西太平洋地區醫學索引(WPRIM)開發建設過程中數據資源的現狀和期刊元數據匯聚面臨的問題,從期刊文獻數據源遴選、元數據標簽映射、內容著錄規范化、非結構化數據轉換4個維度設計多源數據匯聚方案。結果表明,面向WPRIM的多源期刊元數據匯聚框架能夠較好地解決多源期刊數據匯聚問題,可為類似場景提供方案參考。
數據匯聚;多源數據;西太平洋地區醫學索引;多源異構
如何快速整合分散于各國尤其是發展中國家的專業領域文獻[1],消除各國資源之間的信息孤島,建立開放服務的資源共享機制[2],是走向數據融合和知識融合的關鍵問題,也是當前世界衛生組織西太平洋地區醫學索引(WHO Western Pacific Region Index Medicus,WPRIM)面臨的主要挑戰。本文以中國醫學科學院醫學信息研究所開發并建設的WPRIM[3]為例,探索各國數據來源復雜、元數據標準不同、數據著錄水平參差不齊、結構化程度不一致背景下多國醫學領域文獻的匯聚策略與方法,總結多源期刊匯聚過程中的優勢與不足,以期提供高質量的索引服務,為相關機構開展多國、多源專業文獻數據匯聚提供方案參考。
1 WPRIM面臨的現狀與挑戰
1.1 現狀
截至2020年底,WPRIM收錄了包括中國、日本、韓國、蒙古、菲律賓、馬來西亞、新加坡、老撾、越南、斐濟、文萊、巴布亞新幾內亞等國家出版的西太平洋地區科技期刊論文、灰色文獻等生物醫學領域文獻資源,其中生物醫學期刊665種。匯聚對象來源方面,WPRIM收錄期刊的數據來源包括期刊編輯部和第三方數據平臺兩類。來自編輯部的數據一般通過人工錄入或上傳可擴展標記語言(XML)文件的方式進行數據匯交;來自第三方數據平臺(包括韓國KoreaMed、日本科學技術信息集成系統(J-STAGE)、美國PubMed等)的數據由WPRIM平臺統一管理采集。匯聚對象元數據標準方面,編輯部提供的結構化數據主要采用JATS[4-7]作為元數據標準;第三方數據平臺提供的數據采用KoreaMed標簽集、J-STAGE標簽集以及JATS等元數據標準。匯聚對象結構化程度方面,WPRIM元數據對象包括結構化[8-10]期刊數據、非結構化期刊數據與半結構化期刊數據。結構化期刊數據一般保存在XML文件中并進行數據傳輸,如期刊匯交XML格式的數據文件至WPRIM數據管理平臺。非結構化數據通過TXT或HTML格式的文本文件進行數據交換,如部分編輯部提供方正書版導出的文本形式的數據進行數據匯交。半結構化數據是介于結構化數據與非結構化數據之間的一種數據對象,主要存在于XML文件或接口采集的成果中。
