基于代碼行變更指數的異味類排序方法
2021-03-23 09:38:30位歡歡吳海濤高建華
計算機工程與設計 2021年3期
位歡歡,吳海濤,高建華
(上海師范大學 信息與機電工程學院,上海 200234)
0 引 言
代碼異味[1]的出現給軟件質量和可維護性帶來了很大的隱患。而解決它們的有效方式是進行重構,但是由于重構的成本相對較高,對所有的異味進行重構是不現實且不必要的,因為不同異味類的異味程度并不是相等的[2]。因此,需要對異味類進行排序,著重關注那些有較大概率出現異味的代碼。
Vidal等[3]提出了一種基于3個標準的半自動化的異味類排序方法。Fontana等[4]采用度量值與閾值的比較結果(強度值)來對代碼異味進行排序。Natthawute等[5]基于開發人員的角度來研究代碼異味的排序,研究表明開發人員是通過代碼的耦合程度以及組件的重要性來對代碼異味進行篩選和排序的。Anshul Rani等[6]則是通過對不同異味類之間的耦合程度計算出每個類的影響因子,并根據影響因子的大小對代碼異味進行排序。Mcintosh等[7]通過在 5ESS? 軟件項目上進行研究,發現代碼變更的規模與軟件出現錯誤的概率具有相關性。Charalampidou等[8]的研究表明代碼變更的規模與軟件易錯性發生的概率存在正相關關系,即代碼變更規模越大的類,出現異常和錯誤的概率越大。
本文基于代碼變更與軟件易錯性存在正相關關系,通過研究在歷史代碼變更信息中各個類的代碼行數動態變化情況,提出基于代碼行變更指數的異味類排序方法(CLCI)。并在開源項目HospitalAutomationWithJavaEE上進行實證分析,實驗結果表明,本文提出的異味類排序方法可以使后續異味類重構更加容易,從而為項目開發和維護節約成本。
1 相關工作
1.1 異味類排序
Vidal等[3]提出了一種半自動化的方法,用于在決定對代碼異味進行適當重構之前先對異味類進行優先級排序,該排序方法主要基于以下3個標準:發生異味的代碼的穩定性、開發人員是否使用常規標準來對每種異味進行主觀評估,以及相關的可修改性場景。通過在兩個案例研究中進行實驗驗證,結果表明建議的代碼異味順序對開發人員是有用的。其研究結果表明代碼異味排序對于實際的程序開發是有效的。
Fontana等[4]提出基于強度因子來對代碼異味進行排序,強度因子是表示代碼異味強度情況的指標,通過對靜態度量值與閾值的比較并計算得出的。實驗研究是在Qua-litas Corpus上的74個開源項目上進行,實驗使用自己研發的工具JcodeOdor,通過對6種代碼異味進行一些靜態度量值測量來建立實驗模型。但是,強度因子的實驗過程相對復雜,不利于開發人員的實際應用。
Natthawute等[5]通過對10個專業開發人員在異味的選擇和排序需要考慮哪些因素進行問卷調查,把開發人員對于異味的看法分為15個類別,以此來判斷開發人員在異味選擇時最關注的因素。實驗結果表明,開發人員在選擇異味時,工作相關性是首先被考慮的,其次是異味的嚴重性;在開發人員對代碼異味排序時,模塊重要性是普遍被優先關注的,其次是項目相關性。但是,其研究并沒有為開發人員在代碼異味排序提供具體的定量指標。
