基于反向傳播神經(jīng)網(wǎng)絡(luò)模型優(yōu)化冶金廢水單級(jí)脫氮試驗(yàn)研究
2021-04-08 08:11:14鄭小發(fā)王秀模
濕法冶金 2021年2期
鄭小發(fā),楊 麗,刁 月,王秀模
(重慶機(jī)電職業(yè)技術(shù)大學(xué),重慶 402760)

生物廢水處理高度依賴于各種微生物之間復(fù)雜的生物化學(xué)反應(yīng)[10],通過(guò)控制生物反應(yīng)影響因素可提高處理效率,但基本控制因素及具有穩(wěn)定處理效率的優(yōu)化參數(shù)尚未明確。目前,用于廢水處理過(guò)程控制和參數(shù)優(yōu)化的常規(guī)建模方法主要基于單因素/正交試驗(yàn)和物理-數(shù)學(xué)機(jī)制[11-13]。大多數(shù)現(xiàn)有模型(物理-數(shù)學(xué)模型),包括厭氧消化模型(ADM1)、活性污泥模型(ASM1,ASM2)都是基于過(guò)程動(dòng)力學(xué)和傳質(zhì)學(xué)[14];而當(dāng)反應(yīng)器、廢水或微生物工作環(huán)境發(fā)生變化時(shí),這些模型都需要重新校準(zhǔn)[15]。影響廢水中主要污染物質(zhì)去除的因素主要有流體參數(shù)、微生物群落特性及反應(yīng)器操作條件[16]。利用全面自適應(yīng)模型,如機(jī)器學(xué)習(xí)和數(shù)據(jù)驅(qū)動(dòng)模型,結(jié)合數(shù)學(xué)工具(如artificial neural network,ANN)和方差多變量逐步聚類分析[17]對(duì)生物過(guò)程進(jìn)行建模,可以大大減少?gòu)?fù)雜生物過(guò)程建模中所面臨的挑戰(zhàn)。雖然ANN已用于需氧、厭氧系統(tǒng)和其他各種復(fù)雜的網(wǎng)絡(luò)應(yīng)用模式識(shí)別,但ANN和試驗(yàn)設(shè)計(jì)響應(yīng)面法(response surface methodology,RSM)都還需進(jìn)一步研究。