1.2 挑戰
1.2.1 同一期刊存在多個數據來源
部分WPRIM收錄的期刊存在同一期刊數據來源多樣的情況,即同一本期刊被多個數據庫收錄或存在編輯部和第三方檢索平臺都能提供題錄數據的情況。如(ISSN:0037-5675)同時被PubMed、Web of Science、Embase等數據庫收錄,同時該刊物的編輯部也能夠提供題錄數據。如果同時獲取不同來源的期刊數據,就會造成數據重復的問題,增加數據管理的復雜度。
1.2.2 不同數據源的元數據標簽不一致
WPRIM來源數據有多種元數據標準,存在作者、語種、時間等元數據與WPRIM元數據標準命名或含義不一致的情況。元數據項命名包括同名和不同名兩種情況,如JATS中的名字標簽(NAME)的姓名類型(NAME-STYLE)為西文的姓標簽(SURNAME),與WPRIM的姓標簽(LASTNAME)不同名。元數據標簽含義包括同義、近義、不同義3種情況,如J-STAGE標簽集中作者(AUTHORS)與WPRIM元數據中姓(LASTNAME)、名(FIRSTNAME)標簽名稱近義。
1.2.3 不同數據源著錄標準不同
WPRIM收錄期刊的各個數據源著錄標準不一致,作者、刊名、語種、時間、卷期元數據項存在全稱與簡稱、語種等著錄形式的差異。以刊名為例,在KoreaMed數據源中著錄為簡稱J Breast Dis,而非期刊全稱。以語種為例,,期刊文獻的語種在PubMed數據源中著錄為eng,而WPRIM元數據著錄標準要求著錄為English。如果只開展元數據標簽項的融合,則會出現內容不一致的情況,導致數據質量下降。
1.2.4 非結構化數據人工加工成本高
為解決WPRIM數據缺失的問題,需要對非結構化歷史數據進行補充。由各國數據管理人員、編輯部編輯等通過逐條錄入的形式向WPRIM系統匯交非結構化數據。這種數據匯交模式不僅增加了數據管理人員和編輯的工作量,還會出現更新速率慢、易出錯的情況,不符合數據管理未來可持續發展的趨勢。
2 WPRIM的元數據匯聚策略
2.1 多源異構元數據匯聚的相關實踐
為解決數據來源多、形式多(如同型/質異源、異質異構和多種語言[11];結構化、非結構化和半結構化[12-13])、內容雜(如系統異構、語法異構、結構異構和語義異構[14])的現狀,學術界從質量評估、元數據映射、領域本體等角度進行多源數據匯聚路徑的探索。