多模態輕量級圖卷積人體骨架行為識別方法
2021-04-11 12:49:18蘇江毅宋曉寧吳小俊於東軍
計算機與生活 2021年4期
蘇江毅,宋曉寧+,吳小俊,於東軍
1.江南大學人工智能與計算機學院,江蘇無錫 214122
2.南京理工大學計算機科學與工程學院,南京 210094
行為識別是人工智能領域的重要研究方向之一,在視頻監督、智能監控和人機交互等方向有著重要的應用。行為識別同時也是一項具有挑戰性的任務,不僅因為處理視頻片段所需的計算要求更高,而且易受外界環境因素的影響。這導致了基于RGB 視頻的行為識別方法往往難以同時滿足時效性和準確度的要求。最近幾年,得益于深度相機的發展與普及,例如,MicrosoftKinetic[1],基于深度信息的行為識別[2]逐漸成為了該領域的重要研究方向之一。與傳統的RGB 數據相比,骨架序列因為不包含顏色信息,所以具有簡潔、易校準、不易受外觀因素影響的特點。
早期的基于人體骨架的行為識別方法主要通過手工設計特征的方式來對行為進行表征[3]。例如Yang等人[4-5]的EigenJoints 方法,從骨架數據直接獲得成對關節的靜態姿勢和偏移量,通過主成分分析法(principal components analysis,PCA)來減少冗余和干擾,最后通過非參數樸素貝葉斯最近鄰(Naive Bayes nearest neighbor,NBNN)完成行為分類。在深度學習方法未被大規模使用之前,該類方法一直是行為識別領域的主要研究方向。但是,由于手工提取的特征往往表征能力有限并且需要耗費大量精力用于調參優化,因此當深度學習普及以后,一些端對端的基于深度神經網絡的方法越來越受到人們的歡迎。
目前主流的方法可以分為以下三類:(1)基于循環神經網絡(recurrent neural networks,RNN)[6]的方法;(2)基于卷積神經網絡(convolutional neural networks,CNN)[7]的方法;(3)基于圖卷積網絡(graph convolutional networks,GCN)[8]的方法。Du 等人[9]將人體骨架按照軀干與四肢進行劃分,共分成了五部分,網絡級聯地輸入和組合人體骨骼各個部分的運動,從而通過雙向循環神經網絡(bidirectional recurrent neural networks,BRNN)將每個時刻的低層次的關節點拼成一個向量,不同時刻的向量組成一個序列,并對生成的序列進行處理和學習。Liu 等人[10]主要通過雙流3D 卷積神經網絡(3D convolutional neural networks,3D CNN)來同時對關節點的時間特性和空間關系進行建模,最后通過加權平均的方式融合時空間特征獲得最終的分類結果。Yan 等人[11]第一次提出了通過建立骨架序列時空圖的方式,將圖卷積網絡擴展到時空模型上,從而避免了手工設計遍歷規則的弊端,使得網絡具有更好的表達能力和更高的性能。Shi 等人[12]在Yan 等人研究的基礎上融合了基于骨架長度的信息,從而提出了一種雙流自適應圖卷積網絡用于基于骨架的行為識別。
