一種結合語義分割模型和圖割的街景影像變化檢測方法
2021-03-26 14:19:40李文國黃亮左小清王譯著
全球定位系統 2021年1期
李文國,黃亮,2,左小清,王譯著
(1.昆明理工大學國土資源工程學院,昆明 650093;2.云南省高校高原山區空間信息測繪技術應用工程研究中心,昆明 650093)
0 引言
隨著城市化和信息化的發展,城市和許多鄉村都具有影像采集設備,同時隨著交通的迅速發展,通過車載平臺采集影像也越來越便利,這都為街景影像信息采集提供了便利手段.實時、精確的街景影像信息采集對城市規劃、土地調查、交通監管、災后評估等諸多領域都具有重要應用價值.但街景影像由于地物與拍攝設備的距離關系,造成同一地物尺度跨度范圍大、遠距離地物界限不清晰;同時也帶來了地物光譜信息復雜多樣的問題,如天空會同時存在陰云和晴空,造成嚴重的“同物異譜”現象.因此,如何自動、高精度的對街景影像進行語義分割和變化檢測就成為當前計算機視覺領域的研究熱點.
當前街景語義分割已開展了大量研究,但對多時相街景影像進行變化檢測的研究則相對較少.文獻[1]提出了基于視覺詞袋模型(BOVW)的場景變化檢測方法,并對比分析了不同字典構建方法對最終結果的影響.為了解決獨立分類所帶來的誤差累計問題,文獻[2]提出核化慢特征分析方法,并通過貝葉斯理論融合場景變化概率和場景分類概率;文獻[3-4]提出利用二維圖像進行場景變化檢測.這種類型的方法根據不同時間段獲取的圖像對場景進行建模,然后在模型的基礎上檢測成對圖像間的變化特征.但這類方法需要拍攝于同一視角的圖像,不同視角拍攝的圖像則無法處理.文獻[5-8]則將場景變化檢測轉換為三維領域的問題.這類方法首先建立穩定持續的目標場景模型,然后將查詢圖像與目標圖像進行比較以檢測變化.但不同區域城市環境差異大,因此所建立的場景模型并不適合其他地區.近年來,深度學習在計算機視覺領域中展現出優異的表現,同時也應用于諸多領域,如自動駕駛、人機交互、醫學研究等,因此目前也有人開展利用深度學習來對場景進行變化檢測.文獻[9]提出結合卷積神經網絡(CNN)和超像素的方法對街景進行變化檢測.這種方法利用CNN提取多時相影像特征,然后將不同時相的特征圖進行對比形成差異圖,再結合超像素所形成的差異圖,形成整幅圖像的差異圖,最后去除天空和建筑,得到建筑物的變化檢測結果.
綜上所述,三維建模的方法不能適用于其他城市,而傳統CNN由于特征圖分辨率不斷變小的原因,會丟失小尺度地物,因此需要一種既能滿足街景影像的特點,同時又具有普適性的方法.為了解決不同尺度地物的語義分割變化檢測精度的影響,引入了對小尺度地物具有很好識別能力的DeeplabV3+網絡模型;同時為了消除天空、植被等對街景影像的影響,將天空、植被等作為背景信息,采用圖割(GC)的方法將背景信息消除.
1 研究方法
本文提出一種結合DeeplabV3+網絡得到的遷移學習模型和GC的街景影像變化檢測方法.方法架構包括3個部分:1)采用DeeplabV3+網絡遷移學習模型分類;2)基于GC的方法去消除天空和植被等影響,并采用變化向量分析(CVA)獲取差異影像;3)差異影像二值化和精度評價.具體而言,首先將兩幅不同時相的街景數據輸入到DeeplabV3+網絡遷移學習模型得到分類圖,將分類圖去除天空和植被得到GC處理后的分類圖,然后將此分類圖進行CVA運算得到差異圖,最后將差異圖二值化并進行精度評價,流程圖如圖1所示.
