基于多特征圖像視覺顯著性的視頻摘要化生成
2021-04-13 01:59:12金海燕曹甜肖聰肖照林
北京航空航天大學學報 2021年3期
金海燕,曹甜,肖聰,肖照林,*
(1.西安理工大學 計算機科學與工程學院,西安710048; 2.陜西省網絡計算與安全技術重點實驗室,西安710048)
如何以最為直觀且快速的方式查閱視頻數據,完成像文字搜索一般的瀏覽效率是計算機視覺與圖像處理領域的研究熱點。視頻摘要是對原始視頻內容的高度濃縮,其將重要且具有代表性的視頻內容以一種簡潔的形式呈現出來,方便用戶對視頻的瀏覽和管理[1]。
2017年,劉全等[2]使用帶視覺注意力機制的循環神經網絡(RNN)改進了傳統的深度Q網絡模型,提出了一種較為完善的深度強化學習模型。2018年,郎洪等[3]提出一種魯棒主成分分析(RPCA)優化方法,為了快速篩選與追蹤前景目標,以基于幀差歐氏距離方法設計顯著性目標幀號快速提取算法。2019年,張芳等[4]為準確檢測復雜背景下的顯著區域,提出了一種全卷積神經網絡與低秩稀疏分解相結合的顯著性檢測方法,結合利用全卷積神經網絡學習得到的高層語義先驗知識,檢測圖像中的顯著區域。李慶武等[5]針對現有顯著性檢測算法檢測目標類型單一、通用性差的問題,提出了一種基于無監督棧式降噪自編碼網絡的顯著性檢測算法。2020年,陳炳才等[6]提出了一種融合邊界連通性與局部對比性的圖像顯著性檢測算法,得到的顯著圖更接近于真值圖。
由于現有視頻數據量過于龐大,占用內存資源較多,在瀏覽時比較困難。本文基于多特征圖像和視覺注意力金字塔模型,提出了一種改進的可變比例及雙對比度計算的中心-環繞視頻摘要化方法,通過提取的關鍵幀快速理解視頻的主要內容。本文方法不僅易于實現,還改善了傳統方法的提取效果。在Segtrack V2、ViSal及OVP數據集上進行仿真實驗,驗證了本文方法的有效性。
1 相關工作
1.1 視覺顯著性
在某一場景中,能夠令人眼所引起注意的區域就是該場景中最顯著的區域,場景其余部分則可能不會被人眼所注意或考慮在內。通過不同方式滿足人眼的機制并遵循人眼視覺習慣所進行的檢測,即為視覺顯著區域的檢測。
2017年,Ablavatski等[7]設計了一種改進的基于注意力的體系結構,用于多對象識別;Qu等[8]為了解決僵化的描述問題,提出了一種神經和概率框架,將卷積神經網絡(CNN)與循環神經網絡相結合,以產生端到端的圖像字幕。2019年,Liu和Yang[9]提出了一種“前景-中心背景”顯著區域檢測模型,提高了顯著性檢測的性能。
1.2 視頻摘要化
現有的大部分視頻摘要都為靜態視頻摘要。2016年,Li等[10]開發了一種用于在Internet上搜索結果的多媒體新聞摘要的新穎方法,可發現與查詢相關的新聞信息中的基本主題,并將每個主題中的新聞事件穿線以生成與查詢相關的簡要概述。2018年,Hu和Li[11]通過融合基于多個特征和圖像質量的全局重要性和局部重要性來生成動態視頻摘要。Meng等[12]選擇在不同視圖之間代表視頻的視覺元素,使用質心共正則化方法的多視圖稀疏字典選擇,優化了每個視圖中的代表性選擇,并通過將它們針對共識選擇進行正則化來強制將視圖特定的選擇相似。
1.3 關鍵幀提取中的圖像特征
顏色特征作為較為常見和易于獲得的信息為特征提取時所廣泛采用。除了顏色以外,圖像的紋理也是視頻摘要化的常見特征。作為一個圖像或物體表面具有的固有特性,紋理特征通過空間中的某種形式的顏色變化而產生不同的圖案,并通過對圖像進行量化產生特征結果。LBP(Local Binary Pattern)算子是最常見的原始特征算子之一,所提取出的特征即為圖像中局部位置的紋理特征。
2 顯著性檢測
2.1 超像素分割預處理

