基于對抗和遷移學習的災害天氣衛星云圖分類
2021-04-13 01:59:12張敏靖白琮張敬林鄭建煒
北京航空航天大學學報 2021年3期
張敏靖,白琮,2,*,張敬林,鄭建煒,2
(1.浙江工業大學 計算機科學與技術學院,杭州310023; 2.浙江省可視媒體智能處理技術研究重點實驗室,杭州310023;3.南京信息工程大學 大氣科學學院,南京210044)
全球75%經濟損失源于災害天氣,每年約1萬多人因惡劣天氣而死亡[1-2]。災害天氣,包括臺風、強對流和沙暴,嚴重威脅人民生命財產安全,監測災害天氣的形成發展過程是氣象災害預測預報的基礎。通過觀測衛星云圖進行監測是重要的手段之一,因為地球的大部分地區被云覆蓋,各種天氣現象總是和云有著密不可分的聯系。衛星云圖是由氣象衛星自頂而下觀測云層覆蓋和地球表面的圖像,可以用來識別不同的天氣狀態,評估其強度和未來發展趨勢等,為天氣預報和災害天氣預測提供全天候的依據。本文聚焦于衛星云圖中的災害天氣分類問題,即在衛星云圖數據中分類出帶有熱帶氣旋、溫帶氣旋等可能帶有災害天氣的云圖。但是在實際的衛星云圖中,往往是非災害天氣類別的圖片占據了原始數據的大多數,而各個災害天氣的數量相對較少,數據呈現了不平衡的分布形態。這樣的數據分布使得分類器在進行訓練的時候,會比較關注占據數據大多數的非災害天氣樣本,故而雖然總體的分類精度高,但是如熱帶氣旋、溫帶氣旋等這些對于實際研究非常具有指導意義的類別,并沒有從分類器中得到很好的區分。因此需解決衛星云圖災害天氣分類中類間不均衡的問題,才能較好的將各個災害天氣從非災害天氣中區分出來。
圖片數據的類間不平衡問題,近年來一直是一個研究的熱點[3]。圖片數據的類間不平衡是指在分類問題中不同類別的訓練樣例數目差別很大的情況。這一情況與實際生產生活中的數據分布情況相似,非常具有研究的意義和必要性。2012年Krizhevsky等[4]在ILSVRC-2012[5]比賽中獲得了冠軍,成功的將深度學習應用于圖片分類的問題上[3,6-7],至此之后各類深度學習的框架模型開始涌現。但是研究者主要關注平衡數據分布的數據集,關于長尾分布數據的研究并未深入。尤其是在衛星云圖的災害天氣分類問題的研究上,由于原始數據獲取和處理的成本較大,相關的分類研究還較少。災害天氣分類問題中類間不平衡問題較為突出,故而本文對不平衡的衛星云圖災害天氣分類問題展開研究。
本文針對不平衡衛星云圖災害天氣分類,聚焦數據和算法混合的思路,提出了一種結合生成對抗學習(GAN)和遷移學習(TL)的分類訓練模型框架,對云圖數據分別進行過采樣和欠采樣處理,并采用遷移學習進行災害天氣云圖的分類。通過在自建的LSCIDWS-S大尺度衛星云圖數據集進行實驗,證明了所提框架的有效性。本文的主要貢獻如下:
1)提出了一個GAN+TL的訓練模型框架。該框架是針對不平衡衛星云圖災害天氣所設計的分類框架,主要由數據平衡化處理模塊和圖片分類2個模塊組成。
2)在該框架中,GAN用于高質量的圖片生成,代替傳統的簡單復制的過采樣方法,同時結合了欠采樣,對原始不平衡的數據分布進行了均衡化的處理。在卷積神經網絡(CNN)分類訓練過程中引入了遷移學習的方法,使得整體的分類性能在原有的基礎上得到了進一步的提升。
3)實驗結果表明,分類器整體的分類性能得到了一定的均衡。這對于實際研究有一定的借鑒意義,即更受到實際應用所關注但容易被分類器忽略的災害天氣樣本的正判率得到了一定的提升。
1 相關工作
1.1 生成對抗網絡