1.1 街景影像語義分割
當前已有較多語義分割網絡,如U-Net、ICNet、PSPNet、HRNet、Segnet、Deeplab系列.其中,Deeplab V3+網絡結合了空洞卷積與萎縮空間金字塔池化(ASPP),與傳統卷積相比,DeeplabV3+網絡能保持特征圖分辨率不變,對尺寸小的地物具有很好的識別能力,且DeeplabV3+網絡能夠較好的保留邊緣細節信息.DeeplabV3+網絡在PASCAL VOC 2012數據集上取得新的state-of-art表現,其m IoU=89.0,驗證了DeeplabV3+網絡的優秀性能[10].DeeplabV3+網絡于2018年提出,該網絡在原有的DeeplabV3網絡上進行改進,也是目前Deeplab網絡系列中性能最優的網絡.DeeplabV3+網絡具有不同的特征提取主干網絡,不同的特征提取主干網絡會造成網絡性能不一,實驗采用ResNet-18作為特征提取主干網絡,其結構如圖2所示.
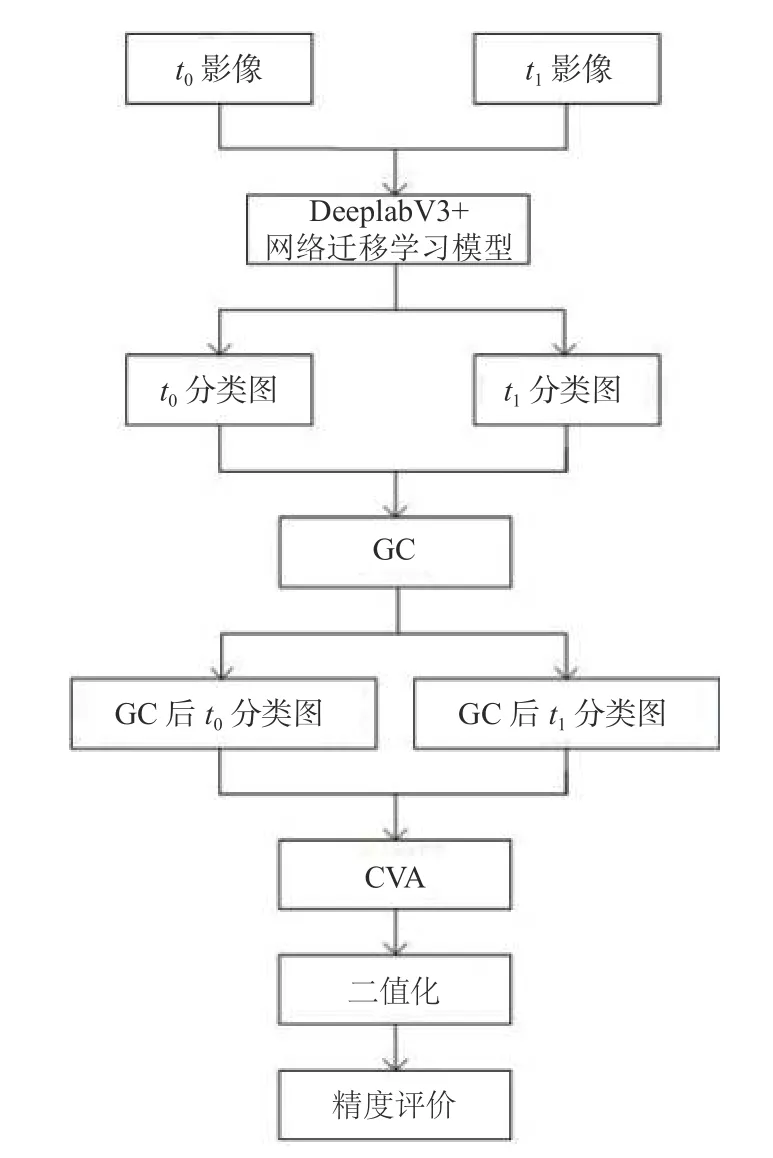
圖1 變化檢測流程圖