上述三類方法,都是目前主流的基于骨架行為識別的方法,但是都存在一定的問題。其中基于RNN的方法,雖然在表征時間信息方面優勢明顯,但是存在優化難度高,而且易丟失原始的關節點信息的問題;而基于CNN 的方法,雖然可以從不同時間區間提取多尺度的特定局部模式,但是存在參數量過于龐大,對計算要求過高的問題。而基于圖卷積的方法得益于對非歐氏數據(non-Euclidean data)建模的巨大優勢,相對于前兩種方法而言更具優勢。
此外,基于圖卷積的方法同時還利用了多模態學習中的相關方法來提高精度。首先,多模態數據是指對同一對象,因為描述方法不同,把描述這些數據的每一個視角叫作一個模態。而多模態表示學習(multimodal representation)是指通過利用多模態之間的互補性,剔除模態間的冗余性,從而學習到更好的特征表示。現階段的多模態數據融合分析方法主要分為基于階段的數據融合、基于特征的數據融合和基于語義的數據融合。其中基于階段的數據融合方法是指在不同階段使用不同的模態數據完成相應的數據融合;基于特征的數據融合方法是指從原始特征中學習新的融合特征,然后通過學習到的新的融合特征完成分類、預測等任務;最后基于語義的數據融合方法需要對每個模態數據的含義以及不同模態之間的特征關系進行理解,通過抽象的語義信息完成跨模態數據的融合。目前,基于圖卷積的方法多采用基于特征的數據融合方法,該方法雖然能較大地提升實驗結果,但是需要針對不同的特征生成的不同訓練集進行多次訓練,通過融合不同訓練集上的訓練結果的方式得到最終的結果。基于圖卷積的方法雖然在最終的結果上有不錯的表現,但是因為需要在多模態數據集上進行多次訓練,所以同樣存在參數量過大和對計算要求過高的問題。
針對上述這些問題,本文提出了一種融合多模態數據的輕量級圖卷積神經網絡用于基于人體骨架的行為識別。不同于之前的一些使用GCN 的方法,本文方法雖然同樣使用了基于特征的數據融合方法來提高實驗結果,但并不需要針對不同的特征預先生成不同的訓練集,而是直接采用多模態數據融合與自適應圖卷積相結合的方式,僅通過一次訓練就能達到其他方法在預先生成的多個數據集上的訓練效果。總體而言,本文方法能夠在兼顧參數量的同時取得很好的效果。最后根據在行為識別數據集NTU60 RGB+D和NTU120 RGB+D 上的測試結果表明,該方法能夠以極低的參數量完成基于人體骨架的行為識別。
1 融合多模態數據的輕量級圖卷積網絡
1.1 圖卷積簡介
由于圖結構的不規則性和復雜性,其節點的排列方式并不存在明顯的上下左右關系,因此無法通過固定大小的卷積核來提取相應的特征,故傳統的卷積神經網絡在這一領域很難發揮作用。為了解決這一問題,研究人員提供了兩條思路:一條是將非歐氏空間的圖轉換到歐氏空間,即構建偽圖;另一條就是構建一種可處理變長鄰居節點的卷積核,這也就是GCN 的最初設計原理。
對于一張給定圖,需要兩種輸入數據來提取特征:一個是維度為N×F的特征矩陣X,其中N為圖中的節點數,F為每個節點的輸入特征;另一個是維度為N×N的鄰接矩陣A。因此,GCN 中隱藏層可以表示如式(1)所示:

其中,l代表層數,代表上一層的輸出,f代表一種傳播規則,而H(0)=X為第一層的輸入。在每一層中,GCN 會通過f將這一層的信息聚合起來,從而形成下一層的特征,不同圖卷積模型的差異點在于f的實現不同。
1.2 具有自適應性的圖卷積