林鑫等[15]、周艷會等[16]、Bruce等[17]從元數據、數字字典、用戶要求、數據應用等角度進行數據質量評估,設置數據質量控制規范規則,提升集成對象的數據質量。Moghaddasi等[18]、于倩倩等[19]等通過元數據標簽映射等方式,從內容標準化和元數據映射兩個維度實現多源數據匯聚。劉盼雨等[20]依據數據流向通過多源異構數據轉換、清洗、元數據管理等手段構建涵蓋“生產-存儲-計算-應用”的多源異構數據服務平臺。侯鑫鑫等[21]提出數據獲取、數據整合、關聯關系建立、入庫及調用的異構大數據整合方案技術路線。曲建升等[14]、崔佳[22]以需求為導向,選擇領域知識本體,并根據知識本體開展數據標準化,實現異構數據的匯聚。
2.2 WPRIM的元數據匯聚思路
面向提供西太平洋地區出版的生物醫學領域文獻、促進欠發達地區生物醫學科技文獻傳播、提供及時準確數據服務的基本需求,破解現有數據加工人工成本高、歷史數據不完整的難題,參考于倩倩等學者提出的基于元數據映射的多源異構數據匯聚策略,從系統需求與內容特征視角,補充數據源遴選制度、內容著錄規范化與非結構化數據轉換環節,增加J-STAGE等元數據標準的映射方法,形成如圖1所示的WPRIM期刊元數據匯聚思路。
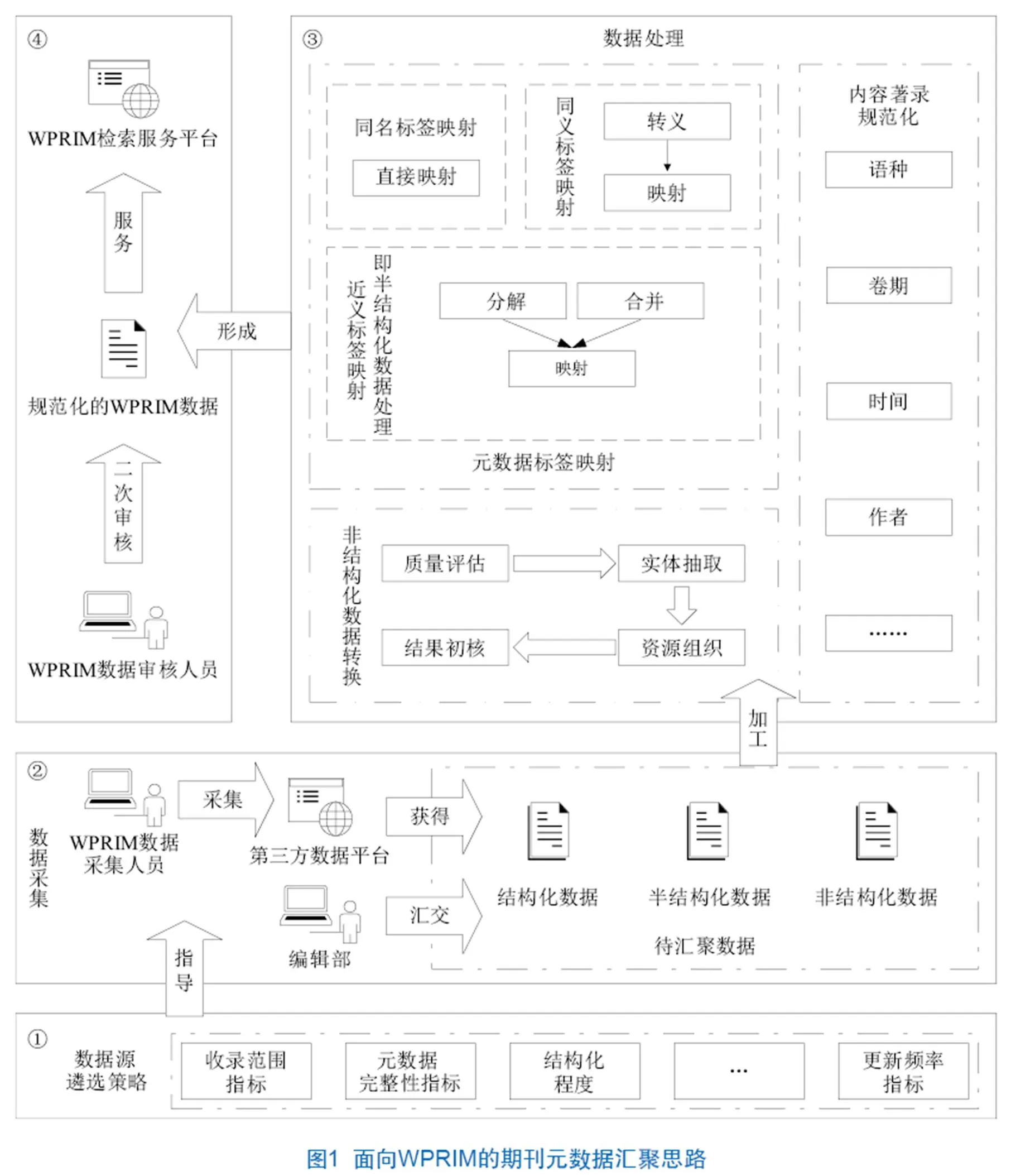
第一,面向WPRIM的期刊元數據匯聚通過設置不同場景下的指標及其權重確定數據源遴選策略指導數據采集及匯交(如①所示)。第二,數據采集人員和編輯部等分別通過采集第三方數據與提交文檔的形式,提供結構化、半結構化與非結構化的待匯聚數據(如②所示)。第三,對待匯聚數據進行元數據標簽映射、內容著錄規范化的數據處理與非結構化數據轉換,匯聚并形成規范化的WPRIM數據(如③所示)。第四,對規范化的WPRIM數據開展二次審核(如審核作者姓名是否為全拼),審核合格的數據通過WPRIM檢索服務平臺對外提供服務(如④所示)。
2.3 WPRIM元數據的匯聚實施方案
2.3.1 數據源遴選
遴選數據源指標和權重設置方面,WPRIM面向不同需求的服務場景設置6個一級指標、19個二級指標進行數據源評價。其中,一級指標包括收錄范圍、元數據完整性、結構化程度、期刊變更信息準確度、是否具有全文或全文鏈接、更新頻率6個指標(見表1)。通過專家咨詢法并結合系統需求場景的變化設置數據源指標權重。WPRIM的基本需求是占用較少的人力資源保證定期、批量更新期刊文獻資源。在這一基本需求下,重點考量數據收錄范圍、元數據完整性等要素。因此,收錄范圍、元數據完整性相關的二級指標在基本需求場景下的所占權重較高。