試驗(yàn)提出優(yōu)化2種反向傳播神經(jīng)網(wǎng)絡(luò)模型,開(kāi)發(fā)并應(yīng)用網(wǎng)絡(luò)連接時(shí)間模型,用上流污泥床(upflow-sludge-bed,USB)反應(yīng)器經(jīng)由SNAP工藝處理富氮廢水去除其中的銨和總氮。ANN模型中,以主成分分析為基礎(chǔ),選取一些參數(shù)作為輸入變量,通過(guò)優(yōu)化隱層神經(jīng)元數(shù)目建立優(yōu)化的ANN結(jié)構(gòu),采用基準(zhǔn)比較和多重非線性回歸(multiple nonlinear regression,MNR)模型的Box-Behnken設(shè)計(jì)模型的自適應(yīng)值(初始值)和權(quán)重/偏差值(初始值),預(yù)測(cè)所提出模型的效率,利用16S rRNA高通量基因測(cè)序微生物群落序列,評(píng)價(jià)USB-SNAP過(guò)程中的生物脫氮途徑和效率。
1 試驗(yàn)部分
1.1 廢水及試劑

微量元素溶液(Ⅰ)(g/L):EDTA 5,F(xiàn)eSO40.006 25;
微量元素溶液(Ⅱ)(g/L):EDTA 15,H3BO40.014;ZnSO4·7H2O 0.43,CuSO4·5H2O 0.25,NiCl2·6H2O 0.19, MnCl2·4H2O 0.99,CoCl2·6H2O 0.24,NaMoO4·2H2O 0.22。
混合液懸浮固體溶液、混合液揮發(fā)性懸浮固體溶液采自市政污水處理廠;試驗(yàn)用水為實(shí)驗(yàn)室自制純水。
1.2 試驗(yàn)裝置與儀器
蠕動(dòng)泵(英國(guó)BT10032J Langer Instruments),分光光度計(jì)(日本島津制作所,UV-1800 UV-VIS),精密離子計(jì)(鄭州南北儀器設(shè)備有限公司,PXS450),在線溶解氧探針(INESA:JPB-607A型),Illumina Miseq測(cè)序平臺(tái)(上海桑根生物科技有限公司)。
1.3 分析方法
USB反應(yīng)器的有效工作量和總工作量分別為0.9 L和1.1 L,頂部空間裝配一個(gè)三相分離裝置,可以促進(jìn)操作過(guò)程中生物質(zhì)、液體和氣體的分離。從市政污水處理廠獲得MLSS(混合液懸浮固體)和MLVSS(混合液揮發(fā)性懸浮固體)用于激活USB。采用熱水浴使USB熱敏電阻和數(shù)字溫度控制器在溫度32±1 ℃下運(yùn)行,隨后用不透明材料覆蓋反應(yīng)器,避免光滲透和微生物群落中的光養(yǎng)細(xì)菌生長(zhǎng)[21]。