渦流人工勢場引導下的RRT*移動機器人路徑規劃
2021-04-11 12:49:16陳陽泉高佳佳
計算機與生活 2021年4期
曹 凱,陳陽泉,高 嵩,高佳佳
1.西安工業大學機電工程學院,西安 710021
2.西安工業大學電子信息工程學院,西安 710021
3.加州大學默塞德分校工程學院,美國默塞德95343
近年來智能移動機器人在軍事國防、航空航天以及星球探索方面起到了重要的作用[1-4],因而成為學術界研究和關注的熱點問題。移動機器人在任務空間自由活動的過程中,首先需要解決路徑規劃問題。路徑規劃是在靜態和動態環境、模型約束以及不確定性的情況下,自動生成到達預定目標點的可行和最佳路徑的過程。目前已有許多路徑規劃算法用于解決靜態和動態環境中的運動規劃問題[5],例如人工勢場[6-7]、基于網格的方法[8-9]、神經網絡[10]、進化仿生的方法[11-13]和基于采樣的規劃[14-15]。
人工勢場(artificial potential fields,APF)包括目標點周圍的吸引勢場和障礙物周圍的排斥勢場。吸引勢場使機器人朝向目標移動,斥力勢場使機器人遠離障礙物,最終機器人將朝著吸引和排斥合力的方向移動。雖然APF 具有簡單的數學表達式和較高的計算效率,但也存在一些固有問題:
(1)容易陷入局部最小;
(2)障礙物密集且間隔較小的環境中找不到可行路徑;
(3)在狹窄通道和目標點附近存在障礙物導致無法到達的情況下出現機器人振蕩。
以往的研究大多假設障礙物遠離目標點,在這種情況下,當機器人接近目標位置時,由于障礙物引起的排斥力可以忽略不計,機器人會被吸引力吸引到目標位置。然而,在實際環境中目標位置或許會非常接近障礙物,導致當機器人靠近目標時,也會接近附近的障礙物,而排斥力將遠大于吸引力,并且目標位置不是總勢能的全局最小值。因此,由于附近的障礙物,機器人無法到達目標。針對這一問題,考慮到機器人與目標之間的相對距離,對路徑規劃中的排斥勢函數進行了修正,從而確保總勢在目標位置有一個全局最小值,機器人最終會達到目標[16]。
基于采樣的規劃(sampling-based planning,SBP)算法對配置空間進行純粹的探索,以保證算法的概率完備性。其中Kavraki 等人于1994 年提出的概率路線圖(probabilistic roadmap,PRM)[17]和Lavalle 于1998 年提出的快速隨機探索樹(rapidly-exploring random tree,RRT)[18]是最有效的SBP 算法。然而,PRM對障礙物信息的依賴使得它只適用于靜態環境。相比之下,RRT 更適合動態環境和未知場景,并且可以包含非完整約束條件。