Anshul Rani等[6]的研究是基于類間的耦合性來對異味進行排序的。實驗共分為兩個部分,第一部分為檢測代碼異味,得到異味類列表;第二部分是基于異味影響因子來對異味類進行排序,影響因子越大表示異味越嚴重。實驗結果表明,根據排序列表進行重構的結果,明顯好于隨機進行重構的結果,作者的研究為開發人員提供新的異味類排序方法。
1.2 代碼變更與軟件易錯率的相關性
Mcintosh等[7]通過在5ESS?軟件項目上進行實證研究,得出代碼變更的規模與軟件出現錯誤的概率具有相關性。通過建立預測模型,研究得出隨著代碼變更次數、代碼變更行數的增加和相關聯的子系統數目的增加,軟件出現錯誤的可能性也會相對增加。此外,不同類型的代碼變更對于軟件系統出錯率的影響是不同的,新增加的代碼出現錯誤的概率要比修復缺陷的代碼變更容易出現錯誤,因為修復代碼的變更相對規模較小。
Charalampidou等[8]通過使用代碼異味出現概率來對常見的TD代碼中的代碼異味進行評估分析,分析異味出現概率與模塊的變化傾向的關系。案例研究的結果表明,比起不易變更模塊中代碼異味出現的概率,代碼異味顯然更易集中在具有變更傾向的模塊中。這些研究結果對研究人員和實踐者都是有用的,可以為后續研究重構策略和重構的優先級提供方向。
陳芝菲[9]通過對大規模數據集的歷史維護信息進行分析,發現出現代碼異味和沒有出現代碼異味的類發生變更或錯誤的次數存在較大的差異。為了進一步探索軟件變更與代碼異味出現的關系,建立負二項回歸模型來對其進行研究,研究表明代碼變更是軟件發生易錯性的最重要因素,尤其是代碼行等自變量。
Luca Gazzola等[10]通過在軟件系統交互時存在故障和程序不穩定問題的研究中,發現代碼的大量變更容易導致項目出現錯誤,并提供統計數據來支持其聲明,更進一步提出應避免對超過25%的現有代碼進行更改,對于此類情況建議重新編碼而不是修改。上述研究均表明代碼變更規模越大,越容易導致項目出現錯誤,給項目后期的維護帶來負擔。
本文基于代碼變更規模與代碼出現異味的概率存在正相關關系,通過關注代碼行數在整個開發過程中的動態變化來定量描述代碼變更的規模,并把代碼變更的規模定義為代碼行變更指數,根據其值的大小來對異味類進行降序排序。
2 代碼行變更指數排序方法
在軟件項目的開發過程中,隨著項目需求的變更、錯誤代碼的修正、軟件項目的優化、測試案例的選擇和后期項目的維護,開發人員需要對代碼進行增加、刪除、修改操作。但是,代碼變更不可以不計其規模而進行,若軟件項目的變更大于項目代碼總數的25%時,修改代碼所花費的成本將大于重新編譯該項目[10]。設計良好的項目結構其類的穩定性相對較高,面臨上述情況時,其代碼變更規模相對較小,相反,若是一個類的代碼行數頻繁變更,則其代碼的結構設計越糟糕,出現異味的概率越大。此前,對于代碼行數的研究大多基于靜態的最終代碼行數,而本文主要關注在一個項目開發周期中代碼行數的動態變化,即每個開發人員每次提交的代碼變更信息中代碼行數的變化,并用代碼行變更指數(CLCI)來表示該變化,CLCI值越大表示該類的代碼變更規模越大,則該類出現異味的概率越大。本文的實驗是基于類的代碼行變更指數(CLCI)來對異味類進行排序,以此減少后期維護成本。實驗的整體流程如圖1所示,共分為3步,描述如下:

圖1 整體流程
(1)檢測階段:在檢測過程中,本文使用開源檢測工具JDeodorant,它是eclipse的免費開源插件,檢測的異味為feature envy,Duplicate code,Type checking,Long Method,God Class,根據檢測結果得到異味類列表;
(2)計算階段:收集項目開發過程中每個開發人員每次提交的代碼變更信息,統計同一異味類每次代碼變更前后的代碼行數,計算其差值為該次代碼變更的行數;之后,把代碼行變更指數與最終代碼行數的比值之和稱為代碼行變更倍數(Times),并對其進行sigmoid函數歸一化,得到的值即為代碼行變更指數(CLCI),分別計算各個異味類的CLCI值,得到所有異味類的代碼行變更指數列表;
(3)排序階段:根據異味類的代碼變更指數(CLCI)值的大小對檢測到的異味類進行排序,CLCI值越大的異味類則表示其代碼變更規模越大,出現代碼異味的概率相對較高,反之,則表示該異味類出現異味的概率相對較低。
2.1 檢測工具的選擇
許多學者已經對代碼異味的檢測進行研究[11-14],而本文主要研究代碼異味的排序方式,對于代碼異味的檢測傾向于選擇開源且易于操作的代碼異味檢測工具。本文通過對代碼異味檢測工具的分析和研究,最終選擇JDeodorant作為本文代碼異味檢測的工具,見表1。選擇JDeodorant工具的優勢:
(1)JDeodorant工具是eclipse軟件的一個開源插件,且操作簡單;
(2)JDeodorant工具可以自動識別java程序中本次實驗需要檢測的所有異味類型;
(3)JDeodorant工具可以向開發人員提供多種重構建議并自動實施開發人員所選擇的重構建議。

表1 異味檢測工具
2.2 代碼變更指數的計算
大量研究表明,代碼變更規模與軟件易錯率存在正相關關系[7-10],本文正是基于代碼變更規模的大小來判斷哪些類更容易出現異常和錯誤,代碼變更規模較大的異味類出現異味的概率相對較大。而此前的研究主要關注每個類最終的靜態代碼行數,而忽略在整個項目開發中每個類的代碼行數隨著每次開發人員提交代碼而發生動態變化的情況。本文基于每次代碼變更前后代碼行數的變化情況來對異味類進行排序,其中代碼變更次數相對較多,每次代碼行數變化相對較大的類,則其出現異味的概率也相對較大。因此,本文為了描述代碼行在整個項目開發周期中的動態變化,定義了代碼行變更指數(CLCI)。代碼行變更指數是指在項目開發周期中,每次開發人員提交代碼時,該異味類代碼行數發生變化的總和是最終代碼行數的倍數Times,并對其進行sigmoid函數歸一化。代碼行變更指數(CLCI)的計算公式如下
(1)
(2)