本文以SGN(semantics-guided neural networks)[13]中的網絡結構為基礎,提出了一種能夠融合多模態數據的自適應圖卷積網絡結構如圖1 所示。與之前的一些同樣使用圖卷積網絡的方法相比,最大的區別在于鄰接矩陣A的構成不同。之前的方法,諸如ST-GCN(spatial temporal graph convolutional networks)[11]與2s-AGCN(two-stream adaptive graph convolutional networks)[12],雖然同樣使用了圖卷積來表征骨架數據,但是這兩個方法所使用的鄰接矩陣A均是通過手工設計的方式完成的。手工設計的鄰接矩陣A在聚合幀內關節點數據時,往往缺乏自適應性,未能進行有效的聚合。
為了解決這個問題,本文提出了一種將多模態數據融合到圖卷積之中的方法。如圖2 所示,通過將不同模態的數據,諸如關節點信息流、骨長信息流、運動信息流、速度差信息流和基于速度差的骨長信息流進行融合,一方面可以確保構建出一個具有全局適應性的鄰接矩陣,另一方面能夠減少運算次數,從而降低運算成本,提高運算效率,最終實現網絡輕量化的目標。
1.3 多模態數據融合
首先,對于一個給定的骨架序列,其關節點的定義如式(2)所示:
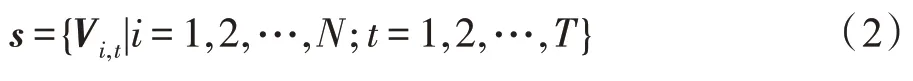

Fig.1 Network framework圖1 網絡框架結構

Fig.2 Multi-modal data fusion圖2 多模態數據融合
其中,T為序列中的總幀數,N為總關節點數,Vi,t表示為在t時刻的關節點i。因為涉及到多模態數據的融合,訓練開始前需要對集合S進行多樣化的預處理。因為關節點信息流可以直接獲取,所以在這里只需要給出骨長信息流、運動信息流和基于速度差的骨長信息流的定義公式。
骨長信息流(bone information flow):通常定義靠近人體重心的點為源關節點,其坐標可以定義為Vi,t=(xi,t,yi,t,zi,t),而遠離重心的點為目標關節點,其坐標為Vj,t=(xj,t,yj,t,zj,t),通過源關節點與目標關節點的差值可以計算骨長信息流。因此骨長信息流的定義如下所示:
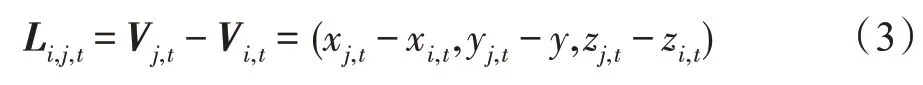
運動信息流(motion information flow):運動信息流是通過計算相鄰兩個幀中相同關節點之間的差值得到的。本文定義在t幀上的關節點i,其坐標為Vi,t=(xi,t,yi,t,zi,t),則在t+1 幀上的關節點i定義為Vi,t+1=(xi,t+1,yi,t+1,zi,t+1)。因此在關節點Vi,t與關節點Vi,t+1之間的運動信息流可以定義如式(4)所示:
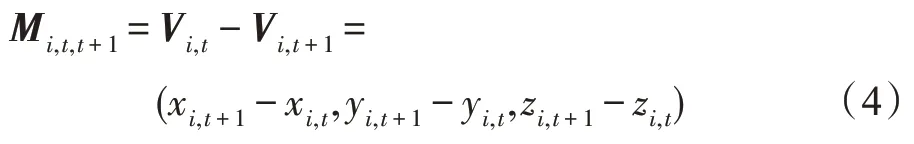
速度差信息流(velocity difference information flow):速度差信息流首先需要計算前T-1 幀與后T-1 幀的差值,接著通過填補0 元素的方式擴充矩陣,彌補維度上的變化。假設關節點i在前T-1 幀上的定義為Vi,0:T-1=(xi,0:T-1,yi,0:T-1,zi,0:T-1),在后T-1 幀上的定義為Vi,t+1=(xi,1:T,yi,1:T,zi,1:T),因此速度差信息流的定義如下所示:
