基于GA優化的支持向量機模型在青椒作物需水量預測中的應用
2021-01-27 00:25:58劉婧然武海霞李灶鵬
節水灌溉 2021年1期
關鍵詞:模型
劉婧然,劉 心,武海霞,鄧 皓,李灶鵬
(1.河北工程大學水利水電學院,河北 邯鄲056038;2.河北省智慧水利重點實驗室,河北 邯鄲056038)
0 引 言
近年來,隨著經濟的發展、人口的增長,水資源短缺問題日益突出。2025年農業用水量需增加19%,才能滿足基本糧食需要[1]。中國是農業大國,農業是最主要的用水部門[2-3]。2018年,農業用水占用水總量的61%以上[4]。農田灌溉用水量占農業用水量的80%以上[5]。在干旱和半干旱地區,灌溉用水尤其匱乏,因此,實現智能精準灌溉,進行作物需水量預測,節約農業灌溉用水,對緩解水資源短缺問題尤為重要。
氣象條件,農業技術措施等均會對作物需水量產生影響。作物需水量與其影響因素之間呈非線性關系,采用人工智能方法模擬非線性關系已得到廣泛應用[6],因此很多學者用人工神經網絡(ANN)對作物需水量進行預測:李志新[7]等構建了GA-Elman 神經網絡參考作物需水量預測模型;孟瑋[8]等建立基于人工蜂群算法的徑向基網絡預測日參考作物需水量模型;鄧皓[9]等提出基于MIV-MEA-Elman 核桃果實膨大期作物需水量預測模型;Abrishami[10]等采用ANN 對小麥和玉米日實際需水量進行估算。此外,支持向量機(SVM)也是人工智能領域中的重要算法模型之一,與ANN 相比,SVM 能夠很好地克服ANN 訓練時間長,訓練結果存在隨機性和過學習等不足[6]。彭世彰[11]等建立了有較強適應性的基于支持向量回歸機的參考作物騰發量實時預報模型,該模型比BP 神經網絡模型有更優的泛化能力;郭淑海[12]等用最小二乘支持向量機對實際蒸散發量進行了估算,估算精度較高;楊會娟[6]等在氣象資料短缺的干旱地區,建立了預測精度較高的基于SVM 的月潛在蒸散發模型;Yunjun Yao[13]等人用貝葉斯模型平均法、一般回歸神經網絡法以及SVM 法估計地面蒸散發,發現SVM 優于其他方法。
以上所述作物需水量(ET)預測模型的輸入變量大多僅選用了常規的氣象因素(氣溫、風速等)。因為氣象因素是作物需水量的主要影響因素之一,但是除氣象因素之外,作物因素、種植模式也會對作物需水量產生影響[14]。對植物而言,作物冠層溫度(Tc)是反映作物水分狀況的一個良好指標,當植物受到水分脅迫、土壤水分虧缺時,導致許多植物氣孔關閉,Tc升高[15-16],可見,Tc與作物需水量息息相關。但以往的作物需水量預測模型研究鮮見將Tc作為預測模型的輸入因素之一,同時,Tc的獲取克服了作物其它生理參數測量時取樣誤差較大和費時的缺點[17],因此本文探討了將Tc引入作物需水量預測模型的適用性。此外,針對節水灌溉的特定種植模式下青椒實際作物需水量(ET)的預測模型研究也較少。滴灌(Drip irrigation)是一種現代高效節水灌溉技術,在國內外已被廣泛應用[18]。壟溝集雨覆蓋種植技術采用溝壟集雨、秸稈覆蓋技術改善土壤水熱狀況,減少土壤水分散失,提高作物產量和水分利用效率,該技術已成為全球農田生態系統的一項重要的集水節灌技術[19-23]。本文將滴灌、秸稈覆蓋、壟溝集雨技術相結合(MFR-DI),用于青椒種植,并對青椒ET 的SVM預測模型進行研究,實現多重節水。為避免模型訓練過程中出現局部最優解,采用具有較強全局優化能力的遺傳算法(GA)優化SVM 模型。同時,探討了在模型輸入因子中引入Tc時,預測模型的適用性,為實際作物需水量預測提供參考,對節約水資源有重要的現實意義。