遇突發情況時,用戶的主要需求是快速獲得第一手的科技論文資源。面對這類特殊需求,則以數據更新速率指標為最高權重來遴選數據來源。如新型冠狀病毒疫情爆發初期,WRPIM平臺與期刊編輯部合作,在不考慮數據是否結構化的基礎上,提供人力支持,輔助編輯部優先匯交新型冠狀病毒主題文獻資源。同時,WPRIM監測國內外醫學檢索平臺(如PubMed、KoreaMed、SinoMed、萬方醫學網等)、出版商(如中華醫學會出版社等)的新型冠狀病毒文獻專題,及時發現優先出版的期刊文獻資源,不嚴格限制文獻資源來源唯一性。
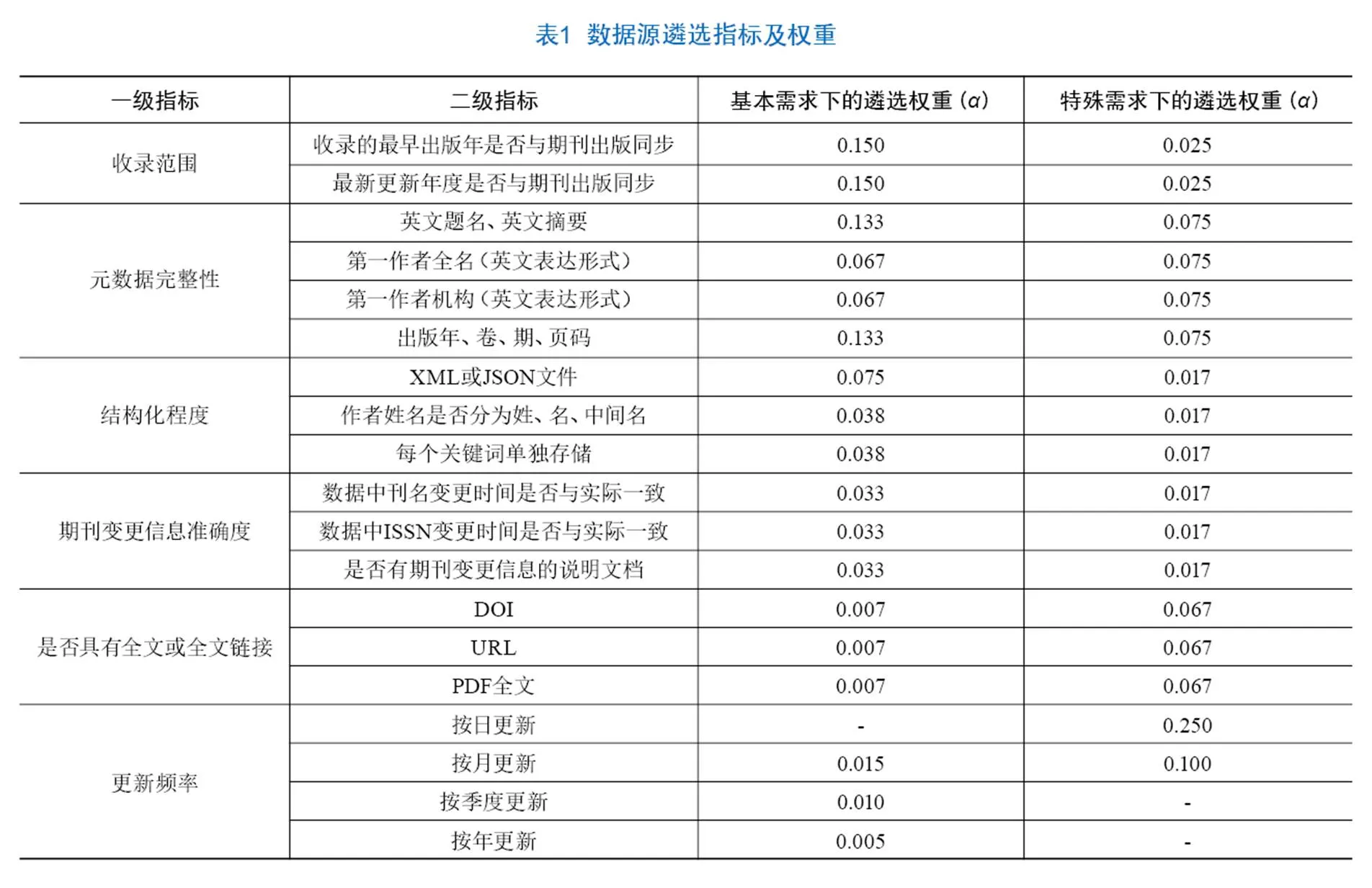
數據源遴選實現上,當一本期刊有多個數據來源時,WPRIM通過計算各個數據源的分數值(Score),并取最大Score值對應的數據來源作為該本期刊的數據源。計算方法見公式(1)。
其中,coresource表示期刊某一數據源的分數值,等于指標及其權重乘積的和;表示評價期刊數據源的全部指標,表示中的一個指標,S表示指標的分值,a表示指標在評價中所占權重。當滿足指標要求時,S設為100,反之則設為0,若二級指標包含多個三級指標時,S平均分配至三級指標。
2.3.2 元數據標簽映射
WPRIM參考全球醫學索引、美國PubMed、韓國KoreaMed等文獻檢索系統元數據標準,提出并建立了WPRIM元數據方案,規定采用包括論文題名在內的12個元數據項描述文獻資源。WPRIM匯聚的結構化、半結構化數據的元數據標簽與WPRIM元數據標簽存在同名、同義及近義3種情況。這3類標簽的映射方法具體包括以下內容。
(1)同名標簽的元數據映射。同名標簽的元數據映射必須確定標簽項的含義是否一致。如中文期刊數據中題名標簽指中文題目,WPRIM的題名標簽指文獻的英文標題,兩者含義是不同的。又如,JATS的期標簽(ISSUE)與WPRIM的期標簽(ISSUE)的含義是相同的。在保證含義一致的情況下,采用直接映射取值的方式,實現同名元數據項取值。
(2)同義標簽的元數據映射。通過對數據源元數據標簽含義的調研,確定同義標簽的對應關系,構建同義標簽的轉義工具,將非WPRIM元數據標準的數據標簽轉換為WPRIM元數據標準的元數據標簽,實現同義標簽數據的映射。