蠕動(dòng)泵用于將廢水輸送到反應(yīng)器中,反應(yīng)器運(yùn)行階段分別是階段Ⅰ、階段Ⅱ和階段Ⅲ,水力停留時(shí)間(HRT)分別為36、24、18 h,氨負(fù)荷率(NLR)分別為120、170、220 g/(m3·d)。
采用分光光度計(jì)在420 nm波長(zhǎng)處測(cè)定水樣中的銨離子質(zhì)量濃度,在540 nm和220 nm處分別測(cè)定亞硝酸鹽和硝酸鹽質(zhì)量濃度;用精密離子計(jì)和在線溶解氧探針?lè)謩e測(cè)定pH和溶解氧水平。
1.4 高通量測(cè)序
對(duì)USB 3個(gè)操作階段結(jié)束時(shí)獲得的污泥進(jìn)行微生物群落調(diào)查,以確定USB內(nèi)的各種反應(yīng)。分離DNA后,用瓊脂糖凝膠電泳和基因組對(duì)DNA進(jìn)行定量聚合酶鏈反應(yīng),隨后在Illumina Miseq測(cè)序平臺(tái)進(jìn)行DNA(僅質(zhì)量DNA)測(cè)序[22],對(duì)序列進(jìn)行聚類分析。
1.5 ANN架構(gòu)說(shuō)明
采用MATLAB軟件2017 B版開(kāi)發(fā)3層(輸入、隱藏和輸出層)反向傳播訓(xùn)練算法ANN模型。ANN模型如圖1所示。圖1表示第i個(gè)權(quán)重輸入和第j個(gè)隱藏神經(jīng)元,輸入層神經(jīng)元數(shù)量,隱藏神經(jīng)元和輸出神經(jīng)元權(quán)重。
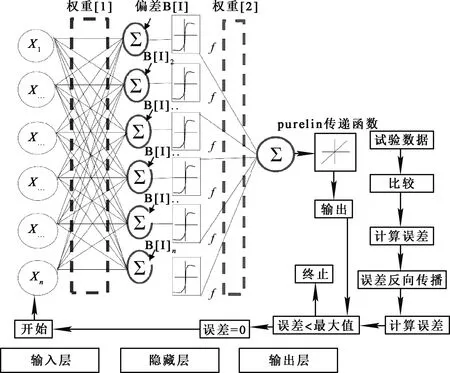
圖1 ANN模型示意
1.6 ANN訓(xùn)練算法和網(wǎng)絡(luò)拓?fù)涞膬?yōu)化
影響SNAP工藝性能的變量主要通過(guò)分析主成分進(jìn)行選擇,通過(guò)將所有相關(guān)變量轉(zhuǎn)換為不相關(guān)變量來(lái)執(zhí)行主成分分析。通過(guò)基準(zhǔn)比較,選擇用于構(gòu)建有效的ANN架構(gòu)的訓(xùn)練算法。選擇MATLAB平臺(tái)訓(xùn)練算法,對(duì)每種訓(xùn)練算法,在隱藏層分配2~18個(gè)神經(jīng)元,并記錄和比較最小均方差[23]。