日本國立國會圖書館互聯網資源存檔研究與啟示
2021-04-19 14:33:58楊云鵬
數字圖書館論壇 2021年1期
楊云鵬
數字資源保存
日本國立國會圖書館互聯網資源存檔研究與啟示
楊云鵬
(國家圖書館,北京 100081)
日本國立國會圖書館從2002年開始進行互聯網資源存檔項目WARP,目前已經建立完善的體制。本文從網站篩選、采集技術、網站加工和保存技術4個方面對日本國立國會圖書館互聯網資源存檔項目進行詳細介紹,并從采集方法、數據加工、保存方式、法規建設、國際交流與合作5個方面提出中國開展互聯網資源存檔的建議,以期互聯網資源存檔能得到更好的發展。
互聯網資源存檔;網站;日本國立國會圖書館;采集
過去人們只能從書籍和文檔中了解歷史事件。但是,隨著互聯網和數字技術的發展,紙上留下的信息正迅速被網站等電子信息所取代。而當后代試圖回顧歷史時,如果網站上沒有任何信息,那么大部分歷史信息將丟失。為防止這種情況的發生,需要將網站上的信息保存下來。互聯網的飛速發展,促使人們的生活、學習和工作逐漸離不開網絡,而2020年新冠肺炎疫情的爆發,也加劇了通過網絡獲取信息這種形式的發展,然而網絡資源的壽命一般在90~100天,因此互聯網信息存檔尤為迫切。互聯網資源存檔不僅可以保存人類在短期到中期內訪問的互聯網信息,而且對將來保留歷史資料具有長遠意義。
互聯網資源存檔主要由世界各地的國家圖書館和公共機構(世界各地的網絡檔案館)負責,IA(Internet Archive)是已知最大的互聯網存檔內容保存機構,截至目前已擁有PB級別的壓縮數據,并保存了3?300億個網頁和網頁快照。它成立于1996年,是一個非營利性組織,其成立標志著網絡信息資源保存研究的開始[1]。繼IA之后很多國家陸續建立了互聯網資源存檔項目,其中采集規模較大的包括英國、法國和日本。法國和英國的互聯網資源存檔成分別成立于2002年和2004年,均保存本國域名的網站。日本國立國會圖書館自2002年以來一直在進行本國互聯網資源存檔項目(WARP)的研究,通過長期互聯網資源存檔開發了一套包括篩選、采集、組織、保存和發布在內的軟件,讓互聯網資源存檔變得更加容易和高效。中國互聯網資源存檔事業目前還處于初級階段,亟需改進以跟上互聯網的發展腳步,通過剖析其他國家或組織的互聯網資源存檔的技術和經驗,對我國進行互聯網資源存檔,跟上世界步伐,實現互聯網資源的長期保存具有重要意義,而現有研究主要圍繞擴大采集范圍和增加采集數量展開,缺乏采集技術、數據加工和長期保存方法等方面的研究。
因IA開放度不高且技術相對封閉,所以本文從互聯網資源存檔項目技術先進、開放程度高且與中國互聯網資源存檔發展路線一致的日本國立國會圖書館的互聯網資源存檔項目(WARP)出發,詳細分析日本互聯網資源存檔的機制和支持互聯網資源存檔的技術,總結可以借鑒的技術和經驗,以便更好地推動我國互聯網資源存檔的發展。
1 日本互聯網資源存檔項目概述
1.1 互聯網資源存檔的意義
互聯網上的信息很容易更新、修訂和刪除,并且網站本身也會消失。近年來,政府機構發布報告之類的重要材料已經從紙質媒體轉變為網絡版本。而部分經過重大更新的網站時,總理辦公室的網站將進行重大更新,更新后只保留過去的信息,并不會保留頁面顯示樣式。此外,重大事件的網站也會隨著事件的結束而消失。例如,2002年在日本和韓國舉行的FIFA世界杯日本組委會的網站在比賽結束后就從互聯網上消失了。日本互聯網資源存檔項目保存了日本政府機構和國家重大事件網站發布的所有內容,其涵蓋文化、歷史、政治和宗教等多個方面,未來能讓更多的國民通過互聯網資源存檔項目了解國家的發展和變化,對整個日本歷史文化的傳承甚至人類文明的傳承起到非常重要的作用。