2.2 雙對比度金字塔顯著性檢測
計算RG、BY顏色分量及亮度特征分量。其中,亮度分量Intensity=(R+B+G)/3,紅-綠顏色分量RG=R-G,黃-藍顏色分量BY=B-(G+R)/2。對已進行超像素分割的圖像序列,為每一個圖像特征通道構建中心金字塔與環繞金字塔的尺度空間。設每一個圖像的中心金字塔為C,C={C0,C1,C2,…,CN},每一個圖像的環繞金字塔為s,s={S0,S1,S2,…,SN}。本文N的值為5,即金字塔的層數為5。同樣,每一個中心金字塔圖像Ck都有一個與之對應的環繞金字塔圖像Sk。其中,環繞金字塔圖像Sk是由中心圖像經過高斯平滑處理所得到。高斯平滑因子為

式中:μs為環繞金字塔圖像Sk的平滑因子值;μc為用于得到中心金字塔圖像Ck對應的值。因此,算法可以自由動態地調整平滑因子的值大小,產生更多的靈活性來適應系統,從而在之后的計算中得到更好的效果。
對每一個圖像特征通道計算中心-環繞對比度。設中心金字塔中第i層圖像為Ci,環繞金字塔中第i層圖像為Si,由式(2)、式(3)分別得到正-負對比度Contrast+和負-正對比度Contrast-。

同時,將數值中所有小于0的特征值統一設為0。在得到對比度結果后,將所有特征圖按照正-負對比度與負-正對比度2類進行加法求和。
2.3 光流信息提取
設像素點p(x,y)在某個時間段t內移動的距離為(d x,d y),原像素點表示為p(x,y,t),變化移動的點表示為p(x+d x,y+d y,t+d t),考慮亮度恒定的情況,得到

根據亮度恒定得到的公式以灰度值進行空間坐標位置求導,得到泰勒級數展開公式,進一步得

d x/d t、d y/d t分別為X、Y軸方向點以灰度信息來描述的值的變化速率,設為U、V;而?p/?x、?p/?y、?p/?t分別為二維圖像上X、Y、t方向的偏導,設為px、py、pt,由此得到光流法公式:

px、py、pt即為根據圖像序列在(x,y,t)上的差分。由于式(6)中存在2個未知變量的情況,在求得式(6)后,需要多加一個約束式來得到光流場計算結果。這里使用Lucas-Kanade光流法方式來增加約束。
2.4 前后幀圖像抑制法的光流檢測
在動態檢測時,可能會由于經常引入不相關的背景或線條輪廓內容,對檢測產生較大影響,且在融合時并不能完全削減這部分噪聲。以顏色直方圖方式統計前后圖像內顏色的占比,設當前幀的顏色直方圖為Histi,前一幀為Histi-1,若相鄰2幀相似度較高,則2幀之間的相似性可以描述為

式中:j為顏色分量;N為總顏色量級數目;j∈N;D為2幀的相似性表示。
因此,構建加權函數W如下:
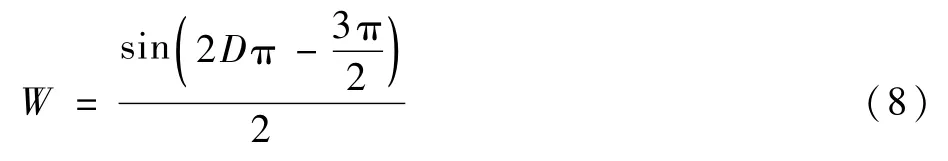
最終融合時,按式(9)進行:

式中:Mi-1表示前一幀圖像的運動顯著性結果;Mi表示當前幀的運動顯著性結果;M為最終運動顯著圖。

圖1 動態顯著圖調整效果前后對比Fig.1 Effect comparison of dynamic saliency map before and after adjustment
圖1展示了經過調整前與調整后的動態顯著圖效果,并用橢圓形標出了調整后產生改進的區域。
2.5 顯著性圖像計算及自適應融合
設Mi為運動顯著結果,Ji為靜態顯著結果,通過difi將權重系數歸一化至[0,1],如下:

并通過式(11)完成融合:
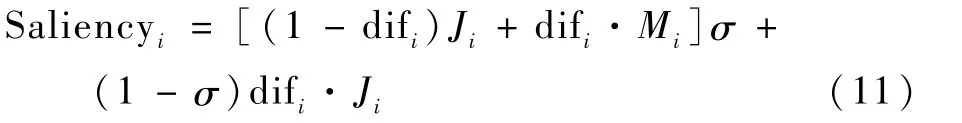
式中:σ為比例系數,本文設為0.4。
顯著結果自適應融合如圖2所示。

圖2 顯著結果自適應融合Fig.2 Adaptive fusion of saliency results
3 關鍵幀提取
在關鍵幀提取前,對連續視頻圖像序列進行顯著性目標檢測的目的是為了能夠預先完成顯著前景目標的提取,同時提升關鍵幀提取階段的檢測準確率與效果。本節主要方法內容和整體技術框架如圖3所示。

圖3 關鍵幀提取主要方法內容和整體技術框架Fig.3 Main method content and overall technical framework of key frame extraction
3.1 LBP紋理特征提取
通過尺寸為3×3的基準檢測窗口進行0、1標記,形成二進制的特征值結果,如下:
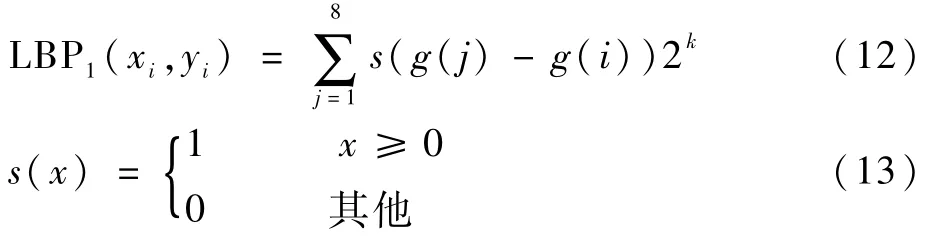
式中:g(j)為基準窗口內第j個點的灰度;g(i)為中心點對應的值。
根據旋轉不變原則,最終的特征值為

3.2 顯著性檢測效果增強及顏色特征提取
取顯著性檢測結果與原始視頻中同一幀圖像進行對應相乘。先得到原圖像R、G、B分量,設為fR、fG、fB,設當前幀顯著性結果圖像為F,將結果F分別與fR、fG、fB對應相乘,得到增強的顯著性結果F′,如圖4所示。

圖4 顯著性檢測效果增強結果Fig.4 Enhancement results of saliency detection effect
將圖像從RGB空間轉化為HSV空間,再分別提取H、S、V三個分量結果,將H、S、V三通道按照16∶4∶4的等級進行量化;之后將所有的顏色分量按比例等級融合形成特征矢量,如下:

式中:Qs和Qv為量化的等級。
將顏色空間進行量化,并將量化后的顏色根據式(15)進行融合并映射,映射的像素值范圍為[0,255],得到相乘圖顏色信息。
3.3 哈希函數相似性計算
基于內容的感知哈希(Perceptual Hash)函數是一種用于獲取圖像哈希值,并用其來描述的特征相似性表示方法。根據值的對比計算,可以得到2幅圖像基于漢明距離的相似性程度結果。
調整圖像分辨率大小統一至32×32范圍,并轉換多通道圖像為單通道,完成離散余弦變換(DCT)。此步是為了將圖像具有的位置特征轉移至頻域當中,并能夠對圖像進行良好的壓縮,且保持無損轉換。基于DCT的對稱變換方式,待圖像轉為頻域下的特征編碼后,反方向DCT得到原先的特征信息,具體的DCT變換如式(16)、式(17)所示。
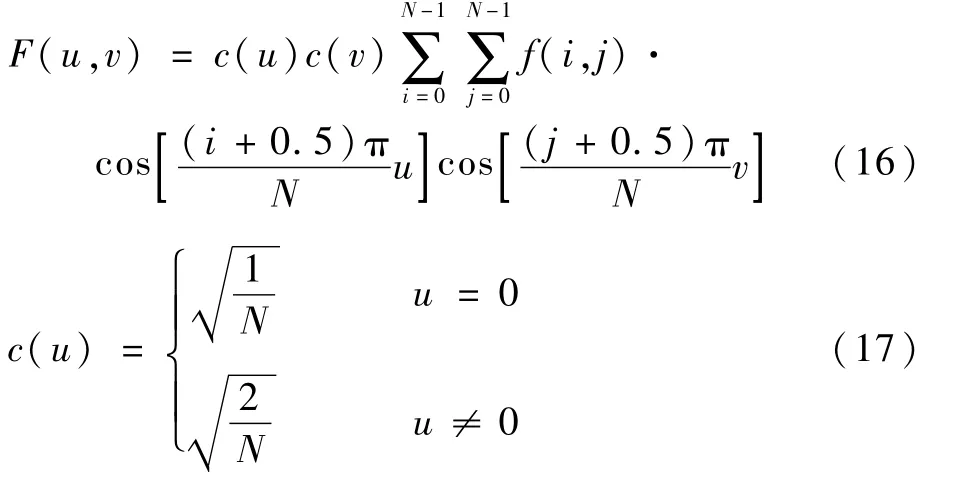
式中:F(u,v)表示DCT變換結果;N為像素點的數量;c(u)c(v)為DCT變換中的正交變換矩陣;f(i,j)為DCT變換前原始像素點的值。
在得到32×32大小的圖像區域后,只取圖像矩陣中左上角位置中大小為8×8區域的像素點坐標值矩陣,此部分區域可以表示整幅圖像當中頻率信息最低的區域。按式(18)計算圖像區域內64個像素點的平均像素大小ˉp′:

式中:pi為像素點大小。
計算比較像素點與ˉp′的大小得到完整的pHash值,即圖像的感知哈希值,并計算2個不同圖像間pHash值的漢明距離。
3.4 基于哈希函數互信息計算
互信息是指在2個不同的個體中,相互之間包含對方信息內容數量多少的描述,屬于信息論理論范疇,其基于熵的概念來進行2個物體的計算,公式如下:
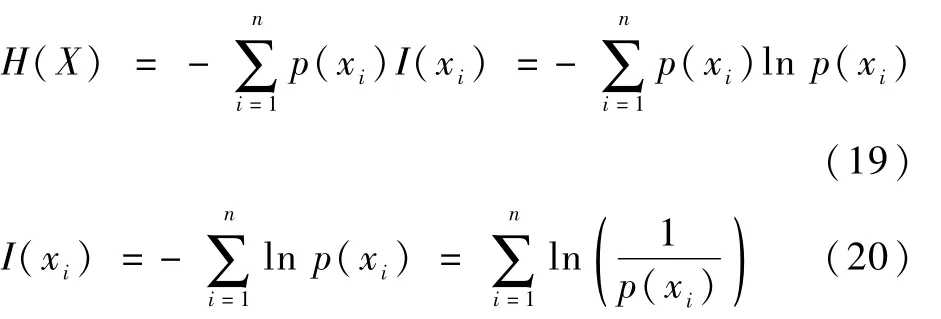
式中:p(xi)為基于事件xi的概率數值;I(xi)為具體內容信息的量。則2個隨機變量間熵對應的聯合信息期望值可表示為