生成對抗網絡(Generative Adversarial Networks,GANs)是在2014年,由Goodfellow等[8]提出。GANs的基本思想是源于博弈論中的零和游戲。它的網絡結構由一個生成器(Generator)和一個判別器(Discriminator)組成,生成器的作用是為了盡可能地去學習數據的真實分布情況從而生成數據,而判別器的作用是判斷輸入的數據是來源于真實的數據還是由生成器生成的,二者之間不斷的進行優化從而達到相對平衡。根據生成對抗網絡有生成樣本的這一特點,DCGAN(Deep Convolutional GAN)[9]為首個將CNN與GAN相結合以生成相應的圖片樣本,但是生成的圖片質量不高并且不穩定。2020年,NVIDIA研究人員發布了StyleGAN2[10],該網絡設計了具有非常規的生成器架構,從而可以生成高質量的圖片,并且訓練過程較為穩定。本文所提方法中的GAN的設計就引用了該網絡結構,從而可以生成相對質量較高的過采樣樣本。
1.2 圖片分類中的類間不平衡問題
關于圖片數據類間不平衡的研究主要可以分為3層次:數據、算法和數據算法的兩相結合[3,11]。關于數據層面的研究主要是對原始不平衡的數據進行均衡化的處理,把不平衡的數據轉化為相對平衡的數據再加入模型中展開之后的訓練。Hensman和Masko[11]提出了提升樣本的解決思路,主要是對樣本中數量較少的類別,對其進行簡單的復制從而達到擴充樣本數量的效果,該方法雖然簡單但是性能提升有限。基于算法層面的改進,主要是對損失函數的重新設計以及學習方式的改進。Wang[12]等提出了MSFE(Mean Squared False Error Loss)函數,該損失函數可以很好的平衡大樣本和小樣本之間的關系,從而也可以達到較好的分類性能。數據與算法的結合則是一種數據和算法混合的方法,如He[13]等提出的LMLE(Large Margin Local Embedding),該方法采用了5倍抽樣法和THL(Tripleheader Hinge Loss)這一損失函數。本文所提框架是結合了數據和算法混合的方法,在數據層面上進行了包括對原始數據欠采樣和引入了StyleGAN過采樣的數據均衡化處理,而在算法層面則引入了遷移學習的思想。
1.3 遷移學習
遷移學習是把源域的知識遷移到目標域的學習方法,可使得目標域能夠取得更好的學習效果。在深度學習中,神經網絡從一個任務中學習到的知識可以應用到另一個相關的獨立任務當中。在類間不平衡問題的處理上,遷移學習可以對相對平衡的數據集中訓練出的模型進行遷移學習,該模型較好的學習到少數樣本的類別特征,因而取得了不錯的效果,如Lee等[14]提出了二階段的訓練方法;Kang等[15]提出了CRT(Classifier Retraining)方法,該方法是使用類平衡采樣的數據對分類器進行重新訓練,故而本文中的分類模塊也會引入遷移學習這一思想。結合衛星云圖災害數據的實際情況,本文中所采用的遷移學習的思路是將原始數據集訓練處的結果遷移到均衡化處理后的數據,該過程主要是為了在提升各個少樣本的天氣類別分類精度的基礎上,盡可能的保留原始數據中非災害天氣這一類別的精度。
2 本文所提方法
