基于Levenshtein距離的Word操作題自動評分算法
2021-01-18 03:38:14羅泉劉芝
現代計算機 2020年32期
羅泉,劉芝
(1.廣西大學行健文理學院,南寧 530005;2.南寧師范大學,南寧 530001)
0 引言
《大學計算機基礎》是大多數高校的通識必修課程,學生們通過學習后能熟練掌握Word、Excel、Power?Point等軟件的常用操作,這就需要任課教師能督促學生完成課堂、課后練習并及時修改。但由于班級眾多,任課教師需要大量時間進行批閱修改。為了減輕教師負擔,眾多學者對Office操作題的自動評分進行了研究,采用的方法主要有幾種。
方法1:使用Office內嵌的VBA技術或Office提供的COM接口,讀取考生文檔每個元素的屬性信息,依次與標準答案的屬性信息進行比較,根據得分點自動計算出分數[1-3]。
方法2:通過計算考生文檔與標準答案之間的文本距離,獲得兩者之間的相似度,實現操作題的自動評分[4]。
方法1依賴于Office軟件,不適用于多線程、高并發情景;方法2適用于考生從空白文件創建答卷文檔的情景,而不適用于從給定素材創建答卷文檔的情景。例如,素材文件有文字“Hello”,題目要求在素材基礎上添加信息,并得到最終文字“Hello World”。若考生將素材文件作為答卷提交,按方法2會得到50分,但實際應為0分。
依據上述分析,本文針對學生基于素材完成操作練習的場景,基于編輯距離實現了一種Word操作題自動評分算法,并對算法進行了測試驗證。
1 Word OpenXML文件格式介紹
微軟從Office 2007開始使用OpenXML[5]格式來存儲信息,一個Office文檔由多個XML文件構成,每個XML文件被稱為部件,用于存儲不同含義的信息。將Word文檔后綴名改為zip并解壓,可以得到如圖1所示的目錄結構。
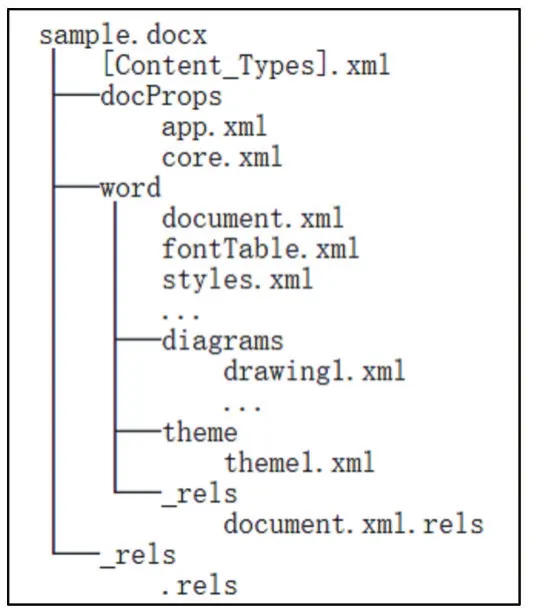
圖1 Word的OpenXML目錄結構
圖1中,styles.xml包含Word樣式信息,分別存儲在
2 Levenshtein距離
Levenshtein距離即文本編輯距離,提出于1965年,是字符串A通過編輯(添加、刪除、修改)單個字符,最終修改為字符串B所用的最少步驟次數,主要用于度量兩個字符串間的距離[7]。其公式如下:

在本文中,Levenshtein距離主要用于度量兩個XML片段間的距離,如片段 A:
(1)定義innerNode類型,innerNode.label用于存儲文本
(2)創建innerNode類型數組NodeArray
(3)依據片段的開始標簽,構造innerNode對象,使 innerNode.label=”A”,添加到 NodeArray數組尾部
(4)依據片段的屬性名attr1,構造innerNode對象,使 innerNode.label=”attr1”,添加到 NodeArray 數組尾部
(5)依據片段的屬性值val1,構造innerNode對象,使innerNode.label=”val1”,添加到NodeArray數組尾部
(6)依據片段的文本abc,構造3個innerNode對象,使每個對象的 label分別為”a”、”b”、”c”,并依次添加到NodeArray數組尾部
(7)依據片段的結束標簽,構造innerNode對象,使 innerNode.label=”/A”,添加到 NodeArray 數組尾部