若(x,y)對應的聯合分布用p(x,y)表示,對應的邊緣分布用p(x)、p(y)表示,聯合與乘積分布p(x,y)、p(x)p(y)相對熵的結果即為I(x,y),即互信息:

根據式(20),得到對于圖像中的互信息為

本文基于感知哈希函數進行圖像相似性計算,結合連續前后幀圖像的pHash圖像,進行相似性計算。
圖3中展示了2018年羽毛球湯姆斯杯丹麥對陣馬來西亞比賽視頻中第280幀、第281幀、第282幀圖像中的感知哈希圖像結果。其中,第280幀和第281幀屬于同一鏡頭下的相似場景圖像,而第281幀及第282幀圖像則發生了跳變,圖中展示了這連續3幀圖像的互信息值變化。
3.5 摘要化生成
將得到的所有圖像的紋理信息、所有顯著增強圖像的顏色信息及光流法得到的光流信息進行融合,將每個特征圖像對應的圖像矩定義為矩陣A、B、C并按列拼接,形成融合的特征向量矩陣[A B C]。計算前后2個特征矩陣之間的歐氏距離,其距離定義為其中所有元素間歐氏距離的累加和。根據歐氏距離計算特征矩陣之間的相似性,以距離的平均值進行冗余幀剔除,小于距離平均值的幀被舍棄。


假設滿足式(26)的最小I(X,Y)值為篩選分界值:
小于此值的圖像幀分為一類,否則另歸為新的一類,得到劃分后的關鍵幀類別序列f2={Cluster1,Cluster2,…,Clustern}。
設已劃分的2個相鄰關鍵幀集合Cluster1與Cluster2的互信息值為MI(Clusteri,Clusteri+1),則MI(Clusteri,Clusteri+1)=