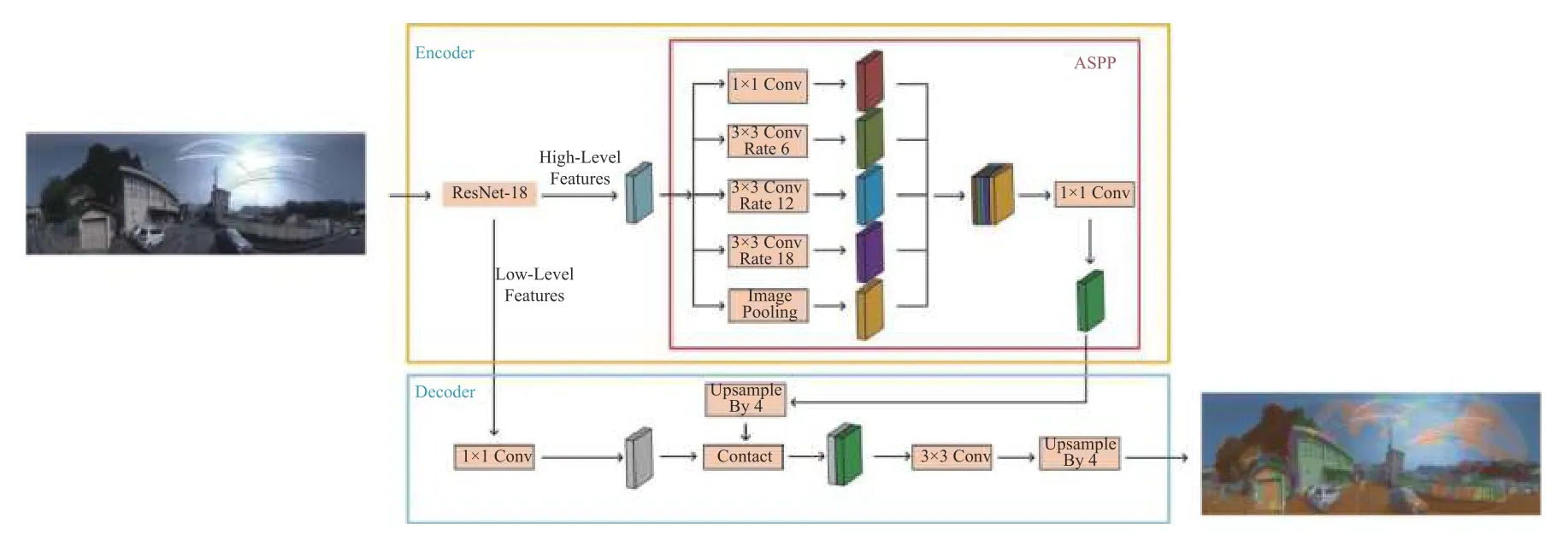
圖2 DeeplabV3+網絡結構
深度學習需要大量的優質標簽,而制作標簽的過程常常是耗時耗力,本文所使用的街景影像數據集標簽數量少,因此會因標簽數量過少導致模型性能差,為了解決標簽數量少的問題,引入遷移學習解決該問題.遷移學習可以減少訓練時間和成本,同時也不需要大量的標簽,在實驗中,采用Camvid數據集訓練的DeeplabV3+網絡遷移學習模型對兩幅不同時相的街景影像進行分類,圖3(a)和圖3(b)分別展示了DeeplabV3+網絡遷移學習模型和Segnet網絡遷移學習模型在街景影像分類結果,其中可以看出DeeplabV3+網絡對汽車、電桿等識別能力優于Segnet網絡,而且邊緣細節也優于Segnet網絡.因此本文選用Deeplab V3+網絡對兩個時相的街景影像進行語義分割.

圖3 Deep labV3+網絡與Segnet網絡分類結果
1.2 背景消除
由于天空和植被等類別存在嚴重的“同物異譜”現象,為了消除“同物異譜”的影響.本文將天空和植被等作為背景類,其他作為目標類.采用GC法對目標類和背景類進行分割.