(3)近義標簽的元數據映射。近義標簽的元數據映射(半結構化數據處理)是將與WPRIM元數據標簽近義的、內容半結構化的數據進行分解或重組,提取處理后的元數據值,并映射至目標元數據的相近標簽。以J-STAGE的作者映射為WPRIM作者為例,J-STAGE元數據雖然部分利用XML結構化的形式存儲數據,但作者(authors)包含非結構化的作者姓、名。這類數據被稱為半結構化數據。通過分解,該半結構化數據被分解形成姓(LASTNAME)和名(FIRSTNAME)兩部分,取值分別為Masahiro和Hamashima,并賦值于相應元數據項。
2.3.3 內容著錄規范化
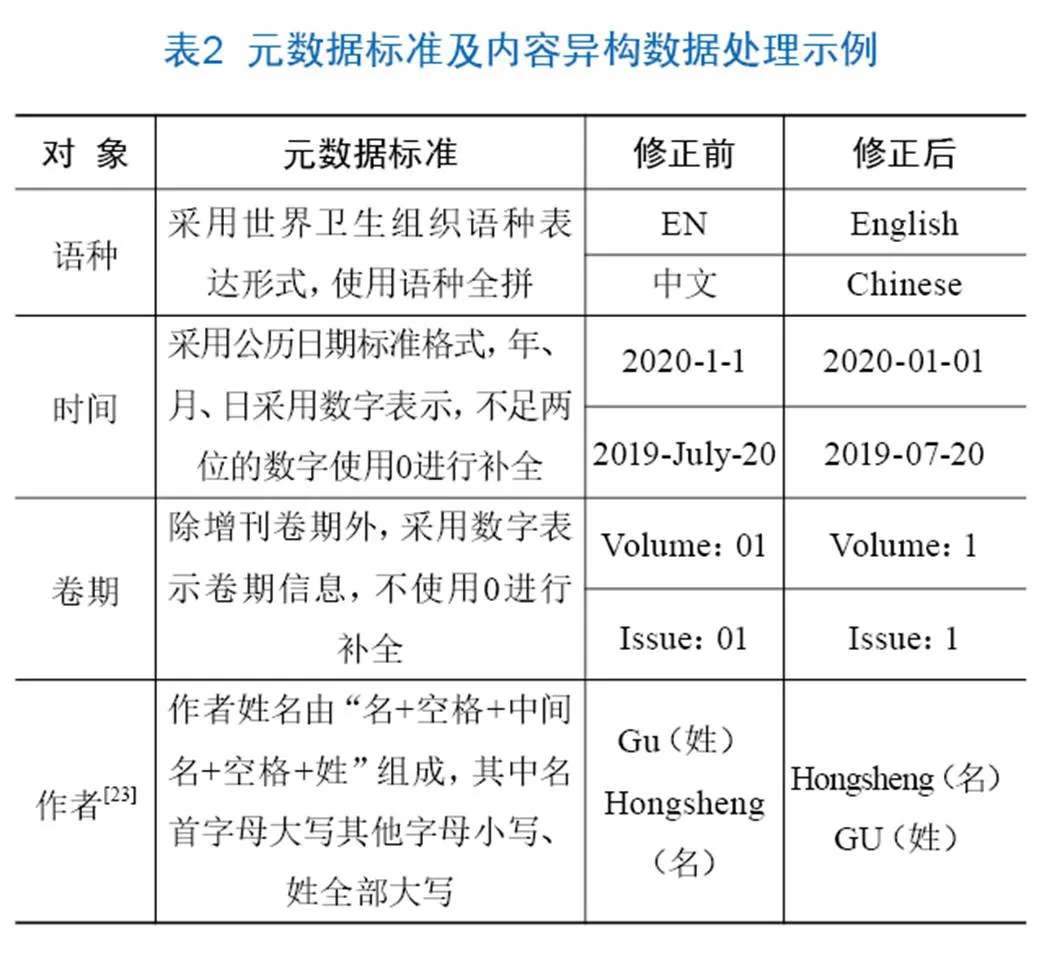
通過設置規范策略,在不破壞數據本身含義的前提下,對不同表達形式的內容進行分析與修正,統一數據內容形式,保證數據著錄規范。異構內容依照WPRIM數據著錄標準進行匯聚,對不滿足著錄標準的內容進行修正。常見修正內容包括語種、時間、卷期、作者的表達形式(見表2)。
2.3.4 非結構化數據轉換
非結構化數據轉換包括質量評估、實體抽取、資源組織與結果審核4個環節,實現非結構化數據轉換為結構化數據,用于資源匯聚(見圖2)。

(1)質量評估。采用隨機抽樣分析的方法進行質量評估。即抽樣一期或兩期的非結構化文檔進行內容、順序、特征3個維度的質量評估。首先,內容層面對內容完整度和質量進行評估。內容完整度上,要求著錄內容基本完整,包括但不限于英文題名、英文作者信息(姓名全拼、機構)、摘要、頁碼的數據內容。質量上,要求同一元數據位于同一行,如文獻標題不出現中間換行。其次,要求非結構化文檔內容順序具有一致性。即同一本期刊題名、作者、關鍵詞、摘要出現順序保持一致。最后,非結構化文檔應具備定位特征。即非結構化文檔存在明確識別出一篇文章的開始或結束的定位標志。“中圖分類號:……”的內容是一篇文章開始的特征;“DOI:……”的內容是一篇文章的結束特征。這兩個特征之間的內容符合英文標題、作者及機構、摘要、關鍵詞的著錄順序,組成了WPRIM所需的數據項。
(2)實體抽取。依據質量評估的結果(特征、順序)定制實體抽取策略,依次或分批提取英文題名、英文作者、摘要、頁碼等內容。
(3)資源組織。根據WPRIM元數據標準,對已抽取的實體信息進行結構化組織,形成符合WPRIM元數據標準的XML格式數據文件。
(4)結果校驗。利用XML文件中指定的文檔類型定義(DTD)對成果進行完整性和合理性自動校驗。完整性校驗判斷是否缺失必備字段項,并對缺失必備項的數據進行剔除。合理性校驗對數據內容是否合理開展語法與語義兩個維度的審核。語法方面,開展諸如判斷頁碼是否存在非數字字符、作者是否包含數字的語法檢查。語義方面,開展諸如作者姓名拼寫是否符合西方語言國家、南島語系國家(如印度尼西亞、馬來西亞、菲律賓)、漢藏語系國家(如中國)的內容檢查。