本文提出了一個基于GAN+TL的衛星云圖災害天氣分類的框架,如圖1所示。該框架主要分為2部分,一個是數據均衡化處理模塊,另外一個是圖片分類模塊。在數據平衡化處理模塊中首先是對原始不均衡的數據分布進行處理,處理之后得到一個相對較為均衡的數據分布情況。數據處理的過程采用不同的手段,對多數據樣本的類別進行欠采樣,對少樣本的數據進行過采樣。具體來講,過采樣的方法是采用生成對抗網絡,對數據樣本進行擴充。而欠采樣是將樣本根據設定的閾值進行縮減。在圖片分類模塊,首先在原始數據分布的數據集進行訓練,之后將訓練出來的模型遷移學習到類別較為均衡分布的數據集上要進行訓練的模型上。
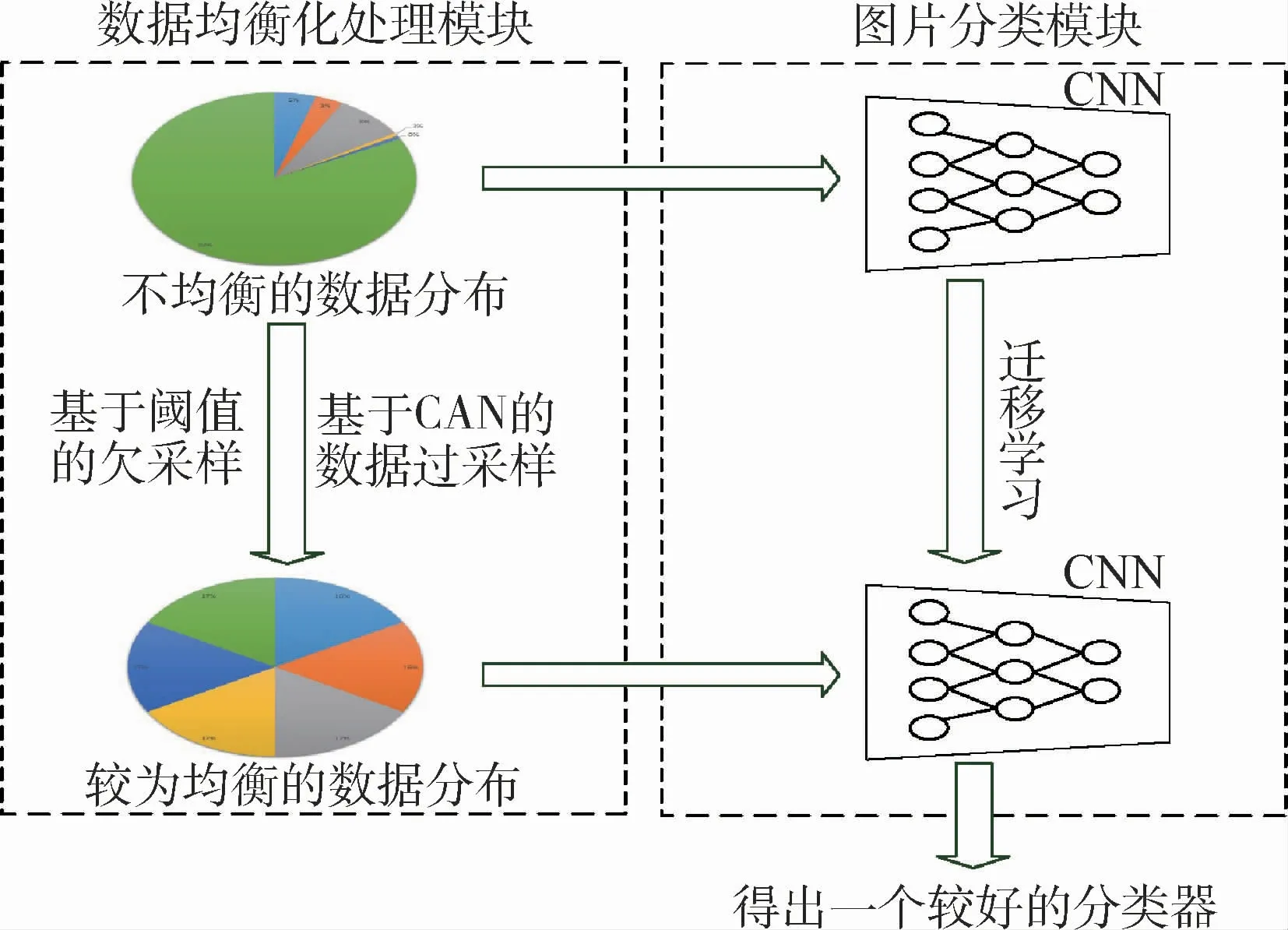
圖1 處理氣象衛星中類間不平衡的模型框架圖Fig.1 Model framework for handling imbalance between classes in meteorological satellites
2.1 數據均衡化處理模塊
數據均衡化處理過程的具體細節如圖2所示,圖2(b)為理想數據分布,是現如今深度學習分類中所研究的大多數數據分布的情況,各個類別的數據量基本相近,而且也取得相對較好的分類性能。本文數據處理模塊的主要目的是將原始數據集的分布趨向理想數據分布的方向進行改進,這樣可以把數據不均衡的問題轉化為數據均衡化處理的問題。數據均衡化的過程分為基于閾值N的欠采樣和基于GAN的過采樣,具體細節如下:
步驟1 基于閾值欠采樣。在均衡化處理的過程中,首先根據各個類別之間的數量關系,設置一個較為合理的閾值N,然后根據這個閾值,對樣本數據量大于這個閾值的類別進行數據隨機丟棄的處理。本文采用的是去掉樣本數量最多類別的數量和樣本數量最少類別的數量,然后取剩下類別的樣本數量計算平均數的方法確定閾值。具體實現如式(1)所示,Xtotal為數據集中包含的總數量;Xmax和Xmin分別為類別數量最大和類別數量最小的數量,n為數據集中的類別數量。確定好閾值之后,對于樣本數量大于該閾值的類別,進行隨機欠采樣,使得類別的數量達到閾值為止,此時的數據分布如圖2(c)所示。
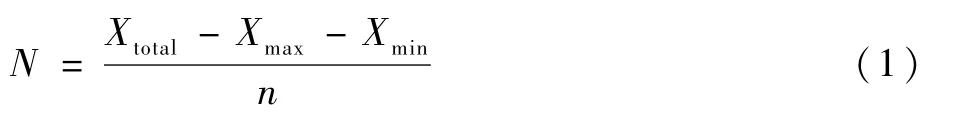
步驟2 基于GAN的過采樣。在完成數據欠采樣的操作之后,對相應的樣本數量少的類別進行過采樣。本文提出以StyleGAN2為基礎網絡基于GAN的過采樣方法。即首先把StyleGAN2在進行過采樣的類別數據上進行訓練,之后用訓練好的生成器生成相應類別的數據并加入到已經完成欠采樣操作的數據集中,此時的數據分布如圖2(d)所示。圖3為GAN設計的核心思想流程,G(z)fake為隨機化的初始噪音,G為生成器,用來生成圖片;D為判別器,用于判別生成圖片的真假;Datareal為本框架結構中要進行數據增強的部分;real和fake表示經過判別器判斷生成的數據為真還是假。
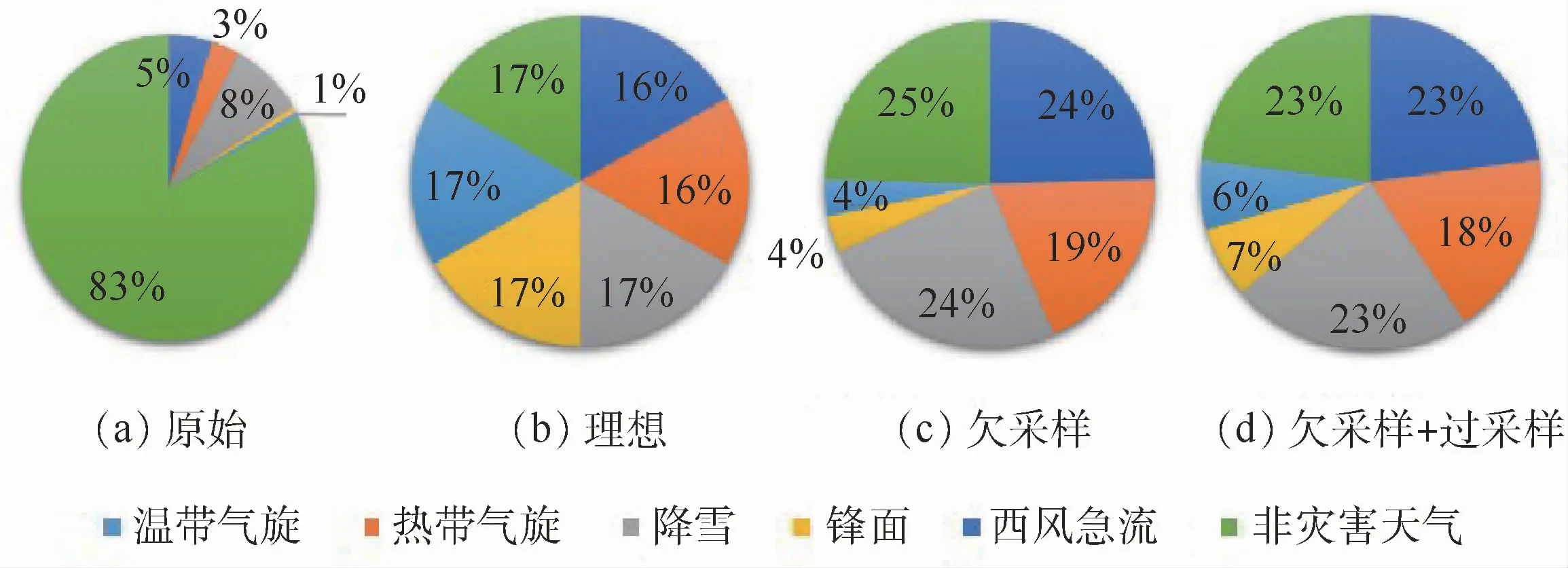
圖2 不同方法對應數據分布情況的百分占比示意圖Fig.2 Schematic diagram of data percentage proportion of data distribution corresponding to different methods
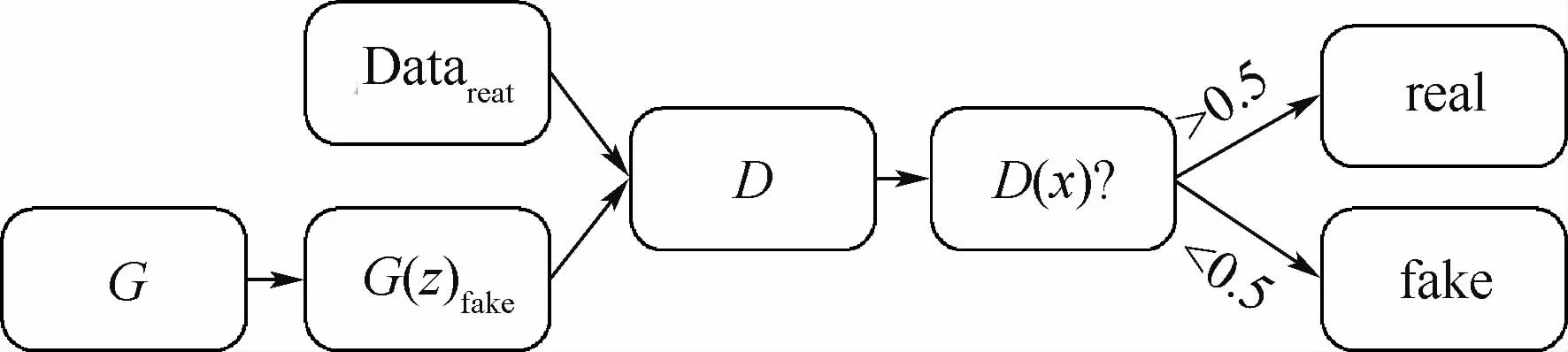
圖3 GAN的核心思想Fig.3 Core idea of GAN