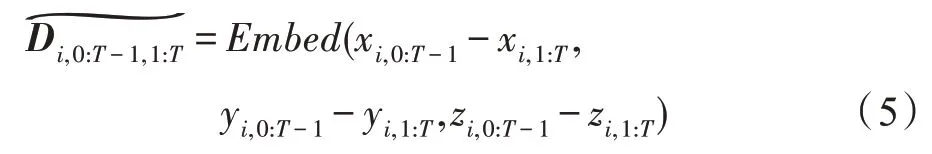
基于速度差的骨長信息流(bone information flow based on velocity difference):基于速度差的骨長信息流是在速度差信息流的基礎上通過計算相鄰兩個幀中相同骨骼之間的差值得到的。根據式(2)的骨長信息流與式(5)的速度差信息流定義,可以定義前T-1 幀上的源關節點i到目標關節點j骨長的信息流為,后T-1 幀上的骨長信息流為,因此基于速度差的骨長信息流如式(6)所示:
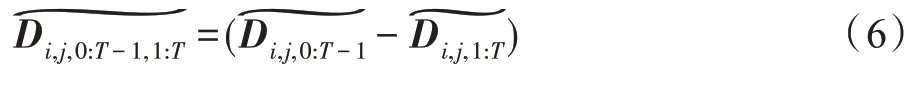
如圖2 所示,根據式(2)到式(6)中對于關節點信息流、骨長信息流、運動信息流、速度差信息流和基于速度差的骨長信息流的定義,多模態數據融合的定義如下所示:
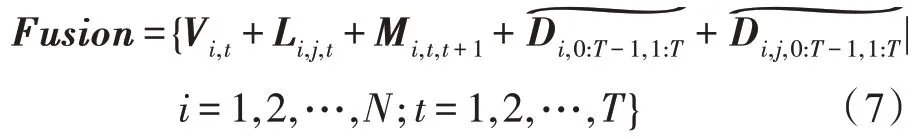
1.4 基于密集連接卷積網絡的空間流模塊
為了更好地表征骨架序列在時間維度空間維度上的信息,本文在SGN[13]的基礎上,重新設計了時間流模塊和空間流模塊。
設計空間流模塊的目的主要是為了獲得某一幀內不同關節點之間的相關性。在空間流模塊中,通過使用圖卷積來探索結構型骨架數據中關節點的相關性,如圖3所示,空間流模塊的主體部分主要由三層圖卷積組成。相比于之前一些方法,例如ST-GCN[11],該方法雖然同樣使用圖卷積來建模骨架數據,但是這些方法都缺乏自適應性,即ST-GCN[11]中的圖的拓撲結構是根據人體的物理結構預先定義好的,但是通過這樣的方法定義的圖結構并不一定適用于行為識別的任務。此外,由于需要對不同的動作進行識別,如果都使用相同的拓撲結構的圖顯然也是不合理的。針對這些問題,一個合適的解決方法是設計一種具有自適應的圖卷積網絡來建模結構型骨架數據。如圖3 所示,通過計算t幀的關節點i與關節點j之間的相關性來得到這兩個節點之間的邊緣權重(edge weight),具體公式如下:

其中,θ與φ主要用來進行維度變換,具體實現如下所示:

通過計算同一幀中所有關節點之間的相關性,得到了具有所有幀中所有關節點的自適應鄰接矩陣。
在SGN[13]的基礎上,本文還采用了密集連接卷積網絡(densely connected convolutional networks,Dense-Net)[14]中密集連接(dense connection)的方式來提高模型的泛化效果。本文借用DenseNet 的思想,將第一層GCN 之前的輸出與之后每層GCN 的輸出直接相連。具體的實現過程并不是殘差網絡(residual network,ResNet)[15]中所采用的直接相加的方式,而是采用了連結結構(concatenate)的方式,這樣能夠以增加少量參數量為代價,實現淺層特征的復用,加強特征在三層GCN 網絡中的傳播,同時也能夠避免某些層被選擇性丟棄,造成信息堵塞等。通過建立不同層之間的密集連接,不僅能夠提高運算效率,減少不同層之間的依賴性;同時還能加強深層特征與淺層的聯系,最終達到復用淺層特征的目的。
1.5 基于殘差網絡的時間流模塊
