基于DA-XGboost算法的復雜機械產品質量預測*
2021-03-26 05:43:32董海,田賽
組合機床與自動化加工技術 2021年3期
董 海, 田 賽
(沈陽大學 a.應用技術學院;b.機械工程學院,沈陽 110044)
0 引言
隨著信息技術的發展,復雜機械產品制造過程中相關質量數據的采集對制造產品質量的影響日益重要。從機械產品構成的角度來看,機械產品從整體分解到部件,再從部件分解到零件的過程中,產品質量特性數據集的維度會隨之提高[1]。正是由于復雜機械產品自身特性和生產方式的影響,復雜機械產品的質量特性數據集普遍存在著高維度、小樣本和數據不平衡等特點。
目前,國內外學者通過把智能算法與機器學習算法相結合進行復雜機械產品質量預測。Hsu W H[2]通過結合決策樹和遺傳算法(GA)的特征選擇算法,降低決策樹的分類錯誤率。Li A D等[3]建立改進的非支配排序遺傳算法(NSGA-II),提高對關鍵質量識別的分類準確率。Rao Haidi等[4]結合人工蜂群和梯度增強決策樹的特征選擇,進行關鍵產品質量識別。李岸達等[5]提出多目標鯨魚優化特征算法,利用多樣性帕累托排序策略,解決關鍵質量特性識別中非平衡制造過程數據問題。賈振元等[6]利用灰關聯分析法分析影響產品質量特性的主要因素,再采用BP神經網絡實現對產品質量特性的預測。徐蘭等[7]以灰色關聯度為目標函數,結合粒子群算法和BP神經網絡進行質量預測。蔣晉文等[8]采用XGboost(eXtreme Gradient Boosting)算法識別出對質量影響較大的特征變量,對制造業進行質量預測。李先飛等[9]針對SVM參數選擇精度不高、收斂速度慢的問題,提出改進遺傳蜂群算法(IGBCA)對SVM進行參數優化。針對復雜機械產品質量預測中高維小樣本不平衡數據集的分類問題,遺傳算法和粒子群算法等存在訓練速度慢,易陷入局部極值問題,SVM參數選取盲目性。
本文采用蜻蜓算法(Dragonfly Algorithm, DA)[10]進行質量預測特征值選擇,其特點有結構簡單、易于實現且魯棒性強等,再結合XGboost進行質量預測。基于DA-XGboost的復雜機械產品質量預測流程,首先,對數據進行標準化和缺失值處理,保證數據的有效性。其次,以智能算法中的蜻蜓算法對制造過程中的CTQs進行識別,降低數據集的維度。最后,采用機器學習中的XGboost集成分類算法,進行質量預測,如圖1所示。
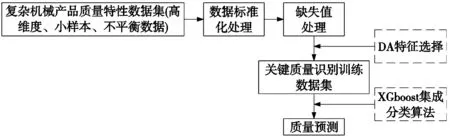
圖1 基于DA-XGboost 的復雜機械產品質量預測流程圖
1 蜻蜓算法概述