RRT 算法是從根(起始點)開始向未探索的區域隨機生成一棵可行軌跡樹,當其中一條無碰撞軌跡到達目標區域時產生一條可行路徑。而路徑間隙、路徑長度以及規劃時間都取決于節點產生的隨機性。因此,RRT 算法主要問題有:
(1)在初始迭代期間,目標區域附近的有用樣本無法最快做出貢獻,增加了規劃時間;
(2)在整個探索空間中進行探索采樣,產生較多節點,擴大了內存需求;
(3)尋找到的路徑往往不是最優的,路徑成本較高,且向最優路徑收斂緩慢;
(4)車輛與障礙物之間的距離,會改變生成路徑的間隙,從而影響路徑安全。
目前,有大量文獻關于RRT 算法以及RRT*算法存在的問題提出了一些解決方案,例如文獻[19]提出RRT-Connect 方法,它從起始點和目標點生長兩棵不同的樹,同時不斷嘗試用貪婪的啟發式方法連接它們,以改善規劃時間。在文獻[20]中,限制節點擴展的最大數量,并通過刪除無效節點,添加高性能節點,保證了完整節點重新布線后的路徑長度最短,但是收斂速度比RRT*慢。RRT*算法作為RRT 的一種重要變體。文獻[21]中的RRT*算法通過配置路徑成本函數來連接樹中的節點,從而降低路徑長度。文獻[22]和文獻[23]提出在找到可行路徑之后,對路徑再進行優化以得到較短的路徑。文獻[24]使用啟發式滑動窗口采樣減少B-RRT*算法隨機采樣所帶來的誤差,并將車輛運動學約束加入到重選父節點和重布隨機樹的過程,使用貝塞爾曲線對所規劃的路徑進行平滑處理。文獻[25]采用目標偏向策略和氣味擴散法來改善擴展節點的選取,使得隨機樹的生長趨向于目標點,并提出一種基于三次B 樣條曲線的路徑平滑方法,極大地提升了搜索效率和路徑質量。
本研究在APF 中加入渦流的引導,并與RRT*采樣的方法相結合來解決RRT*存在的一些問題。該方法利用渦流人工勢場(vortex-APF,VAPF)引導探索更有前途的配置空間,減少了得到最優路徑的迭代次數,從而降低執行時間,加快收斂速度。在軌跡樹中拒絕插入無效節點和高成本節點,以降低內存需求。然后對可行路徑進行修剪和平滑處理,在無障礙區域連接盡可能少的節點得到一條長度較短、更為平滑的最優或次優路徑。仿真結果表明,該方法在內存需求、執行時間和路徑復雜性方面均具有有效性。
