計算機Matlab軟件的SVM回歸分析設計研究
2021-03-26 03:29:50秦昌琪
電子元器件與信息技術 2021年11期
秦昌琪
(江蘇信息職業技術學院,江蘇 無錫 214000)
0 引言
隨著我國電子計算機技術的不斷發展,Matlab得到了越來越廣泛的應用,該軟件在鐵路貨運領域的應用大幅提升了貨運量運輸預測的準確性,為鐵路資源的合理調配提供了大量的科學依據。做好SVM回歸分析的關鍵在于預測模型的設計工作,本文將對SVM預測模型的設計方案進行重點介紹。
1 鐵路貨運量SVM預測模型的基本設計思路
SVM即Support Vector Machine,中文為支持向量機,是一種常用的回歸分析手段,本質上特征空間上間隔最大的線性分類器[1],能夠針對未知的新樣本實施高水平的分類預測,其根本目的在于以二次規劃求解的方式來實現預測[2]。在鐵路貨運量的預測方向,本次研究所提出的SVM預測模型的建立流程如下:
第一步:基于現有的貨運量數據實施歸一化處理,進而建立測試樣本數據集和訓練樣本數據集,即通過歸一化的方式將原始數據樣本納入至[a,b]范圍內,所采用的計算公式為:
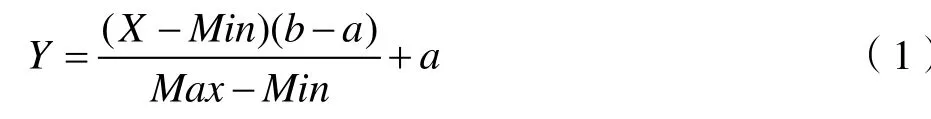
上式將原始數據記為X;將X經過歸一化處理后的數據記為Y;將原數據樣本的最大值記為Max,將原數據樣本的最小值記為Min。
第二步:通過交叉驗證法確定核函數參數g和參數懲罰因子c[3]。設有一個核函數參數g,再隨機將訓練集劃分為k個不相交的子集,將測試樣本鎖定為k,將訓練樣本鎖定為除第k以外的部分,在此基礎上估計該參數的效果,經過k次測試后對比結果,進而提取出合理的參數,最終所獲取的性能評價指標為k次模型結果的MSE平均值。
第三步:在獲取最佳參數的基礎上學習訓練樣本集數據[4]。
第四步:基于測試樣本數據實施預測,通過反歸一化的方式獲取數值。
第五步:對梯形預測結果進行驗證。
為了對所建模型的預測精度及有效性進行驗證,本次研究通過兩種檢驗標準對模型進行了檢驗[5-6]。
(1)通過預測相對誤差對模型預測精度進行檢驗
定義如下所示的預測相對誤差(FRE):

2 鐵路貨運量SVM預測模型的具體設計方案
2.1 基于模糊信息粒化的鐵路貨運量SVM預測模型
本次研究基于MATLAB軟件R2016a版本設計了如圖1所示的鐵路貨運量預測流程。