與空間流模塊不同的是,時間流模塊的設計目的是獲得幀與幀之間的相關性。如圖4 時間流模塊所示,時間流模塊主要由空間最大池化層、時間最大池化層以及兩層CNN 所組成。其中空間最大池化層(spatial maxpooling layer,SMP)用來聚合同一幀中的關節點信息;時間最大池化層(temporal maxpooling layer,TMP)用來聚合不同幀之間的信息。第一層CNN 為時間卷積層,用于對幀的相關性進行建模;第二層CNN 用于增強其所學習到特征的泛化能力。與SGN[13]中的結構相比,本文通過在雙重卷積層之間引入ResNet[15]中的快捷連接(skip connection)的方式,確保幀內信息的多次使用,從而在加強幀與幀之間相關性的同時,加強特征的表現能力。
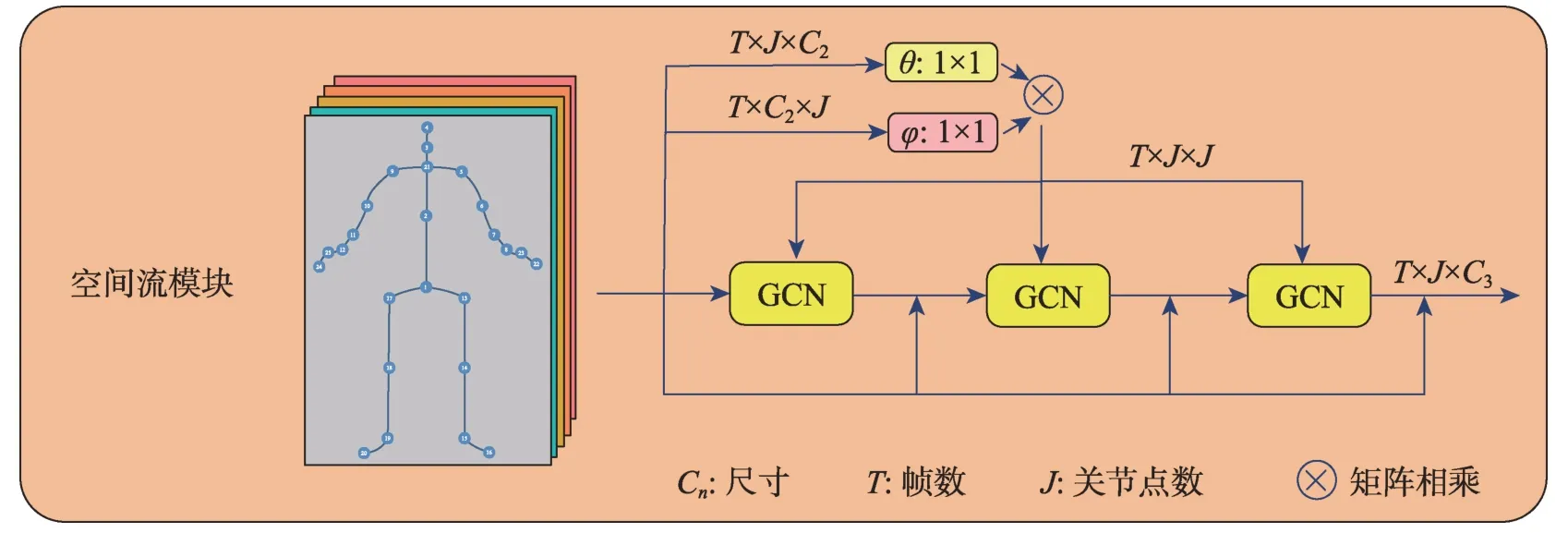
Fig.3 Spatial flow module圖3 空間流模塊
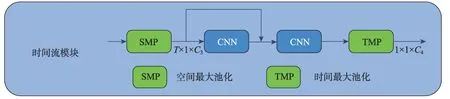
Fig.4 Temporal flow module圖4 時間流模塊
1.6 融合多模態數據的輕量級圖卷積網絡的參數量對比
近幾年,雖然基于人體骨架的行為識別方法成為了主要研究方向之一,但是這些方法往往都存在一些問題。一方面是這些方法往往通過構建復雜的網絡結構的方式來提高實驗精度,針對人體骨架這種簡單有效的數據而言,過于復雜的網絡結構會造成整體計算效率的低下。另一方面,這些方法在初始數據集的基礎上生成多個派生數據集用于訓練,通過將多個派生數據集上的訓練結果進行融合的方式獲得更高的精度,這造成了時間成本的大量浪費。
為了解決這一問題,本文提出了一種基于人體骨架的輕量級行為識別方法。除了網絡結構更加高效之外,訓練過程也較為簡單。不同于之前一些基于圖卷積的方法所采用的方法,該方法并不需要在多個派生數據集上進行多次訓練。本文通過多模態數據融合的方式直接將多種信息流進行融合,這樣做的好處就是可以避免生成多個對應的派生數據集,將訓練次數減少為一次,從而降低網絡的整體參數量。與之前的方法相比,該方法最大的特點就是能夠在參數量與精度之間達到很好的平衡,即通過較少的參數量達到甚至超過之前的一些方法的精度。
為了驗證該方法的具體表現,與近兩年的方法在NTU60 RGB+D[15]數據集的X-sub 標準上進行了比較。如圖5 所示,ST-GCN[11]、2s-AGCN[12]、AS-GCN(actional-structural graph convolutional networks)[16]這三個方法均是基于GCN 的方法,相比于其他方法可以看出,使用了圖卷積的方法在參數量和精度方面都有較好的表現。相較于基于CNN 的方法VA-CNN(view adaptive convolutional neural networks)[17]與基于RNN 的方法AGC-LSTM(joint)(attention enhanced graph convolutional LSTM network)[18],雖然同樣取得了不錯的結果,但是參數量卻遠超其他方法。通過對比可以發現,相比于VA-CNN[17]與AGC-LSTM(joint)[18]這兩類非圖卷積方法,本文方法不僅在精度上有很大的提升,同時參數量也僅為VA-CNN[17]與AGC-LSTM(joint)[18]的1/100;相比于ST-GCN[11]、2s-AGCN[12]、AS-GCN[16]這三個均是基于GCN 的方法,本文方法同樣在精度和參數量上有明顯優勢。