1 相關工作
1.1 RRT*算法
RRT 算法是通過隨機探索自由空間,并構建一棵從起始點(zstart)開始尋找朝向目標狀態的可行路徑的樹。在迭代的過程中,創建隨機點并搜索距離該點最近的頂點,然后以固定步長得到該方向上的新節點,并檢查其是否屬于自由空間,直至達到目標(zgoal)。
RRT*算法使用了三個新的概念對RRT 進行了改進:第一個是新增節點的本地鄰域;第二個是成本函數,它計算了從初始狀態到樹中節點的總成本;第三個是重新布線,它利用路徑成本函數在新增節點的本地鄰域中重新布線,從而降低路徑成本。RRT*算法的流程與RRT 算法類似,在迭代的過程中,創建隨機采樣節點,搜索到該點的最近節點znearest,根據固定步長連接到最近的節點,就形成探索樹中的新節點。新節點領域中的點znear由新節點為中心半徑為r的區域來確定,如果通過新節點的路徑比通過當前父節點的路徑具有更低的成本并且兩點之間是無障礙區域,那么新節點被設置為最佳父節點以保持樹的結構,如圖1 所示。
重復上述過程來維護節點樹的增長,直到達到目標。如果目標狀態位于障礙物空間中,則迭代過程被中止或者尋找路徑失敗,稱為陷阱狀態。RRT*算法的基本流程如下所示。
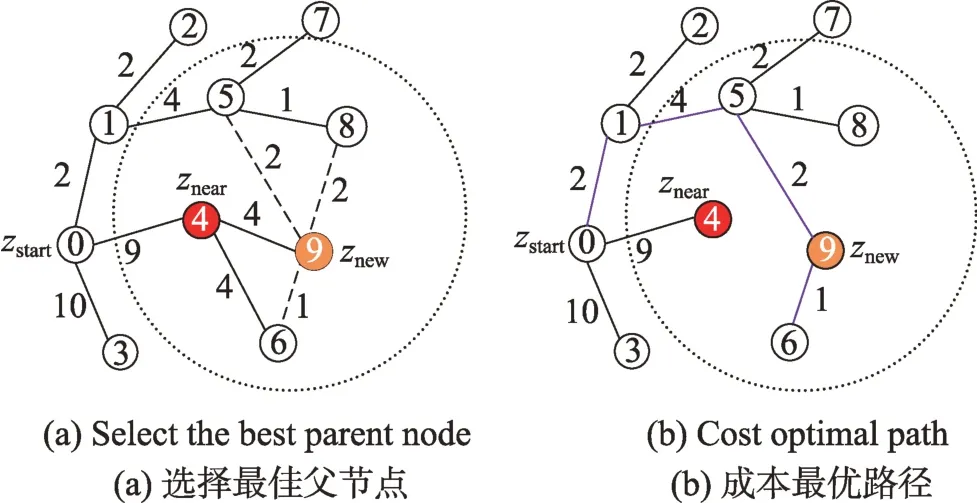
Fig.1 RRT*node extension process圖1 RRT*節點擴展過程
算法1T=(V,E)←RRT*(zstart,zgoal)

1.2 人工勢場法
1986 年,Khatib 提出利用勢場進行避障和路徑規劃的思想[26],即人工勢場法APF。它來自物理學中場的概念,它將物體的運動視為兩種力相互作用的結果。因此在該方法中,機器人被建模為受吸引力和排斥力影響的粒子。障礙物表示為斥力場Urep,目標則是吸引場Uatt。在吸引力和排斥力的共同作用下,機器人沿著合力的方向移動,安全地到達目標區域,即不發生任何碰撞。目標點對于機器人的引力場和斥力場如式(1)和式(2)所示,目標對于機器人的吸引力Fatt和排斥力Frep分別為吸引勢場和排斥勢場的負梯度,如式(3)和式(4)所示。吸引勢場和排斥勢場的矢量和是勢場的總和Ftotal,其計算公式如式(5)所示。