當比較兩個innerNode類型對象是否相等時,等價于比較對象的label值是否相等。經過轉換,本節例子中片段A與片段B之前的編輯距離轉成了計算Node?Array數組A和NodeArray數組B之間的編輯距離,計算過程與公式(1)一致,最終結果為1。
3 自動評分算法實現
課堂上,在Word操作練習時,教師為學生提供素材文檔,學生基于素材,按照標準答案效果進行操作。因此,評分算法基于素材和答案文檔進行度量更為合理。
(1)XML文件的特征節點向量
一個XML文件可以看成有序特征節點t[i]的集合,可表示為:
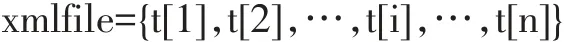
其中,t[i]擁有 name、NodeArray屬性,name 表示當前特征節點名稱,NodeArray表示該節點XML片段轉換而成的innerNode類型數組。
設xmlfilename是xmlfile中所有name屬性值相等的元素的集合,則有:
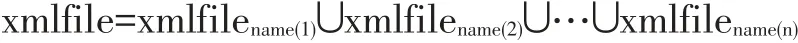
(2)XML 文件編輯距離 xdist(xmla,xmlb)
設A、B分別為文件xmla、xmlb的特征節點向量,Aname、Bname分別是A、B中所有name屬性值相等的元素的集合。分別向A、B中添加NodeArray長度為0的元素,使|A|=|B|并且|Aname(i)|=|Bname(i)|,則兩個 XML 文件的編輯距離計算方式如下:
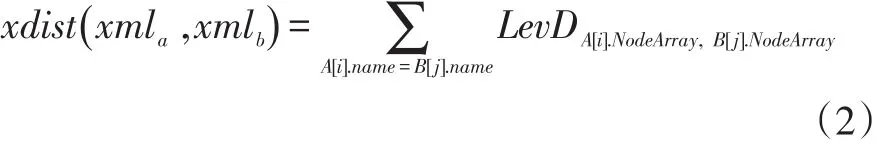
其中,A[i]屬于 A,B[j]屬于 B,A[i]、B[j]必須且只能參與一次LevD運算,A中的元素按順序與B中name屬性相同的元素進行LevD運算。
(3)Word文件距離向量
一個Word文件由多個XML文件構成,為此可表示為 docx={f[1],f[2],…,f[n]},其中,f[n]為一個 XML 文件,按短文件名順序排列。
定義兩個Word文件docxA和docxB之間的距離向量為兩文件之間同名XML文件的編輯距離的有序集合 wVector(docxA,docxB),計算方式如下:
商務筆譯,顧名思義,是針對商務文本的翻譯。對于商務筆譯的研究涉及兩個關鍵詞:一個是商務文本,另一個是翻譯。關于商務文本,需要梳理清四個問題:1)什么是商務文本?即商務文本的涵蓋范圍和種類。2)商務文本的分類方式如何?3)商務文本的功能是什么?4)商務文本的文體風格是什么?關于翻譯,需要梳理清三個“誰”的問題:1)作者是誰?2)譯者是誰?3)讀者是誰?只有理清了以上的問題,才能進入到下一步討論,即什么樣的翻譯理論對商務筆譯有切實的指導作用?本文將主要討論文本類型理論視角下的商務筆譯。
wVector(docxA,docxB)={v[1],v[2],…,v[n]},其中 v[i]=xdist(fa[i],fb[i]),fa[i]∈docxA,fb[i]∈docxB,fa[i]和 fb[i]的短文件名相同。
(4)Word操作題自動評分算法
有 Word 文件 d0、dx、d100,其中 d0 表示素材,dx表示學生答卷,d100表示答案。評分的基本思路為:以d0為基準,分別計算dx到d0的距離向量vx、d100到d0的距離向量v100,然后依據vx在v100上的投影計算分值。
①計算vx=wVector(dx,d0),vx為學生答卷與原始素材文件的文件距離向量。