1.2 日本互聯網資源存檔項目采集情況
自2002年以來,日本國立國會圖書館的WARP項目一直在保存即將消失的有價值的網站,如政府網站發布的信息、發布國家重大事件的網站及發布出版物的網站等[2]。互聯網資源存檔的作用是采集、存儲并提供服務,以便讓用戶可以隨時查找消失的網站。
1.2.1 日本互聯網資源存檔的數據量
日本互聯網資源存檔項目截至2020年3月已采集12?556個網站,177?154個網頁,85億個文件,數據量達1?678TB。2010年日本修訂了《國立國會圖書館法》,允許全面采集網站,因此從2010年開始日本采集數據量快速增長,2010—2013年每年增加100TB左右,2014—2019年每年增加200TB左右。
1.2.2 日本互聯網資源存檔的數據類型
互聯網資源存檔項目包括多種文件類型,主要有jpg、png、tiff、pdf、html、php、css、js、xls、xlsx、doc、docx等,其中圖片格式、html格式和PDF格式類占71.33%[3]。存檔文件類型中圖片格式占比最高,這是由于日本政府和大學的網站都是以圖文并茂的形式呈現,是為了讓更多的人能夠快速理解文章的意思。日本政府類網站上公報、公文和政策類文件大多以PDF形式呈現,因此PDF類型的占比也相對較高。
1.2.3 日本互聯網資源存檔的方法
互聯網資源存檔從采集技術上可分為兩種方法:一種是通過軟件采集網站,保存網頁內容的原始格式(jpg、pdf、html、php、css、js等)通過數據庫進行管理服務;另一種是通過軟件對網站進行采集,將采集的內容保存成WARC格式的壓縮包,然后通過回訪軟件進行服務。第一種方法是網站原始格式,文件數量多、數據容易被修改,未經過壓縮,占據存儲空間大,不便于管理,因此國際上很少用這種方法進行互聯網資源存檔長期保存。日本國立國會圖書館是通過第二種方法進行互聯網資源存檔,這種方法是以WARC壓縮包的形式保存,數據不能被修改,同時一個壓縮包能保存多個文件,不但減少了文件數量而且減少了文件所占存儲空間。
互聯網資源存檔從獲取方式上也有兩種方法:一種是通過軟件采集進行保存,另一種是通過征集贈與或繳存的形式保存。征集贈與或繳存的網站是數據庫形式的內容,需要轉換成WARC格式。目前轉換成WARC格式的技術還不成熟,轉換后的網站回放的效果并不理想,會有一部分內容無法顯示或出錯,因此國際上主要以軟件采集的方法進行保存,日本國立國會圖書館同樣就是用軟件采集方法進行保存。
1.3 日本互聯網資源存檔項目的特色服務
為更方便快捷地對存檔內容進行檢索及使用,日本國立國會圖書館對其存檔的互聯網資源進行了可視化操作和互聯網出版物數據加工。①存儲站點類別可視化:運用大數據可視化工具對存儲的站點進行分類,用不同顏色的圓圈表示,資源容量越大,對應顏色的圓圈所占面積也越大。②公共團體網站可視化:以地圖的形式分析采集公共團體網站,分析網站的變化和消失情況。③國家機構文件的可視化:從采集的國家機構文件中選取出1?000萬個文件,以圖表的形式展示其近5年出現和消失的情況。④互聯網出版物的數據加工:從存儲網站上提取出版物和受版權保護的作品,如白皮書、會議資料、報告和專著等,并添加標題和作者等數據,以便可以對其進行有效搜索。
互聯網資源存檔項目主要保存國家重要文化財產,通過深度挖掘并利用大數據技術對其進行可視化操作,可為不同專業的科研人員提供豐富數據和圖表供其研究使用,同時也能讓更多的人明白互聯網存檔的價值和意義。
2 日本互聯網資源存檔全流程