1 數據來源及模型構建
1.1 數據來源
試驗在河北省邯鄲市河北工程大學精準灌溉試驗場進行(36°35′20″N,114°29′23″E,海拔62.22 m)。試驗布置如圖1所示,試驗小區長為1.2 m,寬為1 m,植株行距50 cm,株距30 cm。集雨滴灌(MFR-DI)種植中,壟和溝的寬度分別約為40 cm和60 cm,壟的高度約15 cm,壟上鋪設塑料薄膜。青椒種植于溝內,同時將玉米秸稈粉碎成20 cm 左右碎段,均勻撒于集雨溝內,測孔距離滴頭5 cm。青椒生育期劃分為4個階段:苗期(約35 d)、開花坐果期(約30 d)、結果盛期(約45 d)、結果后期(約40 d)。研究區氣候為溫帶大陸性季風氣候,年平均氣溫14°C,多年平均降水量548 mm,全年無霜期200 d,年日照時數2 557 h。精準灌溉試驗場設有自動氣象站,記錄的主要氣象數據有:氣溫(°C)、日平均相對濕度(%)、日平均風速(m/s)等。冠層溫度(Tc)采用紅外熱像儀測量,測量精度為0.07°C。在試驗小區內選取長勢均勻的4棵植株,測量每棵植株東南西北各方向的頂部葉片,4個方向的頂部葉片溫度平均值為青椒植株的冠層溫度。將小區內4棵植株的冠層溫度平均值作為本小區青椒的冠層溫度。Tc觀測時間為8∶00-18∶00,每小時測量一次。將每日測量的均值作為日平均冠層溫度。青椒作物需水量的計算根據水量平衡方程求出[14],試驗區無地下水補給。
試驗地土壤土質均勻一致,均為壤土,0~40 cm 土層內的平均容重1.54 g/cm3,田間持水量(占干土質量)為27%,土壤pH值約為7.42。
1.2 GA-SVM 青椒作物需水量預測模型構建
1.2.1 支持向量機
支持向量機(SVM)是1995年由貝爾實驗室的Vapnik 和其研究團隊在統計學習理論的基礎上提出來的一種機器學習算法[24]。支持向量機是建立在統計學理論的VC 維理論和結構風險最小原理基礎上的,通過非線性核函數,將輸入樣本空間映射到高維線性特征空間,因此可以處理高度非線性的分類和回歸等問題[12]。該算法的基礎依據主要是ε-不敏感函數(ε-insensitive function)和核函數(kernel-function)算法。假定訓練樣本集為(xi,yi),i=1,2,…,n,xi為輸入矢量,yi為對應的輸出結果。φ(xi)為樣本數據轉換到高維空間的非線性映射,則在高維空間的線性回歸表達式為[25]:
式中:w為權值矢量;b為偏置值。
w和b有最優解,可用下列函數得到[25]:
約束條件:
式中:C 為懲罰因子,即對SVM 出錯時的懲罰程度,此參數的設置有效防止了個別誤差影響支持向量機整體的優化性能[25]。
根據非線性回歸問題在高維空間的解法,最終得到支持向量機的回歸函數(即ε-不敏感函數)為:
ε-不敏感函數所得結果是該曲線和訓練點的“ε管道”[11]。其中ai*和ai為拉格朗日系數,xiT為樣本向量的轉置,i=1,2,…,n;x為支持向量。在所有樣本點中,只有分布在“管壁”上的那一部分樣本點才決定管道的位置,這部分訓練樣本稱為“支持向量”,這一求解策略使過擬合受到限制,因此能夠顯著提高模型的預報能力[11]。