式中:n1和n2分別為關鍵幀類別Clusteri和Clusteri+1中圖像的數量;MI為結果,即當前關鍵幀類別集合與關鍵幀類別集合的圖像互信息值,定義為2個集合中所有圖像與除本身之外的所有其他圖像的互信息值和的平均值。
根據特定閾值進行關鍵幀分類結果合并。將2個集合的互信息值與閾值進行比較,合并規則與相鄰圖像間的篩選方式相同,最終得到經合并后一定數量的分類集合f3={Cluster1,Cluster2,…,Clustern}。最終挑選每一集合中與集合內其余圖像MI相比最大的圖像幀為當前集合的代表。
4 實驗及分析
4.1 顯著性數據集
在顯著性檢測的過程中,實驗所使用的圖像數據來源于Segtrack V2、MSRA[3]及ViSal數據集。Segtrack是一種視頻對象分割數據集,同時也作為顯著性檢測的數據集,Segtrack V2是Segtrack數據集的擴大版本,主要包含人類奔跑、鳥類、獵豹、羚羊等動物的運動視頻;MSRA則包含約5 000張圖像,囊括了各類場景圖像,且都包含了真值圖像ground truth;ViSal則同樣是用于目標檢測的數據集,且其中的數據都是視頻形式。
4.2 視頻摘要數據集
本文所使用的數據集包括了YouTube、OVP(Open Video Project)等公共視頻數據集。以運動視頻為研究對象,采集了網上大量的室內羽毛球比賽運動場景視頻。YouTube數據集格式為MPEG,視頻分辨率大小為352×240;OVP數據集的格式包括FLV和AVI兩種,類型包括新聞、動畫、廣告、電視劇、比賽視頻等不同的場景。室內羽毛球比賽場景視頻則包括2018年世界羽聯年終總決賽男單決賽、2018年羽毛球湯姆斯杯丹麥對陣馬來西亞、2019年世錦賽第二輪戴資穎對陣菲迪亞尼等的比賽視頻,皆為MP4、1 280×720分辨格式。在運動視頻的用戶摘要確定過程中,選擇10位同學進行人工篩選,在預先不告知內容重點的情況下,得到10位同學的關鍵幀摘要結果,并對這10種結果中相似的視頻幀計算幀數平均值得到最終的用戶摘要結果,確保用戶摘要的客觀及合理性。
本文對多特征融入后的距離計算剔除冗余幀的過程中,使用了歐氏距離的平均值作為剔除的閾值。但有時完全通過平均值無法剔除足夠數量的冗余幀,仍然會保留一部分無用的幀,該部分圖像既會對之后的檢測和判斷產生干擾,也會降低整體的計算時間效率。根據數據集類型的不同,在平均值的基礎上加入了微調因子a,對You-Tube、OVP等數據集設置a=2.5,而對比賽視頻數據集設置為a=20。
仿真實驗中,人工閾值thresh可以控制最終生成的摘要所包含圖像數量的多少。thresh越高,所產生的摘要圖像數量越少;反之越多。經過實驗分析,對YouTube、OVP等數據集設置thresh=0.5,對運動視頻數據集設置為thresh=1.2,使得結果達到了最佳。
4.3 顯著性檢測
本文方法主要與MR[14]、SF[15]、FT[16]、GS[17]方法進行對比,實驗結果如圖5所示。
MR方法根據圖像元素與給定種子或查詢的相關性定義圖像元素的顯著性,將圖像表示為以超像素為節點的閉環圖,以提取背景區域和前景顯著對象;SF方法采用基于對比度的顯著性估計抽象出不必要的細節,從元素對比中得出顯著性度量,以將前景和背景分開;FT方法可輸出具有清晰定義的顯著對象邊界的全分辨率顯著圖,通過保留原始圖像中更多的頻率內容,以保留這些邊界;GS方法使用背景先驗來計算圖像的測地線顯著性區域。
從圖5可知,MR方法無法有效區分物體中心和圖像之間的類別差異;SF方法對于背景明亮的物體同樣也會檢測出來,抗干擾性較差;FT方法可以快速地檢測出圖中不同物體間的頻譜差,但無法增加具體的細節信息,只能體現對比度信息;GS方法則與之前方法相比效果有所提升,但仍然會有較大的噪聲干擾存在。本文方法不但能夠準確定位目標,對于前后背景對比度差異較小的圖像也能較好地區分出前景目標。本文以Segtrack V2和MSRA為數據展示顯著性的F-measure柱狀結果差別,如圖6所示。
4.4 實驗結果及分析
本文選用不同類別視頻,如OVP包含的新聞或比賽場景等,并將結果與現有的幾種經典視頻摘要或關鍵幀提取算法(如OV[18]、VSUMM[19]、STIMO[20]、SD[21]、KBKS[22]等)進行對比。圖7為使用公共摘要數據集中的“v20.flv”動畫視頻及“v101.flv”新聞視頻得出的摘要化結果。
從圖7可以看到,在“v20.flv”和“v101.flv”視頻中,OV算法在左側視頻中的第1、4幀產生了冗余,右側視頻中第5幀圖像出現了冗余,同時在左側視頻中的第2、5、6、8幀出現了檢測不準確的情況,檢測結果較差;而在VSUMM算法中,左右2段視頻中誤檢的情況比OV算法相比較少,但仍有冗余的情況;在STIMO算法中,左側視頻有8幀圖像命中了用戶摘要結果,比OV、VSUMM 兩種算法的結果要更好一些,但檢測出的圖片數量較多,也包含了一些冗余的圖像;而在SD算法與KBKS算法中,得到的結果基本都包含了用戶摘要,只有少量誤檢的情況,但得到的摘要數量少于真實用戶標注結果,無法完整地描述視頻的主要內容;在本文中左側視頻產生了13幀摘要結果,其中11幀命中了用戶摘要,同時只產生了2幀冗余,在右側視頻中,得到11幀摘要結果,其中11幀命中摘要,只漏掉了用戶摘要中的第3幀,表現出了良好的摘要化結果。

