基于廣義線性模型的混合屬性數(shù)據(jù)聚類方法
2021-03-07 08:13:34朱永杰
科學(xué)技術(shù)與工程 2021年4期
關(guān)鍵詞:方法
朱永杰
(許昌學(xué)院信息化管理中心, 許昌 461099)
現(xiàn)代信息技術(shù)日新月異,社會(huì)各領(lǐng)域產(chǎn)生大量數(shù)據(jù)信息,可使用數(shù)據(jù)挖掘技術(shù)從海量數(shù)據(jù)中得到有效信息。數(shù)據(jù)聚類是一種使用頻率較高的數(shù)據(jù)挖掘技術(shù),在商品營(yíng)銷、圖像處理、數(shù)據(jù)分析等領(lǐng)域應(yīng)用較廣[1]。實(shí)際應(yīng)用中,可根據(jù)數(shù)據(jù)具體情況選擇聚類方法。以混合屬性數(shù)據(jù)為例,與單種屬性數(shù)據(jù)不同,混合屬性數(shù)據(jù)包含多種屬性,如數(shù)值屬性、符號(hào)屬性、時(shí)間屬性等[2]。由于屬性種類較多,算法進(jìn)行聚類過(guò)程中需通過(guò)轉(zhuǎn)換方式將數(shù)據(jù)屬性統(tǒng)一,屬性轉(zhuǎn)換過(guò)程復(fù)雜,容易降低算法聚類準(zhǔn)確度。中外不少專家學(xué)者對(duì)混合屬性數(shù)據(jù)聚類方法進(jìn)行了研究,并取得了較好的研究成果。黃德才等[3]提出了混合屬性數(shù)據(jù)流的二重k近鄰聚類算法。采用二重k近鄰和改進(jìn)的維度距離形成數(shù)據(jù)的微聚類,根據(jù)均值的余弦模型以及動(dòng)態(tài)標(biāo)準(zhǔn)化數(shù)據(jù)方法生成初始宏聚類,通過(guò)基于均值的余弦模型和先驗(yàn)聚類結(jié)果進(jìn)行宏聚類優(yōu)化,以實(shí)現(xiàn)混合屬性數(shù)據(jù)的聚類,但是該方法存在聚類適應(yīng)度較低的問(wèn)題。Skabar[4]提出了一種基于隨機(jī)漫步的混合屬性數(shù)據(jù)聚類方法,該方法不需要任何顯式的相似性或距離度量,就能夠?qū)崿F(xiàn)混合屬性數(shù)據(jù)聚類,但是該方法存在迭代收斂速度較快的問(wèn)題。現(xiàn)針對(duì)現(xiàn)有方法存在的問(wèn)題,提出一種基于廣義線性模型的混合屬性數(shù)據(jù)聚類方法。引入低階多元廣義線性模型考慮數(shù)據(jù)屬性時(shí)間特性,構(gòu)建屬性時(shí)間序列矩陣。用優(yōu)化方法計(jì)算數(shù)據(jù)相異度、樣本與聚類集間距離,當(dāng)聚類結(jié)果趨于平穩(wěn)時(shí)終止運(yùn)算,輸出聚類結(jié)果。通過(guò)此過(guò)程能夠有效提高聚類適應(yīng)度,提高聚類算法準(zhǔn)確度,是提升混合屬性數(shù)據(jù)聚類性能最為有效的途徑。
1 混合屬性數(shù)據(jù)聚類方法
1.1 低階多元廣義線性模型構(gòu)建
定義yq(t)為混合數(shù)據(jù)屬性的時(shí)間序列,混合數(shù)據(jù)屬性聚類過(guò)程中,構(gòu)建廣義線性模型為
yq(t)=d(t)γq+