StyleGAN2也是在該思想流程上的改進,可以生成更加高質量的圖片。因為本文中所用的LSCIDWS-S數據集,原本就是高質量的衛星云圖,故而本文選擇了StyleGAN2作為GAN數據平衡化處理模塊中的基礎網絡。StyleGAN2主要在消除圖片偽像上進行了進一步的改進,圖片的偽像就是生成圖片中圖像上呈現出的類似于水滴的特征,該算法將改進的方向定位到了AdaiN的運算中,該算法的特點可分別歸一化到每個特征圖的均值和方差。具體的修改細節如下:首先對每個輸入特征圖的尺度根據調制卷積操作進行相應的調整,如式(2)所示,w和w′分別為原始權重和調制權重;si為與第i個輸入特征圖對應的比例;j和k分別為特征圖和卷積的空間下標。式(3)為完成相應調制卷積操作之后的輸出權重(調制權重)的標準差。式(4)表示式(2)中σj固化到卷積權重中去,ε為很小的數值,是為了確保被除數不為0。
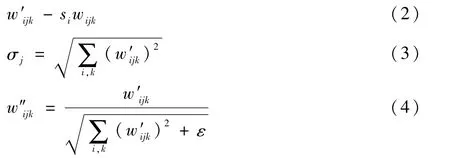
3.2 圖片分類模塊
在完成數據均衡化處理之后,進入分類訓練的模塊,流程如圖4所示。先根據原始不均衡的數據集訓練出一個模型,再將不均衡分布數據訓練出來的模型進行遷移學習,即把上述訓練得到的模型權重初始化到較為均衡分布的數據集的分類模型上。采取這樣二階段訓練的目的,主要是為了解決,均衡化后的數據分布所訓練出的模型會丟失較多關于原樣本數量較多類別特征信息的問題。故而能在犧牲樣本數量較多類別的分類精度的前提下,提升其他各個類別的分類性能。同時二階段訓練的處理方法,也使得原始不均衡的數據分布和后處理的較為均衡的數據分布之間建立相應的關聯。2個模塊之間的相互關聯,使得整個數據處理和之后的圖片分類過程形成一個閉環,也使得分類器的性能達到相應的穩定和平衡。對應算法步驟如下所示:
算法1 圖片分類框架算法。
輸入:原始訓練集Xtrain,均衡化處理后的訓練集X′train,模型訓練的次數m。
輸出:對測試集Xtest的分類結果。
1.隨機初始化用于遷移學習的網絡參數Mt
2.Repeat
for i=1 to m do
根據網絡預測結果與真實的標簽進行損失計算
反向傳播更新網絡的參數Wt
3.獲得遷移學習的模型Mt
4.用模型Mt初始化分類模型Mc的參數
5.Repeat
for i=1 to m do
根據網絡預測結果與真實的標簽進行損失計算
反向傳播更新網絡的參數Wc
6.完成最終分類模型Mc的訓練
7.將待預測的樣本輸入Mc獲得最終分類結果
本文在圖片分類模塊中采用ResNet101作為訓練過程中的基礎模型。這主要是因為本文的數據集原始數量大,希望可以用深層次的網絡取得較好的性能,但大量研究表明,隨著網絡深度的增加,會出現梯度爆炸,導致無法收斂這一問題。而殘差思想的提出[13]可以使得網絡的性能不隨網絡深度的增加而退化,因此本文選擇ResNet101作為分類模塊中的基礎模型。
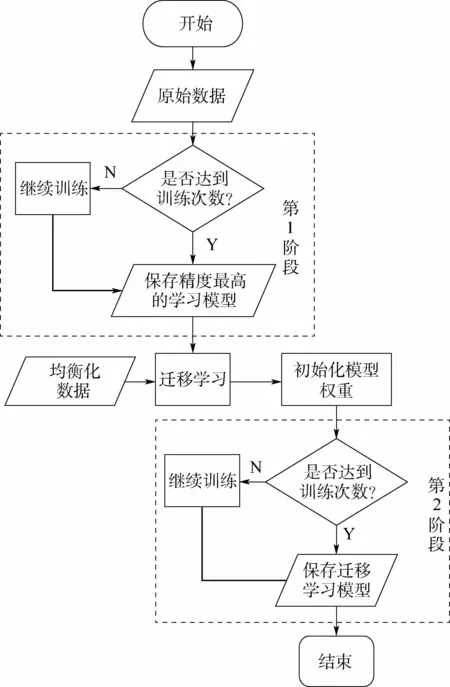
圖4 分類模塊訓練的流程圖Fig.4 Flowchart of classification module training
以上2個模塊的結合,構成了災害天氣衛星云圖的分類框架,并充分考慮了數據中的不平衡問題。
3 實驗結果及分析
3.1 數據集