此外,通過與SGN[13]進行對比可以發現,SGN[13]的參數量為6.9×105,而本文方法參數量為7.7×105;如果僅從參數量上看,由于本文方法從結構上對SGN[13]網絡中的空間流模塊和時間流模塊進行了優化,導致了參數量比它略多了8×104;但是從精度對比上看,在NTU60 RGB+D[15]數據集上本文提升了約1 個百分點,在NTU120 RGB+D 數據集[19]上,提升了約3 個百分點,通過增加少量的參數量,得到在精度上的較大提升。通過綜合比較可以看出,在綜合考慮參數量與精度的情況下,本文方法均取得了很好的效果。
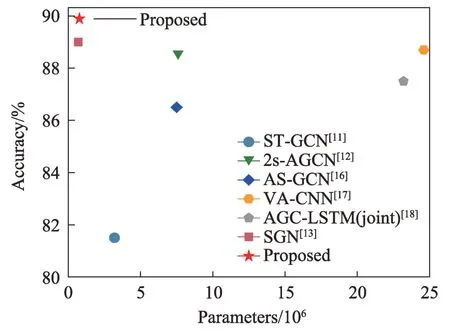
Fig.5 Comparison of parameters of different methods圖5 不同方法參數量對比
1.7 算法介紹
根據1.3 節公式的推導過程與1.4 節、1.5 節對空間流模塊和時間流模塊的描述,本文算法的具體流程描述如算法1 所示。
算法1本文算法的具體流程
輸入:維度為(T×J×C1)的原始骨架序列。
輸出:最終分類結果。


2 實驗結果與分析
2.1 數據集
本文使用了兩個目前主流的基于人體骨架的數據集NTU60 RGB+D 數據集[20]和NTU120 RGB+D 數據集[19],作為實驗對象,其樣例如圖6 所示。
Fig.6 Visualization of three actions(reading,writing and shaking hands)in NTU RGB+D dataset圖6 NTU RGB+D 數據集中三種行為(閱讀、書寫、握手)的可視化
NTU60 RGB+D[15]數據集出自新加坡南洋理工大學,該數據集由3 個Microsoft Kinect v2 相機同時捕獲完成,具體采樣點的分布如圖7 所示。該數據集采集的關節點數為25,相機擺放位置組合有17 個,由56 880 個動作片段組成,包含有40 名演員執行的60個動作分類。
本文采用了該數據的兩種評判標準:(1)跨表演人(X-Sub),X-Sub 表示訓練集和驗證集中的行為來自不同的演員,其中身份標識為1、2、4、5、8、9、13、14、15、16、17、18、19、25、27、28、31、34、35、38 的演員所演示的行為用于訓練,而其余的用作測試,其中訓練集樣本數為40 320,測試集樣本數為16 560。(2)跨視角(X-View),X-View 表示標號為2 和3 的攝像機所拍攝的行為用作訓練集數據,另一個用作測試,其中訓練集樣本數為37 920,測試集樣本為18 960。
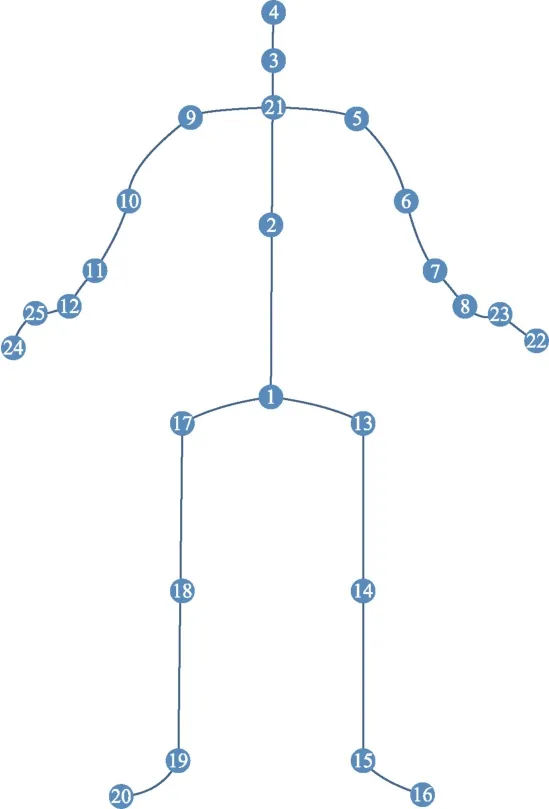
Fig.7 NTU RGB+D dataset joint point labels圖7 NTU RGB+D 數據集關節點標簽
NTU120 RGB+D 數據集[19]是對原數據集的擴充,相機擺放位置組合由17 個擴充到32 個,動作分類由原來的60 類行為擴充到120 類,演員人數擴充為106人,動作片段擴充到114 480,關節點數保持不變。