(1)
式(1)中:
φq為a維列向量;d(t)γq為數(shù)據(jù)屬性混合導(dǎo)致的數(shù)據(jù)低頻漂移;s(t)表示混合屬性數(shù)據(jù)響應(yīng)函數(shù);K表示廣義線性模型特征量指數(shù);b(t-e)表示刺激函數(shù)。
采用廣義線性模型完成混合數(shù)據(jù)聚類,可同時(shí)處理大量數(shù)據(jù),提供更多的時(shí)間信息致使數(shù)據(jù)噪聲干擾降低[5]。混合屬性數(shù)據(jù)的響應(yīng)函數(shù)存在差異,因此采用B-樣條插值方法擬合混合數(shù)據(jù)的響應(yīng)函數(shù)[6],過(guò)程為
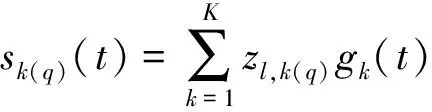
(2)
式(2)中:gk(t)和zl,k(q)分別表示B樣條基函數(shù)與未知系數(shù);sk(q)表示擬合混合數(shù)據(jù)的響應(yīng)函數(shù)。

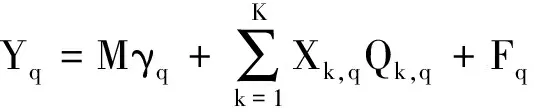
(3)
混合屬性數(shù)據(jù)的特征信息全部體現(xiàn)在系數(shù)矩陣Qk,q中,采用最小二乘法求解即可。值得注意的是,廣義線性模型參數(shù)多、混合屬性數(shù)據(jù)信噪比低的特點(diǎn)導(dǎo)致最小二乘法求解結(jié)果變異概率高,將Qk,q變換成低階矩陣相乘的方式解決該問(wèn)題,具體過(guò)程如下:令Qk,q=Ek,qGk,q,Ek,q、Gk,q表示低階矩陣,維數(shù)為L(zhǎng)×P、P×D,P取值為2,變換后的形式體現(xiàn)了混合屬性數(shù)據(jù)的時(shí)間特性[7]。混合屬性數(shù)據(jù)聚類研究的是混合屬性,所以模型的誤入項(xiàng)應(yīng)考慮到屬性間的差異[8],據(jù)此擴(kuò)展廣義線性模型為低階多元廣義線性模型,即

(4)
相比單一的廣義線性模型而言,低階多元廣義線性模型存在以下優(yōu)點(diǎn):①可處理混合屬性數(shù)據(jù)的聚類問(wèn)題,使用領(lǐng)域擴(kuò)大[9];②考慮了混合屬性數(shù)據(jù)的時(shí)間特性,可處理大量混合屬性信息,降低數(shù)據(jù)噪聲,同時(shí)改善了聚類算法的聚類精度[10];③在低階多元廣義線性模型中,設(shè)置Ek,q矩陣為定值,對(duì)比Gk,q矩陣即完成混合屬性數(shù)據(jù)響應(yīng)函數(shù)的對(duì)比。
混合屬性數(shù)據(jù)聚類過(guò)程中,應(yīng)用到考慮時(shí)間特性屬性的時(shí)間序列矩陣,可改善聚類算法精確度,詳細(xì)聚類過(guò)程如下。
1.2 基于優(yōu)化K-prototypes的混合屬性數(shù)據(jù)聚類
由于基于K-prototypes的混合屬性數(shù)據(jù)聚類方法[11]存在迭代收斂速度快、聚類精度低的問(wèn)題,因此要對(duì)該方法進(jìn)行優(yōu)化。優(yōu)化的K-prototypes混合屬性數(shù)據(jù)聚類原理如下:首先,定義Xi(i=1,2,…,n)表示樣本數(shù)據(jù)集,A1,A2,…,Ak表示聚類集,數(shù)據(jù)迭代過(guò)程中計(jì)算Xi與聚類集間的距離,將距離值最小的數(shù)據(jù)樣本歸類至聚類集內(nèi);其次,優(yōu)化聚類及數(shù)值屬性均值與分類屬性值計(jì)數(shù)器,為獲取聚類代價(jià)函數(shù)J(X,G)的最小值,迭代完成后更新分類屬性模式。優(yōu)化K-prototypes混合屬性數(shù)據(jù)聚類算法考慮了屬性的時(shí)間序列矩陣,可提高聚類精度,由此得到優(yōu)化的相異度計(jì)算方法,樣本分類屬性值和聚類集內(nèi)非未知樣本屬性值的不匹配概率和即為相異度[12],式(5)、式(6)分別為樣本與聚類集間的距離計(jì)算方法,結(jié)合式(5)、式(6)獲取分類屬性距離計(jì)算結(jié)果。
μ(Xij,Aij)=1-|Alij|/|Al|Yq;μ∈[0,1]
(5)