因目前沒有公開可用的云圖數據庫,本論文實驗數據集采用自建的數據集,稱之為LSCIDMR-S(Large-scale Satellite Cloud Image Database for Meteorological Research System)。LSCIDMR-S是以葵花-8號氣象衛星為數據來源建立的一個大尺度靜止氣象云圖的單標簽數據集。該數據集的數據采集時間跨度為1年,包含了溫帶氣旋、熱帶氣旋、鋒面、西風急流、降雪、高冰云、低水云、海洋、沙漠、植被和其他總共11個類別總計104 390張圖片,圖片的原始大小為1 000×1 000像素。在本文中,因主要聚焦于災害天氣的分類識別,故將高冰云、低水云、海洋、沙漠、植被和其他合并為非災害天氣類別,圖5為數據集中的部分云圖示例,表1為數據集中各個類別的分布情況。重新劃分后的數據不平衡比率(Imbalanced Ratio,IR)為137.25。IR為衡量數據集不均衡程度的一個指標,其具體計算如式(5)所示,是數據量最多的類別的數量和數據量最少的類別的數量比例,一般大于10認定為類間不平衡的數據集[3,7]。Ci為第i個類別對應的類別數量。

圖5 LSCIDMR-S數據集的部分示意圖Fig.5 Partial schematic of LSCIDMR-S dataset
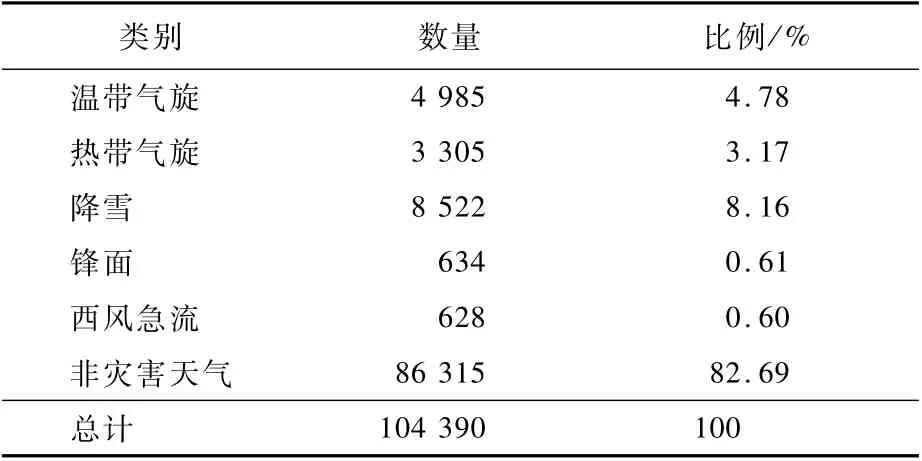
表1 LSCIDMR-S處理之后的數據分布情況表Table 1 Data distribution of LSCIDMR-S after processing

3.2 評估方法
本文中的實驗評估方法采用分類中通常使用的總體精度(Overall Accuracy)和各個類別的分類精度(Category Accuracy)進行評估。總體精度是指預測正確的標簽數量和待預測的總標簽數量的比例,這一指標只能籠統的評價模型的整體性能。對于長尾數據集的分布,單一的總體精度還不足以充分的體現這一模型與實際問題的貼合程度。單一的總體精度的虛高并不能很好地表示模型的性能很好,很有可能是因為數據集中占據絕大多數類別的單個類別的性能好。比如本文中的非災害天氣類別這一類別,占總數據集的82.69%,如果總體精度達到了80%,也很有可能只是單一的非災害天氣類別這個類別的精度高而已。而在實際的長尾分布數據集當中,占數據量少的類別往往更是應該關注的對象。故而占樣本數量較少的溫帶氣旋、熱帶氣旋、西風急流、鋒面和降雪,它們單個類別的分類精度對于實際問題的研究更加有意義,故而本文還采用各個類別的分類精度。
總體精度和單個類別的精度能從數值上說明一個模型的整體性能。于此同時本文還采用了ROC曲線作為評估指標[9],該曲線可視化了正確分類的陽性樣本與陰性樣本之間的關系,故而ROC曲線是衡量模型在不均衡數據集中性能的一個重要指標。ROC曲線通常用于二分類的研究,橫坐標為假陽性(特異度),縱坐標為真陽性(靈敏度)。本文為將其擴展到多分類問題上,首先對輸出進行二值化,然后分別進行如下操作:①對每個類別繪制了一個對應的ROC曲線;②Micro-average通過把多分類問題轉化為二元預測來繪制ROC曲線;③Macro-average用于多分類的評估方法是對每個標簽給予相同的權重,實現宏觀的平均,最后將同一個類別的數據匯總到1張ROC曲線上。ROC曲線下方與坐標軸圍成的面積被定義為AUC(Area Under Curve),表示預測的正例樣本排在負例樣本前面的概率,這個面積的數值通常介于0.5~1之間,數值越大,表明分類方法的性能越好。
3.3 參數設定
本文實驗均在一個配備了32 GB內存和3.6-GHz Inter(R)Core i9-9900K CPU處理器及GeForce RTX 2080Ti顯卡的工作站上進行。