日本互聯網資源存檔全流程如圖1所示,由5個部分組成,即篩選、采集、組織、保存和發布。網站上發布的信息將隨著時間而改變,互聯網資源存檔項目通過定期重復此流程來跟蹤網站中的更改。
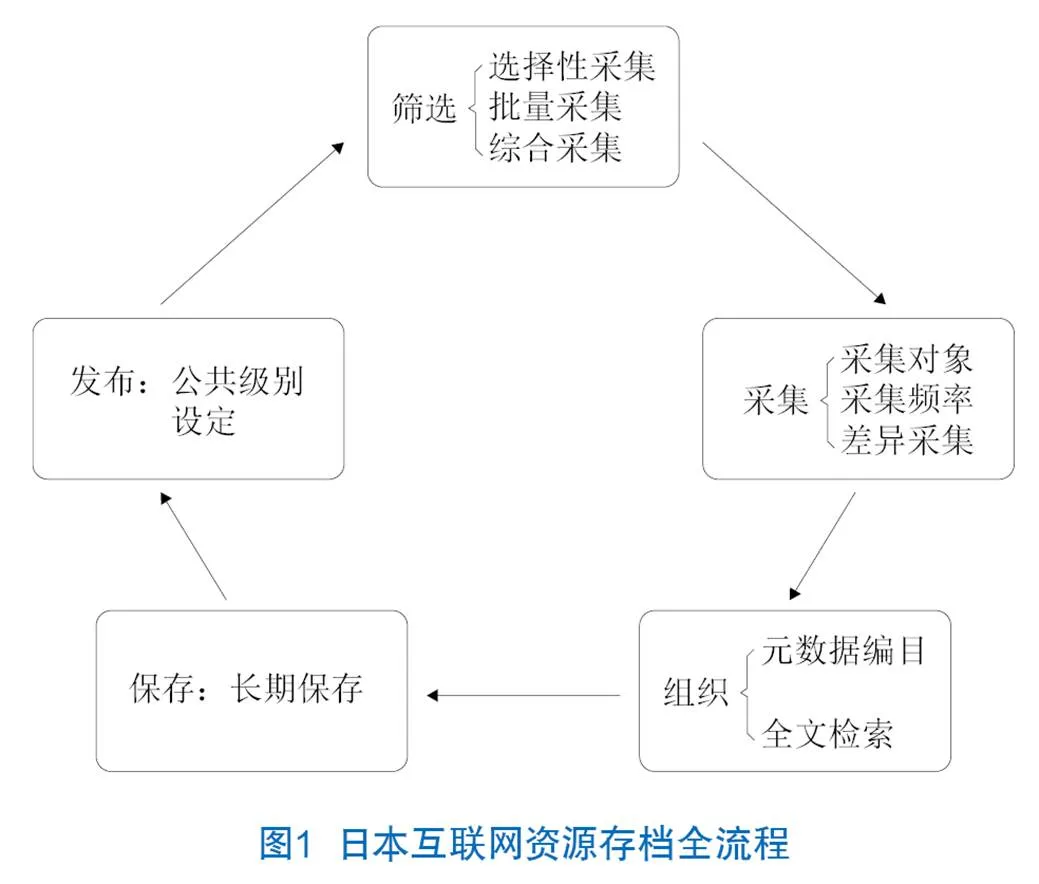
2.1 互聯網資源存檔網站篩選策略
根據制定的需求(包括目標類型和規模)篩選要采集的網站,以確定采用何種方式進行信息采集。其中根據目標類型需求按照專題采集特定類型的網站,一般采用選擇性采集的方式。根據采集的規模,小規模采集僅采集國內的綜合性網站,多采用選擇性采集或批量采集的方式進行;大規模采集針對全世界范圍采集網站,一般選擇批量采集或綜合采集的方式進行。
2.1.1 選擇性采集
特定主題網站的集合稱為選擇性采集,需要指定一個采集單位,如站點單位或網頁單位。此方法用于中小型互聯網資源存檔,如奧運會等類專題采集需要采用選擇性采集,因為相關網站只有個別欄目是介紹這類專題的,沒有必要完全整站采集。針對沒有法律許可的網站,如版權聲明中明確規定不允許復制保存的新聞類和受版權保護的文學類網站資源,采集部分內容前必須獲得創建者的許可,其沒有關于“批量采集”法律許可,故此種類型的網站采集也需選用選擇性采集的方式。
2.1.2 批量采集
批量采集是跨國家/地區域(如“.com”和“.de”)的大規模網站集合。一些機構,如IA,會聚合世界各地的網站,因此日本國立國會圖書館在采集此類網站信息時,需采用批量采集的方式。
在法律制度下,大部分互聯網資源是由國家圖書館等公共機構進行存檔。批量采集法律許可的網站,無須事先獲得創建者的同意。根據2010年4月生效的《國立國會圖書館法》(修訂版),日本國立國會圖書館有權批量采集公共機構網站的資源。
2.1.3 綜合采集
綜合采集是將選擇性采集和批量采集相結合的方式進行采集。日本國立國會圖書館通過立法可以對一部分網站進行批量采集,但是對于社交網站、視頻網站和私人網站等并沒有批量采集的權限,因此當采集需求涉及這類沒有權限的網站時,只能采取選擇性采集的方式進行采集。綜合采集是采集特殊需求的內容,如發生的全國性熱點事件既涉及官方網站內容又涉及社交網站內容,就需要運用綜合采集,對法律允許采集的網站進行批量采集,不在法律規定范圍內的網站須征得同意后才可進行選擇性采集。
2.2 互聯網資源存檔采集技術
在實際采集目標網站時,日本國立國會圖書館使用自動采集程序——采集機器人(抓取工具)進行采集,在采集之前制定采集頻率和采集深度。
2.2.1 采集對象
根據《國立國會圖書館法》第24條規定可以對以下機構進行采集,如國家機關(立法、行政、司法,包括當地分支機構)、獨立行政機關、國立大學法人(包括大學聯合機構法人)、特殊法人等。第24-2條規定的機構包括地方公共組織(包括法定的委員會)和地方公社(港務局、房屋供應公司、道路公司、土地開發公司、地方獨立行政機構、全國地方賽馬協會、地方公共組織金融組織、日本下水道公司)等[4]。除法律規定外,WARP項目還會與網站創建者溝通,采集創建者允許的私人網站。
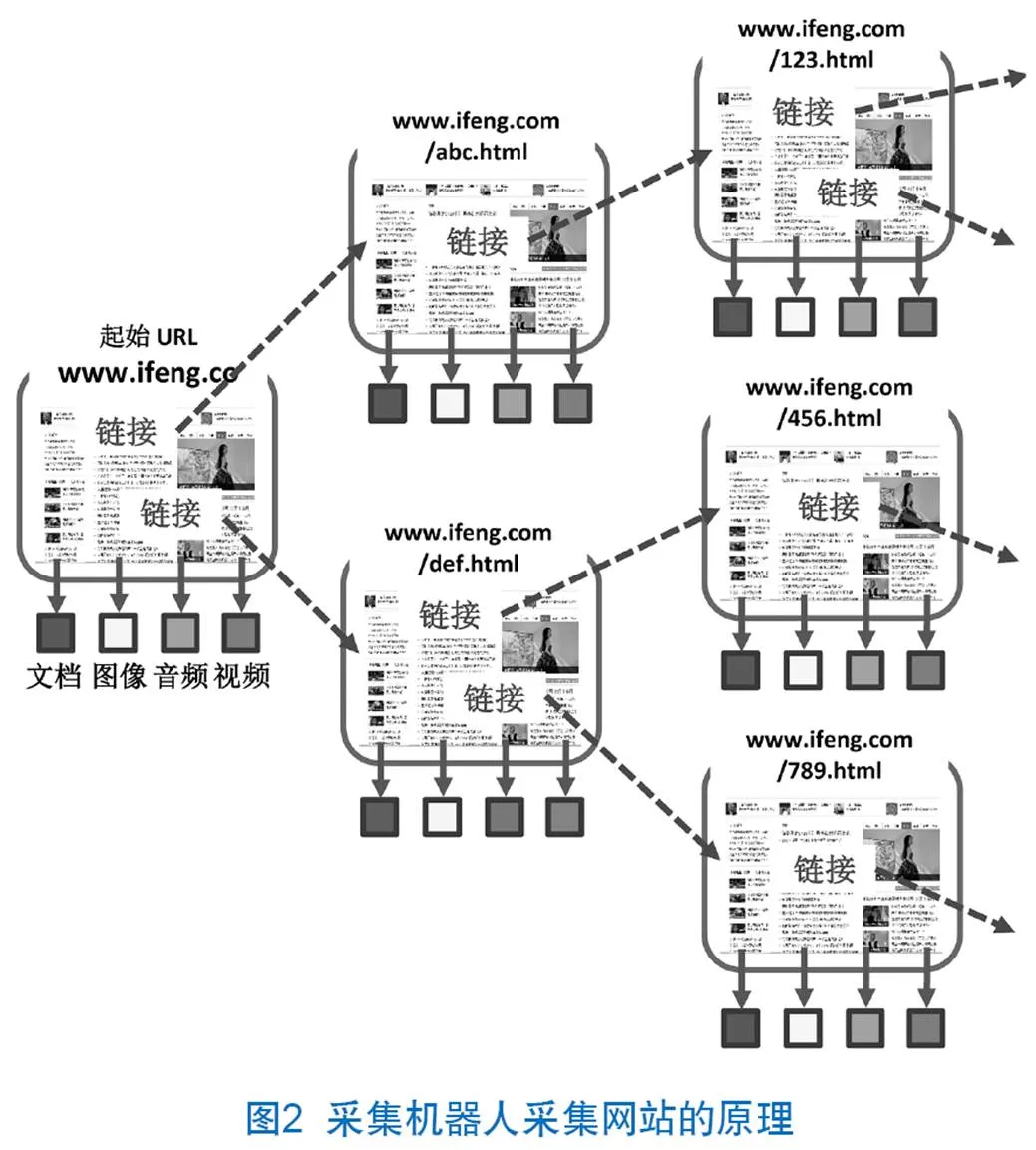
2.2.2 采集原理
日本WARP項目使用自動采集程序(Heritrix)自動采集網站。采集機器人采集網站原理如圖2所示,采集機器人首先訪問起始網頁(起始URL)。然后,在采集頁面html文件的同時,分析html文件中的結構并開始采集文件,包括文檔、圖像、音頻、視頻、樣式表和腳本文件。從起始URL跳轉到其他鏈接頁面,然后重復相同的操作直至到達設定的采集深度或者沒有鏈接為止。為了減少對采集網站服務器上的網絡負載,每次采集之間將保留1秒或更長的下載間隔[5-6]。