②計算 v100=wVector(d100,d0),v100 為答案文件與原始素材文件的文件距離向量。
③計算兩個向量vx、v100之間的余弦cosθ=vx·v100/(|vx|·|v100|)
⑤計算百分制成績score=100*projection/|v100|
⑥將百分制成績轉換成等級成績level,當score<60時為一等級,否則每10分為一等級,等級劃分從高到低為 A、B、C、D、E。
4 實驗驗證
本文選用一套綜合練習題,由48位學生在課堂上完成,使用等級成績,以人工評分為基準,對比本文算法與文獻[4]算法,驗證評分效果。
該綜合練習題提供基本素材文件,由學生在此基礎上完成文字替換、字體顏色設置、段落格式設置、添加SmartArt圖形等操作,限時30分鐘完成。首先由教師課后人工評分,結果如表1所示,絕大部分學生能在限定時間內完指定練習,有3位學生講所提供素材作為最終成果提交,人工評分應為0分,等級為E。
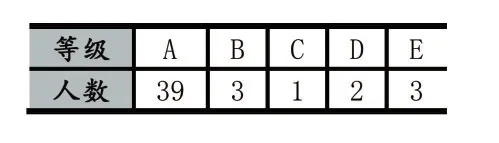
表1 人工評分結果等級分布
在人工評分之后,分別使用本文算法、文獻[4]算法自動給學生作品評分,并與人工評分結果比較,使用聚類中常用的Precision準確度、Recall召回率、F1-Score等指標來評價兩種算法哪一個更優[8];通過記錄兩種算法的運行時間來評價其執行效率。一般來說相關指標數值越大表明越優,實驗結果如表2、表3所示。
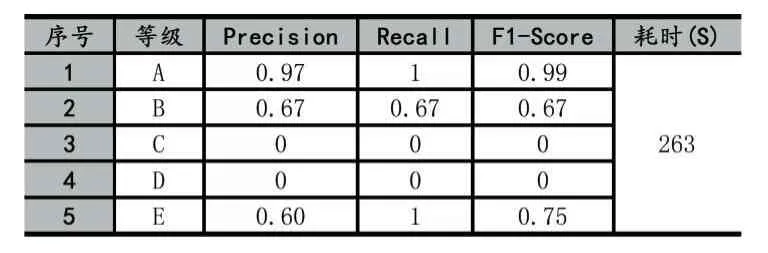
表2 本文算法實驗結果
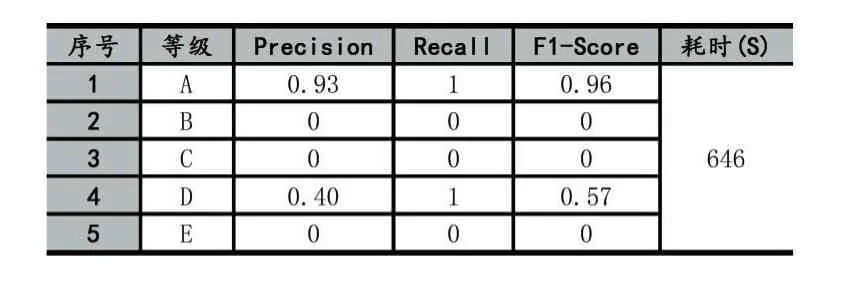
表3 文獻[4]算法實驗結果
從表2、表3中可以看出,在A等級中,Recall為1,說明人工評分中為A的所有成績,在兩種算法中均評定為A,表2的Precision指標比表3的相應指標略高,說明本文算法比文獻[4]算法略優;對于人工評分判定為E等級的3位學生,表2的Recall為1,說明本文算法判定其成績為E等級,表3的Recall為0,說明文獻[4]算法判定為其他等級,因此本文算法更為準確合理;在執行效率上,本文算法所消耗時間263秒,比文獻[4]算法少。綜上所述,在所選測試樣本數據下,與文獻[4]算法相比,本文算法較優,且能滿足日常練習的操作題評分要求。但由于本文算法忽略不同操作步驟的權重,因此無法根據作品所完成的步驟評分,尚未做到與人工評分完全一致。
5 結語
本文針對學生在素材基礎上完成操作練習的場景,設計了一種基于Levenshtein距離的Word自動評分算法,通過計算學生作品文件與原始素材、答案文件之間的距離,通過一系列運算自動獲得該作品分數等級。實驗結果表明,該算法在為等級A、E的作品評分時有較高的精確率,日常的練習評分中有較好的應用效果,可有效提高老師的工作效率,但不足之處在于不能調整步驟分值,不能為操作的每一個步驟設置得分權重,而且測試樣本容量較小,不能覆蓋所有的操作測試,有待進一步完善。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電影(2018年9期)2018-11-14 06:57:21
電子制作(2018年18期)2018-11-14 01:48:06
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
