基于區塊鏈的數據透明化:問題與挑戰
2021-02-06 09:27:14孟小峰劉立新
計算機研究與發展 2021年2期
孟小峰 劉立新,2
1(中國人民大學信息學院 北京 100872)2(內蒙古科技大學信息工程學院 內蒙古包頭 014010)(xfmeng@ruc.edu.cn)
隨著大數據技術和人類生產生活的交匯融合,豐富的數據通過多種方式源源不斷地被多方數據收集者收集,進而依據這些數據進行數據決策和提供服務.這種先予后取的數據收集模式已成為越來越多應用的必要條件.固然大規模數據收集為個人、企業和國家帶來巨大的數據價值,但也帶來隱私泄露和決策不可信等問題,表現為大規模數據收集(mass collection)、大規模數據監視(mass surveillance)和大規模數據操縱(mass manipulation)三個方面.
1) 大規模數據收集.大規模數據通過被動、主動和自動方式被收集,如醫療就醫、購物、網站搜索、個人移動通信、出行和位置軌跡等數據.然而,作為數據生產者,我們不知道哪些數據被收集、被誰收集、數據被收集后會流向何處以及作何使用,導致隱私泄露追蹤問責困難.
2) 大規模數據監視.大規模數據收集導致大規模數據監視,例如醫療就醫和個人移動通信等數據被政府部門收集,購物、社交和出行等數據被各大公司掌握.個人在享受服務的同時也時刻處于被監視狀態,個人隱私在深度和廣度受到巨大沖擊.
3) 大規模數據操縱.由于現有政策、技術和制度的不完善,數據戰略合作和數據交易等過程中存在大量用戶隱私與安全問題.在數據決策過程中,數據非真實產生、數據被篡改、數據質量管理過程中的單點失敗等問題導致決策數據不可靠,由此導致數據決策結果不可信[1-2].然而,我們深受數據操縱影響卻對此束手無策.
“Facebook-劍橋分析事件”是大規模數據收集、大規模數據監視和大規模數據操縱的典型案例.匿名和差分等傳統隱私保護技術主要解決數據發布時的隱私泄露問題,致使其并不能很好地解決當下數據自主匯聚產生的隱私泄露問題.同時,數據決策應用于人類生產生活的方方面面,決策數據不可靠導致的決策不可信是影響大數據進一步發展和應用的重要因素[3].
進一步,數據自主匯聚還導致數據壟斷現象出現.數據本身的易聚集特性、大公司覆蓋各數字化領域的商業模式和龐大的用戶規模等因素加劇數據聚集現象,各公司數據持有量出現差異[4].我們在2019年《中國隱私風險指數分析報告》中對3000萬移動用戶的權限數據(權限數據是指在移動場景下,某用戶安裝并使用一系列App,數據收集者通過App的權限體系獲取該用戶的個人隱私數據)收集情況進行分析,數據收集者獲取權限數據的分布如圖1所示[5].可以看出前10%的數據收集者獲取大于99%的數據,數據壟斷現象已悄然形成.數據壟斷可能會阻礙市場競爭、使消費者福利受損、阻礙行業技術創新和帶來更嚴重的個人隱私泄露風險等.現實世界財富獲取的“二八定律”指20%的人占有80%的社會財富,這依賴于法律、稅收等方式的調節.而在虛擬世界,如果將數據比作財富,還是一個沒有得到有效調節和分配的領地.因此,急需建立相關技術手段和法律法規.

Fig. 1 Data acquisition distribution of the collectors圖1 數據收集者權限數據獲取分布
如何使這些問題得到有效治理,使數據得到正確、合理和規范地使用是大數據發展面臨的主要挑戰.導致這些問題的主要原因是大數據價值實現過程中存在不透明性,數據獲取和數據等共享流通過程的不透明性使隱私泄露問題問責困難和數據壟斷問題缺乏解決依據,數據決策的不可審計性導致大數據驅動的決策不可信.工業界對大數據價值實現過程的透明性提出迫切需求.蘋果CEO庫克在2019年《時代周刊》發表評論建議設立新框架增強企業處理用戶數據的透明性,并建議建立數據清算和要求所有數據中介在清算所注冊,從而使用戶能夠跟蹤被捆綁并被銷售的數據.Gartner發布的2020年戰略性技術研究趨勢報告中也將“透明性與可追溯性”作為十大戰略性技術趨勢之一[6].
增加大數據價值實現的透明性,是促進大數據正確使用的重要舉措和必經之路.據此,本文提出數據透明性的概念,指在大數據價值實現過程中,各個參與方都能獲取與自身相關的全部數據信息.并將數據透明性分為數據獲取透明性、數據共享透明性、數據云存儲服務透明性、數據決策透明性和法律法規透明性5個部分,通過這5個部分實現數據透明化.數據透明化需要公開透明地記錄數據的獲取和共享流通等信息,以及去中心化地管理數據和執行數據質量管理.這些需求與區塊鏈的特性天然契合,而且區塊鏈的去中心和不可篡改特性使數據透明化具有更強的問責能力.
1 數據透明化概述
數據透明化旨在增加大數據價值實現過程的透明性.其研究內容涉及數據生命周期內各階段,其實現途徑主要包括法律法規和技術方法等方面.
1.1 定義與研究框架
文獻[7]在2017年提出數據透明化概念,并建議從數據透明性策略、日志系統和算法透明性3個方面進行實現.但是對數據透明化的研究維度劃分沒有涵蓋大數據生態中的主要透明性需求,也沒有深入分析數據透明化與當前大數據生態中的隱私保護、決策可解釋和數據壟斷關系.
本文提出的數據透明化研究與文獻[7]一脈相承,都是保證大數據在其生命周期內各個階段的透明性.但本文對數據透明化研究的劃分更為清晰和具象,進一步將數據透明化研究放在大數據生態范圍進行考慮,并闡述數據透明化研究與數據隱私保護、決策可解釋和數據壟斷的內在關系.
實現數據透明化涉及到大數據生命周期內多方參與主體,各個參與主體有不同的數據透明性需求.目前,參與主體主要包括數據生產者(data contri-butors)、數據收集者(data collectors)、數據使用者(data consumers)、數據處理者(data processors)和數據監管者(data supervises) 5個角色.其中,數據生產者是指產生數據的個人或機構;數據收集者是指收集數據的個人或機構,如服務提供者和科研工作者;數據使用者是指任何形式使用數據的個人或機構;數據處理者是指在授權的情況下代替數據使用者處理數據的個人或機構;數據監管者是指對數據生命周期各階段的數據共享流通等情況進行監管的機構,主要包括政府部門、可信第三方組織等.各參與主體之間可能存在重合,例如當數據收集者自己使用數據并且具有處理能力時,數據收集者也充當數據處理者和數據使用者.
