基于中心點的多類別車輛檢測算法
2021-04-13 01:59:04梁禮明彭仁杰藍智敏
科學技術與工程 2021年7期
梁禮明, 熊 文, 彭仁杰, 藍智敏
(江西理工大學電氣工程與自動化學院, 贛州 341000)
隨著中國經濟的飛速發展,機動車數量逐年遞增,每年發生的交通事故不計其數,如何通過先進的車輛檢測技術減少交通事故的發生已成為城市交通管理的一項重要工作[1]。
車輛檢測作為目標檢測領域的重要研究內容,在智能交通、車輛跟蹤、無人駕駛等領域具有廣泛的應用需求和重要的研究價值[2]。自深度學習在圖像分類任務[3-4]中取得巨大成功后,基于深度學習的方法被廣泛用于目標檢測任務中,諸如Faster R-CNN[5]、SSD[6]、YOLO[7]等通用目標檢測算法均取得了不錯的效果。上述方法均采用了目標檢測領域流行的錨框機制來遍歷特征圖生成目標的候選區域,但是錨框的長寬比和尺度需要根據特定的數據集預先設計,常用的方法為采用K-means算法[8]或K-means++算法[9]通過特定數據集的真實邊界框進行聚類,從而得到初始錨框的參數,聚類值的選擇對最終生成的錨框參數影響較大,從而產生不同的聚類偏差,并最終影響到模型的綜合性能。
針對此問題,有關學者嘗試采用關鍵點的方法來對目標定位和分類。Law等[10]提出通過計算目標的一對左上角點和右下角點來回歸出目標的位置,但是在海量的角點信息中分辨出屬于具體的目標時存在精確度差和耗時過久的問題,從而導致大量不正確的檢測框產生。Duan等[11]提出在一對角點中增加一個中心點,形成的關鍵點三元組(左上角點、中心點、右下角點)可以更準確地定位檢測框位置。Zhou等[12]提出用4個極值點來和1個中心點來生成目標的真值熱圖[10],并以此預測出目標的位置。上述三種方法采用的關鍵點個數較多,在后續步驟中需要額外對關鍵點進行分組,檢測效率不高。
為了提高檢測效率,現借鑒Centernet算法[13]設計思路,采用中心點檢測的方法回歸車輛的邊界框和類別信息。
1 算法原理
1.1 算法流程
本文算法流程如圖1所示。具體地,首先將輸入圖像大小調整為512×512像素,并采用兩次步長為2的卷積操作將圖像分辨率縮小4倍;然后通過特征提取網絡Hourglass反復提取車輛特征,得到車輛不同層次的特征信息;車輛特征信息經預測模塊處理后輸出3個預測分支,分別預測車輛中心點位置、車輛檢測框尺度和車輛中心點位置偏移;最后基于預測信息回歸出車輛檢測框,完成最終的車輛檢測任務。

圖1 算法流程Fig.1 Algorithm process
1.2 車輛特征提取網絡
采用堆疊沙漏網絡Hourglass[14]車輛特征提取網絡,網絡結構如圖2所示。Hourglass網絡采用2個堆疊的沙漏網絡模塊構成,每個沙漏網絡模塊中除中間過渡層外分別進行了5次降采樣和5次上采樣操作,并不斷提取各層次車輛特征信息,低層的卷積層可提取到各種類別車輛的邊緣、線條等局部細節信息,高層的卷積層可從低層獲取的局部細節信息中學習到更為復雜的語義信息。由于深層網絡可能會存在隨著網絡的加深出現梯度消失和梯度爆炸的現象,從而導致網絡性能退化的問題[15]。通過在Hourglass網絡中引入殘差網絡[16]較好地避免了此類問題的發生。由于在Hourglass網絡中反復對輸入圖像進行降采樣和上采樣操作,可能會存在車輛有效特征信息丟失的情況,從而導致最終的檢測模型出現車輛漏檢和誤檢現象發生,通過融合通道數與尺度相同的各層特征圖,保證層與層之間的最大信息流。