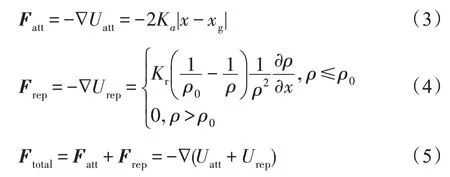
式(1)~(5)中,x是機器人當前的位置,xg為目標點,機器人與障礙物之間的最短距離用ρ表示,ρ0表示勢場的最小影響距離,Ka和Kr分別表示吸引場和斥力場的縮放因子。
2 路徑規劃混合優化方法
2.1 改進的RRT*算法(Improved RRT*)
在RRT*算法中遠離生成路徑的擴展節點重復連線,通常這些節點不僅沒有降低路徑成本,還因為無效節點間的重新布線增加了時間成本。因此,在生成路徑的節點附近進行有意義的重新布線操作,可以有效地改善路徑成本。
改進RRT*算法僅在有前途的區域中探索,生成更有前景的樹T,從而以更少的時間和更小的內存需求找到最佳路徑。它以zstart為根來初始化探索樹T,先確定zstart和zgoal之間的偏向區域BRegion,然后隨機選擇BRegion中的節點進行采樣,找到可行的初始路徑。同時對初始路徑使用節點拒絕技術,去除高成本節點和無效節點,然后進行原始路徑修剪,獲得一條長度更小,節點更少的優化路徑,如圖2 所示。
首先,確定探索區域,使用偏向采樣探索區域,并對采樣產生的節點頻繁地進行重新布線操作,這有利于迅速地降低當前探索路徑的成本。當發現目標節點或目標區域內(最小步長范圍內)的節點時,找到一條從起始位置到目標位置的初始路徑,如圖2(a)所示。如果當前區域探索完成后未找到可行路徑,則重新改變區域的大小,直到找到目標位置,如圖2(c)所示。
傾向得分匹配法可以控制處理組與對照組之間不可觀測且不隨時間變化的組間差異(Heckman,LaLonde & Smith,1999)。此方法的核心邏輯是針對樣本數據中不存在實施過境免簽政策地區在沒有實施此項政策情況下的入境旅游績效的“反事實情形”,采用半參數估計方法估計實施地區未實施該項政策的傾向得分值,進而為實施地區選擇匹配特征盡可能接近的未實施地區,保證處理組與對照組在政策實施前的發展軌跡基本“平行”。
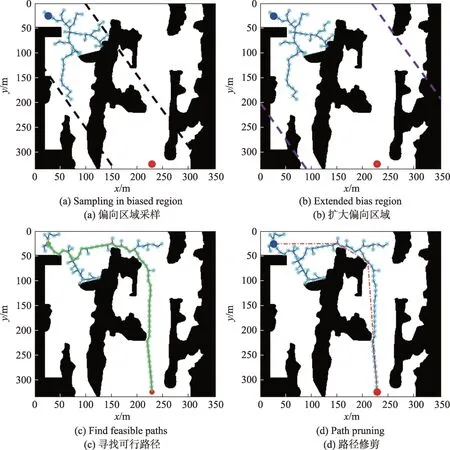
Fig.2 Improved RRT*processing flow圖2 改進的RRT*算法處理流程