本文采用該數據集的兩種評判標準:(1)跨表演人(X-Sub),X-Sub 表示訓練集和驗證集中的行為來自不同的演員,其中身份標識為1、2、4、5、8、9、13、14、15、16、17、18、19、25、27、28、31、34、35、38、45、46、47、49、50、52、53、54、55、56、57、58、59、70、74、78、80、81、82、83、84、85、86、89、91、92、93、94、95、97、98、100、103 的演員所演示的行為用于訓練,而其余的用作測試。(2)跨相機擺放位置(X-Set),X-Set 表示將身份標識為偶數的相機擺放位置組合用于訓練,其余的用作測試。
2.2 實驗細節
在實驗過程中,將batch 設置為64,模型迭代次數(epoch)設置為120,批大小(batch size)為64,初始學習率為0.1,當迭代次數分別為60、90、110 時,學習率乘以0.1。為了節省計算資源,提高計算效率,選用Adam 算法對模型進行優化,其中權重系數(weight decay)為0.000 1。為了防止過擬合,在訓練時加入了Dropout,并設置為0.2。所有的模型由一塊GeForce RTX 2080 Ti GPU 訓練完成,深度學習框架為PyTorch1.3,Python 版本為3.6。
2.3 實驗結果
為了驗證算法的效果,本文在NTU60 RGB+D[15]與NTU120 RGB+D[19]兩個數據庫上進行實驗對比,同時為了驗證該網絡在較低參數量的情況下的具體表現,僅選擇近兩年內提出的主流方法作為參考比較的對象。其中在NTU60 RGB+D 數據集上的實驗結果如表1 所示。
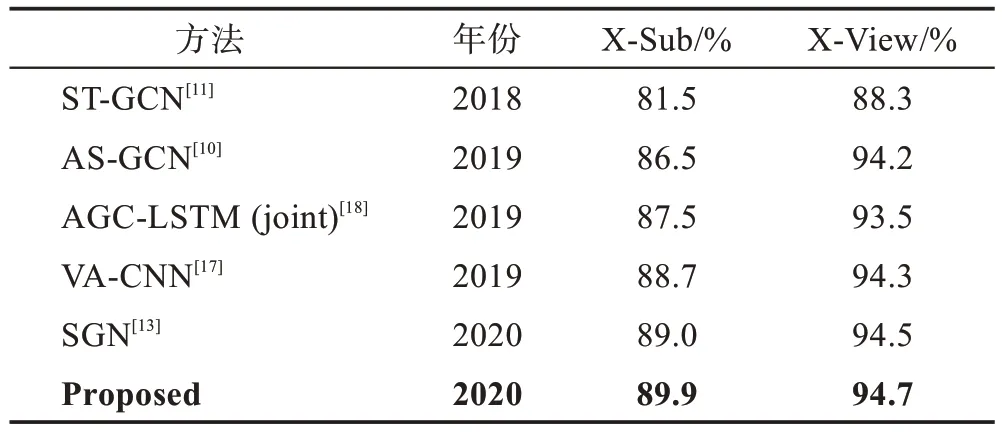
Table 1 Comparison of accuracy on NTU60 RGB+D dataset表1 NTU60 RGB+D 數據集上的實驗精度對比
本文方法在NTU60 RGB+D數據集上的X-Sub與X-View 兩個評價標準上的精度分別為89.9%、94.7%。相比于SGN[13],分別提升了0.9 個百分點與0.2 個百分點。與基于循環神經網絡的方法AGC-LSTM(joint)[18]、基于卷積神經網絡的方法VA-CNN[17]相比,無論是在參數量上還是在精度上,本文方法都有較大的提升。當與基于圖卷積的方法ST-GCN[11]、AS-GCN[10]相比時,本文方法在精度上和參數量上也較為優越。具體的參數展示如表2 所示,相比于近兩年內的其他方法,本文方法綜合表現最為出色。
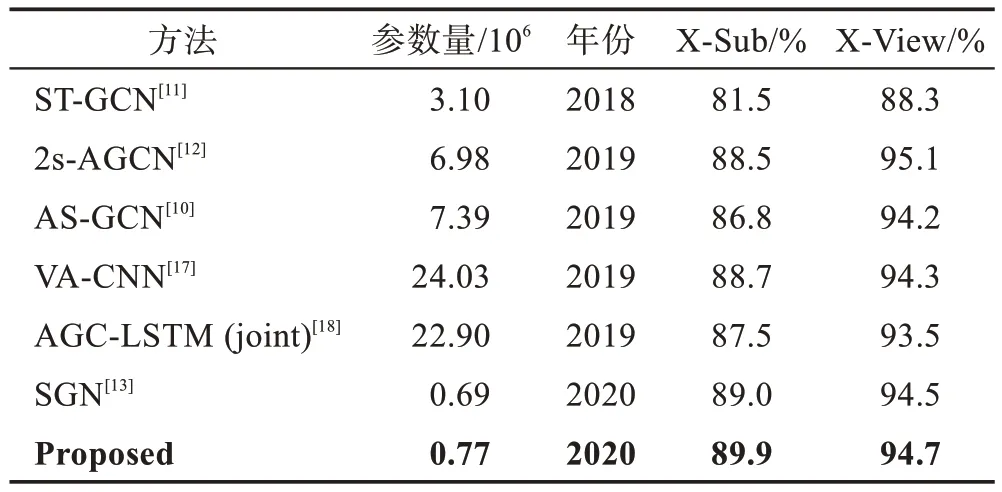
Table 2 Comparison of parameters表2 參數量對比
為了更好地證明本文方法的優越性,同樣在NTU120 RGB+D 數據集[19]上進行了比較,具體的實驗結果如表3 所示。