(6)
式中:Al表示已有樣本數(shù)量;|Alij|表示可分類樣本Xi在分類Al內(nèi)出現(xiàn)的頻率;Yq為樣本分類屬性的時(shí)間序列矩陣;d(Xi,Al)為樣本Xi與聚類集Al間的距離;Glj表示聚類集Al的數(shù)值屬性均值。
定義以下參數(shù):X={X1,X2,X3,…,X10},G={G1,G2,G3},G1=X7,G2=X2,G3=X5,A={A1,A2,A3},A1=[7,0,…,0],A2=[2,0,…,0],A3=[5,0,…,0]。K-prototypes算法聚類過(guò)程如圖1所示,優(yōu)化K-prototypes聚類算法如圖2所示。

圖1 K-prototypes聚類算法Fig.1 K-Prototypes clustering algorithm

圖2 優(yōu)化K-prototypes聚類算法Fig.2 Optimized K-Prototypes clustering algorithm
分析圖1可知,K-prototypes聚類算法迭代過(guò)程中,混合數(shù)據(jù)樣本同聚類中心距離決定了數(shù)據(jù)樣本的聚類[13]。圖2信息表明,優(yōu)化K-prototypes聚類算法在考慮樣本同聚類中心距離基礎(chǔ)上兼顧已知樣本信息內(nèi)容和屬性的時(shí)間序列矩陣。詳細(xì)分析圖2中的樣本X10,采用K-prototypes聚類算法得到以下形式:d(X10,G1)≥d(X10,G2)≥d(X10,G3),據(jù)此歸類X10至A3。采用優(yōu)化K-prototypes聚類算法獲取上述3個(gè)樣本到聚類中心的距離,根據(jù)距離最小原理歸納X10至A2。原因分析如下:根據(jù)圖1和圖2中樣本節(jié)點(diǎn)排列情況可知,X10至X2距離等于X10至X5的距離,歸納X10至A2更合理是因?yàn)闃颖綳3與X6存在A2內(nèi)。總結(jié)優(yōu)化K-prototypes算法聚類過(guò)程如下。
步驟1已知聚類數(shù)量為k,聚類集A的原始聚類中心樣本是隨機(jī)選擇的原始節(jié)點(diǎn)G={G1,G2,…,Gk},那么A1={G1},…,Ak={Gk},同時(shí)定義η表示分類屬性的權(quán)重值。
步驟2存在Xi(1≤i≤n,Xi≠Gj,j=1,2,…,k),與聚類集的距離表示為d(Xi,Al)。p表示聚類集元素計(jì)數(shù)器,設(shè)定p的初始值為1,歸納Xi至聚類集Amin中,Amin為距離最小的聚類集,若計(jì)數(shù)器值增加1,說(shuō)明聚類運(yùn)算了1次,用參數(shù)表示為Amin·p=i,p=p+1,新樣本加入后,需再次計(jì)算聚類集Amin的數(shù)據(jù)屬性均值,據(jù)此調(diào)整分類屬性值計(jì)數(shù)器內(nèi)容。
步驟3根據(jù)數(shù)據(jù)的混合屬性差異獲取聚類集原始聚類中心樣本[14],原則為:數(shù)值型屬性取聚類元素均值,分類型屬性取聚類樣本的分類屬性中頻繁出現(xiàn)的值。
步驟4各迭代目標(biāo)函數(shù)值可依據(jù)目標(biāo)函數(shù)公式(7)計(jì)算,即