GC是一種能量優化算法,可以將目標和背景分割出來.GC將圖像分割問題轉換為圖的最小割問題.具體而言,首先圖具有兩種邊和兩種頂點:第一種頂點為普通頂點,對應圖像中每個像素,普通頂點間的連接線構成第一種邊,為n-links;第二種頂點為終端頂點,用于區分前景和背景,因此也就有兩個終端頂點,為S和T,每個普通頂點和終端頂點的連線構成第二種邊,為t-links,每條邊都具有權值.所有邊的集合稱為E,一個割即為邊集合E的子集,為C,集合E中所有邊的斷開會導致S和T的分開,所以就為“割”.如果一個割,它的邊的所有權值之和最小,那么這個就為最小割,也就是GC的結果.Boykov等[11]使用最大流最小割算法實現最小割.
在實驗中,將天空和植被設定為背景,其他類別設定為前景,但未使用最大流最小割算法來計算前景和背景間的分割線,這樣會導致前景和背景分割不精確,部分區域存在錯誤分類,因此人為設定一條分割線,從而實現前景與背景分割.
1.3 差異影像獲取和二值化
為了獲取兩期街景影像語義分割結果的變化區域,本文采用CVA方法.CVA是一種常用的多波段影像差異分析方法,每個像元的特征是采用向量的方式來表示的,g和h為對應波段的一維列向量.由于TSUNAM I數據集使用R、G、B三個波段信息,因此n=3.設時相t1和時相t2中像元的灰度矢量分別為:

?中包含兩期圖像中所有像元的變化信息,其變化強度用歐式距離∥?∥來表示,以此可以生成兩期影像的變化強度圖.

式中,∥?∥中表示全部像元的灰度差異,當∥?∥越大時,則說明變化的可能性越大.因此在分割變化像元和非變化像元,可通過確定變化強度的大小,來選擇分割的最佳閾值.
實驗在獲取差異影像后,將差異影像的像素分為兩種類型:一種為0值,代表未變化區域;一種為非0值,代表變化區域.然后將差異影像中為0值的像素更改為255,將差異影像中非零值的像素更改為0,此過程即為二值化.二值化后黑色像素代表變化區域,白色像素代表未變化區域.
2 實驗結果及分析
2.1 數據介紹
本文采用的街景數據集為TSUNAM I數據集,TSUNAM I數據集來源于文獻[12],是日本某一地區海嘯前后的全景街區影像.圖4展示了實驗選取的兩組街景影像及參考圖,兩組影像的大小都為1 024像素×224像素,對兩組街景影像分別命名為G1和G2,其中t0代表變化前的影像,t1代表變化后的影像,G1組t0和t1影像分別如圖4(a)、圖4(b)所示,G2組t0和t1影像分別如圖4(c)、圖4(d)所示,G1和G2參考圖分別如圖4(e)、圖4(f)所示.G1組影像的變化區域像素為50242,非變化區域像素為 179134;G2組影像變化區域像素為55052,非變化區域像素為174 324.從每組數據兩幅不同時刻的影像中看出建筑物的尺度變化范圍大,遠處的建筑物邊界十分模糊,在陰影地方建筑物與植被界限混淆在一起;同時車輛及電桿等地物也存在尺度范圍變化大,與周圍地物界限模糊的問題,天空不同天氣的原因也造成像素不均勻,高亮區域和灰暗區域同時存在.

圖4 G1和G2街景影像及參考圖
2.2 實驗設計
為了驗證提出方法在街景影像變化檢測中的有效性,設計了兩組對比實驗:1)采用提出方法與OTSU[13]和K均值[14]進行對比;2)采用Segnet、DeeplabV3+網絡、Segnet+GC和本文方法進行對比.精度評價采用文獻[15]中的錯檢率、漏檢率和總體精度.
2.3 第一組對比實驗
實驗采用OTSU、K均值和本文所提出的方法,分別對G1和G2兩組影像進行變化檢測.G1和G2兩組影像采用OTSU方法得到的結果圖如圖5(a)、圖5(b)所示,采用K均值方法得到結果圖如圖5(c)、圖5(d)所示,本文方法結果圖如圖5(e)、圖5(f)所示.實驗結果精度如表1所示.