探索區域的確定主要是利用起始點和目標點之間的連線的斜率,計算出延長線與地圖邊界之間的交點P和Q,然后對P和Q分別加減100 單位(可根據地圖比例調節),得到與地圖相交的新交點P1、P2、Q1 和Q2,并連接P1 和Q1,P2 和Q2,得到新的直線方程。如果這些新交點超出地圖范圍,則以地圖頂點和直線方程重新計算得到交點P3 和Q3,P3、P2、Q1 和Q3 形成連通區域,如圖3 所示。
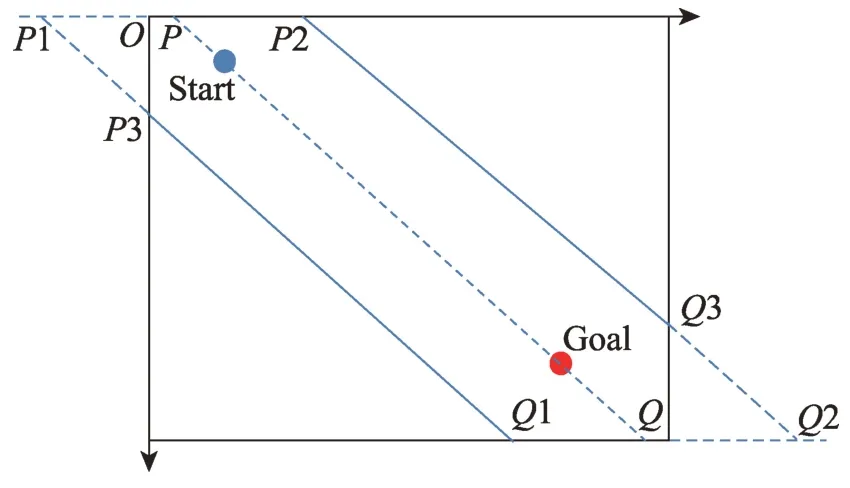
Fig.3 Determining biased region圖3 偏向區域確定的方法
其次,節點拒絕的工作是去除高成本節點和無效節點。如果新的節點和目標之間的距離成本大于當前路徑的距離成本,那么新采樣的節點就被拒絕插入樹中。此外,如果某一個節點不能被擴展(沒有子節點或者僅有一個子節點),這也意味著它不在達到目標狀態的路徑上,這樣的節點也會從樹杈中被刪除掉。因此,只通過有用節點來擴展樹,不僅可以維持樹的成本,還可以快速地尋找到一條路徑成本較小、收斂時間最短、內存需求最少的可行路徑,如圖2(c)所示。
最后,對先前得到的路徑進行修剪(類似于樹木生長過程中需要將多余的樹枝修剪掉,以保證樹主干的營養吸收)。因為RRT*算法是概率完備的,它傾向于隨機點方向構建可行軌跡樹,所以大多數解決方案不是最優的。因此,需要采用修剪算法以獲得路程更短,噪聲更少的路徑,如圖2(d)所示。
路徑修剪的原理如圖4 所示,獲得初始路徑后,從起點開始遍歷每一個路徑節點并相互連線,如果起點和其中的一個節點Zp1之間存在障礙物(藍色虛線),則退回Zp1的上一個節點Zp1-1,而起點到Zp1-1之間的線段就是一段平滑路徑。同時,Zp1-1作為新的起點遍歷剩余的路徑節點。以此類推,直到遍歷到目標點形成一條優化后的低成本路徑(橙色虛線)。

Fig.4 Path pruning圖4 路徑修剪
2.2 改進的APF 方法
APF 方法將障礙物作為移動機器人的斥力場,斥力場是以障礙物為中心產生向外發散的排斥力,從而使機器人遠離障礙物,如圖5 所示。圖5 中的紅色線條表示3 個圓形障礙物向外產生的發散的排斥力。雖然在吸引力的作用下可以到達目標點,往往難以遵循能量最小、時間和路徑最優等優化準則。
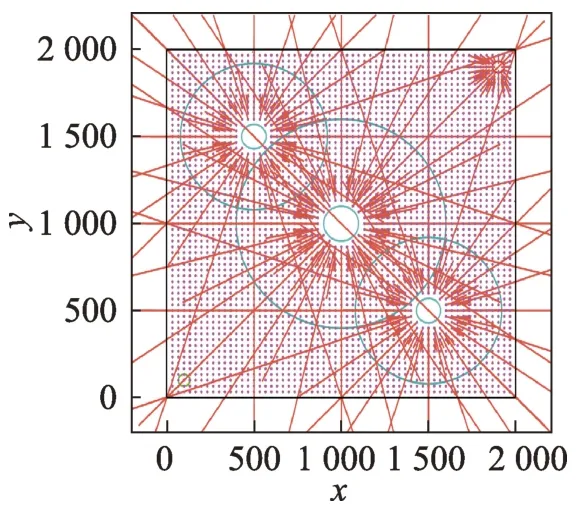
Fig.5 Repulsive field distribution圖5 斥力場分布
本研究在APF 的基礎上將渦流引入勢場,從而形成渦流場。渦流場可以產生切向梯度,利用迫使機器人繞過每個障礙物的動作來代替原本的排斥動作,從而引導機器人避開指向自然運動方向的有害或不利梯度,如圖6 所示。