根據《國家國立圖書館法》第25-3條第2項的規定,對于設置了爬蟲協議(robots.txt)的網站,要求網站必須將日本國立國會圖書館添加到爬蟲協議中。
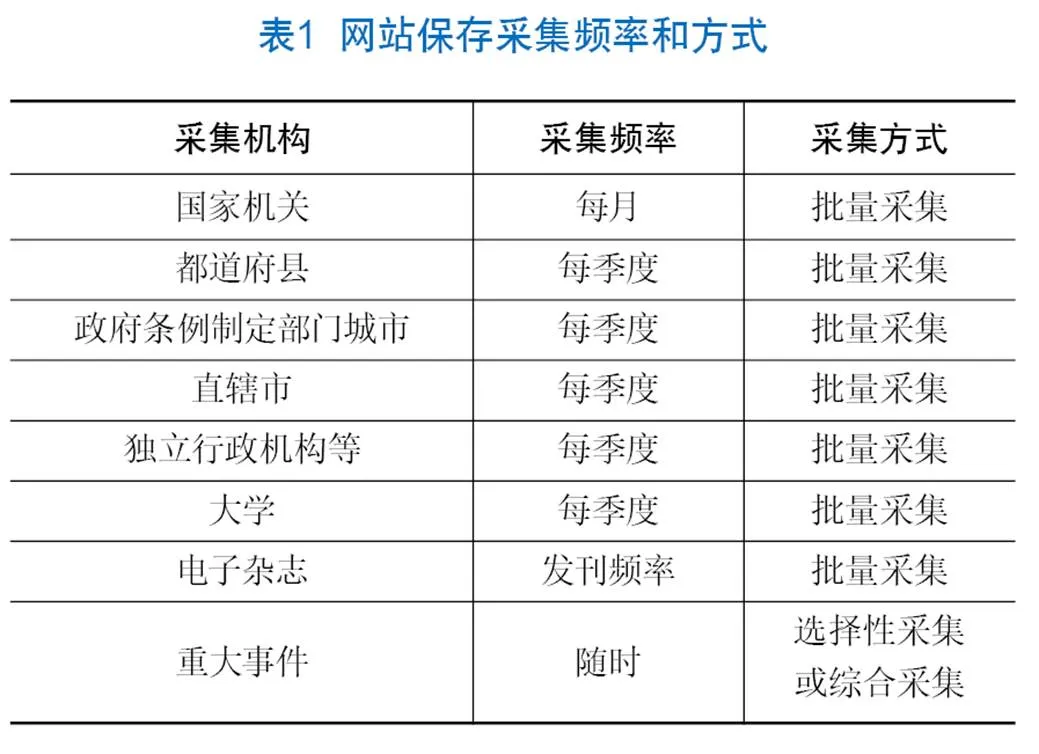
2.2.3 采集頻率
最理想的采集頻率是網站每次更新便采集,但這需要一種能實時監測網站更新信息的爬蟲。一些大學研究機構正在開發配合大數據分析的高性能爬蟲工具,但目前還沒有互聯網資源存檔操作機構使用這種爬蟲,因為這種爬蟲對服務器的要求特別高,并不適合大批量采集,且還處于實驗階段。
日本國立國會圖書館根據不同網站設定不同的采集頻率,如表1所示,基于法律規定盡可能保存“國家機關”的信息,因此采取國家機關每月采集一次,都道府縣、政府條例制定部門城市等每季度采集一次,電子雜志根據發刊頻率進行采集,重大事件網站根據需要采用選擇性采集或綜合采集的方式隨時采集。
2.2.4 差異采集
互聯網資源存檔會定期采集相同的網站。因此,部分新采集的文件相比之前采集的文件發生了變化,有一部分文件則與之前的完全相同,造成時間和存儲空間的浪費。為了解決數據重復采集的問題,日本國立國會圖書館提出差異采集法。每次采集時保存所有文件的方法稱為完全采集,而僅保存更改過的文件的方法稱為差異采集。
在差異采集中,通過比較哈希值來判斷文件是否相同。哈希值是通過使用某種計算方法(哈希函數)來處理電子數據而獲得的值。由于不同電子數據的哈希值很少相同,因此可以將其比作電子數據中的指紋。電子數據的任何細微變化都會改變哈希值。
日本國立國會圖書館的差異采集是在開源軟件DeDuplicator的基礎上進行的二次開發。差異采集中,首先分析網站結構,篩選出不易變化的文檔類型,避免由于網頁微小噪音導致哈希值變化進行錯誤采集。然后選擇文本文檔、非文本文檔或者兩者都進行過濾。最后對比以前的采集日志,如果文件名稱均不相同,則進行保存;如果存在相同名稱的文件,需比較通過SHA-1算法自動計算出的網頁文檔的哈希值,若相同則不保存,反之保存。
回放差異采集保存網站時,如果存在保存的文件,則顯示該文件,如果當時沒有文件,則顯示最近保存的同名文件。被保存的文件因為擁有相同的哈希值,所以即使采集時間不同,也可以在保持原始狀態的同時對其進行再現。
通過差異采集,不但可以減少要保存的文件數量,而且可以減少保存文件所需的存儲空間。如前所述,WARP項目每月都會對國家機關的資源進行采集,每季度對其他機構進行采集。經測試,與完全采集相比,差異采集方式約能減少70%的采集量。換言之,差異采集所需的存儲容量約為全部館藏的30%。通過差異采集方式進行采集,有效地節省了互聯網資源存檔的存儲空間。
2.3 互聯網資源存檔的內容組織
為了給用戶提供更好服務,日本國立國會圖書館對采集到的網站進行了深度加工,分別是網址深加工、元數據編目、全文內容挖掘的處理。
2.3.1 網址深加工
采集網站回放的URL雖與原始URL不同,但保留了與原始URL的關系。圖書館回放地址通過兩種形式呈現,即日期和網址組合、標識符和網址組合。
日期和網址組合的回放網址由三部分組成,即互聯網資源存檔域(http://web.archive.org/web/)、日期(20040618115539)和原始URL(/http://www.meti.go.jp/),其表示該網址是在2004年6月18日11:55:39開始采集的。
與日期和網址組合不同的是,標識符和網址組合將日期替換為標識符信息(info:ndljp/pid/285403/),而其他則保持不變。
2.3.2 元數據編目
日本國立國會圖書館會根據文檔大小、用戶需求和目標內容3個方面來控制元數據的粒度。