在NTU120 RGB+D 數據集[19]上的X-Sub與X-Set兩個評價標準上的精度分別為82.1%、83.8%。相比于SGN[13]方法,分別提升了2.9 個百分點與2.3 個百分點。與基于循環神經網絡的方法Logsin-RNN[21]和基于卷積神經網絡的方法Body Pose Evolution Map[22]相比,本文方法有較明顯的優勢。與基于循環神經網絡的方法GVFE+AS-GCN with DH-TCN[23]相比,本文方法也有一定的優勢。在該數據集上的實驗結果表明本文方法可以在兼顧參數量的同時顯著提高實驗精度。
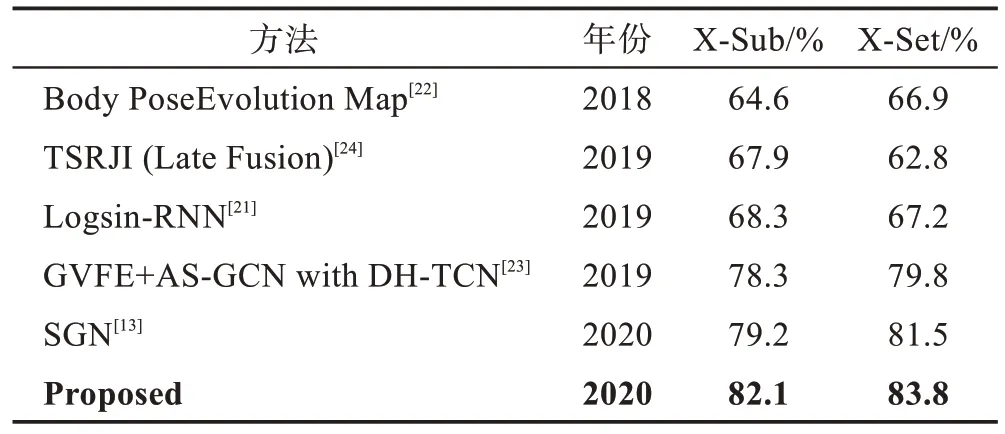
Table 3 Comparison of accuracy on NTU120 RGB+D dataset表3 NTU120 RGB+D 數據集上的實驗精度對比
最后,為了更客觀地證明本文中所提出的多模態數據融合與時空間流模塊的性能和有效性,本文在NTU60 RGB+D 數據集[15]與NTU120 RGB+D 數據集[19]上分別構建了五個網絡,用來測試刪除該模塊后對整個實驗結果的具體影響,具體實驗結果如表4 所示。其中wo-bone(without bone information flow)表示為數據融合中缺少骨長信息流;wo-motion(without motion information flow)表示為數據融合中缺少運動信息流;wo-diff(without velocity difference information flow)表示為數據融合中缺少速度差信息流;wo-diffbone(without bone information flow based on velocity difference)表示為數據融合中缺少基于速度差的骨長信息流。最后一組表示缺少時空間流模塊中的密集連接與快捷連接。通過綜合比較NTU60 RGB+D數據集[15]與NTU120 RGB+D 數據集[19]上各模塊的測試結果,發現在這四類數據之中,缺少骨長信息流和速度差信息流會對實驗結果造成較大影響。綜合上述分析,證明了本文提出的多模態數據融合與時空間流模塊的有效性。
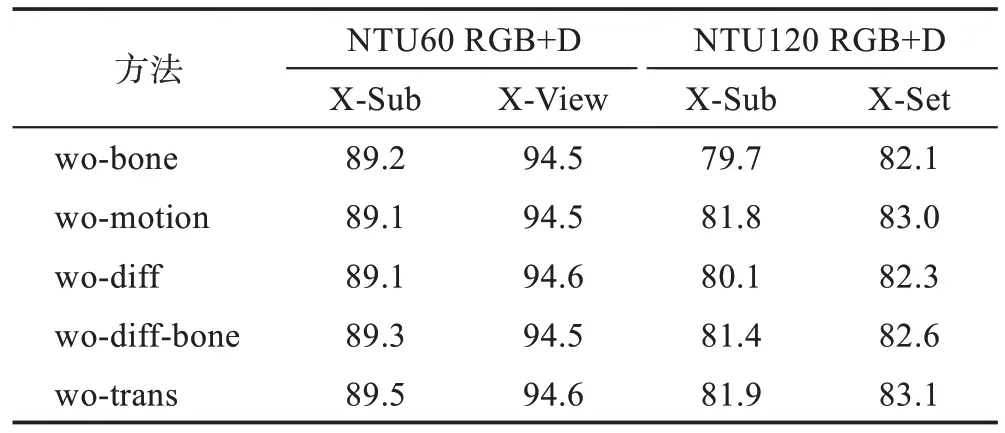
Table 4 Comparison of different modules表4 各模塊對比%
3 結束語
針對傳統的行為識別方法計算復雜度過高的問題,本文提出了一種基于輕量級圖卷積的人體骨架數據的行為識別方法。該算法通過多模態數據融合與自適應圖卷積相結合的方式,在兼顧參數量的同時取得了很好的效果,同時通過密集連接以及快捷連接的方式提高特征的利用率。最后,在行為識別數據集NTU60 RGB+D 和NTU120 RGB+D 上的實驗結果表明,該方法在較低參數量的情況下,能達到較高的實驗精度。美中不足的是,通過密集連接以及快捷連接的方式雖然能夠大幅提高精度,但是仍然會對參數量造成一定的影響。在未來的工作中,將繼續研究基于人體骨架數據的行為識別方法,實現以更少的參數量達到更高的精度這一目標。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
Coco薇(2016年2期)2016-03-22 02:42:52
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