通過對機器人與障礙物之間位置關系進行反切運算可以得到渦流場的方向。同時,在原有的斥力場計算中加入了梯度信息和機器人與障礙物之間的距離可以得到渦流斥力場。渦流人工勢場(VAPF)的引入,能夠使機器人的路徑更加平滑。
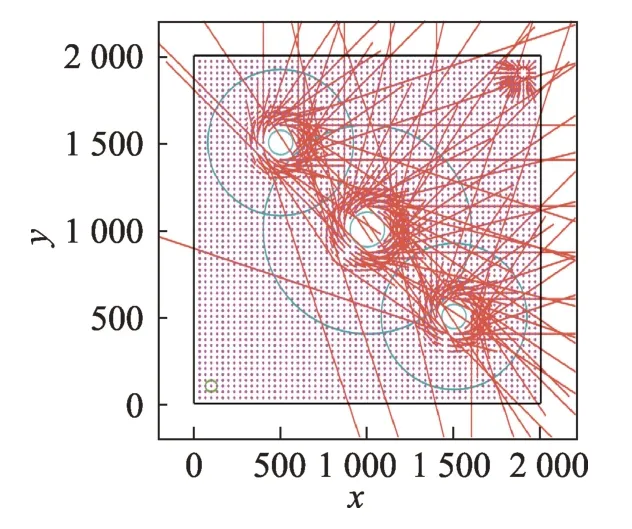
Fig.6 Vortex repulsive field distribution圖6 渦流斥力場分布
2.3 VAPF 與改進的RRT*混合優化方法
首先利用RRT*算法在偏向區域中進行隨機采樣,然后根據機器人的位置和障礙物的影響范圍,計算了作用于機器人的渦流場,并利用隨機吸引場梯度下降對隨機采樣點zrand進行改造,得到一個引導采樣點zprand,同時利用節點拒絕技術將路徑中無效的節點(不在主路徑中的節點)進行剔除,通過節點擴展的迭代得到一條初始路徑,然后進行路徑修剪和路徑平滑處理,最終可以得到一條最優路徑。VAPFRRT*混合優化方法的基本流程如下所示:
算法2T=(V,E)←VAPF-RRT*(zstart,zgoal)


算法第6 行中的隨機梯度下降(randomized gradient descent,RGD)子函數表示隨機吸引場梯度下降,它用吸引勢場對隨機采樣點zrand進行擴展,得到一個改進的采樣點xprand,并將xprand作為后續算法的隨機采樣點。算法流程偽代碼如下所示:
函數1RGD(zrand)
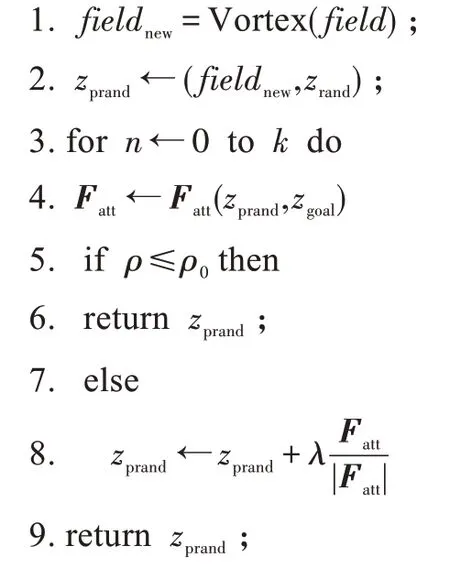
3 算法仿真與結果分析
本研究在Matlab2016 中設計仿真場景,分別使用RRT、改進RRT*和VAPF-RRT*方法進行路徑規劃,考慮到RRT 類算法具有概率隨機性,因此每種方法進行了32 次實驗,取平均路徑長度、執行時間和采樣節點用來分析路徑規劃方法的性能。為了將執行時間限制在合理范圍,迭代次數設定為2 000 次。
仿真場景由多個不同半徑的圓形障礙物組成,使用RRT 和改進RRT*方法完成路徑規劃的效果圖,如圖7 所示。使用VAPF-RRT*方法對障礙物產生的渦流場和路徑規劃效果圖,如圖8 所示。
使用3 種算法在上述場景分別進行32 次仿真實驗,表1 給出了每種算法用于達到最優路徑解的平均執行時間、采樣節點和路徑成本。