其中,k表示代碼變更總次數,CR(i)(Code Row) 為異味類第i次代碼變更后的代碼行數,其中CR(0)=0,則CR(i)-CR(i-1) 為第i次代碼變更時,發生變化的代碼行數,在除以最終代碼行數(LCR)并求和,并對求和結果進行sigmoid函數歸一化,使其值范圍屬于(0,1)之間。計算代碼行變更指數的偽代碼設計如下:
算法1: CLCI計算過程
輸入: 代碼提交行數CR,代碼變更次數k,最終代碼行數LCR
輸出: CLCI值
(1) CLCI←0,CR(0)←0
(2) Fori←1 tokDo
(3) If CR(i)≥CR(i-1) Then
(4) CCR(i)←CR(i)-CR(i-1)
(5) Else
(6) CCR(i)←CR(i-1)-CR(i)
(7) End if
(8) Times←Times+CCR(i)/LCR
(9) End for
2.3 異味類排序
通過上述方式對異味類進行計算得出所有異味類的代碼行變更指數,CLCI的值越大,則表示在項目開發過程中該類的代碼變更規模越大,即該類出現異味的概率越大。反之,CLCI的值越小,則該類出現異味的概率越小。最后,根據CLCI值的大小來對異味類進行降序排序,從而得到排序后的異味類列表。
3 實驗研究
為驗證依據代碼行變更指數對異味類排序的有效性,本文以HospitalAutomationWithJavaEE[6]系統作為測試背景,計算該項目所有異味類的代碼行變更指數,并依據代碼行變更指數值的大小進行排序,最終得到排序后的異味類列表。實驗主要尋求以下幾個問題的解答:
Q1:使用CLCI排序方式進行重構,前序異味類重構之后能否使后續需要重構的異味類數量減少?
Q2:使用CLCI排序方式進行重構,重構后總體異味類剩余數量是否減少?
Q3:使用CLCI排序方式進行重構,比基于類間耦合性[6]進行排序,異味剩余率是否減少更快?
3.1 實驗準備
本文實證研究是在java開源項目上進行的,項目名稱為HospitalAutomationWithJavaEE[6],此項目共有49個類,58次代碼變更記錄信息,選擇此項目的原因為:①曾在其它論文中使用[6],具有一定的可信度;②有很高的錯誤比例(36%),給代碼異味的排序供了實例。檢測代碼異味的工具為自動化檢測工具JDeodorant,主要檢測的代碼異味為feature envy,Duplicate code,Type checking,Long Method,God Class,該工具操作簡單且具有重構功能,能夠為后期重構節約成本。
3.2 數據預處理
實驗所需的初始數據為項目歷史記錄信息,項目歷史記錄信息可以在公共的開發倉庫獲得,如CSV,GitHub,對于公司內部項目,開發人員更改代碼的記錄可以從項目日志中獲得。本文實驗數據是從github項目倉庫中獲得,實驗項目的歷史記錄信息為每次代碼變更提交的commit記錄。項目歷史記錄信息包含的內容較多,但本次實驗并不需要所有的數據信息,因此,根據本文實驗要求從歷史記錄信息中提取實驗所需代碼變更信息,舉例如圖2所示。

圖2 代碼變更信息舉例