圖1 SVM 預測流程
第一步:基于目標鐵路站點的流量數據提取出用于預測和訓練的貨運量數據。
第二步:通過三角形模糊信息粒化的處理方式在鐵路貨運量數據中提取出Up數據、R數據和Low數據。
第三步:通過交叉驗證的方式對經過模糊粒化處理的Up數據、R數據和Low數據進行SVM尋優,進而獲得RBF核函數,在此基礎上確定參數g、c的值,再對擬合結果和誤差狀況進行分析。
第四步:在最優參數的基礎上獲取最終決策函數,再針對鐵路貨運量實施訓練與預測,獲取Up、R和Low的值。
第五步:對模型的預測結果進行驗證。
2.2 模糊信息粒化FIG-SVM預測模型
本次研究基于MATLAB軟件R2016a版本設計了如圖2所示的鐵路貨運量預測流程。
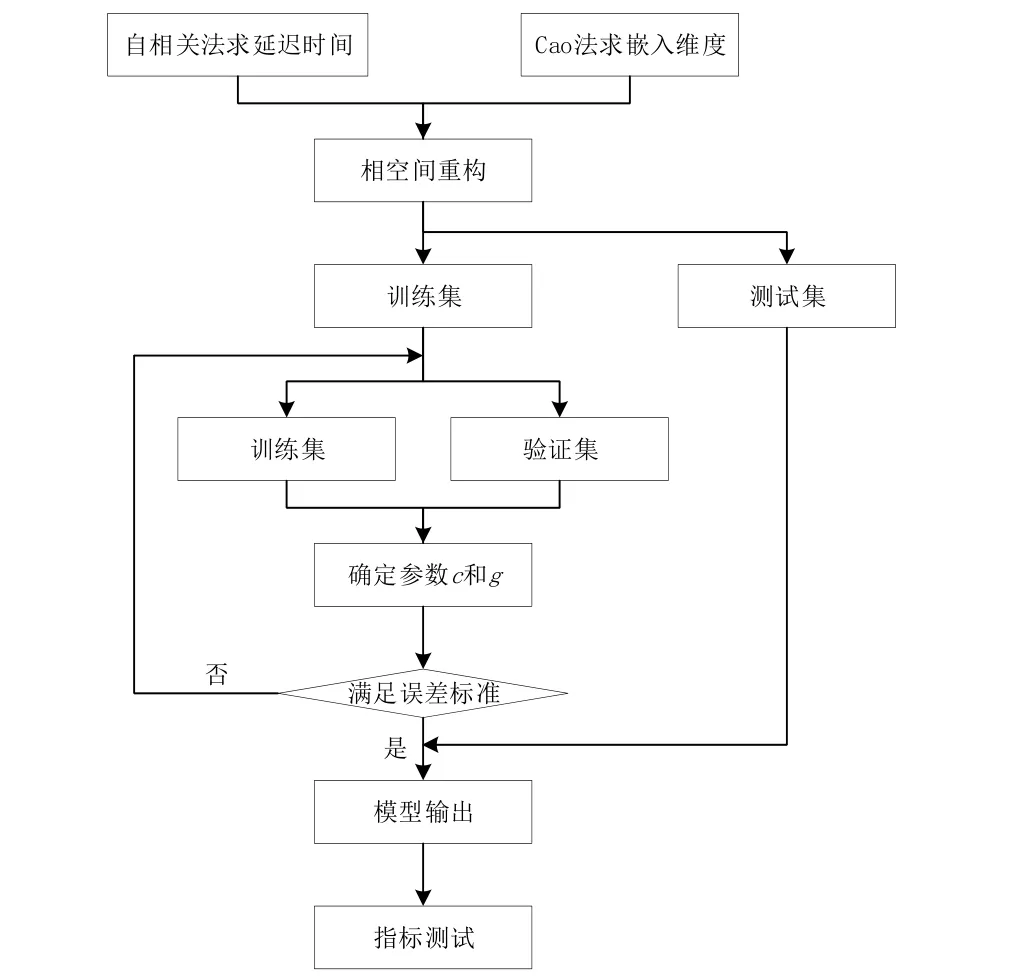
圖2 相空間重構-SVM預測流程圖
第一步:基于目標鐵路站點的流量數據提取出用于預測和訓練的貨運量數據。
第二步:以矩陣形式對鐵路貨運時間序列進行轉換,明確數據之間的關系。為了充分反映系統的運動特征,還需要選取合理的延遲時間τ和嵌入維m,基于經過變形后的一維時間序列提取出輸入樣本X并用于訓練,每一列為一個相點。
第三步:選取RBF核函數,在對貨運量數據進行空間重構處理后對SVM進行尋優,進而獲取參數g和參數c的值,并對誤差進行分析。
第四步:在最優參數的基礎上獲取最終決策函數,再針對鐵路貨運量實施訓練與預測。
第五步:對模型的預測結果進行驗證。

3 結語
本文以鐵路貨運量的SVM預測為例詳細介紹了基于計算機Matlab軟件的SVM回歸分析方法,在未來的研究中,還可以利用最小二乘法、神經網絡法等方法對各種不同的特征的數據進行更加深入的分析,以提升數據預測的準確度,為科學管理提供更加有效的指導。
猜你喜歡
天天愛科學·科學啟蒙(2025年3期)2025-03-27 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南畫報(2021年12期)2021-03-08 00:50:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2018年7期)2018-08-29 01:17:04
光學精密工程(2016年6期)2016-11-07 09:07:19
通信電源技術(2016年4期)2016-04-04 02:58:04
工程建設與設計(2016年3期)2016-02-27 10:50:46
核科學與工程(2015年4期)2015-09-26 11:59:03