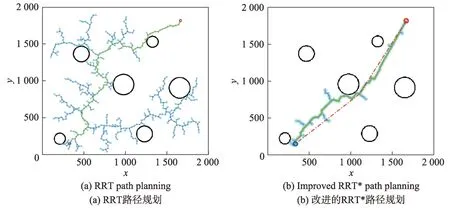
Fig.7 RRT and improved RRT*path planning圖7 RRT 與改進的RRT*方法路徑規劃

Fig.8 VAPF-RRT*vortex and path planning圖8 VAPF-RRT*方法產生的渦流場和路徑規劃

Table 1 Simulation results for calculating optimal or approximate optimal path表1 計算最優或近似最優路徑的仿真結果
從圖7 中可以直觀地看出,改進RRT*方法不論從擴展節點數量還是路徑成本都要優于RRT 算法,而圖8 顯示了VAPF-RRT*算法沒有擴展多余的節點,形成的路徑更加平滑,而且斥力場的存在使機器人與障礙物之間保持相對距離,從而保證了機器人在運動過程中的安全性。通過表1 可以得到,改進RRT*算法的平均執行時間和路徑成本是3 種方法中最優的,相對于RRT 算法和VAPF-RRT*算法,執行時間分別減少了12.1%和33.1%,路徑成本分別縮短了21.1%和10.3%,說明偏向區域搜索可以明確搜索方向,加快收斂速度,降低執行時間;路徑修剪可以修剪多余節點,達到優化路徑的效果。在擴展節點方面,VAPF-RRT*方法的節點數量要優于另外兩種方法,因為VAPF 的渦流場引導RRT*的隨機采樣節點,并將引導節點作為路徑形成的導航點,從而降低擴展節點的數量。改進RRT*方法在偏向區域中隨機采樣再進行節點拒絕,收斂速度要優于使用渦流場來引導采樣節點。雖然路徑修剪使路徑成本有明顯的下降,但是容易出現優化路徑貼著障礙物的情況,而且折線路徑在實際應用中也存在較多問題。
從子函數RGD 流程中可以看出,障礙物勢場的影響距離ρ0會影響引導節點的選取,從而影響執行時間、擴展節點和路徑成本。本研究在實驗過程中分別選取圓形障礙物半徑的1.0、1.5、2.0 和3.0 倍作為障礙物勢場的影響距離,圖9 顯示了選取不同影響距離對于最終路徑形成產生的影響,其中黑色圓圈為障礙物,包圍障礙物的青色圓圈為最小影響距離,綠色圓圈和深藍色圓圈分別為起始點和目標點。
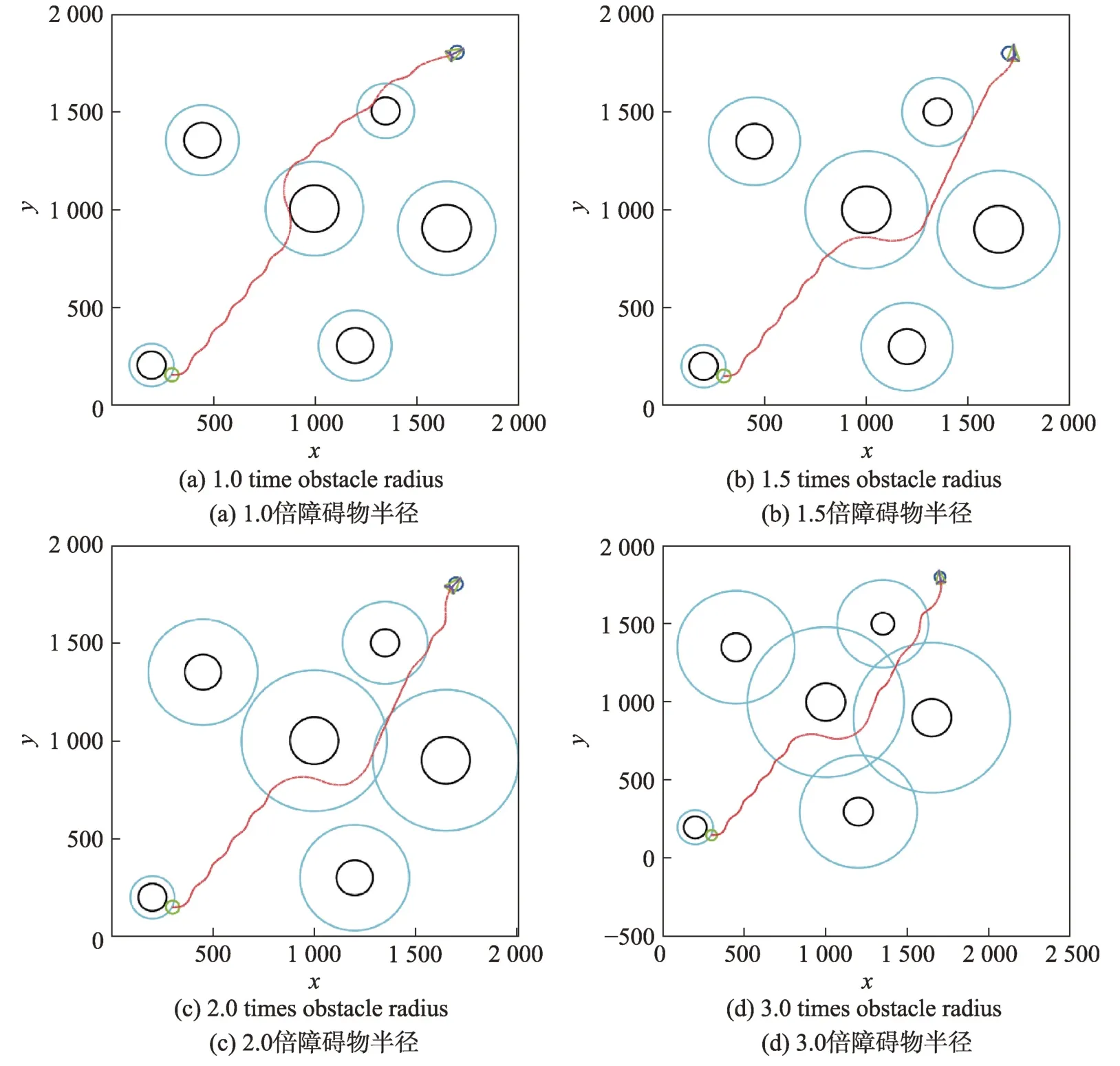