定義1.數據透明性.在大數據價值實現過程中,使所有參與主體均能有效獲取與自身相關的全部數據信息.其中,數據信息包括原始數據、間接數據和決策數據.
數據透明化研究圍繞各方參與主體的數據透明性需求展開,根據大數據生命周期和各方參與主體的透明性需求,將數據透明性分為數據獲取透明性、數據共享透明性、數據云存儲服務透明性、數據決策透明性和法律法規透明性5個部分.通過實現數據獲取透明性和數據共享透明性來記錄數據獲取和共享流通等信息,在隱私泄露和數據濫用等事件發生后進行追蹤溯源,并對違反規范的參與方進行問責;通過實現云儲存服務透明性增加云存儲服務的可信性;通過實現數據決策透明性對決策數據進行審計,從而促進大數據驅動的決策的可信性.數據透明化研究框架和各部分信息如圖2所示.
1) 數據獲取透明性.數據獲取透明性指對數據收集內容、形式和使用目的等信息進行記錄,數據生產者、數據收集者和數據監管者等能獲知相關信息.目前,通過透明增強工具(transparency enhanced tools)、數據使用協議和可審計的訪問控制等方式實現獲取透明.
2) 數據共享透明性.依據數據共享方式,數據共享透明性可以分為支持溯源問責的數據共享、可驗證分布式數據集共享和可驗證的分布式機器學習.當發生數據訪問和流通時,需要實現支持溯源問責的數據共享,對數據流向進行記錄,數據生產者和數據監管者能夠據此對數據共享情況和隱私泄露進行追蹤問責,數據處理者和數據使用者能據此說明是合法使用數據.當由于傳輸代價和法律法規等因素限制,需要在不泄露原始數據情況下通過分布式數據集共享技術和分布式機器學習等方式進行數據共享,這時需要對數據提供者(包括數據生產者和數據收集者)提供的加密數據和參數等進行記錄,數據使用者可對共享過程進行驗證.
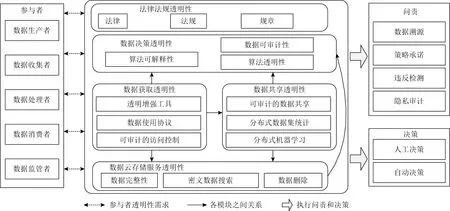
Fig. 2 Dimensions of data transparency圖2 數據透明化研究框架
3) 數據云存儲服務透明性.越來越多的企業和個人將數據存儲到云服務器,享受云存儲服務帶來的便利.然而傳統的數據完整性驗證、可驗證可搜索加密、確定性數據刪除等云數據安全和隱私保護技術通常依賴于可信的第三方且實現過程存在不透明性,實現數據云存儲服務透明性旨在增加其透明性.
4) 數據決策透明性.數據是決策的基礎,所以數據使用者需要對決策數據進行審計和追蹤溯源.除此之外,數據決策透明性的實現還需要算法可解釋和算法透明的支持(1)目前,關于算法透明和算法可解釋有2種理解.一類認為兩者是不同的,透明是指算法源代碼或者實現原理等內容的公開(public),而可解釋則是指向用戶解釋算法是如何做決策,側重解釋(interpretation)和理解(understanding);另一類認為兩者相同,指解釋和理解..算法可解釋性主要是指機器學習算法的可解釋性,即合理解釋特定機器學習算法做決策原理以及判斷算法是否存在不公平現象.算法透明是指選擇合適方式公開決策算法.
5) 法律法規透明性.法律法規是技術之外重要的數據透明化實現手段.世界各國家和組織出臺法律法規將知情同意作為個人隱私數據獲取、共享、使用和存儲等過程的基本要求.知情同意是指數據收集者在收集個人數據之時,應當充分告知有關個人數據被收集、處理和利用的情況,并征得主體明確的同意.例如,歐盟實施的《一般數據保護條例》將透明性作為數據主體的基本權利.
通過上述5個部分的數據透明性實現可以將各方參與主體所需要的數據信息作為溯源數據記錄下來.之后,可以依據這些溯源數據實施追蹤問責和對數據決策進行驗證.通常情況下,在問責過程中,需要策略承諾(policy compliance)、違反檢測(violation detection)和隱私審計(privacy audit)等支持;在決策過程中,對數據決策驗證后,還需要綜合考慮數據自動決策和人工決策去獲取更加全面的決策結果.
1.2 實現途徑
數據透明化需要從法律法規和技術2種主要途徑進行考慮.法律法規具有威懾和事后懲罰的作用,技術上實現數據透明性能夠事先預防和為事后提供依據.
法律法規中數據透明性要求的實現建立在法律法規約束、第三方信用背書和道德自律的基礎上.然而,第三方信用背書僅從形式上告知用戶數據獲取內容、數據共享情況和如何使用用戶數據等情況[8].而由于數據獲取、數據共享和數據使用等過程對外不可見,其契約履行情況也無從考證.
技術上實現數據透明性為各個參與主體獲取與自身相關的數據信息提供技術支持.數據獲取透明性和數據共享透明性的實現需要可信的“賬本”記錄數據獲取和共享流通等信息;數據云存儲服務透明性和數據決策透明性需要去中心方式執行驗證、管理數據和執行質量管理等.數據透明化的這些需求與區塊鏈[9-10]的不可篡改、可追蹤、去中心和公開透明的特性相契合.
總體而言,法律法規和技術2種途徑之間既存在互相支持關系也存在互補關系.本文主要探討技術途徑實現數據透明性.
2 數據獲取透明性和數據共享透明性
大數據獲取形式多樣且共享流通錯綜復雜,對于直接發生數據流通的場景,需要實現支持溯源問責的數據獲取和共享,當發生隱私泄露時,數據生產者和數據監管者能夠進行溯源問責;對于需要在分布式數據集上實現數據共享和機器學習的場景,除了需要考慮安全和隱私,還需要考慮透明性和可驗證性,數據使用者能對其過程進行驗證.