代碼變更信息中包含類、配置文件以及網頁的變更信息,基于本文的實驗要求,首先需要對代碼變更信息進行數據選取,即保留類的變更信息,清除其它不必要的變更信息,進行數據選取時,可以依據提交主題中的關鍵詞進行快速數據選取;其次,依據類名對代碼變更信息進行分類匯總,得到每個類的代碼變更信息;最后,對分類信息進行統計整理,記錄每個類的代碼變更hash值、代碼變更作者、代碼變更時間、代碼變更行數以及該類的最終代碼行數,此處以SaveAppointmentsService.java類的變更信息為例,見表2。
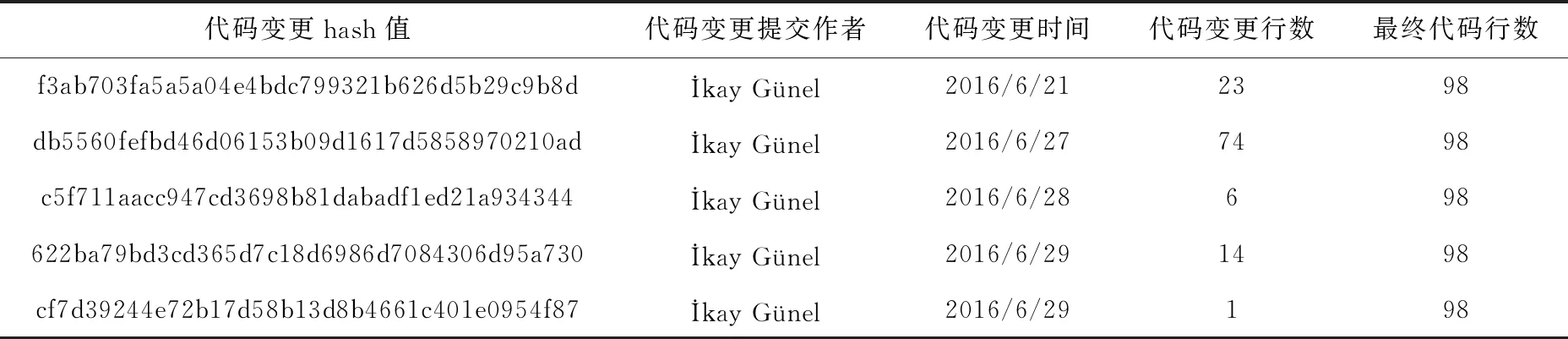
表2 SaveAppointmentsService.java類代碼行變更信息
3.3 檢測與計算結果
通過對HospitalAutomationWithJavaEE項目的49個類,58次代碼變更記錄信息進行異味類檢測與代碼行變更指數計算,檢測與計算的結果見表3,該表采用代碼行變更指數遞減的順序排列。檢測階段的結果表明,在該項目中Duplicate Code異味較為常見,其次為Feature Envy與God Class異味。計算階段的結果表明,當CLCI值大于0.9時,出現代碼異味的概率較大。

表3 檢測與計算階段結果
3.4 實驗結果分析
根據檢測階段和計算階段的實驗結果,逐一回答前文提到的Q1、Q2、Q3問題。
Q1:為驗證使用CLCI的排序方式進行重構,前序異味類重構之后能否使后續需要重構的異味類數量減少,本文采用JDeodorant工具對異味類按照代碼行變更指數降序排序的順序對異味類進行重構,并在一個異味類重構之后觀測后續異味類的數量是否減少。通過實驗觀測發現,Service/AvailableAppointmentsService.java與Service/DoctorService.java均為Duplicate Code異味,它們的代碼行變更指數分別0.7311和0.7714,根據上述重構規則需要優先對Service/DoctorService.java異味類進行重構,但是在重構過程中發現這兩個異味類具有相同的代碼片段,兩個異味類的相同代碼片段如圖3所示。使用重構工具JDeodorant提取重復代碼片段定義為新的類KlinikerEqualClinic.java,則在service/DoctorService.java異味類被檢測出來后,使用JDeodorant插件按照開發人員選擇的重構建議進行重構之后,service/AvailableAppointmentsService.java類的異味隨之自動解決;此外,對Controller/GetDoctors.java進行God Class重構后,Controller/GetHospital.java類的異味也自動消失。研究結果表明異味類之間具有相關性,一個異味類重構以后會使后續需要重構的異味類數量減少,從而減少重構成本。

圖3 異味類重復代碼片段