(1)在批量采集的情況下,由于文檔數量巨大,難以提供細粒度的元數據;而在選擇性采集的情況下,由于文檔數量很小,因此會提供相對詳細的元數據。
(2)互聯網資源存檔內容最終的目的是服務用戶,因此元數據應滿足一般用戶的需求。當用戶需要詳細的元數據時,圖書館會盡可能提供。
(3)元數據的粒度還取決于目標內容。按特定目標采集互聯網資源時,在采集之前,會將標題、發布者和時間等元數據添加到待采集的目標互聯網資源中。發布網站時,一部分會直接使用原始網站的元數據,如標題、發布者和原始URL;一部分會在原有基礎上增加一些必要的元數據字段,如摘要、主題事件、主題人物和關鍵詞等,因此元數據并不統一。此外,圖書館會從保存的網站中提取出特定的出版文檔,如白皮書、會議資料、報告、年鑒和論文,并為其添加詳細的元數據。這樣,用戶就可以集中、有效地搜索和瀏覽散布在整個互聯網網站上的出版物。
2.3.3 全文內容挖掘
互聯網資源存檔的搜索服務與元數據編目是互補的關系,但是只基于元數據的搜索服務并不完善,因為透過元數據搜索不會搜到存檔內容的詳細信息,因此在元數據搜索的基礎上還需開發全文搜索服務。目前,全球60%的互聯網資源存檔機構都具備全文搜索功能。
日本國立國會圖書館WARP項目利用開源軟件Solr進行二次開發,在Solr服務器上使用warc-indexer插件對存檔文件進行索引,實現對所有采集資源(html頁面、pdf、不同媒體類型的元數據、URL等)的全文和元數據檢索。全文檢索功能除了需要對存檔內容進行索引加工外,還需要硬件設備的支持,由于全文索引和搜索需要具備高速計算和快速響應的搜索服務器,同時由于存檔網站的數量巨大,因此還需要具備快速讀寫的存儲設備。
2.4 互聯網資源存檔保存技術
無論是書籍還是數字內容,圖書館都必須保證其保存的內容可以長期使用(100年或更長)。這種措施和嘗試被稱為長期保存。
2.4.1 存檔資源內容的保存技術
互聯網資源存檔的長期保存主要通過數據冗余和不同介質備份兩種方式完成。
數據冗余主要用于防止由于硬盤故障而導致的數據丟失,目前通過使用RAID(磁盤冗余陣列)等技術來實現。
不同介質備份主要是定期將硬盤上的數據備份到光盤等其他介質,以保留多代數據。劃分存儲位置以進行風險分配(災難恢復)也是防止數據丟失的一種重要手段。數據的存儲介質需要存儲在穩定的物理環境中,并且需要定時進行介質轉換以防止存儲介質的劣化。
2.4.2 存檔資源質量的保存技術
互聯網資源存檔不僅要保存數據內容,而且要保證數據能被正常使用。日本國立國會圖書館采用數據遷移和虛擬軟件的方法來保證數據的可用性。
數據遷移是文件由于硬件或軟件環境的變化,在技術上變得不可讀之前,需要轉換格式或遷移到另一種存儲介質的方法。例如,使用老式處理軟件創建的文件轉換為最新的處理軟件的數據格式,或者在硬件設備更改時將介質從軟盤更改為光盤來保存數據。
虛擬軟件是在新的硬件和軟件環境下,模擬原來的文件和軟件的使用環境。例如,可以通過使用虛擬軟件在最新的Windows環境中重現Windows 3.1環境來使用僅在Windows 3.1上運行的軟件。
為了有效地管理和實施數據遷移和虛擬仿真,有必要創建與保存相關的元數據,以記錄數據存檔時的播放設備、播放環境、創建應用程序、文件格式版本等。通過將存儲在元數據中的信息與最新的技術趨勢進行比較,可以及時掌握文件的過時情況并進行數據遷移和準備合適的虛擬仿真環境。
2.5 互聯網資源存檔的發布
2.5.1 互聯網資源存檔發布范圍
在世界各地的互聯網資源存檔機構中,很少有將其存儲的所有內容無條件地發布在互聯網上,資源的發布經常受到一些限制,如訪問的位置、資格、范圍等。