2.1 支持溯源問責的數據獲取和數據共享
現有關于支持溯源問責的數據獲取研究還相對有限,數據未知收集、數據過度收集和用戶缺乏控制權等問題有待解決.皮尤研究中心一份關于美國隱私狀況的報告指出:91%的受訪者認為他們對個人數據被收集和使用已經失去控制,61%的受訪者對不了解數據收集者如何使用個人數據感到沮喪[11].文獻[12]提出基于區塊鏈管理移動應用程序的權限,通過權限透明管理實現數據的獲取透明和支持溯源問責.當用戶安裝App時,將權限列表存入區塊鏈,數據經加密后存儲在分布式散列表(distributed Hash table, DHT),用戶發送交易實現權限授予、更新與回收.
現有研究大多基于區塊鏈實現支持溯源問責的數據共享.數據被收集后,由數據收集者存儲并通過訪問控制等方式與其他第三方進行數據共享.然而大多數訪問控制遵循OAuth開放網絡標準實現訪問授權,由數據收集者作為處理訪問控制邏輯的授權引擎,這導致數據共享不支持審計溯源問責.通過訪問控制與區塊鏈結合實現數據共享透明可以支持溯源問責,已經應用在物聯網[13-15]、醫療[16-17]、社交網絡[18]和邊緣計算等場景[19-20].
基于區塊鏈實現的訪問控制可以概括為“數據獲取層—存儲層—區塊鏈層—共享層”4層.在數據獲取層,數據收集者獲取數據生產者產生的數據,需要實現數據獲取透明.在存儲層,采用傳統數據庫管理系統、云存儲和分布式存儲系統等方式存儲數據[21],同時為保證數據安全通常需要將數據加密后存儲.在區塊鏈層,與傳統訪問控制模型自主訪問控制(discretionary access control, DAC)、強制訪問控制(mandatory access control, MAC)、基于屬性的訪問控制(attribute based access control, ABAC)和基于角色的訪問控制(role-based access control, RBAC)等相結合,由區塊鏈執行訪問控制,使任何數據訪問情況都通過交易被記錄在區塊鏈.在共享層,實現數據共享并對共享關系進行保護.
圖3為基于區塊鏈實現社交網絡數據共享.①~③為服務提供者向用戶申請獲取數據,④⑤為訪問請求與授權,⑥~⑨為區塊鏈執行訪問控制.
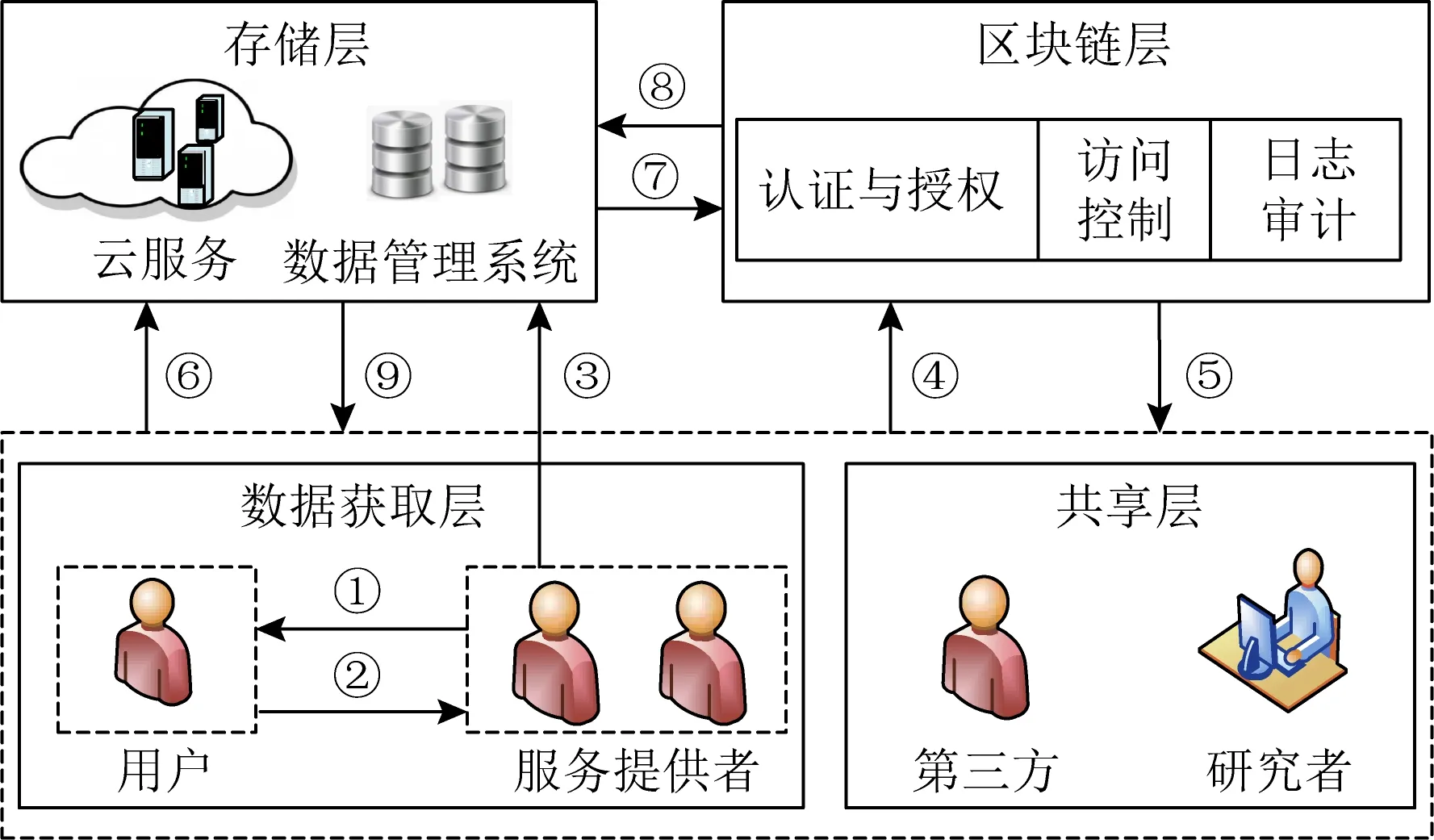
Fig. 3 Data sharing based on blockchain for access control圖3 基于區塊鏈實現社交網絡數據共享透明性
基于區塊鏈實現訪問控制可分為基于交易和基于智能合約2種方式.基于交易方式是使用區塊鏈的交易對訪問控制的策略權限進行管理.大多方法基于比特幣的安全性,應用OP_RETURN指令在比特幣上存儲策略權限.由于比特幣腳本不適合實現復雜的業務邏輯,所以常結合DAC模型實現訪問控制[12].在物聯網數據共享場景中,考慮到底層區塊鏈的可擴展性,區塊鏈層之上增加虛鏈層來提高系統可擴展性[14,22].針對物聯網設備計算和存儲能力受限,目前有2種解決方法:一種方法是采用RBAC模型的擴展模型OrBAC,引入比特幣錢包執行訪問控制代理,并通過授權令牌形式管理權限[13];另一種方法是在區塊鏈之下添加邊緣設備層,由邊緣設備管理設備的身份驗證、創建交易、收集和發送數據至存儲層[15].