1.1 蜻蜓算法
蜻蜓算法主要根據蜻蜓群體的兩種行為模式:靜態群體和動態群體。其中,靜態群體和動態群體的主要特征分別是飛行路徑的局部移動性和方向一致性,并且均依靠以下5種個體行為,其計算公式如下:
(1) 分離
(1)
其中,X為當前個體的位置;Xj為第j個附近個體的位置;N為相鄰個體的個數。
(2) 結隊
(2)
其中,Vj為第j個相鄰個體的速度。
(3) 內聚
(3)
(4) 覓食
Fi=X+-X
(4)
其中,X+為食物所在的位置。
(5) 躲避外敵
Ei=X-+X
(5)
其中,X-為敵人所在的位置。
為了在搜索空間里更新蜻蜓的位置并模擬其飛行行為,設置了兩個向量:步長向量(ΔX)和位置向量(X)。
位置向量和步長向量計算如下:
Xt+1=Xt+ΔXt+1
(6)
ΔXt+1=(sSi+aAi+cCi+fFi+eEi)+ωΔXt
(7)
其中,s為分離權重;a為結隊權重;c為內聚權重;f為覓食因子;e為外敵因子;Si為第i個體分離后的位置;Ai為第i個體結隊后的位置;Ci為第i個體內聚后的位置;Fi為第i個體食物的位置;Ei為第i個體外敵的位置;ω為慣性權重;t為當前的迭代次數;Xt為當前t代種群的位置;Xt+1為t+1代種群的位置;ΔXt+1為t+1代位置更新步長。
當周圍無鄰近蜻蜓時,定義蜻蜓遵照如下隨機游走行為:
Xt+1=Xt+Le′vy(d)Xt
(8)
其中,t為當前迭代次數;d為位置向量維數;Le′vy為設定的飛行函數,計算公式如下:
(9)
(10)

1.2 算法流程
算法流程框架如圖2所示。
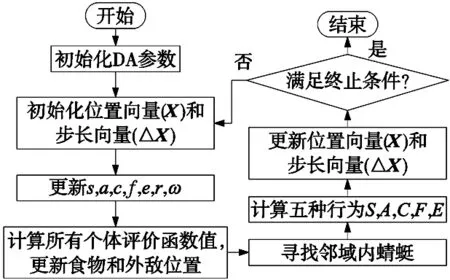
圖2 DA流程圖
具體算法:
步驟1:初始化DA參數。如初始化種群數量和空間維度等。
步驟2:初始化X和ΔX。隨機初始化個體的位置和步長。
步驟3:更新權重值。進行各個權重的初始化。
步驟4:計算所有個體評價函數值,更新X+和X-。根據位置X計算個體對應的函數值,再通過比較,尋找蜻蜓的最優個體和最差個體。
步驟5:尋找領域內蜻蜓。通過計算歐式距離,判斷鄰域內是否存在其他蜻蜓。存在其他蜻蜓,應用式(6)和式(7)更新蜻蜓的位置和步長,反之,應用式(8)更新相應的位置。
步驟6:計算S,A,C,F,E。使用式(1)~式(5)計算各個行為度。
步驟7:更新位置向量(X)和步長向量(ΔX)。
步驟8:判斷是否結束算法的下一次迭代,直到達到最大迭代次數終止,若此時迭代過程滿足終止條件,則直接停止,若不滿足終止條件,則迭代次數加1,繼續執行迭代,跳轉執行步驟2。
2 基于XGboost的復雜機械產品質量預測