對于數據集的訓練集和測試集按照9∶1的比例進行劃分。對于數據集欠采樣的部分,按照數據均衡的方向調整,設置了閾值N=3 826,該閾值根據訓練集中去掉了類別中數量的最大值和最小值取均值。然后對數據量超過這個數值的類別的數據進行隨機丟棄直到數據數量達到3 826。對于數據過采樣部分,是基于數據欠采樣的基礎上對數據再進行進一步的處理,對于類別數量較少的鋒面和西風急流擴充k倍,默認為1,相應的數據數量分別為571和766。對于參數,按照0.5的步長設置進行了相應的參數實驗。
使用StyleGAN2生成的圖片大小為256×256像素。分類模型中的各個超參數分別設置為learning rate=0.001,momentum=0.9,batch_size=64,圖片統一為256像素×256像素。每個模型都訓練20次,保留總精度最高的模型,進行指標計算。
3.4 實驗結果及分析
針對本文所提GAN+TL框架,設計對比實驗證明所提模型方法有效。分別為:采用未經過任何處理的原始數據進行訓練與分類的Base方法;對原始數據按照對超過閾值的類別進行隨機欠采樣處理后的Base_under方法;在Base_under的基礎上對Base進行遷移學習的Base_under_t方法;Base_under_over是對原始數據集進行按閾值隨機欠采樣之后的基礎上,再對原始數據集中樣本數量較少的類別進行機械復制的過采樣方法;Base_under_over_t是在Base_under_over方法的基礎上對Base進行遷移學習的結果;之后的Base_under_gan相比于Base_under_over是用生成對抗網絡來代替傳統的復制對數據進行過采樣,從而使得數據分布達到一個較為均衡的狀態;最后的Base_under_gan_t也是本文所提的GAN+TL框架,即在Base_under_gan的數據處理基礎上對Base訓練出的模型進行遷移學習。接下來的實驗分析中,也將主要從數據平衡化模塊和圖片分類模塊分別展開分析。
首先是數據均衡化,表2為不同方法所對應的數據分布情況和相應的數據不平衡系數。可知,原始數據集的數據不均衡系數達到137.25。而經過本文所提數據均衡化處理之后,數據不平衡系數降到了3.35。圖2為不同方法對應的數據分布情況的百分比占比示意圖,圖2(a)為數據的原始分布示意圖,圖2(b)為大多數研究中數據理想的均衡分布圖,圖2(c)和圖2(d)分別對應了不同數據均衡化處理的過程。圖6為基于GAN的數據過采樣的部分結果示意圖,以西風急流為例,圖6(a)為原始數據集中西風急流的部分示意圖,圖6(b)為基于GAN生成的數據樣例,從圖片中可以觀測到StyleGAN2,可以較好地學習到圖像的輪廓、紋理、顏色等特征。雖然伴隨著一定的噪音,但是從表3的實驗結果中可以觀察到,StyleGAN2生成的圖片信息能夠較好地學習原圖像的特征。
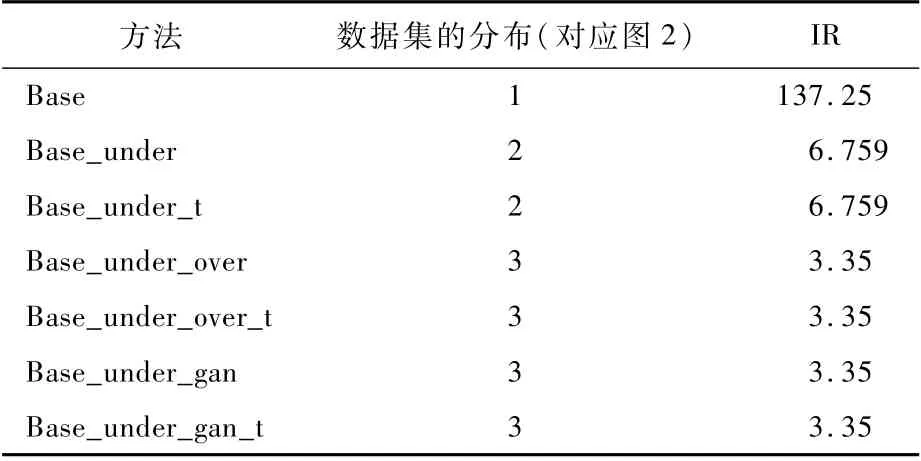
表2 各方法對應的數據分布及數據不平衡系數Table 2 Data distribution and data imbalance degree corresponding to each method

圖6 基于GAN的數據過采樣生成的圖片Fig.6 Schematic diagram of oversampling data image generated by GAN