核函數是預報樣本點的向量x的函數Φ(x)與支持向量x′的函數Φ(x′)的內積[11]。
本文使用RBF 核函數,其表達式為exp (- g|x - xi|2),核函數參數g和懲罰因子C 是影響SVM 性能的主要參數[25],使用遺傳算法(GA)對SVM的主要參數進行優化。
1.2.2 遺傳算法
遺傳算法(GA)是一種模擬自然界生物進化機制的隨機全局搜索和優化方法,其本質是一種高效、并行、全局搜索的方法,具有很強的解決問題能力和廣泛的適應性[26]。該理論利用一組稱為群體的染色體進行操作。該算法包括種群初始化、適應度評價、選擇、交叉和變異五個過程。首先對所有可能的解進行編碼產生初始種群,然后計算種群中每個個體的適應度值,根據適應度值選擇下一代個體,本文采用輪盤賭方法進行選擇操作,之后對選出的個體進行交叉、變異操作以產生新的個體,再對新個體繼續進行選擇、交叉、變異操作[7,24,26],當滿足終止條件時輸出、解碼最優個體,得到SVM 最優參數g和C的初始輸入值。通過反復試驗,設定參數見表1 所示:種群大小100,交叉概率為0.8,變異概率為0.01,迭代次數為100。

表1 遺傳算法參數設置Tab.1 Parameter setting of Genetic Algorithm
1.2.3 GA-SVM 預測模型構建
合理選擇SVM 的參數C 和g,對于提高SVM 預測模型的性能至關重要,傳統SVM 預測模型隨機生成參數值,預測存在不穩定因素。GA 具有較強的尋優能力,本文選取GA 優化SVM 的主要參數,構建GA-SVM 預測模型,構建思路如圖2所示,具體步驟如下:
(1)首先進行數據的采集與預處理。將得到的氣象數據、作物需水量等數據進行歸一化處理,消除原始數據之間的量綱差異。
(2)種群初始化與編碼[26]。構建一定數量的初始種群,并設置懲罰因子C 和核函數參數g的取值范圍,對這兩個參數進行二進制編碼。
(3)計算適應度函數與解碼。計算個體適應度函數,如果滿足要求,解碼種群中的染色體,獲取C 及g 并進行步驟(5) 的模型訓練,如果適應度函數不滿足要求則進行步驟(4)。
(4)選擇、交叉、變異操作。根據適應度值來決定選擇下一代的個體,采用“輪盤賭”選擇法進行個體選擇。之后對選出的個體進行交叉、變異操作來產生新個體,再次進行適應度計算,當滿足遺傳算法的終止條件時輸出、解碼最優參數組合,進行步驟(5),否則再次進行步驟(4),即選擇、交叉、變異操作產生新一代種群,開始新的遺傳。
(5)將最優參數C及g輸入SVM預測模型中進行訓練。
(6)當模型預測精度達到要求,則輸出預測結果,否則需重新調整參數C和g的初始化尋優范圍。
2 結果分析與評價
2.1 數據分析及處理
MFR-DI種植方式下青椒作物實際需水量(ET)在作物生長發育期內的變化規律如圖3 所示,從圖3 可以看出,2014-2017年,青椒從苗期到結果盛期ET 波動式逐漸增加,至結果盛期達到最大值,之后到結果后期階段ET 又波動式逐漸減少,但仍比苗期的ET大。總體來看,青椒ET在生育期內呈現出周期規律性變化。