3 結論與展望
針對WPRIM數據資源的同一期刊存在多個數據來源、不同數據源的元數據標簽不一致、不同數據源著錄標準不同、非結構化數據人工加工成本高的現狀,從數據源遴選、元數據標簽映射、內容著錄規范化、非結構化數據轉換4個維度設計多源數據匯聚方案,實現WPRIM收錄期刊元數據的匯聚。WPRIM平臺文獻總量已由2016年的60余萬篇增長至2020年的80余萬篇,回溯非結構化期刊資源2萬多篇,規范作者、卷、期、時間數據60余萬篇,匯聚與規范成果已被全球醫學索引、谷歌學術等文獻檢索平臺收錄。2020年,WPRIM平臺月均文章點擊量達到198?912次,較2018年月均文章點擊量增長46%。
國內已開展或建成一系列“一帶一路”、中國-東盟等跨國別的數據庫,也面臨各國數據資源來源、結構化水平和著錄質量差異的挑戰。結合世界衛生組織西太平洋地區醫學索引的建設實踐,未來多源數據匯聚可以參考以下5個方面加以改進。
(1)需求驅動匯聚數據資源的遴選。立足用戶對文獻資源的需求,梳理不同數據源的優勢與不足,動態調整獲取途徑,通過不斷完善數據資源遴選標準,快速匯聚成果并提供用戶使用。
(2)關注元數據標準及其著錄規范。元數據標簽映射能實現資源匯聚,但仍存在一定不足。通過著錄規范化的視角,一方面能夠提高匯聚成果的質量;另一方面也能夠減少重復數據的出現,降低數據歸一與去重的工作量。
(3)開展精細化、互補化的多源數據融合。WPRIM數據是通過數據遴選制度確定唯一數據來源,從而降低數據去重工作量,加快數據更新效率。但在提高效率的同時,部分字段項內容缺失、預出版數據與正式出版數據重復的問題顯現。WPRIM及其他相似索引平臺應補充多源篇級論文精準匹配和字段及內容融合的研究,實現多源數據精細化、互補化的融合。
(4)拓展索引服務深度與廣度。一方面,索引服務要深挖資源包含的知識內容,開展文獻標引研究,深化數據內容,服務智能檢索;另一方面,聚焦新媒體的資源傳播場景,開展如社交媒體、視頻等場景下的文獻傳播方法研究。
(5)構建數據匯聚的可持續發展機制。一方面,跨國別的資源匯聚平臺需要開展國際合作交流,組織深入的數據管理培訓,提升編輯或數據管理人員的計算機水平,指導其開展匯聚前的數據結構化,降低匯聚平臺的數據復雜度;另一方面,引入自然語言處理、機器學習等不斷出現的先進技術,實現精準匹配、文獻標引等維度的數據深度融合。