圖5 第一組對比實驗結果圖
結果表明兩組數據采用本文方法得到的總體精度比OTUS分別高38%、41%,比K均值分別高31%、29%;結合錯檢率與漏檢率來看,本文方法在漏檢率方面雖然與其他兩種方法差別不明顯,但錯檢率方面遠遠少于另外兩種方法;從結果圖來看,本文方法錯檢及漏檢區域都遠遠少于OTSU和K均值.其原因在于DeeplabV3+網絡對街景影像的整體分類效果優于其他兩種方法,同時GC方法有效減少了天空和植被等區域的錯檢.
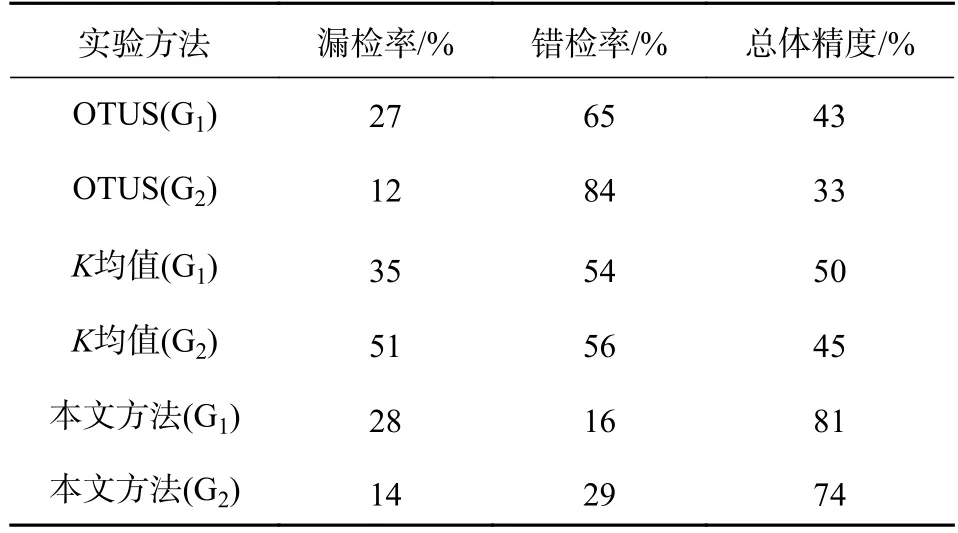
表1 實驗結果精度對比
綜上,本文方法相比OTSU和K均值,不僅變化檢測效果優于OTSU和K均值,而且對街景影像的分類效果也優于OTSU和K均值,因此本文方法更適用于街景影像變化檢測.
2.4 第二組對比實驗
實驗采用Segnet網絡、DeeplabV3+網絡、Segnet網絡結合GC方法和本文方法,分別對G1和G2兩組影像進行變化檢測.G1和G2兩組影像采用Segnet網絡方法得到的結果圖如圖6(a)、圖6(b)所示,采用DeeplabV3+網絡方法得到結果圖如圖6(c)、圖6(d)所示,采用Segnet網絡結合GC方法結果圖如圖6(e)、圖6(f)所示,本文方法結果圖如圖6(g)、圖6(h)所示.實驗結果精度如表2所示.
從實驗結果精度來看,G1和G2兩組街景影像采用本文方法得到的漏檢率比Segnet網絡方法分別低9%、25%,錯檢率比Segnet網絡方法分別低36%、25%,總體精度比Segnet網絡方法分別高30%、25%;對比DeeplabV3+網絡方法,漏檢率比DeeplabV3+網絡方法分別高4%、低1%,錯檢率比DeeplabV3+網絡方法分別低28%、18%,總體精度比DeeplabV3+網絡方法分別高19%、13%.從實驗結果圖來看,本文方法在植被和天空類別的錯檢區域遠少于Segnet網絡方法和DeeplabV3+網絡方法.