基于智能合約方式是將訪問控制策略編寫為智能合約,由智能合約自動執行,當前研究嘗試與DAC或ABAC等訪問控制模型相結合.DAC模型基于身份進行授權,與智能合約結合實現不同身份的用戶權限判斷透明.文獻[16]將策略存儲在以太坊智能合約實現分布式醫療數據庫共享.但是隨著策略規模增加,以太坊智能合約運行成本會增大,且其權限管理不夠靈活;考慮到分布式數據庫可能存在的安全問題,文獻[17]基于Fabric并采用對稱密碼加密醫療數據并將其存儲在符合法律法規要求的云存儲;文獻[18]依據Fabric實現社交網絡數據共享透明;文獻[19]實現不同利益相關者邊緣設備上數據共享透明,并提出符合邊緣設備應用的共識機制、交易類型和區塊來適應邊緣設備計算和存儲能力.DAC模型與區塊鏈相結合能支持問責,但區塊鏈公開透明性也會泄露共享關系和身份隱私,一定程度上僅依據假名并不能保護用戶隱私.ABAC模型通過屬性對實體及約束進行描述,按照訪問者權限條件設置屬性和權限的關系,將區塊鏈與ABAC模型相結合能實現細粒度的、支持身份隱私保護和透明的共享.文獻[23]基于區塊鏈解決屬性簽名時密鑰管理問題實現醫療數據共享;文獻[24]基于EbCoin區塊鏈實現ABAC訪問控制;文獻[25]基于屬性簽名和密文策略屬性加密實現物聯網數據共享;文獻[26]設計密文策略屬性加密實現數據共享.采用ABAC模型,策略不會隨用戶數量呈指數增長,但需權衡問責與隱私保護.
上述方法依據區塊鏈實現訪問控制直接進行數據共享流通,可能會帶來隱私泄露和數據濫用等問題,例如數據收集者承諾使用數據用于科研,而實際卻是用于廣告推薦.由區塊鏈執行訪問控制,與同態加密、安全多方計算相結合[27-28]實現可控的間接數據共享,可避免上述因數據共享流通帶來的問題.此外,數據共享過程中,還可借助區塊鏈實現無需第三方的公平支付,激勵數據共享[29-32].
表1為基于區塊鏈的數據獲取和共享透明方法對比.在區塊鏈層,基于交易的方式多采用比特幣;在共享層,大部分方法都不支持共享關系保護[33-37].同時,大部分方法都是實現訪問控制,只有文獻[32]提出通用的數據共享協議,具有普適性和更廣泛應用場景.此外,這些方法都基于現有區塊鏈實現,沒有考慮現有區塊鏈可擴展性對實現數據獲取與共享透明的影響[38-40].

Table 1 Access Control Methods Based on Blockchain
綜上所述,區塊鏈和傳統訪問控制模式結合從技術上實現數據獲取性和數據共享透明性,使數據生產者能控制自己的數據.但是還存在5個待解決問題:1)數據獲取透明性相關研究仍然有限;2)大量訪問控制請求帶來區塊鏈存儲和可擴展性需求,區塊鏈系統的效率成為亟待解決的重要問題;3)將策略和權限存儲在區塊鏈,很容易被攻擊者找到漏洞,同時會泄漏共享關系,因此需要有效的方法對其進行保護;4)區塊鏈交易確認時間會影響權限更新的及時性;5)大部分研究只給出理念和系統設計,并未提供具體技術實現方法.
2.2 可驗證的分布式數據集共享
在醫學研究、公共安全和商業合作等很多領域,限于一些安全和隱私因素并不能直接傳輸原始數據,需要在分布式數據集上執行統計分析實現數據共享.分布式數據集共享方法如圖4所示.早期的PeerDB[41]和混合P2P系統[42]等傳統分布式數據管理和共享系統并沒有考慮隱私和安全.考慮安全和隱私的方法可以分為中心化和去中心化2類.中心化方法基于可信的第三方、誠實且好奇的第三方、可信的硬件實現,該類方法的通信代價較低但可能存在單點失敗[43-48].去中心化方法主要有秘密共享、安全多方計算和多計算節點等方式.基于秘密共享方式是數據提供者將隱私數據存儲在多個服務端并通過秘密共享方式解密數據[49-50],致使數據提供者失去數據控制權.安全多方計算在不泄露數據情況下執行計算,但目前一些安全多方計算的編譯庫并不支持多于三方參與[51-55].多計算節點方式采用多個計算節點解決單點失敗問題,同時保證數據提供者仍然能控制自己的數據且適用于大規模數據提供者場景.但在實際應用中,數據提供者可能是不可信的,計算節點也可能被攻擊或惡意違背執行協議從而導致結果錯誤,因此需要對數據提供者和計算節點進行驗證,增強分布式數據集共享的可驗證性.

Fig. 4 Ways of distributed data sharing圖4 分布式數據集共享方法
為實現分布式數據集共享的可驗證性,采用區塊鏈或公告牌(bulletin board)公共存儲驗證信息,并通過零知識證明對數據提供者的輸入數據和計算節點計算過程進行驗證[56-58].此外,多計算節點共享方式還需考慮數據機密性、數據提供者和數據之間不可連接性、查詢結果機密性和計算結果的魯棒性等安全和隱私問題.文獻[57]假設數據提供者是誠實且好奇的,且至少存在一個計算節點是誠實的,但沒有將驗證信息公開.文獻[58]假設數據提供者和計算節點都是惡意的,將區塊鏈作為驗證層,實現分布式數據共享.文獻[59]假設數據提供者是惡意的,基于公告牌實現去中心的、可驗證的在線信譽評價系統.