[1] 曾建勛. 開放融合環境下NSTL資源建設的發展思考[J]. 大學圖書館學報,2020,38(6):63-70.
[2] 趙志耘. 構建國家科研論文和科技信息高端交流平臺[J]. 數字圖書館論壇,2020(11):1.
[3] 王軍輝,錢慶,方安,等. 西太平洋地區醫學索引元數據方案的設計與應用[J]. 醫學信息學雜志,2011,32(4):68-72.
[4] NCBI. Journal Article Tag Suite[EB/OL].[2020-12-10]. https://jats.nlm.nih.gov/about.html.
[5] NCBI. Journal Publishing Tag Set Standard versions[EB/OL].[2020-12-10]. https://jats.nlm.nih.gov/publishing/versions.html.
[6] NCBI. Journal Archiving and Interchange Tag Set[EB/OL].[2020-12-10]. https://jats.nlm.nih.gov/archiving/.
[7] NCBI. Article Authoring Tag Set[EB/OL].[2020-12-10]. https://jats.nlm.nih.gov/articleauthoring/.
[8] 劉冰,游蘇寧. 我國科技期刊應盡快實現基于結構化排版的生產流程再造[J]. 編輯學報,2010,22(3):262-266.
[9] 姚偉欣,馬建華. 新學術環境下科技期刊數字出版平臺的技術發展趨勢[J]. 中國科技期刊研究,2013,24(6):1039-1043.
[10] 蘇磊,李明敏,蔡斐. 科技期刊采用XML結構化排版的優勢與應用實踐分析[J]. 科技與出版,2017(10):108-111.
[11] 化柏林. 多源信息融合方法研究[J]. 情報理論與實踐,2013,36(11):16-19.
[12] 郭春霞. 大數據環境下高校圖書館非結構化數據融合分析[J]. 圖書館學研究,2015(5):30-34.
[13] 涂子沛. 大數據及其成因[J]. 科學與社會,2014,4(1):14-26.
[14] 曲建升,劉紅煦. 知識發現中異構信息標準化處理研究——以資源環境領域文獻為例[J]. 圖書情報工作,2016,60(6):84-90.