Fig.9 Path planning under different influence radii圖9 不同影響距離下的路徑規劃
從圖9(a)和圖9(b)中可以看出,選取1.0 倍和1.5 倍障礙物半徑作為勢場的影響距離,通過VAPFRRT*算法形成的路徑與障礙物之間保持的距離較小,甚至出現了貼著障礙物運動的情況,這不僅增加了執行時間和路徑成本,也無法保證機器人在運動過程中的安全性。而對2.0 倍半徑的影響距離而言,規劃出的路徑不僅相對平滑,而且可以和障礙物之間保持相對安全的距離。對比圖9(c)和圖9(d)可以發現,路徑與障礙物之間的距離雖然稍有擴大,但后半段的路徑卻出現了波動。通過仿真實驗發現,影響距離在大于2.0 倍障礙物半徑后,逐漸增加影響距離對路徑規劃已無明顯的改變。
綜上所述,仿真結果證明了VAPF-RRT*算法在執行時間、采樣節點、路徑成本方面優化的有效性,如:
(1)在偏向區域內探索,加快了收斂到可行軌跡的速度,減少了規劃時間;
(2)VAPF 算法的渦流場效應使節點產生的方向性增強,從而生長軌跡更為集中的擴展樹;
(3)降低了內存需求,使RRT*算法也可以應用于內存有限的嵌入式系統;
(4)路徑修剪和路徑平滑,可以得到路徑長度相對較短且平滑的路徑;
(5)RRT*算法的隨機性可以克服APF 算法容易陷入局部最優的問題。
4 結束語
在本研究中,提出了一種渦流人工勢場引導下的RRT*算法來解決路徑規劃中存在的一些問題。通過多次仿真實驗,其仿真結果可以定量分析改進算法的優越性、高效性和實用性。實驗結果表明:本文方法可以有效地減少采樣節點,降低規劃時間并優化得到一條相對較短且平滑的路徑。同時,RRT*算法的隨機性又克服了APF 算法容易陷入局部最優的問題。
重復進行實驗后發現,雖然本研究中的方法可以使用較少的時間和較小的內存,但是得到的路徑并非全局最優路徑。此外,也沒有考慮實際場景中工業機器人和移動機器人的運動學和動力學約束條件下的安全問題。未來研究工作中希望可以根據搜索的初始路徑擬合空間貝塞爾曲線,并通過優化曲線控制點使行駛軌跡滿足各類約束的同時,提高路徑的平順性與安全性。最后希望本研究將可以應用于自主無人車輛和工業生產加工的高維運動規劃研究領域。
猜你喜歡
公民與法治(2020年11期)2020-07-25 02:02:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