表3為分類實驗的總體精度和各個類別的分類精度。可知,本文所提的數據處理:欠采樣、基于StyleGAN2的過采樣方法和基于不平衡樣本的遷移學習(Base_Under_Over_Gant)的方法對解決類間不平衡問題有效。由表3可知,雖然Base方法的整體精度和非災害天氣這一類別的分類性能達到了最優,但是對于西風急流、熱帶氣旋、鋒面和溫帶氣旋這4個類別的數據,他們的分類精度還非常低。這4個類別的原始數據量較少,但是能準確地識別它們對于實際應用場景非常有意義。上述實驗結果進一步說明了長尾數據的分布對于CNN的特征提取有一定的影響,在分類的時候會更加關注數量多的類別,因而數量多的類別(非災害天氣)能取得較好的提取特征,進而忽略了其他數量較少類別的特征的學習,由此對數據量較大的類別(非災害天氣)進行處理就非常有必要。對于閾值大于N=3 826的類別進行了隨機丟棄的欠采樣處理,從表3中可以看出,Base_under與最開始的Base相比,雖然損失了非災害天氣這一類別的精度,但是其他各個類別的精度都得到了一定的提升,與此同時,Base方法中對數量較多的非災害天氣這一類別的特征有較好的學習,故而把Base方法訓練的結果遷移學習到進行調整的Base_under模型,得到了新的模型Base_under_t,發現部分類別的精度會得到一定的提升。故而提升少數類別的數量,可以幫助CNN均衡的提取各個類別的特征。將欠采樣和過采樣相結合的同時,再加上遷移學習,這給訓練一個更好的分類器提供了思路。用GAN對于少數樣本的數據進行過采樣,從表3中可以看出,Base_under_gan和Base_under_over 2個模型相比,Base_under_gan的總精度和絕大部分類別的分類精度基本高于Base_under_over。這說明用GAN生成圖像的過采樣方法比簡單的復制粘貼過采樣的方法能取得更好的分類效果。最后,本文所提出的Base_over_gan_t模型基本在所有類別都取得了相對較高的精度。在降雪類別的數據上雖然沒有取得最高的分類精度,但是也取得了相對不錯的精度。究其原因是在對數據進行了欠采樣和過采樣處理之后的數據各個類別的分布比例雖然達到了一定的均衡,但是降雪(如圖2(d)所示)這一類別相較于其他類別的數量占比較大,故而分類器在該類別的特征提取上能夠取得較優的性能。表3中數據部分加粗的是各個類別取得的最高精度。
圖7(a)~圖7(h)分別對應非災害天氣、西風急流、熱帶氣旋、降雪、鋒面、溫帶氣旋、Microaverage和Macro-average在各個不同模型下的ROC曲線圖,圖中的Model 1~7分別對應表2中的各個方法。表3中本文所提Base_under_gan_t方法,相比于其他的方法,整體的性能達到了最佳,對應的ROC曲線的頂角靠近左上角,對應的AUC與其他方法相比達到了最高:非災害天氣(0.83)、西風急流(0.85)、熱帶氣旋(0.85)、降雪(0.94)、鋒面(0.73)和溫帶氣旋(0.83)。
之后對生成對抗網絡進行數據擴充的倍數k對各個類別分類精度的影響進行了進一步的探究,實驗結果如圖8所示。圖8(a)為基于GAN的數據過采樣之外不采用遷移學習進行模型訓練的分類性能情況;圖8(b)為同時采用基于GAN的數據過采樣和遷移學習進行模型訓練之后的分類性能情況。k=0.5、1、1.5、2、2.5、3、3.5、4、4.5、5、5.5,訓練數據集對應的IR分別為4.5、3.35、2.70、2.25、1.93、1.69、1.50、1.35、1.23、1.13、1.04,相應的各類別的數據分布情況如圖9所示。