(7)
式(7)中:若eil為1,說(shuō)明Al包含樣本Xi;若eil為0,說(shuō)明Al不包含樣本Xi。
步驟5循環(huán)操作步驟2~步驟4,采用固定的迭代目標(biāo)函數(shù)值,當(dāng)聚類結(jié)果趨于平穩(wěn)時(shí)終止運(yùn)算[15],輸出聚類結(jié)果。
采用廣義線性模型與優(yōu)化K-prototypes聚類算法結(jié)合的方法完成混合屬性數(shù)據(jù)聚類[16],有效提升聚類算法處理混合屬性數(shù)據(jù)的準(zhǔn)確度。
2 實(shí)驗(yàn)分析
為驗(yàn)證本文方法對(duì)于混合屬性數(shù)據(jù)的聚類優(yōu)勢(shì),將文本數(shù)據(jù)作為混合屬性聚類的樣本數(shù)據(jù),展開(kāi)混合屬性數(shù)據(jù)聚類分析測(cè)試。實(shí)驗(yàn)環(huán)境如下。①硬件環(huán)境:Inter(R) Corel(TM) Duo 2.00GHz CPU,內(nèi)存為8 GB,使用Windows 10操作系統(tǒng);②實(shí)驗(yàn)對(duì)比方法:K-prototypes數(shù)據(jù)聚類方法、二重K近鄰聚類方法;③實(shí)驗(yàn)數(shù)據(jù)使用權(quán)威數(shù)據(jù)平臺(tái)提供的語(yǔ)言詞匯表,分為測(cè)試集A(包含5×102個(gè)混合屬性數(shù)據(jù))、測(cè)試集B(包含2×103個(gè)混合屬性數(shù)據(jù))與測(cè)試集C(包含5×103個(gè)混合屬性數(shù)據(jù)),部分混合屬性數(shù)據(jù)如表1所示。表1中,數(shù)據(jù)的混合屬性包括分類屬性與數(shù)值屬性,分類屬性為“渠道”“范疇”,數(shù)值屬性為“時(shí)間”。
2.1 聚類方法性能對(duì)比
本次測(cè)試在數(shù)據(jù)量不同的測(cè)試集A、B、C中進(jìn)行,不同方法混合屬性數(shù)據(jù)聚類性能如表2所示。
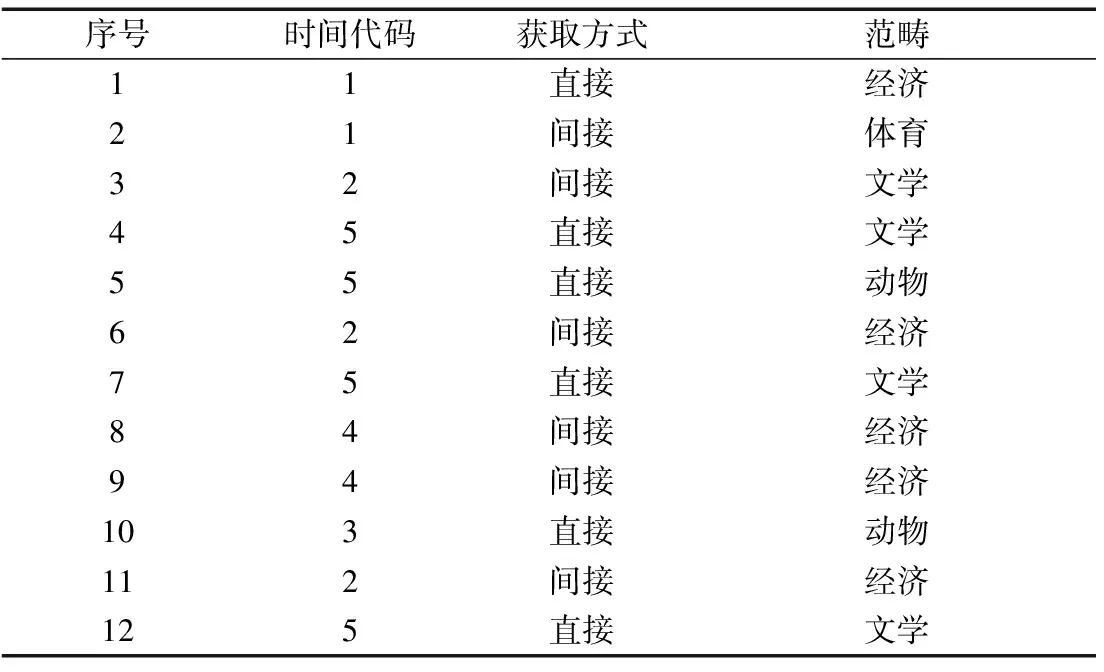
表1 語(yǔ)言詞匯
表2數(shù)據(jù)顯示:在不同數(shù)據(jù)量的數(shù)據(jù)集聚類測(cè)試中,本文方法迭代時(shí)間在1 s左右、迭代次數(shù)約為21次,上下波動(dòng)小,均優(yōu)于其他兩種聚類方法;本文方法進(jìn)行混合屬性數(shù)據(jù)聚類準(zhǔn)確度均高于99.6%,不隨數(shù)據(jù)量增加而降低,K-prototypes數(shù)據(jù)聚類方法、二重K近鄰聚類方法聚類準(zhǔn)確度隨數(shù)據(jù)量增加而降低的趨勢(shì)較明顯;另外,3種方法最優(yōu)解原始樣本組數(shù)量均隨測(cè)試集數(shù)據(jù)量的增加而增長(zhǎng),本文方法聚類后,得到最優(yōu)解的原始樣本組數(shù)量均高于其他兩種方法。綜上所述,本文方法進(jìn)行混合屬性數(shù)據(jù)聚類性能優(yōu)于同類方法,之后詳細(xì)分析本文聚類方法的具體優(yōu)勢(shì)。
2.2 平均目標(biāo)函數(shù)值分析
采用本文方法在內(nèi)的3種聚類方法進(jìn)行混合屬性數(shù)據(jù)聚類測(cè)試,3種方法聚類平均目標(biāo)函數(shù)值與迭代次數(shù)關(guān)系如圖3所示。
圖3數(shù)據(jù)表明:3種聚類方法處理混合屬性數(shù)據(jù)過(guò)程中,平均目標(biāo)函數(shù)值均與迭代次數(shù)呈反比例關(guān)系;迭代次數(shù)一定時(shí),本文方法的平均目標(biāo)函數(shù)值最低,另外兩種方法均高于本文方法,由于平均目標(biāo)函數(shù)值越低,聚類精度越高,所以本文方法的聚類精度優(yōu)于K-prototypes數(shù)據(jù)聚類方法、二重K近鄰聚類方法;另外,由測(cè)試過(guò)程可知,迭代次數(shù)為20~30時(shí),本文方法優(yōu)化劃分聚類集,迭代次數(shù)為30~42時(shí),K-prototypes數(shù)據(jù)聚類方法優(yōu)化劃分聚類集,迭代次數(shù)為38~48時(shí),二重K近鄰聚類方法優(yōu)化劃分聚類集,相比之下,本文方法僅使用較少的迭代次數(shù)即可優(yōu)化劃分混合屬性數(shù)據(jù)的聚類集,說(shuō)明本文方法效率較高。