圖5 數據集在不同方法上的顯著性圖比較Fig.5 Comparison of saliency maps of datasets among different methods
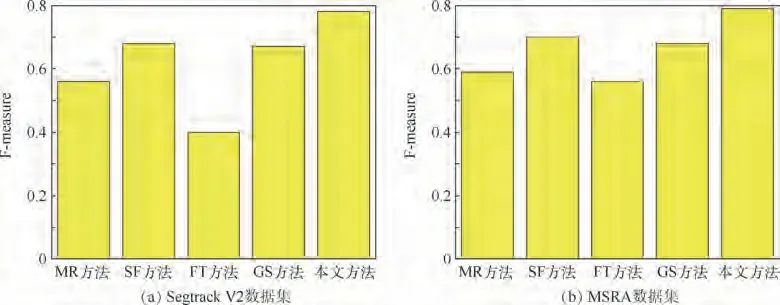
圖6 F-measure在不同數據集上的情況Fig.6 F-measure on different datasets

圖7 視頻“v20.flv”及“v101.flv”在不同摘要算法下的結果Fig.7 Results of video“v20.flv”and“v101.flv”under different summarization algorithms
在圖8中,以2018年世界羽聯年終總決賽男單決賽及2018年羽毛球湯姆斯杯丹麥對陣馬來西亞兩段視頻為準,進行結果分析。由于電視中的運動比賽視頻分辨率較高,且會出現鏡頭停留時間較長的情況,一般方法較容易產生檢測冗余的現象。在OV算法與VSUMM 算法中,都得到了大于用戶摘要數量的關鍵幀,其中對于鏡頭產生移動,但基本內容沒有產生變化的圖像,2種算法都得到了不同數量的相似場景冗余幀。
在OV算法與VSUMM 算法中,左側視頻的第1、2幀及右側的第4、5、8幀都得到了不同數量的相似場景冗余幀;STIMO算法也是相同;SD算法與KBKS算法則出現了更多;在本文方法中,左側視頻雖然得到的摘要結果數量不足,但9幀的結果中都命中用戶摘要,只有漏檢的情況發生,而在右側視頻中得到了足夠數量的圖像結果,用戶摘要共13幀,其中有11幀命中用戶結果,說明了本文方法的高準確性及低誤檢率。
為了更加直觀地描述不同方法在公開數據集及室內羽毛球比賽運動場景視頻數據上的表現,使用準確率、錯誤率、漏檢率、精度、召回率和Fmeasure等指標,分別對實驗數據視頻依次對比,如表1所示。

圖8 運動視頻在不同摘要算法下的結果Fig.8 Results of sports video under different summarization glgorithms

表1 運動視頻在不同摘要算法下的對比Table 1 Comparison of spor ts videos under various summarization algorithms
5 結 論
本文以視覺顯著性模型為基礎,在中心-環繞比金字塔檢測模型中融合超像素分割以加速大分辨率圖像視頻數據的計算,同時選擇雙對比度方式計算、提取圖像中更多的特征信息;在計算運動顯著圖時,通過前后幀結果抑制的方式生成更佳的動態結果,并使用自適應方式融合得到效果良好的顯著結果,良好的顯著性結果也為在視頻摘要與關鍵幀選擇的過程提供了更多的圖像信息。
1)在摘要化生成中,結合了顯著性檢測及感知哈希互信息方式進行提取。在顯著性檢測的基礎上,利用圖像的紋理及顏色等信息,對顯著性檢測的結果圖像進行了二次特征提取并完成相鄰圖像之間的相似性判斷,進行多次冗余幀的剔除及相似圖像的類別劃分,從而得到屬于不同類別的、能夠最大程度描述視頻的結果。
2)在公共數據集及本文的運動視頻數據集上進行了效果對比,驗證了本文方法對視頻摘要化生成的良好效果和較優表現。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