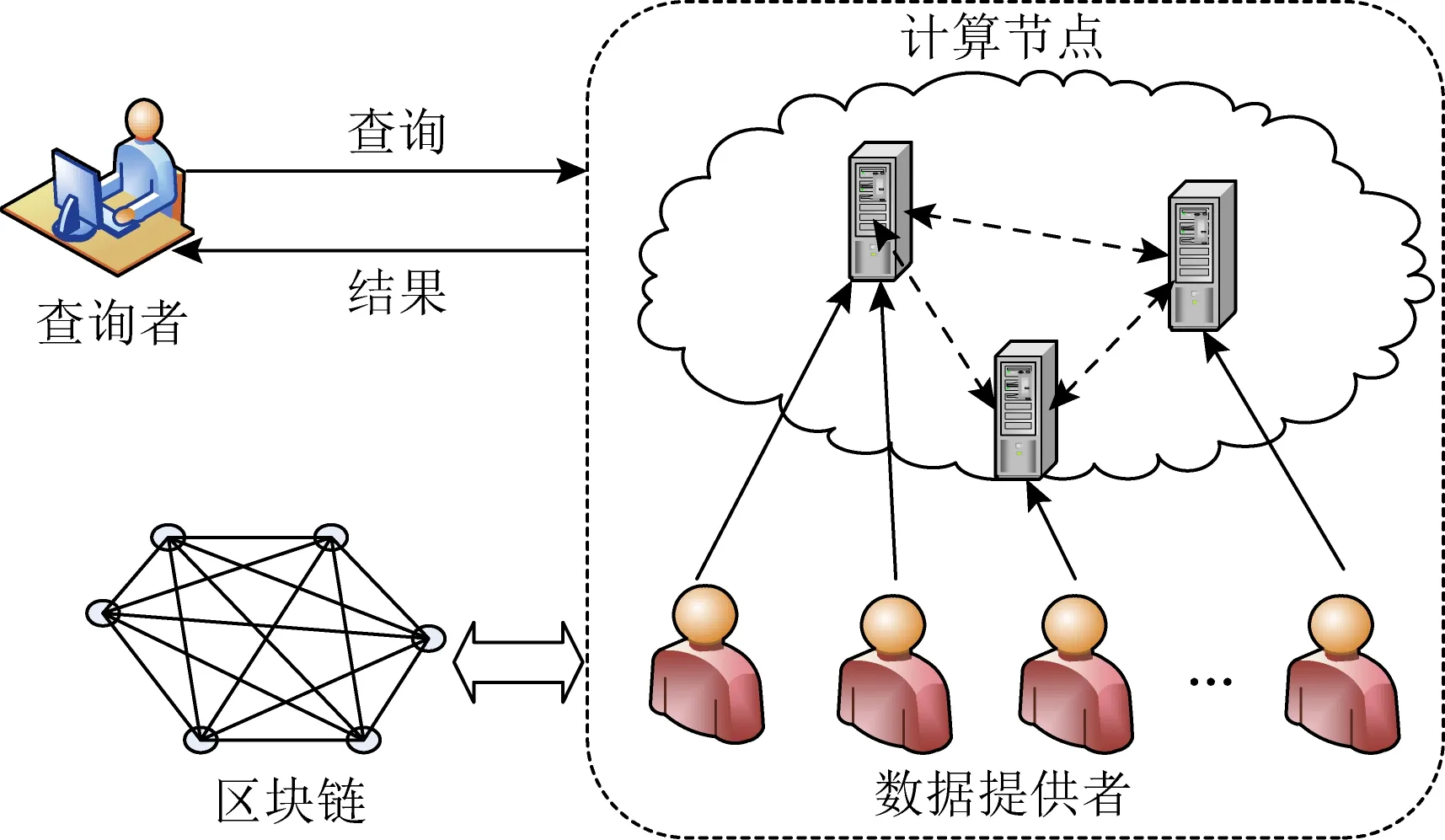
Fig. 5 Verified distributed data sharing system圖5 可驗證分布式數據集共享
圖5將區塊鏈作為驗證層,實現多計算節點的分布式數據集共享.數據提供者和計算節點基于零知識證明和密碼學承諾(commitment)把證明存入區塊鏈.區塊鏈作為驗證層,執行驗證并記錄共享過程.
綜上所述,通過區塊鏈或公告牌作為驗證層可增加分布式數據共享的透明性和支持可驗證.但是還存在2個待解決問題:1)現有方法采用零知識證明和密碼學承諾的方法對數據提供者和計算節點進行驗證,然而零知識證明生成證明和驗證過程都存在較大計算開銷;2)現有方法大都依據范圍承諾對數據提供者的輸入進行驗證,適用范圍有限.
2.3 可驗證的分布式機器學習
分布式機器學習通過數據并行(data parallelism)或模型并行(model parallelism)實現,能間接實現數據共享.目前,分布式機器學習常采用中心化方式,即1個主節點(master)和多個參與節點(parties)共同完成機器學習任務.主節點單點失敗[60-63]和參與節點投毒攻擊(poisoning attack)[64-66]等原因會影響機器學習結果.所以,存儲分布式機器學習過程中重要參數信息是必要的,識別哪些節點貢獻了哪些參數以及該參數對整個模型的影響[67-70].
基于區塊鏈可以實現可驗證的分布式機器學習,由區塊鏈記錄和傳遞重要參數,同時參數傳遞過程中采用差分隱私、秘密共享和同態加密等技術對參數進行保護.實現方式也分為中心化和去中心化2種:中心化方式是指保持固定的主節點和參與節點,由區塊鏈存儲機器學習過程中產生的參數[71-72],但仍然存在單點失敗;去中心化方式依據區塊鏈共識算法產生主節點,通過區塊鏈交易交換并存儲參數信息[73-75].