存檔機構采集并保存資源必須要使用它,否則毫無意義。日本國立國會圖書館綜合考慮版權、個人信息和許可條件等采用了不同的發布形式。對于法律允許的采集內容在互聯網上公開發布。對于一些版權要求嚴格或者包含許多個人信息的資源,出于研究目的,只在圖書館內部發布。
2.5.2 互聯網資源存檔的發布形式
日本互聯網資源存檔項目為了給用戶提供更好的服務,通過多種形式對采集資源進行發布。①網站搜索服務:將采集的資源進行整合、編目、索引發布到官方網站上,用戶通過搜索找到自己所需資源,這是世界上通用的發布形式。②專題服務:每月確定一個專題,按照專題的需求整合存檔內容,發布到專題頁面。③特色服務:將采集的內容進行整合和深度挖掘,通過可視化和數據再加工的形式展示給用戶,讓用戶能更加直接地了解存檔項目的使用價值。④歷史網站服務:日本用戶通過瀏覽器瀏覽網站如果出現錯誤或者打不開時,將提供跳轉到WARP歷史網站界面選項,進入后可以選擇不同采集日期的頁面,讓用戶能夠瀏覽被修改和刪掉的網站內容。
3 日本互聯網資源存檔對我國的啟示
3.1 開發互聯網資源存檔的采集軟件
目前國內存檔機構還在采用完全采集的方法對網站進行采集,這導致許多數據被重復采集,造成人力資源和存儲資源的浪費。日本國立國會圖書館利用差異采集方法實現了只采集修改的網站數據,節省了時間和存儲空間。
隨著互聯網的快速發展,越來越多的資源需要采集,差異采集方法是必然趨勢。我國存檔機構目前正面臨采集數據量快速增長導致存儲空間不夠的問題,而差異采集能夠減少存儲空間的占用從而提高采集效果,因此國內存檔機構可以借鑒現有的差異采集軟件,如DeDuplicator、OutbackCDX和warcrefs的技術經驗,開發出適合中文數據資源的差異采集軟件[7-9],解決存儲空間不夠的問題。差異采集方法實現之后,不但能夠解決國內存儲空間緊張的問題,還能解決后期發布人工刪除重復頁面的工作,大大節約了人力和時間成本。
3.2 建立互聯網資源存檔的元數據庫
中國國家圖書館互聯網資源存檔項目的編目僅采用一種統一的編目格式,并沒有針對文檔大小、用戶需求和目標內容控制元數據的粒度。中國互聯網資源存檔數據量巨大,國家圖書館由于受到人力和財力的限制,像日本一樣將元數據添加到所有互聯網資源存檔內容中是不現實的。當前國內圖書館互聯網資源存檔項目采集的資源隨著互聯網的發展越來越多,單獨通過網址查找資源已經不能滿足用戶的需求(并不是所有用戶都知道準確的網址),因此亟需建立自己的元數據庫,讓用戶能夠通過元數據準確查找資源。雖然因存檔數據量巨大,無法通過人力實現對所有的存檔數據建立詳細元數據庫,但是可以借鑒日本國立國會圖書館的經驗,將采集的出版物提取出來,單獨制作詳細的元數據,為用戶提供服務。
中國互聯網資源存檔解決用戶通過元數據查找資源的需求,需要開發一套資源采集系統,理解所采集網站的內容,并利用語義網等技術自動添加元數據。存檔編目還可以引入社交標簽的機制,讓用戶自行將主題的元數據添加到正在觀看的內容當中。元數據庫建立后不但能讓用戶通過元數據準確查找資源,而且還能通過元數據建立資源之間的關系,提供關聯服務。
3.3 強化互聯網資源存檔的長期保存
互聯網資源存檔不僅是把網絡資源做一個備份存儲下來,而且還要保證采集到的資源能夠通過瀏覽器回放。國內存檔機構目前還處在擴大采集規模和數量的階段,對于保存只是做了硬盤備份和服務器RAID設置,并沒有考慮到資源的長期使用和長期保存。