[15] 林鑫,李想,李靜. 資源發現系統中基于多源數據融合的文獻元數據質量提升[J/OL]. 情報理論與實踐,2021:1-8[2020-12-10]. http://kns.cnki.net/kcms/detail/11.1762.g3.20201203.1624.004.html.
[16] 周艷會,曾榮仁. 基于元數據的數據質量管理研究[J]. 信息技術與信息化,2020(7):26-29.
[17] BRUCE T R,HILLMANN D I. The continuum of metadata quality:defining,expressing,exploiting[C]//HILLMANN D I,WEATBROOKS E L. Metadata in Practice. Chicago:American Library Association,2004:238-256.
[18] MOGHADDASI J,WU K. Multifunctional transceiver for future radar sensing and radio communicating data-fusion platform[J]. IEEE Access,2016,4:818-838.
[19] 于倩倩,張建勇. NSTL集成利用第三方來源元數據的實踐與探索[J]. 現代圖書情報技術,2016(1):97-102.
[20] 劉盼雨,王昊天,鄭棟毅,等. 多源異構文化大數據融合平臺設計[J/OL]. 華中科技大學學報(自然科學版),2021:1-8[2020-12-10]. https://doi.org/10.13245/j.hust.210216.
[21] 侯鑫鑫,朱文佳,朱莉,等. 多源異構學術成果大數據的整合與揭示[J/OL]. 情報理論與實踐,2021:1-11[2020-12-10]. http://kns.cnki.net/kcms/detail/11.1762.G3.20201204.1105.002.html.
[22] 崔佳. 基于領域本體的多元異構數據融合關鍵技術研究[D]. 青島:中國石油大學(華東),2018.
[23] 王蕾,方安,范云滿,等. 多來源作者數據加工策略與實現——以西太平洋地區醫學索引為例[J]. 醫學信息學雜志,2019,40(2):75-80.
Research on Multi-Source Journal Metadata Fusion:Taking WHO Western Pacific Region Index Medicus as An Example
WANG Lei FANG An YANG YuSheng FAN YunMan WANG Qian
( Institute of Medical Information, CAMS & PUMC, Beijing 100020, China )
Analyzing status of source data and problems on multi-source journal metadata fusion in WHO Western Pacific Region Index Medicus. This paper designs a multi-source data fusion scheme from source selection, metadata label mapping, content standardization, and unstructured data transformation. The result shows that the path can solve WPRIM multi-source data fusion and provide a reference for similar situations as well.
Data Fusion; Multi-Source Data; WPRIM; Multi-Metadata and Heterogeneous
G354.49;G255.2
10.3772/j.issn.1673-2286.2021.01.007
王蕾,方安,楊雨生,等. 多源期刊元數據匯聚研究——以世界衛生組織西太平洋地區醫學索引為例[J]. 數字圖書館論壇,2021(1):47-53.
*本研究得到中國醫學科學院醫學與健康科技創新工程服務“一帶一路”戰略先導科研專項“衛生信息服務研究”(編號:2017-I2M-B&R-10)和中國醫學科學院醫學與健康科技創新工程“醫學科技創新評價與衛生服務體系研究”(編號:2016-I2M-3-018)資助。
王蕾,女,1989年生,碩士,助理研究員,研究方向:信息技術、大數據處理。
方安,男,1976年生,博士,研究館員,研究方向:醫學知識組織與數字圖書館。
楊雨生,男,1994年生,助理館員,研究方向:信息技術應用。
范云滿,男,1980年生,碩士,助理研究員,研究方向:醫學數據自然語言處理、云計算環境下大數據分析算法。
王茜,女,1981年生,博士,副研究館員,通信作者,研究方向:信息技術應用,E-mail:wang.qian@imicams.ac.cn。
(收稿日期:2020-12-18)
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
科學大眾(2021年21期)2022-01-18 05:53:48
科學大眾(2021年17期)2021-10-14 08:34:02
科學大眾(2021年19期)2021-10-14 08:33:02
科學大眾(2021年9期)2021-07-16 07:02:52
科學大眾(2020年23期)2021-01-18 03:09:18
科學大眾(2020年17期)2020-10-27 02:49:04
中國現代醫藥雜志(2020年12期)2020-01-08 16:42:06
中國現代醫藥雜志(2020年10期)2020-01-08 06:42:11
臺聲(2016年2期)2016-09-16 01:06:53