G1和G2兩組街景影像采用本文方法得到的漏檢率比Segnet網絡結合GC方法分別低5%、14%,錯檢率比Segnet網絡結合GC方法分別低4%、3%,總體精度比Segnet網絡結合GC方法分別高4%、7%;從精度結果來看,本文方法雖然在漏檢率和總體精度上比Segnet網絡結合GC方法具有一定的優勢,但錯檢率上不存在明顯差別.結合結果圖來看,也未具有明顯的差距.但從DeeplabV3+網絡與Segnet網絡的分類圖可以看出,DeeplabV3+網絡不僅對汽車、樹木等小尺寸地物具有很好的識別能力,同時邊緣細節也優于Segnet網絡.

圖6 第二組對比實驗結果圖
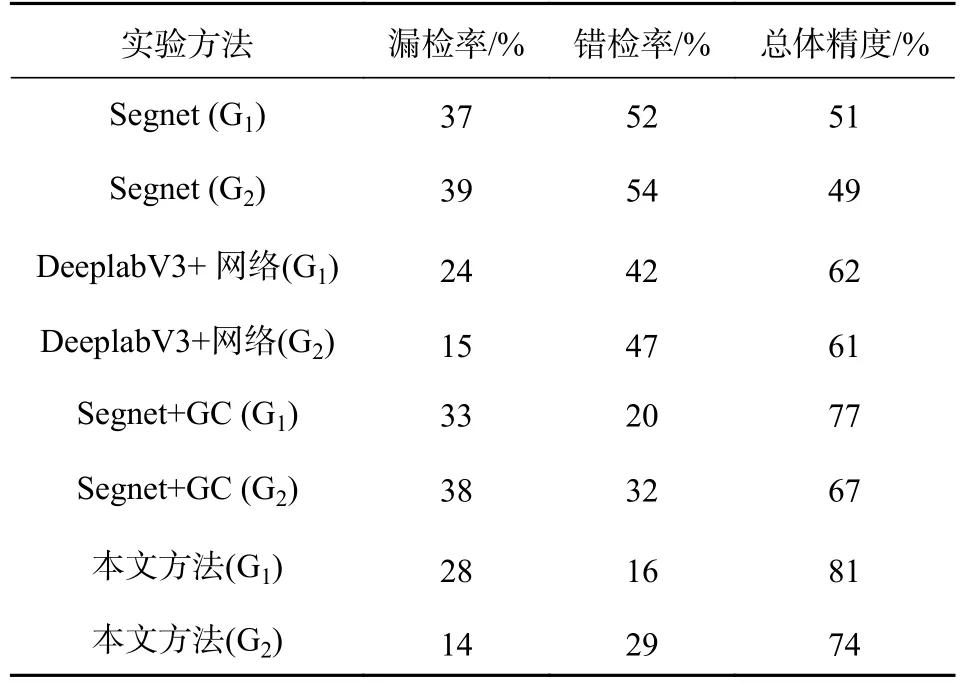
表2 實驗結果精度對比
綜上,本文方法相比Segnet網絡和DeeplabV3+網絡能有效降低錯檢率,同時提升變化檢測精度,而相比Segnet網絡結合GC方法,本文方法得益于空洞卷積及ASPP的優勢,比具有傳統卷積的Segnet網絡更加適合街景數據變化檢測,也更加具有發展潛力.
3 結論
針對多時相街景影像變化檢測,提出了一種結合DeeplabV3+網絡模型和GC的變化檢測方法.為了驗證提出方法,設計了兩組對比實驗,實驗結果表明提出的方法優于傳統的統計方法、機器學習方法、未經改進的Segnet網絡和DeeplabV3+網絡模型.
實驗利用遷移學習的方法對街景數據進行分類,但實際上這種未經過大量樣本訓練的神經網絡泛化能力還有待加強,后續將通過對本數據集街景數據進行大量標注樣本來重新測試網絡,同時,對網絡改進也將成為未來的主要工作.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