Q2:為驗證使用CLCI的排序方式進行重構,重構后總體異味類剩余數量是否減少,本文采用對照實驗,把項目復制成內容相同的兩份,實驗組采用優先對代碼行變更指數較大的異味類進行重構;對照組采用隨機方式對異味類進行重構。為了判斷重構后異味類的剩余情況,本文采用異味剩余率(CML,即“code smell left %”)作為評價指標,異味剩余率為重構后的異味類剩余數量占總異味類數量的比例,其公式如下所示
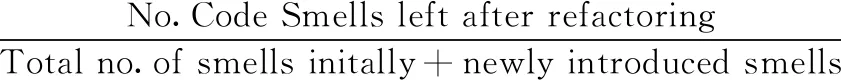
(3)
異味剩余率(CML)值越小則表示使用該代碼異味排序方式重構后的異味數量越少,即該代碼異味排序方式更優。本文使用JDeodorant工具,并分別采用兩種不同的排序方式來對相同項目的代碼異味進行重構,重構剩余率對比如圖4所示,從圖4可以看出當對前10個異味類采用本文的排序方式進行重構后的異味類剩余數量僅占總異味類數量的25%,則使用隨機排序方式進行重構后的剩余異味類數量占總異味類數量的50%;使用本文的排序方式,代碼異味的剩余率減少速度比隨機排序方式快,說明采用本文的排序方式可以使重構后的總體異味類剩余數量減少,從而減少重構成本。
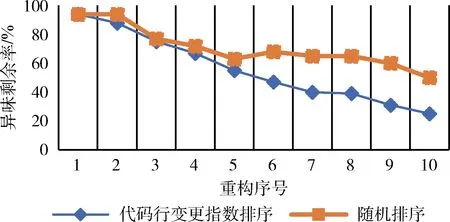
圖4 CLCI與隨機排序重構后異味剩余率對比
Q3:為驗證使用CLCI的排序方式進行重構,比基于類間耦合性[11]進行排序,異味剩余率是否減少更快。本文采用Q2的對照實驗,實驗組為基于代碼行變更指數的異味類排序方式,對照組為基于類間耦合性的異味類排序方式,并采用異味剩余率來對其結果進行比較。其中,基于類間耦合性的異味類排序方式的計算公式如下
(4)
具體計算公式,可以參考文獻[11]。在整個實驗過程中,分別記錄對照組采用基于類間耦合性排序方式進行重構,重構后的前10個異味類的異味剩余率變化過程和實驗組采用基于代碼行變更指數排序方式進行重構,重構后的前10個異味類的異味剩余率變化過程,見表4。
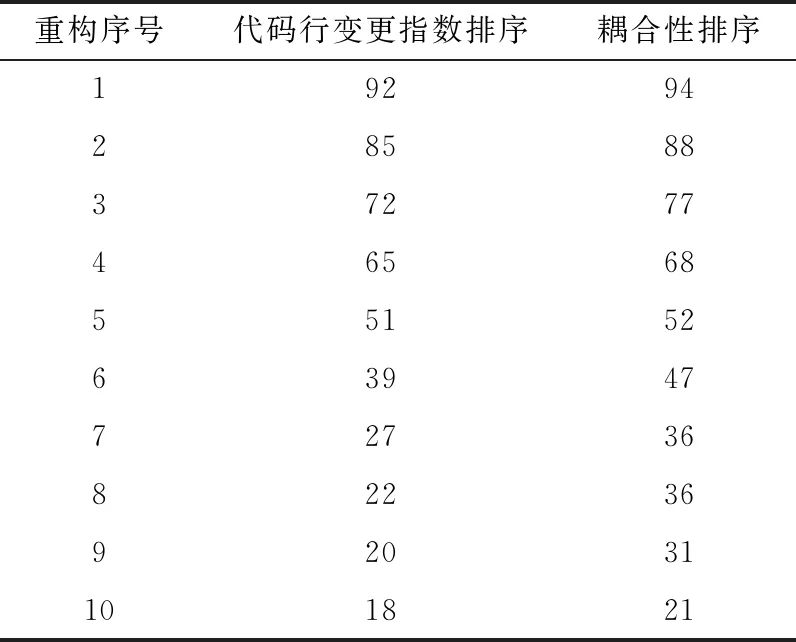
表4 類間耦合與CLCI排序重構后剩余率
從表4可以看出,當CLCI指數較大的7個異味類被重構之后,異味剩余率下降開始減緩,此時,該CLCI值開始小于0.9。而基于耦合性的排序方式在整個重構過程中,異味剩余率下降較為平穩,但整體效果比起CLCI值下降更少,如圖5所示。
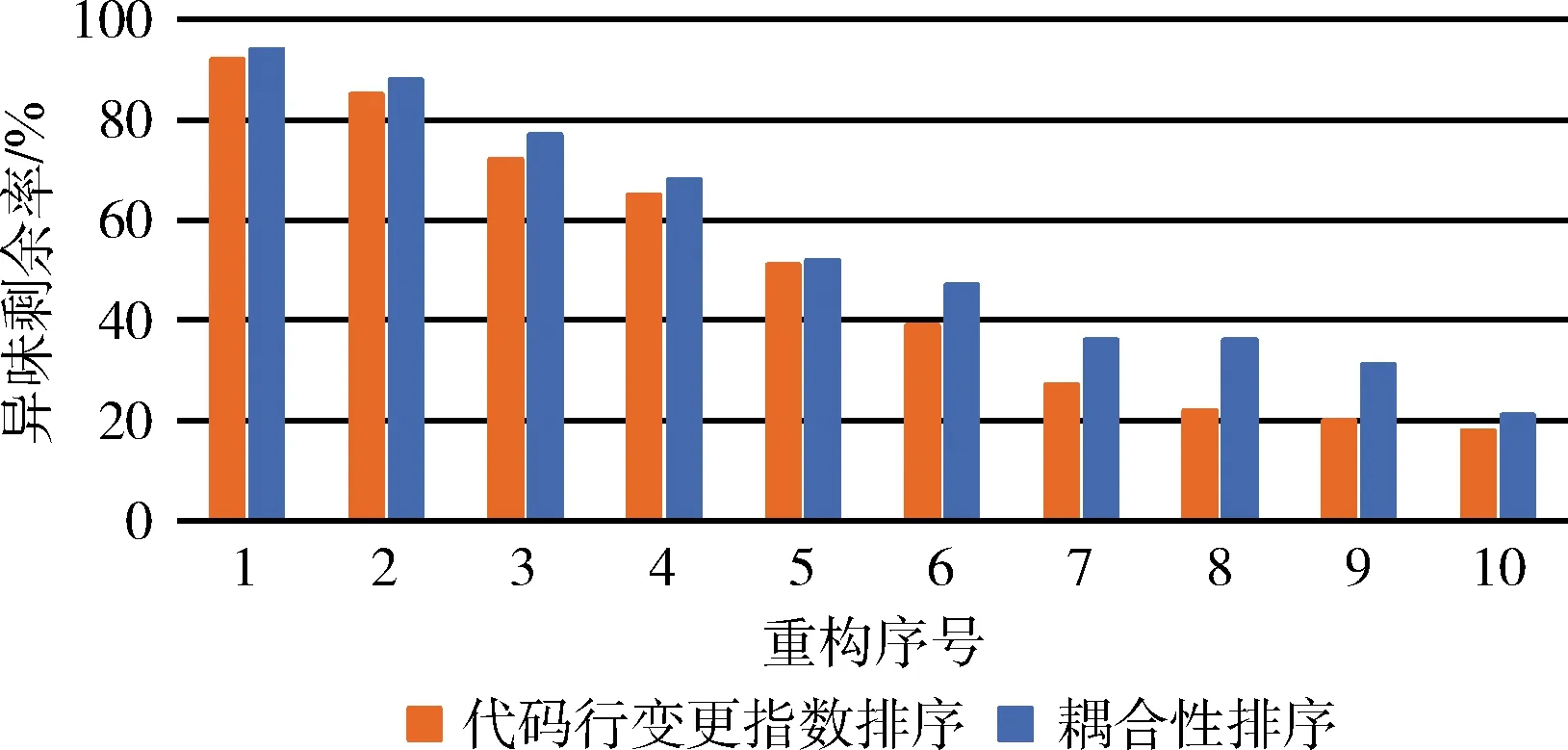
圖5 CLCI與耦合性排序重構后的異味剩余率
4 結束語
本文依據代碼變更規模與軟件發生錯誤的概率存在正相關關系,定義代碼行變更指數來描述軟件開發過程中,代碼發生變更時代碼行的動態變化,并以此來對異味類進行排序,實驗結果表明,使用代碼行變更指數來對異味類進行排序可以使后續的重構更容易,從而提高重構的效率。在未來的工作中,將會在以下幾個方面展開:
(1)持續研究代碼變更中其它因素,如代碼變更的原因以及發生變更的代碼重要程度對于異味排序的作用。
(2)通過研究異味類之間的相關關系,改進基于代碼行變更指數的異味類排序方法。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