MFR-DI 種植方式下青椒作物冠層溫度(Tc)與同時段測得的平均氣溫在作物生長發育期內的變化規律如圖4所示,可以看出,2014-2017年,氣溫與Tc的變化規律均為苗期最低,隨后逐漸波動增加,至結果盛期達最高值,之后又逐漸波動降低。氣溫始終高于Tc。并且Tc與氣溫之間的差距(冠氣溫差的絕對值)在苗期最小,隨后逐漸增加,到結果盛期最大,之后又逐漸降低,但仍比苗期差距大。經過相關回歸分析,同一時間段Tc與氣溫的相關系數R2約為0.95。Tc與同一天的平均氣溫的相關系數R2約為0.9,說明Tc與氣溫關系密切。而氣溫又是影響作物需水量的重要氣象因素之一。綜上所述,青椒作物冠層溫度與氣溫、作物需水量息息相關,有必要將其作為預測ET的輸入向量之一。
在模型預測時為便于模型訓練,消除原始數據之間的量綱差異以及極值對模型的影響,更好地反映各因素之間的相互關系,需要對樣本數據進行歸一化預處理,將數據轉換到[0,1]之間。采用公式(5)進行歸一化處理。
式中:xi(i=1,2,…,n)為第i 個樣本數據;x′i為歸一化后的數值;xmax=max{xi},xmin=min{xi}。
不僅要對模型的輸入數據進行處理,對輸出數據也應進行歸一化處理。對使用模型預測的輸出數據,還應進行還原計算,還原計算是公式(5)的逆計算過程,以恢復其實際值。
2.2 預測模型的性能評價
使用均方根誤差(RMSE)、平均絕對誤差(MAE)和納什效率系數(Nash-Sutcliffe coefficient,NS)等來評價模型性能。
式中:Pi為預測值;Oi為計算值(觀測值);ETmean為計算值的均值;N 為觀測數。RMSE 和MAE 的單位都是mm/d,取值范圍從0到∞。NS是無量綱的,取值范圍從1到-∞。對模型進行評價時,RMSE和MAE越小,NS越大,預測精度越高。
2.3 GA-SVM 模型的預測結果分析與評價
以2014-2016年的數據樣本進行訓練,以2017年的數據樣本進行驗證。選擇了不同輸入組合建立了預測模型,如表2所示,其中T 為溫度,包括日最高氣溫(Tmax),日最低氣溫(Tmin)和日平均氣溫(Tmean);RH 為日平均相對濕度;Ph為日平均氣壓;u2為兩米處風速;Rs為太陽輻射;Tc為青椒冠層溫度。因此,所有模型的輸入向量數為7,輸出結果為MFR-DI種植方式下青椒作物實際需水量。設置遺傳種群數量大小為100,迭代次數為100,交叉概率0.8,變異概率0.01,懲罰因子C的變化范圍為0~100,核函數參數g的變化范圍為0~20,經過反復訓練,搜索到SVM最優參數C為0.162 8,g為1.528 8。根據遺傳算法尋優得到的最優參數C和g建立GA-SVM 預測模型并進行2017年青椒作物需水量預測,預測結果如圖5和表3所示。
圖5可以看出,在預測模型輸入向量一致的情況下,GASVM 模型預測青椒作物需水量的精度比SVM 模型精度高,且預測性能穩定。為檢驗模型預測值與計算值ET(即期望目標值)之間的相關性,對二者進行了回歸分析,GA-SVM1 模型預測值與計算值ET 相關系數R2為0.807 33,而SVM 模型的R2為0.728 63。表明GA-SVM 模型比SVM 模型的預測值與計算值之間具有更強的一致性。表3 為GA-SVM 與SVM 模型預測結果的統計性能分析表,可見SVM 與GA-SVM1 模型的RMSE分別為0.960 7、0.901 0 mm/d;MAE 分別為0.769 1、0.673 5 mm/d;NS分別為0.968 0、0.971 8,說明GA-SVM 模型的預測性能優于SVM 模型。由以上分析可知,在輸入相同因素向量時,GA-SVM 比SVM 預測模型具有更高的精度性能。因此,本文僅選取GA-SVM 預測模型,討論了模型輸入因素引入冠層溫度時對模型的預測性能產生的影響。