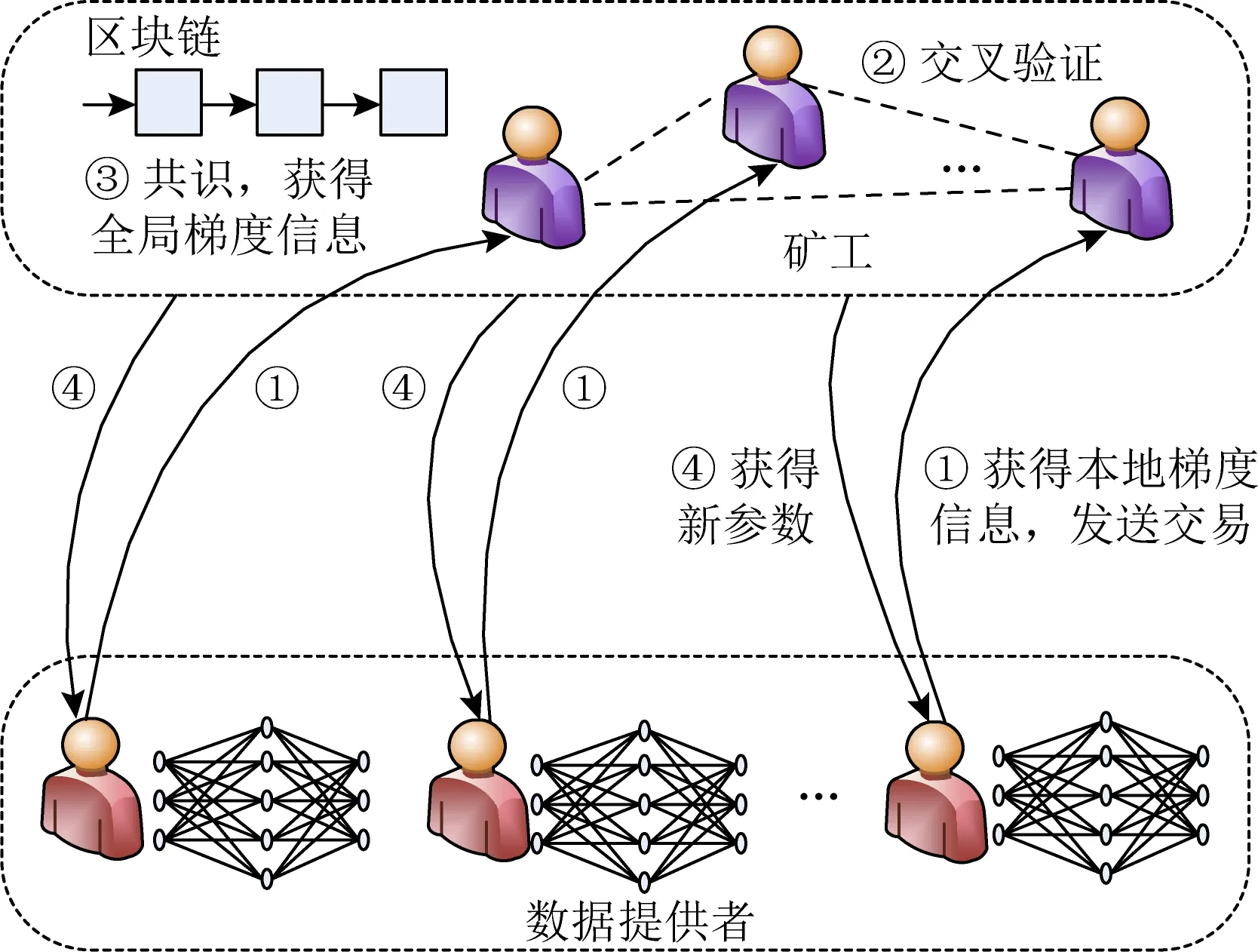
Fig. 6 Machine learning based on blockchain圖6 基于區塊鏈的機器學習
圖6為去中心化的分布式機器學習模型.其中,①為各個數據提供者依據本地數據獲得本地梯度信息(gradient descent, GD),并通過區塊鏈交易上傳至區塊鏈.②為區塊鏈網絡中各個礦工交叉驗證.③為礦工通過共識算法生成并更新全局梯度信息.④為區塊鏈網絡再將更新后的全局梯度信息發送給各個數據提供者.重復迭代執行①~④,直至滿足要求.
表2為基于區塊鏈實現可驗證分布式機器學習方法.大多數方法都采用去中心化方式實現,采用差分隱私對數據提供者的本地梯度信息進行保護.而且,文獻[58]同時支持分布式數據集統計分析和分布式機器學習.

Table 2 Comparison of Distributed Machine Learning Methods
綜上所述,依據區塊鏈實現分布式機器學習,可以增加透明性和支持可驗證.但是還存在3個待解決問題:1)零知識證明生成證明和驗證過程都存在較大計算開銷;2)區塊鏈延遲性對分布式機器學習產生影響[76];3)雖然可以通過經濟激勵和區塊鏈實現公平,如何合理激勵數據提供者并解決激勵帶來的新問題.目前分布式機器學習方法大多假設數據提供者有足夠的數據且愿意參加,事實上對數據提供者獎勵應該與其數據量多少和數據質量等因素成正比,但這也會促使數據提供者為獲得獎勵而虛報數據量等問題.
3 數據云存儲服務透明性
越來越多的數據擁有者 (data owner, DO)將數據存儲至云端,享受云服務提供商(cloud service provider, CSP)提供的云存儲服務.由于DO和CSP之間不存在完全信任,數據完整性驗證、可搜索加密和確定性數據刪除等是保障云存儲數據安全和隱私的重要技術.現有方法大多基于CSP是不完全可信、DO是誠實可信的假設條件,進而引入可信的第三方審計(third party audit, TPA)并支持DO實施驗證.然而,這些假設條件在實際部署和實施時是有限制的,而且大多數方法實現仍然缺乏透明性.事實上,TPA也可能會發生錯誤或合謀,DO也可能進行欺詐[77],所以需要增加CSP,TPA,DO之間交互的透明性和可信性.應用區塊鏈可以在不依賴可信第三方的情況下實現服務透明.此外,依據區塊鏈還可以實現不依賴可信第三方的數據云存儲服務公平.