XGboost[11]相對于傳統的GBDT,XGboost不僅支持CART(Classification and Regression Trees),還支持線性分類器,降低模型的方差,使學習到的模型更加簡單,避免過擬合。
假設模型有K個決策樹,即:
(11)
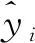
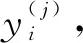
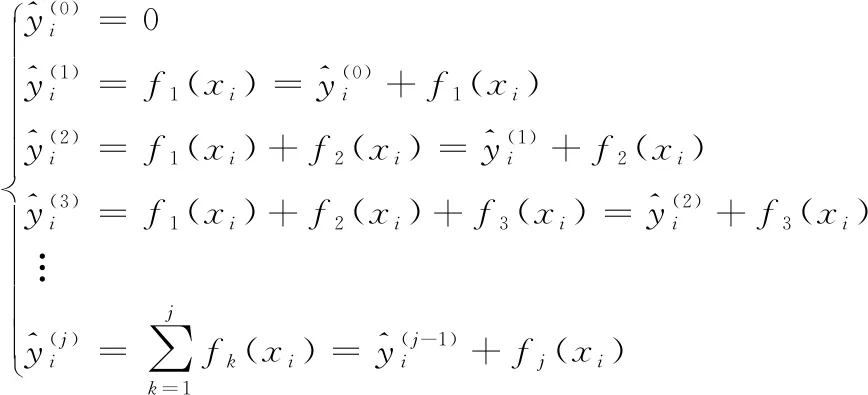
(12)
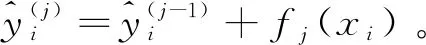
因此,得到XGboost算法的目標函數,如式(13)所示。
(13)
對目標函數泰勒展開,如式(14)所示:
Ω(fj)+constant
(14)
其中,gi、hi分別是1階和2階導數。
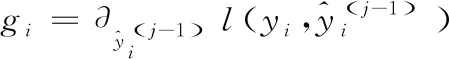
(15)
移除常數項有:
(16)
對于樹,定義其正則項為:
(17)
其中,ωt為樹f中第t個葉子節點上的分值;T為樹f中葉子節點的總數目;γ,λ為XGboost自定義參數,γ為L1正則的懲罰項,λ為L2正則的懲罰項。
將It={i|q(xi)=t}定義為第t個葉子點,即:
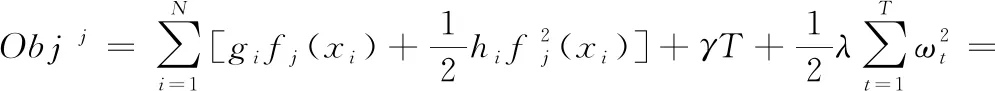
(18)
對上式求導并求其極值,可得:
(19)
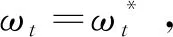
(20)
由式(20)可知,目標值越小,整個樹的結構最優。
3 案例分析
3.1 數據集選擇
通過如下實例驗證本文所建預測模型和所提特征選擇算法。該數據集為UCI數據庫中SECOM數據集,屬于高維且樣本量較少的數據。如表1所示,該數據集是半導體的最終質量,其中“N1”“N2”…“N590”表示樣本的質量特性,“-1”表示合格,“1”表示不合格。
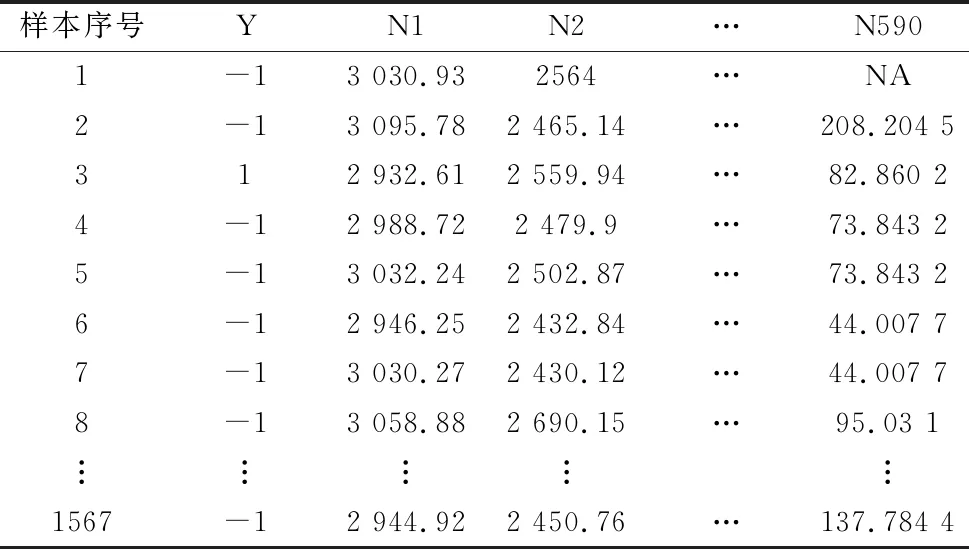
表1 SECOM數據集
3.2 仿真分析
以SECOM數據集為例,圖3表示利用蜻蜓算法(DA)、遺傳算法(GA)、粒子群算法(PSO)表示在搜索過程中隨著迭代次數的增加適應值函數的曲線,其中適應值函數綜合了分類精度和特征子集的特征量。
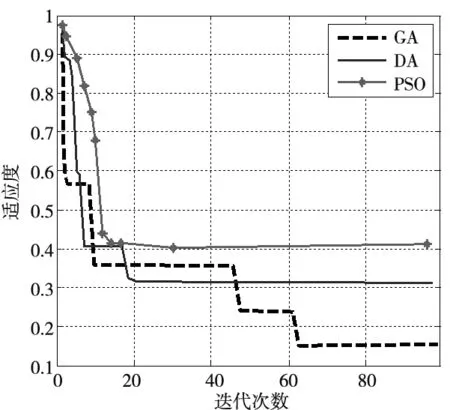
圖3 數據集收斂曲線圖
可以看出DA在19代時收斂于0.32,PSO在30代收斂于0.4,GA在61代收斂于0.15。DA更早收斂,說明在前期有可能找到更優解并向更優的區域搜索并收斂。