日本國立國會圖書館從存檔數據長期保存和長期使用的角度出發,在硬件上利用服務器RAID設置和定時轉換存儲介質的方法來保證數據的長期完整性,在軟件上利用數據遷移技術和虛擬軟件的方式來保證數據的實用性。中國存檔機構可以借鑒日本的經驗,根據國內存檔情況制定定時存儲介質轉換計劃和積極開發虛擬軟件模擬資源的原始運行環境,保證存檔的數據能夠長期保存和使用。互聯網資源長期保存的目的就是讓消失和被修改的資源能夠以原始的樣式重新展示,讓更多的人通過互聯網存檔計劃了解真實的歷史和文化,因此保證長期保存數據的可用性是十分重要的。
3.4 完善互聯網資源存檔的法規建設
合法性通常是網絡資源存檔面臨最大的非技術性問題[10-11]。在所有者沒有明確許可的情況下,是否擁有復制內容和提供獨立于原始網站訪問的合法權利?是否侵犯了所有者的版權?一些網站明確標出了版權許可或版權授權信息,如知識共享或官方版權,可以部分解決網絡存檔合法性問題。但是,很大程度上取決于有關國家規定和存檔機構的職權范圍。
日本國立國會圖書館采用法律授權和創建者授權的方式,解決了互聯網資源采集和服務的合法性問題。目前,中國國家圖書館正在積極準備互聯網資源存檔相關法律的提案,如果提案被通過,國家圖書館將能夠對互聯網信息進行復制、編輯、長期保存和公共服務。在此之前,國內存檔機構需要積極與網站創建者溝通獲取采集和發布權限,盡最大可能保存即將消失的互聯網資源。
3.5 加強互聯網資源存檔的國際合作
中國的互聯網資源采集機構主要有國家圖書館、北京大學、國家檔案館、臺灣圖書館和臺灣大學圖書館。不同機構雖然采集策略不同但還是有重合的地方,會形成對一個站點重復存檔的問題。國內存檔機構的交流與合作有助于避免網站的重復采集和技術升級,實現更大規模的互聯網資源存檔。
日本國立國會圖書館積極參與國際交流,利用開源軟件進行二次開發,實現了互聯網資源存檔的快速發展。因此,國內存檔機構應積極參與國際交流并吸收國外經驗,讓國內互聯網資源存檔盡快達到國際標準。互聯網資源存檔是一個全球化的工作,國際交流和合作是必不可少的,通過交流不但能夠獲取先進的技術,而且保證了所保存的內容符合國際標準。
4 結語
隨著互聯網的快速發展,越來越多的行業從線下轉到了線上,在網絡上產生了大量有價值的資源,同時由于互聯網資源與實體資源相比具有壽命較短的不足,互聯網資源存檔勢在必行。但目前中國互聯網資源存檔還處于初級階段,沒有完善的法律保障、先進的技術支持和充足的資金保證,因此面對海量的網絡資源,如何進行批量采集、加工、編目、保存和發布,突破知識產權和采集技術兩大難題,成為亟待解決的問題。日本國立國會圖書館互聯網資源存檔項目的成功,為我們做了很好的示范和啟示,我們應該吸收和借鑒日本的成功經驗,包括差異采集方式、元數據規范、長期保存技術等,建立完善的法律法規、加強國內外交流學習先進的采集技術,建設適合中國的互聯網資源存檔項目,實現中國互聯網資源存檔的快速發展。
[1] Internet Archive[EB/OL].[2020-09-07]. https://archive.org/about/.
[2] 國立國會図書館インターネット資料収集保存事業(WARP)[EB/OL].[2021-01-02]. https://warp.da.ndl.go.jp/.
[3] 國立國會図書館インターネット資料収集保存事業統計[EB/OL].[2020-05-11]. https://warp.da.ndl.go.jp/info/WARP_statistic.html.
[4] 國立國會図書館法によるインターネット資料の収集について[EB/OL].[2021-01-02]. https://warp.da.ndl.go.jp/bulk_info.pdf.
[5] 陳瑜. 日本國立國會圖書館網絡信息資源采集保存項目介紹研究[J]. 圖書館雜志,2014,33(3):91-94.