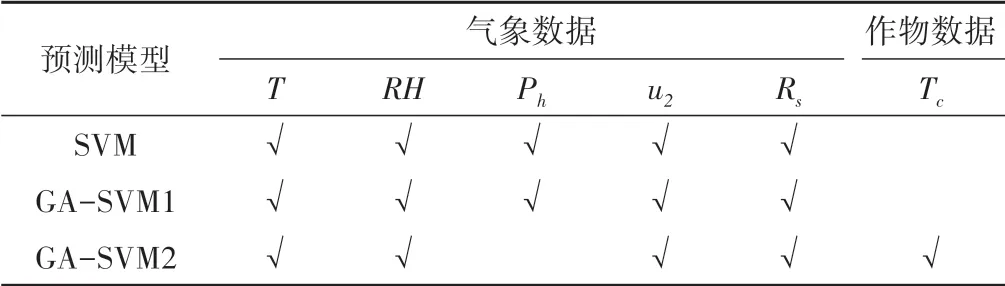
表2 MFR-DI種植模式下基于SVM預測模型的輸入組合Tab.2 Summary of input combinations for SVM prediction model in MFR-DI
2.4 引入冠層溫度的GA-SVM 模型預測結果分析與評價
通過對作物需水量的影響因素(氣象因素,Tc)與作物需水量之間進行相關回歸分析,發現Ph與作物需水量的相關關系比Tc與作物需水量的相關關系弱,因此將GA-SVM1 預測模型氣象因素中的Ph替換為Tc,以保證模型的輸入向量個數不變,如表2 所示(即將GA-SVM1 模型轉變為GA-SVM2 模型)。GA-SVM2 模型預測2017年的作物需水量預測模型性能評價結果如圖6及表3所示。
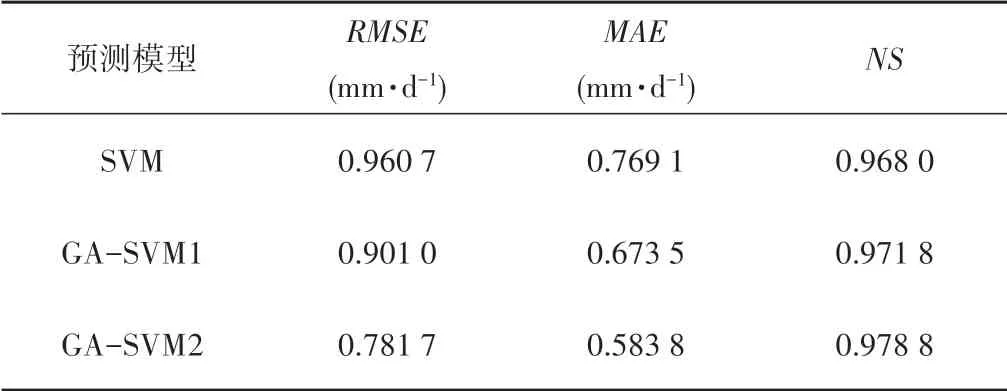
表3 ET預測模型的性能對比Tab.3 Performance comparison of ET prediction models
由圖6可以看出,GA-SVM2模型預測值與計算值ET 相關系數R2為0.830 58,比GA-SVM1 的R2約提高了2.9%,比SVM約提高了14%。另外,從表3可見,GA-SVM2的RMSE,MAE和NS分別為:0.781 7,0.583 8和0.978 8。可以明顯看出引入冠層溫度的GA-SVM2 預測模型的預測結果比單獨輸入氣象因素的GA-SVM1 模型預測的結果更接近ET 計算值(期望目標值),即GA-SVM2模型預測的準確度比GA-SVM1和SVM模型預測的準確度都高。因此,引入影響作物需水量的作物因素中的Tc對預測青椒ET模型起到了積極作用。
3 結 語
本文使用支持向量基作為非線性擬合方法,用于河北省南部地區MFR-DI種植模式下青椒作物需水量的預測,為實現多重、高效節水灌溉提供參考。利用農田水量平衡原理計算得到ET數據(期望目標值),以2014-2016年數據作為訓練樣本,對2017年模型預測結果進行了驗證。在輸入因子相同的情況下,GA-SVM 模型的預測結果優于SVM 模型,由于GA算法的優化,提高了SVM 預測模型的收斂速度,使預測模型的精確度更高,實用性更強。
另外,在預測模型的輸入向量中引入了影響作物需水量的作物因素(冠層溫度,Tc)。通過對該預測模型的性能評價可見,采用引入Tc的GA-SVM2 模型預測結果的準確度最高,其RMSE,MAE,NS,R2分別為:0.781 7 mm/d,0.583 8 mm/d,0.978 8,0.8305 8。綜上所述,引入Tc的GA-SVM 方法為預測青椒作物需水量提供了新思路。
GA-SVM 預測模型參數是在一定自然條件及管理水平下試驗獲取,有一定的適用范圍,并且各物理量之間的關系不能通過預測模型反映出來,這是此類預測模型不可避免的局限性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