每種訓(xùn)練算法都是在隱藏層指定2個(gè)神經(jīng)元情況下啟動(dòng),然后逐步增加至估計(jì)出最小均方差(MSE)。通過(guò)將整個(gè)數(shù)據(jù)集隨機(jī)分為3個(gè)子集,即訓(xùn)練(70%)、驗(yàn)證(15%)和測(cè)試集(15%)進(jìn)行檢查,隨后采用訓(xùn)練子集來(lái)評(píng)估梯度及形成權(quán)重因子和偏差。訓(xùn)練集開(kāi)始學(xué)習(xí)數(shù)據(jù)集之后采用驗(yàn)證集。從驗(yàn)證集獲得的誤差被連續(xù)用于監(jiān)視訓(xùn)練過(guò)程,基于3級(jí)因子完成Box-Behnken設(shè)計(jì)[24-25]。
2 試驗(yàn)結(jié)果與討論
2.1 USB脫氮效率與微生物群落演替

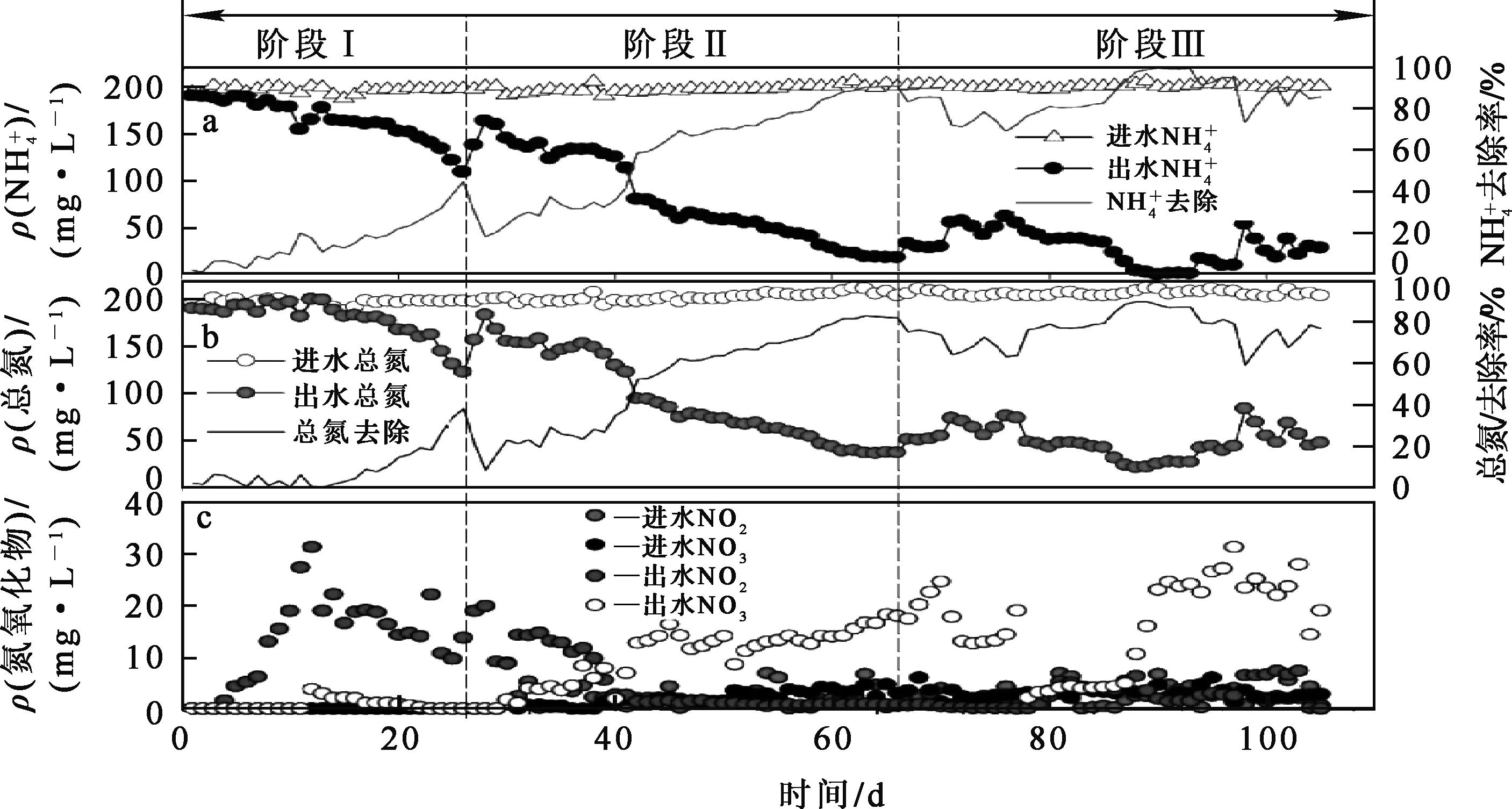
去除率;b—總氮去除率;c—氮氧化物。圖2 USB內(nèi)的脫氮效率
2.2 ANN模型的優(yōu)化
2.2.1 基于基準(zhǔn)比較的最優(yōu)訓(xùn)練函數(shù)識(shí)別
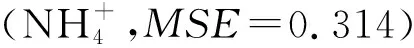
2.2.2 基于ANN模型的性能評(píng)估


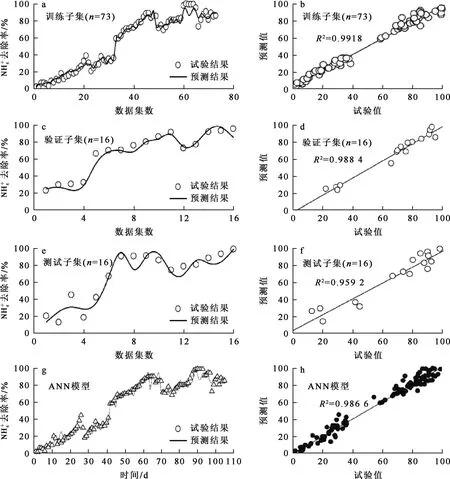
圖3 基于ANN的去除模型
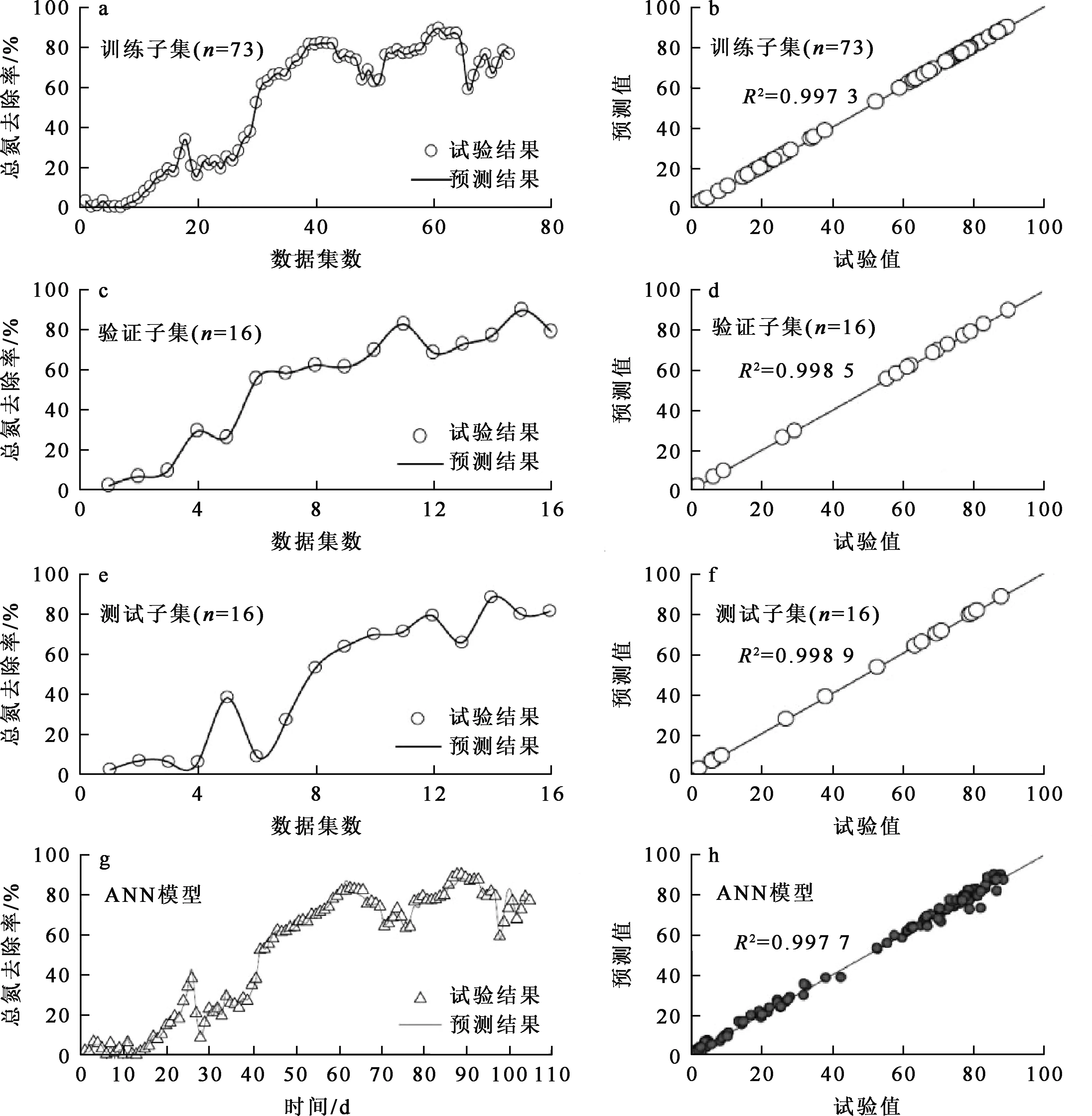
圖4 基于ANN的總氮去除模型

ANN模型能夠?qū)W習(xí)輸入和輸出變量之間的復(fù)雜和非線性相互關(guān)系,而不需要復(fù)雜的狀態(tài)方程和動(dòng)力學(xué)變量[27],所以,通過(guò)模擬和預(yù)測(cè),利用基于ANN的模型對(duì)污水生物處理工藝進(jìn)行優(yōu)化和控制是可行的。此外,本研究也說(shuō)明ANN可以用來(lái)評(píng)估遮蔽函數(shù)并進(jìn)行近似估計(jì),這表明ANN有能力處理非常復(fù)雜的數(shù)據(jù),尤其在需要主觀判斷的領(lǐng)域更具有廣闊應(yīng)用前景。
3 結(jié)論
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