[6] 閆曉創. 日本網絡資源存檔項目實踐研究[J]. 浙江檔案,2017(12):20-23.
[7] 孟慶浩. 互聯網數據增量采集系統的設計與實現[D]. 北京:北京郵電大學,2015.
[8] 孟慶浩,王晶,沈奇威. 基于Heritrix的增量式爬蟲設計與實現[J]. 電信技術,2014(9):97-101.
[9] 高婷,白如江. 基于OutbackCDX的增量式Web信息采集研究[J]. 山東理工大學學報(社會科學版),2020,36(4):99-105.
[10] 陸媛媛. 《公共圖書館法》應關注網絡信息資源長期保存問題[J]. 安徽電子信息職業技術學院學報,2017,16(1):104-107.
[11] 張林華,徐維晨. 淺析國外網頁檔案實踐及其對我國的啟示[J]. 檔案與建設,2020(6):9,38-41.
Research and Enlightenment of Internet Resource Archiving in the National Diet Library of Japan
YANG YunPeng
( National Library of China, Beijing 100081, China )
The National Diet Library of Japan started the internet resource archiving project WARP in 2002 and has established a complete system. This paper gives a detailed introduction to the internet resource archiving project of the National Diet Library of Japan from four aspects of website screening, collection technology, website processing and preservation technology. Meanwhile, it puts forward a proposal for China to carry out internet resource archiving from five aspects of collection methods, legal construction and international exchanges to get better development.
Internet Resource Archive; Website; National Diet Library of Japan; Collection
G279
10.3772/j.issn.1673-2286.2021.01.004
楊云鵬. 日本國立國會圖書館互聯網資源存檔研究與啟示[J]. 數字圖書館論壇,2021(1):24-31.
楊云鵬,男,1986年生,碩士,工程師,研究方向:數字資源整合與互聯網資源存檔,E-mail:syzyyp@126.com。
(收稿日期:2021-01-02)
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
文苑(2019年20期)2019-11-16 08:52:12
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
小天使·一年級語數英綜合(2014年8期)2014-06-26 14:42:04