表2列出10次運行結果的中值、最優值、標準差及選擇的特征數量。由實驗結果可知,DA在精確度和選擇的特征數量指標表現優于GA和PSO。
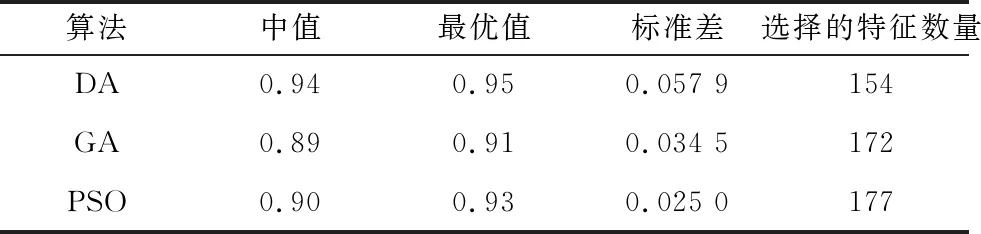
表2 SECOM數據集結果
將降維后的數據分別用XGboost和SVM進行分類,并選擇在ACC指標和AUC指標來評價所構建的復雜機械產品質量預測模型,參數K為5、10、15、20、25、30時的實驗結果如表3所示。
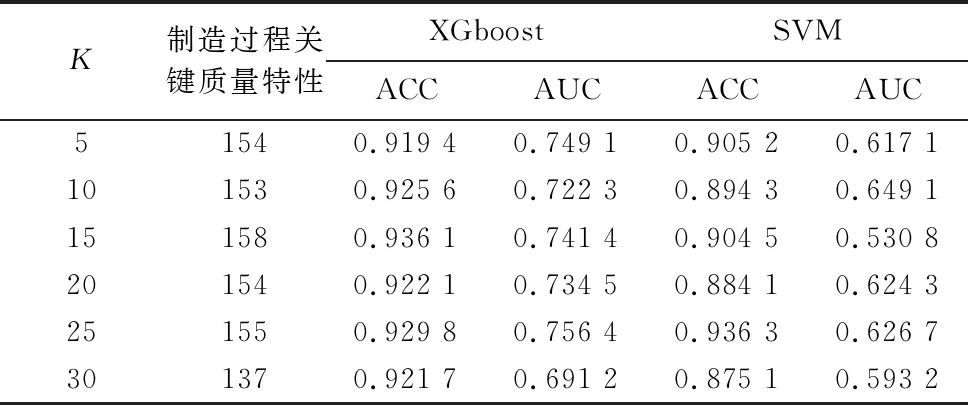
表3 DA-XGboost與DA-SVM預測結果
表3為DA特征選擇算法下XGboost與SVM的ACC與AUC指標對比,可以看出:無論參數K取何值時,大多數的情況下XGboost的ACC值和AUC值均比SVM值大且參數K取25時最優。
綜上可知:對于復雜機械產品的高維小樣本不平衡數據集,XGboost的預測結果皆優于SVM,表明XGboost更適合應用于復雜機械產品質量的預測。
4 結論
本文針對復雜機械產品的高維小樣本數據不平衡,采用基于DA-XGboost算法進行復雜機械產品質量預測,最終可得到結論如下:
(1)采用特征選擇算法DA識別制造過程中的CTQs,有效降低了復雜機械產品質量特性數據集的維度。
(2)提出基于XGboost集成分類算法,構建了復雜機械產品質量預測模型,該算法可以有效降低模型的復雜度,防止過擬合。
(3)通過仿真實驗表明,基于DA-XGboost的質量預測模型在對復雜機械產品質量進行預測時,其特征選擇算法的迭代速度、精確度和選擇的特征數量明顯要高于GA與PSO,分類性能也明顯優于SVM,同時驗證了該算法具有良好的穩定性。
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
當代工人(2020年8期)2020-05-25 09:07:38
中國眼鏡科技雜志(2019年9期)2019-11-11 12:15:30
勞動保護(2019年7期)2019-08-27 00:41:04
中國生殖健康(2019年2期)2019-08-23 08:12:08
質量技術監督研究(2018年1期)2018-03-26 08:04:36
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
新農業(2016年20期)2016-08-16 11:56:22
科技知識動漫(2016年8期)2016-07-29 20:40:09