從圖8中可以看出,無論是否采用遷移學習,隨著值的增大,總精度基本穩定在0.75。而其他各個數據類別的分類精度會呈現先升高,然后穩定在一定數值之后再下降的趨勢,當值介于1~2之間的時候整體的分類器的性能都取得較為均衡的結果,稱之為最佳取值范圍。總體上當處于最佳取值范圍時,采用遷移學習之后的總精度和各個類別的分類精度都有一定的提升。而隨著k的增加,IR趨近于1的時候,對不均衡分布數據訓練出來的模型進行遷移學習的分類器的性能提升并沒有明顯效果。這主要是因為樣本增加的數量遠大于該類別原始數據的數量,通過GAN進行數據的過采樣會導致分類器在特征學習過程中受到生成數據中噪聲的影響,進而影響特征學習效果。
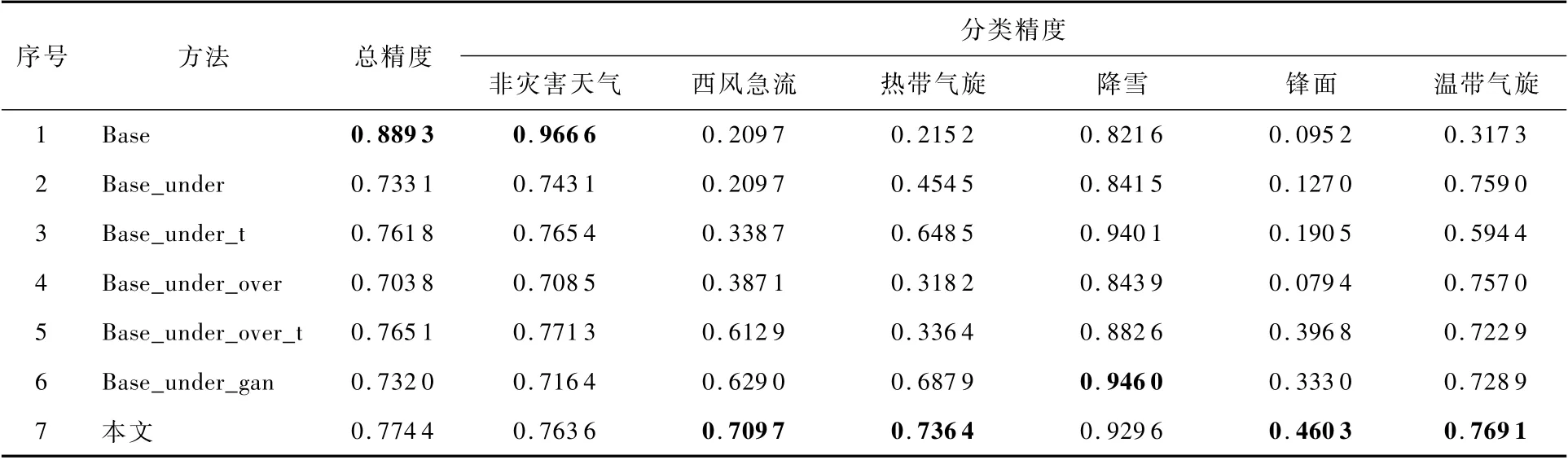
表3 各個模型的總精度和分類精度的統計Tabel 3 Statistics of total accuracy of each model and accur acy of each category(Accuracy)
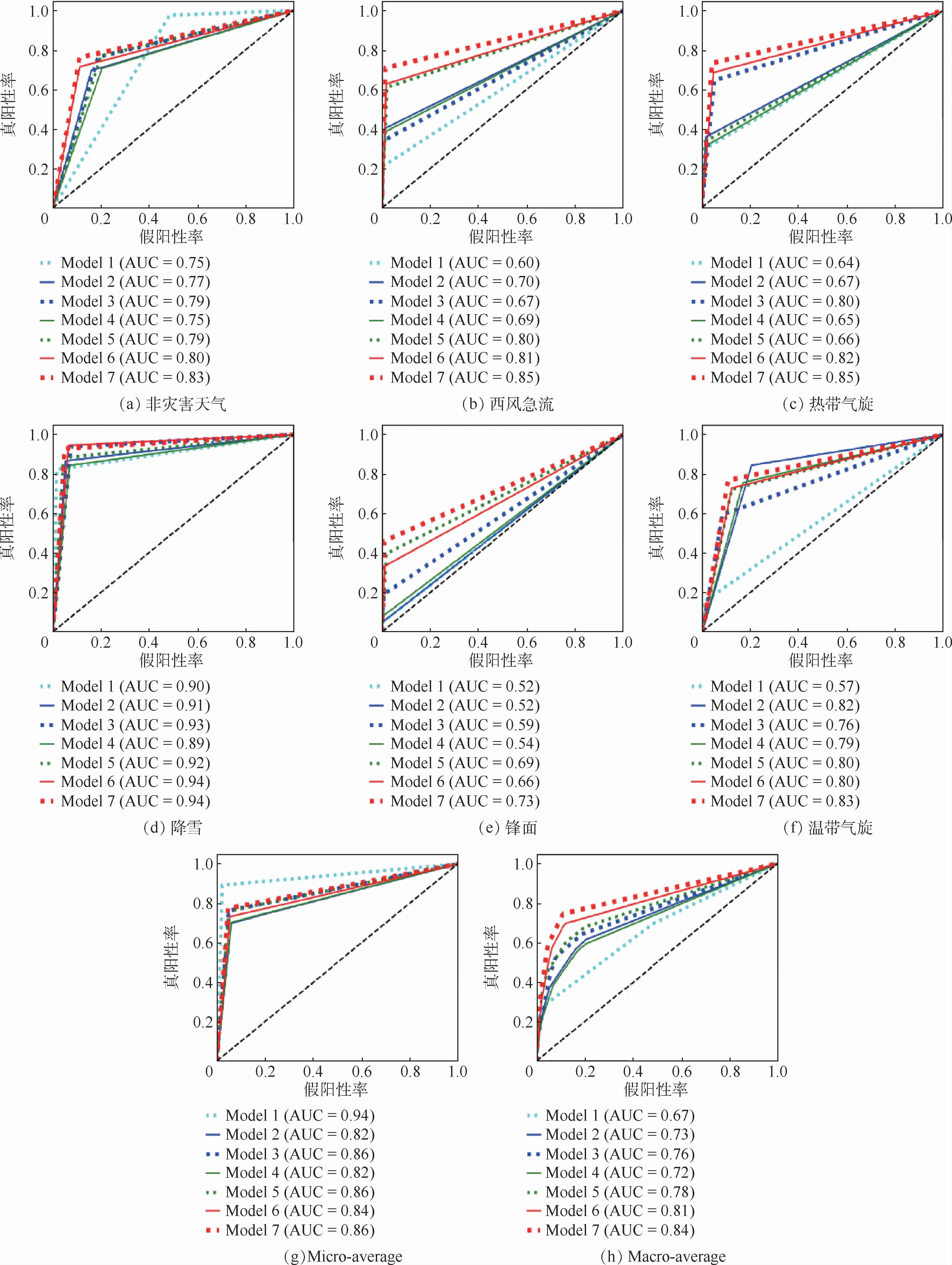
圖7 各個模型中各個類別對應的ROC曲線Fig.7 ROC curve corresponding to each category in each model
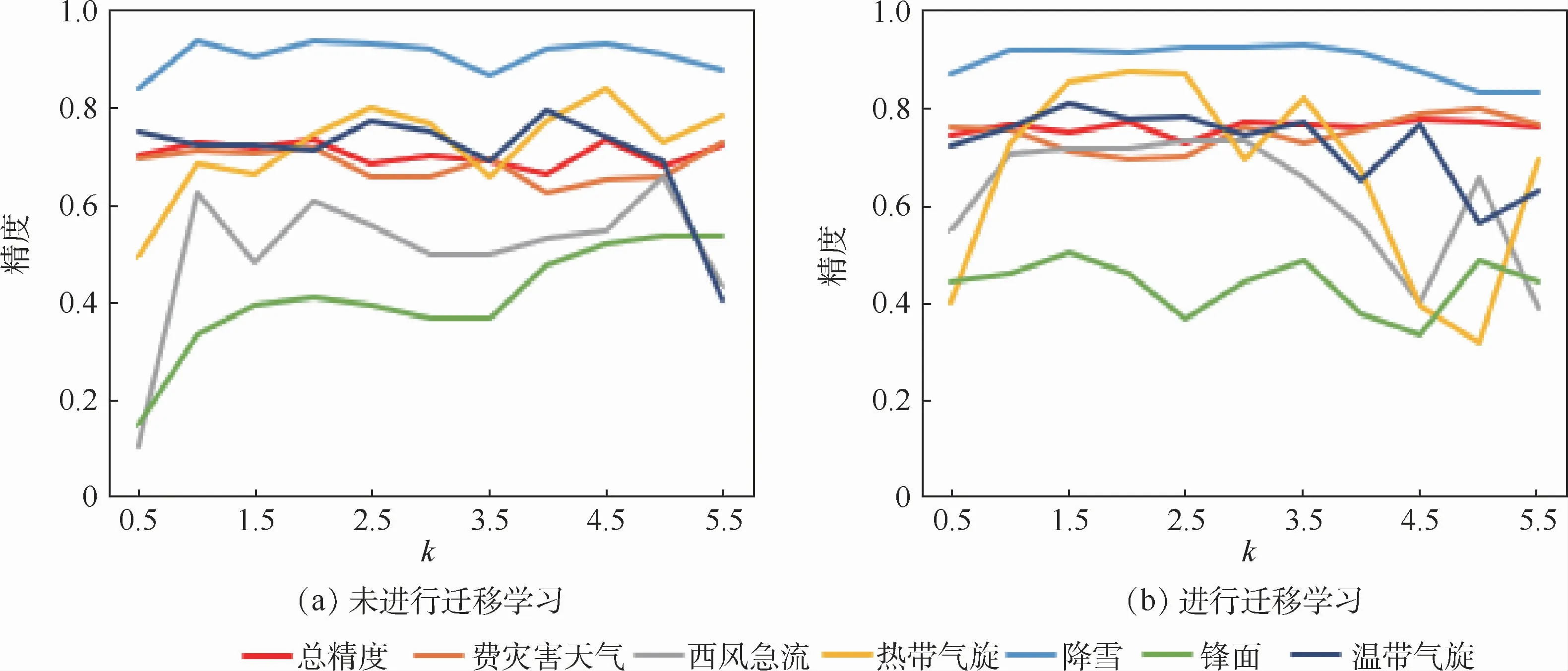
圖8 參數k對分類性能的影響Fig.8 Influence of parameter k on classification performance
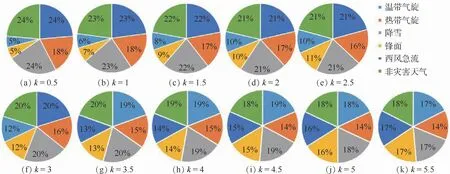
圖9 不同k對應的數據分布Fig.9 Data points corresponding to different k
4 結 論
1)本文提出了一個結合生成對抗網絡和遷移學習處理災害天氣氣象衛星云圖中的長尾數據分類的框架。該框架分為數據均衡化處理模塊和數據分類2個模塊。數據均衡化處理模塊采用GAN對少樣本的數據類別進行過采樣,然后將過采樣和欠采樣相結合實現原始數據均衡化處理。
2)通過上述過程,GAN可根據數據的分布情況生成新的過采樣數據,進而能夠給CNN中的特征提取提供更加優質的圖片信息;在圖片分類模塊中,采用對原始不均衡數據集訓練得到的模型進行遷移學習,用所得的模型對圖片進行分類的方法。
3)在自建的大規模衛星云圖數據上的多方面實驗證明,所提框架中的基于GAN的數據過采樣和基于遷移學習的模型訓練方法可以較好地解決衛星云圖中的數據不平衡問題。所提框架在傳遞數量較多的數據類別特征信息的同時又可對數量較少的數據類別提取較好的特征,故而在提升少量樣本類別分類精度的同時,也盡可能地保證大量樣本的分類精度。為之后解決類間不平橫的長尾數據分布提供了一個可以借鑒的解決思路。與此同時,雖然其他各個類別分類的精度都得到了可觀的提升,但是數據分類的總體精度和非災害天氣的分類精度有了一定的下降,其中非災害天氣精度下降可能是因為隨機欠采樣不能充分保留原始數據的多樣性(原始災害天氣中并沒有進行更加細致的類別劃分,從而不能有計劃的從各個非災害天氣類別中進行隨機欠采樣)。這也是之后研究中所需要進一步改進和研究的方向:即在保證各個少量樣本類別分類精度得到提升的同時,分類的總體精度也要保證一定的提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