圖3 平均目標(biāo)函數(shù)值與迭代次數(shù)關(guān)系Fig.3 Relationship between average objective function value and iteration times
由于本文方法對(duì)混合屬性數(shù)據(jù)進(jìn)行聚類過(guò)程中,考慮到聚類集中的已有樣本數(shù)據(jù),所以減少了迭代分析次數(shù),提高數(shù)據(jù)聚類效率,這也是本文方法相對(duì)同類型K-prototypes數(shù)據(jù)聚類方法的優(yōu)化與改進(jìn)之處。
2.3 原始樣本數(shù)量與迭代次數(shù)關(guān)系分析
迭代次數(shù)影響混合屬性數(shù)據(jù)聚類效果,2.2節(jié)實(shí)驗(yàn)對(duì)迭代次數(shù)與聚類方法的平均目標(biāo)函數(shù)值關(guān)系進(jìn)行分析,為全面掌握迭代次數(shù)對(duì)聚類效果的影響與干擾,本次實(shí)驗(yàn)測(cè)試聚類方法迭代次數(shù)與最優(yōu)解原始樣本組數(shù)量的關(guān)系,測(cè)試結(jié)果如圖4所示。
分析圖4可知,迭代次數(shù)一定時(shí),本文方法得到最優(yōu)解樣本數(shù)量大于K-prototypes數(shù)據(jù)聚類方法、二重K近鄰聚類方法,以迭代次數(shù)20次為例,本文方法有55個(gè)原始樣本組達(dá)到最優(yōu)解,K-prototypes數(shù)據(jù)聚類方法有33個(gè)原始樣本組達(dá)到最優(yōu)解,二重K近鄰聚類方法有23個(gè)原始樣本組達(dá)到最優(yōu)解;另外,本文方法聚類迭代30~50次時(shí)最優(yōu)解樣本數(shù)量趨于穩(wěn)定,另外兩種方法沒(méi)有趨于穩(wěn)定的跡象,證明本文方法可靠性較強(qiáng)。上述數(shù)據(jù)表明,本文方法進(jìn)行混合屬性數(shù)據(jù)聚類過(guò)程中,聚類性能優(yōu)于另外兩種方法,且迭代穩(wěn)定性、可靠性強(qiáng)。