1) 數據完整性驗證.數據完整性驗證方法有數據持有證明(provable data possession, PDP)和數據可恢復證明(proof of retrievability, POR).PDP可以快速驗證數據是否被云端正確地持有.POR不僅能夠識別數據是否已丟失或損壞,還能對丟失或損壞的數據進行修復.對數據完整性進行驗證時,通常依賴TPA執行驗證,由于驗證過程缺乏透明性,DO只能相信TPA返回的驗證結果.雖然已有研究通過支持DO復審[78-79]、多TPA驗證[80]、可信硬件[81]解決驗證過中TPA的不可信和驗證過程不透明問題,但是這些方法需要引入其他可信方.區塊鏈與傳統完整性驗證方法相結合能夠增加透明性和可信性,有去中心化驗證和中心化驗證2種方式.去中心化驗證是指區塊鏈網絡代替TPA執行驗證.文獻[82]結合PDP和以太坊實現數據完整性驗證,但是并沒有考慮如何減少GAS開銷,文獻[83]也采用PDP和以太坊實現完整性驗證,并實現不依賴第三方的服務公平;文獻[84]采用聯盟鏈驗證,并設計符合應用場景的共識機制.中心化驗證指仍由TPA執行數據完整性驗證,但將完整性驗證挑戰信息存入區塊鏈用于日后復審.文獻[85]利用區塊中nonce字段構建完整性驗證時的挑戰信息,由DO對TPA驗證結果進行復審.這種方式能支持批量處理,提高驗證效率,但要求DO具有一定的計算能力執行復審.
2) 可搜索加密.可搜索加密技術,根據實現功能不同可以分為單關鍵詞搜索、連接關鍵詞搜索和復雜邏輯結構搜索;根據構造算法不同可以分為對稱可搜索加密(symmetric searchable encryption, SSE)和非對稱可搜索加密(asymmetric searchable encryption, ASE)[86].可搜索加密結果完整性驗證方法大多都假設可信的TPA執行公共驗證,缺乏透明性.區塊鏈與傳統可搜索加密方法相結合能夠增加透明性和可信性,可分為去中心化搜索和中心化搜索2種方式.去中心化搜索時,由區塊鏈網絡中各節點通過執行智能合約代替CSP執行搜索,共識過程保證搜索結果是正確的,不需要數據擁有者對搜索結果進行驗證[87].中心化搜索指仍然由CSP執行搜索,在給DO返回搜索結果的同時將驗證信息存入區塊鏈[88].此外,除了傳統中心云存儲,結合區塊鏈還可以實現Storj和Filecoin等去中心云存儲關鍵字搜索結果完整性驗證[89-90].
3) 確定性數據刪除.確定性數據刪除方法有覆蓋寫刪除(deletion by overwriting)和密碼學刪除(deletion by cryptography).當進行確定性數據刪除時,DO發出刪除請求之后,CSP執行刪除操作并返回1位的“成功”或“失敗”作為響應.DO無法根據此響應來確定云端數據是否已經被刪除,刪除過程亦缺乏透明性.已有研究依賴于用戶能訪問存儲介質[91]、沙漏模型[92]等假設條件,或者基于可信硬件[93]和可信第三方[94]實現可驗證確定性數據刪除,但仍缺乏透明性.由區塊鏈記錄刪除證明可以增加數據確定性刪除的透明性.在執行數據刪除時仍由CSP執行刪除, 基于信任但可驗證原則(trust-but-verify),將DO的刪除請求和CSP的刪除證明存入區塊鏈.任何人都可以依據區塊鏈執行驗證操作,增加刪除透明性,防止DO和CSP雙方都可能存在的惡意行為.文獻[95]采用覆蓋寫方法,假設DO和CSP之間已通過身份驗證實現問責,并引入時間服務器為刪除證明提供時間戳服務.文獻[96]在此之上使用基于屬性簽名代替比特幣中采用橢圓曲線數字簽名增加隱私性和安全性,并將交易內容加密防止竊聽攻擊.
表3為基于區塊鏈增加云存儲服務透明性和公平性研究總結.數據完整性驗證多采用去中化方法,僅支持DO驗證.可搜索加密技術都考慮了公平性.確定性數據刪除都采用去中心化方式和公有鏈實現,支持DO和CSP雙方驗證.

Table 3 Comparison of Cloud Storage Services Transparency
綜上所述,應用區塊鏈可增加數據云存儲服務的透明性和公平性.但是還存在3個待解決問題:1)數據完整性驗證,采用中心化驗證方式仍然需要DO執行復審,增加DO的計算負擔;采用去中心化方式,由于以太坊智能合約的執行需要消耗燃料(gas),燃料需要通過以太幣進行購買,所以需要盡力優化實現代碼等方式減少代價消耗.2)可搜索加密技術,一般來說密文和索引都有可能造成不同程度的信息泄露,需要設計更安全的模型使陷門和索引都不泄露關鍵詞信息;采用中心化搜索方式需要實現可驗證的多關鍵詞和復雜邏輯結構搜索.此外,可搜索加密技術也存在以太坊計算燃料消耗問題.3)確定性數據刪除,現有方法均基于覆蓋寫刪除方法,依賴于DO事后發現數據仍然存在的假設,需要設計可驗證的即時數據刪除方法.此外,如果數據擁有者和云服務提供者要求將區塊鏈上信息也同時刪除,此時應該考慮鏈上數據刪除技術[97-99].
4 數據決策透明性
在基于“數據—信息—知識—智慧”模型的數據決策過程中[100],首先需要收集數據,并對其加工處理之后形成對決策有價值的信息,進一步對信息使用歸納、演繹方法得到知識,最后利用這些知識并經由探討得出最終決策.然而,在大數據環境下,此模型的有效性受到沖擊.數據被篡改、數據質量管理過程中的單點失敗等問題會導致決策數據不可靠;訓練數據偏見、算法設計偏見和算法錯誤都可能導致決策算法不可靠.為此,數據決策透明性需要實現決策數據可審計、算法可解釋[101-105]和算法透明.
區塊鏈作為去中心化的分布式數據庫,為決策數據可審計提供支持.通過獲取透明、共享透明和服務透明,在對數據進行追蹤溯源的同時也為數據使用者對決策數據進行審計有促進作用.此外,基于區塊鏈的去中心化存儲模式,數據使用者可以驗證數據是否被篡改和對數據進行追蹤,在金融保險[106]、醫療[107-110]和供應鏈[111-114]等數據完整性要求較高領域有重要意義.區塊鏈作為分布式數據庫,區塊鏈的可擴展性[115]、安全[116]]和隱私[117]等問題是影響其應用的重要因素.此外,考慮到區塊鏈存儲限制,通常采用“鏈上”存儲元數據與“鏈下”存儲數據相結合的方式,并進一步在這些可信數據上執行查詢分析.大部分區塊鏈查詢系統僅提供區塊、交易和賬戶等信息的簡單查詢,并未提供復雜查詢功能.實際應用中還需要實現范圍查詢和Top-k查詢等復雜查詢[118]、數據查詢完整性驗證[119]、密文查詢[120]和細粒度在線查詢溯源[121]等.