圖2 Hourglass網絡結構Fig.2 Hourglass network structure
1.2.1 可變形卷積
在多類別的車輛檢測任務中,常受車輛種類、大小、視覺變化以及非剛體形變等因素的影響,從而導致車輛檢測精度低的問題。傳統卷積模型受其自身固定的幾何結構限制,缺乏幾何形變建模能力,不利于網絡訓練時損失函數的擬合從而導致建模的失敗。為克服上述問題,引入可變形卷積[17]輛特征提取網絡重建,以此提高網絡中各卷積層的車輛特征表達能力。傳統卷積和可變形卷積在車輛檢測中的示意圖如圖3所示,其中采樣點為3×3,可以看出可變形卷積在采樣時更能適應多類別車輛的形狀與尺寸。假設一個3×3卷積k定義為

圖3 傳統卷積與可變形卷積Fig.3 Traditional convolution and deformable convolution
k={(-1,1),(0,1),(1,1),(-1,0),(0,0),(1,0),(-1,-1),(0,-1),(1,-1)}
(1)
對輸入特征圖f(*)采用傳統卷積操作后,在局部位置αλ處的特征映射T可定義為
(2)
式(2)中:w()為采樣點權重值;αn為k的局部位置,n=1,2,…,|k|。在可變形卷積中加入偏移量Δαn的學習之后,可根據不同種類、形狀、尺寸的車輛目標動態調整可變形卷積核的大小和位置,從而高效完成多類別車輛檢測任務。可變形卷積定義為
(3)
1.3 預測模塊與損失函數的設計
在CenterNet算法中預測模塊分為三個預測分支,即中心點位置(x,y)預測、車輛檢測框尺度(w,h)預測、中心點位置偏移(offset)預測。三個預測分支的總輸出可作為車輛檢測框回歸的重要依據。
針對中心點位置采用帶有懲罰項的邏輯回歸損失[18],即
(4)

針對車輛檢測框和中心點位置偏移分別采用L1距離損失函數
(5)
(6)

車輛檢測框和中心點位置偏移均采用L1距離損失函數,但是評價模型性能的重要參考指標是真實框A與預測框B的IoU(intersection over union)。在模型訓練時,L1距離損失函數值通過不斷迭代達到最優時,并不能代表預測框與真實框的重合程度達到最大。若將IoU引入損失函數中,當真實框與檢測框無交集時,無論兩者距離如何變化,IoU始終為零,最終導致模型性能無法進行優化。針對此問題,引入GIoU[19](generalized intersection over union)實框與檢測框重合程度的新標準,GIoU可定義為
(7)
(8)
式中:T表示包含真實框與檢測框的最小封閉框;T(A∪B) 表示最小封閉框區域T不包含A與B的部分。A、B和T的關系如圖4所示。GIoU可作為一種距離度量指標,當A與B無交集時,GIoU可表示為

圖4 A、B和T的關系Fig.4 Eelationship of A, B and T
(9)
當A∪B為定值時,T不斷減小,A與B將不斷向有交集的情況進行優化。
為解決評價指標IoU與目標函數不統一的問題,本文在原有損失函數的基礎上增加一項衡量預測框(Pre)與真實框(Tru)的距離損失,即