表2 不同方法聚類性能對(duì)比結(jié)果

圖4 迭代次數(shù)與初始樣本組數(shù)量的關(guān)系Fig.4 The relationship between the number of iterations and the number of initial sample groups
2.4 適應(yīng)度分析
聚類適應(yīng)度影響聚類方法性能,因此,對(duì)3種混合屬性數(shù)據(jù)聚類方法的適應(yīng)度進(jìn)行測(cè)試,測(cè)試結(jié)果如圖5所示。
從圖5能夠看出,3種聚類方法適應(yīng)度隨時(shí)間的進(jìn)化過(guò)程,本文方法適應(yīng)度值在0.88~0.94,處于穩(wěn)定發(fā)展?fàn)顟B(tài),K-prototypes數(shù)據(jù)聚類方法適應(yīng)度先增加再降低,最高適應(yīng)度值為0.68,二重K近鄰聚類方法呈由高至低的狀態(tài),實(shí)驗(yàn)結(jié)束時(shí)適應(yīng)度值僅為0.3。

圖5 適應(yīng)度變化曲線Fig.5 Fitness curve
總體看來(lái),本文方法適應(yīng)度值最高,適應(yīng)度最強(qiáng),增強(qiáng)了混合屬性數(shù)據(jù)聚類的性能。
3 結(jié)論
提出一種基于廣義線性模型的混合屬性數(shù)據(jù)聚類方法,實(shí)驗(yàn)證明本文方法解決混合屬性數(shù)據(jù)聚類問(wèn)題性能較優(yōu),相比同類方法具有優(yōu)勢(shì)。
總結(jié)本文提出的基于廣義線性模型的混合屬性數(shù)據(jù)聚類方法優(yōu)點(diǎn)如下:①構(gòu)建低階多元廣義線性模型,考慮了混合屬性樣本數(shù)據(jù)的時(shí)間特性,得到混合屬性時(shí)間序列矩陣,提升聚類算法準(zhǔn)確度;②迭代聚類過(guò)程中,參考混合屬性數(shù)據(jù)樣本同原型的差異,樣本與聚類集間的距離計(jì)算采用更新的相異度公式與距離公式,得到的距離結(jié)果更加精準(zhǔn),有效提高聚類準(zhǔn)確度。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