多源數據的格式、標準不統一等問題也會影響數據質量,進而影響數據決策.然而傳統數據質量管理和質量控制方法通常依賴可信第三方執行,存在缺乏透明性、單點失敗和時間資源消耗較大的問題.依靠智能合約自動執行可以制定統一數據格式、規則來提高數據質量管控的透明度[122-123].
綜上所述,基于區塊鏈可以促進決策數據可審計,進而有助于決策可解釋.但是還存在3個待解決問題:1)大數據來源廣泛,雖然采用區塊鏈存儲和管理數據可以實現數據追蹤問責,但是如何保證數據在存入區塊鏈之前的真實可信是挑戰問題;2)支持區塊鏈上復雜數據查詢、查詢隱私保護和密文數據查詢等;3)如何保證 “鏈下”存儲數據的安全性.
5 挑戰問題
基于區塊鏈的數據透明化旨在增加大數據價值實現過程的透明性,記錄數據獲取、數據共享和數據使用等信息.進而依據這些信息實現具有不可篡改性質的溯源問責和數據在其生命周期內的可審計,為隱私保護和數據決策可審計提供支持.數據透明性、溯源問責和數據可審計的實現主要面臨5個挑戰問題:
1) 符合數據透明化需求的區塊鏈架構問題.基于區塊鏈的數據透明化具有更強的問責能力,但現有區塊鏈的技術和系統無法被直接應用于數據透明化.例如,實現數據獲取透明性和數據共享透明性對區塊鏈的可擴展性提出較高要求;實施溯源需要涉及多區塊鏈之間的互操作性;實施問責與現有公有鏈的監管困難相沖突.為此,需要設計符合數據透明化需求的高可擴展性、隱私與監管并重、輕量級的區塊鏈,而非完全依賴于現有的、開源的區塊鏈平臺.
2) 具有用戶控制權的數據獲取透明性問題.目前的數據獲取過程缺乏透明性和用戶控制權,導致隱私泄露問題嚴峻.然而,目前關于數據獲取透明性的研究仍然相對有限,亟需一種全新的數據獲取架構以及政策和法律法規的支持,實現數據獲取透明性.此外,用戶(即數據生產者)在數據獲取過程中缺少控制權,用戶或者同意數據收集者制定的數據協議而付出所有數據收集者要求的數據,或者不同意但會導致不能享受服務.在數據獲取透明性實現過程中,如何將控制權還給用戶,由用戶決定數據內容、目的和形式,并根據用戶同意的數據提供服務是挑戰問題.由此,用戶所獲得的服務與自身數據隱私損失之間的平衡也至關重要.
3) 保證數據使用協議的數據共享透明性問題.服務提供者(service provider)作為數據收集者收集用戶數據并為用戶提供服務,但服務提供者是否依據數據使用協議執行數據共享是不透明的.為此如何實現強制執行數據使用協議進行共享并對數據共享情況進行透明記錄是一個挑戰問題.此外,數據開放共享平臺是重要的數據共享流通方式,可以促進不同領域資源相融合,使數據發揮更大價值.例如,政府公共部門數據共享開放可以促進更智能高效的服務和據此為公共問題提出有效的方案.但是數據開放共享平臺的數據可能會涉及眾多個人隱私,原則上數據開放共享需要征求個人同意,但實現難度較大且可能會導致數據出現偏差.為此,在數據提供者和數據使用者能夠保護數據義務的前提下,可以考慮個人同意讓位于集體公共利益,在不經過個人同意情況下實現共享.那么,針對這種 “捆綁”數據共享流通情況,如何在隱私保護前提下實現數據共享透明性,并使用戶能追蹤與他們數據有關的共享流通信息也是一個挑戰問題.
4) 具有不可篡改性質的溯源問責問題.通過獲取透明和共享透明可以獲得溯源數據,依據這些溯源數據可以實現溯源問責.溯源問責的前提是溯源數據的完備性,然而如何使所有的數據獲取和共享事件都被記錄是一個挑戰問題.除技術手段,還需要政策、法律法規等多方面的支持.例如,可采用激勵等非技術手段,將記錄數據獲取和共享信息與企業信譽相關聯,主動記錄數據獲取和共享信息的企業獲得較高的信譽,增加用戶的信任,利于其業務發展.進一步,在大規模數據收集和數據共享流通錯綜復雜背景下,如何實現跨平臺和跨領域的溯源問責是仍未解決的挑戰問題.同時,由于溯源數據描述數據獲取和共享流通整個脈絡,在數據溯源過程中也可能會泄露其他隱私信息,所以溯源過程的隱私保護也至關重要.進一步,如何根據策略承諾和溯源數據自動進行違反檢測也是一個挑戰問題.
5) 保證數據在其數據周期內的可審計問題.在數據生命周期內,數據是否真實產生和處理、數據在共享流通過程中是否被篡改等問題都會影響數據決策結果.雖然基于區塊鏈進行去中心化存儲和管理數據會使數據使用者能夠對數據完整性進行驗證和追溯,但并不能防止數據在存入區塊鏈之前數據被偽造和篡改等問題.此外,為保證決策結果可解釋性,應該保證數據的準確性.然而數據隱私保護技術會在某種程度上擾動數據,必然會造成數據準確性降低,并影響決策數據的可解釋性.如何平衡數據隱私保護和決策數據可審計是一個挑戰問題.
6 總 結
如何保證數據得到正確、合理和規范的使用已經成為大數據生態中亟待解決的根本問題,建立數據透明化的治理體系是有效途徑和重要舉措.本文提出數據透明化研究框架,并總結和分析該框架下的基于區塊鏈的數據透明化研究現狀,最后提出主要面臨的挑戰問題.此外,作為一個跨學科問題,數據透明化將數據獲取和共享流通置于新的范式之下,如何確保用戶具備足夠的法律法規素養來理解和應對這種變化,也是需要學界和全社會共同去探索的課題.于此同時,我們更要遵從“管理數據、理解數據、敬畏數據”的理念,從而促進大數據生態良性發展.