(10)
新的組合損失函數為
L=Lc+γ1Loffset+γ2Lwh+LG
(11)
式(11)中:γ1、γ2為損失權重系數,設為0.1和1。
2 實驗分析
2.1 數據集和實驗平臺
本次實驗選用國際公開的KITTI庫[20]和自制數據庫對模型進行訓練和評估,根據實驗要求,將兩數據庫標注格式均轉化為VOC2007數據集格式,保留實驗需要的4個類別標簽(Car、Van、Truck和Tram),并從中篩選出高質量的車輛圖像,最終得到公開數據庫中的7 000張圖像,自制數據庫中的3 000張圖像,訓練集和測試集按3∶1比例劃分。為了有效降低模型過擬合的風險,此次實驗還采用隨機縮放、水平翻轉以及對比度變換等數據增強方法來提高模型的泛化能力。
本次實驗的仿真平臺是PyCharm,使用PyTorch深度學習框架,計算機配置為Intel?CoreTMi7-6700H CPU,16 G內存,Nvidia GeForce GTX 2070 GPU,操作系統為Ubuntu16.04.2。網絡參數配置如下:最大迭代次數為500次;批量大小設置為8;采用學習率衰減的方式訓練,初始學習率為0.000 25,網絡每迭代100次,學習率下調10倍。
2.2 公開數據庫測試結果
實驗采用均值平均精度(mean average precision,mAP)與傳輸速率來評估本文模型的綜合性能,并與目標檢測通用算法Faster R-CNN[5]、SSD[6]、 CornerNet[10]、CenterNet[13]以及YOLOv3[21]對比實驗,所有算法均在公開數據庫上訓練和測試。表1顯示本文算法與其他算法的實驗對比結果。
如表1所示,本文算法在公開數據庫上取得了93.42%的mAP,精度優于其他算法,并以49 f/s的檢測速度達到了實時檢測的要求。表1中前三種算法皆采用錨框機制來遍歷特征圖生成車輛的候選區域,并以此回歸出車輛檢測框信息,其中YOLOv3在精度和檢測速度上都要優于其他兩種算法。后三種算法均采用關鍵點檢測方法回歸車輛類別和位置信息,擺脫了錨框的依賴性,3種關鍵點檢測方法在精度方面好于錨框機制方法。CornerNet算法由于采用目標左上角點和右下角點定位目標檢測框,在目標車輛預測中存在對角點分組的步驟,此步驟增加了網絡計算的復雜度,極大地降低了算法的檢測速度。
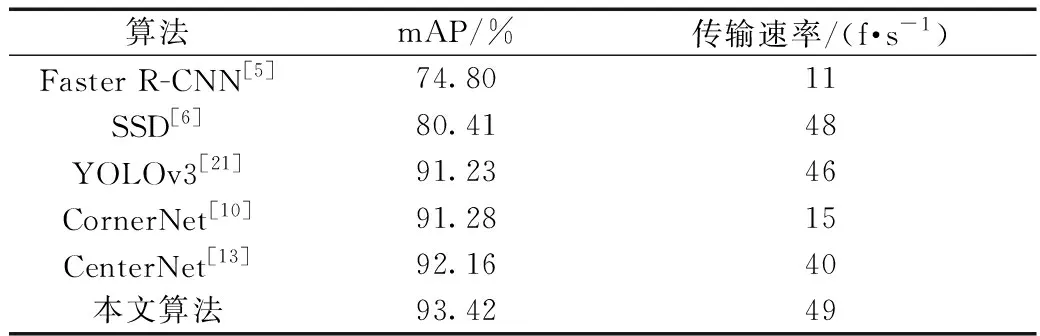
表1 不同算法在公開數據庫上對比結果Table 1 The comparison results of different algorithms on public database
2.2.1 不同改進模塊對模型性能的影響
為了驗證本文算法引進的可變形卷積模塊和GIoU損失模塊對模型性能產生的影響,采用控制變量法,在原CenterNet算法基礎上依次加入以上所提改進模塊,實驗結果如表2所示。
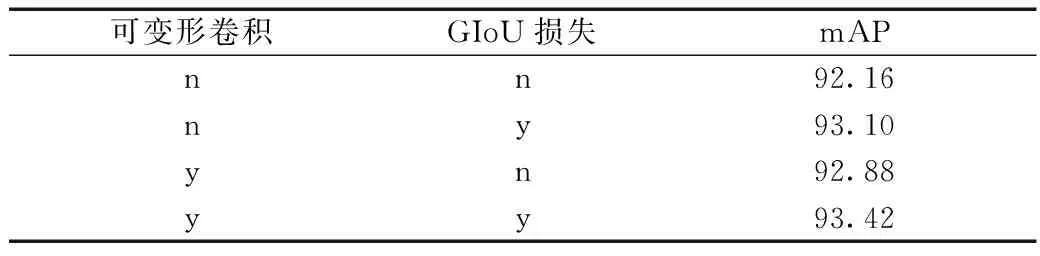
表2 不同模塊對本文模型性能的影響Table 2 The impact of different modules on the performance of the model
當只引入可變形卷積后,模型測試精度相對CenterNet算法只有0.72個百分點的提高;損失函數加入GIoU損失項時,精度提高了0.94個百分點;當同時引入可變形卷積和GIoU損失項時,模型精度得到最大提升。
2.3 自制數據庫測試結果
為了驗證本文算法在其他車輛數據集上的檢測性能,在自制數據庫上對本文算法和CenterNet算法進行訓練和測試,其中測試集有圖像1 000張,圖像中總共含有車輛數目為3 253輛。通過比較兩種算法在車輛檢測時出現漏檢和誤檢的情況,得到測試結果如表3所示。
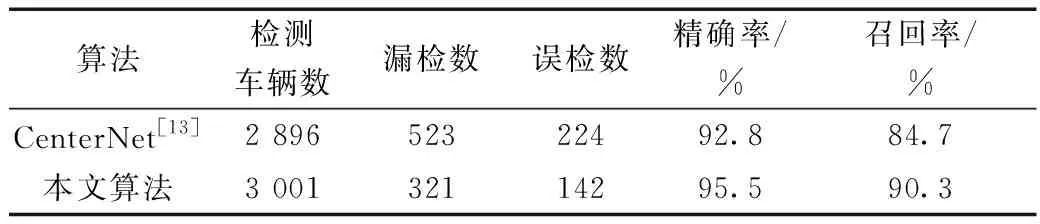
表3 原算法和本文算法對比結果Table 3 The comparison results of the original algorithm and our algorithm
本文算法相比原算法在自制數據庫上也具有一定的優勢性,不僅減少了車輛漏檢情況的發生,同時也降低了車輛誤檢數。本文算法相比原算法精確率和召回率分別提高了2.7%和5.6%,這充分說明本文算法可適應不同場景下的車輛檢測任務。
2.4 本文算法在公開數據庫和自制數據庫的檢測效果
將兩種數據庫中的圖像輸入到本文模型中測試,得出部分圖像檢測效果如圖5所示,其中檢測框左上角為目標車輛類別和score,IoU閾值設置為0.7,score閾值設置為0.3,每張圖像的下方顯示了從圖像最左端到最右端依次檢測出的目標類別及score。圖5中前3張圖像來源于公開數據庫,后3張圖像來源于自制數據庫,公開數據庫中目標車輛個數較多,背景中非檢測目標對待檢測目標車輛的分類和定位產生一定的干擾。從圖5中可以看出本文方法在多類別車輛檢測中,檢測框與目標車輛重合程度大,誤檢、漏檢和重復檢測現象較少。

圖5 兩種數據庫中的部分圖像檢測效果Fig.5 Partial image detection effect in two databases
3 結論
借鑒通用目標檢測算法CenterNet思路,將其應用到多類別車輛檢測任務中。針對車輛類別多及形狀大小各異等檢測難點,引進可變形卷積對CenterNet網絡重建,提高網絡對各種車輛特征提取能力。考慮到CenterNet損失函數的局部最優時不等價于模型評價指標IoU的局部最優,通過引進GIoU損失使原損失函數更為合理。在公開數據庫和自制數據庫上的仿真實驗結果表明,本文算法的綜合性能要優于其他算法。在后續工作中,將對算法流程進行簡化,使車輛檢測速度與精度得到更大的提升。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
財經(2016年3期)2016-03-07 07:44:46
